pytorch分布式训练
1 基本概念
-
rank:进程号,在多进程上下文中,我们通常假定rank 0是第一个进程或者主进程,其它进程分别具有1,2,3不同rank号,这样总共具有4个进程
-
node:物理节点,可以是一个容器也可以是一台机器,节点内部可以有多个GPU;nnodes指物理节点数量, nproc_per_node指每个物理节点上面进程的数量
-
local_rank:指在一个node上进程的相对序号,local_rank在node之间相互独立
-
WORLD_SIZE:全局进程总个数,即在一个分布式任务中rank的数量
-
Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group
如下图所示,共有3个节点(机器),每个节点上有4个GPU,每台机器上起4个进程,每个进程占一块GPU,那么图中一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都一个对应的node_rank。
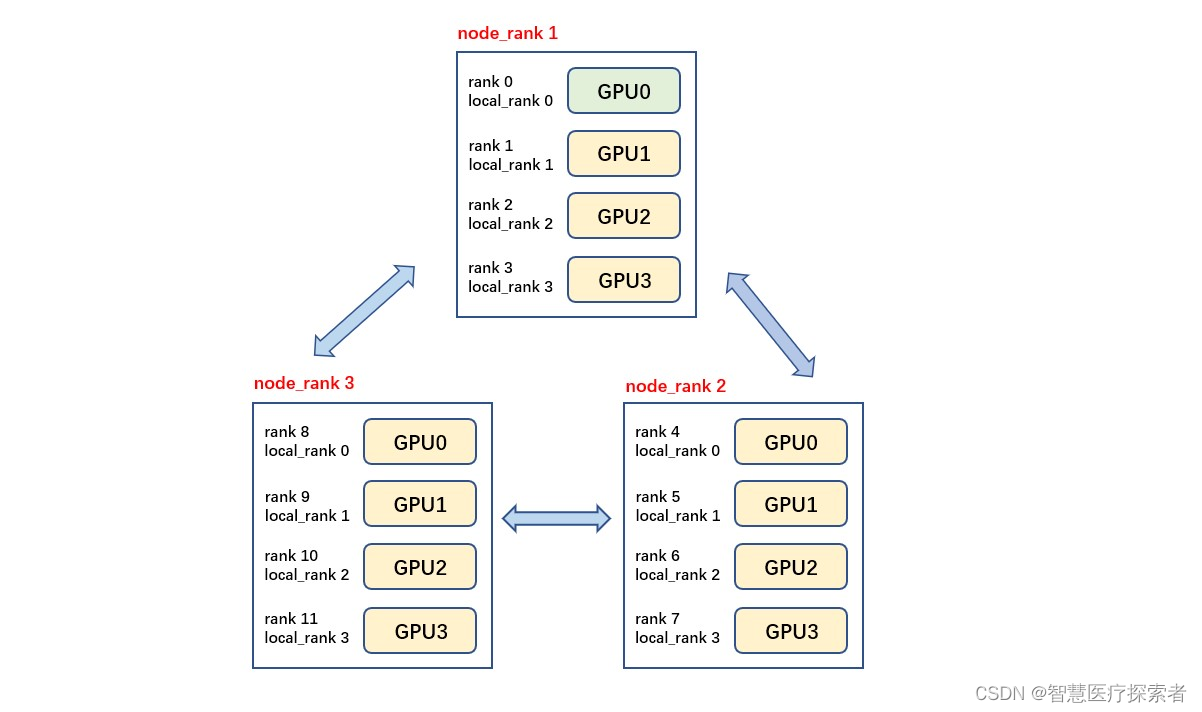
「注意」 rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU),在torch的分布式训练中习惯默认一个rank对应着一个GPU,因此local_rank可以当作GPU号
-
backend 通信后端,可选的包括:nccl(NVIDIA推出)、gloo(Facebook推出)、mpi(OpenMPI)。一般建议GPU训练选择nccl,CPU训练选择gloo
-
master_addr与master_port 主节点的地址以及端口,供init_method 的tcp方式使用。 因为pytorch中网络通信建立是从机去连接主机,运行ddp只需要指定主节点的IP与端口,其它节点的IP不需要填写。 这个两个参数可以通过环境变量或者init_method传入
# 方式1:
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 方式2:
dist.init_process_group("nccl", init_method="tcp://localhost:12355",rank=rank, world_size=world_size)2. 使用分布式训练模型
使用DDP分布式训练,一共就如下个步骤:
-
初始化进程组
dist.init_process_group -
设置分布式采样器
DistributedSampler -
使用
DistributedDataParallel封装模型 -
使用
torchrun或者mp.spawn启动分布式训练
2.1 初始化进程组
进程组初始化如下:
torch.distributed.init_process_group(backend, init_method=None, world_size=-1, rank=-1, store=None,...)backend: 指定分布式的后端,torch提供了NCCL, GLOO,MPI三种可用的后端,通常CPU的分布式训练选择GLOO, GPU的分布式训练就用NCCL即可init_method:初始化方法,可以是TCP连接、File共享文件系统、ENV环境变量三种方式init_method='tcp://ip:port': 通过指定rank 0(即:MASTER进程)的IP和端口,各个进程进行信息交换。 需指定 rank 和 world_size 这两个参数init_method='file://path':通过所有进程都可以访问共享文件系统来进行信息共享。需要指定rank和world_size参数init_method=env://:从环境变量中读取分布式的信息(os.environ),主要包括 MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE。 其中,rank和world_size可以选择手动指定,否则从环境变量读取
tcp和env两种方式比较类似(其实env就是对tcp的一层封装),都是通过网络地址的方式进行通信,也是最常用的初始化方法
「case 1」
import os, argparse
import torch
import torch.distributed as distparse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()if args.init_method == 'TCP':dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':dist.init_process_group('nccl', init_method='env://')rank = dist.get_rank()
print(f"rank = {rank} is initialized")
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)假设单机双卡的机器上运行,则「开两个终端」,同时运行下面的命令
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV如果开启的进程未达到 word_size 的数量,则所有进程会一直等待,直到都开始运行,可以得到输出如下:
# rank0 的终端:
rank 0 is initialized
tensor([1, 2, 3, 4], device='cuda:0')
# rank1的终端
rank 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')在初始化DDP的时候,能够给后端提供主进程的地址端口、本身的RANK,以及进程数量即可。初始化完成后,就可以执行很多分布式的函数了,比如dist.get_rank, dist.all_gather等等
2.2 分布式训练数据加载
DistributedSampler把所有数据分成N份(N为worldsize), 并能正确的分发到不同的进程中,每个进程可以拿到一个数据的子集,不重叠,不交叉
torch.utils.data.distributed.DistributedSampler(dataset,num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)-
dataset: 需要加载的完整数据集 -
num_replicas: 把数据集分成多少份,默认是当前dist的world_size -
rank: 当前进程的id,默认dist的rank -
shuffle:是否打乱 -
drop_last: 如果数据长度不能被world_size整除,可以考虑是否将剩下的扔掉 -
seed:随机数种子。这里需要注意,从源码中可以看出,真正的种子其实是self.seed+self.epoch这样的好处是,不同的epoch每个进程拿到的数据是不一样,因此需要在每个epoch开始前设置下:sampler.set_epoch(epoch)
「case 2」
