TensorRT之LeNet5部署(onnx方式)
文章目录
- 前言
- LeNet-5部署
- 1.ONNX文件导出
- 2.TensorRT构建阶段(TensorRT模型文件)
- 🧁创建Builder
- 🍧创建Network
- 🍭使用onnxparser构建网络
- 🍬优化网络
- 🍡序列化模型
- 🍩释放资源
- 3.TensorRT运行时阶段(推理)
- 🍄创建Runtime
- 🍅反序列化模型
- 🍒创建ExecutionContext
- 🍓执行推理
- 🍎释放资源
- 4.编译和运行
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
本文记录一下TensorRT部署流程,上一篇使用wts文件构造网络结构,这篇会使用ONNX构造网络。关于TensorRT的基础知识,参考前一篇文章:TensorRT部署(wts)
LeNet-5部署
1.ONNX文件导出
关于LeNet-5网络模型的搭建、训练以及保存参考上面的链接文字。这一步导出ONNX文件默认你已经有了LeNet-5的权重文件(pth)。
导出ONNX文件源程序如下:
import torch
from model import LeNet# s实例化网络
model = LeNet()
# 加载网络模型
model.load_state_dict(torch.load('Lenet.pth'))model.eval()input_names = ['input']
output_names = ['output']# 创建一个示例输入
input_data = torch.randn(1, 1, 28, 28) # 根据您的模型需要调整输入尺寸# 定义输出路径
onnx_file_path = "LeNet.onnx"# 转换为 ONNX 模型
torch.onnx.export(model, input_data, onnx_file_path, input_names=input_names, output_names=output_names, verbose=True)
将导出的ONNX文件使用Netron打开,Netron链接:Netron
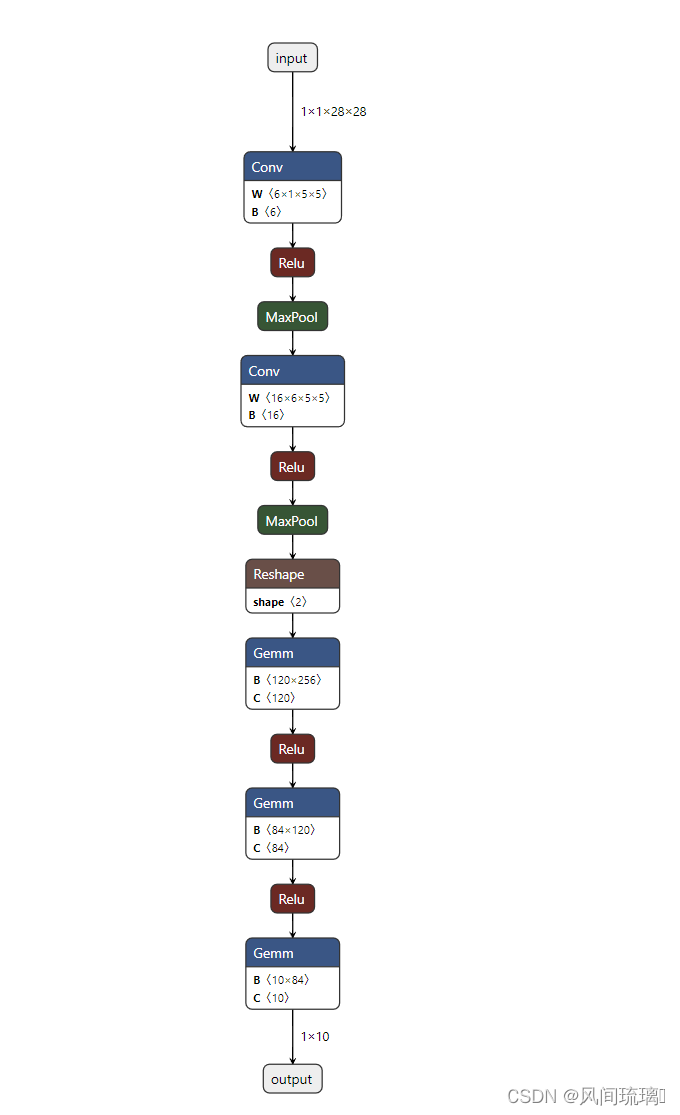
可以看到和我们在model中定义的网络结构是一样的。
2.TensorRT构建阶段(TensorRT模型文件)
🧁创建Builder
// 创建TensorRT的Builder对象
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger));
if (!builder)
{std::cerr << "Failed to create builder" << std::endl;return -1;
}
使用了TensorRT的createInferBuilder函数创建了一个nvinfer1::IBuilder实例,并将其包装在std::unique_ptr中,这样可以确保在作用域结束时正确释放资源。
std::unique_ptr 的模板参数是 nvinfer1::IBuilder,因此 builder 的类型是 std::unique_ptr< nvinfer1::IBuilder>。这表示 builder 是一个独占所有权的智能指针,管理一个 nvinfer1::IBuilder 类型的对象。在上一节中创建Builder如下
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
这里 builder 是一个原始指针,你需要手动管理其生命周期和释放内存。这容易导致内存泄漏或悬挂指针问题,因为你需要确保在使用完 builder 后调用 delete 或相应的释放函数。
这里使用了 std::unique_ptr,它是一个 C++ 智能指针,能够自动管理对象的生命周期。当 builder 超出作用域时,std::unique_ptr 会自动释放其拥有的内存。这有助于防止内存泄漏,并提高代码的安全性。
🍧创建Network
在TensorRT中使用builder的成员函数createNetworkV2来构建network。
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{std::cout << "Failed to create network" << std::endl;return -1;
}
创建一个 TensorRT 网络,并使用显式批处理标志。显式批处理允许你在运行推理时动态设置批次大小,而不是在构建引擎时固定批次大小。
🍭使用onnxparser构建网络
// 读取ONNX模型文件
char* onnxPath = "/home/mingfei/codeRT/test/lenet_onnx/LeNet.onnx";
std::ifstream onnxFile(onnxPath, std::ios::binary);
if (!onnxFile)
{std::cerr << "无法打开ONNX模型文件: " << onnxPath << std::endl;return 1;
}// 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnxPath, static_cast<int>(gLogger.getReportableSeverity()));
if (!parsed)
{std::cout << "Failed to parse onnx file" << std::endl;return -1;
}
首先将上面导出的ONNX文件加载进来,然后使用 TensorRT 的 ONNX 解析器进行解析。
createParser函数创建一个 ONNX 解析器对象,这个解析器对象是一个用于解析 ONNX 模型的实例。
inline IParser* createParser(nvinfer1::INetworkDefinition& network, nvinfer1::ILogger& logger)
network:表示 TensorRT 网络的对象。解析器将根据 ONNX 模型的信息构建这个网络。
logger:日志记录器,用于记录解析器操作的日志信息
parseFromFile函数使用解析器解析来自 ONNX 模型文件的模型信息。
virtual bool parseFromFile(const char* onnxModelFile, int verbosity) = 0;
onnxModelFile:ONNX 模型文件的路径,指定要解析的 ONNX 模型文件。
verbosity:解析过程中的详细程度或冗余程度。这通常是一个整数值,用于控制解析器的输出信息的详细级别。
这两个函数的联合使用允许您创建一个 ONNX 解析器对象,然后使用该解析器对象从文件中读取 ONNX 模型并解析出 TensorRT 网络。解析完成后,您就可以使用 TensorRT 的网络进行后续的优化和推理。
🍬优化网络
添加相关Builder 的配置。createBuilderConfig接口被用来指定TensorRT应该如何优化模型。
// 优化网络
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{std::cout << "Failed to create config" << std::endl;return -1;
}// 设置最大batchsize
builder->setMaxBatchSize(1);
// 设置最大工作空间(新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
在示例代码中,仅配置workspace(workspace 就是 tensorrt 里面算子可用的内存空间 )大小、运行时batch size和精度。
🍡序列化模型
使用 TensorRT 的 builder 对象根据配置创建一个序列化的引擎,并将其保存到文件中。
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{std::cout << "Failed to create engine" << std::endl;return -1;
}// 序列化保存engine
std::ofstream engine_file("lenet5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
🍩释放资源
因为使用了智能指针,所以不需要手动释放资源。
构建阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"using namespace nvinfer1;static Logger gLogger;int main()
{// 读取ONNX模型文件char* onnxPath = "/home/mingfei/codeRT/test/lenet_onnx/LeNet.onnx";std::ifstream onnxFile(onnxPath, std::ios::binary);if (!onnxFile){std::cerr << "无法打开ONNX模型文件: " << onnxPath << std::endl;return 1;}// 创建TensorRT的Builder对象auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger));if (!builder){std::cerr << "Failed to create builder" << std::endl;return -1;}// 显性batchconst auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);// 调用builder的createNetworkV2方法创建networkauto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));if (!network){std::cout << "Failed to create network" << std::endl;return -1;}// 创建onnxparser,用于解析onnx文件auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger));// 调用onnxparser的parseFromFile方法解析onnx文件auto parsed = parser->parseFromFile(onnxPath, static_cast<int>(gLogger.getReportableSeverity()));if (!parsed){std::cout << "Failed to parse onnx file" << std::endl;return -1;}// 