Elasticsearch(ES)概述
文章目录
- 一.什么是Elasticsearch?
- 1.正向索引和倒排索引
- 2.Mysql和ES的概念对比
- 3.安装elasticsearch、kibana
- 二.IK分词器
- 三.索引库操作
- 四.文档操作
- 五.RestClient操作索引库
- 1.初始化RestClient
- 2.创建索引库
- 3.删除索引库
- 4.判断索引库是否存在
- 六.RestClient操作文档
- 1.新增文档
- 2.查询数据
- 3.修改数据
- 4.删除数据
- 5.批量插入数据
- 七.DSL查询文档
- 八.RestClient检索查询文档
一.什么是Elasticsearch?
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
Elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
Elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
Elasticsearch是elastic stack的核心(不可替换),负责存储、搜索、分析数据。

1.正向索引和倒排索引
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语
正向索引(Forward Index):
定义: 正向索引是根据文档-词项对的方式建立的索引。每个文档都有一个记录,其中包含了文档中的所有词项及其位置信息。
例如Mysql就是使用的正向索引,根据id检索一个文档非常快,但是根据文档中某个字段检索文档只能逐条检索
倒排索引(Inverted Index):
定义: 倒排索引是根据词项-文档对的方式建立的索引。每个词项都有一个记录,其中包含了包含该词项的所有文档及其位置信息。即对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
Elasticsearch就使用了倒排索引,将文档按照语义分成词条,根据词条建立词条表,这样就形成了词条-文档的结构,导致检索字段时非常快
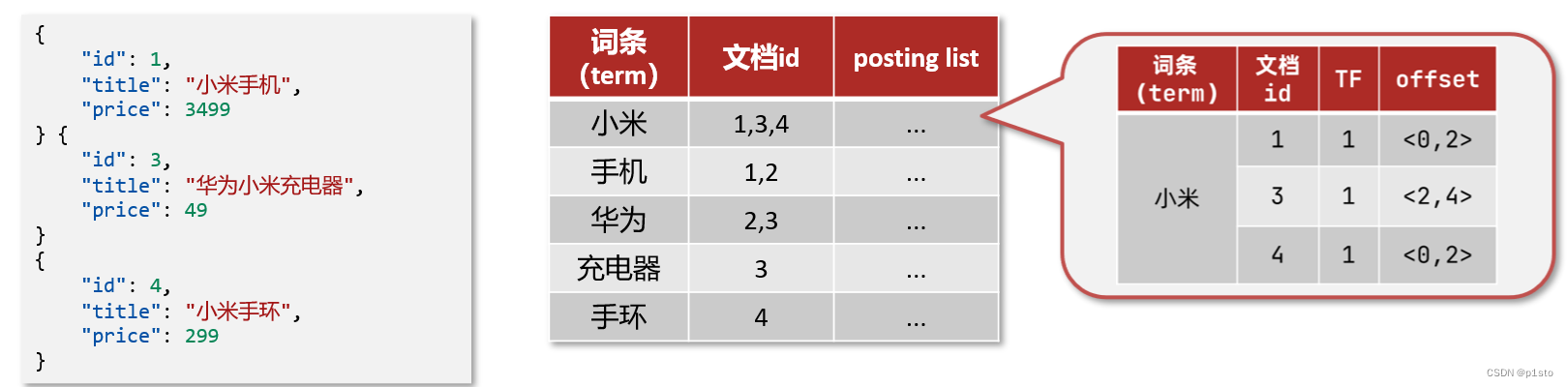
倒排索引中包含两部分内容:
-
词条词典(Term Dictionary):记录所有词条,以及词条与倒排列表(Posting List)之间的关系,会给词条创建索引,提高查询和插入效率
-
倒排列表(Posting List):记录词条所在的文档id、词条出现频率 、词条在文档中的位置等信息
-
文档id:用于快速获取文档
-
词条频率(TF):文档在词条出现的次数,用于评分
-
文档:
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。
索引:
相同类型的文档的集合
映射:
索引中文档的字段约束信息,类似表的结构约束