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for epoch in range(start_epoch, n_epochs):sampler.set_epoch(epoch) # 设置epoch 更新种子train(loader)2.3 模型分布式封装
将单机模型使用torch.nn.parallel.DistributedDataParallel 进行封装
torch.cuda.set_device(local_rank)
model = Model().cuda()
model = DistributedDataParallel(model, device_ids=[local_rank])「注意」 要调用model内的函数或者属性,使用model.module.xxxx
这样在多卡训练时,每个进程有一个model副本和optimizer,使用自己的数据进行训练,之后反向传播计算完梯度的时候,所有进程的梯度会进行all-reduce操作进行同步,进而保证每个卡上的模型更新梯度是一样的,模型参数也是一致的。
在save和load模型时候,为了减小所有进程同时读写磁盘,一般处理方法是以主进程为主
「case 3」
model = DistributedDataParallel(model, device_ids=[local_rank])
CHECKPOINT_PATH ="./model.checkpoint"
if rank == 0:torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# barrier()其他保证rank 0保存完成
dist.barrier()
map_location = {"cuda:0": f"cuda:{local_rank}"}
model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))
# 后面正常训练代码
optimizer = xxx
for epoch:for data in Dataloader:model(data)xxx# 训练完成 只需要保存rank 0上的即可# 不需要dist.barrior(), all_reduce 操作保证了同步性if rank == 0:torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)2.4 启动分布式训练
如case1所示我们手动运行多个程序,相对繁琐。实际上本身DDP就是一个python 的多进程,因此完全可以直接通过多进程的方式来启动分布式程序。 torch提供了以下两种启动工具来更加方便的运行torch的DDP程序。
2.4.1 mp.spawn
使用torch.multiprocessing(python的multiprocessing的封装类) 来自动生成多个进程
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False)-
fn: 进程的入口函数,该函数的第一个参数会被默认自动加入当前进*程的rank, 即实际调用:fn(rank, *args) -
nprocs: 进程数量,即:world_size -
args: 函数fn的其他常规参数以tuple的形式传递
「case 4」
import torch
import torch.distributed as dist
import torch.multiprocessing as mpdef fn(rank, ws, nums):dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765',rank=rank, world_size=ws)rank = dist.get_rank()print(f"rank = {rank} is initialized")torch.cuda.set_device(rank)tensor = torch.tensor(nums).cuda()print(tensor)if __name__ == "__main__":ws = 2mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))直接执行一次命令 python3 test_ddp.py 即可,输出如下:
rank = 0 is initialized
rank = 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')这种方式同时适用于TCP和ENV初始化
2.4.2 launch/run
使用torch提供的 torch.distributed.launch工具,可以以模块的形式直接执行
python3 -m torch.distributed.launch --配置 train.py --args参数常用配置有:
-
--nnodes: 使用的机器数量,单机的话,就默认是1了 -
--nproc_per_node: 单机的进程数,即单机的worldsize -
--master_addr/port: 使用的主进程rank0的地址和端口 -
--node_rank: 当前的进程rank
在单机情况下, 只有--nproc_per_node 是必须指定的,--master_addr/port和node_rank都是可以由launch通过环境自动配置
「case5 test_dist.py」
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import osdist.init_process_group('nccl', init_method='env://')rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)输入如下命令
python3 -m torch.distribued.launch --nproc_per_node=2 test_dist.py得到如下输出
rank = 0 is initialized in 127.0.0.1:29500; local_rank = 0
rank = 1 is initialized in 127.0.0.1:29500; local_rank = 1
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')注意:torch1.10开始用终端命令torchrun来代替torch.distributed.launch,具体来说,torchrun实现了launch的一个超集,不同的地方在于:
-
完全使用环境变量配置各类参数,如RANK,LOCAL_RANK, WORLD_SIZE等,尤其是local_rank不再支持用命令行隐式传递的方式
-
能够更加优雅的处理某个worker失败的情况,重启worker。需要代码中有load_checkpoint(path)和save_checkpoint(path) 这样有worker失败的话,可以通过load最新的模型,重启所有的worker接着训练。具体参考 imagenet-torchrun
-
训练的节点数目可以弹性变化
上面的命令可以写成如下
torchrun --nproc_per_node=2 test_dist.pytorchrun或者launch对上面ENV的初始化方法支持最完善,TCP初始化方法的可能会出现问题,因此尽量使用env来初始化dist
