PyLMKit(3):基于角色扮演的应用案例
角色扮演应用案例RolePlay
0.项目信息
- 日期: 2023-12-2
- 作者:小知
- 课题: 通过设置角色模板并结合在线搜索、记忆和知识库功能,实现典型的对话应用功能。这个功能是大模型应用的基础功能,在后续其它RAG等功能中都会用到这个功能。
- 功能与作用:RolePlay角色扮演是一种基础功能,也是重要的功能。现在在各大大模型企业的APP中可以看到很多关于短视频文案、小红书文案、高情商朋友圈等这些功能的底层逻辑是基于角色扮演中设置不同的角色模板实现的。
- GitHub:https://github.com/52phm/pylmkit
- PyLMKit官网教程
- PyLMKit应用(online application)
- English document
- 中文文档
PyLMKit RolePlay

1.下载安装
# 下载安装
pip install pylmkit -U --user
2.设置API KEY
应用哪个大模型,就提前设置好该大模型对应的 API KEY
import os# openai chatgpt
os.environ['openai_api_key'] = ""# 百度
os.environ['qianfan_ak'] = ""
os.environ['qianfan_sk'] = ""# 阿里
os.environ["DASHSCOPE_API_KEY"] = ""# 科大讯飞-星火
os.environ["spark_appid"] = ""
os.environ["spark_apikey"] = ""
os.environ["spark_apisecret"] = ""
os.environ["spark_domain"] = "generalv3"# 智谱AI
os.environ['zhipu_apikey'] = ""或者在.env文件中批量加载设置好的API KEY,加载方法如下:
from dotenv import load_dotenv# load .env
load_dotenv()
3.加载大语言模型
导入大语言模型,在本案例中使用百度千帆大模型作为例子进行介绍。
from pylmkit.llms import ChatQianfan # 百度-千帆
from pylmkit.llms import ChatSpark # 讯飞-星火
from pylmkit.llms import ChatZhipu # 清华-智谱
from pylmkit.llms import ChatHunyuan # 腾讯-混元
from pylmkit.llms import ChatBaichuan # 百川
from pylmkit.llms import ChatTongyi # 阿里-通义
from pylmkit.llms import ChatOpenAI # OpenAImodel = ChatQianfan()
4.选择记忆功能
PyLMKit 设计了四种记忆功能,分别如下:
- MemoryHistoryLength:记忆历史长度,强调使用近期多长的记忆内容;
- MemoryConversationsNumber:记忆对数数,强调使用近期N组对话作为记忆的内容;
- MemorySummary:记忆摘要,强调精简提取记忆;
- 暂未公布
本案例使用MemoryHistoryLength记忆功能,使得大语言模型能到根据该历史记忆记住上下文内容,以便连贯回答用户的问题。(更多关于记忆的用法,可以在后续memory专题中查阅)
from pylmkit.memory import MemoryHistoryLengthmemory = MemoryHistoryLength(memory_length=500, streamlit_web=False) # 在python中运行
# memory2 = MemoryHistoryLength(memory_length=500, streamlit_web=True) # 在streamlit web中运行
5.设计角色模板
大语言模型是一种一对多关系的模型架构,其中一表示大语言模型,而多表示下游任务,比如写作、客服、分析数据等这些都属于下游任务。
因此需要我们通过设计提示词模板去引导大语言模型高效且有质量地完成指定下游任务。
在设计角色模板之前,我们先来了解PyLMKit中一些必须固定的关键词:
- {query}:表示这是用户输入的提问内容;
- {search}:表示线上实时搜索引擎搜索返回的内容;
- {memory}:表示记忆的内容;
- {ra}:表示知识库搜索返回的内容。
下面我们来看一个角色模板的例子:
# 它们所在的位置,表示它们内容所嵌入的位置
role_template = "{memory}\n {search}\n 用户提问:{query}"# 当然,你还可以进一步设计模板
role_template = "历史对话内容:{memory}\n 搜索的相似内容:{search} {ra}\n 请结合上述内容回答问题:{query}"model.invoke(query="如何学习python?")
角色模板决定大语言模型回答的质量,因此角色模板需要反复打磨,以设计一个高质量的角色模板,对问题的解决效果可以达到事半功倍。
另外,值得注意的是,如果你设计的角色模板的关键词,不在[query, search, ra, memory]中,那么你需要额外添加新的变量和变量值,例如:
role_template = "{memory}\n 请为我推荐{query}的{topic}"# 额外的关键字,可以像 topic="美食" 一样添加,多个也是一样的步骤进行添加
