LangChain(0.0.339)官方文档四:Prompts下——prompt templates的存储、加载、组合和部分格式化
文章目录
- 一、 部分提示模板
- 1.1 使用字符串值进行部分格式化(Partial with strings)
- 1.2 使用函数进行部分格式化(Partial with functions)
- 二、Prompt pipelining
- 2.1 String prompt pipelining
- 2.2 Chat prompt pipelining
- 三、使用PipelinePrompt组合多个Pipeline prompts
- 四、prompts存储和加载
- 4.1 PromptTemplate
- 4.1.1 从 YAML 加载
- 4.1.2 从 JSON 加载
- 4.1.3 多文件加载
- 4.2 FewShotPromptTemplate
- 4.2.1 单文件加载含示例的prompts
- 4.2.2 多文件存储
- 4.2.2.1 使用YAML 加载示例
- 4.2.2.2 从 JSON 加载示例
- 4.2.2.3 单文件加载
- 4.3 带有 OutputParser 的 PromptTemplate
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe
一、 部分提示模板
参考《Partial prompt templates》
部分提示模板格式化(Partial prompt templates)是LangChain支持的一种提示模板使用方式。它允许用户仅格式化提示模板的部分必要变量,用户可以在之后传入剩余缺失的变量来进一步格式化该部分提示模板,最终完整地渲染出完整的提示。Partial prompt templates有以下应用场景:
-
分步骤构建提示。在某些场景下,提示可能需要通过多步构建,所以获取变量的时间或顺序可能不固定。部分格式化允许每一步只传递该步相关的变量,逐步完善提示模板。
-
复用提示模板。通过部分格式化,可以基于同一个提示模板,构建出适用于不同场景的定制化提示模板。不同的定制需求通过部分格式化来实现,使得提示模板更通用。
-
组合提示。部分格式化允许分离变量获取流程与提示模板组装流程,变量可以通过不同途径获取,只要最后汇总到一起即可。
总体来说,部分提示模板格式化支持更加灵活和富有创造性的提示模板使用方式,使得提示功能的构建和使用更加高效。
LangChain在部分提示模板方面的两种支持方式:
- 使用字符串值进行部分格式化
- 使用函数(返回字符串值)进行部分格式化
1.1 使用字符串值进行部分格式化(Partial with strings)
Partial prompt templates的一个常见场景是获取模板变量的时间顺序不一致。假设提示模板需要两个变量foo和baz,在工作链中先获得了foo,后获得baz。通常做法是等到获取两个变量之后再在某个位置将它们传递给提示模板。现在你可以先使用 foo的 值部分格式化提示模板,然后使用该部分提示模板在后续步骤中传入baz的值。
- 部分格式化PromptTemplate示例
首先实例化一个PromptTemplate,然后调用它的partial方法进行部分格式化,得到一个部分格式化后的PromptTemplate对象(partial_prompt)。
from langchain.prompts import PromptTemplateprompt = PromptTemplate(template="{foo}{bar}", input_variables=["foo", "bar"])
partial_prompt = prompt.partial(foo="foo");
print(partial_prompt.format(bar="baz"))
foobaz
- 使用部分变量初始化PromptTemplate
直接在初始化PromptTemplate的时候就传入部分变量partial_variables,这样当其实例化时就完成了部分格式化。
prompt = PromptTemplate(template="{foo}{bar}", input_variables=["bar"], partial_variables={"foo": "foo"})
print(prompt.format(bar="baz"))
两段代码最终实现的效果是一样的,区别在于部分格式化的时机不同。第一种方式更加灵活,可以按需多次部分格式化
1.2 使用函数进行部分格式化(Partial with functions)
Partial prompt templates的另一种常见用法是使用函数进行部分格式化。当你有一个变量,希望总是通过某种常用的方式获取时,就可以这样做。
一个典型的例子就是获取日期或时间。假设你有一个提示模板,总是希望内含当前日期,你既不能在模板中硬编码日期,也不太方便每次和其他输入变量一起传递日期。这种情况下,使用函数部分格式化提示模板会非常方便,我们很容易写一个函数来返回当前日期和时间。
from datetime import datetimedef _get_datetime():now = datetime.now()return now.strftime("%m/%d/%Y, %H:%M:%S")
prompt = PromptTemplate(template="Tell me a {adjective} joke about the day {date}",input_variables=["adjective", "date"]
);
partial_prompt = prompt.partial(date=_get_datetime)
print(partial_prompt.format(adjective="funny"))