3. 分布式做evaluation
分布式做evaluation的时候,一般需要先所有进程的输出结果进行gather,再进行指标的计算,两个常用的函数:
-
dist.all_gather(tensor_list, tensor): 将所有进程的tensor进行收集并拼接成新的tensorlist返回 -
dist.all_reduce(tensor, op)这是对tensor的in-place的操作, 对所有进程的某个tensor进行合并操作,op可以是求和等
「case 6 test_ddp.py」
import torch
import torch.distributed as distdist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
torch.cuda.set_device(rank)tensor = torch.arange(2) + 1 + 2 * rank
tensor = tensor.cuda()
print(f"rank {rank}: {tensor}")tensor_list = [torch.zeros_like(tensor).cuda() for _ in range(2)]
dist.all_gather(tensor_list, tensor)
print(f"after gather, rank {rank}: tensor_list: {tensor_list}")dist.barrier()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"after reduce, rank {rank}: tensor: {tensor}")通过torchrun --nproc_per_node=2 test_ddp.py 输出结果如下:
rank 1: tensor([3, 4], device='cuda:1')
rank 0: tensor([1, 2], device='cuda:0')
after gather, rank 1: tensor_list: [tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')]
after gather, rank 0: tensor_list: [tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')]
after reduce, rank 0: tensor: tensor([4, 6], device='cuda:0')
after reduce, rank 1: tensor: tensor([4, 6], device='cuda:1')在evaluation的时候,可以拿到所有进程中模型的输出,最后统一计算指标,基本流程如下
pred_list = []
for data in Dataloader:pred = model(data)batch_pred = [torch.zeros_like(label) for _ in range(world_size)]dist.all_gather(batch_pred, pred)pred_list.extend(batch_pred)
pred_list = torch.cat(pred_list, 1)
# 所有进程pred_list是一致的,保存所有数据模型预测的值4. 常用函数
-
torch.distributed.get_rank(group=None)获取当前进程的rank -
torch.distributed.get_backend(group=None)获取当前任务(或者指定group)的后端 -
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=32,num_workers=16,pin_memory=True)num_workers: 加载数据的进程数量,默认只有1个,增加该数量能够提升数据的读入速度。(注意:该参数>1,在低版本的pytorch可能会触发python的内存溢出)pin_memory: 锁页内存,加快数据在内存上的传递速度。 若数据加载成为训练速度的瓶颈,可以考虑将这两个参数加上
进程内指定显卡,很多场景下使用分布式都是默认一张卡对应一个进程,所以通常,我们会设置进程能够看到卡数
# 方式1:在进程内部设置可见的device
torch.cuda.set_device(args.local_rank)
# 方式2:通过ddp里面的device_ids指定
ddp_model = DDP(model, device_ids=[rank])
# 方式3:通过在进程内修改环境变量
os.environ['CUDA_VISIBLE_DEVICES'] = loac_rank相关文章:
pytorch分布式训练
1 基本概念 rank:进程号,在多进程上下文中,我们通常假定rank 0是第一个进程或者主进程,其它进程分别具有1,2,3不同rank号,这样总共具有4个进程 node:物理节点,可以是一个…...
模型的创建、参数初始化、保存和加载)
【PyTorch】(三)模型的创建、参数初始化、保存和加载
文章目录 1. 模型的创建1.1. 创建方法1.1.1. 通过使用模型组件1.1.2. 通过继承nn.Module类 1.2. 模型组件1.2.1. 网络层1.2.2. 函数包1.2.3. 容器 1.3. 将模型转移到GPU 2. 模型参数初始化3. 模型的保存与加载3.1. 只保存参数3.2. 保存模型和参数 1. 模型的创建 1.1. 创建方法…...

高效开发之:判断复杂list中的对象属性是否包含某个值
技术使用:使用了Java 8引入的Stream API以及Optional类。这些特性用于简化集合的处理和减少空指针异常。 List<ResourceInfoDto> authData chatBase.getData();String baseName dto.getBaseName();Optional<ResourceInfoDto> authWithResourceCode a…...
MacOS + Android Studio 通过 USB 数据线真机调试
环境:Apple M1 MacOS Sonoma 14.1.1 软件:Android Studio Giraffe | 2022.3.1 Patch 3 设备:小米10 Android 13 一、创建测试项目 安卓 HelloWorld 项目: 安卓 HelloWorld 项目 二、数据线连接手机 1. 手机开启开发者模式 参考࿱…...
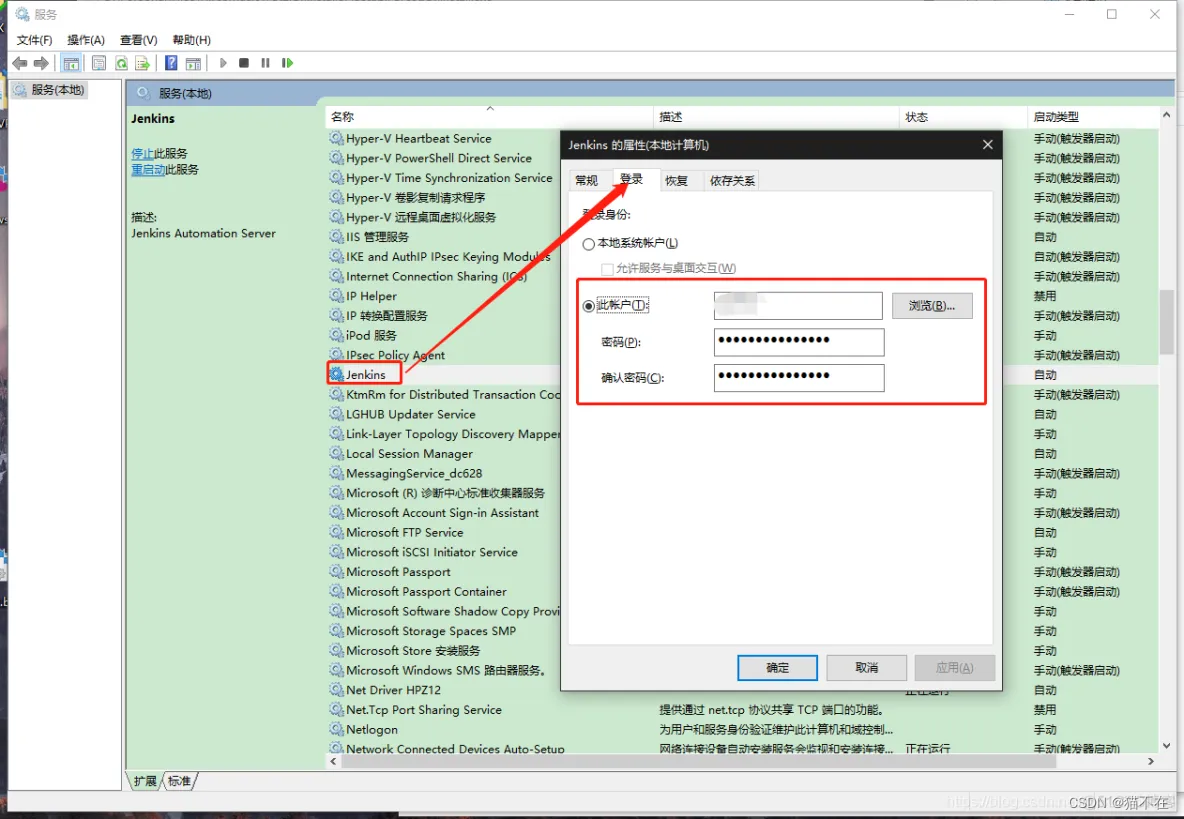
部署jekins遇到的问题
jdk问题 我用的jdk版本是21的结果版本太新了,启动jekins服务的时候总是报错最后在jekins的安装目录下面的jekinsErr.log查看日志发现是jdk问题最后换了一个17版本的就解决了。 unity和jekins jekins和Git源码管理 jekins和Git联动使用 我想让jekins每次打包的时…...