model.invoke(query='北京', topic="美食")
role_template = "{memory}\n 请为我推荐{query}的{topic}"
6.加载角色扮演应用
RolePlay角色扮演是一种基础功能,也是重要的功能。现在在各大大模型企业的APP中可以看到很多关于短视频文案、小红书文案、高情商朋友圈等这些功能的底层逻辑是基于角色扮演中设置不同的角色模板实现的。
from pylmkit.app import RolePlayrp = RolePlay(role_template=role_template, # 角色模板llm_model=model, # 大语言模型memory=memory, # 记忆# online_search_kwargs={},online_search_kwargs={'topk': 2, 'timeout': 20}, # 搜索引擎配置,不开启则可以设置为 online_search_kwargs={}return_language="中文"
)
7.在python中运行
while True:query = input("User query:")topic = input("User topic:")response, refer = rp.invoke(query, topic=topic)print("\nAI:", response)print("\nRefer\n:", refer)
User query:北京
User topic:美食2023-12-02 01:28:27 - httpx - INFO - HTTP Request: POST https://duckduckgo.com "HTTP/2 200 OK"
2023-12-02 01:28:29 - httpx - INFO - HTTP Request: GET https://links.duckduckgo.com/d.js?q=%E5%8C%97%E4%BA%AC&kl=wt-wt&l=wt-wt&s=0&df=&vqd=4-45222965241755774163610013696327482249&o=json&sp=0&ex=-1 "HTTP/2 200 OK"AI: 北京有很多美食,以下是为您推荐的一些美食:1. 北京烤鸭:是北京最著名的传统美食,具有独特的皮脆肉嫩、肥而不腻的口味。2. 炸酱面:是一道非常受欢迎的主食,面条劲道,炸酱味道浓郁,可以搭配各种蔬菜和肉类。3. 炒肝:是一种传统早点,主要原料是猪大肠和猪肝,口感鲜美,适合早餐食用。4. 羊肉串:是北京街头巷尾最常见的烧烤之一,肉质鲜嫩,味道鲜美。5. 豆汁儿:是北京传统特色小吃之一,由绿豆制作而成,味道独特,需要慢慢品尝。6. 爆肚:是北京传统小吃,口感鲜美,特别适合夏天食用。7. 涮羊肉:是一种传统的火锅美食,口感鲜美,涮出的羊肉非常嫩滑。除此之外,北京还有各种烤肉、烧麦、饺子、包子、馄饨等美食,您可以根据自己的口味选择尝试。Refer
: [1] **https://zh.wikipedia.org/wiki/北京市** 北京古迹众多,著名的有紫禁城、天坛、颐和园、圆明园、北海公园等;胡同和四合院作为北京老城的典型民居形式,已经是北京历史重要的文化符号 。北京是中国重要的旅游城镇,被《米其林旅游指南》评为"三星级旅游推荐"(最高级别)目的地 。[2] **https://baike.baidu.com/item/北京市/126069** 北京市(Beijing),简称"京",古称燕京、北平,中华民族的发祥地之一,是中华人民共和国首都、直辖市、国家中心城市、超大城市,国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心,中国历史文化名城和古都之一,世界一线城市。截至2023年10月,北京市下辖16个区,总 ...
在streamlit web中运行
要在终端中运行:假设你的.py文件名为main.py,那么在终端运行:
streamlit run main.py
# main.py
from pylmkit.core.base import BaseWebUI
from pylmkit.memory import MemoryHistoryLengthweb = BaseWebUI(language='zh') # 使用中文网站
memory = MemoryHistoryLength(memory_length=web.param(label="记忆长度", type='int', value=500), # 添加页面交互参数streamlit_web=True)web.run(obj=rp.invoke,input_param=[{"name": "query", "label": "地点", "type": "chat"},{"name": "topic", "label": "主题", "type": "text"},],output_param=[{'label': '结果', 'name': 'response', 'type': 'chat'},{'label': '参考', 'name': 'refer', 'type': 'refer'}]
)
相关文章:
PyLMKit(3):基于角色扮演的应用案例
角色扮演应用案例RolePlay 0.项目信息 日期: 2023-12-2作者:小知课题: 通过设置角色模板并结合在线搜索、记忆和知识库功能,实现典型的对话应用功能。这个功能是大模型应用的基础功能,在后续其它RAG等功能中都会用到这个功能。功…...

