FLASK博客系列6——数据库之谜
我们上一篇已经实现了简易博客界面,你还记得我们的博客数据是自己手动写的吗?但实际应用中,我们是不可能这样做的。大部分程序都需要保存数据,所以不可避免要使用数据库。我们这里为了简单方便快捷,使用了超级经典的SQLite,它是一种基于文件,不需要启动后台服务的数据库。当然了,仅限于操作简单,访问量比较低的应用中使用,这也正是我们选用它的原因。
SQLAlchemy——python数据库工具
SQLAlchemy是python下的一个数据库工具,它提供了SQL工具包及对象关系映射(ORM)工具。你可以通过定义python类来表示数据库中的一张表,然后通过这个类来进行各种操作,从而代替书写SQL语句,而这个类我们称之为模型类。
但是,我们今天用另一个包——Flask-SQLAlchemy。它是一个简化了SQLAlchemy 操作的flask扩展,是SQLAlchemy的具体实现,封装了对数据库的基本操作。简而言之,可以更快更方便地帮助我们去构建博客,而不用细致去深究其原理。等以后有时间了我们另开一篇,讲讲SQLAlchemy的操作。
先把包装一下。
pip3 install flask-sqlalchemy接着初始化一下,将其跟flask关联起来。
import os
from flask_sqlalchemy import SQLAlchemy # 导入扩展类basedir = os.path.abspath(os.path.dirname(__file__)) # 绝对路径
app = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'blog.db')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = Falsedb = SQLAlchemy(app) # 初始化扩展,传入程序实例 app
接着我们在pycharm打开控制台,创建数据库:
>>> from app import db
>>> db.create_all()然后在当前目录下我们可以看到生成了blog.db。是不是很简单呢?但这种方式会有问题,因为采用db.create_all在后期修改字段的时候,不会自动的映射到数据库中,必须删除表,然后重新运行db.create_all才会重新映射,这样不符合实际的工作要求。因此flask-migrate就是为了解决这个问题,它可以在每次修改模型后,可以将修改的东西映射到数据库中。
Flask-Migrate
使用flask_migrate必须借助flask_scripts,那么flask-script的作用是什么呢?flask-script的作用是可以通过命令行的形式来操作Flask。例如通过命令跑一个开发版本的服务器、设置数据库,定时任务等。
老样子,动手装包:
pip install Flask-Script如果用过django的同学都知道,操作很多命令都是通过python manager.py + 命令 来实现的。那我们也来模仿一番。
我们来定义下命令:
- python manage.py db init:初始化一个迁移脚本的环境,只需要执行一次,实际就是db.create_all()
- python manage.py db migrate:将模型生成迁移文件,只要模型更改了,就执行一遍这个命令。
- python manage.py db upgrade:将迁移文件真正映射到数据库中,每次运行migrate命令后,记得要运行这个命令。
我们接着新建一个models.py,用来定义模型类。定义一下User类和Article类。
from app import dbclass User(db.Model): # 表名将会是 user(自动生成,小写处理)id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 主键name = db.Column(db.String(20)) # 用户名class Article(db.Model): # 表名将会是 user(自动生成,小写处理)# id 主键 自增id = db.Column(db.Integer, primary_key=True, autoincrement=True)# 文章标题 非空title = db.Column(db.String(100), nullable=False)# 文章正文 非空content = db.Column(db.Text, nullable=False)# 关联表,这里要与相关联的表的类型一致, user.id 表示关联到user表下的id字段author_id = db.Column(db.Integer, db.ForeignKey('user.id'))# 给这个article模型添加一个author属性(关系表),User为要连接的表,backref为定义反向引用# lazy表示禁止自动查询,后面可以直接操作这个对象。只可以用在一对多和多对多关系中,不可以用在一对一和多对一中author = db.relationship('User', backref=db.backref('articles'), lazy='dynamic')
