2023-02-10 - 5 文本搜索
与其他需要精确匹配的数据不同,文本数据在前期的索引构建和搜索环节都需要进行额外的处理,并且在匹配环节还要进行相关性分数计算。本章将详细介绍文本搜索的相关知识。
本章首先从总体上介绍文本的索引建立过程和搜索过程,然后介绍分析器的构成和使用。ES内置的分析器对于中文的使用略显尴尬,因此本章还会介绍当下使用较多的中文分析器,然后再介绍使用中文分析器实现的拼音搜索功能。ES对于文本搜索结果提供了高亮显示功能,本章的最后会结合实例对其进行详细介绍。
1 文本搜索简介
作为一款搜索引擎框架,文本搜索是其核心功能。ES在文本索引的建立和搜索过程中依赖两大组件,即Lucene和分析器。其中,Lucene负责进行倒排索引的物理构建,分析器负责在建立倒排索引前和搜索前对文本进行分词和语法处理。本节将文本的搜索功能拆分成索引建立过程和搜索过程分别进行介绍。
1 文本的索引建立过程
为了完成对文本的快速搜索,ES使用了一种称为“倒排索引”的数据结构。倒排索引中的所有词语存储在词典中,每个词语又指向包含它的文档信息列表。
假设需要对下面两个酒店的信息进行倒排索引的创建:
- 文档ID为001,酒店名称为“金都嘉怡假日酒店”;
- 文档ID为002,酒店名称为“金都欣欣酒店”。
首先,ES将文档交给分析器进行处理,处理的过程包括字符过滤、分词和分词过滤,最终的处理结果是文档内容被表示为一系列关键词信息的集合。这里的关键词信息指的是关键词本身以及它在文档中出现的位置信息和词性信息,如图5.1所示为文档001的分析结果示意图。
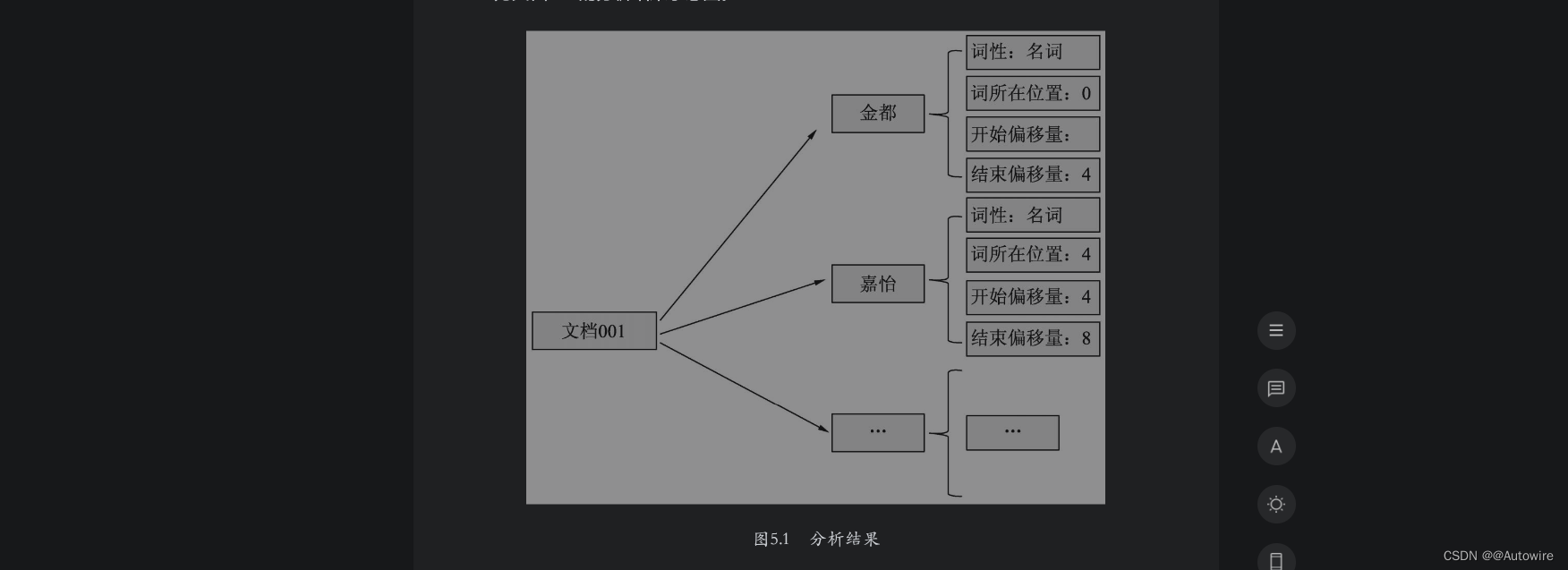
其次,ES根据分析结果建立文档-词语矩阵,用以表示词语和文档的包含关系,本例中的文档-词语矩阵如图5.2所示。
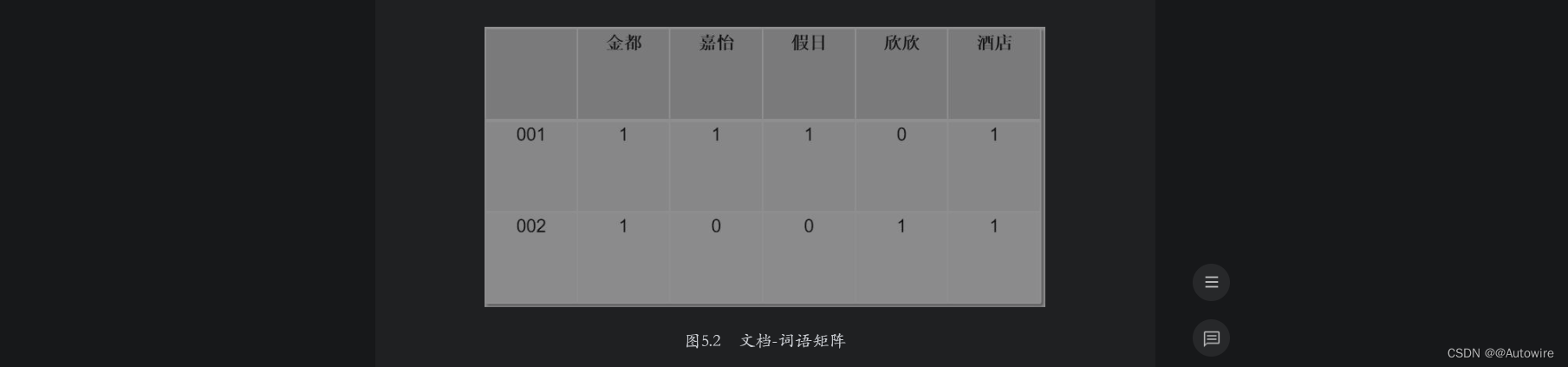
通过上面的文档-词语矩阵可知,ES从文档001中提取出4个词语,从文档002中提取出3个词语。
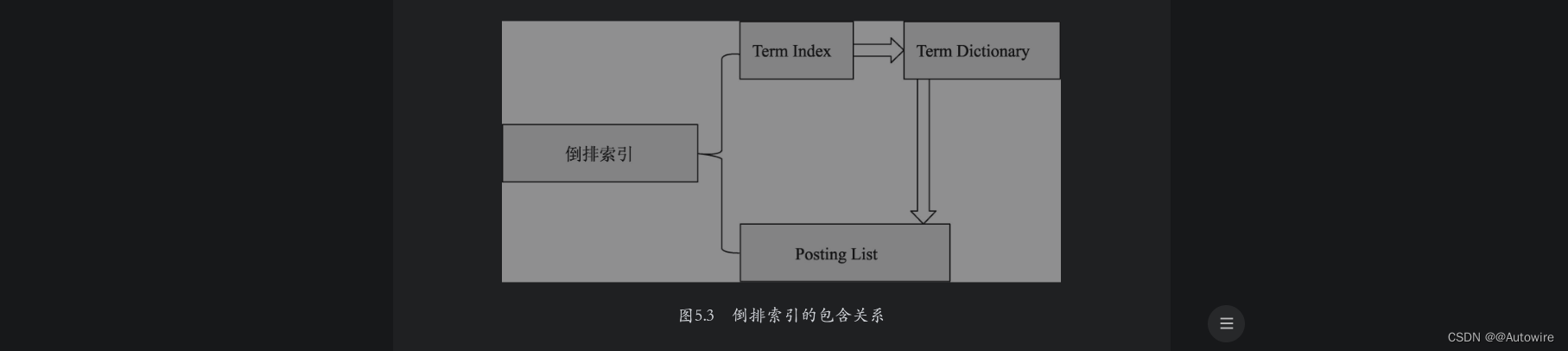
文档-词语矩阵建立完成之后,接着需要建立基于词语的倒排索引。ES会遍历文档词语矩阵中的每一个词语,然后将包含该词语的文档信息与该词语建立一种映射关系。映射关系中的词语集合叫作Term Dictionary,即“词典”。映射中的文档集合信息不仅包含文档ID,还包含词语在文档中的位置和词频信息,包含这些文档信息的结构叫作Posting List。对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的词语集合,能否快速定位某个词语,直接影响搜索时的响应速度。因此需要一种高效的数据结构对映射关系中的词语集合进行索引,这种结构叫作Term Index。上述3种结构结合在一起就构成了ES的倒排索引结构,倒排索引与三者之间的逻辑关系如图5.3所示。
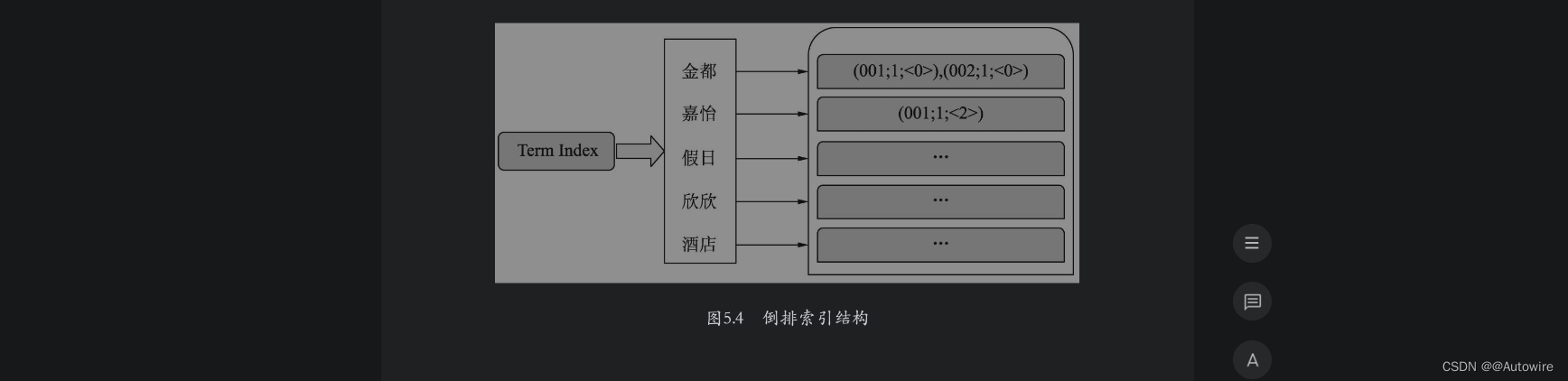
本例中的倒排索引结构如图5.4所示。
2 文本的搜索过程
在ES中,一般使用match查询对文本字段进行搜索。match查询过程一般分为如下几步:
(1)ES将查询的字符串传入对应的分析器中,分析器的主要作用是对查询文本进行分词,并把分词后的每个词语变换为对应的底层lucene term查询。
(2)ES用term查询在倒排索引中查找每个term,然后获取一组包含该term的文档集合。(3)ES根据文本相关度对每个文档进行打分计算,打分完毕后,ES把文档按照相关性进行倒序排序。
(4)ES根据得分高低返回匹配的文档。
如图5.5所示为对酒店索引中搜索“金都嘉怡”的查询流程。
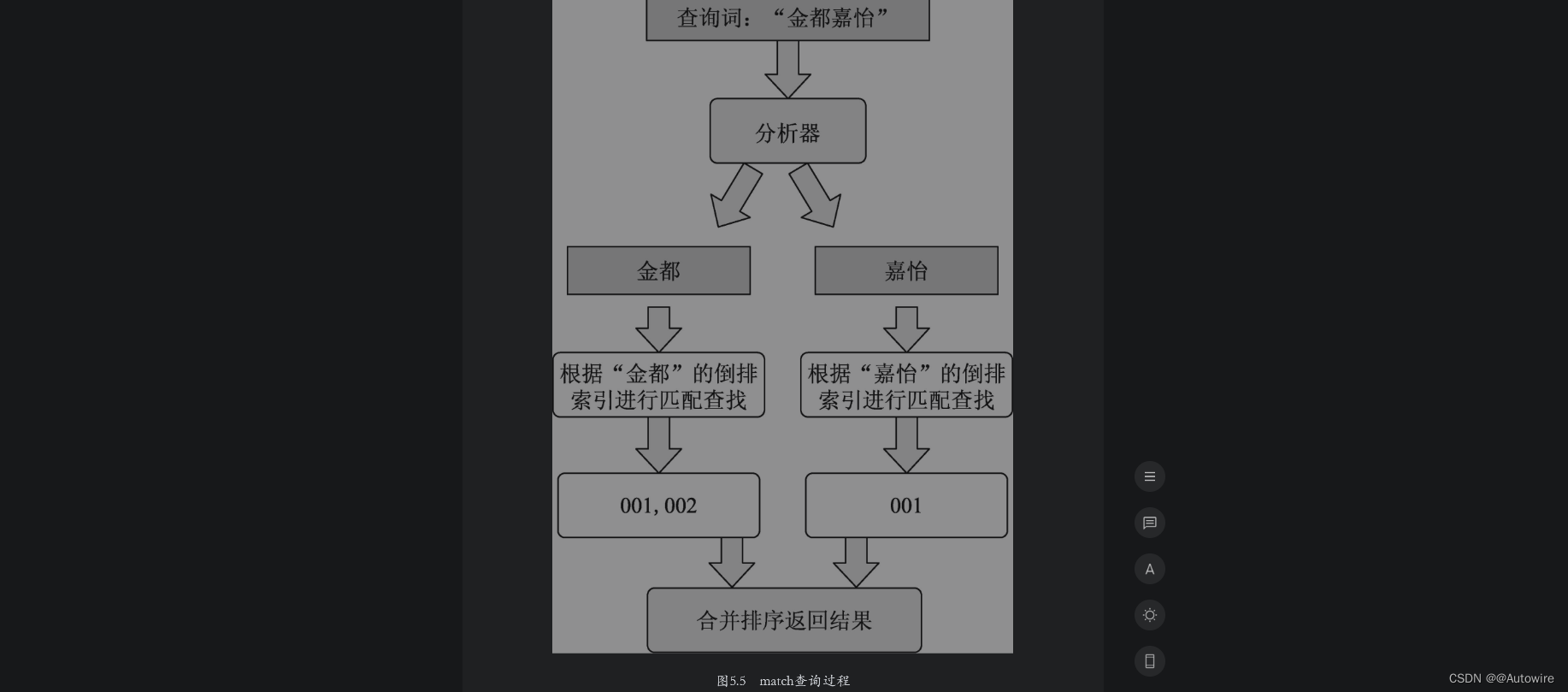
在图5.5中,ES分析器先将查询词切分为“金都”和“嘉怡”,然后分别到倒排索引里查找两个词对应的文档列表并获得了文档001和002,然后根据相关性算法计算文档得分并进行排序,最后将文档集合返回给客户端。
2 分析器简介
5.1节提到,ES在文本字段的索引建立和搜索阶段都会用到分析器。那么,分析器的主要作用是什么?它是由哪几部分构成的?各部分的作用又是什么呢?本节将对这些疑问进行解答。
分析器一般用在下面两个场景中:
- 创建或更新文档时(合称索引时),对相应的文本字段进行分词处理;
- 查询文本字段时,对查询语句进行分词。
ES中的分析器有很多种,但是所有分析器的结构都遵循三段式原则,即字符过滤器、分词器和词语过滤器。其中,字符过滤器可以有0个或多个,分词器必须只有一个,词语过滤器可以有0个或多个。从整体上来讲,三个部分的数据流方向为字符过滤器→分词器→分词过滤器。如图5.6所示为一个分析器的构成示例。
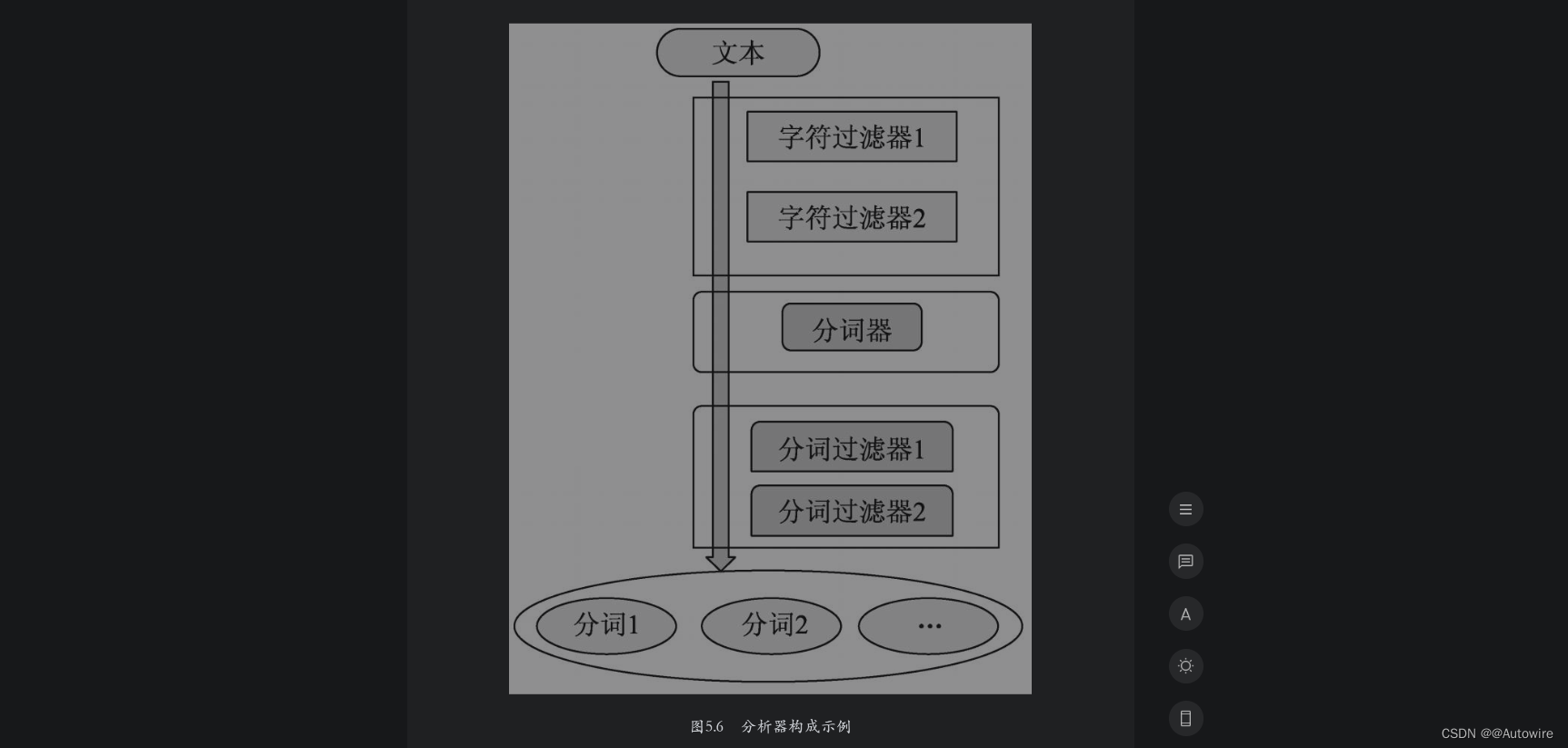
在图5.6中,文本先以字符流的形式流经字符过滤器,在本例中,由两个子字符过滤器组成一个字符过滤器组合。字符过滤器处理完字符后将结果传递给分词器,分词器对文本进行分词处理后将结果又传递给分词过滤器。在本例中,由两个子分词过滤器组成一个分词过滤器组合。最终,分析器输出分词后每个词的信息,至此,一个分析器的处理流程结束。
对于不同的分析器,上述三部分的工作内容是不同的,为了正确匹配,如果在数据写入时指定了某个分析器,那么在匹配查询时也需要设定相同的分析器对查询语句进行分析。
1 字符过滤器
字符过滤器是分析器处理文本数据的第一道工序,它接收原始的字符流,对原始字符流中的字符进行添加、删除或者转换操作,进而改变原始的字符流。例如,原始数据中可能包含来自爬虫的结果,字符过滤器可以去除文本中的HTML标签,也可以将原始文本中的一些特殊字符进行转义,如把“&”转换为and。总而言之,字符过滤器就是对原始文本做一些粗加工的工作,为后续的分词做准备。
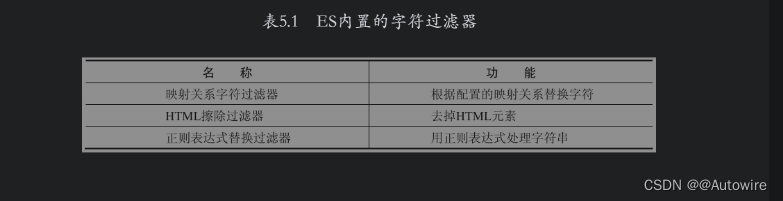
ES内置了一些字符过滤器,其中常用的字符过滤器及其功能如表5.1所示。
2 分词器
分词器在分析器中负责非常重要的一环工作——按照规则来切分词语。对于英文来说,简单的分词器通常是根据空格及标点符号进行切分。然而对于中文分词来说,字符之间往往没有空格,因此采用英文的切分规则是不可取的。中文分词有多种切分方案,在后面的内容中将会介绍这些方案。不同的分词器采用的方案不同,处理后的结果也可能不同。分词器对文本进行切分后,需要保留词语与原始文本之间的对应关系,因此分词器还负责记录每个Token的位置,以及开始和结束的字符偏移量。

