Python压缩、解压文件
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC
@file: util_compress.py
@time: 2023/5/28 14:58
@desc: rarfile 使用需要安装 rarfile 和 unrar 并且将 unrar.exe 复制到venv/Scrpits目录下
(从WinRar安装目录下白嫖的)
下载地址:https://jhc001.lanzoub.com/iquO61ga91ha
密码:c7hn
"""
import os
import gzip
from zipfile import ZipFile
import shutil
import rarfile
# 这俩工具包在下边
from sdk.utils.util_folder import FolderProcess
from sdk.utils.util_file import FileProcessclass ZipProcess(object):"""压缩,解压文件"""def __init__(self):""""""self.folder = FolderProcess()self.file = FileProcess()self.format = [".zip", ".rar", ".gz"]def zip(self, zip_name: str, filefolder: str = None, kind: str = "zip"):"""压缩:param zip_name::param filefolder: 支持file/folder:param kind: zip,tar,gztar等:return:"""shutil.make_archive(zip_name, kind, filefolder)def _check_zip_files(self,save_folder):""":param save_folder::return:"""for args in self.folder.get_all_files(save_folder):tail = self.file.get_file_tail(args["file"])if tail in self.format:self.unzip(args["file"], os.sep.join(self.folder.split_path(args["file"])[:-1]))def unzip(self, zip_file: str, save_path: str = "./"):"""解压 原路径结构 中文会出现乱码(原因未知):param zip_file::param save_path:可以不存在:return:"""file_split = self.folder.split_path(zip_file)save_folder = self.folder.merge_path([save_path, file_split[-1].split(".")[0]])self.folder.create_folder(save_folder)file_name = file_split[-1]if zip_file.lower().endswith(".zip"):with ZipFile(zip_file, 'r') as zip_ref:zip_ref.extractall(save_folder)elif zip_file.lower().endswith(".rar"):with rarfile.RarFile(zip_file) as rar_file:rar_file.extractall(save_folder)elif zip_file.lower().endswith(".gz"):with gzip.open(zip_file, 'rb') as gz_file, \open(self.folder.merge_path([save_folder, file_name]), 'wb') as output_file:output_file.write(gz_file.read())else:raise ValueError("不支持的格式:{}".format(zip_file))# 删除已经解压的压缩文件self.folder.remove(zip_file)# 遍历已经解压的压缩包内容,检查嵌套压缩文件继续解压self._check_zip_files(save_folder)
util_folder .py
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC
@file: util_folder.py
@time: 2023/5/28 13:56
@desc:
"""
import os
import traceback
import shutil
from sdk.base.base_temp import Baseclass FolderProcess(Base):""""""def __init__(self):super(FolderProcess, self).__init__()def create_folder(self, path):"""创建文件夹:param _path::return:"""os.makedirs(path, exist_ok=True)def merge_path(self, path_lis):"""合并路径:param path_lis::return:"""if path_lis:return os.path.sep.join(path_lis)def split_path(self, path: str, spliter: str = None):"""拆分路径"""if not spliter:if not path.startswith("http://") or not path.startswith("https://"):return os.path.normpath(path).split(os.sep)else:return os.path.normpath(path).split("/")else:return path.split(spliter)def remove(self, file: str = None, folder: str = None):"""删除文件、文件夹:param file::param folder::return:"""try:if folder:shutil.rmtree(folder)if file:os.remove(file)except Exception as e:print(e, e.__traceback__.tb_lineno)def get_all_files(self, path: str, ext: list = None):"""获取文件夹下所有文件绝对路径:param path::param ext: 后缀列表[".txt",".json",...]:return:"""try:if os.path.exists(path) and os.path.isabs(path):for path, dir_lis, file_lis in os.walk(path):if len(file_lis) > 0:for name in file_lis:if ext:if os.path.splitext(name)[-1] in ext:yield {"name": name,"file": os.path.join(path, name),}else:yield {"name": name,"file": os.path.join(path, name),}except BaseException:print(traceback.format_exc())util_file.py
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC
@file: util_file.py
@time: 2023/5/27 21:25
@desc:
"""
import os
import shutil
import traceback
import chardet
from sdk.base.base_temp import Base