优化网络auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());if (!config){std::cout << "Failed to create config" << std::endl;return -1;}// 设置最大batchsizebuilder->setMaxBatchSize(1);// 设置最大工作空间(新版本的TensorRT已经废弃了setWorkspaceSize)config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibratorconfig->setFlag(nvinfer1::BuilderFlag::kFP16);// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));if (!plan){std::cout << "Failed to create engine" << std::endl;return -1;}// 序列化保存enginestd::ofstream engine_file("lenet5.engine", std::ios::binary);assert(engine_file.is_open() && "Failed to open engine file");engine_file.write((char *)plan->data(), plan->size());engine_file.close();// 释放资源 // 因为使用了智能指针,所以不需要手动释放资源std::cout << "Engine build success!" << std::endl;return 0;
}3.TensorRT运行时阶段(推理)
在生成Engine文件后,在推理阶段的流程和上一篇的基本是一样的,这里就简单介绍一下,具体的可以参考前面一篇。
🍄创建Runtime
// 创建推理运行时runtime
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(gLogger.getTRTLogger()));
if (!runtime)
{std::cout << "runtime create failed" << std::endl;return -1;
}
🍅反序列化模型
// 反序列化生成engine // 加载模型文件
auto plan = load_engine_file("lenet5.engine");
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
if (!mEngine)
{return -1;
}
🍒创建ExecutionContext
// 创建执行上下文context
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{std::cout << "context create failed" << std::endl;return -1;
}
🍓执行推理
在进行推理之前需要对输入的图片的图片的进行预处理,预处理的操作需要保持在网络训练的时候的操作一样的,如归一化,减均值等。
cv::Mat preprocess(cv::Mat &image)
{// 获取图像的形状(高度、宽度和通道数)int height = image.rows;int width = image.cols;int channels = image.channels();// 打印图像的形状std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;// 使用blobFromImage函数创建blobcv::Mat blob;cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));// 获取图像的形状(高度、宽度和通道数)height = blob.rows;width = blob.cols;channels = blob.channels();// 打印图像的形状std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;return blob;
}
然后将处理后的图片数据转成float的指针类型,为后面的推理做准备。
// 获取blob的数据指针
uchar* ucharData = blob.ptr<uchar>(); // 使用uchar*类型的指针
// 获取图像数据指针
float* data = reinterpret_cast<float*>(ucharData);
然后需要将CPU的数据传输到GPU上进行计算,计算结束后需要将结果传回CPU。
// 执行推理
float prob[OUTPUT_SIZE];
inference(*context, data, prob, 1);// 执行推理
void inference(nvinfer1::IExecutionContext& context, float* input, float* output, int batchSize)
{// 获取与上下文相关的引擎const nvinfer1::ICudaEngine& engine = context.getEngine();// 为输入和输出设备缓冲区创建指针以传递给引擎assert(engine.getNbBindings() == 2);void* buffers[2];// 为了绑定缓冲区,需要知道输入和输出张量的名称const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);// 在设备上创建输入和输出缓冲区CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));// 创建流cudaStream_t stream;CHECK(cudaStreamCreate(&stream));// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));//context.enqueue(batchSize, buffers, stream, nullptr); // 新版本中是enqueueV2context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2// 将推理结果从设备拷贝到主机上:outputCHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);// 释放流和缓冲区cudaStreamDestroy(stream);CHECK(cudaFree(buffers[inputIndex]));CHECK(cudaFree(buffers[outputIndex]));
}
然后就是对结果进行处理,如softmax,这里由于的做的是分类模型,所以需要找到置信度最大的概率和标签。
// softmax
std::vector<float> result = softmax(prob);// 找到最大值和索引
auto maxElement = std::max_element(result.begin(), result.end());
float maxValue = *maxElement;
int maxIndex = std::distance(result.begin(), maxElement);// 打印结果
std::cout << "probability: " << maxValue << std::endl;
std::cout << "Number is : " << maxIndex << std::endl;
// 显示
std::ostringstream text;
text << "Predict: " << maxIndex;
cv::resize(image,image,cv::Size(400,400));
cv::putText(image, text.str(), cv::Point(10, 50), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1, cv::LINE_AA);
// 保存图像到当前路径
cv::imwrite("output_image.jpg", image);
🍎释放资源
因为使用了unique_ptr,所以不需要手动释放
运行时阶段源程序
#include <iostream>
#include <fstream>
#include <cassert>
#include <vector>
#include <algorithm>#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>#include <NvInfer.h>
#include <NvOnnxParser.h> // onnxparser头文件
#include "logging.h"static Logger gLogger;static const int INPUT_H = 28;
static const int INPUT_W = 28;
static const int OUTPUT_SIZE = 10;const char* INPUT_BLOB_NAME = "input";
const char* OUTPUT_BLOB_NAME = "output";#define CHECK(status) \do\{\auto ret = (status);\if (ret != 0)\{\std::cerr << "Cuda failure: " << ret << std::endl;\abort();\}\} while (0)// 加载模型文件
std::vector<unsigned char> load_engine_file(const std::string &file_name)
{std::vector<unsigned char> engine_data;// 打开二进制文件流std::ifstream engine_file(file_name, std::ios::binary);// 检查文件是否成功打开assert(engine_file.is_open() && "Unable to load engine file.");// 定位到文件末尾以获取文件长度engine_file.seekg(0, engine_file.end);int length = engine_file.tellg();// 调整容器大小以存储整个文件的数据engine_data.resize(length);// 重新定位到文件开头engine_file.seekg(0, engine_file.beg);// 读取文件数据到容器中engine_file.read(reinterpret_cast<char *>(engine_data.data()), length);return engine_data;