JAVA全栈开发 集合详解(day14+day15汇总)
一、数组 数组是一个容器,可以存入相同类型的多个数据元素。 数组局限性: 长度固定:(添加–扩容, 删除-缩容) 类型是一致的 对象数组 : int[] arr new int[5]; … Student[] arr …...
Linux Spug自动化运维平台本地部署与公网远程访问
文章目录 前言1. Docker安装Spug2 . 本地访问测试3. Linux 安装cpolar4. 配置Spug公网访问地址5. 公网远程访问Spug管理界面6. 固定Spug公网地址 前言 Spug 面向中小型企业设计的轻量级无 Agent 的自动化运维平台,整合了主机管理、主机批量执行、主机在线终端、文件…...

zookeeper集群和kafka集群
(一)kafka 1、kafka3.0之前依赖于zookeeper 2、kafka3.0之后不依赖zookeeper,元数据由kafka节点自己管理 (二)zookeeper 1、zookeeper是一个开源的、分布式的架构,提供协调服务(Apache项目&…...
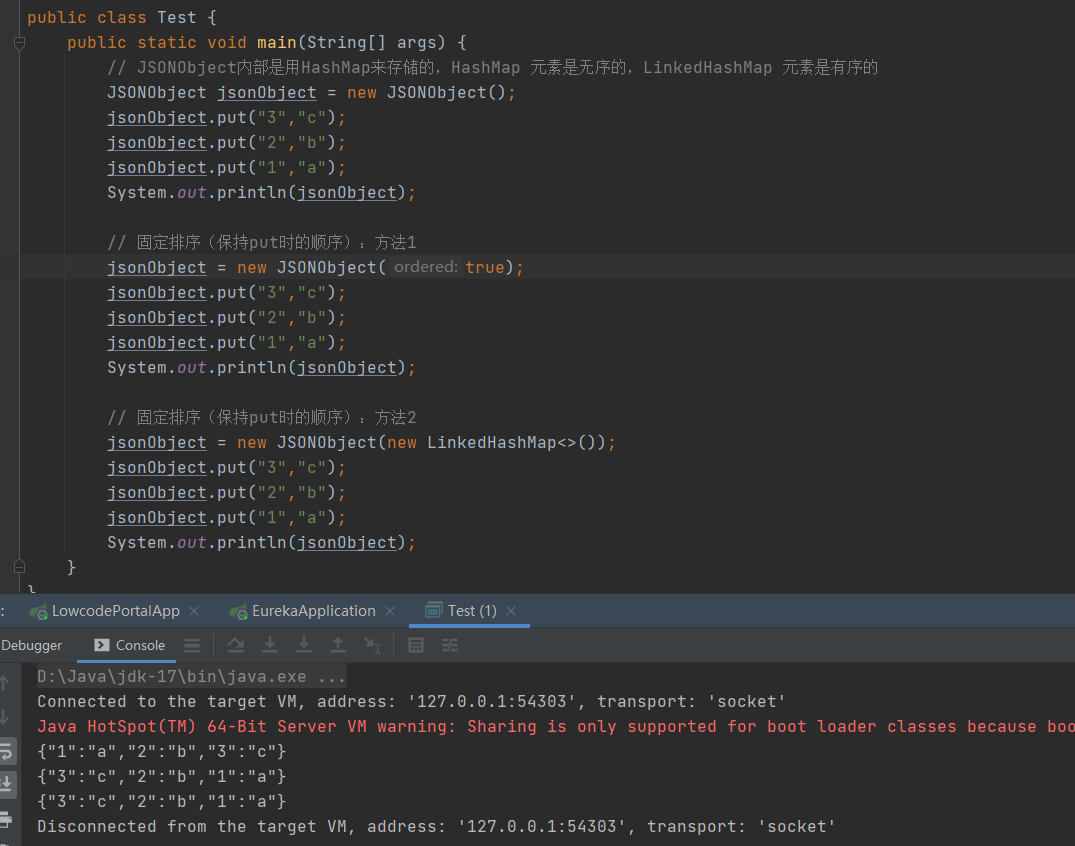
Java——》JSONObjet 数据顺序
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