Tell me a funny joke about the day 02/27/2023, 22:15:16
你也可以可以使用部分变量初始化提示,这通常在此工作流程中更有意义。
prompt = PromptTemplate(template="Tell me a {adjective} joke about the day {date}",input_variables=["adjective"],partial_variables={"date": _get_datetime}
);
print(prompt.format(adjective="funny"))
Tell me a funny joke about the day 02/27/2023, 22:15:16
使用
_get_datetime这种命名方式遵循了Python对私有函数的通用约定和规范,一般被定义在类或模块的内部,而不是外部接口,通常用于实现类或模块内部的某些逻辑,以起到辅助作用。
二、Prompt pipelining
参考《Prompt pipelining 》
prompt pipelining技术,旨在提供用户友好的界面,以便轻松组合不同部分的提示。该技术可以用于处理string prompts和chat prompts。
2.1 String prompt pipelining
使用String prompt 时,您可以直接使用提示或字符串来组合提示模板(列表中的第一个元素必须是提示)。
from langchain.prompts import PromptTemplateprompt = (PromptTemplate.from_template("Tell me a joke about {topic}")+ ", make it funny"+ "\n\nand in {language}"
)
prompt
PromptTemplate(input_variables=['language', 'topic'], output_parser=None, partial_variables={}, template='Tell me a joke about {topic}, make it funny\n\nand in {language}', template_format='f-string', validate_template=True)
prompt.format(topic="sports", language="spanish")
'Tell me a joke about sports, make it funny\n\nand in spanish'
您也可以像以前一样在 LLMChain 中使用它。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAImodel = ChatOpenAI()
chain = LLMChain(llm=model, prompt=prompt)
chain.run(topic="sports", language="spanish")
'¿Por qué el futbolista llevaba un paraguas al partido?\n\nPorque pronosticaban lluvia de goles.'
2.2 Chat prompt pipelining
由于chat prompt由消息列表组成,一种便捷组合chat prompt的方式是,向chat prompt管道中添加new message。这种方法使得构建聊天对话变得更加直观和方便,开发者只需逐步添加新消息即可形成完整的对话提示。
通常我们会先用系统消息初始化基本 ChatPromptTemplate,然后逐个添加新的消息。如果没有需要格式化的变量,可以使用Message。而如果有需要格式化的变量,可以使用MessageTemplate。此外,还可以直接使用字符串,这会自动被推断为HumanMessagePromptTemplate。
from langchain.schema import AIMessage, HumanMessage, SystemMessageprompt = SystemMessage(content="You are a nice pirate")new_prompt = (prompt + HumanMessage(content="hi") + AIMessage(content="what?") + "{input}"
)
在底层,这会创建 ChatPromptTemplate 类的一个实例,因此您可以像以前一样使用它
new_prompt.format_messages(input="i said hi")
[SystemMessage(content='You are a nice pirate', additional_kwargs={}),HumanMessage(content='hi', additional_kwargs={}, example=False),AIMessage(content='what?', additional_kwargs={}, example=False),HumanMessage(content='i said hi', additional_kwargs={}, example=False)]
您也可以像以前一样在 LLMChain 中使用它。
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAImodel = ChatOpenAI()
chain = LLMChain(llm=model, prompt=new_prompt)
chain.run("i said hi")
'Oh, hello! How can I assist you today?'
