LeNet对MNIST 数据集中的图像进行分类--keras实现
我们将训练一个卷积神经网络来对 MNIST 数据库中的图像进行分类,可以与前面所提到的CNN实现对比CNN对 MNIST 数据库中的图像进行分类-CSDN博客
加载 MNIST 数据库
MNIST 是机器学习领域最著名的数据集之一。
- 它有 70,000 张手写数字图像 - 下载非常简单 - 图像尺寸为 28x28 - 灰度图像
from keras.datasets import mnist# 使用 Keras 导入预洗牌 MNIST 数据库
(X_train, y_train), (X_test, y_test) = mnist.load_data()print("The MNIST database has a training set of %d examples." % len(X_train))
print("The MNIST database has a test set of %d examples." % len(X_test))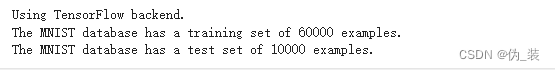
将前六个训练图像可视化
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.cm as cm
import numpy as np# 绘制前六幅训练图像
fig = plt.figure(figsize=(20,20))
for i in range(6):ax = fig.add_subplot(1, 6, i+1, xticks=[], yticks=[])ax.imshow(X_train[i], cmap='gray')ax.set_title(str(y_train[i]))
查看图像的更多细节
def visualize_input(img, ax):ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width):for y in range(height):ax.annotate(str(round(img[x][y],2)), xy=(y,x),horizontalalignment='center',verticalalignment='center',color='white' if img[x][y]<thresh else 'black')fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
visualize_input(X_train[0], ax)
预处理输入图像:通过将每幅图像中的每个像素除以 255 来调整图像比例
# normalize the data to accelerate learning
mean = np.mean(X_train)
std = np.std(X_train)
X_train = (X_train-mean)/(std+1e-7)
X_test = (X_test-mean)/(std+1e-7)print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
对标签进行预处理:使用单热方案对分类整数标签进行编码
from keras.utils import np_utilsnum_classes = 10
# print first ten (integer-valued) training labels
print('Integer-valued labels:')
print(y_train[:10])# one-hot encode the labels
# convert class vectors to binary class matrices
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)# print first ten (one-hot) training labels
print('One-hot labels:')
print(y_train[:10])
重塑数据以适应我们的 CNN(和 input_shape)
# input image dimensions 28x28 pixel images.
img_rows, img_cols = 28, 28X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)print('image input shape: ', input_shape)
print('x_train shape:', X_train.shape)定义模型架构

