Python批处理PDF文件,PDF附件轻松批量提取
PDF附件是指在PDF文档中嵌入的其他文件,如图像、表格、音频、视频或其他文档。这些附件可以与PDF文档一起存储、传输和共享,为文档提供了更丰富的内容和更多的功能。通过添加附件,我们可以将相关文件和信息捆绑在一起,使其更易于管理和共享。此外,PDF附件还可以用于在文档中引用外部资源,提供更全面的参考资料和支持材料。然而,处理大量的PDF附件可能会很繁琐且费时费力。通过利用Python程序,我们可以轻松地批量处理这些附件,极大地提高工作效率。本文将介绍如何通过Python轻松批量提取并保存PDF附件、插入附件到PDF文档中以及删除PDF文件中的附件。
文章目录
- 使用Python批量提取PDF附件
- 使用Python轻松插入附件到PDF
- 使用Python批量删除PDF附件
本文所介绍的方法需要用到Spire.PDF for Python,可从官网下载或通过PyPI安装:
pip install Spire.PDF
使用Python批量提取PDF附件
提取PDF文档中的附件主要用到的是PdfDocument.Attachments属性和 PdfAttachment.Data.Save() 方法。PdfDocument.Attachments属性可以获取一个PDF文档中的所有附件并返回一个附件集合,而PdfAttachment.Data.Save()方法则可以将指定附件保存到指定文件夹。详细操作步骤如下:
- 指定输入文件夹和输出文件夹的路径。
- 获取输入文件夹中以".pdf"结尾的PDF文件列表。
pdfFiles = [f for f in os.listdir(inputFolder) if f.endswith(".pdf")]
- 遍历每个PDF文件。
- 创建PdfDocument类的对象,并使用PdfDocument.LoadFromFile()再入PDF文件。
document = PdfDocument()
document.LoadFromFile(filePath)
- 获取PDF文件的附件列表。
attachments = document.Attachments
- 判断附件列表是否为空,如果有附件,则构建储存附件的文件夹。
- 遍历附件列表,获取附件对象,并将附件保存到指定路径。
attachment = attachments.get_Item(i)
attachmentPath = os.path.join(outputFolderPath, attachment.FileName)
attachment.Data.Save(attachmentPath)
- 关闭PDF文件。
完整代码示例:
import os
from spire.pdf import *
from spire.pdf.common import *# 指定输入文件夹和输出文件夹的路径
inputFolder = "文档/PDF"
outputFolder = "文档/附件"# 获取输入文件夹中以".pdf"结尾的PDF文件列表
pdfFiles = [f for f in os.listdir(inputFolder) if f.endswith(".pdf")]# 遍历每个PDF文件
for fileName in pdfFiles:# 构建PDF文件的完整路径filePath = os.path.join(inputFolder, fileName)# 创建PdfDocument对象并加载PDF文件document = PdfDocument()document.LoadFromFile(filePath)# 获取PDF文件的附件列表attachments = document.Attachments# 如果附件存在if attachments:# 获取PDF文件名(不包含扩展名)fileNameWithoutExt = os.path.splitext(fileName)[0]# 构建输出文件夹路径outputFolderPath = os.path.join(outputFolder, fileNameWithoutExt)# 创建输出文件夹os.makedirs(outputFolderPath, exist_ok=True)# 遍历附件列表for i in range(attachments.Count):# 获取附件对象attachment = attachments.get_Item(i)# 构建附件保存路径attachmentPath = os.path.join(outputFolderPath, attachment.FileName)# 保存附件到指定路径attachment.Data.Save(attachmentPath)# 关闭PDF文档document.Close()
用于提取附件的PDF文件:

提取结果:

使用Python轻松插入附件到PDF
通过创建PdfAttachment类的实例即可创建PDF附件,并对附件相关信息进行设置,如描述和修改日期。在创建好附件后,使用PdfDocument.Attachments.Add()方法即可将附件添加到PDF文件中。附件还可以与PDF注释结合,实现从页面上跳转到指定附件。一下步骤是添加附件的简单示例:
- 创建PdfDocument类的对象并再入PDF文档。
document = PdfDocument()
document.LoadFromFile(pdfPath)
- 创建PdfAttachment类的对象,并设置附件描述和修改日期。
attachment = PdfAttachment(attachmentPath)
attachment.Description = "参会人员名单"
attachment.ModificationDate = DateTime.get_Now()
- 将附件添加到PDF文件中。
document.Attachments.Add(attachment)
- 保存并关闭PDF文件。
document.SaveToFile("output/添加附件.pdf")
document.Close()
完整代码示例:
from spire.pdf import *
from spire.pdf.common import *# 定义PDF文件路径和附件路径
pdfPath = "文档/示例5.pdf"
attachmentPath = "示例/名单.txt"# 创建PdfDocument对象并加载PDF文件
document = PdfDocument()
document.LoadFromFile(pdfPath)# 创建PdfAttachment对象
attachment = PdfAttachment(attachmentPath)# 设置附件的描述信息和修改日期
attachment.Description = "参会人员名单"
attachment.ModificationDate = DateTime.get_Now()# 将附件添加到PDF文档中
document.Attachments.Add(attachment)# 保存PDF文档到指定路径
document.SaveToFile("output/添加附件.pdf")# 关闭PDF文档
document.Close()
添加效果:

使用Python批量删除PDF附件
删除PDF文件中的附件则比较简单,直接使用PdfDocument.Attachments属性获取一个PDF文件中的附件,然后再删除指定的附件或所有附件即可。一下是操作步骤:
- 创建PdfDocument类的对象并再入PDF文档。
document = PdfDocument()
document.LoadFromFile(pdfPath)
- 获取PDF文件中的附件集合。
document.Attachments
- 删除指定附件。
attachments.RemoveAt(0)
- 或删除所有附件。
attachments.Clear()
- 保存并关闭PDF文件。
document.SaveToFile("output/删除附件.pdf")
document.Close()
完整代码示例:
from spire.pdf import *
from spire.pdf.common import *# 定义PDF文件路径
pdfPath = "文档/示例5.pdf"# 创建PdfDocument对象并加载PDF文件
document = PdfDocument()
document.LoadFromFile(pdfPath)# 获取PDF文件的附件集合
attachments = document.Attachments# 删除指定附件
attachments.RemoveAt(0)# 删除所有附件
attachments.Clear()# 保存并关闭PDF文件
document.SaveToFile("output/删除附件.pdf")
document.Close()
以上是关于如何利用Python在PDF文件中添加、提取及删除附件的方法介绍。Spire.PDF for Python还支持许多其他功能,请前往Spire.PDF for Python教程了解更多。
相关文章:
Python批处理PDF文件,PDF附件轻松批量提取
PDF附件是指在PDF文档中嵌入的其他文件,如图像、表格、音频、视频或其他文档。这些附件可以与PDF文档一起存储、传输和共享,为文档提供了更丰富的内容和更多的功能。通过添加附件,我们可以将相关文件和信息捆绑在一起,使其更易于管…...

Python可迭代对象排序:深入排序算法与定制排序
更多Python学习内容:ipengtao.com 排序在计算机科学中是一项基础而关键的操作,而Python提供了强大的排序工具来满足不同场景下的排序需求。本文将深入探讨Python中对可迭代对象进行排序的方法,涵盖基础排序算法、sorted函数的应用、以及定制排…...