我们新建一个manage.py。
manage.py
from flask_script import Manager
from flask_migrate import Migrate, MigrateCommand
from app import app, db
from models import User, Articlemanager = Manager(app)# 1. 要使用flask_migrate,必须绑定app和db
migrate = Migrate(app, db)
# 2. 把MigrateCommand命令添加到manager中
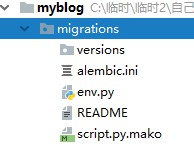
manager.add_command('db', MigrateCommand)if __name__ == '__main__':manager.run()把上面生成的blog.db删除,在命令行中执行 python manage.py db init。同样的,生成了blog.db。同时在我们的项目中会生成一个migrations文件夹,其中versions中没有任何内容。如下图:
然后我们开始迁移数据库。上面的命令成功后,执行如下命令,将模型生成迁移文件。
python manage.py db migrate如下所示,versions文件夹中生成了一个文件88ae96b5a85e_.py。
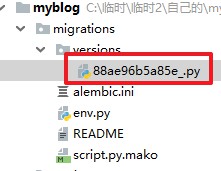
这个就是迁移文件了。我们打开来看看里面是什么。
"""empty messageRevision ID: 88ae96b5a85e
Revises:
Create Date: 2020-05-24 19:51:53.279700"""
from alembic import op
import sqlalchemy as sa# revision identifiers, used by Alembic.
revision = '88ae96b5a85e'
down_revision = None
branch_labels = None
depends_on = Nonedef upgrade():# ### commands auto generated by Alembic - please adjust! ###op.create_table('user',sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),sa.Column('name', sa.String(length=20), nullable=True),sa.PrimaryKeyConstraint('id'))op.create_table('article',sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),sa.Column('title', sa.String(length=100), nullable=False),sa.Column('content', sa.Text(), nullable=False),sa.Column('author_id', sa.Integer(), nullable=True),sa.ForeignKeyConstraint(['author_id'], ['user.id'], ),sa.PrimaryKeyConstraint('id'))# ### end Alembic commands ###def downgrade():# ### commands auto generated by Alembic - please adjust! ###op.drop_table('article')op.drop_table('user')# ### end Alembic commands ###
这就是ORM能够帮我们操作数据库的秘密,emmmm。这时候你的数据库里是还没有创建表的。必须执行下面的语句。
python manage.py db upgrade我们借助pycharm来查看下创建的表结构是不是跟我们预期的一样。
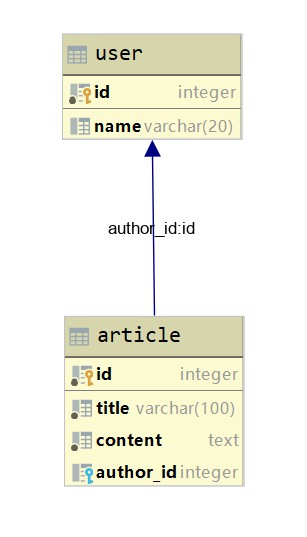
奈斯,一模一样。
好啦,至此我们的数据库部分就完成了创建,下一节我们将会介绍如何去插入数据并展示在我们的博客中。
相关文章:
FLASK博客系列6——数据库之谜
我们上一篇已经实现了简易博客界面,你还记得我们的博客数据是自己手动写的吗?但实际应用中,我们是不可能这样做的。大部分程序都需要保存数据,所以不可避免要使用数据库。我们这里为了简单方便快捷,使用了超级经典的SQ…...