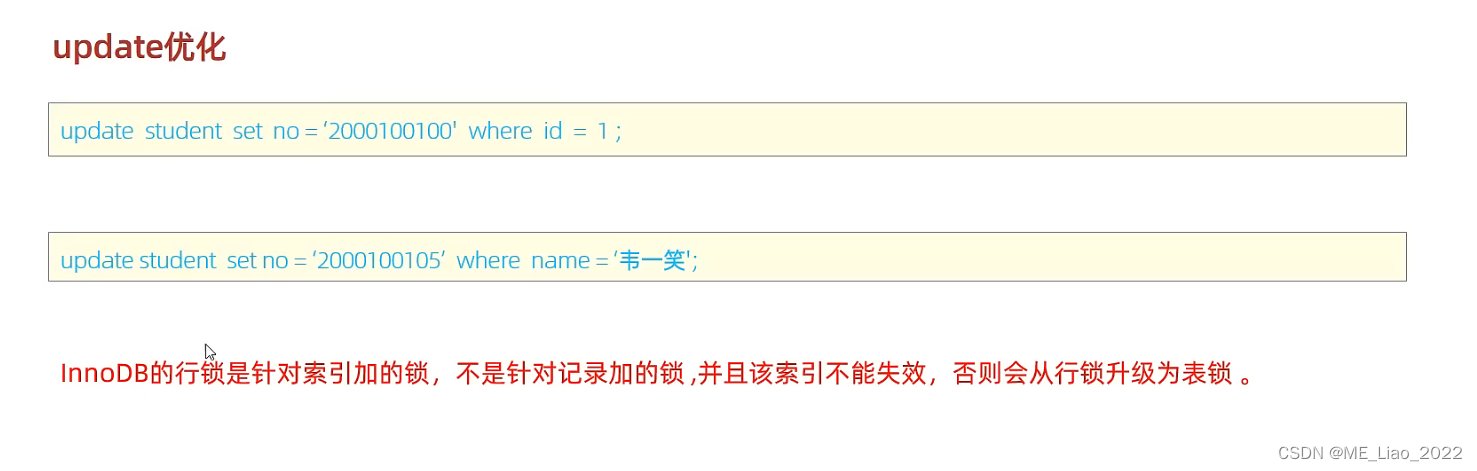
SQLY优化
insert优化 1.批量插入 手动事务提交 主键顺序插入,主键顺序插入性能高于乱序插入 2.大批量插入数据 如果一次性需要插入大批量数据,使用Insert语句插入性能较低,此时可以使用MYSQL数据库提供的load指令进行插入 主键优化 主键设计原则 …...
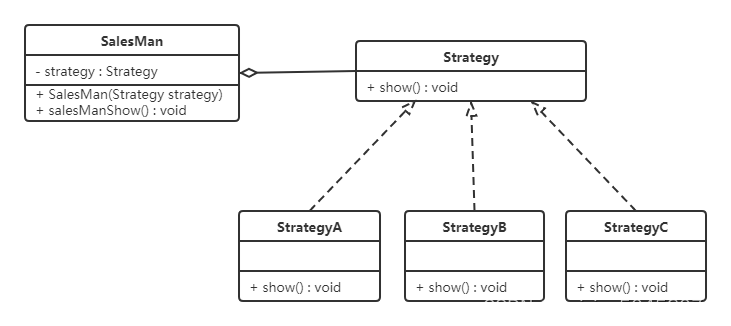
设计模式——行为型模式(一)
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。 行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为,后者采用组合或聚合在对象间分配行…...
