AI模特换装的前端实现
本文作者为 360 奇舞团前端开发工程师
随着AI的火热发展,涌现了一些AI模特换装的前端工具(比如weshop网站),他们是怎么实现的呢?使用了什么技术呢?下文我们就来探索一下其实现原理。
总体的实现流程如下:我们将下图中的这个模特的图片,使用Segment Anything Model在后端分割图层,然后将分割后的图层mask信息返回给前端处理。在前端中选择需要保留的图层信息(如下图中的模特的衣服图层),然后将选中的图层信息交给后端中的Stable Diffusion处理。后端使用原始图片结合选中的图层蒙版图片结合图生图的功能,可以实现weshop等网站的模特换衣等功能。

本文先简单介绍一下使用SAM智能图层分割,然后主要介绍一下在前端中怎么对分割后的图层进行选择的处理流程。
使用SAM识别图层
首先我们需要对图层进行分割,在SAM出来之前,我们需要使用PS将模特的衣服选取出来,然后倒出衣服的模板,然后再使用其他工具进行替换。但是现在有了SAM后,我们可以对图片中的事物进去只能区分,获取各种物品的图层。
Segment Anything Model(SAM)是一种尖端的图像分割模型,可以进行快速分割,为图像分析任务提供无与伦比的多功能性。SAM 的先进设计使其能够在无需先验知识的情况下适应新的图像分布和任务,这一功能称为零样本传输。SAM 使任何人都可以在不依赖标记数据的情况下为其数据创建分段掩码。
要深入了解 Segment Anything 模型和 SA-1B 数据集,请访问Segment Anything 网站(https://segment-anything.com/)并查看研究论文Segment Anything(https://arxiv.org/abs/2304.02643)。
我们使用SAM进行图像分割,将一个图片中的物体分割成不同的部分。
def mask2rle(img):'''img: numpy array, 1 - mask, 0 - backgroundReturns run length as string formated'''pixels = img.T.flatten()pixels = np.concatenate([[0], pixels, [0]])runs = np.where(pixels[1:] != pixels[:-1])[0] + 1runs[1::2] -= runs[::2]return ' '.join(str(x) for x in runs)def trans_anns(anns):if len(anns) == 0:returnsorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=False)list = []index = 0# 对每个注释进行处理for ann in sorted_anns:bool_array = ann['segmentation']# 将boolean类型的数组转换为int类型int_array = bool_array.astype(int)# 转化为RLE格式rle = mask2rle(int_array)list.append({"index": index, "mask": rle})index += 1return listimage = cv2.imread('<your image path>')import sys
sys.path.append('<your segment-anything link path>')
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor# sam 模型路径
sam_checkpoint = '<your sam model path>'
# 根据下载的模型,设置对应的类型
model_type = "vit_h"# device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
# sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(image)
# 处理sam返回的图层信息
mask_list = trans_anns(masks)mask_obj = {"height": image.shape[0],"width": image.shape[1],"mask_list": mask_list
}import json
print(json.dumps(mask_obj))运行以上python代码之前,需要配置sam的python环境,具体的配置描述请查看sam的官方描述。
我们通过以上代码,将我们提供的图片,通过SAM处理后,返回图层分割数据。在trans_anns方法中,将图层按照area从小到大的顺序排序。遍历各个图层,将boolean类型的数组转换为 0 1 int类型,然后对二维numpy array类型的0 1二进制mask图像转换为RLE格式。
RLE是一种简单的无损数据压缩算法,通常用于表示连续的相同值的序列。RLE编码的字符串通常用于在图像分割等任务中存储和传输二进制掩码信息,以便更有效地表示图像中的目标区域。并且方便数据压缩和传输。我们参照的这种编解码方式。也可以使用coco RLE的编解码方式。
将编码后的各图层信息存储到list中,就可以通过接口传输给前端处理了。
前端选择图层
下面这些是本文的重点,在前端将刚才解析后的mask_list信息展示,并可以通过交互选取需要保留的模版,并生成最终合并选取的mask生成一个需要保留的服装模版。
body中的基本组件为
<div id="layer-box" style=" width: 500px; height: 500px;position: relative"><img style="width: 100%; height: 100%; position: absolute" src="https://p0.ssl.qhimg.com/t01989f0d446bed3e58.jpg" /></div><div id="save" @click="save" style="margin-top: 20px;margin-right: 20px; margin-left: 20px;">保存</div><canvas id="mergedCanvas" style="border:1px solid #000;"></canvas>id为layer-box的div组件作为各个mask的父组件,用于查找和管理各个mask的隐藏和展示。其子组件中的第一个标签是展示原始的模特图片的。
id为save的组件在点击时可以处理保存选中的各个mask为一个新的mask图片,用于处理图片合成。
id为mergedCanvas的canvas是进行图片合成和展示合成后的图片的。
解析SAM处理后的mask_list信息