3 分词过滤器
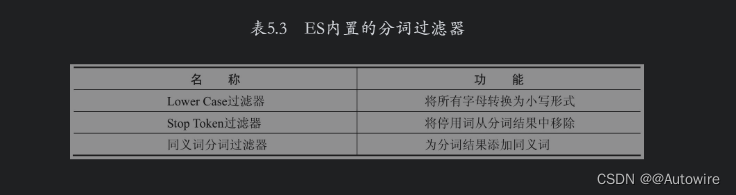
分词过滤器接收分词器的处理结果,并可以将切分好的词语进行加工和修改,进而对分词结果进行规范化、统一化和优化处理。例如,它可以将文本中的字母全部转换为小写形式,还可以删除停用词(如的、这、那等),还可以为某个分词增加同义词。
3 分析器的使用
5.2节介绍了分析器的组成和其工作流程,接下来将介绍分析器的使用。ES提供了分析器的调用API,使用户可以方便地对比不同分析器的分析结果。另外,ES提供了一些开箱即用的内置分析器,这些分析器其实就是字符过滤器、分词器和分词过滤器的组合体,可以在索引建立时和搜索时指定使用这些分析器。当然,如果这些分析器不符合需求,用户还可以自定义分析器。
1 测试分析API
为了更好地理解分析器的运行结果,可以使用ES提供的分析API进行测试。在DSL中可以直接使用参数analyzer来指定分析器的名称进行测试,分析API的请求形式如下:
POST _analyze
{ "analyzer": ${analyzer_name}, //指定分析器名称 "text":${analyzer_text} //待分析文本
}
以下示例使用standard分析器分析一段英文:
POST _analyze
{ "analyzer": "standard", //指定分析器名称为standard "text": "The letter tokenizer is not configurable." //待分析文本
}
上述文本的分析结果如下:
{ "tokens" : [ //分析器将文本切分后的分析结果 { "token" : "the", //将文本切分后的第一个词语 "start_offset" : 0, //该词在文本中的起始偏移位置 "end_offset" : 3, //该词在文本中的结束偏移位置 "type" : "<ALPHANUM>", //词性 "position" : 0 //该词语在原文本中是第0个出现的词语 }, { "token" : "letter", "start_offset" : 4, "end_offset" : 10, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "tokenizer", "start_offset" : 11, "end_offset" : 20, "type" : "<ALPHANUM>", "position" : 2 }, … ]
}
据以上结果可以看到,standard分析器对文本进行分析时,按照空格把上面的句子进行了分词。分析API返回信息的参数说明如下:
·token:文本被切分为词语后的某个词语;
·start_offset:该词在文本中的起始偏移位置;
·end_offset:该词在文本中的结束偏移位置;
·type:词性,各个分词器的值不一样;
·position:分词位置,指明该词语在原文本中是第几个出现的。
start_offset和end_offset组合起来就是该词在原文本中占据的起始位置和结束位置。
下面使用standard分析器分析一段中文文本。
POST _analyze
{ "analyzer": "standard", //使用standard分析器 "text": "金都嘉怡假日酒店"
}
分析结果如下:
{ "tokens" : [ { "token" : "金", //将文本切分后的第一个词语 "start_offset" : 0, //该词在文本中的起始偏移位置 "end_offset" : 1, //该词在文本中的结束偏移位置 "type" : "<IDEOGRAPHIC>", //词性 "position" : 0 //该词语在原文本中是第0个出现的词语 }, { "token" : "都", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, … { "token" : "假", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, … ]
}
如上述结果所示,使用standard分析器对中文进行分析时,由于中文没有空格,无法根据空格进行切分,因此只能按单字进行切分,并给出了每个单字的词性。在中文里,两个单字的词性和每个单字的词性是不同的,因此使用standard分析器分析中文时给出的词性不具备参考价值。不仅如此,ES内置的其他分析器也不适合分析中文,在后面的章节中将介绍专门的中文分析器来解决这些问题。
除了指定分析器进行请求分析外,用户还可以指定某个索引的字段,使用这个字段对应的分析器对目标文本进行分析。下面使用酒店索引的title字段对应的分析器分析文本。
POST /hotel/_analyze
{ //使用酒店索引的title字段对应的分析器分析文本 "field": "title", "text": "金都嘉怡假日酒店"
}
另外,用户还可以在API中自定义分析器对文本进行分析。在下面的示例中自定义了一个分析器,该分析器的分词器使用standard,分词过滤器使用Lower Case,其将分词后的结果转换为小写形式。
GET _analyze
{ "tokenizer": "standard", //使用standard分词器 "filter":["lowercase"], //使用Lower Case分词过滤器 "text": "JinDu JiaYi Holiday Hotel" //待分析文本
}
2 内置分析器
ES已经内置了一些分析器供用户使用,在默认情况下,一个索引的字段类型为text时,该字段在索引建立时和查询时的分析器是standard。standard分析器是由standard分词器、Lower Case分词过滤器和Stop Token分词过滤器构成的。注意,standard分析器没有字符过滤器。除了standard分析器之外,ES还提供了simple分析器、language分析器、whitespace分析器及pattern分析器等,这些分析器的功能如表5.4所示。