2.Mysql和ES的概念对比

Mysql:擅长事务类型(ACID特性)操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
总而言之:
-
正向索引适合于文档级别的查询,因为它直接提供了文档中的词项信息。
-
倒排索引适合于词项级别的查询,因为它直接提供了包含某个词项的文档信息。
3.安装elasticsearch、kibana
通过Dokcer拉取镜像安装即可
二.IK分词器
ES在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。故需要更好的分词策略:IK分词器
安装(安装到es-plugins/_data即可):IK分词器官方地址,重启es后IK分词器生效
ik分词器包含两种模式:
- ik_smart:最少切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器-拓展词库
IK分词器虽然说按照字典查找词语进行组合,但是随着网络文化发展和新词的逐渐产生,IK分词器不可能马上更新这些词汇,这时候就需要进行拓展词汇库和增加禁用词汇
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
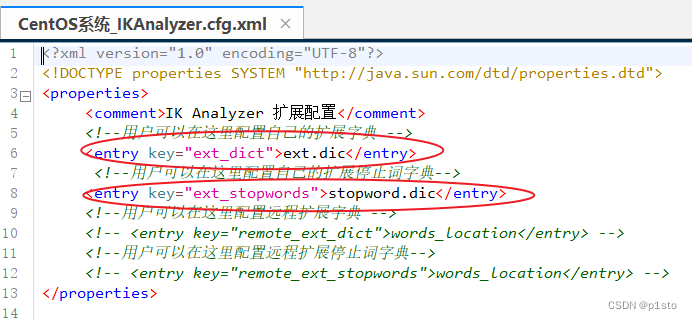
在ext.dic文件中添加拓展词汇
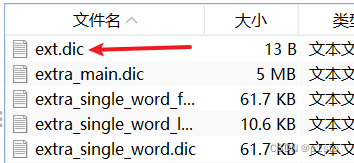
在stopword.dic文件下添加禁用词汇
三.索引库操作
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
数值:long、integer、short、byte、double、float
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
创建索引库
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
查看索引库语法:
GET /索引库名
删除索引库的语法:
DELETE /索引库名
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
四.文档操作
添加文档
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
查看文档语法:
GET /索引库名/_doc/文档id
删除文档:
DELETE /索引库名/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
{"doc": {"字段名": "新的值",}
}文档操作-动态映射
当我们向ES中插入文档时,如果文档中字段没有对应的mapping,ES会帮助我们字段设置mapping,规则如下:
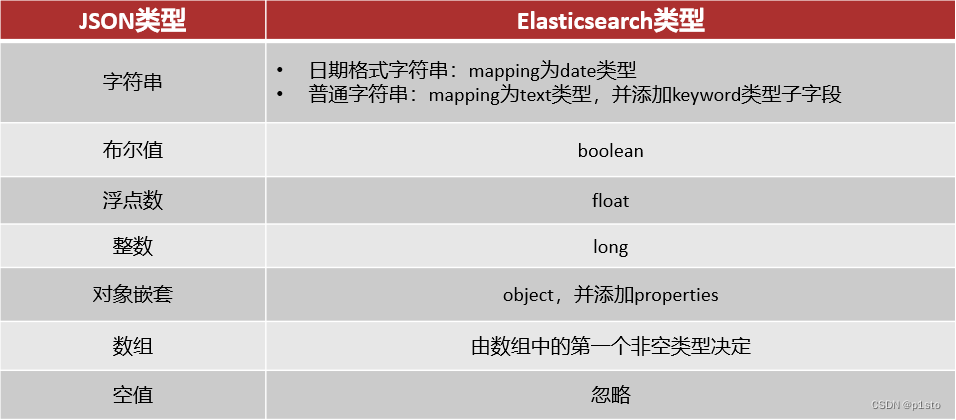
五.RestClient操作索引库
什么是RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
使用:
1.初始化RestClient
1.引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></dependency>
2.可以发现客户端的版本号,引入的依赖版本必须和客户端一致(不一致则需修改)
修改版本号
<properties><java.version>1.8</java.version><elasticsearch.version>客户端版本号</elasticsearch.version></properties>
3.初始化RestHighLevelClient:
private RestHighLevelClient client;//测试类中使用@BeforeEach注解来标记一个方法,该方法将在每个测试方法执行之前执行(@AfterEach同理)@BeforeEachvoid setUp(){this.client=new RestHighLevelClient(RestClient.builder(HttpHost.create("自己的Linux局域网ip地址:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
2.创建索引库
@Testvoid testCreateHotelIndex() throws IOException {CreateIndexRequest request = new CreateIndexRequest("索引库名");request.source("DSL语句", XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);}
其中:indices()包含了所有操作索引库的API
3.删除索引库
@Testvoid testDeleteHotelIndex() throws IOException { // 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("索引库名");// 2.发起请求client.indices().delete(request, RequestOptions.DEFAULT);
}
4.判断索引库是否存在
@Testvoid testExistsHotelIndex() throws IOException { // 1.创建Request对象 GetIndexRequest request = new GetIndexRequest("索引库名"); // 2.发起请求 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); // 3.输出 System.out.println(exists);
}六.RestClient操作文档
1.新增文档
IndexRequest request = new IndexRequest("索引库名").id(设置id);request.source(JSON文档, XContentType.JSON);client.index(request, RequestOptions.DEFAULT);
2.查询数据
GetRequest request = new GetRequest(索引库名, id); GetResponse response = client.get(request, RequestOptions.DEFAULT); String json = response.getSourceAsString();
3.修改数据
UpdateRequest request = new UpdateRequest(索引库名,id);request.doc("键1","值1","键2","值2"...);client.update(request, RequestOptions.DEFAULT);
4.删除数据
DeleteRequest request = new DeleteRequest(索引库名,id);client.delete(request, RequestOptions.DEFAULT);
5.批量插入数据
request.add(new IndexRequest(索引库名).id(id1).source(JSON文档1, XContentType.JSON));
request.add(new IndexRequest(索引库名).id(id2).source(JSON文档2, XContentType.JSON));
request.add(new IndexRequest(索引库名).id(id3).source(JSON文档3, XContentType.JSON));
//request可以添加多个IndexRequest
client.bulk(request, RequestOptions.DEFAULT);
七.DSL查询文档
DSL Query的分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range
- term
- 地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询的基本语法如下:
GET /indexName/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}
全文检索查询
match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}}
}
multi_match:与match查询类似,只不过允许同时查询多个字段,语法:
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD12"]}}
}
需要注意的是:根据多个字段查询,参与查询字段越多,查询性能越差,建议使用多个字段拷贝到一个字段进行多字段的查询
精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
term查询:
// term查询
GET /indexName/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}
range查询:
// range查询
GET /indexName/_search
{"query": {"range": {"FIELD": {"gte": 10,"lte": 20}}}
}
地理查询
geo_bounding_box(不常用):查询geo_point值落在某个矩形范围的所有文档
// geo_bounding_box查询
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
geo_distance(常用):查询到指定中心点小于某个距离值的所有文档
// geo_distance 查询
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km","FIELD": "31.21,121.5"}}
}
复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
常见的三个算分函数:

TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平
Function Score Query
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。
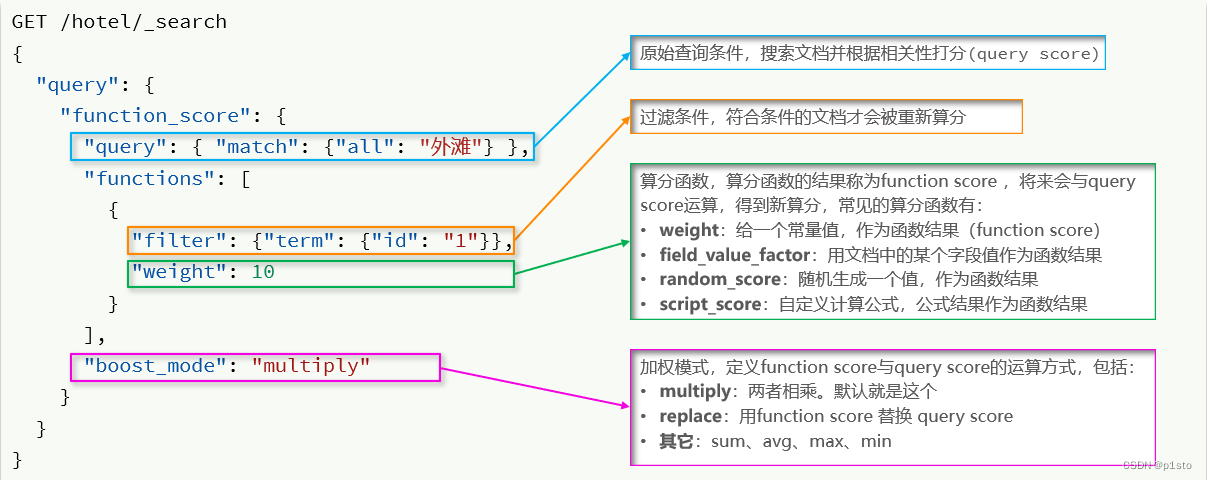
function score query定义的三要素:
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
复合查询 Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
例子:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": { "price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km", "location": {"lat": 31.21, "lon": 121.5}}}]}}
}
搜索结果处理
1.排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段和排序方式ASC、DESC}]
}
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"FIELD" : "纬度,经度","order" : "asc","unit" : "km"}}]
}
2.分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
GET /hotel/_search
{"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
深度分页问题(ES设定结果集查询的上限是10000)
针对深度分页,ES提供了两种解决方案:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
3.高亮
高亮:就是在搜索结果中把搜索关键字突出显示。
原理是这样的:
将搜索结果中的关键字用标签标记出来
在页面中给标签添加css样式
语法:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT"}},"highlight": {"fields": { "FIELD": {// 指定要高亮的字段"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
八.RestClient检索查询文档
需要说明的是,这里的RestClient查询文档不同于上面使用的GetRequest查询,GetRequest查询是简单查询,传入的参数只限制以下几个:
1.match_all查询