/*** rle格式图片信息转换为mask信息*/function rle2mask(mask_rle, shape = [500, 500]) {/*mask_rle: run-length as string formatted (start length)shape: [width, height] of array to returnReturns an array, 1 - mask, 0 - background*/const s = mask_rle.split(" ");let starts = s.filter((_, index) => index % 2 === 0).map(Number);const lengths = s.filter((_, index) => index % 2 !== 0).map(Number);starts = starts.map(start => start - 1);const ends = starts.map((start, index) => start + lengths[index]);const img = new Array(shape[0] * shape[1]).fill(0);for (let i = 0; i < starts.length; i++) {for (let j = starts[i]; j < ends[i]; j++) {img[j] = 1;}}// return transposeArray(img, shape);const transposed = new Array(shape[1]).fill(0).map(() => new Array(shape[0]).fill(0));for (let i = 0; i < shape[0]; i++) {for (let j = 0; j < shape[1]; j++) {transposed[j][i] = img[i * shape[1] + j];}}return transposed;}/*** 转换mask图片信息,并设置mask的填充颜色*/function transformMaskImage(item, _width, _height) {let canvas = document.createElement("canvas");let canvasContext = canvas.getContext("2d");canvas.width = _width;canvas.height = _height;let rgbaData = rle2mask(item.mask || '', [_width, _height])for (let y = 0; y < rgbaData.length; y++) {let row = rgbaData[y];for (let x = 0; x < row.length; x++) {let dot = rgbaData[y][x];if (1 === dot && canvasContext) {// 值为1的点填充颜色(canvasContext.fillStyle = "#4169eb"), canvasContext.fillRect(x, y, 1, 1);}}}// canvas当前层的图片(base64格式)// matrix:上边生成的二维数组return { imageData: canvas.toDataURL("image/png"), matrix: rgbaData };}// 使用sam处理后的图层信息(rle编码后的,由于篇幅限制,已省略)const res = { "height": 500, "width": 500, "mask_list": [{ "index": 0, "mask": "109864 3 110361 7 110860 9 111359 10 111859 10 112359 10 112860 9 113360 10 113860 10 114360 10 114860 10 115360 10 115861 8" }, { "index": 1, "mask": "121910 2 122409 4 122908 6 123408 7 123907 8 124407 9 124907 9 125406 11 125905 12 126404 13 126905 12 127405 12 127906 12 128406 12 128907 11 129407 10 129908 8 130408 4" },......] }layers = res.mask_list.map((item) =>transformMaskImage(item, res.width, res.height));res是sam处理后返回的图层信息(由于篇幅限制,已省略,详情请看demo(https://github.com/yuhao1128/AI-model-mask-select-demo/blob/main/index.html)中的数据)。遍历mask_list,使用canvas保存各个mask的信息。由于前面sam处理后的mask_list是经过压缩编码的,所以在rle2mask方法中对rle编码后的数据解码为 0/1二维数组的格式。rle2mask中的解码方式请参考这种解码(https://www.kaggle.com/code/pestipeti/decoding-rle-masks)方式。
然后遍历二维数组,将值为1的点填充颜色,此处是填充的rgba为"#4169eb"的颜色,可以根据需要自己修改为其他的颜色。此处填充的颜色会在下文中鼠标移动到mask上面时,在mask展示的时候呈现此颜色。
最后在layers中存储各个mask的base64格式的图片信息和二维数组信息。
将各个mask添加到图层
const box = document.querySelector("#layer-box");const baseStyle = "width:100%;height:100%;position: absolute;";//将各个mask添加为layer-box的子组件,并隐藏mask的展示layers.forEach((ele) => {const image = document.createElement("img");image.src = ele.imageData;image.style = `${baseStyle}opacity:0`;image.className = "layer";box.append(image);});将各个mask添加的图片添加为layer-box组件的子组件,并且设置opacity为0,先隐藏这些mask的展示,在下文会监听鼠标的位置,通过设置mask的opacity属性来展示mask。
监听鼠标的位置和点击