另外,用户也可以自定义分析器,并且可以在索引建立或搜索时指定自定义分析器。自定义分析器的使用方式将在后面介绍。
3 索引时使用分析器
文本字段在索引时需要使用分析器进行分析,ES默认使用的是standard分析器。如果需要指定分析器,一种方式是在索引的settings参数中设置当前索引的所有文本字段的分析器,另一种方式是在索引的mappings参数中设置当前字段的分析器。
以下示例在settings参数中指定在酒店索引的所有文本字段中使用simple分析器进行索引构建。
PUT /hotel
{ "settings": { "analysis": { "analyzer": { //指定所有text字段索引时使用simple分析器 "default": { "type": "simple" } } } }, "mappings": { "properties": { … } }
}
以下示例在mappings参数中指定在酒店索引的title字段中使用whitespace分析器进行索引构建。
PUT /hotel
{ "mappings": { "properties": { "title": { "type": "text", //指定索引中的title字段索引时使用whitespace分析器 "analyzer": "whitespace" }, … } }
}
4 搜索时使用分析器
为了搜索时更加协调,在默认情况下,ES对文本进行搜索时使用的分析器和索引时使用的分析器保持一致。当然,用户也可以在mappings参数中指定字段在搜索时使用的分析器。如下示例展示了这种用法:
PUT /hotel
{ "mappings": { "properties": { "title": { "type": "text", "analyzer": "whitespace", //索引时使用whitespace分析器 "search_analyzer": "whitespace" //搜索时使用whitespace分析器 }, … } }
}
注意,这里指定的搜索分析器和索引时的分析器是一致的,但是在大多数情况下是没有必要指定的,因为在默认情况下二者就是一致的。如果指定的搜索分析器和索引时的分析器不一致,则ES在搜索时可能出现有不符合预期的匹配情况,因此该设置在使用时需要慎重选择。
5 自定义分析器
当系统内置的分析器不满足需求时,用户可以使用自定义分析器。在有些场景中,某个文本字段不是自然语言而是在某种规则下的编码。例如,在酒店索引中有个sup_env字段,其值为“APP,H5,WX”,表示当前酒店可以在App、Web端和微信小程序端上显示。假设当前搜索用户使用的是H5或App客户端,则需要过滤掉不支持在这两个客户端上显示的酒店。
首先,需要在索引创建的DSL中定义分析器comma_analyzer,该分析器中只有一个分词组件,该分词组件使用逗号进行词语切分;然后在mappings中使用analyzer参数指定字段sup_env的分析器为定义好的comma_analyzer分析器。具体的DSL如下:
PUT /hotel
{ "settings": { "analysis": { "analyzer": { "comma_analyzer": { //自定义分析器 "tokenizer": "comma_tokenizer" //使用comma_tokenizer分词器 } }, "tokenizer": { //定义分词器 "comma_tokenizer": { "type": "pattern", "pattern": "," //指定切分时使用的分隔符 } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "whitespace", //设定title字段索引时使用whitespace分析器 //设定title字段搜索时使用whitespace分析器 "search_analyzer": "whitespace" }, "sup_env": { "type": "text", //设置sup_env字段使用comma_analyzer分析器 "analyzer": "comma_analyzer" }, … } }
}
下面向酒店索引中插入几条数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title":"金都嘉怡假日酒店","city":"北京","price":337,"sup_env":"APP,H5"}
{"index":{"_index":"hotel","_id":"002"}}
{"title":"金都欣欣酒店","city":"天津","price":200,"sup_env":"H5,WX"}
{"index":{"_index":"hotel","_id":"003"}}
{"title":"金都酒店","city":"北京","price":500,"sup_env":"WX"}
当前用户的客户端为H5或App,当搜索“金都”关键词时应该构建的DSL如下:
GET /hotel/_search
{ "query": { "bool": { "must": [ { //match查询,使用whitespace分析器 "match": { "title": "金都" } }, { //match查询,使用comma_analyzer分析器 "match": { "sup_env": "H5,APP" } } ] } }
}
运行上面的DSL后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ //命中的文档集合 { "_index" : "hotel", "_type" : "_doc", "_id" : "001", "_score" : 1.5761212, "_source" : { "title" : "金都嘉怡假日酒店", … "sup_env" : "App,H5" //切分成App和H5,两部分都与查询词匹配 } }, { "_index" : "hotel", "_type" : "_doc", "_id" : "002", "_score" : 0.7015199, "_source" : { "title" : "金都欣欣酒店", … "sup_env" : "H5,WX" //切分成H5和WX,其中H5与查询词匹配 } } ] }
}
由上面的结果可以看到,索引中有3个文档,只有文档001和文档002对应的酒店标题中包含“金都”且可以在H5或App客户端显示。使用自定义的分词器可以将以逗号分隔的字段进行分词后建立索引,从而在搜索时也使用逗号分隔符进行匹配搜索。
6 中文分析器
对于英文来说,一个文档很容易被切分成关键词的集合,因为除了标点符号外都是由空格把各个英文单词进行分隔的。例如I have a red car,用空格进行切分的结果为I/have/a/red/car。对于中文来说,一般由一个或多个字组合在一起形成一个词语,并且句子中没有词的界限。根据不同的使用场景,对于词语切分颗粒度的需求也是不一样的,请看如下示例。
例句:我来到北京清华大学。
分词结果1:我/来到/北京/清华/华大/大学/清华大学
分词结果2:我/来到/北京/清华大学
上面的两种分词方式都是正确的,它们可以应用在不同的场景中。
中文分词根据实现原理和特点,分词的切分算法主要有两种,即基于词典的分词算法和基于统计的机器学习算法。
1 基于词典的分词算法
基于词典的分词算法是按照某种策略将提前准备好的词典和待匹配的字符串进行匹配,当匹配到词典中的某个词时,说明该词分词成功。该算法是匹配算法中最简单、速度最快的算法,其分词算法分为3种,即正向最大化匹配法、逆向最大化匹配法和双向最大化匹配法。
2 基于统计的机器学习算法
基于统计的机器学习算法的主要思想是事先构建一个语料库,该语料库中是标记好的分词形式的语料,然后统计每个词出现的频率或者词与词之间共现的频率等,基于统计结果给出某种语境下应该切分出某个词的先验概率。后续进行分词时,使用先验概率给出文本应该切分的结果。这类算法中代表的算法有HMM、CRF、深度学习等,比如结巴分词基于HMM算法、HanLP分词工具基于CRF算法等。
当前,中文分词的难点主要有以下三方面:
- 分词标准:不同的分词器使用的分词标准不同,分词的结果也不同。例如,在分词的颗粒度方面,对“中华人民共和国”进行切分时,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是“中华”“人民”“共和国”。
- 分词歧义:使用分词器对文本进行切分,切分后的结果和原来的字面意义不同。例如,在“郑州天和服装厂”中,“天和”是厂名,是一个专有词,“和服”也是一个词,它们共用了“和”字。如果分词器不够精准,则很容易切分成“郑州、和服、服装、服装厂”,但是原文中并没有与“和服”有关的含义,因此这里就产生了歧义。
- 新词识别:新词也称未登录词,即该词没有在词典或者训练语料中出现过。在这种情况下,分词器很难识别出该词。目前,新词识别问题的解决依赖于人们对分词技术和中文结构的进一步认识。
ES通过安装插件的方式来支持第三方分析器。比较常用的第三方中文分析器是HanLP和IK分析器,后面小节将对这两个分析器进行介绍。
3 IK分析器
IK分析器是一个开源的、基于Java语言开发的轻量级的中文分词工具包,它提供了多种语言的调用库。在ES中,IK分析器通过第三方插件的方式来使用,其代码托管到了GitHub上,项目地址为https://github.com/medcl/elasticsearch-analysis-ik。IK分析器实现了词典的冷更新和热更新,用户可以选择适合自己的方式进行词典的更新。
安装:https://blog.csdn.net/zs18753479279/article/details/128902665?spm=1001.2014.3001.5501
下例使用ik_max_word分析器对待测试文本进行分析。
POST _analyze
{ "analyzer": "ik_max_word", //使用ik_max_word中文分析器分析文本 "text": "金都嘉怡假日酒店"
}
分析结果如下:
{ "tokens" : [ { "token" : "金都", //将文本进行切分,“金都”被切分出来 "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 //“金都”是第一个被切分出的词语,索引位置为0 }, { "token" : "嘉", "start_offset" : 2, "end_offset" : 3, "type" : "CN_CHAR", "position" : 1 }, { "token" : "怡", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 2 }, { "token" : "假日酒店", "start_offset" : 4, "end_offset" : 8, "type" : "CN_WORD", "position" : 3 }, { //ik_max_word分析器的词语切分颗粒度较细,将“假日”单独切分了出来 "token" : "假日", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 4 }, { //ik_max_word分析器的词语切分颗粒度较细,将“酒店”单独切分了出来 "token" : "酒店", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 5 } ]
}
下例使用ik_smart分析器对待测试文本进行分析。
POST _analyze
{ "analyzer": " ik_smart ", //使用ik_smart分析器 "text": "金都嘉怡假日酒店"
}
分析结果如下:
{ "tokens" : [ { "token" : "金都", //将文本进行切分,切分出词语“金都” "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 //“金都”是第一个被切分出的词语,索引位置为0 }, { "token" : "嘉", "start_offset" : 2, "end_offset" : 3, "type" : "CN_CHAR", "position" : 1 }, { "token" : "怡", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 2 }, { "token" : "假日酒店", "start_offset" : 4, "end_offset" : 8, "type" : "CN_WORD", "position" : 3 } ]
}
从上述两个分析结果中可以看到,ik_max_word和ik_smart分析器的主要区别在于切分词语的粒度上,ik_smart的切分粒度比较粗,而ik_max_word将文本进行了最细粒度的拆分,甚至穷尽了各种可能的组合。
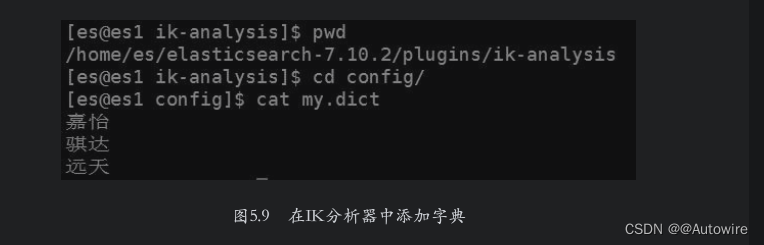
另外可以看到“嘉怡”这个词被切分成了“嘉”和“怡”,这个词没有在IK分析器的词典里,因此被切分成了两个单字,这需要为IK分析器添加词典来解决该问题。在IK分析器的安装目录下的config子目录中创建文件my.dict,在其中添加“嘉怡”即可。如果有更多的词语需要添加,则每个词语单独一行,添加示例如图5.9所示。
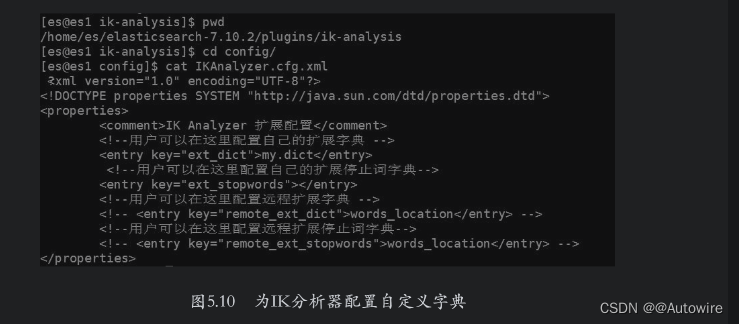
添加完成后修改IK分析器的配置文件,路径为config/IKAnalyzer.cfg.xml,将新建的字典文件加入ext_dict选项中,如图5.10所示。
配置完成后重启ES,然后使用分析器分析上面的文本,此时“嘉怡”就可以被切分出来。下面是使用ik_smart分析器切分文本的过程。
{ "tokens" : [ { "token" : "金都", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "嘉怡", // 添加自定义词典后,ik_smart分析器将“嘉怡”切分了出来 "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 }, { "token" : "假日酒店", "start_offset" : 4, "end_offset" : 8, "type" : "CN_WORD", "position" : 2 } ]
}
安装完毕后,也可以将IK分析器应用到索引的字段中。下面将ik_max_word分析器设置为酒店索引中title字段的默认分析器。
PUT /hotel
{ "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" //指定title字段使用ik_max_word分析器 }, … } }
}
7 使用同义词
在搜索场景中,同义词用来处理不同的查询词,有可能是表达相同搜索目标的场景。例如,当用户的查询词为“带浴缸的酒店”和“带浴池的酒店”时,其实是想搜索有单独泡澡设施的酒店。再例如,在电商搜索中,同义词更是应用广泛,如品牌同义词Adidas和“阿迪达斯”,产品同义词“投影仪”和“投影机”,修饰同义词“大码”和“大号”等。用户在使用这些与同义词相关的关键词进行搜索时,搜索引擎返回的搜索结果应该是一致的。如图5.13所示,左右两幅图分别是在京东商城和天猫商城中搜索“番茄”后的返回结果。
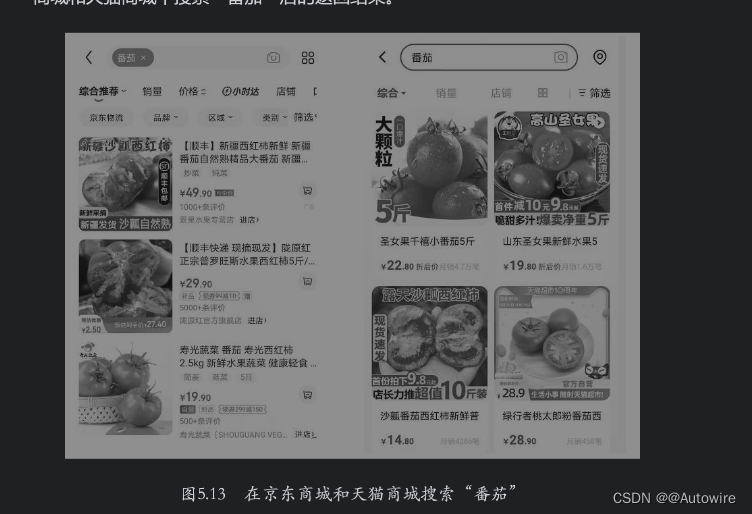
从上面的结果中可以看到,搜索“番茄”时,两个电商平台都会匹配“番茄”和“西红柿”相关产品。
用户还可以通过ES中的分析器来使用同义词,使用方式分为两种,一种是在建立索引时指定同义词并构建同义词的倒排索引,另一种是在搜索时指定字段的search_analyzer查询分析器使用同义词。
1 建立索引时使用同义词
在ES内置的分词过滤器中,有一种分词过滤器叫作synonyms,它是一种支持用户自定义同义词的分词过滤器。以下是使用IK分析器和synonyms分词过滤器一起定义索引的DSL:
PUT /hotel
{ "settings": { "analysis": { "filter": { //定义分词过滤器 "ik_synonyms_filter": { "type": "synonym", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_filter" ] } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_analyzer_synonyms" //指定索引时使用自定义的分析器 }, … } }
}
为方便测试,下面向酒店索引中写入几条数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅假日酒店"}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "北京金都嘉酒店"}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "天津金都欣欣酒店"}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都酒店"}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店"}
搜索关键词“首都度假酒店”,DSL如下:
GET /hotel/_search
{ "query": { //使用match搜索 "match": { "title": "首都度假" } }
}
搜索后的返回结果如下:
{ … "hits" : { … "max_score" : 2.1445937, "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "002", "_score" : 2.1445937, "_source" : { "title" : "北京金都嘉酒店" //字段中的“北京”与查询词中的“首都”匹配 } }, { "_index" : "hotel", "_type" : "_doc", "_id" : "001", "_score" : 1.7899693, "_source" : { "title" : "文雅假日酒店" //字段中的“度假”与查询词中的“假日”匹配 } } ] }
}
由上面的结果可见,酒店标题中的“北京”和“假日”分别可以匹配查询词中的“首都”和“度假”,说明前面的同义词设置成功。
2 查询时使用同义词
在ES内置的分词过滤器中还有个分词过滤器叫作synonym_graph,它是一种支持查询时用户自定义同义词的分词过滤器。
以下是使用IK分析器和synonym_graph分词过滤器一起定义索引的DSL:
PUT /hotel