from sdk.utils.util_json import JsonProcessclass FileProcess(Base):"""文件处理类"""def __init__(self):super(FileProcess, self).__init__()self.json = JsonProcess()def get_file_lines(self, file: str, status: int = 1):"""获取文件总行数:param file::param status:0:大文件、1小文件:return:"""if status == 1:return sum(1 for _ in open(file, 'rb'))else:with open(file, 'rb') as f:for count, _ in enumerate(f, 1):passreturn countdef rename_file(self, old: str, new: str):"""重命名文件:param old::param new::return:"""try:if os.path.isfile(old) and not os.path.exists(new):os.renames(old, new)except BaseException:print(traceback.format_exc())def get_file_encode(self, file: str, size=1024 * 1024) -> str:"""获取文件编码:param file::param size::return:"""with open(file, "rb")as fp:fp_bit = fp.read(size)return chardet.detect(fp_bit)["encoding"]def get_file_size(self, file: str, unit: str = "MB") -> str:"""获取文件大小:param file::param unit::return:"""file_size = os.path.getsize(file)if unit == "KB":return str(round(file_size / float(1024), 2)) + " " + unitelif unit == "MB":return str(round(file_size / float(1024 * 1024), 2)) + " " + unitdef get_file_tail(self, file: str):"""获取文件后缀:param file::return:"""return os.path.splitext(file)[-1]def read_yield(self, file: str, headers: list = None,encoding: str = "utf-8", spliter: str = "\t", sheets: list = None, mode="r") -> dict:"""按行读文件:param file::param headers::param encoding::param spliter::param sheets::return:"""with open(file, mode=mode, encoding=encoding)as fp:# 传headers 从第一行开始处理,不传headers默认第一行为headersif not headers:headers = fp.readline().strip().split(spliter)for num, data in enumerate(fp):line = data.strip("\n").split(spliter)yield {"headers": headers,"num": num + 1,"line": line}def read_json_file(self, file: str, encoding: str = "utf-8") -> dict:"""读取json文件:param file::param encoding::return:"""with open(file, "r", encoding=encoding)as fp:return self.json.loads(fp.read())def save(self, file: str, data: dict, mode: str = "w", encoding: str = "utf-8",spliter: str = "\t", indent: int = None, ensure_ascii: bool = False):"""保存文件:param file::param data::param mode::param encoding::param spliter::param indent::param ensure_ascii::return:"""with open(file, mode=mode, encoding=encoding)as fp:tail = self.get_file_tail(file)if data.get("headers") is not None:if tail == ".txt":fp.write("{}\n".format(spliter.join(data["headers"])))for line in data.get("line"):fp.write("{}\n".format(spliter.join(line)))else:if tail == ".json":if isinstance(data["line"], dict):fp.write(self.json.dumps(data["line"]))else:fp.write(self.json.dumps(data["line"]))def split_file(self, file: str, spliter_nums: int = 1000,headers: str = None, encoding: str = "utf-8", spliter="\t") -> dict:"""按行 拆分文件:param file::param spliter_nums::param headers::param encoding::return:"""lis = []with open(file, "r", encoding=encoding)as fp:if not headers:headers = fp.readline().strip().split(spliter)for i in fp:line = i.strip().split(spliter)lis.append(line)if len(lis) == spliter_nums:yield {"headers": headers,"line": lis,}lis.clear()if len(lis) > 0:yield {"headers": headers,"line": lis,}def merge_file(self, file1, file2, headers=None,encoding="utf-8", mode="r"):"""合并文件:param file1:待合并文件:param file2:合并后新文件:param headers::param encoding::param mode::return:"""with open(file2, "a", encoding=encoding)as fp:for args in self.read_yield(file1, headers=headers, encoding=encoding, mode=mode):line = args["line"]fp.write("{}\n".format("\t".join(line)))def move_file(self, old_file, new_file):""":param old_file::param new_file::return:"""shutil.copy(old_file, new_file)base_temp.py
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC
@file: base_temp.py
@time: 2023/5/27 21:07
@desc:
"""class Base(object):""""""def read_yield(self, file: str, headers: list = None,encoding: str = "utf-8", spliter: str = "\t", sheets: list = None) -> dict:"""按行返回:param file::param headers::param encoding::return:"""def save(self, file: str, data: dict, mode: str = "w", encoding: str = "utf-8",spliter: str = "\t", indent: int = None, ensure_ascii: bool = False) -> str:"""保存结果:param file::param data:{'headers': ['', '', ''], 'data': [{"line":1,"data":[]},{"line":2,"data":[]}]} /{'headers': ['', '', ''], 'data': [{"line":1,"data":[{},{}]},{"line":2,"data":["{}","{}"]}]}:param mode::param encoding::return:"""def remove(self, file: str = None, folder: str = None):"""删除文件、文件夹:param file::param folder::return:"""util_json.py
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC
@file: util_json.py
@time: 2023/5/27 22:41
@desc:
"""
import jsonclass JsonProcess():"""json 序列化 反序列化"""def loads(self, data: str) -> dict:"""str - dict:param data::return:"""return json.loads(data, strict=False)def dumps(self, data: dict, indent: None = 4,ensure_ascii: bool = False) -> str:"""dict-str:param data::param indent::param ensure_ascii::return:"""return json.dumps(data, indent=indent, ensure_ascii=ensure_ascii)相关文章:

Python压缩、解压文件
#!/usr/bin/python3 # -*- coding:utf-8 -*- """ author: JHC file: util_compress.py time: 2023/5/28 14:58 desc: rarfile 使用需要安装 rarfile 和 unrar 并且将 unrar.exe 复制到venv/Scrpits目录下 (从WinRar安装目录下白嫖的) 下载…...

面试就是这么简单,offer拿到手软(一)—— 常见非技术问题回答思路
面试系列: 面试就是这么简单,offer拿到手软(一)—— 常见非技术问题回答思路 面试就是这么简单,offer拿到手软(二)—— 常见65道非技术面试问题 文章目录 一、前言二、常见面试问题回答思路问…...
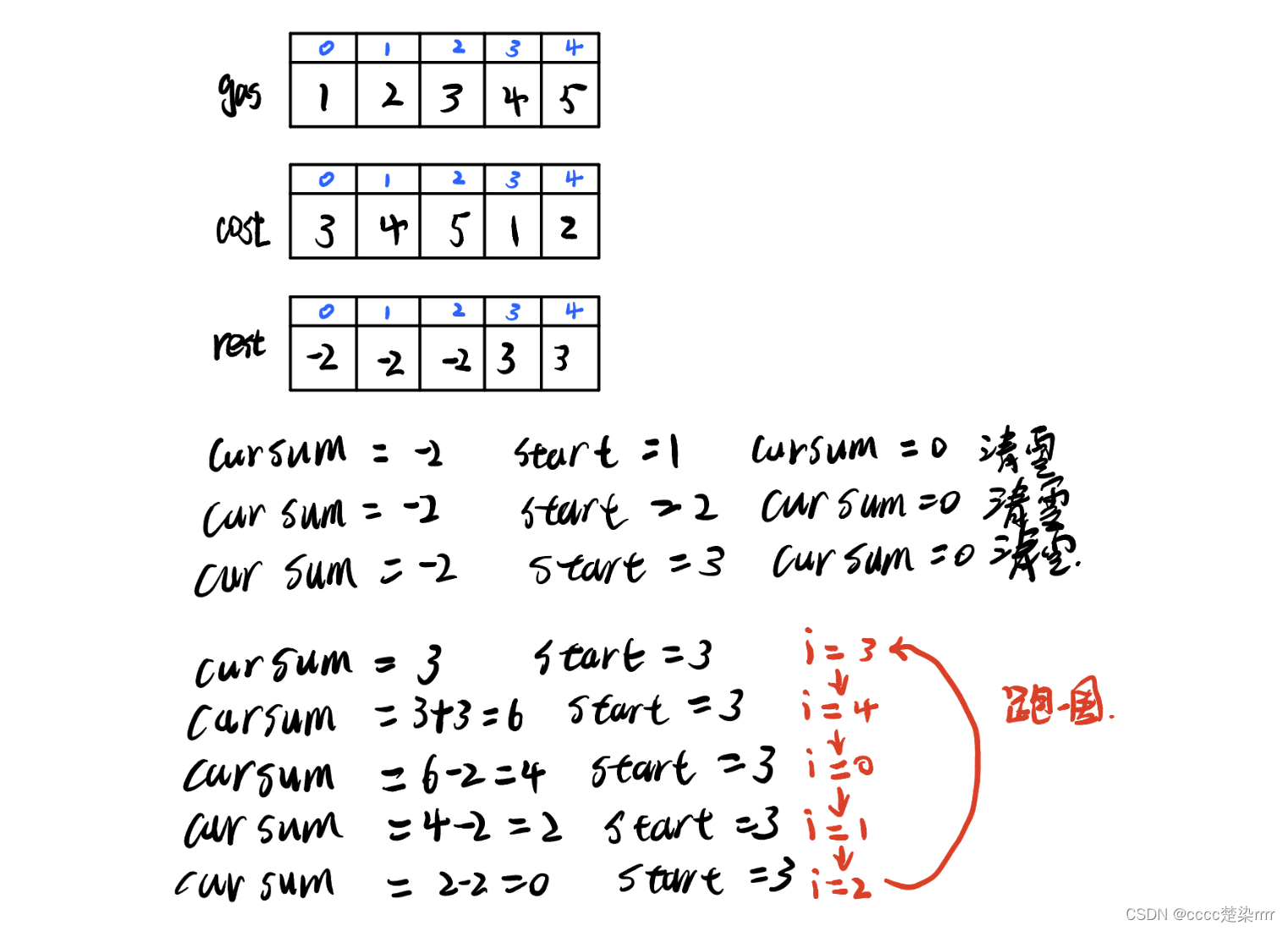
134. 加油站(贪心算法)
根据题解 这道题使用贪心算法,找到当前可解决问题的状态即可 「贪心算法」的问题需要满足的条件: 最优子结构:规模较大的问题的解由规模较小的子问题的解组成,规模较大的问题的解只由其中一个规模较小的子问题的解决定ÿ…...
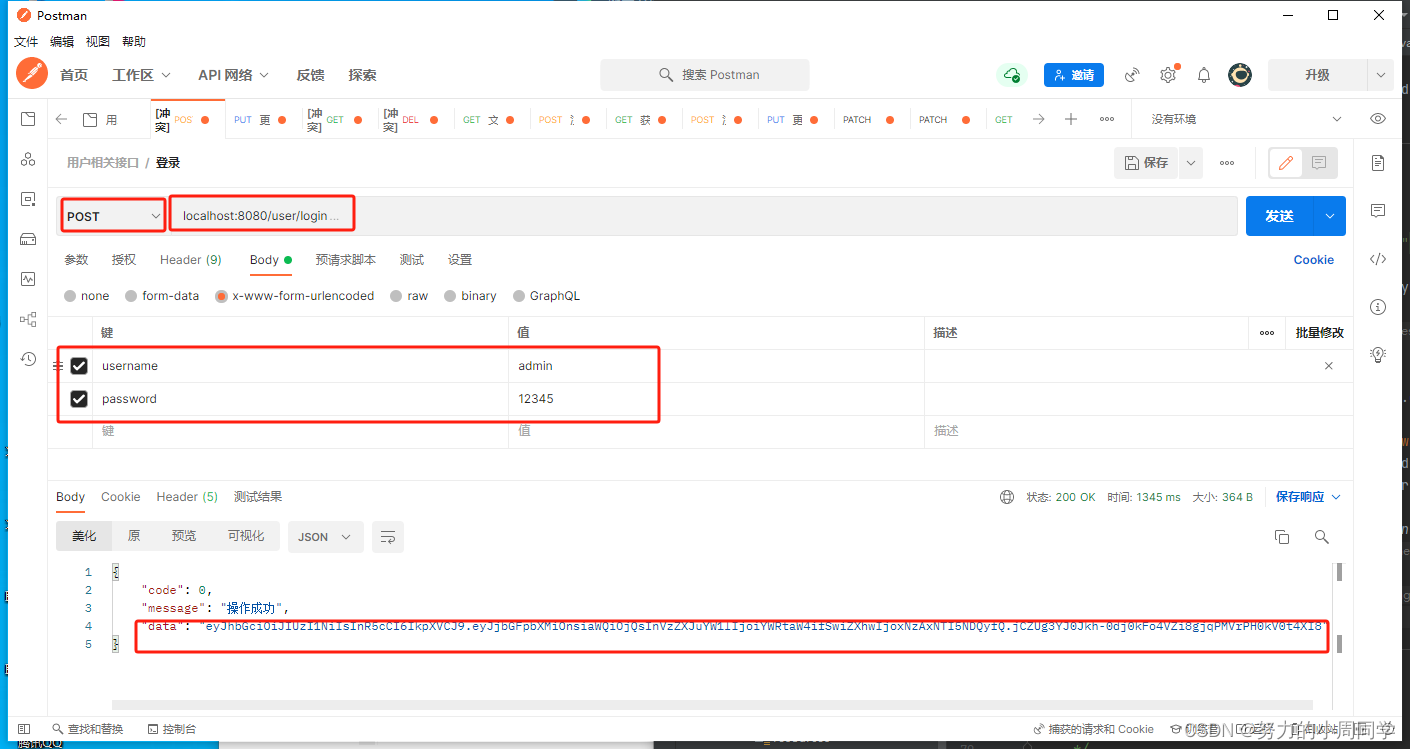
Springboot3+vue3从0到1开发实战项目(二)
前面完成了注册功能这次就来写登录功能, 还是按照这个方式来 明确需求: 登录接口 前置工作 : 想象一下登录界面(随便在百度上找一张) 看前端的能力咋样了, 现在我们不管后端看要什么参数就好 阅读接口文档…...