// 鼠标移入mask组件的区域时,展示maskbox.addEventListener("mousemove", (e) => {const { clientX, clientY } = e;const X = box.getBoundingClientRect().left + document.body.scrollLeft;const Y = box.getBoundingClientRect().top + document.body.scrollTop;const x = parseInt(res.width * (clientX - X) / box.getBoundingClientRect().width)const y = parseInt(res.height * (clientY - Y) / box.getBoundingClientRect().height)const allLayers = box.querySelectorAll(".layer");const index = layers.findIndex((item) => item.matrix?.[y]?.[x]);allLayers.forEach((ele, i) => {if (i === index) {ele.style = `${baseStyle}opacity:0.7`;} else {// 已经选中的不需要隐藏if (selectedIndexList.indexOf(i) === -1) {ele.style = `${baseStyle}opacity:0`;}}});});// 鼠标移出mask组件的区域时,隐藏maskbox.addEventListener("mouseout", (e) => {console.log('mouseout selectedIndexList', selectedIndexList);const allLayers = box.querySelectorAll(".layer");allLayers.forEach((ele, i) => {// 只有选中的才会展示if (selectedIndexList.indexOf(i) > -1) {ele.style = `${baseStyle}opacity:0.7`;} else {ele.style = `${baseStyle}opacity:0`;}});});// 用户点击时,保存用户选中的mask的indexbox.addEventListener("mousedown", (e) => {const { clientX, clientY } = e;const X = box.getBoundingClientRect().left + document.body.scrollLeft;const Y = box.getBoundingClientRect().top + document.body.scrollTop;const x = parseInt(res.width * (clientX - X) / box.getBoundingClientRect().width)const y = parseInt(res.height * (clientY - Y) / box.getBoundingClientRect().height)const index = layers.findIndex((item) => item.matrix?.[y]?.[x]);if (selectedIndexList.indexOf(index) === -1) {//保存点击选中的元素indexselectedIndexList.push(index)}});box就是上文的layer-box,是各个mask的父组件。layer-box监听鼠标的move事件和click事件,当move到对应的mask上时,将mask展示,移除mask时,隐藏mask。mask在list中是从小到大的顺序,所以遍历匹配mask时,会优先匹配面积小的组件,方便灵活选择。当点击mask的位置时,保存mask在list中的index到selectedIndexList中,方便后续导出保存选择,并高亮展示选中的mask。
选中的mask合成图片
// 存储各个图层图片信息let layers = []// 选择layer的indexconst selectedIndexList = []// 点击保存document.getElementById('save').onclick = function () {const images = [];selectedIndexList.forEach(index => {images.push(layers[index].imageData)})drawing(images)}/*** 图片合成*/function drawing(images) {const canvas = document.getElementById("mergedCanvas");canvas.width = 500; // 设置canvas宽canvas.height = 500; // 设置canvas高const ctx = canvas.getContext("2d");let loadedImages = 0;images.forEach(function (src) {const img = new Image();img.src = src;img.onload = function () {loadedImages++;// 绘制每张图片到 canvas 上ctx.drawImage(img, 0, 0);// 如果所有图片都加载完成,保存合并后的图片if (loadedImages === images.length) {// 获取图片的像素数据const imageData = ctx.getImageData(0, 0, img.width, img.height);const data = imageData.data;// 转换为黑白效果for (let i = 0; i < data.length; i += 4) {// 将 R、G、B 设置为0data[i] = 0;data[i + 1] = 0;data[i + 2] = 0;}// 将修改后的数据放回 canvasctx.putImageData(imageData, 0, 0);// 导出为 base64 图片const mergedImageBase64 = canvas.toDataURL("image/png");// 如果需要,你可以将mergedImageBase64图片用于其他操作,比如发送到服务器}};});}当选择完成后,可以点击“保存”按钮,将选择的mask使用canvas生成一个合并后的图片。此处已将合成后的图片转换为黑白蒙版照片,之后可以使用这个合并后的图片进行后续的处理。
根据选中的图层,点击保存后,生成的模板如下图所示。