基于matlab的图像去噪算法设计与实现
摘 要 随着我们生活水平的提高,科技产品飞速更新换代,在信息传输中,图像传输所占的比重越来越大。但自然噪声会在图像传输时干扰其传输过程,甚至会使图片不能表达其原来的意义。去噪处理就是为了去除图像中的噪声,从而…...
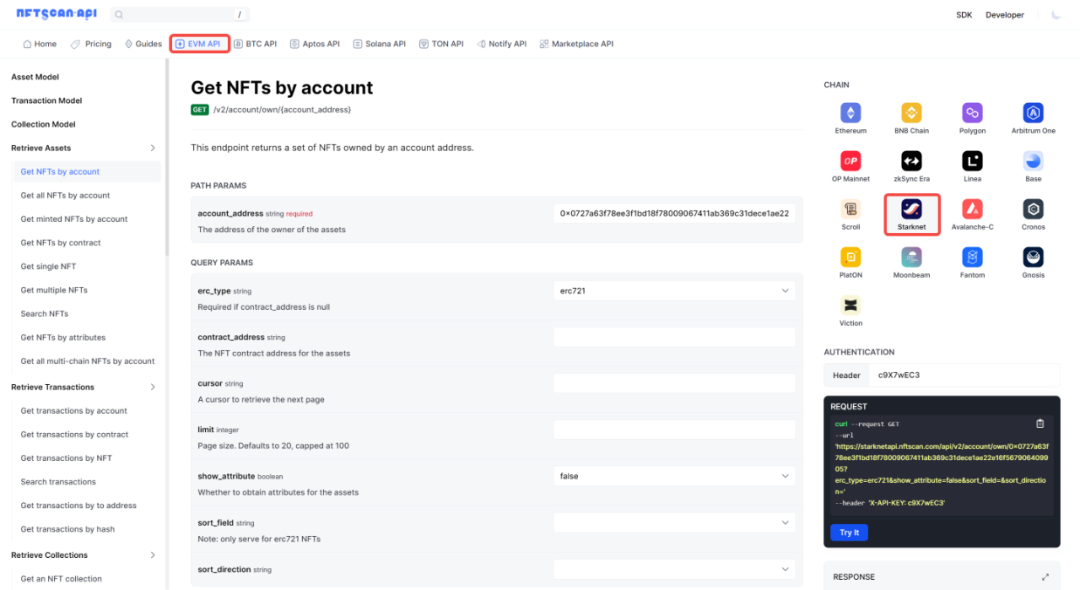
NFTScan 正式上线 Starknet NFTScan 浏览器和 NFT API 数据服务
2023 年 11 月 30 号,NFTScan 团队正式对外发布了 Starknet NFTScan 浏览器,将为 Starknet 生态的 NFT 开发者和用户提供简洁高效的 NFT 数据搜索查询服务。NFTScan 作为全球领先的 NFT 数据基础设施服务商,Starknet 是继 Bitcoin、Ethereum、…...

2023年亚太杯APMCM数学建模大赛A题水果采摘机器人的图像识别
2023年亚太杯APMCM数学建模大赛 A题 水果采摘机器人的图像识别 原题再现 中国是世界上最大的苹果生产国,年产量约3500万吨。同时,中国也是世界上最大的苹果出口国,世界上每两个苹果中就有一个是中国出口的,世界上超过六分之一的…...

mysql which is not in SELECT list; this is incompatible with DISTINCT解决方案
mysql报错Expression #1 of ORDER BY clause is not in SELECT list, references column ‘xxx’ which is not in SELECT list; this is incompatible with DISTINCT解决方案: 这是在 mysql5.7 版本,DISTINCT 与 order by 在一起用时则会报3065错误。因…...

linux /proc 文件系统
/proc系统是一个伪文件系统,它只存在内存当中,而不占用外存空间,以文件系统的方式为内核与进程提供通信的接口。 /proc目录下有很多以数字命名的目录,每个数字代表进程号PID它们是进程目录。系统中当前运行的每一个进程在/proc下都…...
java开发之个微群聊自动添加好友
请求URL: http://域名/addRoomMemberFriend 请求方式: POST 请求头Headers: Content-Type:application/jsonAuthorization:login接口返回 参数: 参数名必选类型说明wId是String登录实例标识chatRoom…...

Git .gitignore 忽略文件不生效解决方法
.gitignore 匹配规则 *.sample # 忽略所有 .sample 结尾的文件 !lib.sample # 但 lib.sample 除外 /TODO # 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO build/ # 忽略 build/ 目录下的所有文件 doc/*.txt # 会…...

【Java】16. HashMap
16. HashMap public static String find3(String key) {Map<String, String> map Map.of("bright", "小明","white", "小白","black", "小黑");return map.get(key); }Map.of 用来创建不可变的 Map&#…...