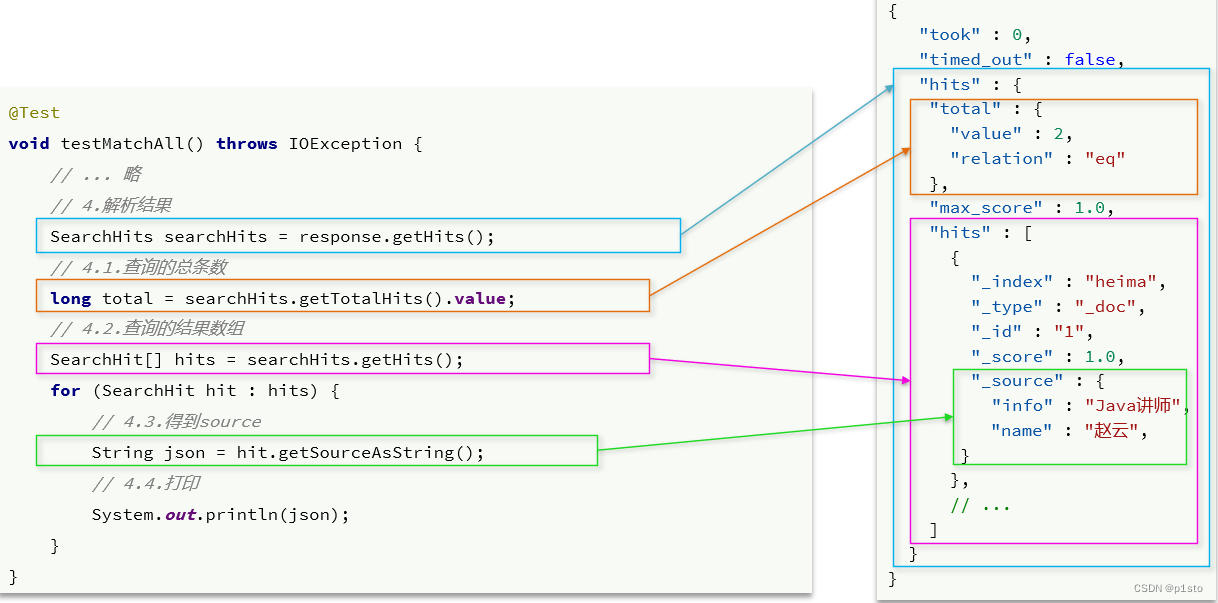
@Test
void testMatchAll() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.matchAllQuery());SearchResponse response = client.search(request, RequestOptions.DEFAULT);SearchHits searchHits = response.getHits();long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String json = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc=" + hotelDoc);}}
可以把request.source()理解为查询的整体,在source()下又有sort(),highlighter(),size(),from(),query()等等,这些方法均是已经学习过的DSL查询的query()的平级,即RestAPI中其中构建DSL是通过HighLevelRestClient中的resource()来实现的,其中包含了查询、排序、分页、高亮等所有功能
RestAPI中其中构建查询条件的核心部分是由一个名为QueryBuilders的工具类提供的,其中包含了各种查询方法:

2.全文检索查询
全文检索的match和multi_match查询与match_all的API基本一致。==差别是查询条件,也就是query的部分。==同样是利用QueryBuilders提供的方法:

其实就是query里面的参数不同,对应到java代码中就是QueryBuilders调用的API不同而已
// 单字段查询
QueryBuilders.matchQuery("字段", "字符串");
// 多字段查询
QueryBuilders.multiMatchQuery("字符串", "字段1", "字段2");
3.精确查询
精确查询常见的有term查询和range查询
// 词条查询
QueryBuilders.termQuery("字段", "字符串");
// 范围查询
QueryBuilders.rangeQuery("字段").gte(xxx).lte(xxx);
4.复合查询-boolean query
精确查询常见的有term查询和range查询,由于在DSL语句中bool包含了多个属性,故需要先创建一个BoolQueryBuilder对象,依次向对象中添加条件属性
// 创建布尔查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 添加must条件
boolQuery.must(QueryBuilders.termQuery("字段", "字符串"));
// 添加filter条件
boolQuery.filter(QueryBuilders.rangeQuery("字段").lte(xxx));
//添加must_not条件
boolQuery.mustNot((QueryBuilders.xxx);
5.排序和分页
搜索结果的排序和分页是与query同级的参数,故改变source()调用的API即可
request.source().from(起始页码).size(每页显示条数);request.source().sort("字段", SortOrder.ASC);//升序
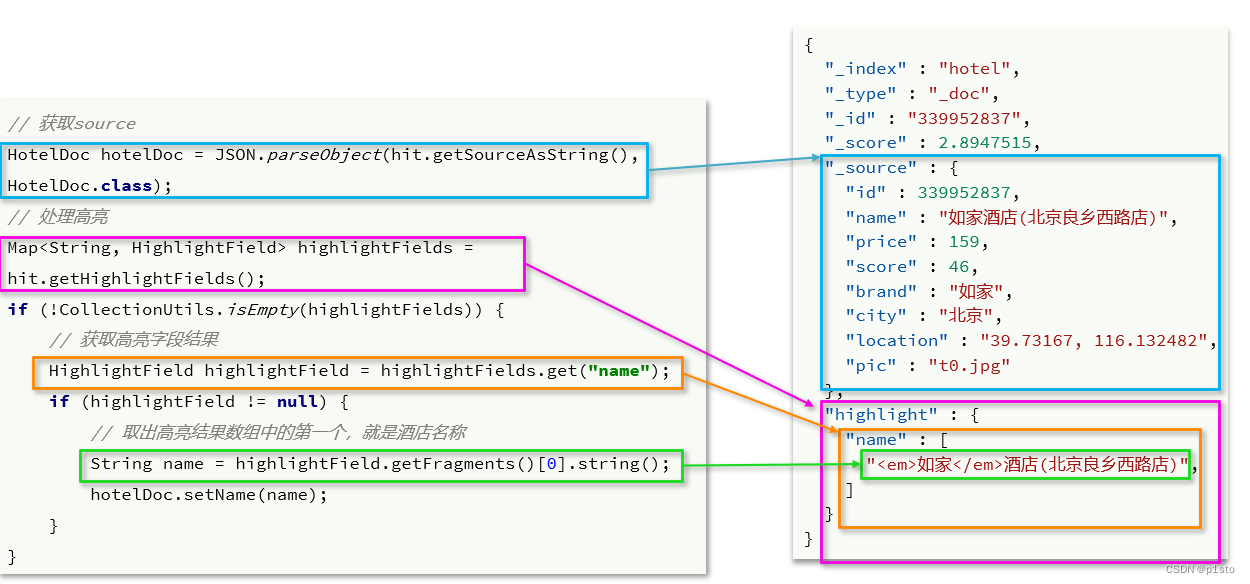
6.高亮
request.source().highlighter(new HighlightBuilder() .field("字段") // 是否需要与查询字段匹配 .requireFieldMatch(false)//不填写pre_tags和post_tags属性默认为<em>标签
);
高亮的结果处理(其实就是获取每一个hit里面的highlight值,就可以取出高亮字段中的值了):
相关文章:
Elasticsearch(ES)概述
文章目录 一.什么是Elasticsearch?1.正向索引和倒排索引2.Mysql和ES的概念对比3.安装elasticsearch、kibana 二.IK分词器三.索引库操作四.文档操作五.RestClient操作索引库1.初始化RestClient2.创建索引库3.删除索引库4.判断索引库是否存在 六.RestClient操作文档1.新增文档2.…...

