【C语言:数据在内存中的存储】
文章目录
- 1.整数在内存中的存储
- 1.1整数在内存中的存储
- 1.2整型提升
- 2.大小端字节序
- 2.1什么是大小端
- 2.2为什么有大小端之分
- 3.整数在内存中的存储相关题目
- 题目一
- 题目二
- 题目三
- 题目四
- 题目五
- 题目六
- 题目七
- 4.浮点数在内存中的存储
- 4.1浮点数存的过程
- 4.2浮点数取得过程

在这之前呢,我们已经学习了C语言的很多知识了,可是你是否有过这样的疑问?
- 各种类型的数据在内存中是如何存储的?
- 有的数据为何在内存中是反着放的?能正着放吗?
- 为什么有的浮点数不是自己想要的?
带着这些问题,我们来看下面的内容:
1.整数在内存中的存储
1.1整数在内存中的存储
我们都知道,整数在内存中是以二进制的形式存储的,但具体是怎么存的?
- 整数的2进制表示方法有三种,即原码、反码和补码。
- 三种表示方法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,最⾼的⼀位是被当做符号位,剩余的都是数值位。
- 正整数的原、反、补码都相同。
- 负整数的三种表示方法各不相同。
- 原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。
- 反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
- 补码:符号位不变,其它位按位取反,再+1就得到补码。
对于整形来说:数据在内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。
原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
1.2整型提升
数据的二进制表示形式在内存中是要存够32个比特位的,那么对于char、short类型的数据在内存中又是如何存储的呢?答案是:整型提升
C语言中整型算术运算总是⾄少以缺省整型类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
- 表达式的整型运算要在CPU的相应运算器件内执⾏,CPU内整型运算器(ALU)的操作数的字节⻓度⼀般就是int的字节⻓度,同时也是CPU的通⽤寄存器的⻓度。因此,即使两个char类型的相加,在CPU执⾏时实际上也要先转换为CPU内整型操作数的标准⻓度。
- 通⽤CPU(general-purposeCPU)是难以直接实现两个8⽐特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种⻓度可能⼩于int⻓度的整型值,都必须先转换为int或unsignedint,然后才能送⼊CPU去执⾏运算。
char a,b,c;
//.......
a = b + c;
在这一过程中,b和c先被提升为普通整型,然后再进行运算
加法运算执行完成后,此时先会发生截断,再存储到a中。
那么如何进行整型提升呢?
有符号整数提升是按照变量的数据类型的符号位来提升的⽆符号整数提升,⾼位补0
- 负数的整形提升
char c1 = -1;
1000001 -原码
11111110 -反码
11111111 -补码
变量c1的⼆进制位(补码)中只有8个⽐特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,⾼位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
- 正数的整形提升
char c2 = 1;
00000001 -原码、反码、补码
变量c2的⼆进制位(补码)中只有8个⽐特位:
00000001
因为 char 为有符号的
char 所以整形提升的时候,⾼位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//⽆符号整形提升,⾼位补0
2.大小端字节序
2.1什么是大小端
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
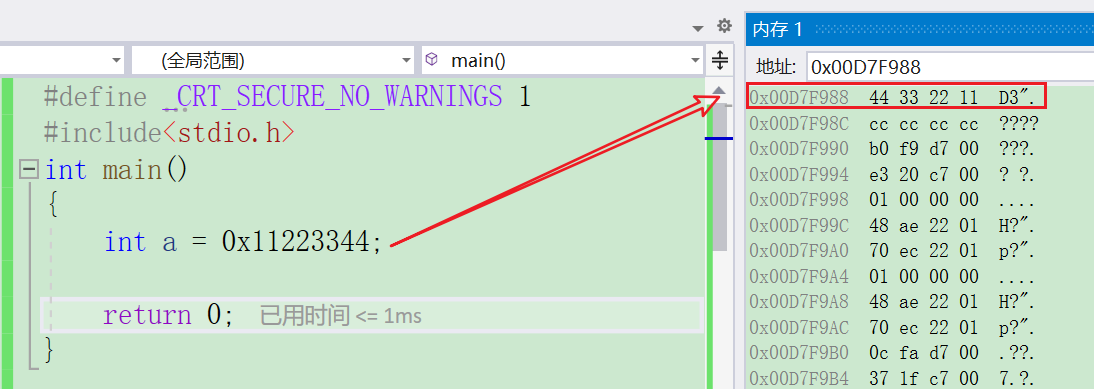