预览效果(https://yuhao1128.github.io/AI-model-mask-select-demo/)、代码详情(https://github.com/yuhao1128/AI-model-mask-select-demo/blob/main/index.html)
使用Stable Diffusion进行后续的处理
由于篇幅的限制,并且这部分网络上以及有很多的介绍资料,就不再本文中进行介绍了,可以参考这篇文章(https://www.uisdc.com/stable-diffusion-24)的介绍尝试体验一下在本地中使用Stable Diffusion的图生图的「重绘蒙版」来进行模特的重新绘制。
也可以在后端部署Stable Diffusion服务中处理模特换装。将前面的模特原图以及生成的蒙版图片,以及其他的SD的图生图功能的参数传给后端的SD服务处理。
除了模特换装的功能,上面的流程还可以应用到物品换背景的功能中。其他的一些智能抠图,智能替换的功能都可以扩展上面的处理流程来实现。
参考链接:
https://github.com/facebookresearch/segment-anything
https://juejin.cn/post/7248903246970503223#heading-2
https://www.uisdc.com/stable-diffusion-24
- END -
关于奇舞团
奇舞团是 360 集团最大的大前端团队,代表集团参与 W3C 和 ECMA 会员(TC39)工作。奇舞团非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。

相关文章:
AI模特换装的前端实现
本文作者为 360 奇舞团前端开发工程师 随着AI的火热发展,涌现了一些AI模特换装的前端工具(比如weshop网站),他们是怎么实现的呢?使用了什么技术呢?下文我们就来探索一下其实现原理。 总体的实现流程如下&am…...
git-5
1.GitHub为什么会火? 2.GitHub都有哪些核心功能? 3.怎么快速淘到感兴趣的开源项目 github上面开源项目非常多,为了我们高效率的找到我们想要的资源 根据时间 不进行登录,是没有办法享受到高级搜索中的代码功能的,登录…...
qt 5.15.2压缩和解压缩功能
qt 5.15.2压缩和解压缩功能 主要是添加qt项目文件.pro内容: 这里要先下载quazip的c项目先编译后引入到本项目中/zip目录下 INCLUDEPATH ./zip CONFIG(debug, debug|release) {win32:win32-g: PRE_TARGETDEPS $$PWD/zip/libquazipd.awin32:win32-g: LIBS -L$$PWD…...
 expects parameter 1 to be string, array given)
thinkphp6出现 htmlentities() expects parameter 1 to be string, array given
为避免出现 XSS 安全问题, thinkphp6默认变量输出都会使用 htmlentities 方法进行转义 输出。 如果不想被转义输出,模板渲染时,需要在变量后面加上 raw方法,如:{$data|raw} 1、出现问题前的代码 PHP代码$this->assi…...

【android开发-03】android中Intent的用法介绍
1,Intent的作用 在Android开发中,Intent的使用非常广泛,包括启动Activity、启动Service、发送广播等。是各组件间交互的一种重要方式,他不仅可以指明当前组件想要执行的动作,还可以在不同组件间传递数据。 Intent可以…...