网络入门---网络编程初步认识和实践
目录标题 前言准备工作udpserver.hpp成员变量构造函数初始化函数(socket,bind)start函数(recvfrom) udpServer.ccudpClient.hpp构造函数初始化函数run函数(sendto) udpClient.cc测试 前言 在上一篇文章中我们初步的认识了端口号的作用,ip地址和MAC地址在网络通信时…...
Linux系统安装Docker-根据官方教程教程(以Ubuntu为例)
Linux系统安装Docker-根据官方教程教程(以Ubuntu为例) 1. 背景介绍2. 环境配置2.1 软件环境要求2.2 软件下载2.3 文档地址2.3 必备命令工具下载 3. 安装Docker3.1 使用root用户操作后续命令3.2 卸载可能存在的旧版本 4. 安装Docker4.1 更新依赖包4.2 配置…...

2023-12-03 LeetCode每日一题(可获得的最大点数)
2023-12-03每日一题 一、题目编号 1423. 可获得的最大点数二、题目链接 点击跳转到题目位置 三、题目描述 几张卡牌 排成一行,每张卡牌都有一个对应的点数。点数由整数数组 cardPoints 给出。 每次行动,你可以从行的开头或者末尾拿一张卡牌&#x…...

【唐山海德教育】安全员b证的考试科目
安全员b证考试内容包括对安全生产知识和管理能力考核,采用书面或计算机闭卷考试方式,内容包括安全生产法律法规、安全管理和安全技术等内容。其中,法律法规占50%,安全管理占40%,土建综合安全技术占6%,机械设…...
吉他初学者学习网站搭建系列(4)——如何查询和弦图
文章目录 背景实现ChordDbvexchords 背景 作为吉他初学者,如何根据和弦名快速查到和弦图是一个必不可少的功能。以往也许你会去翻和弦的书籍查询,像查新华字典那样,但是有了互联网后我们不必那样,只需要在网页上输入和弦名&#…...

九章量子计算机:探索量子世界的革命性工具
九章量子计算机:探索量子世界的革命性工具 一、引言 九章量子计算机的推出,是近年来科技界最为引人瞩目的成就之一。这款基于量子力学的计算机,以其独特的计算方式和潜在的应用前景,引发了全球范围内的关注和讨论。本文将深入探讨九章量子计算机的原理、技术特点、应用前景…...