【个人记录】NGINX反向代理grpc服务
最开始使用proxy_pass去代理了grpc服务,结果请求时候报错提示: rpc error: code Unavailable desc connection error: desc "error reading server preface: http2: frame too large"后来才知道代理grpc服务需要使用grpc_pass,…...

【小白推荐】安装OpenCV4.8 系统 Ubuntu 22.04LST Linux.
先看一下目录,知道大致的流程! 文章目录 安装OpenCV安装依赖下载源码配置与构建安装 测试编写CMakeListx.txt编写测试代码 安装OpenCV 安装依赖 sudo apt update && sudo apt upgrade sudo apt install cmake ninja-build build-essential lib…...
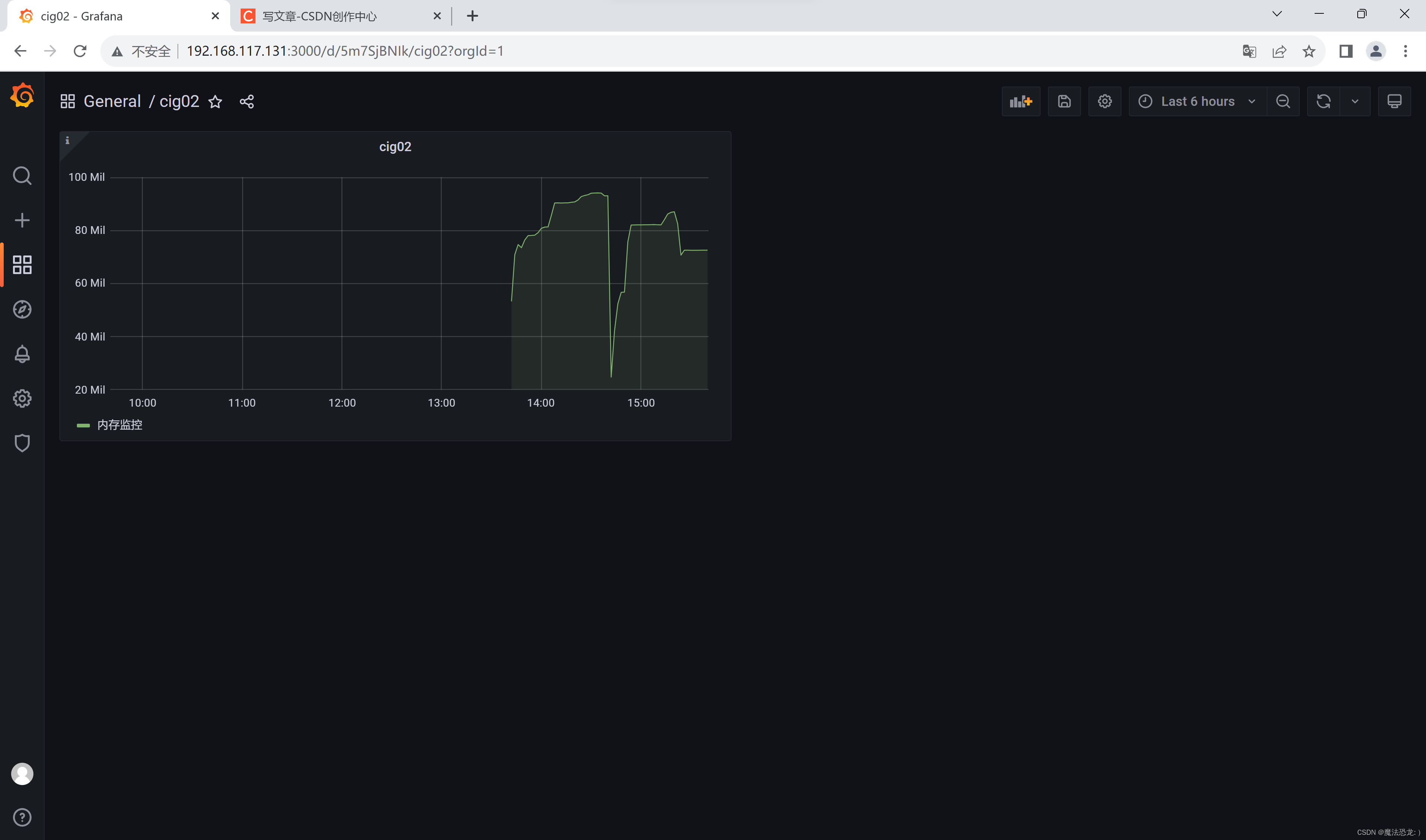
使用Docker Compose搭建CIG监控平台
CIG简介 CIG监控平台是基于CAdvisor、InfluxDB和Granfana构建的一个容器重量级监控系统,用于监控容器的各项性能指标。其中,CAdvisor是一个容器资源监控工具,用于监控容器的内存、CPU、网络IO和磁盘IO等。InfluxDB是一个开源的分布式时序、时…...