Clickhouse UPDATE 和 DELETE操作
历史: 在OLAP数据库中,可变数据(Mutable data)通常是不被欢迎的,Clickhouse也是如此,早期版本不支持UPDATE和DELTE操作。在Clickhouse 1.1.54388版本之后才支持UPDATE和DELETE操作,适用于Merge…...

golang channel执行原理与代码分析
使用的go版本为 go1.21.2 首先我们写一个简单的chan调度代码 package mainimport "fmt"func main() {ch : make(chan struct{})go func() {ch <- struct{}{}ch <- struct{}{}}()fmt.Println("xiaochuan", <-ch)data, ok : <-chfmt.Println(&…...

OpenCvSharp从入门到实践-(04)色彩空间
目录 1、GRAY色彩空间 2、从BGR色彩空间转换到GRAY色彩空间 2.1色彩空间转换码 2.2实例 BGR色彩空间转换到GRAY色彩空间 3、HSV色彩空间 4、从BGR色彩空间转换到HSV色彩空间 4.1色彩空间转换码 4.2实例 BGR色彩空间转换到HSV色彩空间 1、GRAY色彩空间 GRAY色彩空间通常…...

100.有序数组的平方(力扣)
代码解决一 class Solution { public:// 函数接受一个整数数组,返回每个元素平方值排序后的结果vector<int> sortedSquares(vector<int>& nums) {int len nums.size(); // 获取数组的长度vector<int> v; // 创建一个新的数组,用…...
微服务--01--简介、服务拆分原则
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 微服务微服务架构,是服务化思想指导下的一套最佳实践架构方案。服务化,就是把单体架构中的功能模块拆分为多个独立项目。 单体架构微服务架构…...

IntelliJ IDEA安装使用教程
IntelliJ IDEA是一个流行的Java 集成开发环境(IDE),由JetBrains公司开发。它是一款全功能的IDE,支持多种编程语言,如Java、Kotlin、Groovy、Scala、Python、JavaScript、HTML、CSS等等。IntelliJ IDEA 提供了高效的代码…...
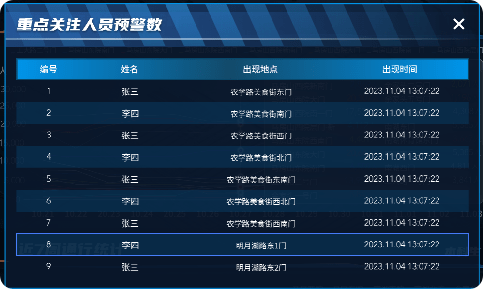
校园门禁可视化系统解决方案
随着科技的持续进步,数字化校园在教育领域中的地位日益上升,各种智能门禁、安防摄像头等已遍布校园各个地方,为师生提供安全便捷的通行体验。然而数据收集分散、缺乏管理、分析困难等问题也逐渐出现,在这个数字化环境中࿰…...