调试的时候,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为什么呢?
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为⼤端字节序存储和⼩端字节序存储,下⾯是具体的概念:
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存在内存的低地址处。
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存在内存的⾼地址处。
2.2为什么有大小端之分
那为什么会有大小端之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8bit 位,但是在C语言中除了8 bit 的char 之外,还有16 bit 的 short 型,32 bit 的 long 型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么0x11 为⾼字节, 0x22 为低字节。
- 对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在⾼地址中,即 0x0011 中。
- ⼩端模式, 0x11 放在高地址中,即 0x0011 中,0x22 放在低地址中,即 0x0010 中。
- 我们常⽤的 X86 结构是⼩端模式,⽽KEIL C51则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是⼤端模式还是⼩端模式。
下面给出一道真题:
设计⼀个⼩程序来判断当前机器的字节序。(10分)
#include <stdio.h>
int check_sys()
{int i = 1;return (*(char*)&i);//char 类型之访问一个字节
}
int main()
{int ret = check_sys();if (ret == 1){printf("⼩端\n");}else{printf("⼤端\n");}return 0;
}
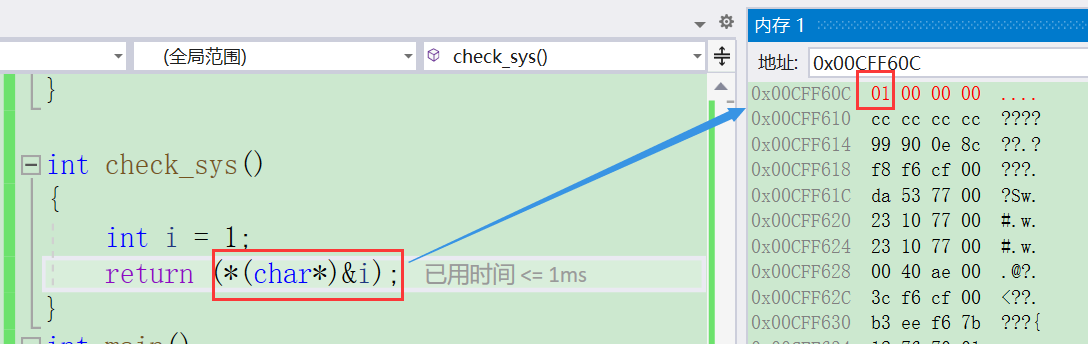
当前使用的VS编译器,正是小端存储。
当学习了共用体的知识后,还可以这样来设计,是不是很巧妙呀。
int check_sys()
{union{int i;char c;}un;un.i = 1;return un.c;
}
3.整数在内存中的存储相关题目
题目一
int main()
{//10000000000000000000000000000001 -1的原码//11111111111111111111111111111110 反码//11111111111111111111111111111111 补码//放进char类型数中,发生截断//仅保留后8位char a = -1;//a : 11111111//发生整型提升,有符号数,按符号位提升//11111111111111111111111111111111 --补码//10000000000000000000000000000001 -- 原码signed char b = -1;//b : 11111111//发生整型提升,有符号数,按符号位提升//11111111111111111111111111111111 --补码//10000000000000000000000000000001 -- 原码unsigned char c = -1;//c : 11111111//发生整型提升,无符号数,补0//00000000000000000000000011111111 -- 补码 == 原码printf("a=%d,b=%d,c=%d", a, b, c); //%d,十进制形式打印有符号整数,会发生整型提升//a=-1,b=-1,c=255return 0;
}
题目二
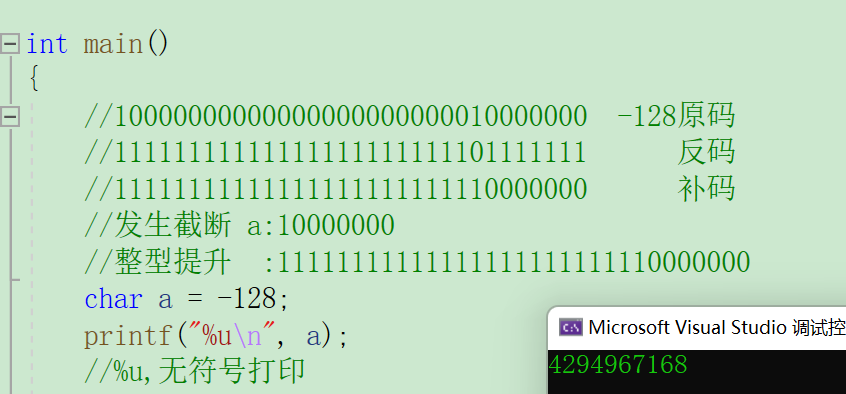
int main()
{char a = -128;printf("%u\n",a);return 0;
}
在做题之前,我们要知道-128能放进一个char类型的数中吗?