论文地址:lecun-01a.pdf
要在 Keras 中实现 LeNet-5,请阅读原始论文并从第 6、7 和 8 页中提取架构信息。以下是构建 LeNet-5 网络的主要启示:
- 每个卷积层的滤波器数量:从图中(以及论文中的定义)可以看出,每个卷积层的深度(滤波器数量)如下:C1 = 6、C3 = 16、C5 = 120 层。
- 每个 CONV 层的内核大小:根据论文,内核大小 = 5 x 5
- 每个卷积层之后都会添加一个子采样层(POOL)。每个单元的感受野是一个 2 x 2 的区域(即 pool_size = 2)。请注意,LeNet-5 创建者使用的是平均池化,它计算的是输入的平均值,而不是我们在早期项目中使用的最大池化层,后者传递的是输入的最大值。如果您有兴趣了解两者的区别,可以同时尝试。在本实验中,我们将采用论文架构。
- 激活函数:LeNet-5 的创建者为隐藏层使用了 tanh 激活函数,因为对称函数被认为比 sigmoid 函数收敛更快。一般来说,我们强烈建议您为网络中的每个卷积层添加 ReLU 激活函数。
需要记住的事项
- 始终为 CNN 中的 Conv2D 层添加 ReLU 激活函数。除了网络中的最后一层,密集层也应具有 ReLU 激活函数。
- 在构建分类网络时,网络的最后一层应该是具有软最大激活函数的密集(FC)层。最终层的节点数应等于数据集中的类别总数。
from keras.models import Sequential
from keras.layers import Conv2D, AveragePooling2D, Flatten, Dense#Instantiate an empty model
model = Sequential()# C1 Convolutional Layer
model.add(Conv2D(6, kernel_size=(5, 5), strides=(1, 1), activation='tanh', input_shape=input_shape, padding='same'))# S2 Pooling Layer
model.add(AveragePooling2D(pool_size=(2, 2), strides=2, padding='valid'))# C3 Convolutional Layer
model.add(Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))# S4 Pooling Layer
model.add(AveragePooling2D(pool_size=(2, 2), strides=2, padding='valid'))# C5 Fully Connected Convolutional Layer
model.add(Conv2D(120, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))#Flatten the CNN output so that we can connect it with fully connected layers
model.add(Flatten())# FC6 Fully Connected Layer
model.add(Dense(84, activation='tanh'))# Output Layer with softmax activation
model.add(Dense(10, activation='softmax'))# print the model summary
model.summary()
编译模型
我们将使用亚当优化器
# the loss function is categorical cross entropy since we have multiple classes (10) # compile the model by defining the loss function, optimizer, and performance metric
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])训练模型
LeCun 和他的团队采用了计划衰减学习法,学习率的值按照以下时间表递减:前两个历元为 0.0005,接下来的三个历元为 0.0002,接下来的四个历元为 0.00005,之后为 0.00001。在论文中,作者对其网络进行了 20 个历元的训练。
from keras.callbacks import ModelCheckpoint, LearningRateScheduler# set the learning rate schedule as created in the original paper
def lr_schedule(epoch):if epoch <= 2: lr = 5e-4elif epoch > 2 and epoch <= 5:lr = 2e-4elif epoch > 5 and epoch <= 9:lr = 5e-5else: lr = 1e-5return lrlr_scheduler = LearningRateScheduler(lr_schedule)# set the checkpointer
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose=1, save_best_only=True)# train the model
hist = model.fit(X_train, y_train, batch_size=32, epochs=20,validation_data=(X_test, y_test), callbacks=[checkpointer, lr_scheduler], verbose=2, shuffle=True)
在验证集上加载分类准确率最高的模型
# load the weights that yielded the best validation accuracy
model.load_weights('model.weights.best.hdf5')计算测试集的分类准确率
# evaluate test accuracy
score = model.evaluate(X_test, y_test, verbose=0)
accuracy = 100*score[1]# print test accuracy
print('Test accuracy: %.4f%%' % accuracy)
评估模型
import matplotlib.pyplot as pltf, ax = plt.subplots()
ax.plot([None] + hist.history['accuracy'], 'o-')
ax.plot([None] + hist.history['val_accuracy'], 'x-')
# 绘制图例并自动使用最佳位置: loc = 0。
ax.legend(['Train acc', 'Validation acc'], loc = 0)
ax.set_title('Training/Validation acc per Epoch')
ax.set_xlabel('Epoch')
ax.set_ylabel('acc')
plt.show()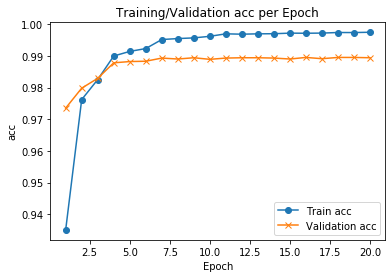
import matplotlib.pyplot as pltf, ax = plt.subplots()
ax.plot([None] + hist.history['loss'], 'o-')
ax.plot([None] + hist.history['val_loss'], 'x-')# Plot legend and use the best location automatically: loc = 0.
ax.legend(['Train loss', "Val loss"], loc = 0)
ax.set_title('Training/Validation Loss per Epoch')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
plt.show() 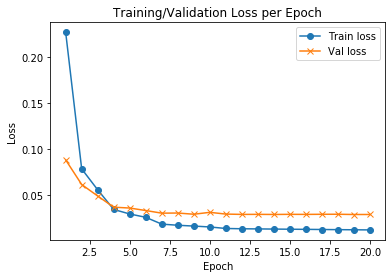
相关文章:
LeNet对MNIST 数据集中的图像进行分类--keras实现
我们将训练一个卷积神经网络来对 MNIST 数据库中的图像进行分类,可以与前面所提到的CNN实现对比CNN对 MNIST 数据库中的图像进行分类-CSDN博客 加载 MNIST 数据库 MNIST 是机器学习领域最著名的数据集之一。 它有 70,000 张手写数字图像 - 下载非常简单 - 图像尺…...