}cv::Mat preprocess(cv::Mat &image)
{// 获取图像的形状(高度、宽度和通道数)int height = image.rows;int width = image.cols;int channels = image.channels();// 打印图像的形状std::cout << "Image Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;// 使用blobFromImage函数创建blobcv::Mat blob;cv::dnn::blobFromImage(image, blob, 1.0 / 255.0, cv::Size(28, 28), cv::Scalar(0.5));// 获取图像的形状(高度、宽度和通道数)height = blob.rows;width = blob.cols;channels = blob.channels();// 打印图像的形状std::cout << "Blob Shape: Height = " << height << ", Width = " << width << ", Channels = " << channels << std::endl;return blob;
}
std::vector<float> softmax(const float input[10])
{std::vector<float> result(10);float sum = 0.0;// Calculate e^x for each element in the input arrayfor (int i = 0; i < 10; ++i) {result[i] = std::exp(input[i]);sum += result[i];}// Normalize the values by dividing each element by the sumfor (float& value : result) {value /= sum;}return result;
}// 执行推理
void inference(nvinfer1::IExecutionContext& context, float* input, float* output, int batchSize)
{// 获取与上下文相关的引擎const nvinfer1::ICudaEngine& engine = context.getEngine();// 为输入和输出设备缓冲区创建指针以传递给引擎assert(engine.getNbBindings() == 2);void* buffers[2];// 为了绑定缓冲区,需要知道输入和输出张量的名称const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);// 在设备上创建输入和输出缓冲区CHECK(cudaMalloc(&buffers[inputIndex], batchSize * 1 * INPUT_H * INPUT_W * sizeof(float)));CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));// 创建流cudaStream_t stream;CHECK(cudaStreamCreate(&stream));// 将输入批量数据异步 DMA 到设备,异步对批量进行推理,然后异步 DMA 输出回主机CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 1 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));//context.enqueue(batchSize, buffers, stream, nullptr); // 新版本中是enqueueV2context.enqueueV2(buffers, stream, nullptr); // 新版本中是enqueueV2// 将推理结果从设备拷贝到主机上:outputCHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);// 释放流和缓冲区cudaStreamDestroy(stream);CHECK(cudaFree(buffers[inputIndex]));CHECK(cudaFree(buffers[outputIndex]));
}int main()
{// 读取图像cv::Mat image = cv::imread("/home/mingfei/codeRT/test/lenet_onnx/8.jpg");// 检查图像是否成功加载if (image.empty()) {std::cerr << "Error: Unable to read the image." << std::endl;return -1;}// 创建推理运行时runtimeauto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(gLogger.getTRTLogger()));if (!runtime){std::cout << "runtime create failed" << std::endl;return -1;}// 反序列化生成engine // 加载模型文件auto plan = load_engine_file("lenet5.engine");// 反序列化生成engineauto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));if (!mEngine){return -1;}// 创建执行上下文contextauto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());if (!context){std::cout << "context create failed" << std::endl;return -1;}// 图像预处理cv::Mat blob = preprocess(image);// 获取blob的数据指针uchar* ucharData = blob.ptr<uchar>(); // 使用uchar*类型的指针// 获取图像数据指针float* data = reinterpret_cast<float*>(ucharData);// 执行推理float prob[OUTPUT_SIZE];inference(*context, data, prob, 1);// softmaxstd::vector<float> result = softmax(prob);// 找到最大值和索引auto maxElement = std::max_element(result.begin(), result.end());float maxValue = *maxElement;int maxIndex = std::distance(result.begin(), maxElement);// 打印结果std::cout << "probability: " << maxValue << std::endl;std::cout << "Number is : " << maxIndex << std::endl;// 显示std::ostringstream text;text << "Predict: " << maxIndex;cv::resize(image,image,cv::Size(400,400));cv::putText(image, text.str(), cv::Point(10, 50), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1, cv::LINE_AA);// 保存图像到当前路径cv::imwrite("output_image.jpg", image);// 释放资源 // 因为使用了unique_ptr,所以不需要手动释放return 0;
}
4.编译和运行
整个工程如下所示:
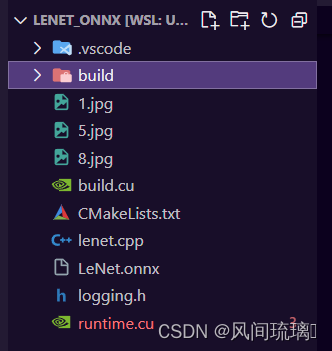
使用CMakeLists.txt来构建整个工程,lenet.cpp相当于集成了build.cu和runtime.cu,然后将生成的文件保存在build目录下。
- 生成可执行程序:
cmake -S . -B build (–> Makefile)
cmake --build build (–>可执行程序) - 运行可执行程序:
./build/build
./build/runtime
CMakeLists.txt如下,相较于上一个wts工程,需要添加nvonnxparser库的链接,其他基本是一样的。
cmake_minimum_required(VERSION 3.10)# 支持c++和cuda编译(nvcc)
project(lenet5 LANGUAGES CXX CUDA) add_definitions(-std=c++11)option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/usr/include/x86_64-linux-gnu/)
link_directories(/usr/lib/x86_64-linux-gnu/)# opencvfind_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})# 生成engine
add_executable(build_engine ${PROJECT_SOURCE_DIR}/build.cu)
target_link_libraries(build_engine nvinfer)
target_link_libraries(build_engine cudart)
target_link_libraries(build_engine nvonnxparser)
target_link_libraries(build_engine ${OpenCV_LIBS})# predict
add_executable(runtime ${PROJECT_SOURCE_DIR}/runtime.cu)
target_link_libraries(runtime nvinfer)
target_link_libraries(runtime cudart)
target_link_libraries(runtime nvonnxparser)
target_link_libraries(runtime ${OpenCV_LIBS})add_definitions(-O2 -pthread)运行结果如下:


结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。
相关文章:
TensorRT之LeNet5部署(onnx方式)
文章目录 前言LeNet-5部署1.ONNX文件导出2.TensorRT构建阶段(TensorRT模型文件)🧁创建Builder🍧创建Network🍭使用onnxparser构建网络🍬优化网络🍡序列化模型🍩释放资源 3.TensorRT运行时阶段(推理)&#x…...
Xilinx FPGA平台DDR3设计详解(二):DDR SDRAM组成与工作过程
本文主要介绍一下DDR SDRAM的基本组成以及工作过程,方便大家更好的理解和掌握DDR的控制与读写。 一、DDR SDRAM的基本组成 1、SDRAM的基本单元 SDRAM的基本单元是一个CMOS晶体管和一个电容组成的电路。 晶体管最上面的一端,称作栅极,通过…...
 属性包装器详解)
ios(swiftui) 属性包装器详解
目录 1. State 2. Binding 3. ObservedObject 和Published 4. StateObject 5. EnvironmentObject和Environment 6. AppStorage 在 SwiftUI 中,属性包装器用于增强和管理视图的状态,以及处理视图与数据模型之间的绑定和交互。下面是一些常见…...
)
【智能家居】面向对象编程OOP和设计模式(工厂模式)
面向对象编程 类和对象 面向对象编程和面向过程编程区别 设计模式 软件设计模式按类型分 工厂模式 面向对象编程 面向对象编程(Object-Oriented Programming,OOP)是一种程序设计范式,其中程序被组织成对象的集合,每…...