{ "settings": { "analysis": { "filter": { //定义分词过滤器 "ik_synonyms_graph_filter": { "type": "synonym_graph", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_graph_filter" ] } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", //指定查询时使用自定义的分析器 "search_analyzer": "ik_analyzer_synonyms_graph" }, … } }
}
使用与5.5.1节相同的数据,搜索关键词“首都度假”,DSL如下:
GET /hotel/_search
{ "query": { //使用match搜索 "match": { "title": "首都度假" } }
}
搜索后的返回结果如下:
{ … "hits" : { … "hits" : [ //命中的文档集合 { "_index" : "hotel", "_type" : "_doc", "_id" : "001", "_score" : 1.2929529, "_source" : { "title" : "文雅假日酒店" } }, { "_index" : "hotel", "_type" : "_doc", "_id" : "002", "_score" : 1.2929529, "_source" : { "title" : "北京金都嘉酒店" } } ] }
}
通过对比两种方式的结果可以看到,命中的结果集和索引时使用的同义词一致,但是结果的排序却不同。这是因为在索引时使用同义词会计算全部的同义词的TF/IDF值,在搜索时进行的相关性计算,是将同义词和其他词同等对待,也就是将其TF/IDF值计算在内。而在搜索时使用同义词,需要ES将同义词转换后再进行相关性计算。以下DSL是查看查询词“度假”和文档001匹配的情况:
GET /hotel/_explain/001
{ //查看查询词和文档的匹配情况 "query": { "match": { "title": "度假" } }
}
ES的返回结果如下:
{ "_index":"hotel", "_type":"_doc", "_id":"001", "matched":true, "explanation":{ //ES将查询词改写成“title:假日”和“title:度假” "value":1.2929529, "description":"weight(Synonym(title:假日 title:度假) in 0)
[PerFieldSimilarity], result of:", "details":[ //具体的匹配打分过程 { "value":1.2929529, "description":"score(freq=1.0), computed as boost * idf * tf
from:", … } ] }
}
根据explain的结果来看,ES将查询改写为title字段匹配关键字“假日”或者“度假”。
如果有更新同义词的需求,则只能使用查询时使用同义词的这种方式。首先需要先关闭当前索引:
POST /hotel/_close
下面更改索引的settings信息,新添加一组近义词“精选,豪华”:
PUT /hotel/_settings
{ "analysis": { "filter": { "ik_synonyms_graph_filter": { //定义分词过滤器 "type": "synonym_graph", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假", "精选,豪华" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ "lowercase", "ik_synonyms_graph_filter" //指定分词过滤器 ] } } }
}
打开索引:
POST /hotel/_open
搜索关键词“豪华”,搜索结果如下:
{ … "hits" : { … "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "005", "_score" : 1.456388, "_source" : { "title" : "文雅精选酒店" //字段中的“精选”与查询词“豪华”匹配 } } ] }
}
根据上述结果可见,通过更新同义词,之前添加的“精选,豪华”已经在搜索时生效。
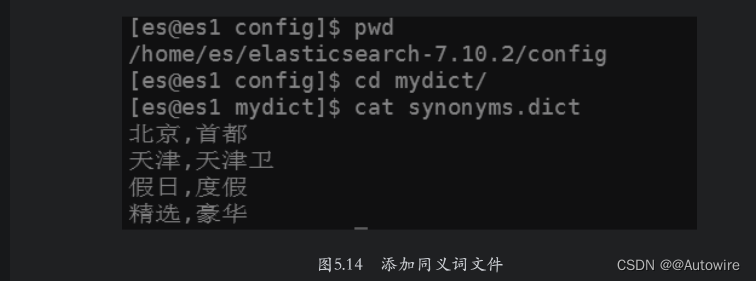
如果同义词比较多,在settings中进行配置时将非常烦琐。ES支持用户将同义词放在文件中,文件的位置必须是在${ES_HOME}/config目录及其子目录下,注意该文件必须存在于ES集群中的每一个节点上。在${ES_HOME}/config目录下建立一个子目录mydict,然后在该目录下创建一个名称为synonyms.dict的文件,文件内容如图5.14所示。
然后在创建酒店索引时,在settings中指定同义词文件及其路径,DSL如下:
PUT /hotel
{ "settings": { "analysis": { "filter": { //定义分词过滤器 "ik_synonyms_graph_filter": { "type": "synonym_graph", "synonyms_path":"mydict/synonyms.dict" //指定同义词文件及其路径 } }, "analyzer": { "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ "lowercase", "ik_synonyms_graph_filter" //指定分词过滤器 ] } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", //指定查询时使用自定义的分析器 "search_analyzer": "ik_analyzer_synonyms_graph" }, … } }
}
当同义词词典文件内容更新时,例如,在其中添加“酒店,旅店”后,则需要执行如下请求:
POST /hotel/_reload_search_analyzers
执行上述请求后,同义词得到更新,后续就可以在查询中使用新添加的同义词了。
8 使用停用词
停用词也叫停止词,是指文本在被分词之后的词语中包含的无搜索意义的词。什么叫作“无搜索意义”呢?假设文本为“这里的世界丰富多彩”,那么分词结果中的“这里”和“的”对于匹配这个文档来说意义不大,因为这两个词的使用频率非常高,并且没有太多独特的意义。在构建搜索引擎索引时,常常忽略这样的词,这样可以大大提升搜索效率。
经常使用的中文和英文停用词可以在网站www.ranks.nl上提取,中文停用词地址为https://www.ranks.nl/stopwords/chinese-stopwords,英文停用词地址为https://www.ranks.nl/stopwords。
如图5.15所示为该网站上的部分中文和英文停用词截图。
1 使用停用词过滤器
可以通过创建自定义分析器的方式使用停用词,方法是在分析器中指定停用词过滤器,在过滤器中可以指定若干个停用词。下面使用standard分词器和停用词过滤器组成一个自定义分析器进行索引定义DSL如下:
PUT /hotel
{ "settings": { "analysis": { "filter": { //定义分词过滤器 "my_stop": { //指定停用词过滤器 "type": "stop", "stopwords": [ //指定停用词集合 "我", "的", "这" ] } }, "analyzer": { //自定义分析器 "standard_stop": { "tokenizer": "standard", "filter":["my_stop"] //指定分词过滤器 } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "standard_stop" //指定自定义分析器 } } }
}
使用上述分析器进行文本分析,DSL如下:
POST /hotel/_analyze
{ //使用title字段的分析器分析文本 "field": "title", "text": "我的酒店"
}
分析结果如下:
{ "tokens" : [ { //“我”和“的”已经被过滤 "token" : "酒", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 //“酒”是分词后的第3个词,索引位置为2 }, { "token" : "店", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 } ]
}
通过以上结果可以看到,“我的酒店”中的“我”和“的”已经被停用词过滤器过滤,只剩下“酒”和“店”。但是“酒”的开始位置是2,“店”的开始位置是3,说明分析结果中“我”和“的”的位置被保留了下来,这种特意保留停用词的方式有助于后续的模糊搜索。
2 在内置分析器中使用停用词
其实,像standard这种常用的分析器都自带有停用词过滤器,只需要对其参数进行相应设置即可。以下示例中使用standard分析器并通过设置其stopwords属性进行停用词的设定:
PUT /hotel
{ "settings": { "analysis": { "analyzer": { //自定义分析器 "my_standard": { "type": "standard", //自定义分析器封装标准分析器 "stopwords":["我","的","这"] //设置标准分析器的停用词 } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "my_standard" //设置自定义分析器 } } }
}
设置完成后,分析目标文本和上面的结果是一致的。
3 在IK分析器中使用停用词
在默认情况下,IK分析器的分词器只有英文停用词,没有中文停用词。以下示例为测试中文停用词的使用情况:
POST _analyze
{ "analyzer": "ik_max_word", //使用ik_max_word分析器 "text": "最清新的一个酒店"
}
返回结果如下:
{ "tokens" : [ //切分的词语列表 { //第1个切分的词语 "token" : "最", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { //第2个切分的词语 "token" : "清新", "start_offset" : 1, "end_offset" : 3, "type" : "CN_WORD", "position" : 1 }, { //第3个切分的词语 "token" : "的", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 2 }, { //第4个切分的词语 "token" : "一个", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 3 }, { //第5个切分的词语 "token" : "酒店", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 4 } ]
}
由上面的结果可知,分析结果中“最”“的”和“一个”这3个停用词没有被过滤。
如果用户想要添加中文停用词,需要通过自定义停用词文件的形式进行添加。在${ES_HOME}/plugins/ik-analysis/config目录下创建my_stopword.dict文件,并在其中添加中文停用词即可,如图5.16所示。
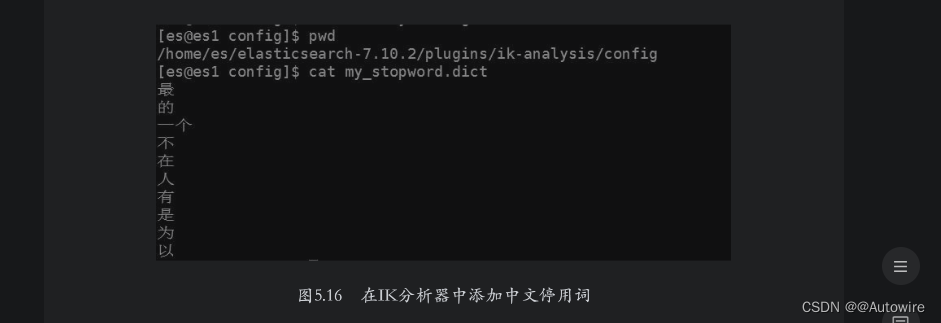
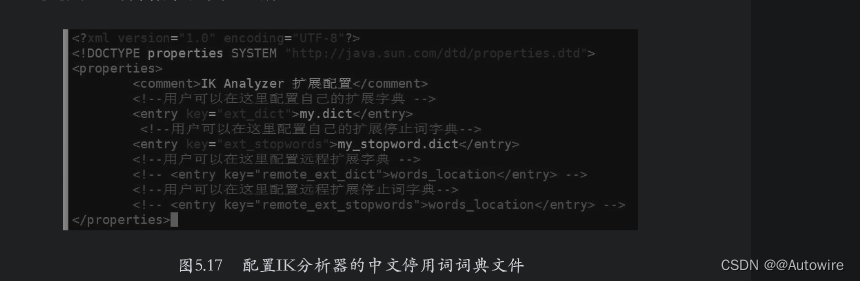
添加完停用词后保存文件并退出,然后修改${ES_HOME}/plugins/ik-analysis/config/IKAnalyzer.cfg.xml文件,设置配置项ext_stopwords的值为停用词词典的文件名称,如图5.17所示。
配置完成后重启ES,再使用上面的文本进行分析,分析结果如下:
{ "tokens" : [ //“最”“的”和“一个”这3个停用词已经被过滤 { "token" : "清新", "start_offset" : 1, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 }, { "token" : "酒店", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 1 } ]
}
根据上面的结果可知,之前配置的停用词已经生效,分析结果中“最”“的”和“一个”这3个停用词已经被过滤。
9 拼音搜索
拼音搜索在中文搜索环境中是经常使用的一种功能,用户只需要输入关键词的拼音全拼或者拼音首字母,搜索引擎就可以搜索出相关结果。在国内,中文输入法基本上都是基于汉语拼音的,这种在符合用户输入习惯的条件下缩短用户输入时间的功能是非常受欢迎的,如图5.19所示为分别在艺龙App和携程App上输入wfj后的搜索结果。
在ES中可以使用拼音分析器插件进行拼音搜索,插件的项目地址为https://github.com/medcl/elasticsearch-analysis-pinyin,该插件对较新的ES版本并不支持,需要用户自行进行编译安装。
1 拼音分析器插件的安装
如果要安装拼音分析器插件,则需要安装Git和Maven这两个工具。首先使用Git命令从互联网中复制该项目,命令如下:
https://github.com/medcl/elasticsearch-analysis-pinyin/releases/tag/v7.8.0
2 拼音分析器插件的使用
拼音分析器提供的分析器为pinyin,另外还提供了与其同名的分词器和分词过滤器。安装完成后,可以使用pinyin分析器或分词器进行验证。
下面使用pinyin分析器对待测试文本进行分析,DSL如下:
POST _analyze
{ "analyzer": "pinyin", //使用pinyin分析器分析文本 "text": "王府井"
}
分析结果如下:
{ "tokens" : [ { //“王”的拼音形式 "token" : "wang", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 0 }, { //“王府井”的拼音首字母 "token" : "wfj", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 0 }, { //“府”的拼音形式 "token" : "fu", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 1 }, { //“井”的拼音形式 "token" : "jing", "start_offset" : 0, "end_offset" : 0, "type" : "word", "position" : 2 } ]
}
在上面的代码中,“王府井”被切分成拼音wang、fu、jing及首字母wfj。
也可以将拼音分析器应用到索引的字段中。以下示例中将自定义的ik_pinyin_analyzer分析器设置为酒店索引中title字段的默认分析器,DSL如下:
PUT /hotel
{ "settings": { "analysis": { "analyzer": { //自定义分析器 "ik_pinyin_analyzer": { "tokenizer": "ik_max_word", //设置分词器为ik_max_word "filter":["pinyin_filter"] //设置分词过滤器为pinyin_filter } }, "filter": { //定义分词过滤器 "pinyin_filter": { "type": "pinyin", //封装pinyin分词过滤器 "keep_first_letter": true, //设置保留拼音的首字母 "keep_full_pinyin": false, //设置保留拼音的全拼 "keep_none_chinese": true, //设置不保留中文 } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_pinyin_analyzer" //设置使用自定义分析器 } } }
}
为演示方便,下面向酒店索引中写入如下数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅假日酒店"}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "北京金都嘉怡酒店"}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "天津金都欣欣酒店"}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都酒店"}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店"}
搜索关键词wy,目的是想搜索“文雅”相关的酒店,DSL如下:
GET /hotel/_search
{ "query": { //搜索匹配wy的文档 "match": { "title": "wy" } }
}
搜索结果如下:
{ … "hits" : { … "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "005", "_score" : 0.919734, "_source" : { "title" : "文雅精选酒店" //字段中的“文雅”和查询词wy匹配 } }, { "_index" : "hotel", "_type" : "_doc", "_id" : "001", "_score" : 0.816522, "_source" : { "title" : "文雅假日酒店" //字段中的“文雅”和查询词wy匹配 } } ] }
}
由此可见,使用带有拼音词语过滤器的分析器后,就可以匹配查询词中的拼音首字母了。正如上面的一些示例,使用拼音分析器时,有很多的选项可以设置。例如,是否显示单字拼音的首字母、是否显示组合词的首字母、是否显示查询词的全部拼音等,具体的设置内容可以参考官网说明,本节不再赘述。
10 高亮显示搜索
“高亮显示”的英文为highlight,是指在搜索结果中通过对文档标题的部分匹配字符串进行颜色(如红色)或者字体(如加粗)等处理,在视觉呈现上使匹配的字符串与未匹配的字符串有明显的区分效果。我们在电商网站中经常会看到有这样的搜索效果,因为这可以让产品的属性和卖点受到更多的关注,从而提高搜索转化率。如图5.23所示为在京东商城网站上搜索“家用高清摄像头”时的搜索结果列表。