rest_framework_django学习笔记一(序列化器)
rest_framework_django学习笔记一(序列化器) 一、引入Django Rest Framework 1、安装 pip install djangorestframework2、引入 INSTALLED_APPS [...rest_framework, ]3、原始RESTful接口写法 models.py from django.db import models 测试数据 仅供参考 INSERT INTO de…...
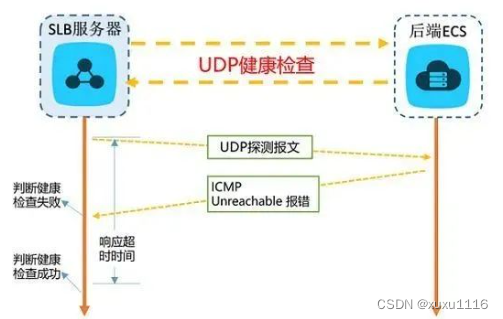
面试题:什么是负载均衡?常见的负载均衡策略有哪些?
文章目录 一、负载均衡二、负载均衡模型分类三、CDN负载均衡四、LVS负载均衡4.1 LVS 支持的三种模式4.1.1 DR 模式4.1.2 TUN 模式4.1.3 NAT 模式 4.2 LVS 基于 Netfilter 的框架实现 五、负载均衡策略是什么六、常用负载均衡策略图解6.1 轮询6.2 加权轮询6.3 最少连接数6.4 最快…...
读书笔记)
精通Git(第2版)读书笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言第 1章 入门 11.1 关于版本控制 11.1.1 本地版本控制系统 1 第 2章 Git基础 132.1 获取Git仓库 132.1.1 在现有中初始化Git仓库 132.1.2 克隆现有仓库 14 2.2 在…...
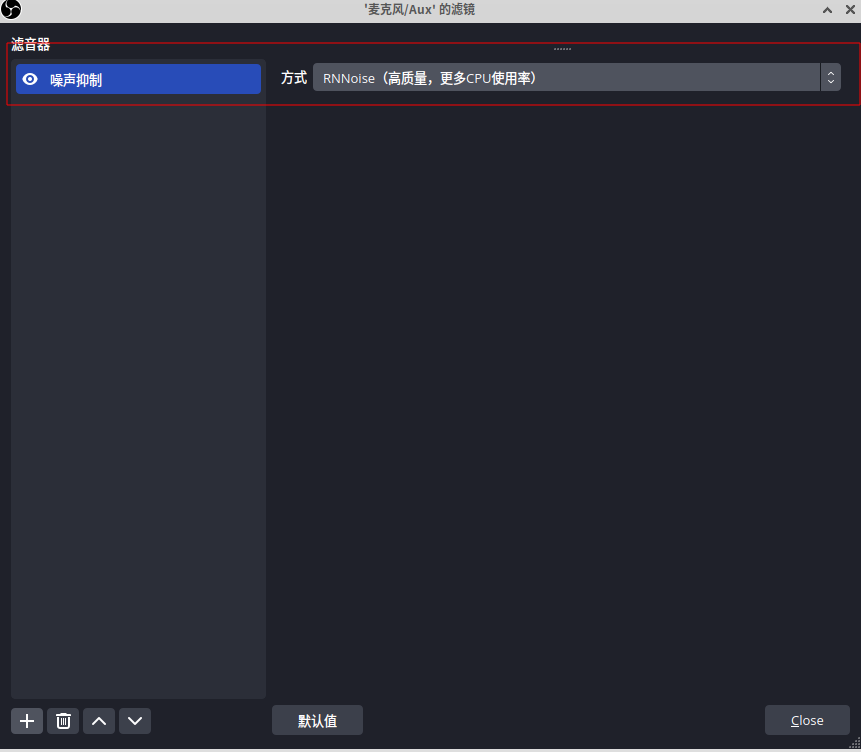
XUbuntu22.04之OBS30.0设置录制音频降噪(一百九十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
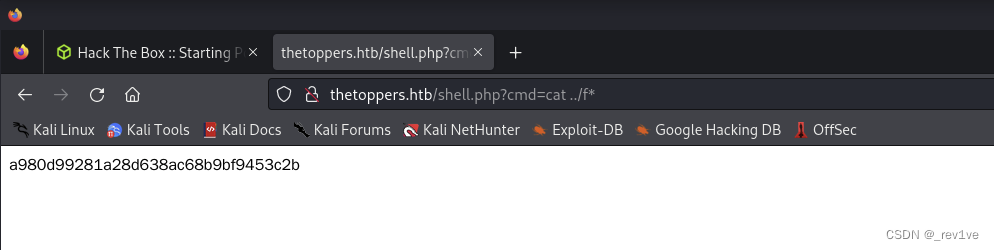
渗透测试学习day4
文章目录 靶机:SequelTask1Task2Task3Task4Task5Task6Task7Task8 靶机:CrocodileTask1Task2Task3Task4Task5Task6Task7Task8Task9Task10 靶机:ResponderTask1Task2Task3Task4Task5Task6Task7Task8Task9Task10Task11 靶机:ThreeTas…...
Deepin使用记录-deepin系统下安装RabbitMq
目录 0、引言 1、由于RabbitMq是erlang语言开发的,所有需要先安装erlang 2、更新源并安装RabbitMq 3、安装完成之后,服务是启动的,可以通过以下语句查看状态 4、这样安装完成之后,是看不到web页面的,需要再安装一…...

【腾讯云云上实验室】用向量数据库——实现高效文本检索功能
文章目录 前言Tencent Cloud VectorDB 简介Tencent Cloud VectorDB 使用实战申请腾讯云向量数据库腾讯云向量数据库使用步骤腾讯云向量数据库实现文本检索 结论和建议 前言 想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关…...