Docker安装Memcached+Python调用
简介:Memcached是一个通用的分布式内存缓存系统。它通常用于通过在RAM中缓存数据和对象来加速动态数据库驱动的网站,以减少必须读取外部数据源(如数据库或API)的次数。Memcached的API提供了一个分布在多台机器上的非常大的哈希表。…...

网页开发 HTML
目录 HTML概述 HTML结构 HTML标签语法 基本标签 标题标签 换行标签 段落标签 文本格式化标签 特殊符号 div和span标签 超链接标签 锚点 img标签 列表标签 表格标签 表单标签 HTML概述 HTML,即超文本标记语言(HyperText Markup Language …...
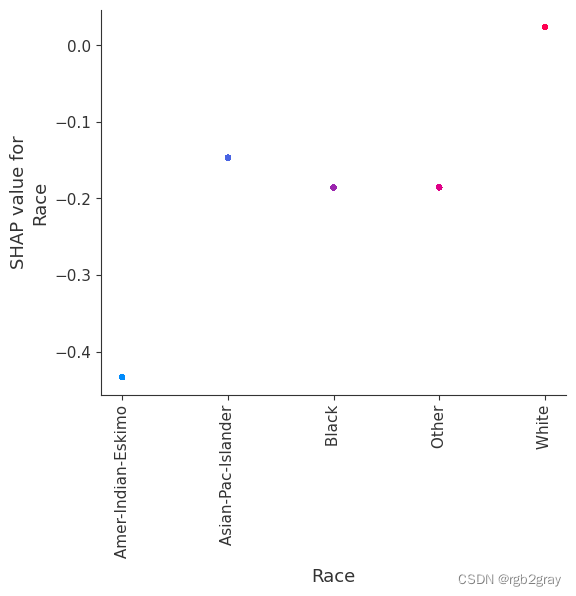
SHAP(五):使用 XGBoost 进行人口普查收入分类
SHAP(五):使用 XGBoost 进行人口普查收入分类 本笔记本演示了如何使用 XGBoost 预测个人年收入超过 5 万美元的概率。 它使用标准 UCI 成人收入数据集。 要下载此笔记本的副本,请访问 github。 XGBoost 等梯度增强机方法对于具有…...