1 初步使用高亮显示搜索
在ES中通过设置DSL的highlight参数可以对搜索的字段高亮显示。例如,下面搜索title字段并且对结果进行高亮显示:
GET /hotel/_search
{ "query": { "match": { "title": "金都酒店" } }, "highlight":{ //设置高亮搜索的字段 "fields": { "title": {} } }
}
以上DSL中增加了highlight的子DSL,在其中设定对title字段的匹配结果进行高亮显示的标记标签,此处使用默认的HTML标签<em></em>,因此将title对应的值置为空对象。上述DSL的搜索结果如下:
{ … "hits" : { … "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "004", "_score" : 0.73944557, "_source" : { "title" : "金都酒店" }, "highlight" : { "title" : [ //使用默认的HTML标签<em></em>标记匹配的词语 "<em>金都</em><em>酒店</em>" ] } } … ] }
}
当然,如果希望使用其他HTML标签对匹配内容进行标记,可以在DSL中进行更改。以下DSL将匹配内容标记标签改为了<high></high>:
GET /hotel/_search
{ "query": { "match": { "title": "金都酒店" } }, "highlight":{ "fields": { "title": { //设置默认使用标签<high></high > 标记匹配词语 "pre_tags": "<high>", "post_tags": "</high>" } } }
}
执行上面的DSL后,搜索结果如下:
{ … "hits" : { … "hits" : [ { "_index" : "hotel", "_type" : "_doc", "_id" : "004", "_score" : 0.73944557, "_source" : { "title" : "金都酒店" }, "highlight" : { "title" : [ //使用标签<high></high >标记匹配词语 "<high>金都</high><high>酒店</high>" ] } } … ] }
}
2 选择高亮显示搜索策略
ES支持的高亮显示搜索策略有plain、unified和fvh,用户可以根据搜索场景进行选择。
plain是精准度比较高的策略,因此它必须将文档全部加载到内存中,并重新执行查询分析。由此可见,plain策略在处理大量文档或者大文本的索引进行多字段高亮显示搜索时耗费的资源比较严重。因此plain策略适合在单个字段上进行简单的高亮显示搜索。
unified策略是由Lucene Unified Highlighter来实现的,其使用BM25(Best Match25)算法进行匹配。在默认情况下,ES高亮显示使用的是该策略。
为了弥补上述两种策略在大文本索引高亮显示搜索时的速度低问题,Lucene还提供了基于向量的高亮显示搜索策略fvh(fast vector highlighter)。fvh策略更适合在文档中包含大字段的情况(如超过1MB)下使用,如果计算机的I/O性能更好(如使用SSD),则fvh策略在速度上的优势更加明显。
选择高亮显示搜索策略时,只需要在highlight子句中指定type字段的值即可。以下示例中设置高亮显示搜索时使用plain策略,DSL如下:
GET /hotel/_sear
{ "query": { "match": { "title": "金都酒店" } }, "highlight":{ "fields": { "title": { "type": "plain" //设置使用plain匹配策略 } } }
}
如果要使用fvh策略进行高亮显示搜索,需要设定字段的term_vector属性值为with_positions_offsets,示例如下:
PUT /hotel
{ "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", //设定字段的term_vector属性值为with_positions_offsets "term_vector": "with_positions_offsets" } … } }
}
然后在查询的DSL中指定高亮显示搜索的type为fvh,具体DSL如下:
GET /hotel/_search
{ "query": { "match": { "title": "金都酒店" } }, "highlight": { "fields": { "title": { "type": "fvh" //使用fvh策略进行高亮显示搜索 } } }
}
3 在Java客户端中进行高亮显示搜索
使用Java客户端进行高亮显示搜索时,需要创建一个HighlightBuilder类的实例,然后通过preTags()和postTags()方法分别设置高亮显示的前缀和后缀,并通过方法field()设置高亮显示的字段。遍历结果时,通过SearchHit.getHighlightFields()方法可以获取所有高亮显示的字段及其对应的高亮显示结果的映射,结构为Map<String,HighlightField>形式。当获取到某字段对应的高亮显示结果后,可以通过HighlightField.getFragments()方法获取结果的Text数组形式,后续进行遍历取出即可。以下示例是在Java客户端上进行高亮显示搜索:
public void hightLightSearch() { SearchRequest searchRequest = new SearchRequest(); //新建搜索请求 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(QueryBuilders.matchQuery("title", "金都").
operator(Operator.AND)); //新建match查询,并设置operator的值为and searchRequest.source(searchSourceBuilder); //设置查询 //新建高亮显示搜索 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.preTags("<high>"); //设置高亮显示标签前缀 highlightBuilder.postTags("</high>"); //设置高亮显示标签后缀 highlightBuilder.field("title"); //设置高亮显示字段 searchSourceBuilder.highlighter(highlightBuilder); //设置高亮显示搜索 try { SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索 SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集 for (SearchHit searchHit : searchHits) { //遍历搜索结果集 Text[] texts = searchHit.getHighlightFields().get("title").
getFragments(); //得到高亮显示搜索结果 for (Text text : texts) { //遍历高亮显示搜索 System.out.println(text); //打印每一个高亮显示结果 } System.out.println("--------------------------------------"); } } catch (Exception e) { e.printStackTrace(); }
}