三、使用PipelinePrompt组合多个Pipeline prompts
参考《Composition》
通过 PipelinePrompt可以将多个提示组合在一起,当您想要重复使用部分提示时,这会很有用。 PipelinePrompt 由两个主要部分组成:
Final prompt: 返回的最终提示,比如以下示例中的full_prompt;Pipeline prompts:元组列表(string name,prompt template),比如示例中的input_prompts。每个提示模板将被格式化,然后作为具有相同名称的变量传递到未来的提示模板。
下面例子中,我们首先创建Final prompt:
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplatefull_template = """{introduction}{example}{start}"""
full_prompt = PromptTemplate.from_template(full_template)
然后分别创建三个Pipeline prompts:
introduction_template = """You are impersonating {person}."""
introduction_prompt = PromptTemplate.from_template(introduction_template)
example_template = """Here's an example of an interaction:Q: {example_q}
A: {example_a}"""
example_prompt = PromptTemplate.from_template(example_template)
start_template = """Now, do this for real!Q: {input}
A:"""
start_prompt = PromptTemplate.from_template(start_template)
使用PipelinePromptTemplate组合所有提示模板:
input_prompts = [("introduction", introduction_prompt),("example", example_prompt),("start", start_prompt)
]
pipeline_prompt = PipelinePromptTemplate(final_prompt=full_prompt, pipeline_prompts=input_prompts)
pipeline_prompt.input_variables
['example_a', 'person', 'example_q', 'input']
使用此pipeline_prompt:
print(pipeline_prompt.format(person="Elon Musk",example_q="What's your favorite car?",example_a="Tesla",input="What's your favorite social media site?"
))
You are impersonating Elon Musk.
Here's an example of an interaction:Q: What's your favorite car?
A: Tesla
Now, do this for real!Q: What's your favorite social media site?
A:
四、prompts存储和加载
参考《Prompt pipelining》
通常来说最好不要将prompts存储为 python 代码,而是存储为文件,这样便于prompts的管理、分享和版本控制。LangChain 提供了强大的 prompts 序列化功能来实现这一点。
-
LangChain支持JSON和YAML两种序列化格式。JSON和YAML格式在磁盘上是人类可读的,而且很很流行,通常用来存储prompts。对于其他资源,如示例(examples),可能支持不同的序列化方法。
-
LangChain支持单文件存储和多文件存储。你可以在一个文件中指定所有内容,或将不同组件存储在不同文件中并进行引用。有些情况下,将所有内容存储在一个文件中可能是最合理的,但对于其他情况,将某些资源(如长模板、大示例、可重复使用的组件)拆分开可能更可取。
-
load_prompt:所有的prompts都可以通过load_prompt来加载,简单快捷。
4.1 PromptTemplate
首先我们可以用PromptTemplate的save方法将其进行存储:
from langchain.prompts import PromptTemplateprompt = (PromptTemplate.from_template("Tell me a joke about {topic}")+ ", make it funny"+ "\n\nand in {language}"
)prompt.save("prompt.yaml")
cat prompt.yaml
_type: prompt
input_types: {}
input_variables:
- language
- topic
output_parser: null
partial_variables: {}
template: 'Tell me a joke about {topic}, make it funnyand in {language}'
template_format: f-string
validate_template: false
如果使用save方法存储ChatPromptTemplate,会报错ChatPromptTemplate,应该是此功能还未实现(截止0.0344版本)。
4.1.1 从 YAML 加载
在notebook中创建一个simple_prompt.yaml文件:
%%writefile simple_prompt.yaml
_type: prompt
input_variables:- adjective- content
template: Tell me a {adjective} joke about {content}.
cat simple_prompt.yaml
_type: prompt
input_variables:- adjective- content
template: Tell me a {adjective} joke about {content}.
加载此yaml文件:
prompt = load_prompt("simple_prompt.yaml")
print(prompt.format(adjective="funny", content="chickens"))
Tell me a funny joke about chickens.