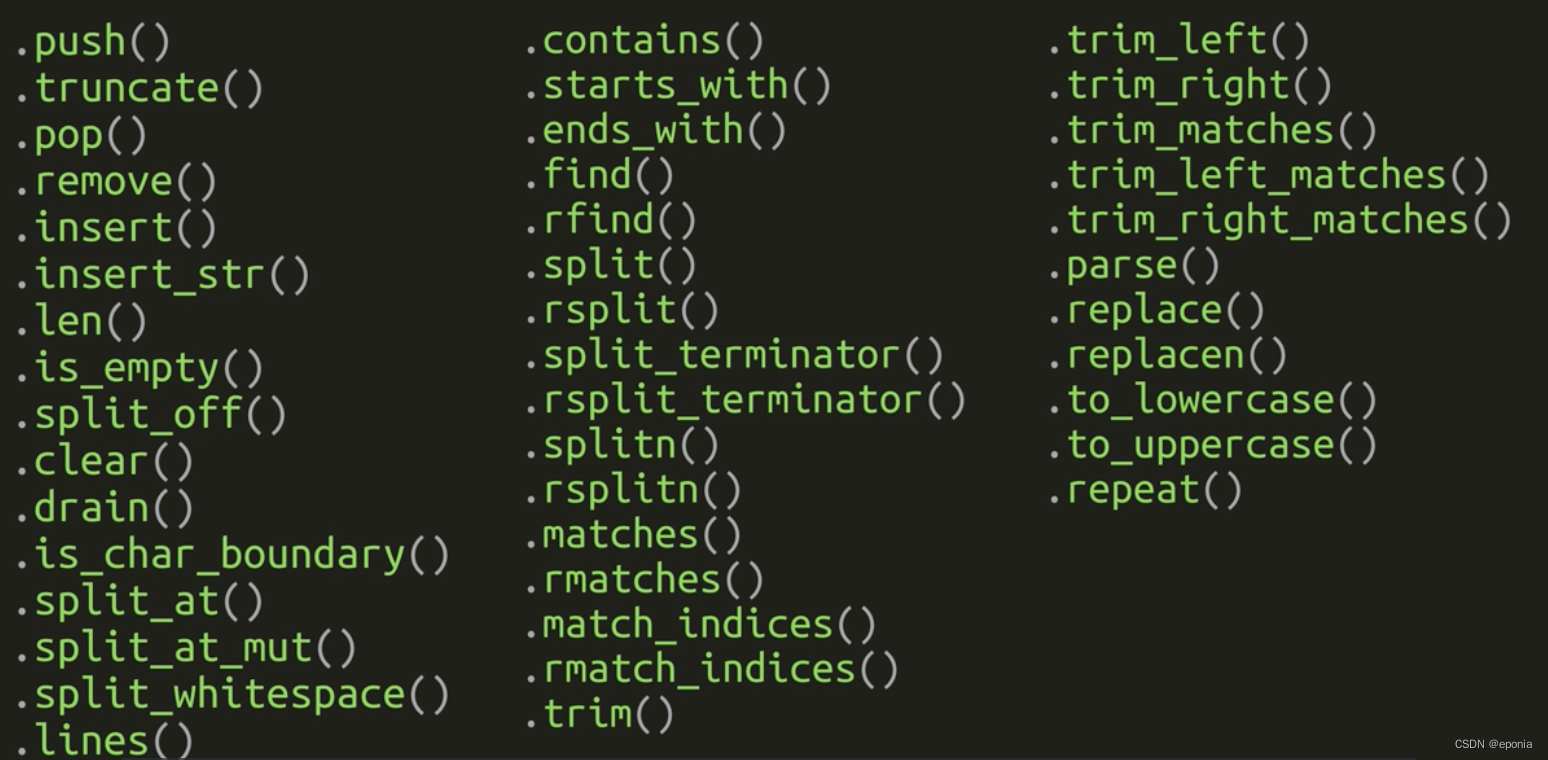
Rust语言入门教程(六) - 字符串类型
在Rust中, 字符串类型其实是一个比较复杂的话题。在Rust的标准库中,至少都提供了6种字符串类型,我们平常使用的最多的是其中的两种。这两种类型互相之间也有所关联: str: 字符串切片String 字符串 其中, 字…...
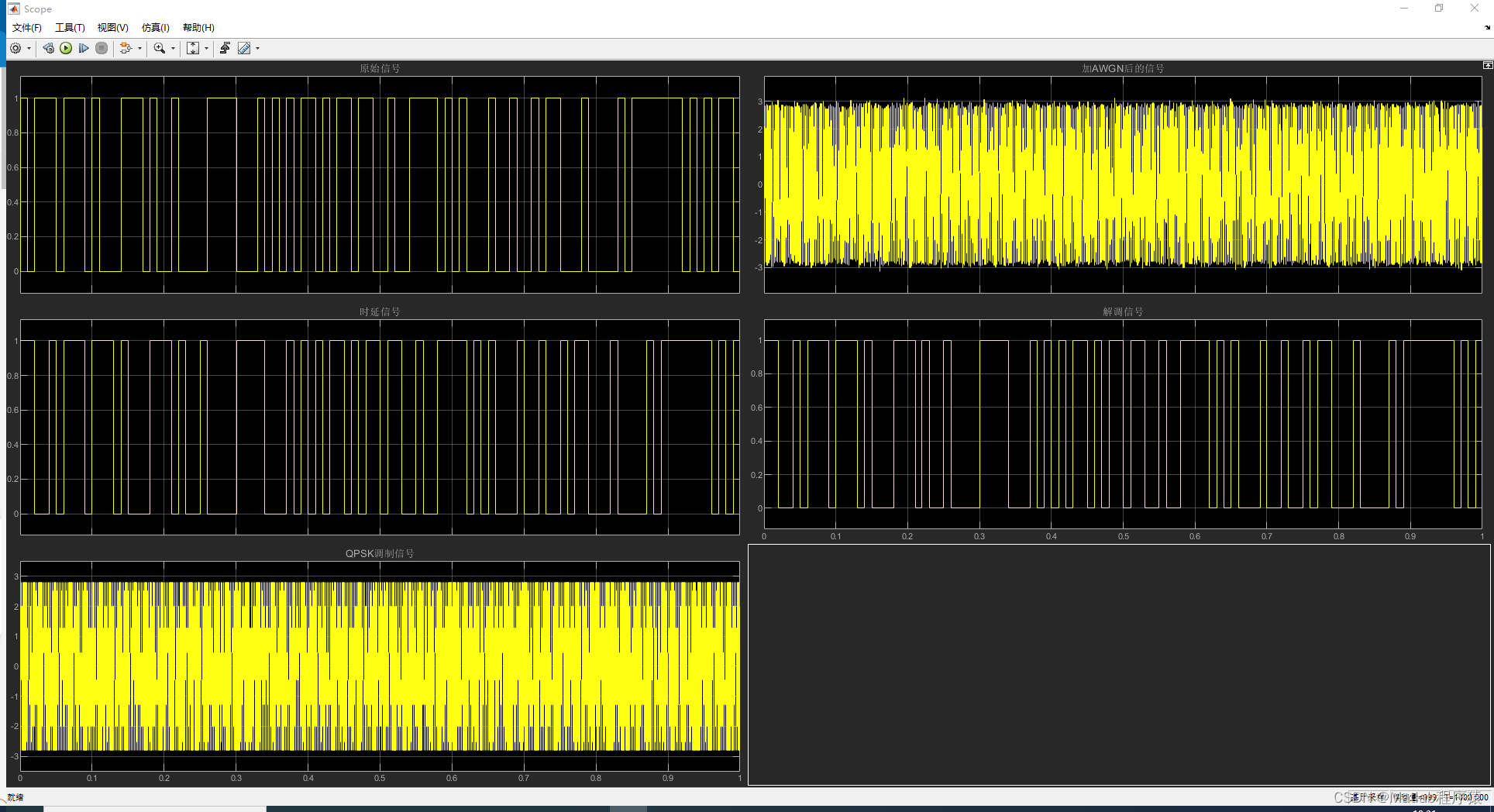
【MATLAB源码-第92期】基于simulink的QPSK调制解调仿真,采用相干解调对比原始信号和解调信号。
操作环境: MATLAB 2022a 1、算法描述 QPSK,有时也称作四位元PSK、四相位PSK、4-PSK,在坐标图上看是圆上四个对称的点。通过四个相位,QPSK可以编码2位元符号。图中采用格雷码来达到最小位元错误率(BER) —…...