11 拼写纠错
用户在使用搜索引擎的过程中,输入的关键词可能会出现拼写错误的情况。针对错误的关键词,绝大多数的搜索引擎都能自动识别并进行纠正,然后将纠正后的关键词放到索引中匹配数据。如果拼写错误特别多导致无法纠正,则会直接告知用户当前搜索没有匹配的结果。如图5.24所示的左右两幅图分别是在京东商城和天猫商城中搜索“薯偏”后的返回结果。
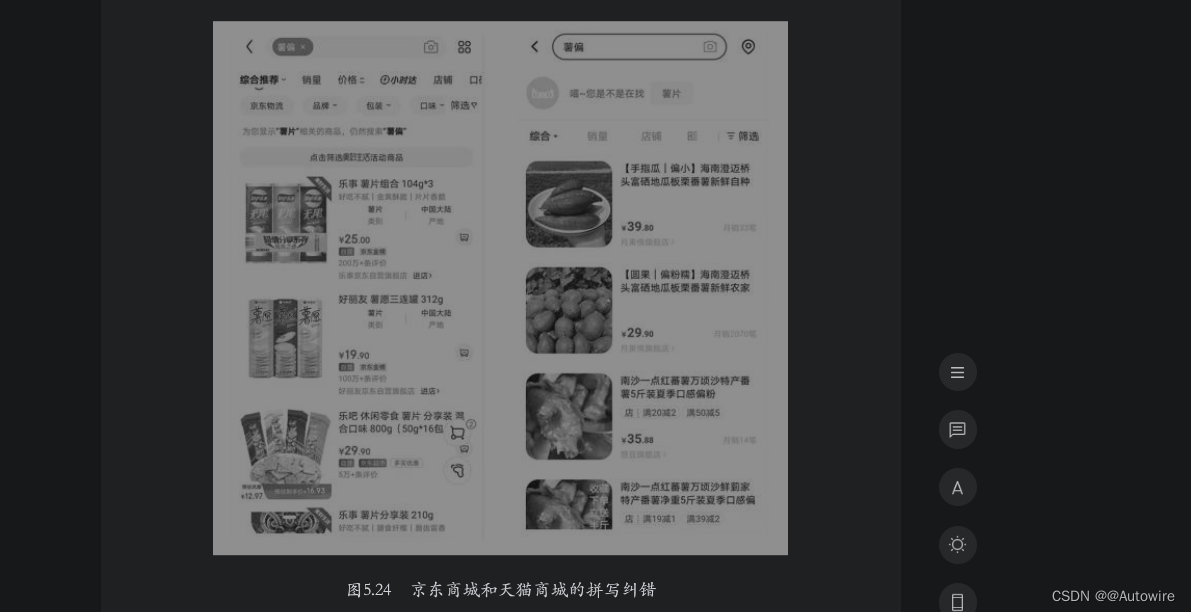
通过图5.24可以看到,两个应用都识别出了“薯偏”是一种拼写错误,并给出了正确的拼写词“薯片”。在搜索结果的展示上,天猫商城保守一些,主要展示了“薯”对应的匹配结果;京东商城则直接展示了“薯片”对应的匹配结果。
1 使用Elasticsearch进行拼写纠错
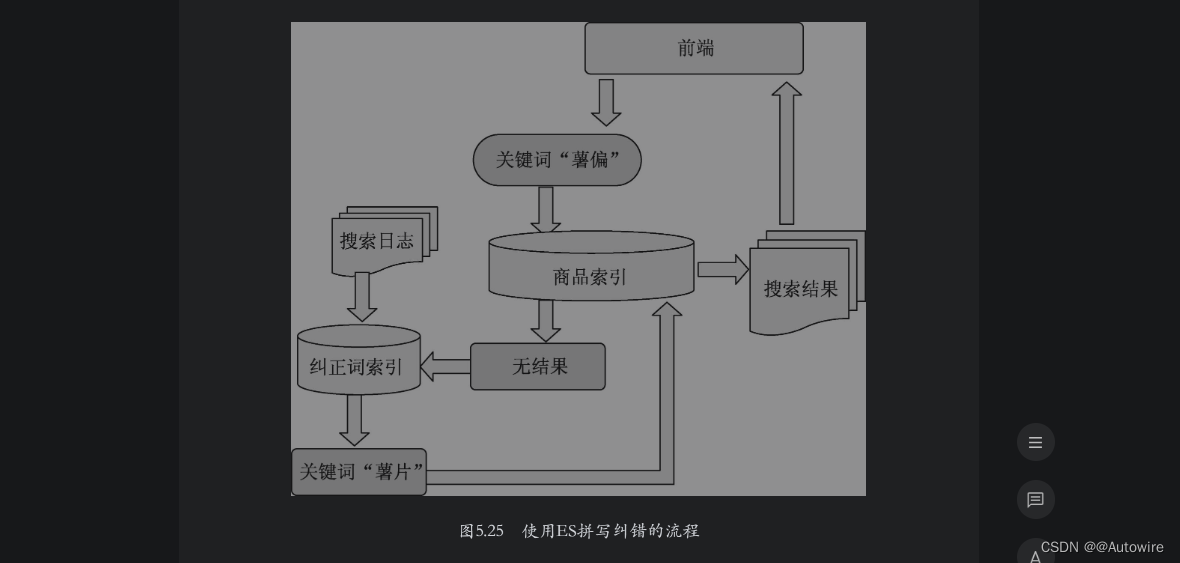
也可以使用ES进行拼写纠错,首先需要搜集一段时间内用户搜索日志中有搜索结果的查询词,然后单独建立一个纠正词索引。当用户进行搜索时,如果在商品索引中没有匹配到结果,则在纠正词索引中进行匹配,如果有匹配结果则给出匹配词,并给出该匹配词对应的商品结果,如果没有匹配结果则告知用户没有搜索到商品,流程如图5.25所示。
在ES中进行纠错匹配时使用fuzzy-match搜索,该搜索使用编辑距离和倒排索引相结合的形式完成纠错,倒排索引前面已经介绍过了,那么,什么是编辑距离呢?词语A经过多次编辑后和词语B相等,编辑的次数就叫作编辑距离。可以这样定义一次编辑:替换一个字符,或删除一个字符,或插入一个字符,或交换两个字符的位置。
假设有词语A为“景王”,词语B为“王府井”,词语A需要进行如下编辑才能等于词语B:
(1)将“景王”两个字符交换位置,变为“王景”。
(2)在“王景”中间添加“府”,变成“王府景”。
(3)将“王府景”中的“景”替换为“井”。
经过上述编辑,词语A和词语B相等,则词语A到词语B的编辑距离为3。上面的例子比较极端,词语A和词语B的编辑距离比较远,在搜索场景中,绝大多数查询词的编辑距离一般不超过2。
为演示方便,首先创建一个纠错索引,名称为error_correct,索引创建语句如下:
PUT /error_correct
{ "mappings": { "properties": { "hot_word": { //设置hot_word的类型为text,并指定分析器为ik_max_word "type": "text", "analyzer": "ik_max_word" } } }
}
接着向该索引中写入以下数据:
POST /_bulk
{"index":{"_index":"error_correct","_id":"001"}}
{"hot_word": "王府井"}
{"index":{"_index":"error_correct","_id":"002"}}
{"hot_word": "王府中环"}
{"index":{"_index":"error_correct","_id":"003"}}
{"hot_word": "双井"}
{"index":{"_index":"error_correct","_id":"004"}}
{"hot_word": "成府路"}
{"index":{"_index":"error_correct","_id":"005"}}
{"hot_word": "大王庄"}
ES的match查询支持模糊匹配,这里的模糊匹配指的是ES将查询文本进行分词进而得到分词列表,然后将列表中的词语分别和索引中的词语进行匹配,这时按照编辑距离进行模糊匹配,在符合编辑距离阈值的情况下才算是匹配。
以下是搜索“王府景”时,指定编辑距离为1的搜索纠错的DSL:
GET /error_correct/_search
{ "query": { "match": { "hot_word":{ "query": "王府景", "operator": "and", "fuzziness": 1 //指定编辑距离为1 } } }
}
上述DSL的执行结果如下:
{ … "hits" : { … "hits" : [ //命中的文档列表 { "_index" : "error_correct", "_type" : "_doc", "_id" : "001", "_score" : 1.2354476, "_source" : { "hot_word" : "王府井" //“王府井”和"王府景"的编辑距离为1 } }, { "_index" : "error_correct", "_type" : "_doc", "_id" : "004", "_score" : 0.0, "_source" : { "hot_word" : "成府路" //“成府路”和"王府景"的编辑距离为1 } } ] }
}
通过以上结果可以看出,纠错结果基本符合预期,但是“成府路”也出现在搜索结果中,这是为什么呢?
按照hot_word字段默认的分析器对查询词“王府景”和查询词“成府路”进行分析,查询词“王府景”被切分成了“王府”和“景”;查询词“成府路”被切分成了“成”“府”和“路”。因为“王府”和“府”的编辑距离为1,符合模糊匹配的编辑距离的阈值,因此“成府路”被匹配上。
2 更精准的拼写纠错
解决上面的问题有两种思路,第一种思路是将“成府路”作为新词加入用户的自定义词典中,此时ES会将“成府路”切分成一个整体“成府路”,它和“王府”的编辑距离是2,不符合阈值,因此不匹配;第二种思路是加入更严格的匹配条件。第一种思路受经验影响比较大,需要人工参与。本节主要介绍使用第二种思路来解决问题。
针对5.9.1节的“王府景”匹配问题,可以采用短语进行匹配查询,但是其必须满足以下3个条件:
·文档中必须包含“王府景”3个字;
·文档中必须满足“府”的位置比“王”的位置大1;
·文档中必须满足“景”的位置比“王”的位置大2。
上述条件缺一不可。但是,现有的文档中没有一个文档同时符合这个条件,甚至连第一个条件都不满足,与其最接近的文档是“王府井”,但是该文档中不包含“景”。我们可以换个角度考虑问题,“王府景”和“王府井”其实属于音同字不同的情况,如果将查询词和索引文档字段都切分成拼音的形式,“王府景”切分成拼音wang、fu、jing,候选项“王府井”切分的结果与查询词是一致的,且其拼音形式的位置排列与查询词也相同,这样就符合短语匹配的条件了。因此我们将字段hot_word变换一下,建立一个子字段pinyin,该字段使用拼音分析器进行切分,DSL如下:
PUT /error_correct
{ "settings": { "analysis": { "analyzer": { //自定义分析器 "pinyin_analyzer": { "tokenizer": "my_pinyin" } }, "tokenizer": { "my_pinyin": { //定义分词过滤器 "type": "pinyin", "keep_first_letter": false, "keep_separate_first_letter": false, "keep_full_pinyin": true } } } }, "mappings": { "properties": { "hot_word": { "type": "text", "analyzer": "ik_max_word", "fields": { //建立子字段 "pinyin": { "type": "text", "analyzer": "pinyin_analyzer" //使用自定义分析器 } } } } }
}
在上面的拼音分析器设置中,设置拼音单字的首字母和拼音组合的首字母全部不使用,只使用拼音单字的全拼形式。接着使用fuzzy-match和match_phrase进行联合查询,DSL如下:
GET /error_correct/_search
{ "query": { "bool": { "must": [ { "match": { "hot_word": { "query": "王府景", "operator": "and", "fuzziness": 1 //设置编辑距离为1 } } }, { "match_phrase": { //使用match_phrase匹配子字段 "hot_word.pinyin": { "query": "王府景", "slop": 0 //设置分词匹配的间隔为0 } } } ] } }
}
使用上述DSL进行查询后,ES返回的结果如下:
{ … "hits" : { … "hits" : [ { //“成府路”不再命中 "_index" : "error_correct", "_type" : "_doc", "_id" : "001", "_score" : 3.1889093, "_source" : { "hot_word" : "王府井" } } ] }
}
从上述结果中可以看到,在返回的匹配结果中,干扰项“成府路”已经不再显示,只有“王府井”被命中显示。
相关文章:
2023-02-10 - 5 文本搜索
与其他需要精确匹配的数据不同,文本数据在前期的索引构建和搜索环节都需要进行额外的处理,并且在匹配环节还要进行相关性分数计算。本章将详细介绍文本搜索的相关知识。 本章首先从总体上介绍文本的索引建立过程和搜索过程,然后介绍分析器的…...
,简单直白)
华为OD机试 - 最近的医院(Python),简单直白
任务混部 | 华为 OD 机试【最新】 题目 新型冠状病毒疫情的肆虐,使得家在武汉的大壮不得不思考自己家和附近定点医院的具体情况。 经过一番调查, 大壮明白了距离自己家最近的定点医院有两家。其中医院 A 距离自己的距离是 X 公里,医院 B 距离自己的距离是 Y 公里。 由于…...