Pytorch中的gather的理解和用法
Pytorch中的gather的理解和用法 这个Gather的用法花费了点时间,我相信很多人一开始不太懂。 跟着我简单理解。 首先样例是: tensor([[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])然后index: [[2, 1, 0]]然后执行的代码: tensor_0.gather(0…...

唯创知音WTN6系列语音芯片:高音频采样率与精细音量控制赋能广泛应用
在语音芯片领域,唯创知音的WTN6系列语音芯片以其出色的性能和广泛的应用领域,无疑是行业的一颗璀璨明星。近期,该系列芯片实现了音频采样率32kHz的突破,以及16级音量控制的精细调节,进一步提升了其在各类应用中的表现。…...

机器人分类
从发展阶段分类: 1第一代机器人2第二代机器人3第三代机器人:智能型机器人。生于90年代。具有传感器,以前的机器人都不具有传感器 从控制方式分类:(我觉得这个分类好乱) 操作型机器人:可自动控…...
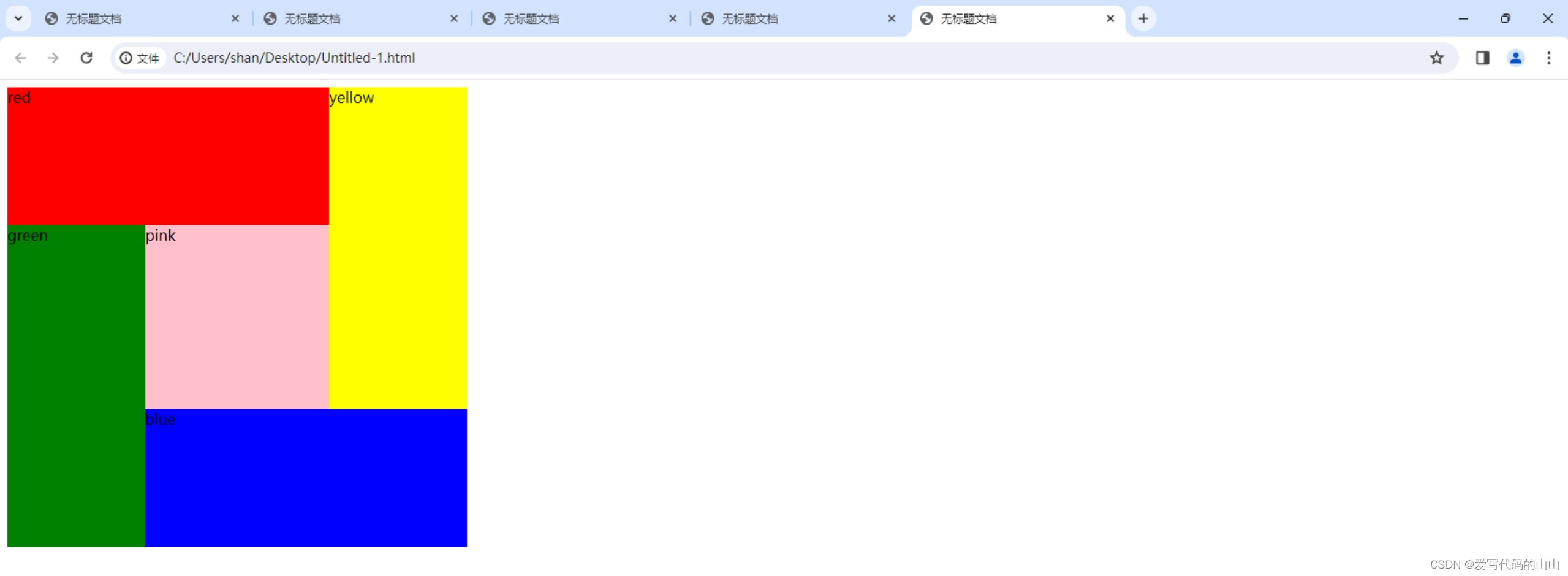
html/css中位置position的绝对位置absolute顺时针盒子案例图片排序
目标图片: Dreamweaver界面: 代码部分: <!doctype html> <html> <head> <meta charset"utf-8"> <title>无标题文档</title> <style type"text/css">.red{background-color:r…...