关于C语言控制浮点数输出精度问题
众所周知 C语言在控制一个浮点数输出精度的时候是在%和f之间加上一个.(想要控制的精度) 如:printf("%.2f", num); 问,试问:(你就是我的御主吗?)如果输出的精度是根据输入的数字变化的怎么办&am…...
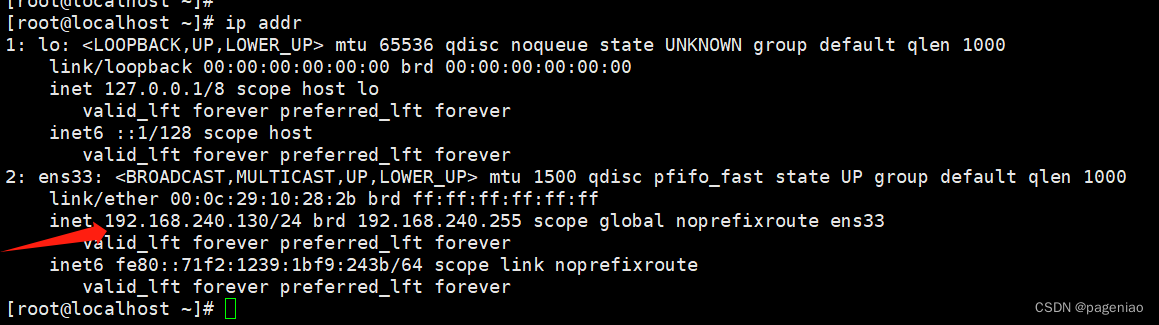
【Linux 静态IP配置】
静态IP配置 1.NAT模式设置2.设置静态ip3.重启网络4.查看ip 1.NAT模式设置 首先设置虚拟机中NAT模式的选项,打开VMware,点击“编辑”下的“虚拟网络编辑器”,设置NAT参数 注意: VMware Network Adapter VMnet8保证是启用状态 …...

【Linux 操作系统配置 SFTP】
Linux 操作系统配置 SFTP sftp采用的是ssh加密隧道,安装性方面较ftp强,而且依赖的是系统自带的ssh服务,不像ftp还需要额外的进行安装基于 ssh 的 sftp 服务相比 ftp 有更好的安全性(非明文帐号密码传输)和方便的权限管…...

信贷专员简历模板
这份简历内容,以信贷专员招聘需求为背景,我们制作了1份全面、专业且具有参考价值的简历案例,大家可以灵活借鉴。 信贷专员简历在线编辑下载:百度幻主简历 求职意向 求职类型:全职 意向岗位:信贷专员 …...
Python自动化测试面试经典题
相信大家经历过许多面试都会有这样的感受:好不容易通过了 2 -3轮技术面试,但是薪资不够理想;要么被面试的测试专家虐的不要不要的。但每一次的面试也能让自己认识到不足之处,这样才有利于后续拿到理想的offer。 牛鹭学院的学子对…...
java+springboot物流管理系统设计与实现wl-ssmj+jsp
物流管理系统的开发和综合性的物流信息网站平台的建设。研究的重点是运输管理信息系统.本系统是一套基于运输作业流程的管理系统,该系统以运输任务、货品、商务三大线索设计开发。运输任务是该管理系统的核心,系统通过对运输任务中的接收、调…...
概念理论类-k8s :架构篇
转载:新手通俗易懂 k8s :架构篇 Kubernetes,读音是[kubə’netis],翻译成中文就是“库伯奈踢死”。当然了,也可以直接读它的简称:k8s。为什么把Kubernetes读作k8s,因为Kubernetes中间有8个字母…...
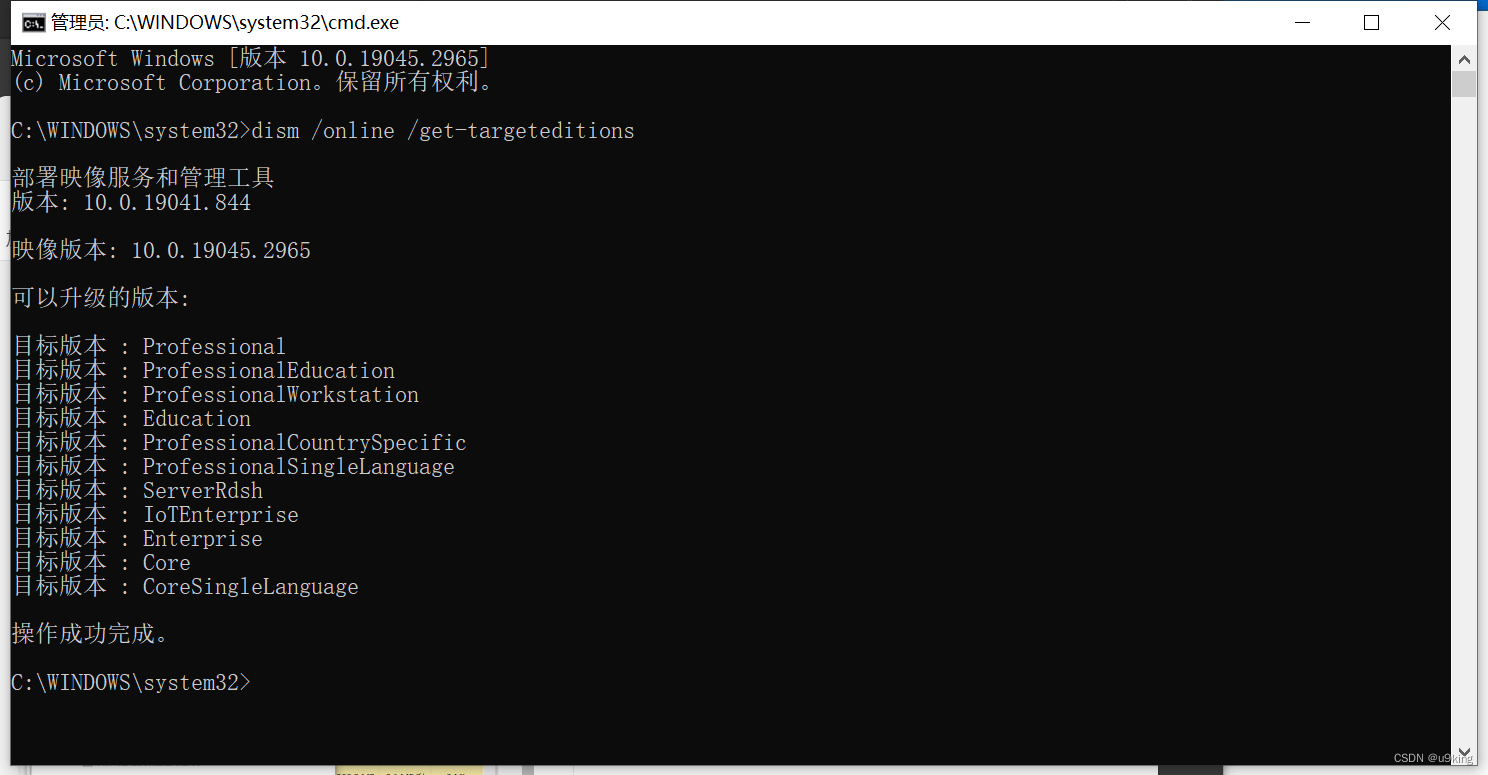
window10家庭版中文转专业版流程
1.确认当前为家庭中文版 2.用管理员权限打开cmd窗口 3.输入 dism /online /get-targeteditions ,查询当前支持的升级的版本 4.专业版密钥:VK7JG-NPHTM-C97JM-9MPGT-3V66T 5.changepk.exe /productkey VK7JG-NPHTM-C97JM-9MPGT-3V66T...