从图中,我们可以清楚的看出char类型的取值范围,因此,a中可以放下、
题目三
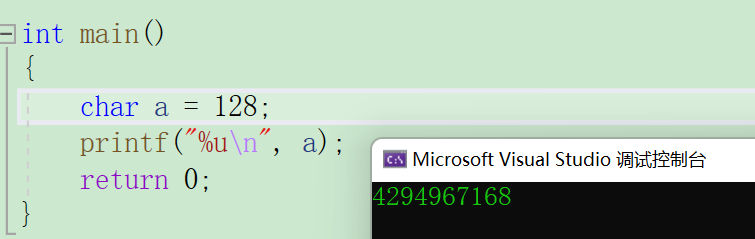
int main()
{char a = 128;printf("%u\n", a);return 0;
}
在这里,我们知道char类型的取值范围是 -123~ 127 ,是存不下128的,存到127再加1就变成了-128,那和上一题的结果就一样了。
题目四
此题注意:\0的ascll码值就是0
int main()
{char a[1000];int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;}//a: -1,-2,-3...-128 127,126,125....3,2,1,0//共255个数printf("%d", strlen(a));return 0;
}
题目五
此题,注意变量 i 的值是无符号char ,范围是 0 ~ 255,那就打印255个hello world ?
255+1 = 0 又变回去了,因此此处是死循环
unsigned char i = 0;
int main()
{for(i = 0;i<=255;i++){printf("hello world\n");}return 0;
}
题目六
int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);}return 0;
}
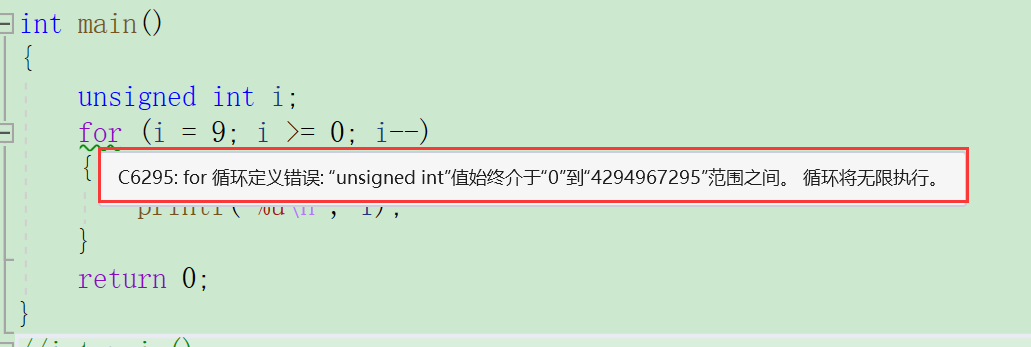
题目七
int main()
{int a[4] = { 1, 2, 3, 4 };int* ptr1 = (int*)(&a + 1);int* ptr2 = (int*)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);//4,2000000return 0;
}