KMP基础架构
前言 Kotlin可以用来开发全栈, 我们所熟悉的各个端几乎都支持(除了鸿蒙) 而我们要开发好KMP项目需要一个好的基础架构,这样不仅代码更清晰,而且能共享更多的代码 正文 我们可以先将KMP分为前端和服务端 它们两端也能共享一些代码,比如接口声明,bean类,基础工具类等 前端和…...

递归实现选择排序.
思路: 1.定位数组中的最大元素或最小元素 2.将其与第一个元素交换位置 3.接着将剩余未排序的元素中的最大值或最小值与第二个元素交换位置 4.以此类推,直到排序完成 示例: [ 8, 5, 1, 9, 3 ] //原始数组 [ 1, 5, 8, 9, 3 ] //3与8交换 [ 1, 3, 8, 9, 5 ] //3与5交换 [ 1,…...

Node.js【文件系统模块、路径模块 、连接 MySQL、nodemon、操作 MySQL】(三)-全面详解(学习总结---从入门到深化)
目录 Node.js 文件系统模块(二) Node.js 文件系统模块(三) Node.js 文件系统模块(四) Node.js 路径模块 Node.js 连接 MySQL Node.js nodemon Node.js 操作 MySQL Node.js 应用 Node.js 文件系统模块…...

公司的销售经理面临哪些压力和挑战?
公司的销售经理面临哪些压力和挑战? 作为公司的销售经理,通常会面临以下挑战和压力: 1. 销售目标难以达成。销售经理需要承担销售目标,这通常是一项艰巨的任务。他们需要制定销售策略,与客户建立联系,并确保…...

【Linux系统编程】如何创建进程(什么是fork函数?进程创建的原理是什么?)
目录 一、前言 二、 进程创建的初次了解(创建进程的原理) 三、什么是fork函数? 💦初识fork函数 💦fork函数的四个为什么? ⭐为什么fork()要给子进程返回0,给父进程返回子进程pidÿ…...
【opencv】计算机视觉基础知识
目录 前言 1、什么是计算机视觉 2、图片处理基础操作 2.1 图片处理:读入图像 2.2 图片处理:显示图像 2.3 图片处理:图像保存 3、图像处理入门基础 3.1 图像成像原理介绍 3.2 图像分类 3.2.1 二值图像 3.2.2灰度图像 3.2.3彩色图像…...
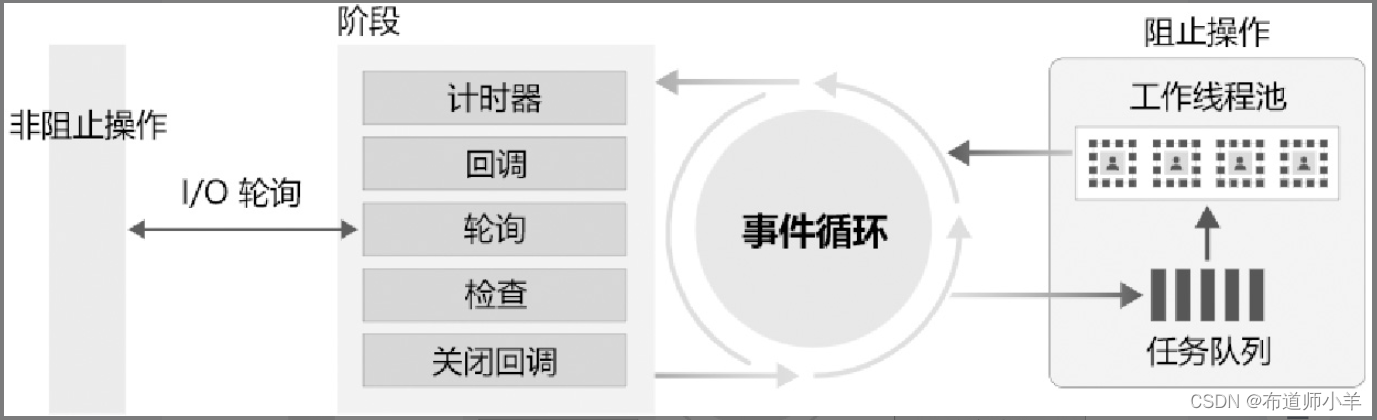
Node——Node.js简介
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,它能够让JavaScript脚本运行在服务端,这使得JavaScript成为与PHP、Python等服务端语言平起平坐的脚本语言。 1、认识Node.js Node.js是当今网站开发中非常流行的一种技术,它以简单易…...