4.1.2 从 JSON 加载
%%writefile simple_prompt.json{"_type": "prompt","input_variables": ["adjective", "content"],"template": "Tell me a {adjective} joke about {content}."
}
prompt = load_prompt("simple_prompt.json")
print(prompt.format(adjective="funny", content="chickens"))
Tell me a funny joke about chickens.
4.1.3 多文件加载
下面演示将模板存储在单独的文件中,然后在配置中引用它的示例。
%%writefile simple_template.txtTell me a {adjective} joke about {content}.
%%writefile simple_prompt_with_template_file.json{"_type": "prompt","input_variables": ["adjective", "content"],"template_path": "simple_template.txt"
}
prompt = load_prompt("simple_prompt_with_template_file.json")
print(prompt.format(adjective="funny", content="chickens"))
Tell me a funny joke about chickens.
4.2 FewShotPromptTemplate
4.2.1 单文件加载含示例的prompts
我们可以在一个文件中存储整个prompt模板,例如:
cat few_shot_prompt_examples_in.json
{"_type": "few_shot","input_variables": ["adjective"],"prefix": "Write antonyms for the following words.","example_prompt": {"_type": "prompt","input_variables": ["input", "output"],"template": "Input: {input}\nOutput: {output}"},"examples": [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"}],"suffix": "Input: {adjective}\nOutput:"
}
prompt = load_prompt("few_shot_prompt_examples_in.json")
print(prompt.format(adjective="funny"))
Write antonyms for the following words.Input: happy
Output: sadInput: tall
Output: shortInput: funny
Output:
4.2.2 多文件存储
首先使用YAML或JSON来存储具体的示例:
cat examples.json
[{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"}
]
cat examples.yaml
- input: happyoutput: sad
- input: talloutput: short
4.2.2.1 使用YAML 加载示例
cat few_shot_prompt.yaml
_type: few_shot
input_variables:["adjective"]
prefix: Write antonyms for the following words.
example_prompt:_type: promptinput_variables:["input", "output"]template:"Input: {input}\nOutput: {output}"
examples:examples.json
suffix:"Input: {adjective}\nOutput:"
prompt = load_prompt("few_shot_prompt.yaml")