4.浮点数在内存中的存储
先看以下这个题目
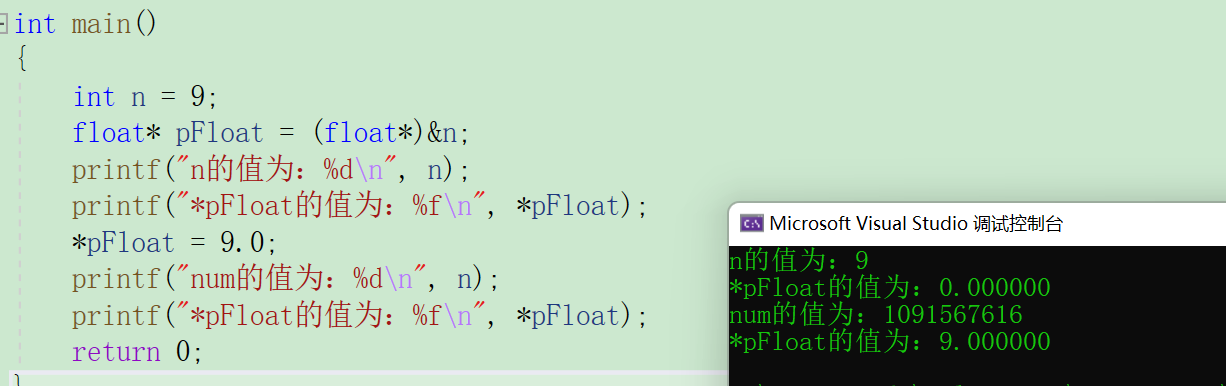
我们发现结果跟我们想的并不一样,原因是什么呢?
上⾯的代码中, num 和 *pFloat 在内存中明明是同⼀个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,⼀定要搞懂浮点数在计算机内部的表⽰⽅法。
根据国际标准IEEE(电气和电⼦工程协会)754,任意⼀个⼆进制浮点数V可以表示成下⾯的形式:
V = (−1) S ∗ M∗ 2E
- (−1)S 表⽰符号位,当S=0,V为正数;当S=1,V为负数
- M 表⽰有效数字,M是⼤于等于1,⼩于2的
- 2E表⽰指数位
举例来说:
⼗进制的5.0,写成⼆进制是 101.0 ,相当于 1.01×22 。
那么,按照上⾯V的格式,可以得出S=0,M=1.01,E=2。
⼗进制的-5.0,写成⼆进制是 -101.0 ,相当于 -1.01×22 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M
对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

4.1浮点数存的过程
IEEE 754 对有效数字M和指数E,还有⼀些特别规定:
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表⽰⼩数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的xxxxxx部分。⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的⽬的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去以后,等于可以保存24位有效数字,更加精确。
至于指数E,情况就比较复杂:
⾸先,E为⼀个⽆符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0 ~ 255;如果E为11位,它的取值范围为0~2047。
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
⽐如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
4.2浮点数取得过程
指数E从内存中取出还可以再分成三种情况:
- E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表示:
即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。
⽐如:0.5 的⼆进制形式为0.1,由于规定正数部分必须为1,即将⼩数点右移1位,则为1.0*2^(-1),其E为-1+127(中间值)=126,表⽰为01111110,⽽尾数1.0去掉整数部分为0,补⻬0到23位00000000000000000000000,则其⼆进制表⽰形式为
:0 01111110 00000000000000000000000
- E全为0
这样意味着什么?我加了一个127之后,还为0,那么你原来得值就是 -127
那就是:(-1)s *M * 2 -127 ,-127次方,这都多小了
那这时怎么办呢?浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字
- E全为1
这样意味着什么?我加了一个127之后,为255,那么你原来得值就是 128
那就是:(-1)s *M * 2 128 ,128次方,这得多大呀
这是,就表⽰±⽆穷⼤(正负取决于符号位s);
了解了浮点数得存储规则后,我们再回到题目中。
为什么 9 还原成浮点数,就成了 0.000000呢?

浮点数9.0,为什么整数打印是1091567616?


现在我们是不是就弄清楚缘由了呀!
结论
- 部分浮点数在内存中是无法精确保存的
- double类型的精度比float高
- 浮点数比较大小的时候,不能直接使用 ,应该给一个精度(一个范围)
相关文章:
【C语言:数据在内存中的存储】
文章目录 1.整数在内存中的存储1.1整数在内存中的存储1.2整型提升 2.大小端字节序2.1什么是大小端2.2为什么有大小端之分 3.整数在内存中的存储相关题目题目一题目二题目三题目四题目五题目六题目七 4.浮点数在内存中的存储4.1浮点数存的过程4.2浮点数取得过程 在这之前呢&…...