Spring中Bean的生命周期
1.生命周期 Spring应用中容器管理了我们每一个bean的生命周期,为了保证系统的可扩展性,同时为用户提供自定义的能力,Spring提供了大量的扩展点。完整的Spring生命周期如下图所示,绿色背景的节点是ApplictionContext生命周期特有的…...

IndexOutOfBoundsException: Index: 2048, Size: 2048] Controller接收对象集合长度超过2048错误
完整异常信息: org.apache.catalina.core.StandardWrapperValve.invoke Servlet.service() for servlet [spring] in context with path [/jsgc] threw exception [Request processing failed; nested exception is org.springframework.beans.InvalidPropertyExce…...
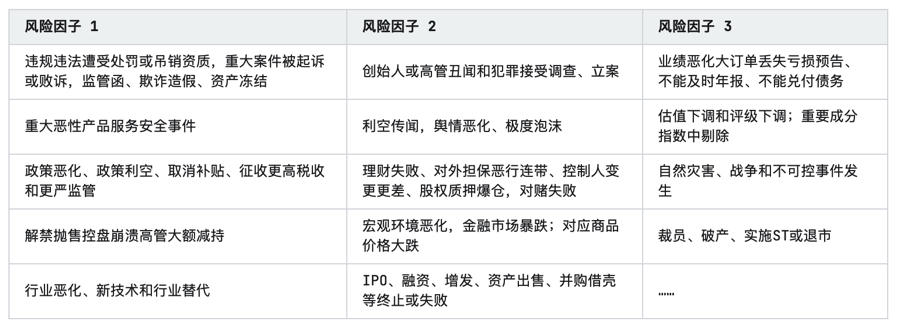
2023年中国消费金融行业研究报告
第一章 行业概况 1.1 定义 中国消费金融行业,作为国家金融体系的重要组成部分,旨在为消费者提供多样化的金融产品和服务,以满足其消费需求。这一行业包括银行、消费金融公司、小额贷款公司等多种金融机构,涵盖了包括消费贷款在内…...
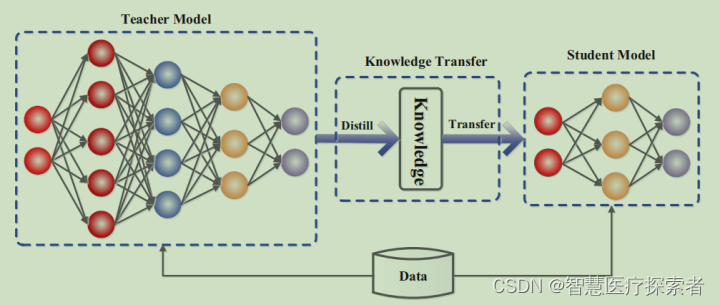
深度学习:什么是知识蒸馏(Knowledge Distillation)
1 概况 1.1 定义 知识蒸馏(Knowledge Distillation)是一种深度学习技术,旨在将一个复杂模型(通常称为“教师模型”)的知识转移到一个更简单、更小的模型(称为“学生模型”)中。这一技术由Hint…...
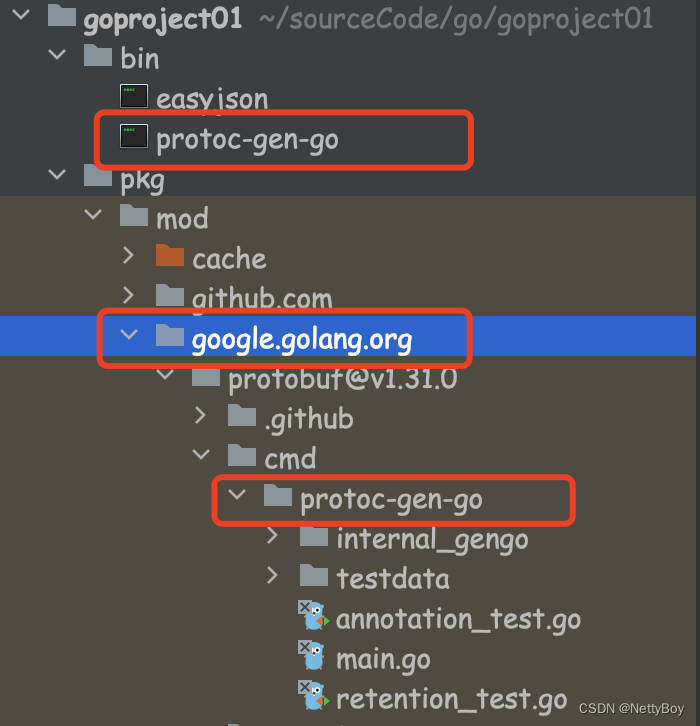
【Go】protobuf介绍及安装
目录 一、Protobuf介绍 1.Protobuf用来做什么 2. Protobuf的序列化与反序列化 3. Protobuf的优点和缺点 4. RPC介绍 <1>文档规范 <2>消息编码 <3>传输协议 <4>传输性能 <5>传输形式 <6>浏览器的支持度 <7>消息的可读性和…...
)
c语言编程题经典100例——(41~45例)
1,实现动态内存分配。 在C语言中,动态内存分配使用malloc、calloc、realloc和free函数。以下是一个示例: #include <stdio.h> #include <stdlib.h> int main() { int *ptr NULL; // 初始化为空 int n 5; // 假设我们想要分配5个整数…...