print(prompt.format(adjective="funny"))
Write antonyms for the following words.Input: happy
Output: sadInput: tall
Output: shortInput: funny
Output:
上面的few_shot_prompt.yaml中, examples:examples.json也可以改成 examples:examples.yaml,结果是一样的。
4.2.2.2 从 JSON 加载示例
cat few_shot_prompt.json
{"_type": "few_shot","input_variables": ["adjective"],"prefix": "Write antonyms for the following words.","example_prompt": {"_type": "prompt","input_variables": ["input", "output"],"template": "Input: {input}\nOutput: {output}"},"examples": "examples.json","suffix": "Input: {adjective}\nOutput:"
}
prompt = load_prompt("few_shot_prompt.json")
print(prompt.format(adjective="funny"))
Write antonyms for the following words.Input: happy
Output: sadInput: tall
Output: shortInput: funny
Output:
4.2.2.3 单文件加载
上面两个例子,只将examples单独写在JSON或者YAML文件中进行引用,你也可以将example_prompt(PromptTemplate )也单独放在一个文件中,等于是整个FewShotPromptTemplate分三个文件来存储。
新建example_prompt.json
cat example_prompt.json
{"_type": "prompt","input_variables": ["input", "output"],"template": "Input: {input}\nOutput: {output}"
}
配置FewShotPromptTemplate:
cat few_shot_prompt_example_prompt.json
{"_type": "few_shot","input_variables": ["adjective"],"prefix": "Write antonyms for the following words.","example_prompt_path": "example_prompt.json","examples": "examples.json","suffix": "Input: {adjective}\nOutput:"
}
prompt = load_prompt("few_shot_prompt_example_prompt.json")
print(prompt.format(adjective="funny")) # 结果是一样的
4.3 带有 OutputParser 的 PromptTemplate
下面演示从文件加载带有OutputParser的PromptTemplate:
cat prompt_with_output_parser.json
{"input_variables": ["question","student_answer"],"output_parser": {"regex": "(.*?)\\nScore: (.*)","output_keys": ["answer","score"],"default_output_key": null,"_type": "regex_parser"},"partial_variables": {},"template": "Given the following question and student answer, provide a correct answer and score the student answer.\nQuestion: {question}\nStudent Answer: {student_answer}\nCorrect Answer:","template_format": "f-string","validate_template": true,"_type": "prompt"