LeetCode 8 字符串转整数
题目描述 字符串转换整数 (atoi) 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C 中的 atoi 函数)。 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空格检查下一…...

前缀和 LeetCode1423. 可获得的最大点数
几张卡牌 排成一行,每张卡牌都有一个对应的点数。点数由整数数组 cardPoints 给出。 每次行动,你可以从行的开头或者末尾拿一张卡牌,最终你必须正好拿 k 张卡牌。 你的点数就是你拿到手中的所有卡牌的点数之和。 给你一个整数数组 cardPoi…...
探索意义的深度:自然语言处理中的语义相似性
一、说明 语义相似度,反应出计算机对相同内容,不同表达的识别能力。因而识别范围至少是个句子,最大范围就是文章,其研究方法有所区别。本文将按照目前高手的研究成绩,作为谈资介绍给诸位。 二、语义相似度简介 自然语言…...

WT2605-24SS高品质录音语音芯片:实时输出、不保存本地,引领音频技术新潮流
随着科技的快速发展,高品质音频技术成为了现代社会不可或缺的一部分。在这个追求高品质、高效率的时代,唯创知音推出的WT2605-24SS高品质录音芯片,以其独特的功能和卓越的性能,引领着音频技术的新潮流。 首先,WT2605-…...

Git 合并冲突解决步骤
Git 合并冲突解决步骤 1. 找到并打开冲突文件 定位到发生冲突的文件。可以通过 Git 的命令行输出找到这些文件。例如: pom.xmlsrc/main/java/com/zzm/config/SecurityConfig.javasrc/main/java/com/zzm/service/chat/UserConversationsServiceImpl.javasrc/main/…...
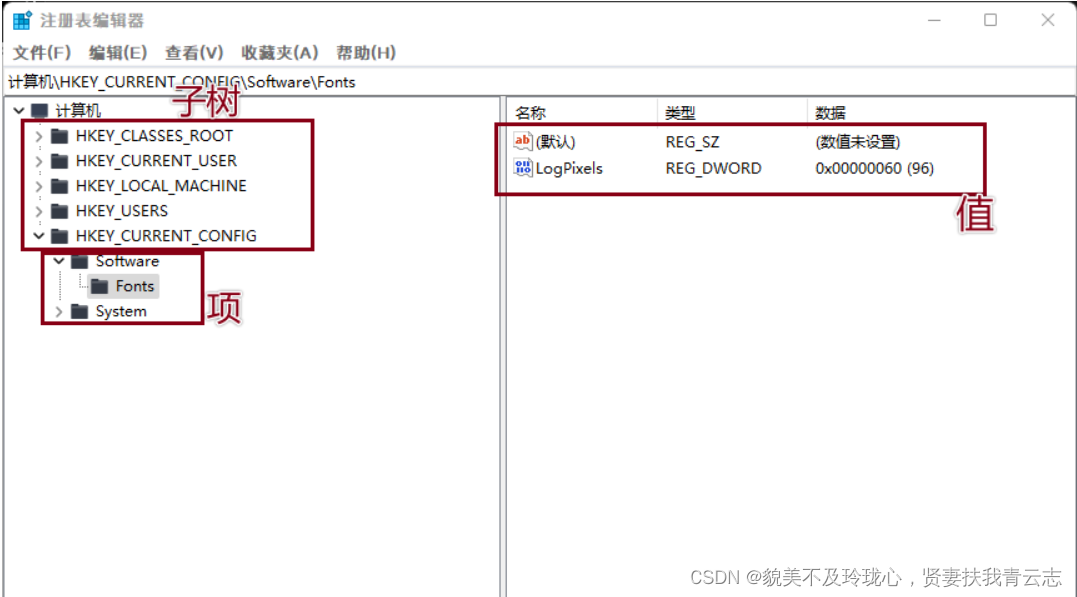
Windows核心编程 注册表
目录 注册表概述 打开关闭注册表 创建删除子健 查询写入删除键值 子健和键值的枚举 常用注册表操作 注册表概述 注册表是Windows操作系统、硬件设备以及客户应用程序得以正常运行和保存设置的核心"数据库",也可以说是一个非常巨大的树状分层结构的…...
【算法专题】二分查找
二分查找 二分查找1. 二分查找2. 在排序数组中查找元素的第一和最后一个位置3. 搜索插入位置4. x 的平方根5. 山脉数组的峰顶索引6. 寻找峰值7. 寻找旋转排序数组中的最小值8. 点名 二分查找 1. 二分查找 题目链接 -> Leetcode -704.二分查找 Leetcode -704.二分查找 题…...