在 Linux 上修改 Oracle 控制文件、日志文件和数据文件的目录的脚本
以下是一个交互式的 Bash 脚本示例,用于在 Linux 上修改 Oracle 数据库控制文件、日志文件和数据文件的目录。脚本会要求您输入要修改的路径,并根据输入的路径执行相应的修改操作。 #!/bin/bash# 修改以下变量以匹配您的 Oracle 数据库设置 ORACLE_SID&…...
JavaScript 延迟加载的艺术:按需加载的最佳实践
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

HTML之实体和标签
HTML之实体和标签 实体标签meta标签语义化标签列表超链接 实体 如果我们需要在网页中书写一些特殊符号,则需要在html中使用【实体】(转义符) 实体语法: &实体的名字; <!DOCTYPE html> <html lang"en"> …...
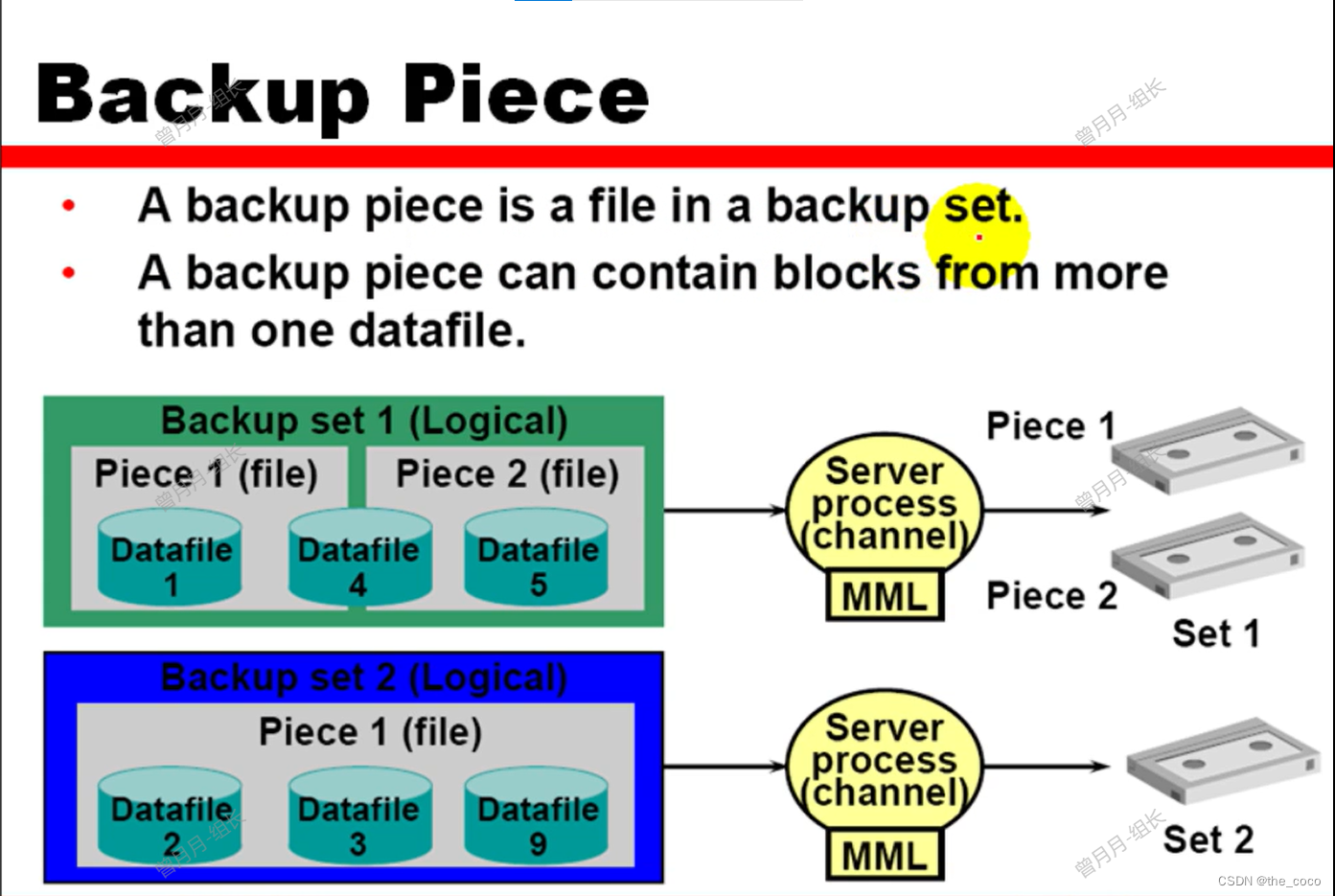
【小布_ORACLE笔记】Part11-1--RMAN Backups
Oracle的数据备份于恢复RMAN Backups 学习第11章需要掌握: 一.RMAN的备份类型 二.使用backup命令创建备份集 三.创建备份文件 四.备份归档日志文件 五.使用RMAN的copy命令创建镜像拷贝 文章目录 Oracle的数据备份于恢复RMAN Backups1.RMAN Backup Concepts&#x…...
卷积神经网络-3D医疗影像识别
文章目录 一、前言二、前期工作1. 介绍2. 加载和预处理数据 二、构建训练和验证集三、数据增强四、数据可视化五、构建3D卷积神经网络模型六、训练模型七、可视化模型性能八、对单次 CT 扫描进行预测 一、前言 我的环境: 语言环境:Python3.6.5编译器&a…...
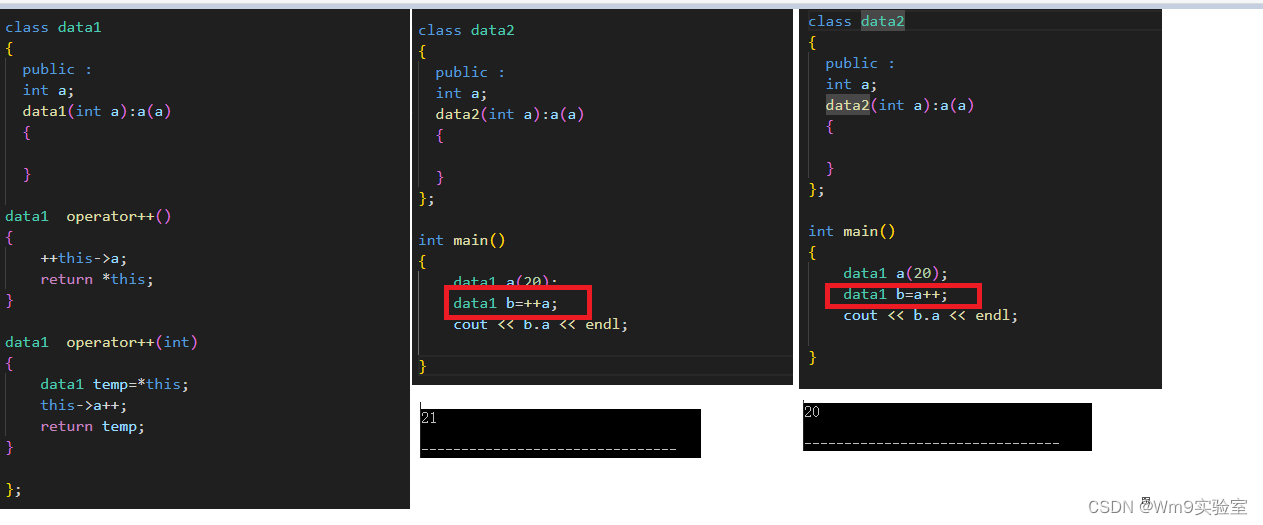
C++基础 -33- 单目运算符重载
单目运算符重载格式 a和a通过形参确定 data1 operator() {this->a;return *this; }data1 operator(int) {data1 temp*this;this->a;return temp; }举例使用单目运算符重载 #include "iostream"using namespace std;class data1 {public :int a;data1(int…...