每日一练:阿姆斯特朗数
如果一个 n 位正整数等于其各位数字的 n 次方之和,则称该数为阿姆斯特朗数。 例如 1^3 5^3 3^3 153。 1000 以内的阿姆斯特朗数: 1, 2, 3, 4, 5, 6, 7, 8, 9, 153, 370, 371, 407。...
)
fatal: remote error: upload-pack: not our ref (未解决问题)
PX4使用 git submodule update --init --recursive报错 fatal: remote error: upload-pack: not our ref解决办法参考:https://stackoverflow.com/questions/61163082/why-does-git-submodule-update-fail-with-fatal-remote-error-upload-pack-not-o 感觉就是清…...
、readline()、readlines() 函数 读取文件)
Python 3 使用 read()、readline()、readlines() 函数 读取文件
1 样例文件 example.txt 春晓 孟浩然〔唐代〕 春眠不觉晓,处处闻啼鸟。 夜来风雨声,花落知多少。 2 分别使用 read()、readline()、readlines() 函数 2.1 # read() -------- 一次性读取所有文本,以字符串的形式返回结果。 # read() ----…...
勒索解密后oracle无法启动故障处理----惜分飞
客户linux平台被勒索病毒加密,其中有oracle数据库.客户联系黑客进行解密【勒索解密oracle失败】,但是数据库无法正常启动,dbv检查数据库文件报错 [oraclehisdb ~]$ dbv filesystem01.dbf DBVERIFY: Release 11.2.0.1.0 - Production on 星期一 11月 27 21:49:17 2023 Copyrig…...
Leetcode144. 二叉树的前序遍历-C语言
文章目录 题目介绍题目分析解题思路1.创建一个数组来储存二叉树节点的值2.根据二叉树的大小来开辟数组的大小3.边前序遍历边向创建的数组中存入二叉树节点的值 完整代码 题目介绍 题目分析 题目要求我们输出二叉树按前序遍历排列的每个节点的值。 解题思路 1.创建一个数组来…...

dmesg命令在软件测试中的实际应用
简介:当你想要了解 Linux 系统在启动时究竟发生了什么?或者当硬件设备不工作时,如何进行调试?这就是 dmesg 命令的用武之地。本文将介绍 dmesg 的基本功能,并深入探讨其在软件测试中的实际应用。 历史攻略:…...

【渗透】记录阿里云CentOS一次ddos攻击
文章目录 发现防御 发现 防御 流量清洗 使用高防...
)
前端面试提问(3)
1、js两个数相加会不会丢精度? 可能会遇到精度丢失的问题。JavaScript 使用的是 IEEE 754 浮点数标准,即一种二进制表示法,有时不能准确地表示十进制小数。如果你需要进行精确的十进制数值计算,可以使用一些处理精确数值的库&…...
fl studio21.2最新汉化中文完整版网盘下载
fl studio 21中文版是Image-Line公司继20版本之后更新的水果音乐制作软件,很多用户不太理解,为什么新版本不叫fl studio 21或fl studio2024,非得直接跳到21.2版本,其实该版本是为了纪念该公司22周年,所以该版本也是推出…...