前端文本省略号后面添加复制文字
前端文本省略号后面添加复制文字 1、效果图 2、代码展示 <div class"link-content-wrap" click"copyLinkText"><div class"link-content">{{ shareResult.url || }} </div><span class"show-ellipsis" click&…...

【算法】动态规划中的路径问题
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,如果给算法的难度和复杂度排一个排名,那么动态规划算法一定名列前茅。今天,我们通过由简单到困难的两道题目带大家学会动…...

代数学笔记9: 群的直积,可解群,自由群,群表示
群的直积 外直积 H 1 , H 2 H_1,H_2 H1,H2是两个群(固定的群), 且有 G H 1 H 2 GH_1\times H_2 GH1H2,(构造的新群) G ( { ( h 1 , h 2 ) ∣ h 1 ∈ H 1 , h 2 ∈ H 2 } , ⋅ ) , G\big(\{(h_1,h_2)|h_1\in H_1,h_2\in H_2\},\cdot\big), G({(h1,h2)∣h1∈H…...
kali学习
目录 黑客法则: 一:页面使用基础 二:msf和Windows永恒之蓝漏洞 kali最强渗透工具——metasploit 介绍 使用永恒之蓝进行攻击 编辑 使用kali渗透工具生成远程控制木马 渗透测试——信息收集 域名信息收集 黑客法则: 一&…...