Leetcode.1223 掷骰子模拟
题目链接 Leetcode.1223 掷骰子模拟 Rating : 2008 题目描述 有一个骰子模拟器会每次投掷的时候生成一个 1 到 6 的随机数。 不过我们在使用它时有个约束,就是使得投掷骰子时,连续 掷出数字 i 的次数不能超过 rollMax[i](i 从 1…...

数据分析到底该怎么学呢?讲真,真不难!
这几年,“数据分析”是很火啊,在这个数据驱动一切的时代,数据挖掘和数据分析就是这个时代的“淘金”,懂数据分析、拥有数据思维,往往成了大厂面试的加分项。 比如通过数据分析,我们可以更好地了解用户画像…...
活动星投票紫砂新青年制作一个投票活动
“紫砂新青年”网络评选投票_免费链接投票_作品投票通道_扫码投票怎样进行现在来说,公司、企业、学校更多的想借助短视频推广自己。通过微信投票小程序,网友们就可以通过手机拍视频上传视频参加活动,而短视频微信投票评选活动既可以给用户发挥…...
Git | 在IDEA中使用Git
目录 一、在IDEA中配置Git 1.1 配置Git 1.2 获取Git仓库 1.3 将本地项目推送到远程仓库 1.4 .gitignore文件的作用 二、本地仓库操作 2.1 将文件加入暂存区 2.2 将暂存区的文件提交到版本库 2.3 查看日志 三、远程仓库操作 3.1 查看和添加远程仓库 3.2 推送至远程仓…...
< Linux >:Linux 进程概念 (4)
目录 五、孤儿进程 六、进程优先级 6.1、基本概念 6.2、查看时实系统进程 6.3、PRI and NI 七、其他概念 四、X 状态:死亡状态 所谓进程处于 X 状态(死亡状态)代表的就是该进程已经死亡了,即操作系统可以随时回收它的资源(操作系统也可以…...
七、Java框架之MyBatisPlus
黑马课程 文章目录1. MyBatisPlus入门1.1 MyBatisPlus入门案例步骤1:创建spring boot工程步骤2:配置application.yml步骤3:创建数据库表(重点)步骤4:编写dao层步骤5:测试1.2 标准数据层开发标准…...