Java中时间工具详解:java.time包的应用
引言 时间在软件开发中是一个至关重要的概念,而Java自从引入java.time包后,提供了更加强大和灵活的时间处理工具。本文将深入介绍java.time包中的一些常用时间工具,帮助你更好地处理日期和时间的操作。 1. LocalDate - 处理日期 LocalDate…...
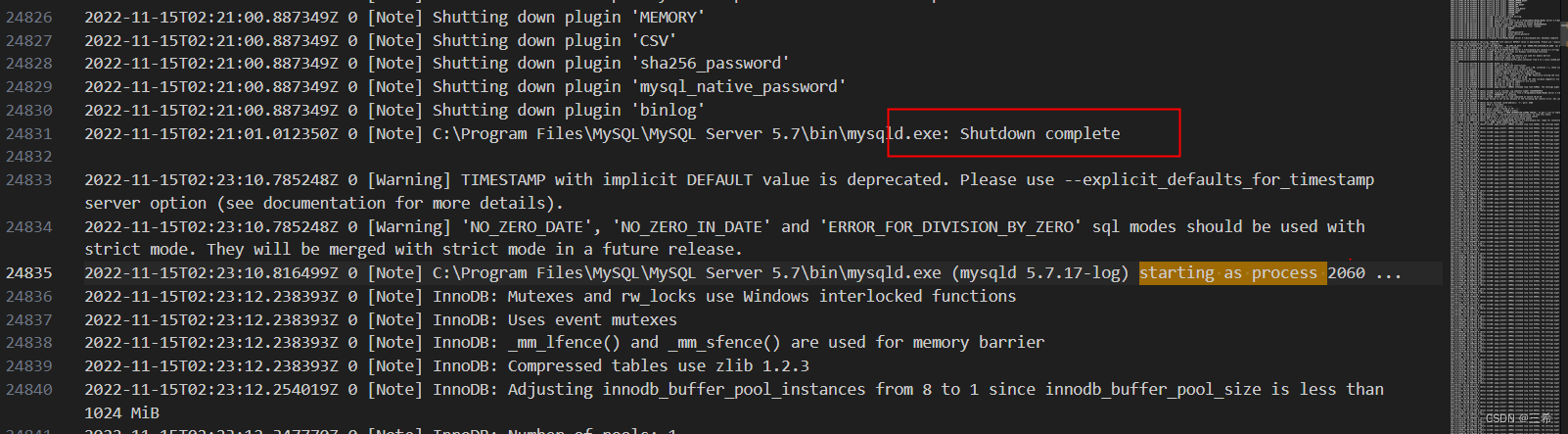
mysql 日志分析
程序启动标志 可以直接全局搜索,查看启动了几次 可以看到总共11次,当前是第2次 如何判断mysql是正常关闭,手动启动的 下图中启动之前出现 Shutdown complete打印说明启动之前是正常关闭的...
网络运维与网络安全 学习笔记2023.11.30
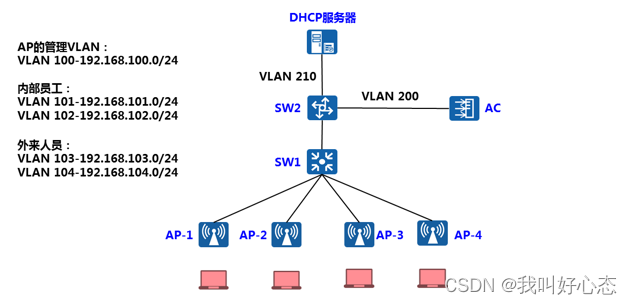
网络运维与网络安全 学习笔记 第三十一天 今日目标 实现AP自动注册、配置WLAN业务参数、无线终端通过wifi互访 实现AP自动注册 项目背景 企业内网的大量AP已经通过DHCP的方式获得IP地址 为了实现后期大量AP的统一管理,希望通过AC实现集中控制 在AC设备上&#…...

Perplexity 推出全新大型在线语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

python中的函数定义
默认参数 注: 在Python中,print(x, and y both correct)是一条打印语句(print statement),用于将一条消息输出到控制台或终端。它的作用是将变量x的值和字符串and y both correct同时输出到屏幕上。 在这个语句中&…...
信贷销售经理简历模板
这份简历内容,以信贷销售经理招聘需求为背景,我们制作了1份全面、专业且具有参考价值的简历案例,大家可以灵活借鉴。 信贷销售经理简历模板在线编辑下载:百度幻主简历 求职意向 求职类型:全职 意向岗位ÿ…...
js事件流与事件委托/事件代理
1 事件流 事件流分为两步,一是捕获,二是冒泡 1.1 捕获概念 捕获就是从最高层一层一层往下找到最内部的节点 1.2 冒泡概念 捕获到最小节点后,一层一层往上返回,像是气泡从最底部往上冒一样,由于水深不同压强不同&…...