}
prompt = load_prompt("prompt_with_output_parser.json")
prompt.output_parser.parse("George Washington was born in 1732 and died in 1799.\nScore: 1/2"
)
{'answer': 'George Washington was born in 1732 and died in 1799.','score': '1/2'}
相关文章:
官方文档四:Prompts下——prompt templates的存储、加载、组合和部分格式化)
LangChain(0.0.339)官方文档四:Prompts下——prompt templates的存储、加载、组合和部分格式化
文章目录 一、 部分提示模板1.1 使用字符串值进行部分格式化(Partial with strings)1.2 使用函数进行部分格式化(Partial with functions) 二、Prompt pipelining2.1 String prompt pipelining2.2 Chat prompt pipelining 三、使用…...
鸿蒙开发笔记
最近比较火,本身也是做前端的,就抽空学习了下。对前端很友好 原视频地址:黑马b站鸿蒙OS视频 下载安装跟着视频或者文档就可以了。如果你电脑上安装的有node,但是开发工具显示你没安装,不用动咱们的node,直…...
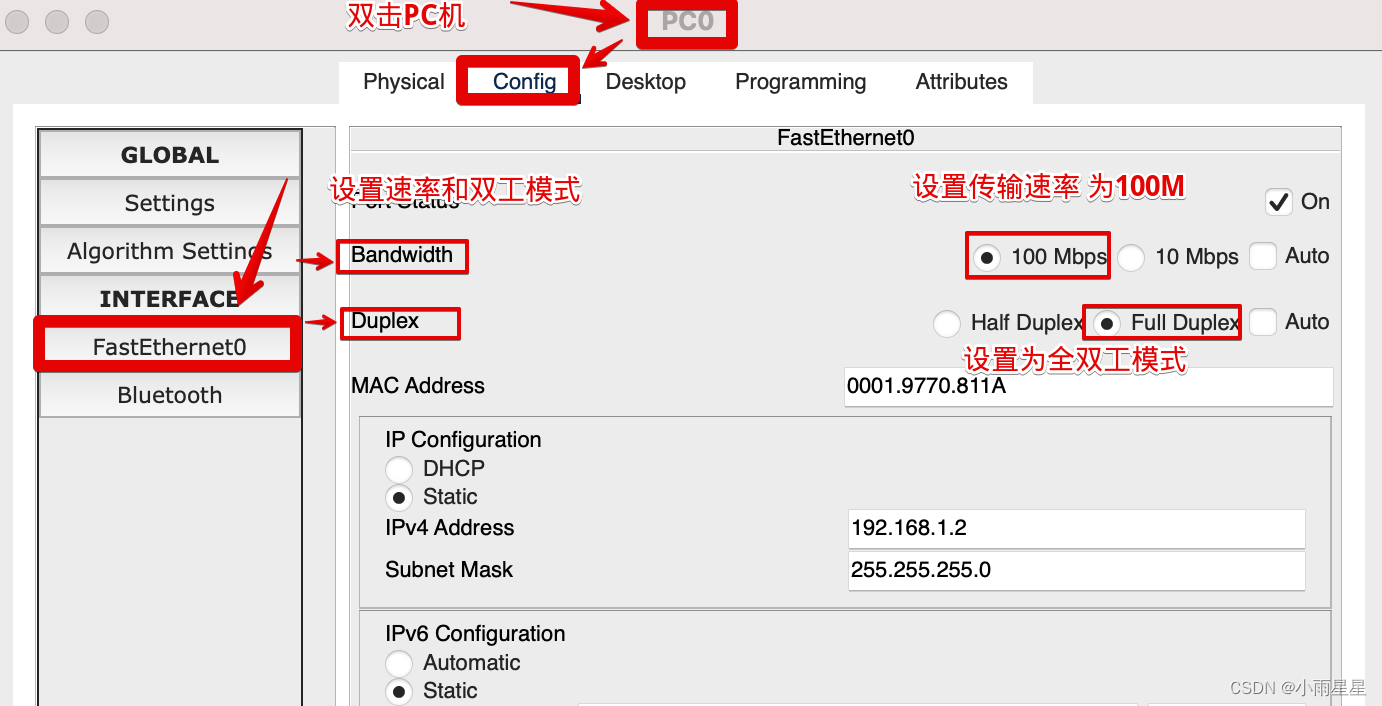
「计算机网络」Cisco Packet Tracker计算机网络仿真器的使用
介绍 Cisco Packet Tracker:网络仿真工具,用于模拟网络配置。 (一) 配置交换机(Switch)(通过 带外管理) 带外:Out-of-Band, OOB写在前面:如何打开Console页…...
:KeyboardInterrupt)
【已解决】if lock.acquire(block, timeout):KeyboardInterrupt
问题描述 Traceback (most recent call last): File "/media/visionx/monica/project/ResShift/app.py", line 134, in <module> demo.launch(shareFalse) File "/home/visionx/anaconda3/envs/ResShift/lib/python3.9/site-packages/gradio/bloc…...

将Excel中的数据导入shell脚本,并调用expect脚本
主脚本test.sh #!/bin/bash # 设置超时时间 set timeout 240 # 将 Excel 文件转换为 CSV 格式 # test.xlsx > temp.csv # 初始化一个二维数组 declare -A data # 逐行读取 CSV 文件,并将每个单元格的数据存储在二维数组中 row1 while IFS, read -r col1 col2 co…...

elementui el-table用span-method方法对相同的列名或行名进行合并
看到的一篇文章 同理 如果对第二列进行合并的话copy一下第一个方法,让值赋给第二个数组就可以 // 合并方法mergeCells({ row, column , rowIndex, columnIndex }) {debugger;if (columnIndex 1) {const _row this.spanArr[rowIndex];const _col _row > 0 ? …...
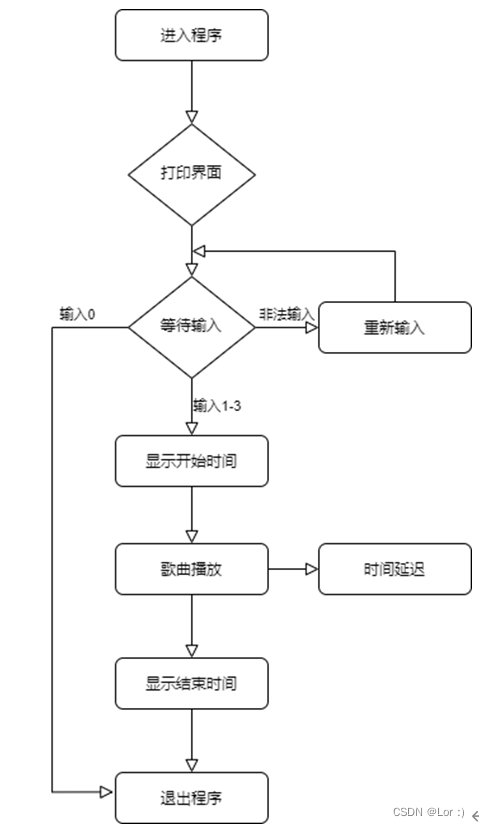
汇编语言实现音乐播放器
目标程序 用汇编语言实现一个音乐播放器,并支持点歌 Overview 乐曲是按照一定的高低、长短和强弱关系组成的音调,在一首乐曲中,每个音符的音高和音长与频率和节拍有关,因此我们要分别为3首要演奏的乐曲定义一个频率表和一个节拍…...