差分数组相关知识点以及刷题
差分数组 差分数组是什么? **举例:**对于数组考虑数组 a[1,3,3,5,8],对其中的相邻元素两两作差(右边减左边),得到数组 [2,0,2,3]。然后在开头补上 a[0],得到差分数组: d[1,2,0…...
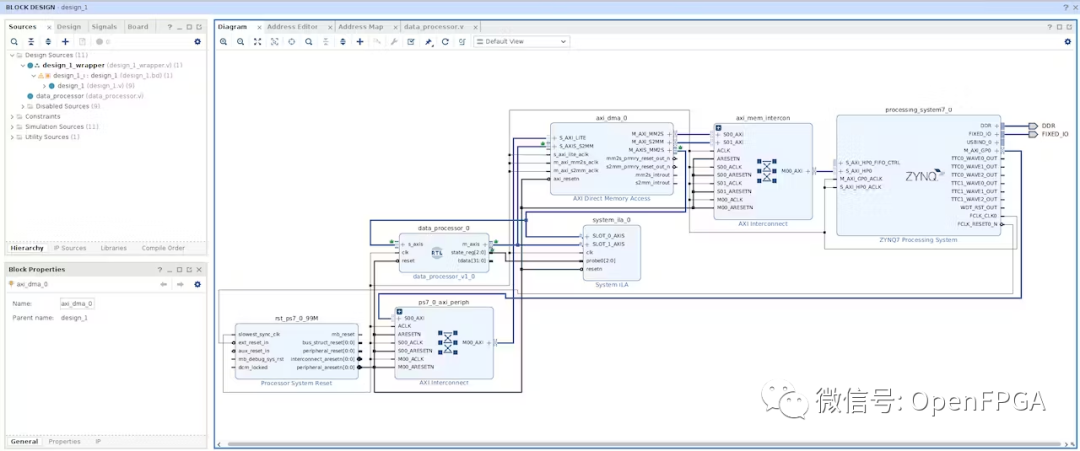
使用 DMA 在 FPGA 中的 HDL 和嵌入式 C 之间传输数据
使用 DMA 在 FPGA 中的 HDL 和嵌入式 C 之间传输数据 该项目介绍了如何在 PL 中的 HDL 与 FPGA 中的处理器上运行的嵌入式 C 之间传输数据的基本结构。 介绍 鉴于机器学习和人工智能等应用的 FPGA 设计中硬件加速的兴起,现在是剥开几层“云雾”并讨论 HDL 之间来回传…...

uniapp地图基本使用及解决添加markers不生效问题?
uniapp地图使用 App端 通过 nvue 页面实现地图 文章目录 uniapp地图使用效果图templatejs添加 marker使用地图查看位置移到到当前位置 效果图 template <template><view class"mapWrap"><!-- #ifdef APP-NVUE --><map class"map-containe…...
使用系统ProgressBar实现三色进度条
使用系统ProgressBar实现如图三色进度条: //布局中<ProgressBarandroid:layout_width"0dp"android:layout_height"8dp"android:layout_marginLeft"16dp"app:layout_constraintBottom_toBottomOf"id/photo"app:layout_c…...

Vue3中的组合式API的详细教程和介绍
文章目录 前言介绍组合式 API 基础setup 组件选项 带 ref 的响应式变量生命周期钩子注册内部 setupwatch 响应式更改独立的 computed 属性后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:vue.js 🐱👓博主在前端…...
Java后端开发——JDBC(万字详解)
Java后端开发——JDBC(万字详解) 今日目标 掌握JDBC的的CRUD理解JDBC中各个对象的作用掌握Druid的使用 1,JDBC概述 在开发中我们使用的是java语言,那么势必要通过java语言操作数据库中的数据。这就是接下来要学习的JDBC。 1.1 …...
python etree.HTML 以及xpath 解析网页的工具
文章目录 导入模块相关语法实战 导入模块 from lxml import etree相关语法 XPath(XML Path Language)是一种用于在XML文档中定位和选择元素的语言。XPath的主要应用领域是在XML文档中进行导航和查询,通常用于在XML中选择节点或节点集合。以…...
待编辑)
电机伺服驱动学习笔记(7)待编辑
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

【云备份】业务处理
文章目录 1. 业务处理作用功能 2. 代码框架编写构造函数UpLoad ——文件上传请求ListShow —— 展示页面请求处理实现Download —— 下载请求的处理实现断点续传实现 1. 业务处理 作用 业务处理模块是对客户端的业务请求进行处理 功能 1.文件上传请求:备份客户端…...
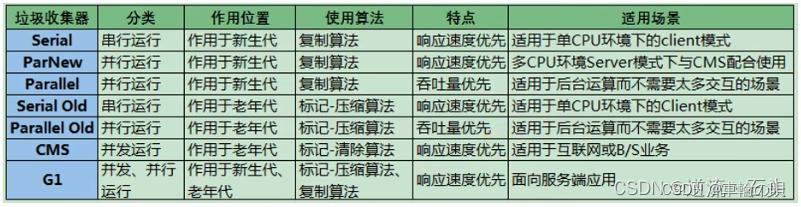
JVM GC算法
一, 垃圾回收分类: 按线程数分,可以分为串行垃圾回收器和并行垃圾回收器。 按工作模式分,可以分为并发垃圾回收器和独占式垃圾回收器 按碎片处理方式分,可以分为压缩式垃圾回收器和非压缩式垃圾回收器按工作的内存区间分,又可分为…...