[传智杯 #3 初赛] 课程报名
题目描述 传智播客推出了一款课程,并进行了一次促销活动。具体来说就是,课程的初始定价为 v 元;每报名 m 个学员,课程的定价就要提升 a 元。由于课程能够容纳的学生有限,因此报名到 n 人的时候就停止报名。 现在老师…...
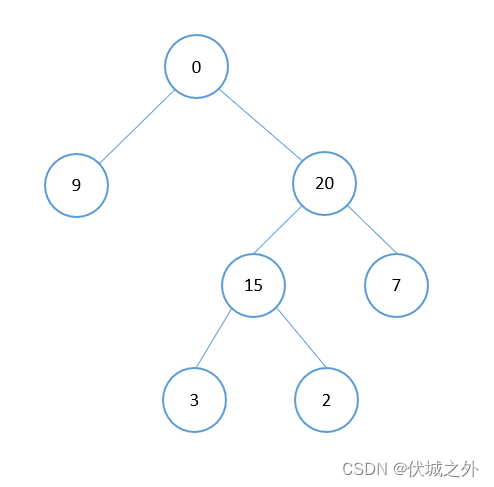
华为OD机试 - 悄悄话(Java JS Python C)
题目描述 给定一个二叉树,每个节点上站一个人,节点数字表示父节点到该节点传递悄悄话需要花费的时间。 初始时,根节点所在位置的人有一个悄悄话想要传递给其他人,求二叉树所有节点上的人都接收到悄悄话花费的时间。 输入描述 给定二叉树 0 9 20 -1 -1 15 7 -1 -1 -1 -1 …...
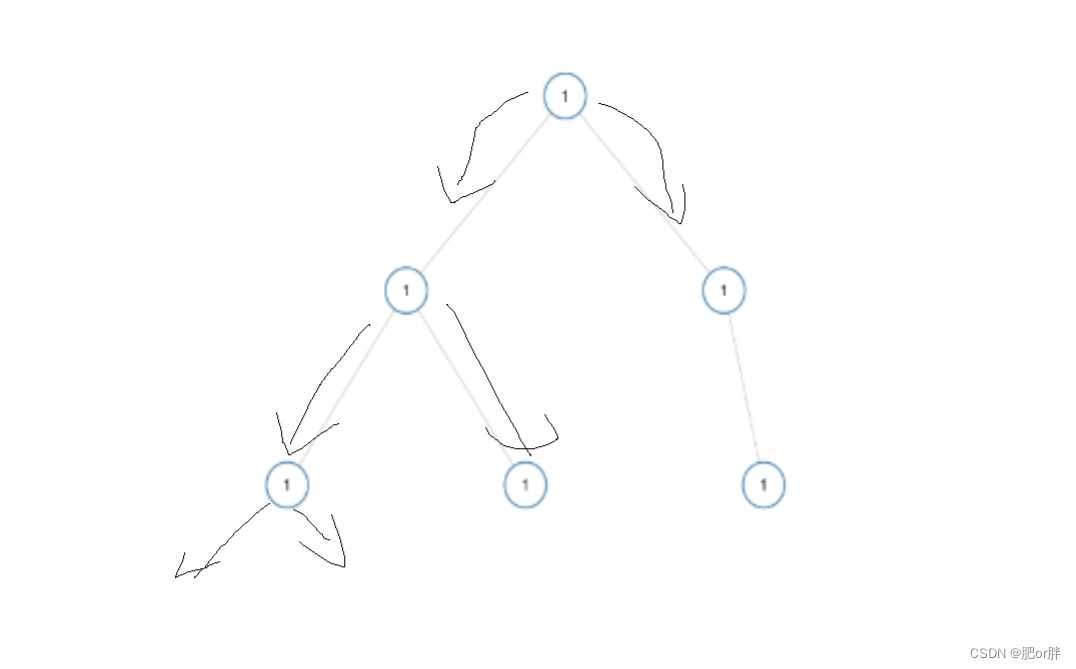
LeetCode - 965. 单值二叉树(C语言,二叉树,配图)
二叉树每个节点都具有相同的值,我们就可以比较每个树的根节点与左右两个孩子节点的值是否相同,如果不同返回false,否则,返回true。 如果是叶子节点,不存在还孩子节点,则这个叶子节点为根的树是单值二叉树。…...
----哈希表--三数之和)
每日一题(LeetCode)----哈希表--三数之和
每日一题(LeetCode)----哈希表–三数之和 1.题目(15. 三数之和) 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所…...