《论文阅读》DualGATs:用于对话中情绪识别的双图注意力网络
《论文阅读》DualGATs:用于会话中情感识别的双图注意力网络 前言摘要模型架构DisGAT图构建图关系类型图节点更新SpkGAT图构建图关系类型图节点更新交互模块情绪预测损失函数问题前言 今天为大家带来的是《DualGATs: Dual Graph Attention Networks...
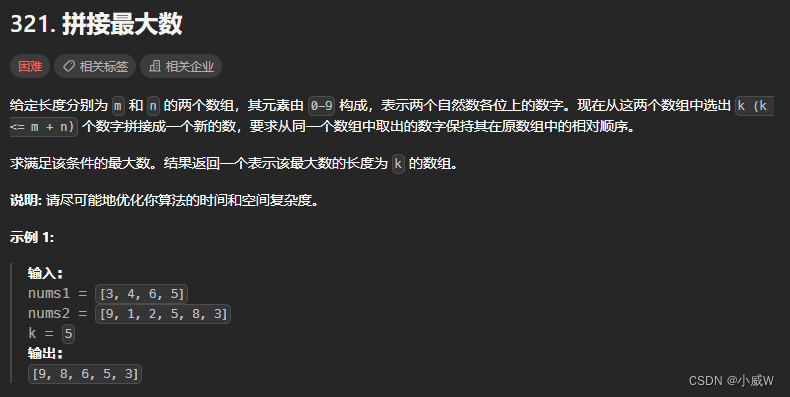
【算法】单调栈题单——字典序最小⭐(一种类型的模板题)
文章目录 题目列表316. 去除重复字母⭐⭐⭐⭐⭐(类型题模板:单调栈,字典序最小)221021天池-03. 整理书架(保留数量为 limit 的字典序最小)402. 移掉 K 位数字(最多删除 k 次 前导零的处理&…...
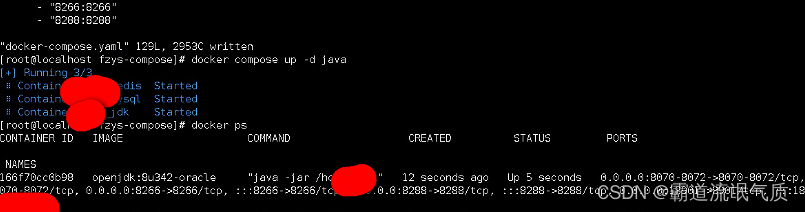
DockerCompose修改某个服务的配置(添加或编辑端口号映射)后如何重启单个服务使其生效
场景 docker-compose入门以及部署SpringBootVueRedisMysql(前后端分离项目)以若依前后端分离版为例: docker-compose入门以及部署SpringBootVueRedisMysql(前后端分离项目)以若依前后端分离版为例_docker-compose部署java mysql redis-CSDN博客 上面讲了docker c…...

DOM 事件的传播机制
前端面试大全DOM 事件的传播机制 🌟经典真题 🌟事件与事件流 事件流 事件冒泡流 事件捕获流 标准 DOM 事件流 🌟事件委托 🌟真题解答 🌟总结 🌟经典真题 谈一谈事件委托以及冒泡原理 dz…...

(数据结构)顺序表的查找
静态分配代码: #include<stdio.h> #include<stdlib.h> #define MAX 100 typedef struct LinkList {int data[MAX];int lenth; }Link; //初始化 void CreateList(Link* L) {L->lenth 0;for (int i 0; i < MAX; i){L->data[i] 0;} } //插入 …...

vue 解决响应大数据表格渲染崩溃问题
如果可以实现记得点赞分享,谢谢老铁~ 1.场景描述 发起请求获取上万条数据,进行表格渲染,使浏览器卡顿,导致网页崩溃。 2.分析原因 1.大量数据加载,过多操作Dom,消耗性能。 2.表格中包含其他…...
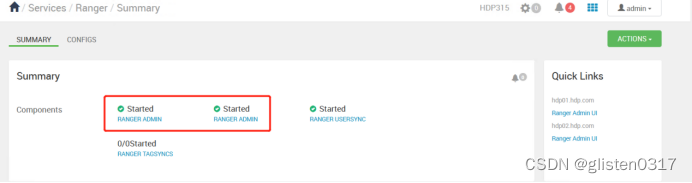
Hdoop学习笔记(HDP)-Part.13 安装Ranger
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

Spring AOP记录接口访问日志
Spring AOP记录接口访问日志 介绍应用范围组成通知(Advice)连接点(JoinPoint)切点(Pointcut)切面(Aspect)引入(Introduction)织入(Weaving&#x…...