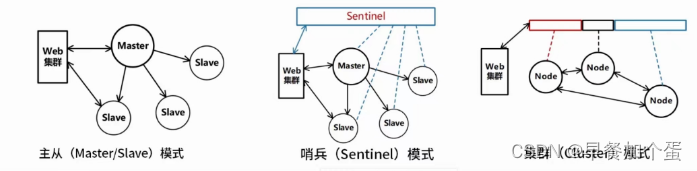
大型网站系统架构演化(Web)
大型网站系统架构演化 大型网站系统架构演化需要关注的维度涉及的技术演进过程单体架构垂直架构使用缓存改善网站性能缓存与数据库的数据一致性问题缓存技术对比Redis分布式存储方案Redis集群切片的常见方式Redis数据类型Redis 淘汰算法使用服务集群改善网站并发能力 大型网站系…...
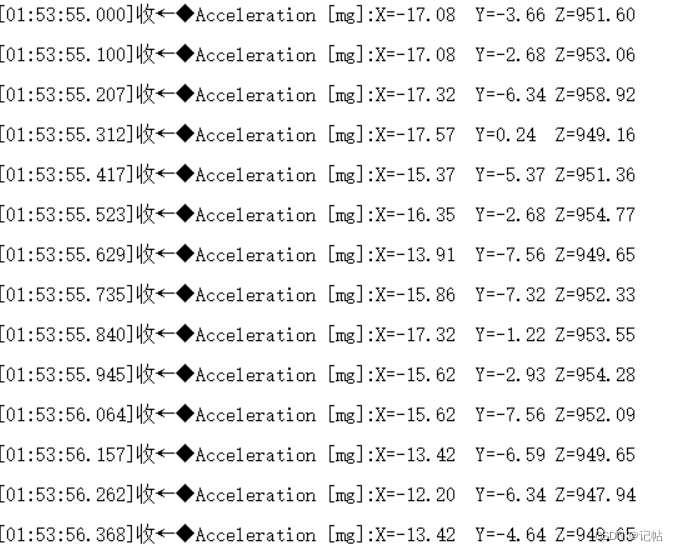
三轴加速度计LIS2DW12开发(2)----基于中断信号获取加速度数据
三轴加速度计LIS2DW12开发.2--轮基于中断信号获取加速度数据 概述视频教学样品申请生成STM32CUBEMX串口配置IIC配置CS和SA0设置INT1设置串口重定向参考程序初始换管脚获取ID复位操作BDU设置开启INT1中断设置传感器的量程配置过滤器链配置电源模式设置输出数据速率中断判断加速…...
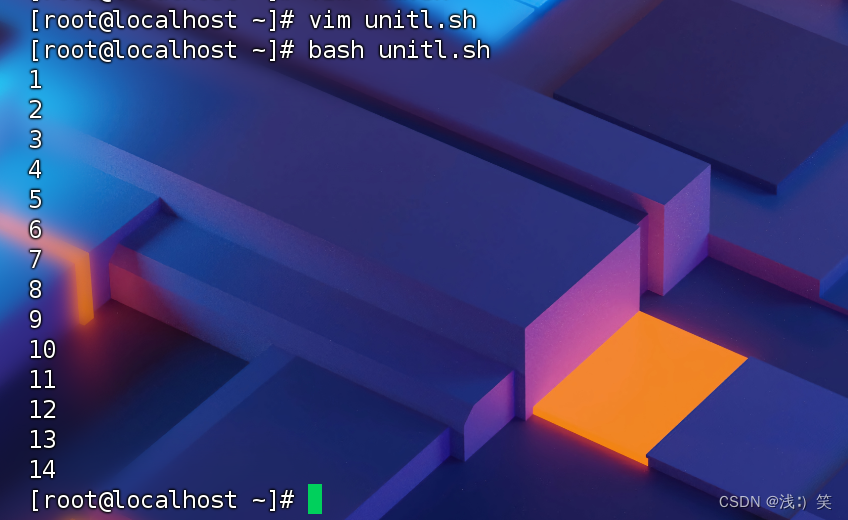
Shell循环:whileuntil
一、特点:循环次数[一定]是固定的 二、while语句结构 while 条件测试 do 循环体 done 当条件测试成立(条件测试为真),执行循环体 演示: 需求:每秒显示一个数字,一…...