中国消费电子行业发展趋势及消费者需求洞察|徐礼昭
一、引言 近年来,随着科技的飞速发展,消费电子行业面临着前所未有的挑战与机遇。本文将从行业发展趋势、消费者需求洞察以及企业数字化转型的方向和动作三个方面,对消费电子行业进行深入剖析。 二、消费电子行业发展趋势 5G技术的普及和应…...
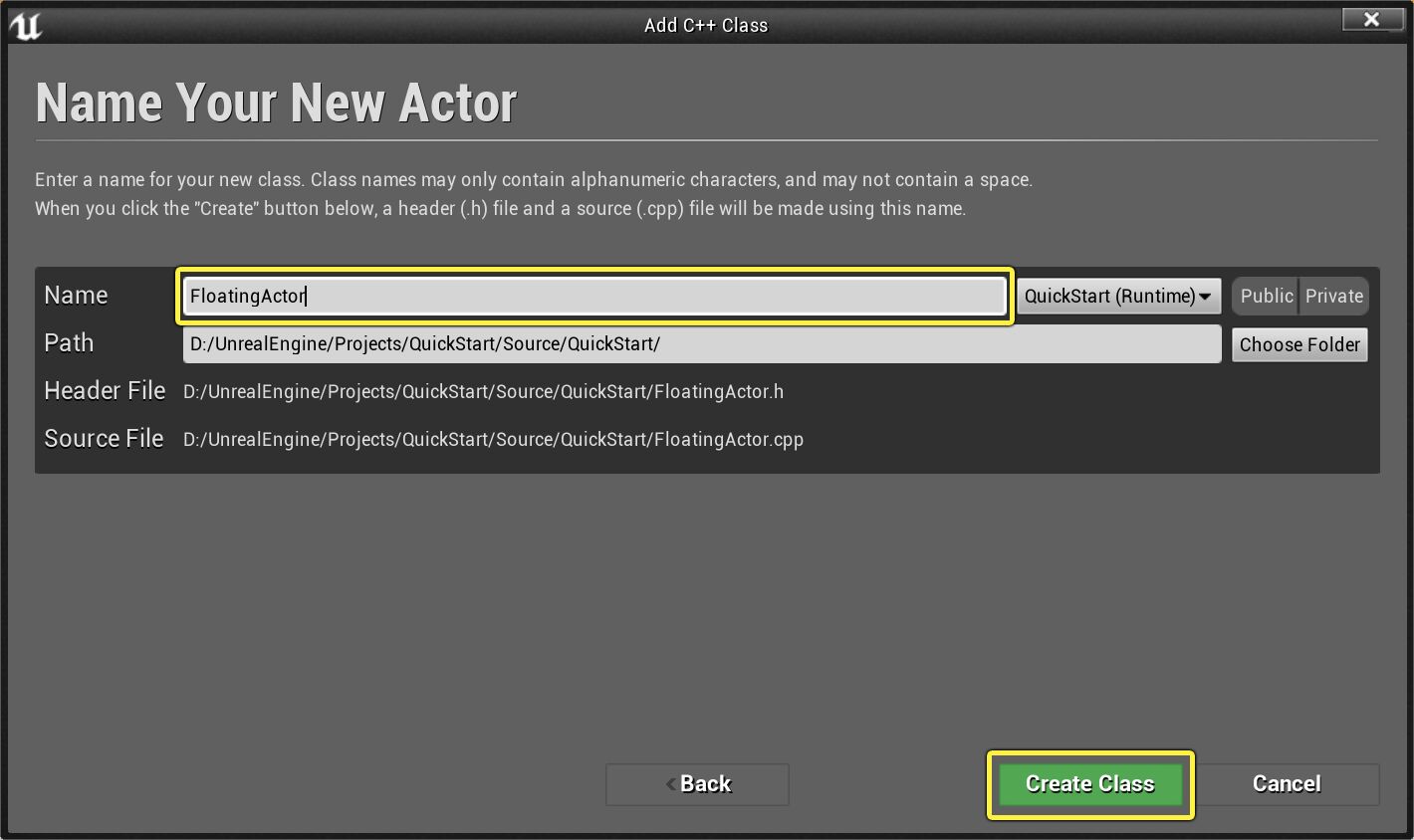
UE学习C++(1)创建actor
创建新C类 在 虚幻编辑器 中,点击 文件(File) 下拉菜单,然后选择 新建C类...(New C Class...) 命令: 此时将显示 选择父类(Choose Parent Class) 菜单。可以选择要扩展的…...