代码随想录算法训练营第三十八天| 509 斐波那契数 70 爬楼梯 746 使用最小花费爬楼梯
509 斐波那契数 class Solution {public int fib(int n) {int f[] new int[n 5];f[0] 0;f[1] 1;for(int i 2;i < n;i){f[i] f[i - 1] f[i - 2];}return f[n];} } 时间复杂度O(n) 空间复杂度O(n) 70 爬楼梯 class Solution {public int climbStairs(i…...

windows 此系统禁止运行脚本报错处理
windows 此系统禁止运行脚本报错处理 start 在命令行中运行执行的脚本,运行原理可以参考文章 《》本文主要介绍,如何处理window默认的对脚本运行的限制。 详细说明 出现报错如下: 主要原因就是系统默认禁止了在 powershell 环境下某些脚…...
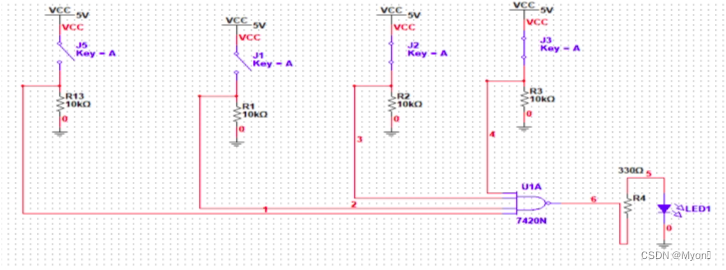
西南科技大学数字电子技术实验一(数字信号基本参数与逻辑门电路功能测试及FPGA 实现)FPGA部分
一、 实验目的 1、掌握基于 Verilog 语言的 diamond 工具设计全流程。 2、熟悉、应用 Verilog HDL 描述数字电路。 3、掌握 Verilog HDL 的组合和时序逻辑电路的设计方法。 4、掌握“小脚丫”开发板的使用方法。 二、 实验原理 与门逻辑表达式:Y=AB 原理仿真图: 2 输入…...

List系列集合
List系列集合特点:有序,可重复,有索引 ArrayList:有序,可重复,有索引 LinkedList:有序,可重复,有索引 (底层实现不同!适合的场景不同!…...
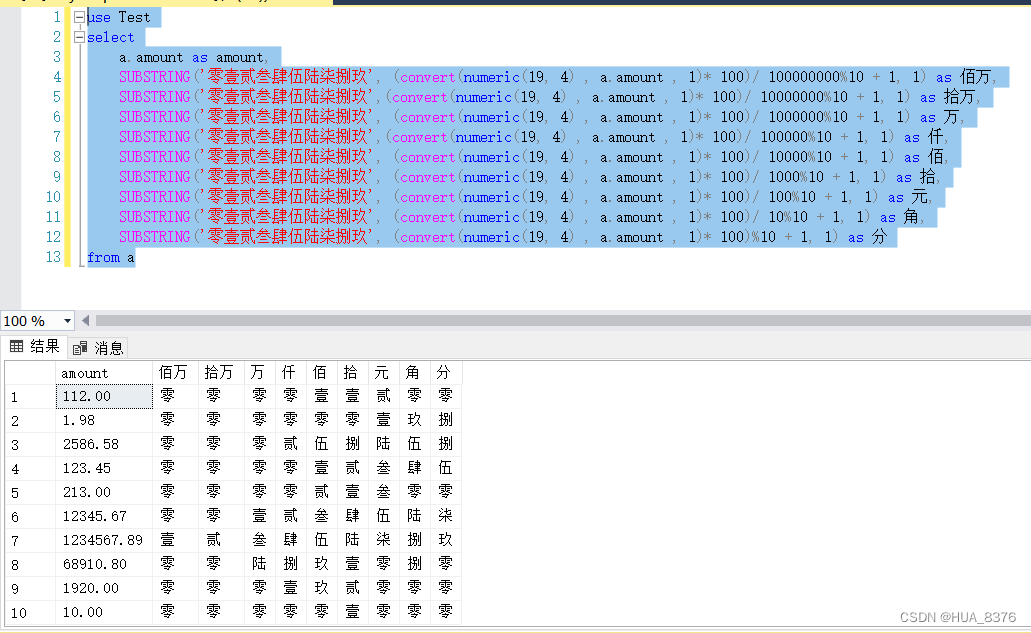
SQL 金额数值转换成中文大写
需求:将金额转换成中文大写格式填入单据合计行: _佰_拾_万_仟_佰_拾_元_角_分 1234567.89 壹佰贰拾叁万肆仟伍佰陆拾柒元捌角玖分 1.函数转换 drop function n2C;CREATE FUNCTION n2C (num numeric(14,2)) RETURNS VARCHAR(20) AS BEGIN …...