分享86个清新唯美PPT,总有一款适合您
分享86个清新唯美PPT,总有一款适合您 86个清新唯美PPT下载链接:https://pan.baidu.com/s/1QEaXeWAekCbAWDD0iTgvMw?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气,收集整…...

视频理解新范式:COOT模型实现对象-场景联合建模的视频描述生成
1. 项目概述:让视频自己“开口说话”的底层逻辑你有没有遇到过这样的场景:手头有一段3分钟的产品演示视频,需要快速生成一段精准的图文摘要发给客户;或者在做无障碍内容开发时,得为一段教学视频配上逐帧语义描述&#…...

云飞云 + SolidWorks服务器 = 10人研发共享方案,附硬件配置清单
10人研发团队用SolidWorks搞设计,是中小制造企业最常见的场景——模型要画、装配要搭、渲染要跑、图纸要存,每天8小时高强度运转。传统模式下每台工作站动辄2~3万元,10台就是25万起步;软件授权10套License,年费轻松30~…...

AI——LangChain 三大核心概念
LangChain 三大核心概念一、LangChain 三大核心概念1. 提示词模板 PromptTemplate2. 模型调用 ChatOpenAI / ChatZhipuAI3. 链 Chain二、完整可运行代码(带角色设定)功能三、如果你想用 **智谱 GLM**四、总结一、LangChain 三大核心概念 1. 提示词模板 …...

2026 AI 培训机构怎么选?6 类人群精准匹配 + 避坑指南
随着大模型、多模态、RAG、Agent 技术持续迭代,企业对于 AI 算法开发、计算机视觉、自然语言处理、工程落地类人才的需求持续上涨。目前国内主流AI学习平台包含咕泡科技、科大讯飞AI大学堂、腾讯云智学堂、深兰科技人工智能教育等,各家平台技术侧重点、课…...

如何快速掌握串口数据可视化:SerialPlot终极完整教程
如何快速掌握串口数据可视化:SerialPlot终极完整教程 【免费下载链接】serialplot Small and simple software for plotting data from serial port in realtime. 项目地址: https://gitcode.com/gh_mirrors/se/serialplot 想象一下,你正在调试一…...

通过Taotoken CLI工具一键配置多开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置多开发环境接入参数 在接入大模型服务时,开发者常常需要为不同的开发工具(如…...

Node.js 服务中如何异步调用 Taotoken 聚合接口实现 AI 功能集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务中如何异步调用 Taotoken 聚合接口实现 AI 功能集成 在 Node.js 服务中集成大模型能力,通常意味着你需要处…...
 中 userdata 参数的正确用法与内存管理)
OpenCV鼠标事件避坑指南:setMouseCallback() 中 userdata 参数的正确用法与内存管理
OpenCV鼠标事件高阶实践:setMouseCallback()中userdata参数的安全使用与多线程陷阱 在计算机视觉开发中,交互式图像处理是一个常见需求。OpenCV提供的setMouseCallback()函数看似简单,但当开发者需要传递复杂数据结构或在多线程环境下使用时…...

DCIM管理系统是什么?它的应用价值与关键功能有哪些?
DCIM管理系统的定义与功能概述 是现代数据中心重要的工具,目的是融合IT管理与设备监控,进而实现高效的容量规划与设备维护。这个系统的核心组件包括实时监控、资产管理及环境监控功能,利用综合运用这些工具,操作人员能够快速识别…...

Awesome Video终极指南:从零开始掌握流媒体视频技术栈
Awesome Video终极指南:从零开始掌握流媒体视频技术栈 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video 流媒…...