计算机毕业设计|基于SpringBoot+MyBatis框架健身房管理系统的设计与实现
计算机毕业设计|基于SpringBootMyBatis框架的健身房管理系统的设计与实现 摘 要:本文基于Spring Boot和MyBatis框架,设计并实现了一款综合功能强大的健身房管理系统。该系统涵盖了会员卡查询、会员管理、员工管理、器材管理以及课程管理等核心功能,并且…...

java学习part27线程死锁
基本就是操作系统的内容 138-多线程-线程安全的懒汉式_死锁_ReentrantLock的使用_哔哩哔哩_bilibili...
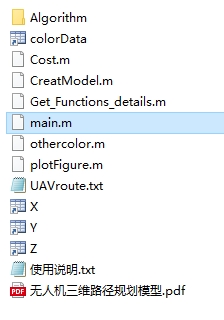
(二)Tiki-taka算法(TTA)求解无人机三维路径规划研究(MATLAB)
一、无人机模型简介: 单个无人机三维路径规划问题及其建模_IT猿手的博客-CSDN博客 参考文献: [1]胡观凯,钟建华,李永正,黎万洪.基于IPSO-GA算法的无人机三维路径规划[J].现代电子技术,2023,46(07):115-120 二、Tiki-taka算法(TTA…...
区间预测 | Matlab实现BP-KDE的BP神经网络结合核密度估计多变量时序区间预测
区间预测 | Matlab实现BP-KDE的BP神经网络结合核密度估计多变量时序区间预测 目录 区间预测 | Matlab实现BP-KDE的BP神经网络结合核密度估计多变量时序区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.BP-KDE多变量时间序列区间预测,基于BP神经网络多…...

LD_PRELOAD劫持、ngixn临时文件、无需临时文件rce
LD_PRELOAD劫持 <1> LD_PRELOAD简介 LD_PRELOAD 是linux下的一个环境变量。用于动态链接库的加载,在动态链接库的过程中他的优先级是最高的。类似于 .user.ini 中的 auto_prepend_file,那么我们就可以在自己定义的动态链接库中装入恶意函数。 也…...