【CTA认证】Android8实现android6以下的应用运行时也要申请权限
需求 CTA入网认证,要求低版本比如Android6以下的应用,运行时,也需要有运行时权限(Runtime Permission)功能,不能默认就取到权限,必须人工在设置中打开才可。 环境 Android 8 实现 frameworks 修改思路是所有APP都…...

gRPC Java、Go、PHP使用例子
文章目录 1、Protocol Buffers定义接口1.1、编写接口服务1.2、Protobuf基础数据类型 2、服务器端实现2.1、生成gRPC服务类2.2、Java服务器端实现 3、java、go、php客户端实现3.1、Java客户端实现3.2、Go客户端实现3.3、PHP客户端实现 本文例子是在Window平台测试,Ja…...
———px,em,rem,vw,vh之间的区别)
前端知识笔记(十九)———px,em,rem,vw,vh之间的区别
一,px(像素):像素是屏幕上显示的最小单位,它是固定的,不随页面缩放而改变大小。在响应式设计中,使用像素单位可能会导致布局在不同屏幕尺寸上显示不一致。例如:现在在你电脑上一个字…...
docker部署frp穿透内网
文章目录 (1)部署frps服务器(2)部署frpc客户端(3)重启与访问frp(4)配置nginx反向代理 (1)部署frps服务器 docker安装参考文档:docker基本知识 1…...

如何在PUBG中实现90%的压枪稳定性提升?揭秘罗技鼠标宏的隐藏技巧
如何在PUBG中实现90%的压枪稳定性提升?揭秘罗技鼠标宏的隐藏技巧 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 你是否曾在《绝地求…...

YouTube 视频翻译中文:基于 Whisper + FFmpeg 的自动化流水线实战
一、背景 YouTube 视频翻译中文,本质上是将外语视频通过语音识别(ASR)、文本翻译(NMT)、语音合成(TTS)三个环节处理后,重新合成为中文版本。每一个环节都有成熟的开源工具链支持&am…...

国产LDO CN86L028实战:解决图像传感器电源噪声,兼容BL8062
1. 项目概述与核心需求解析最近在折腾一个老式录像机的修复与升级项目,目标很明确:提升其图像采集的稳定性。这台设备在运行中,画面时不时会出现条纹干扰,声音里也夹杂着微弱的底噪,尤其是在电源波动较大的环境下&…...
引发的音素错位故障)
ElevenLabs旁遮普语TTS突然失真?3步定位Gurmukhi Unicode变体(U+0A02/U+0A3C/U+0A4D)引发的音素错位故障
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs旁遮普文语音合成异常现象综述 ElevenLabs 目前官方文档明确标注支持旁遮普语(Gurmukhi script, language code: pa),但在实际调用其 REST API 进行语音合…...

动力电池技术迭代:从能量密度到系统集成的多维竞争
1. 动力电池行业的“肌肉”意味着什么最近,行业里关于宁德时代又推出新产品的消息传得沸沸扬扬。作为在这个行业里摸爬滚打了十几年的老兵,每次看到这样的新闻,我的第一反应不是“又来了”,而是“这次他们想解决什么问题ÿ…...

Taotoken用量看板如何帮助团队管理大模型API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理大模型API成本 作为团队的技术负责人,在引入大模型能力支持多个项目时,一…...

TestableMock在Android项目中的应用:完整配置与最佳实践
TestableMock在Android项目中的应用:完整配置与最佳实践 【免费下载链接】testable-mock 换种思路写Mock,让单元测试更简单 项目地址: https://gitcode.com/gh_mirrors/te/testable-mock TestableMock是一款创新的单元测试Mock工具,专…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

Programming Bitcoin最佳实践:10个核心编程技巧助你从零掌握比特币开发 [特殊字符]
Programming Bitcoin最佳实践:10个核心编程技巧助你从零掌握比特币开发 🚀 【免费下载链接】programmingbitcoin Repository for the book 项目地址: https://gitcode.com/gh_mirrors/pr/programmingbitcoin 想要深入理解比特币技术并掌握区块链编…...

3分钟搞定Figma中文界面:设计师必备的终极汉化方案
3分钟搞定Figma中文界面:设计师必备的终极汉化方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 面对Figma满屏的英文界面感到困扰吗?专业术语看不懂、操作按钮…...