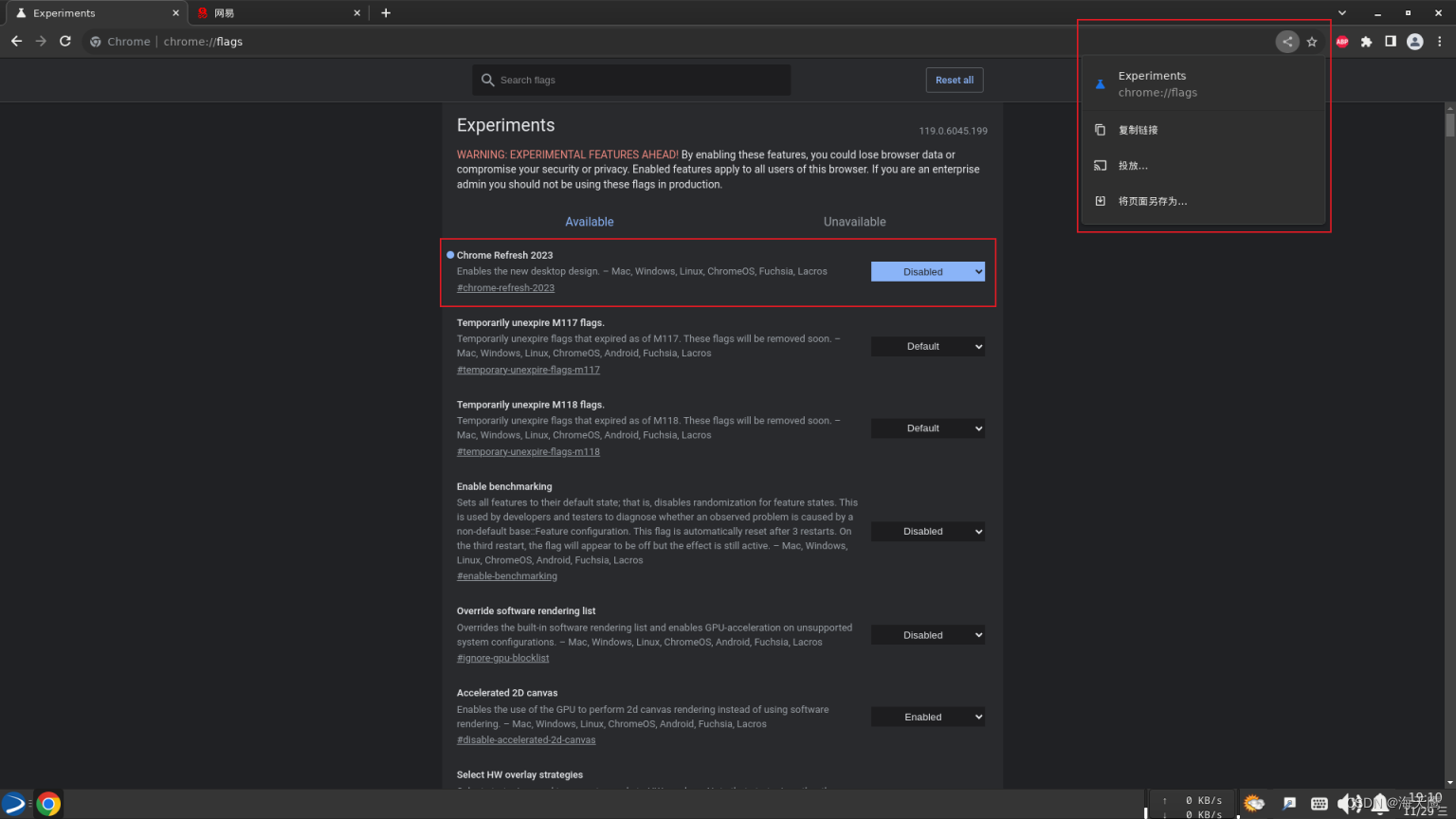
Chrome显示分享按钮
分享按钮不见了! Chrome://flags Chrome Refresh 2023 Disabled 左上角的标签搜索会到右上角。...