Django的回顾的第4天
1.模型层 1.1简介 你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python代码之中。 def current_datetime(request):now datetime.datetime.now()html "<html><body>It is now %s.</body><…...
)
点云从入门到精通技术详解100篇-基于三维点云的工件曲面轮廓检测与机器人打磨轨迹规划(中)
目录 2.2.2 散乱点云滤波去噪 2.2.3 海量点云数据压缩 2.3 点云采集与预处理实验...
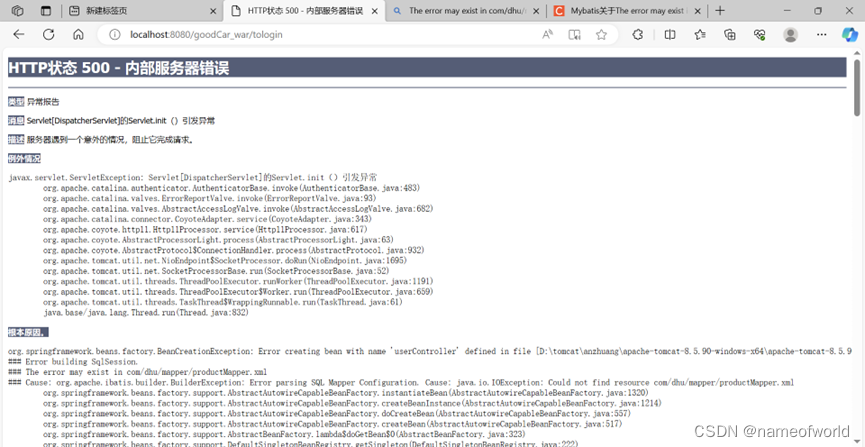
Mapper文件夹在resource目录下但是网页报错找不到productMapper.xml文件的解决
报错如下: 我的Mapper文件夹在resourse目录下但是网页报错找不到productMapper.xml。 结构如下:代码如下:<mappers><mapper resource"com/dhu/mapper/productMapper.xml" /> </mappers> 这段代码是在mybatis-co…...

22.Oracle中的临时表空间
Oracle中的临时表空间 一、临时表空间概述1、什么是临时表空间2、临时表空间的作用 二、临时表空间相关语法三、具体使用案例1、具体使用场景示例2、具体使用场景代码示例 点击此处跳转下一节:23.Oracle11g的UNDO表空间点击此处跳转上一节:21.Oracle的程…...
附录A 指令集基本原理
1. 引言 本书主要关注指令集体系结构4个主题: 1. 提出对指令集进行分类的方法,并对各种方法的优缺点进行定性评估; 2. 提出并分析一些在很大程度上独立于特定指令集的指令集评估数据。 3. 讨论语言与编译器议题以及…...

Unittest单元测试之unittest用例执行顺序
unittest用例执行顺序 当在一个测试类或多个测试模块下,用例数量较多时,unittest在执行用例 (test_xxx)时,并不是按从上到下的顺序执行,有特定的顺序。 unittest框架默认根据ACSII码的顺序加载测试用例&a…...

海云安谢朝海:开发安全领域大模型新实践 人工智能助力高效安全左移
2023年11月29日,2023中国(深圳)金融科技大会成功举行,该会议是深圳连续举办的第七届金融科技主题年度会议,也是2023深圳国际金融科技节重要活动之一。做好金融工作,需要兼顾创新与安全,当智能体…...

Postman接口测试工具完整教程
前言 作为软件开发过程中一个非常重要的环节,软件测试越来越成为软件开发商和用户关注的焦点。完善的测试是软件质量的保证,因此软件测试就成了一项重要而艰巨的工作。要做好这项工作当然也绝非易事。 第一部分:基础篇 postman:4.5.1 1.安…...

Android 滑动按钮(开关) SwitchCompat 自定义风格
原生的SwitchCompat控件如下图,不说不堪入目,也算是不敢恭维了。开个玩笑... 所以我们就需要对SwitchCompat进行自定义风格,效果如下图 代码如下 <androidx.appcompat.widget.SwitchCompatandroid:id"id/switch_compat"android:…...
)
前端面试灵魂提问-计网(2)
1、websocket 为什么全双工? 1.1 WebSocket是什么 WebSocket 是一种通信协议,它在客户端和服务器之间建立持久的全双工连接。全双工意味着数据可以双向流动,即客户端可以向服务器发送消息,服务器也可以向客户端发送消息,而无需…...

Git修改远程仓库名称
1、先直接在远程点仓库名,然后左侧菜单栏找settings-general,然后直接修改工程名,保存即可。 2、还是在settings-general下,下拉找到Advanced点击Expand展开,然后下拉到最底部 在Change path里填入新的项目名称&#x…...
kafka 集群 ZooKeeper 模式搭建
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序 Kafka 官网:Apache Kafka 关于ZooKeeper的弃用 根据 Kafka官网信息,随着Apache Kafka 3.5版本的发布,Zookeeper现…...
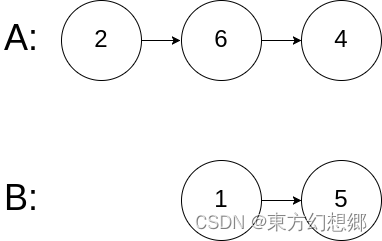
【LeetCode】 160. 相交链表
相交链表 题目题解 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意&am…...