Redis 安装部署
文章目录 1、前言2、安装部署2.1、单机模式2.1.1、通过 yum 安装(不推荐,版本老旧)2.1.1、通过源码编译安装(推荐) 2.2、主从模式2.3、哨兵模式2.4、集群模式2.5、其他命令2.6、其他操作系统 3、使用3.1、Java 代码 —…...
项目中遇到的半导体公司
作为一个技术人,我并不是亲美,从技术的实事求是角度讲,不得不感叹欧美的半导体技术。他们的datasheet能学到的东西太多太多;我甚至佩服他们缜密的逻辑。从他们的文章中领悟我们技术到底有多low,没办法一个一个了解所有…...

汇编:call与ret/retf指令
一、call指令 1.1 依据位移进行转移:call 标号 1.2 实现段间转移:call far ptr 标号 1.3 转移地址在寄存器中:call 16位寄存器 1.4 转移地址在内存中 1.4.1 call word ptr 内存单元地址 1.4.2 call dword ptr 内存单元地址…...

Fiddler抓包工具之高级工具栏中的重定向AutoResponder的用法
重定向AutoResponder的用法 关于Fiddler的AutoResponder重定向功能,主要是时进行会话的拦截,然后替换原始资源的功能。 它与手动修该reponse是一样的,只是更加方便了,可以创建相应的rules,适合批处理的重定向功能。 …...

如何基于OpenCV和Sklearn库开展数据降维
大家在做数据分析或者机器学习应用过程中,不可避免的需要对数据进行降维操作,好多垂直行业业务中经常出现数据量少但维度巨大的情况。数据降维的目的是为了剔除不相关或冗余特征,使得数据易用,去除无用数据,实现数据可…...

详解SpringAop开发过程中的坑
😉😉 学习交流群: ✅✅1:这是孙哥suns给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783…...

【海思SS528 | VDEC】MPP媒体处理软件V5.0 | VDEC的使用总结
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

Kubernetes sample-controller 例子介绍
sample-controller sample-controller 是 K8s 官方自定义 CDR 及控制器是实现的例子 通过使用这个自定义 CDR 控制器及阅读它的代码,基本可以了解如何制作一个 CDR 控制器 CDR 运作原理 网上有更好的文章,说明其运作原理: https://www.z…...

【C/C++指针】指针*与引用的区别
指针变量的值是所指对象的地址(准确说是首地址,其类型定义其所指对象的字节长度)引用变量的值是所引用对象本身的值 1 初始化 指针变量 可不初始化 且 可以更换指向对象 int *p;//此时是个野指针,该指针变量的值是任意值&#x…...

【ArcGIS Pro微课1000例】0039:制作全球任意经纬网的两种方式
本文讲解在ArcGIS Pro中制作全球任意经纬网的两种方式。 文章目录 一、生成全球经纬网矢量1. 新建地图加载数据2. 创建经纬网矢量数据二、布局生成经纬网1. 新建布局2. 创建地图框2. 创建经纬网一、生成全球经纬网矢量 以1:100万比例尺地图分幅为例,创建经差6、维差4的经纬网…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

13456
12356...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...