循环神经网络训练情感分析
文章目录 1 循环神经网络训练情感分析2 完整代码3 代码详解 1 循环神经网络训练情感分析 下面介绍如何使用长短记忆模型(LSTM)处理情感分类LSTM模型是循环神经网络的一种,按照时间顺序,把信息进行有效的整合,有的信息…...
如何绕过某讯手游保护系统并从内存中获取Unity3D引擎的Dll文件
某讯的手游保护系统用的都是一套,在其官宣的手游加固功能中有一项宣传是对比较热门的Unity3d引擎的手游保护方案,其中对Dll文件的保护介绍如下, “Dll加固混淆针对Unity游戏,对Dll模块的变量名、函数名、类名进行加密混淆处理&…...
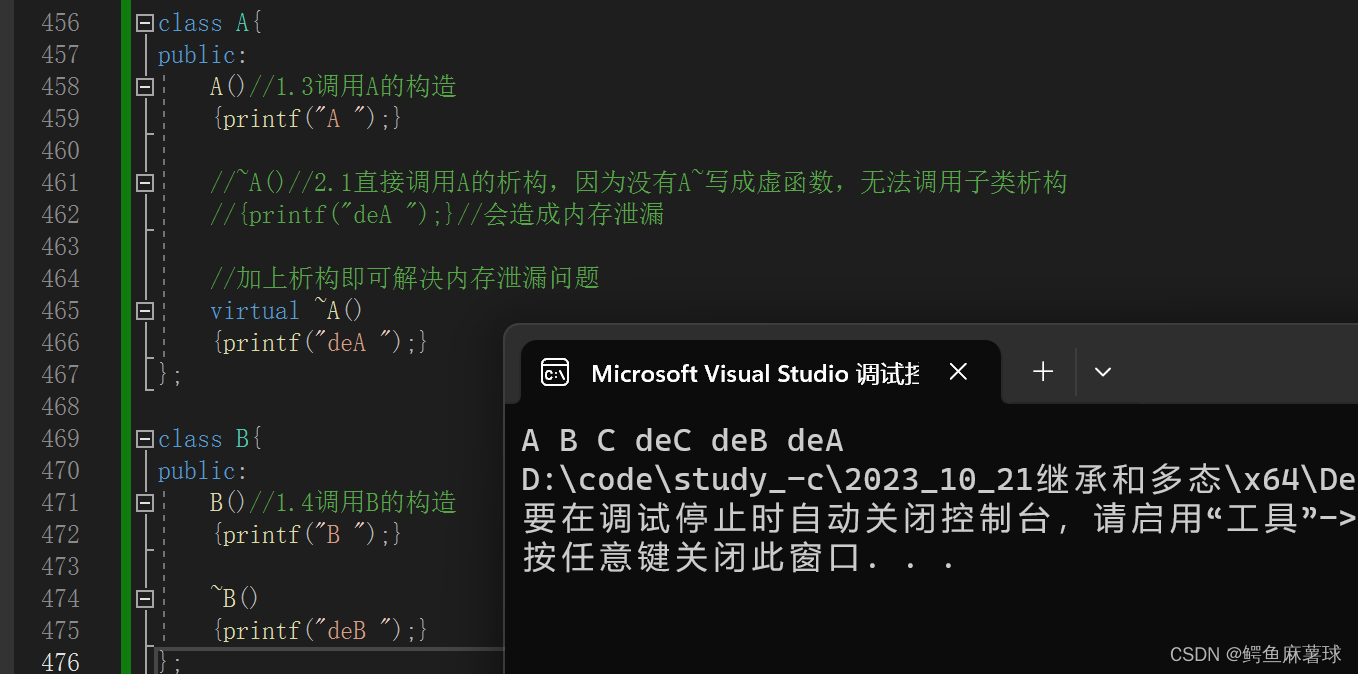
【C/C++笔试练习】公有派生、构造函数内不执行多态、抽象类和纯虚函数、多态中的缺省值、虚函数的描述、纯虚函数的声明、查找输入整数二进制中1的个数、手套
文章目录 C/C笔试练习选择部分(1)公有派生(2)构造函数内不执行多态(3)抽象类和纯虚函数(4)多态中的缺省值(5)程序分析(6)重载和隐藏&a…...
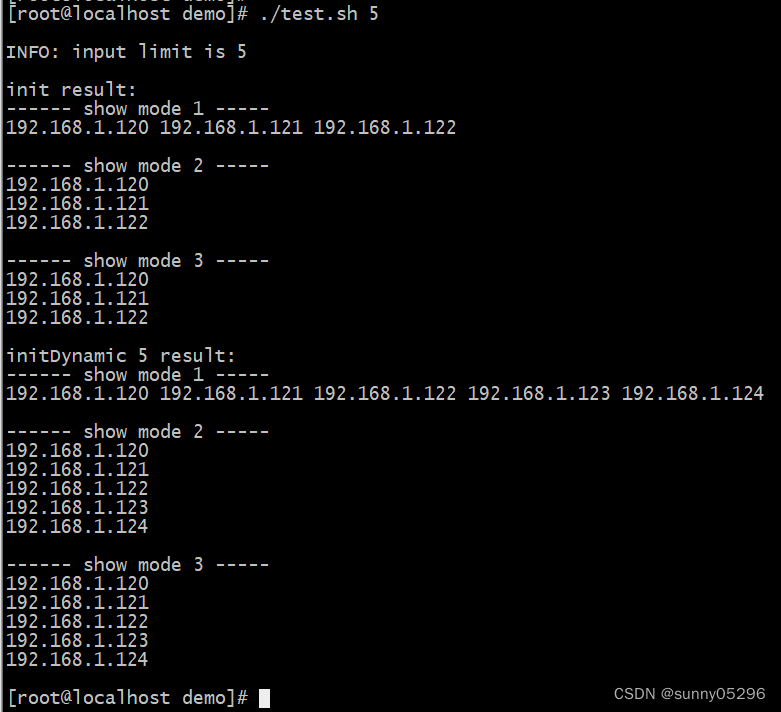
Linux shell中的函数定义、传参和调用
Linux shell中的函数定义、传参和调用: 函数定义语法: [ function ] functionName [()] { } 示例: #!/bin/bash# get limit if [ $# -eq 1 ] && [ $1 -gt 0 ]; thenlimit$1echo -e "\nINFO: input limit is $limit" e…...