cv_resnet18_ocr-detection保姆级教程:从安装到批量处理图片文字
cv_resnet18_ocr-detection保姆级教程:从安装到批量处理图片文字 1. 快速上手:5分钟搞定OCR文字检测 你是不是经常需要从图片里提取文字?比如整理扫描的文档、识别截图里的信息,或者处理一堆商品图片上的标签。手动打字太慢&…...

OpenClaw压力测试:Qwen3-14B持续运行24小时稳定性报告
OpenClaw压力测试:Qwen3-14B持续运行24小时稳定性报告 1. 测试背景与目标 上周在尝试用OpenClaw自动处理一批PDF文档时,遇到了一个奇怪的现象:连续运行4小时后,系统响应速度明显下降,甚至出现了几次任务中断。这让我…...

依赖p4est库的程序windows运行方法----支持vs2022调试
一.前置环境 1.vs2022且包含CLangCL工具集,没有安的在vs的intaller里边修改已安装的vs2022,在右侧目录里勾选上(使用c进行桌面开发/适用于windows的CClang工具)。 2.安装MS-MPI,安在默认位置即可(https://www.micros…...

DHL集团与中国外运将进一步深化全球业务协同
、美通社消息:近日,DHL集团与中国外运正式签署谅解备忘录。双方宣布,将在过往坚实合作的基础上,进一步深化全球业务协同,共同开启新一轮战略对话与长远布局。此次签约正值双方合资公司——中外运敦豪成立四十周年。作为…...

04_RAGFlow之知识图谱与Text2SQL
RAGFlow之知识图谱与Text2SQL:构建智能检索的双引擎 知识体系结构 RAGFlow技术栈 │ ├── 知识图谱层 │ ├── 实体识别与关系提取(NER Relation Extraction) │ ├── 图谱查询与推理(Graph Query & Reasoning&a…...

LLaMA3核心技术深度拆解:从架构革新到高效训练的实战密码
1. LLaMA3的架构革新:为什么这些设计能改变游戏规则 当Meta发布LLaMA3时,最让我惊讶的不是参数规模,而是那些看似微小的架构调整带来的巨大性能提升。作为经历过BERT到GPT-3时代的老兵,我见证过太多"暴力堆参数"的失败案…...

4.1第一次练习作业
1.在root用户的主目录下创建两个目录分别为haha和hehe,复制hehe目录到haha目录并重命名为apple。[rootlocalhost ~]# mkdir {haha,hehe} [rootlocalhost ~]# cp -r hehe haha [rootlocalhost ~]# cd haha [rootlocalhost haha]# mv hehe apple2.将hehe目录移动到app…...

大模型解决方案专家,火山方舟:用大模型赋能企业,成本、效果、落地难题一网打尽!
火山方舟作为大模型解决方案专家,依托豆包大模型家族及智能模型路由等技术,打造企业级服务平台。核心价值在于解决模型效果、推理成本、落地难度三大挑战。提供更强模型能力、更低成本推理、更易落地应用三大解决方案,助力企业高效落地AI应用…...

NSSCTF做题记录十 | [巅峰极客 2022 决赛]开端:strangeTempreture
[巅峰极客 2022 决赛]开端:strangeTempreture随便点击一个流量包,右击点击追踪流,TCP 流把这几个字母拼接到一起,下面还有很多ZmxhZ3s5N2JmZWIwMy1mYTVjLWFhNmYtYWQxZS05YzVkMzhjNzQ0OWV9base64 解码,得到 flagflag{97…...

《YOLO11魔术师专栏》专栏介绍 专栏目录
《YOLO11魔术师专栏》将从以下各个方向进行创新(更新日期25.07.23): 【原创自研模块】【多组合点优化】【注意力机制】 【主干篇】【neck优化】【卷积魔改】 【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】 【小目标…...