GHelper全面革新:华硕笔记本硬件控制的智能突破方案
GHelper全面革新:华硕笔记本硬件控制的智能突破方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...
AudioSeal Pixel Studio实操手册:音频指纹哈希值生成与区块链存证接口对接示例
AudioSeal Pixel Studio实操手册:音频指纹哈希值生成与区块链存证接口对接示例 1. 工具概述与核心价值 AudioSeal Pixel Studio是一款基于Meta开源的AudioSeal算法构建的专业音频水印工具。它能够在保持原始音频质量的前提下,为音频文件嵌入不可感知的…...

GLM-4.1V-9B-Base与Dify联动:零代码构建企业级AI应用平台
GLM-4.1V-9B-Base与Dify联动:零代码构建企业级AI应用平台 1. 企业AI应用的新选择 最近接触了不少企业客户,发现一个普遍现象:大家都想用AI,但真正能用起来的却不多。技术门槛高、开发周期长、维护成本大,这些问题让很…...

OpenClaw对话日志分析:Qwen3.5-9B优化任务执行成功率
OpenClaw对话日志分析:Qwen3.5-9B优化任务执行成功率 1. 问题背景与数据准备 去年开始使用OpenClaw对接Qwen3.5-9B模型时,我发现一个有趣现象:同样的自动化任务,在不同时段执行成功率波动很大。有时能完美完成文件整理和邮件发送…...

DVWA SQL 注入:两种查表字段 Payload 结果差异详解
一、问题引入在 DVWA Medium 级别 SQL 注入实验中,我们通过 Burp Suite 抓包改包,对users表字段进行查询时,会遇到两种看似不同的执行结果:图 1:逐行展示users表的每一个字段名图 2:一行展示user表的所有字…...

AI辅助游戏开发新体验:让快马平台的AI模型为你的Superpowers项目编写剧情与平衡技能
最近在尝试用Superpowers框架开发一款魔法题材的RPG游戏,发现InsCode(快马)平台的AI辅助功能特别适合快速原型开发。这里分享下如何用AI模型辅助完成游戏剧情脚本和技能平衡设计的实践过程。 剧情脚本生成 输入"魔法学校学徒发现古老卷轴"这个简单设定后&…...

从需求到代码:基于快马平台ai生成spring boot电商系统实战项目
从需求到代码:基于快马平台AI生成Spring Boot电商系统实战项目 最近在做一个电商订单处理系统的项目,正好尝试了用InsCode(快马)平台来快速生成Spring Boot代码。整个过程比我预想的要顺畅很多,特别是对于这种包含多个模块的中型项目&#x…...

揭秘Nunchaku FLUX.1 CustomV3工作流:LoRA融合技巧让图片细节更丰富
揭秘Nunchaku FLUX.1 CustomV3工作流:LoRA融合技巧让图片细节更丰富 你是否曾经看着别人用AI生成的图片,惊叹于那些纤毫毕现的发丝、细腻柔和的皮肤质感、以及充满故事感的光影细节,而自己用同样的模型却总感觉差了点什么?画面好…...

自己做SEO时有哪些容易被忽视的关键点_SEO 自己怎么做
自己做SEO时容易被忽视的关键点 在当今的互联网时代,搜索引擎优化(SEO)已经成为每个网站主的必修课。在自己做SEO时,有些关键点往往会被忽视,导致网站的流量和排名并未达到最佳效果。本文将深入探讨这些容易被忽视的关…...

如何通过ImageToSTL实现图像三维化?解锁创意设计新可能
如何通过ImageToSTL实现图像三维化?解锁创意设计新可能 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side.…...