YoloV8改进策略:基于RevCol,可逆的柱状神经网络的完美迁移,YoloV8的上分利器
文章目录 摘要论文:《RevCol:可逆的柱状神经网络》1、简介2、方法2.1、Multi-LeVEl ReVERsible Unit2.2、可逆列架构2.2.1、MACRo设计2.2.2、MicRo 设计2.3、中间监督3、实验部分3.1、图像分类3.2、目标检测3.3、语义分割3.4、与SOTA基础模型的系统级比较3.5、更多分析实验&l…...

新手零基础入门:用快马ai生成你的第一个arduino流水灯程序
作为一个刚接触Arduino的新手,我最近在InsCode(快马)平台上完成了第一个LED流水灯项目。整个过程比我预想的顺利很多,特别适合零基础的朋友入门体验。下面分享我的学习过程和几点实用心得: 硬件准备其实很简单 只需要一块Arduino UNO开发板和…...

社区医院信息平台信息管理系统源码-SpringBoot后端+Vue前端+MySQL【可直接运行】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着信息技术的快速发展,医疗行业对信息化管理的需求日益增长。传统的社区医院管理模式存在信息孤岛、数据冗余、效率低下等问题&#…...

BetterJoy解决Switch手柄PC适配难题:高效无缝的全场景控制器解决方案
BetterJoy解决Switch手柄PC适配难题:高效无缝的全场景控制器解决方案 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https:…...

远程工作事故树:一次误删库引发的跨国追责
远程协作下的“脆弱”系统深夜,伦敦办公室的数据库工程师在连续工作十二小时后,敲下了一条他以为指向“测试环境”的删除命令。与此同时,上海的测试团队正在为次日的上线进行最后一轮回归验证。六小时后,当阳光照进浦东的办公室&a…...

国内顶级的SEO技术网站有哪些
国内顶级的SEO技术网站有哪些? 在当今互联网时代,搜索引擎优化(SEO)已经成为每个网站营销者不可忽视的重要环节。国内顶级的SEO技术网站不仅为业内人士提供了宝贵的技术分享和实践经验,还为企业的网站流量优化提供了有…...
实测)
Phi-3-mini-4k-instruct-gguf惊艳生成效果:5类中文任务(问答/改写/总结/建议/介绍)实测
Phi-3-mini-4k-instruct-gguf惊艳生成效果:5类中文任务实测 1. 模型介绍与测试背景 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本。这个模型特别适合处理中文的问答、文本改写、摘要整理和简短创作等任务。相比大型语言模型&#x…...

OpenClaw替代方案:Qwen2.5-VL-7B与其他自动化工具对比
OpenClaw替代方案:Qwen2.5-VL-7B与其他自动化工具对比 1. 自动化工具选型的核心考量 当我们需要选择一款自动化工具时,通常会面临几个关键问题:这个工具能否理解我的需求?它能在我的设备上安全运行吗?它是否足够灵活…...

OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同
OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同 1. 为什么需要移动审批电子合同? 上周三我在高铁上收到法务同事的紧急消息:"有个供应商合同今天必须签完,但关键条款需要你确认"。当时手边既没电脑也…...

STM32串口发送字符串的底层机制与优化实践
1. STM32串口发送字符串的底层机制解析在嵌入式开发中,USART(通用同步异步收发传输器)是最常用的外设之一。当我们需要通过串口发送字符串时,实际上是将数据写入发送数据寄存器(TDR),然后由硬件…...

OpenClaw飞书机器人配置指南:Qwen3-14b_int4_awq实现对话触发任务
OpenClaw飞书机器人配置指南:Qwen3-14b_int4_awq实现对话触发任务 1. 为什么选择OpenClaw飞书机器人组合? 去年我接手了一个小团队的内部工具优化项目,需要解决两个核心痛点:一是团队成员频繁在飞书群内重复询问相同问题&#x…...