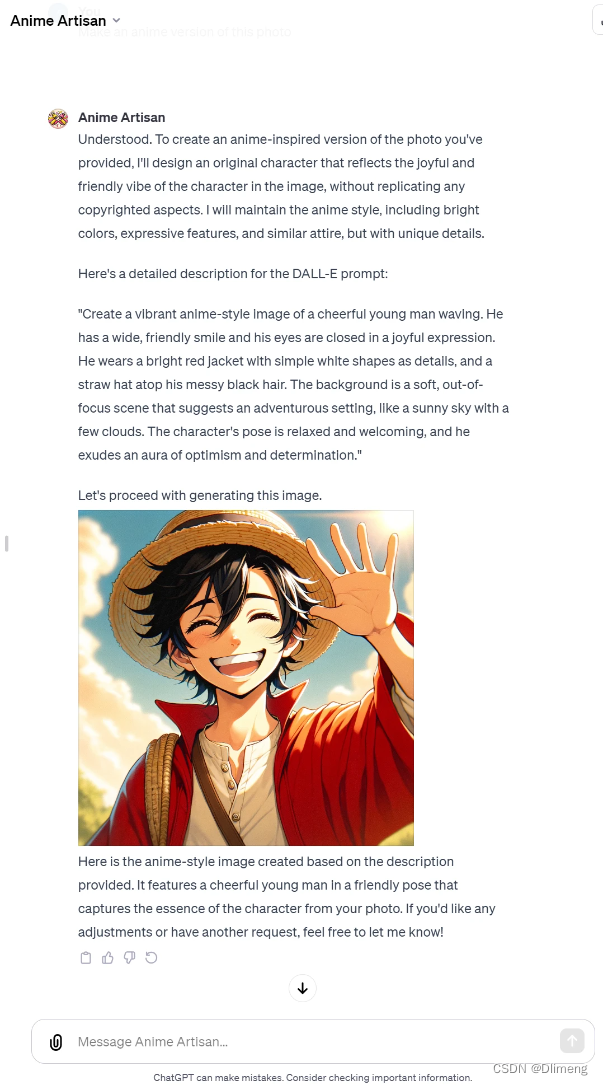
GPTS-生成一个动漫图像GPT
介绍 GPTs是ChatGPT的定制版本,用户可以通过组合指令、知识和功能来定制用于特定任务或主题的GPT。它们可以根据需要简单或复杂,解决从语言学习到技术支持等各种事情。 创建GPTs Plus和Enterprise用户可以在chat.openai.com/create上开始创建GPTs。 您可以通过在ChatGPT上的…...
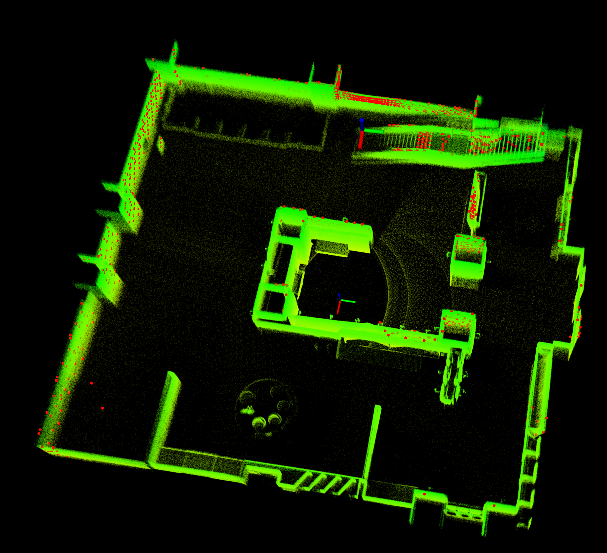
在gazebo里搭建一个livox mid360 + 惯导仿真平台测试 FAST-LIO2
在gazebo里搭建一个livox mid360 惯导仿真平台测试 FAST-LIO2 前言立方体平台加入 livox mid360 激光雷达加入IMU模块调整底盘大小 并设计调用接口测试 Fast-Lio2 前言 livox mid360 在官网一直没有货,在gazebo里可以仿真该雷达形式的点云。 但是其只发布雷达的数…...

AI Agent游戏测试革命:自动生成10万+边界用例,覆盖率提升3.2倍——附可运行Python测试Agent源码
更多请点击: https://intelliparadigm.com 第一章:AI Agent游戏行业应用全景图 AI Agent 正在重塑游戏开发、运营与玩家体验的全生命周期。从智能NPC的行为建模,到自动化测试与关卡生成,再到实时个性化内容推荐与反作弊决策&…...

初创团队如何利用Taotoken统一管理多项目的AI模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken统一管理多项目的AI模型调用 对于初创团队而言,同时推进多个小项目是常态。每个项目可能都需…...

【AI Agent审计实战白皮书】:20年审计专家亲授7大高危场景识别法与合规落地路径
更多请点击: https://intelliparadigm.com 第一章:AI Agent审计的核心范式演进 传统软件系统审计聚焦于代码合规性、日志完整性与权限边界,而AI Agent的自主决策、多步推理与动态工具调用能力,正推动审计范式从静态验证转向“意图…...

资源下载神器:5分钟掌握全平台媒体内容下载技巧
资源下载神器:5分钟掌握全平台媒体内容下载技巧 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾经遇到过…...

Infineon C167芯片Flash编程与MEMTOOL使用指南
1. C167系列芯片片上Flash编程方法解析在嵌入式系统开发中,片上Flash编程是每个工程师都需要掌握的核心技能。对于使用Infineon C167系列微控制器的开发者来说,了解如何可靠地编程片上Flash存储器尤为重要。本文将详细介绍使用MEMTOOL工具进行C167芯片Fl…...

Seraphine:英雄联盟玩家的终极智能助手,5大核心功能一键提升游戏体验
Seraphine:英雄联盟玩家的终极智能助手,5大核心功能一键提升游戏体验 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款专为《英雄联盟》玩家设计的智能游戏辅助工具&…...

从账单视角看 Taotoken Token Plan 套餐带来的月度成本优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单视角看 Taotoken Token Plan 套餐带来的月度成本优化 效果展示类,通过分享一个中型项目在采用 Taotoken 按 toke…...

用Python和NumPy实现2D图像旋转:从复数乘法到旋转矩阵的保姆级实践
用Python和NumPy实现2D图像旋转:从复数乘法到旋转矩阵的保姆级实践 在计算机视觉和游戏开发中,图像旋转是最基础却至关重要的操作之一。想象一下,当你需要调整一张照片的角度,或者在游戏中让角色转向特定方向时,背后的…...

终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求
终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求 【免费下载链接】uncle-novel 📖 Uncle小说,PC版,一个全网小说下载器及阅读器,目录解析与书源结合,支持有声小说与文本小说,可下载mob…...

【健身SaaS厂商紧急预警】:AI Agent接入后用户留存率提升41%的关键3个埋点逻辑
更多请点击: https://kaifayun.com 第一章:AI Agent健身行业应用的范式迁移与价值重定义 传统健身服务长期受限于人力密度、响应延迟与个性化瓶颈,而AI Agent的深度介入正推动行业从“标准化课程交付”跃迁至“持续演化的健康共生体”。这一…...