小型洗衣机什么牌子好又便宜?性价比迷你洗衣机推荐
由于日常所穿的内衣裤由于各种原因,时间一久就很容易产生细菌,而且和其他大件的衣物一起混洗,很容易造成细菌的交叉感染,积攒起来洗就更不卫生了,留在内衣裤上的分泌物会继续滋生细菌,比如闷热的环境下念珠…...

INFINI Easysearch 与华为鲲鹏完成产品兼容互认证
何为华为鲲鹏认证 华为鲲鹏认证是华为云围绕鲲鹏云服务(含公有云、私有云、混合云、桌面云)推出的一项合作伙伴计划,旨在为构建持续发展、合作共赢的鲲鹏生态圈,通过整合华为的技术、品牌资源,与合作伙伴共享商机和利…...

将linux服务器 设置成 proxy.SOCKS5 服务器
gpt: 如果你想在 Linux 服务器上设置一个 SOCKS5 代理服务器,你可以使用一些现有的工具,比如 Shadowsocks、Dante、或者其他支持 SOCKS5 协议的软件。下面是一个使用 Dante 的简单示例: 1. **安装 Dante:** bash sudo apt-g…...

C++继承与组合设计
C继承与组合设计继承和组合是面向对象设计中两种重要的代码复用机制。继承表示"是一个"关系,而组合表示"有一个"关系。理解何时使用继承、何时使用组合是设计良好系统的关键。继承允许派生类继承基类的属性和方法,实现代码复用和多态…...

【YOLO全系列架构演进史】2 YOLOv8:解耦头、Anchor-free与多任务统一框架
YOLOv8:解耦头、Anchor-free与多任务统一框架 1.1 总体定位与认知地图 1.1.1.1 我们为什么需要重新理解YOLOv8 YOLOv8在2023年发布时,很多人以为它只是YOLOv5的增量升级。但如果我们把神经网络看作一条工厂流水线,YOLOv8实际上把整条流水线的三个核心工位都换了:原料处理…...

【ChatGPT】锂电卷绕机深度拆解、信息图、爆炸图、C++代码框架
深度拆解信息图...

iOS自动化测试真机连接失败的五大根因与工程化解决方案
1. 为什么iOS自动化测试总卡在“连不上真机”这一步? Appium做iOS自动化,标题里写“全网最详细”,不是吹牛,是踩过太多坑之后的实话。我带过三支测试团队,从2018年用Xcode 9配Appium 1.8开始,到今天Xcode 1…...

水葫芦生长周期生长阶段早晚期检测数据集VOC+YOLO格式1029张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1029标注数量(xml文件个数):1029标注数量(txt文件个数):1029标注类别…...

曼德勃罗集的 Three.js 实现
效果预览 经典的曼德勃罗集(Mandelbrot Set)分形渲染,配合动态缩放动画探索分形边界的无限细节。使用线性插值平滑着色,呈现出彩虹般的色彩过渡。 👉 点击查看《曼德勃罗集的》完整源码与效果演示 Shader 实现原理…...

2026年京东云OpenClaw/Hermes Agent配置Token Plan详细搭建教程
2026年京东云OpenClaw/Hermes Agent配置Token Plan详细搭建教程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

智能网盘直链解析工具:免会员下载加速的全新解决方案
智能网盘直链解析工具:免会员下载加速的全新解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

KMS智能激活工具:三步永久激活Windows和Office系统完整指南
KMS智能激活工具:三步永久激活Windows和Office系统完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变…...

3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南
3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否经历过这样的场景?急着下载一份重要的…...