TZOJ 1429 小明A+B
答案: #include <stdio.h> int main() {int T0, A0, B0, sum0;scanf("%d", &T); //输入测试数据的组数while (T--) //循环T次{scanf("%d %d", &A, &B); //输入AB的值sum A B;if (sum > 100) //如果是三位数{…...

制作openeuler的livecd
下载该项目,执行下面的操作gitee openeuler livecd项目 基于openeuler环境 #安装工具,第一次可能报错,可以再执行一次 make installx86 livecd-creator -d -v --config./config/euler_x86_64.ks --fslabeleuler-LiveCD --cachecache --log…...

B.牛牛排队伍——模拟双链表
当前位置: 首页 > news >正文 B.牛牛排队伍——模拟双链表 news 2023/12/1 15:14:37 分析 题目其实很简单,就是双链表的增删查,但是刚开始,直接vis标记删除元素,查找一个位置的前一个用的while不断向前找,但是TLE;毕竟O(n*k)的复杂度,一开始没有考虑时间复杂度…...
损失函数与优化器)
【PyTorch】(四)损失函数与优化器
文章目录 1. 损失函数2. 优化器 1. 损失函数 2. 优化器...
执行insert之后没有插入数据)
【Python】使用execute(sql)执行insert之后没有插入数据
在sql为insert语句,用Python的sqlalchemy模块中的execute()执行之后没有插入数据的情况,主要是因为sqlalchemy版本的更新,不能直接只用execute()了,MySQL数据库连接的配置和sql都需要多处理一步: 之前的版本ÿ…...
虚拟机备份数据自动化验证原理
备份数据成功备份下来了,但是备份数据是否可用可靠?对于这个问题,最好最可靠的方法是将备份数据实际恢复出来验证。 但是这样的方法,不仅费时费力,而且需要随着备份数据的定期产生,还应当定期做备份数据验…...

DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线
DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线 在电子工程和硬件测试领域,快速准确地获取元器件的伏安特性(V-A特性)曲线是一项基础但至关重要的任务。无论是LED的导通阈值、电机的启动电流,还是…...

终极指南:如何在Android设备上实现Zwift离线骑行模拟
终极指南:如何在Android设备上实现Zwift离线骑行模拟 【免费下载链接】zwift-offline Use Zwift offline 项目地址: https://gitcode.com/gh_mirrors/zw/zwift-offline 你是否厌倦了网络不稳定导致的Zwift训练中断?想要在任何地方都能享受专业的虚…...

创业团队如何利用Taotoken统一技术栈并降低AI接入门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken统一技术栈并降低AI接入门槛 对于资源有限的创业团队而言,在产品中集成人工智能能力是提升竞…...

通过Python快速调用Taotoken实现自动化文档生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Python快速调用Taotoken实现自动化文档生成 对于嵌入式或单片机开发者而言,为Keil5项目编写和维护技术文档是一项耗…...

利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题 对于依赖Claude Code进行日常开发的工程师而言,服…...

UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知
UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知在全域空间高精度感知产业高速迭代进程中,室内外人员与目标定位技术逐步分化为两大主流发展路径,其一为深耕多年、依托硬件组网实现测距定位的传统UWB厘米级…...

口腔诊所装修性价比提升指南
口腔诊所进行装修时,提升性价比的核心在于 “精准投入” ,即在确保医疗功能、患者体验和卫生合规的前提下,实现成本的最优化。1、 规划先行:奠定性价比基石 功能布局优先: 明确划分接待、候诊、诊疗、消毒等功能区&…...

从零到一:基于YOLOv8的AI自瞄终极指南
从零到一:基于YOLOv8的AI自瞄终极指南 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 想象一下,你正在玩最喜欢的FPS游戏,敌人从掩体后一闪而过&…...

Orbit:革命性记忆增强平台的完整指南
Orbit:革命性记忆增强平台的完整指南 【免费下载链接】orbit Experimental spaced repetition platform for exploring ideas in memory augmentation and programmable attention 项目地址: https://gitcode.com/gh_mirrors/orbit1/orbit Orbit是一个革命性…...

Deno_2.0全栈开发实战下一代JavaScript运行时完全指南
Deno 2.0全栈开发实战:下一代JavaScript运行时完全指南 📅 发布日期:2026-05-21 | 🏷️ 标签:Deno、TypeScript、全栈开发、Fresh框架、边缘计算 📖 阅读时间:约25分钟 | 💡 难度:中级到高级 前言:Deno 2.0——Node.js之父的"理想主义"终于落地 2018年…...