DL中的GPU使用问题
写在前面 在使用GPU进行深度学习训练经常会遇到下面几个问题,这里做一个解决方法的汇总。 🐕Q1🐕:在一个多卡服务器上,指定了cuda:1,但是0号显卡显存还是会被占用一定量的显存。 这个问题很经典的出现场景就…...

Linux命令——watch
watch是周期性的执行下个程序,并全屏显示执行结果 用法: vmfedora:~$ watch --helpUsage:watch [options] commandOptions:-b, --beep beep if command has a non-zero exit-c, --color interpret ANSI color and style sequen…...

力扣题:字符的统计-12.2
力扣题-12.2 [力扣刷题攻略] Re:从零开始的力扣刷题生活 力扣题1:423. 从英文中重建数字 解题思想:有的单词通过一个字母就可以确定,依次确定即可 class Solution(object):def originalDigits(self, s):""":typ…...

从零打造专业GitHub个人资料页:Markdown与动态集成实战指南
1. 项目概述与核心价值 在技术圈子里混了十几年,我越来越觉得,一个开发者的“数字门面”和代码能力同等重要。这个门面,很多时候就是你的GitHub主页。早些年,大家的GitHub个人页面就是个简单的仓库列表,加上一些贡献图…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...

Otter多模态大模型实战:从架构解析到部署应用的完整指南
1. 项目概述:当多模态大模型学会“看”与“说”最近在开源社区里,一个名为Otter的多模态大模型项目引起了我的注意。它来自EvolvingLMMs-Lab,这个实验室的名字就很有意思,“Evolving LMMs”—— 进化中的大型多模态模型。Otter 这…...

5分钟学会创建专业交通网络可视化地图
5分钟学会创建专业交通网络可视化地图 【免费下载链接】transit-map The server and client used in transit map simulations like swisstrains.ch 项目地址: https://gitcode.com/gh_mirrors/tr/transit-map 你想在网页上展示动态的公共交通网络吗?Transit…...

LoRA模型合并实战:多技能大模型融合指南与vLLM+Copaw工具链解析
1. 项目概述:LoRA模型合并的“瑞士军刀” 在AIGC(人工智能生成内容)领域,模型微调是让大语言模型(LLM)或扩散模型适配特定任务、风格或知识库的核心手段。而LoRA(Low-Rank Adaptation࿰…...

CircuitPython串口调试与REPL交互:嵌入式开发的效率倍增器
1. 项目概述:为什么串口交互是嵌入式开发的“生命线”如果你刚开始接触CircuitPython或者任何基于微控制器的嵌入式开发,可能会觉得写代码、上传、看结果这个过程有点“黑盒”。代码上传后,板子默默运行,除了闪烁的LED,…...

免费开源图片去重工具:AntiDupl.NET完整使用教程
免费开源图片去重工具:AntiDupl.NET完整使用教程 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 还在为电脑中堆积如山的重复图片而烦恼吗?每次…...

3步掌握ADB驱动安装:Windows平台最简Android连接方案
3步掌握ADB驱动安装:Windows平台最简Android连接方案 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/la/Lat…...