在Linux上安装KVM虚拟机
一、搭建KVM环境 KVM(Kernel-based Virtual Machine)是一个基于内核的系统虚拟化模块,从Linux内核版本2.6.20开始,各大Linux发行版就已经将其集成于发行版中。KVM与Xen等虚拟化相比,需要硬件支持的完全虚拟化。KVM由内…...

软件设计之原型模式
原型模式是从一个对象再创建另一个可定制的对象,而且不需要知道任何创建的细节。拷贝分浅拷贝和深拷贝。浅拷贝无法拷贝引用对象。在面试的时候,我们会投多家公司,根据岗位的不同我们会适当调整。使用原型模式可以快速达到需求,下…...
Android之高级UI
系统ViewGroup原理解析 常见的布局容器: FrameLayout, LinearLayout,RelativeLayoout,GridLayout 后起之秀:ConstraintLayout,CoordinateLayout Linearlayout Overrideprotected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {if (mOrientation …...

从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得
从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得 引言:当MCU突然"罢工"时 那是一个周五的深夜,产品量产前的最后一周。测试工程师突然报告设备在特定操作序列下会无规律死机,串口日志最后一行…...

CMSIS-DSP库更新指南与性能优化实践
1. CMSIS-DSP库更新需求解析在嵌入式开发领域,CMSIS-DSP库是ARM Cortex-M处理器上信号处理的核心支撑。作为专为微控制器优化的数字信号处理库,它包含了滤波器、矩阵运算、FFT等常用算法,其性能直接影响实时信号处理系统的表现。随着编译器版…...

HarmonyOS ArkUI实战:从零构建购物社交应用UI界面
1. 项目概述与核心价值如果你正在学习HarmonyOS应用开发,或者已经从其他移动端框架(如Android、Flutter)转过来,那么构建一个美观、交互流畅的UI界面,往往是上手实践的第一步,也是最直观检验学习成果的一步…...

昇腾CANN cann-samples:从示例代码到生产力工具的全路径
CANN 55 个仓库里,cann-samples 是最容易被低估的一个。它不定义新算子、不优化性能、不做架构设计——只提供可运行的代码示例。但正是因为「只提供示例」,cann-samples 是新手最快上手、老手最常查阅的仓库。每个示例都是独立可编译的项目:…...

【Feed 高并发架构实战】:雪花 ID + 三级缓存 + 计数旁路设计详解
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

图片批量识别提取信息
图片批量识别提取信息工具,是用aardio写的,调用微信OCR识别图片中的信息,识别正确率非常高,用于提取各类证件和文档,对于在基层村、社区工作的人员是很有帮助的。 喜欢的朋友可以下载试用。分享了「图批量识别提取信息…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan保姆级搭建分享
2026年京东云OpenClaw/Hermes Agent配置Token Plan保姆级搭建分享。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具…...

2026破圈!5款AI论文工具实测,摆脱无效加班,初稿质量效率翻倍
对于学生、科研工作者而言,论文写作往往面临诸多挑战:文献资料筛选耗时冗长、格式排版反复调整、查重率难以精准控制、研究逻辑梳理不够清晰,这些痛点严重制约了写作效率与学术成果的规范性。随着2026年AI技术的持续突破,各类AI论…...

Windows右键菜单终极优化指南:如何用ContextMenuManager让右键菜单秒开如飞
Windows右键菜单终极优化指南:如何用ContextMenuManager让右键菜单秒开如飞 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾经对着电脑屏幕等…...

FPGA 时序优化理论手册
定位:为时序优化手册中每一条规则、每一段代码背后的"为什么"提供物理直觉与数学原理 阅读方式:先读本手册建立理解,再回看时序优化手册对应的操作和代码 目录 第 1 部分 时序分析的物理基础第 1 章 数字电路中的时间:从晶体管到时序公式第 2 章 建立时间与保…...