C语言柔性数组
目录什么是柔性数组柔性数组的使用什么是柔性数组 柔性数组是在C99中定义的 结构体的最后一个元素允许是未知大小的数组,这就叫柔性书组 柔性数组的长度可以写成0,也可以不规定数组长度 下面两种写法都是正确的 struct S { int i; int a[0];//柔性数…...

支付功能测试用例
Author:ChatGPT用例设计下面是一些支付功能测试用例:账户余额检查:测试用户的账户余额是否准确。支付方式选择:测试用户可以使用的支付方式,包括信用卡、借记卡、电子钱包等。支付金额确认:测试用户输入的支…...
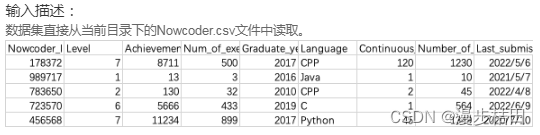
牛客网Python篇数据分析习题(一)
1.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID Level:等级 Achievement_value:成就值 Num_of_exercise&a…...

【C语言】“指针类型”与“野指针”
文章目录一、指针是什么❔二、指针和指针类型1.指针-整数2.指针解引用三.野指针1.引起野指针的原因2.如果避免野指针完结一、指针是什么❔ 指针也就是 内存地址 ,在计算机上我们访问数据需要通过内存地址来访问,在C语言中,指针变量是用来存放…...

Linux:软链接和硬链接的理解
Linux通过命令行创建快捷方式使用的命令是ln,这里就涉及到了软链接和硬链接,确实有些不好理解,如果你也一样,那么可以继续看下去了 目录ln命令语法实操创建软链接:ln -s [源文件或目录][目标文件或目录]创建硬链接&…...

力扣HOT100 (1-5)
目录 1.两数之和 2.两数相加 拓展到牛客的TOP101的BM11( 链表相加(二)) 3.无重复的最长子串(牛客BM92) 解法1: 解法2: 4.寻找两个正序数组的中位数 5.最长回文子串 1.两数之和 思路:用Has…...

车载基础软件——AUTOSAR CP典型应用案例SOME/IP和TSN时间同步
我是穿拖鞋的汉子,魔都中坚持长期主义的一个屌丝工程师! 今天是2023年2月7日,上海还在下着雨,估计是到了梅雨时节(提前到来?),真想说句我劝天公重安排,不让梅雨早时来!!! 老规矩分享一段喜欢的文字,避免自己成为高知识低文化的工科男: “ 我们只需做的,是走好…...
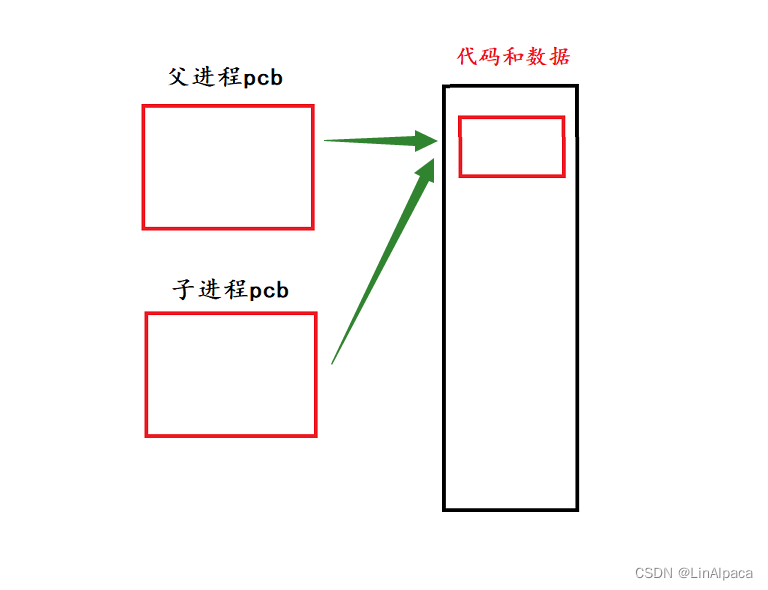
【Linux】操作系统与进程的概念
目录 冯诺依曼体系 注意 为什么CPU不直接访问输入或输出设备? 跨主机间数据的传递 操作系统 管理 进程 描述进程 进程的查看和终止 bash 通过系统调用创建子进程 fork的辨析 冯诺依曼体系 🥖冯诺依曼结构也称普林斯顿结构,是一种将…...

(1分钟突击面试) 高斯牛顿、LM、Dogleg后端优化算法
高斯牛顿法 LM法 DogLeg方法编辑切换为居中添加图片注释,不超过 140 字(可选)知识点:高斯牛顿是线搜索方法 LM方法是信赖域方法。编辑切换为居中添加图片注释,不超过 140 字(可选)这个就是JTJ是…...

d3.js与echarts对比
D3.js 和 ECharts 是两种常用的数据可视化工具,它们有着不同的优缺点: D3.js: 优点: 功能强大,提供了极高的灵活性和定制性,支持多种图表类型,如柱状图、饼图、散点图、树图、网络图等。 可以…...
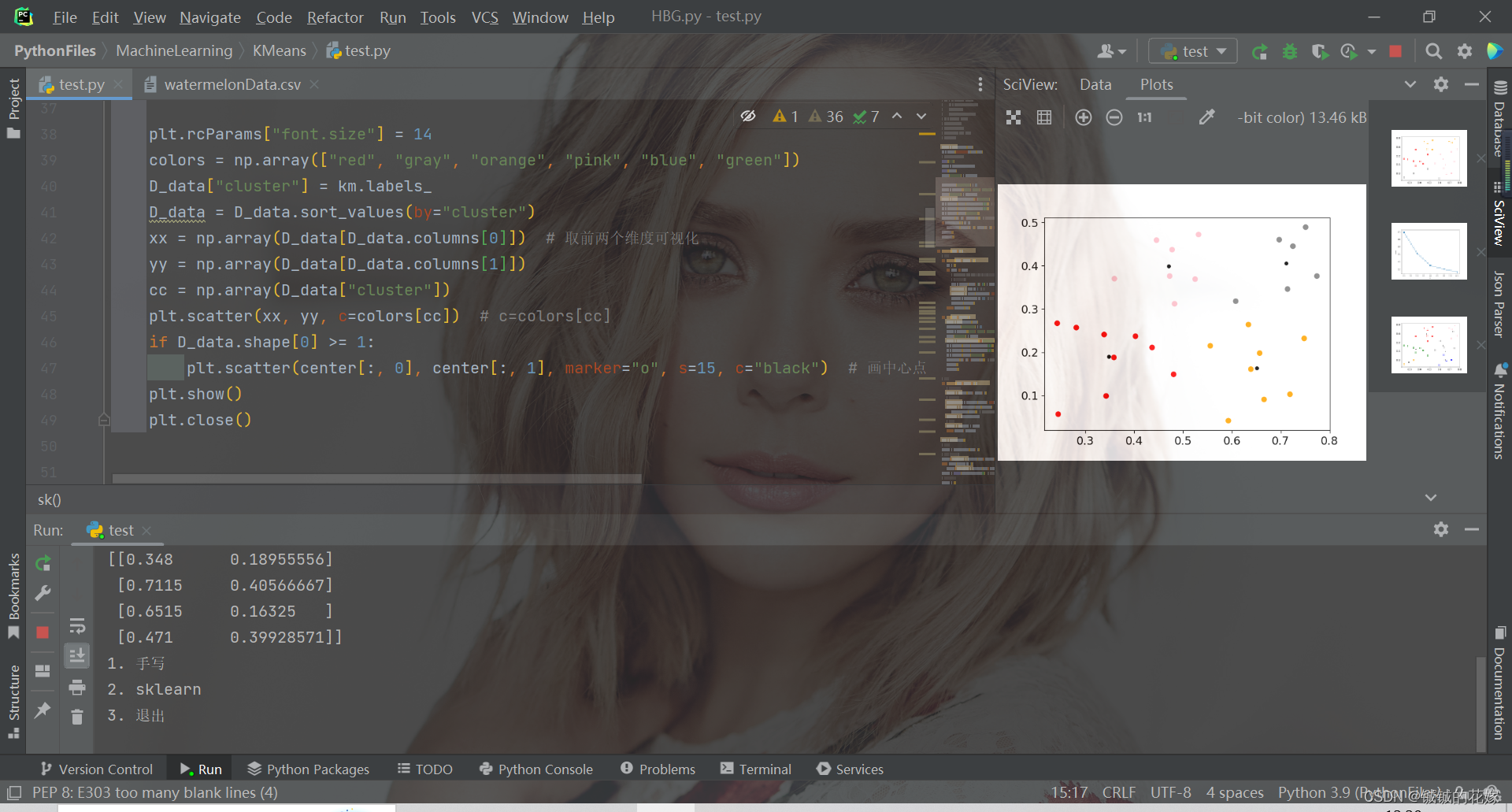
机器学习之K-means原理详解、公式推导、简单实例(python实现,sklearn调包)
目录1. 聚类原理1.1. 无监督与聚类1.2. K均值算法2. 公式推导2.1. 距离2.2. 最小平方误差3. 实例3.1. python实现3.2. sklearn实现4. 运行(可直接食用)1. 聚类原理 1.1. 无监督与聚类 在这部分我今天主要介绍K均值聚类算法,在这之前我想提一…...

OBS 进阶 一个从自定义对话框中 传参到插件的例子
目录 一、自定义对话框,传参综合例子 1、自定义对话框 1)自定义对话框类...

开源项目国际化:多语言配置全流程指南
开源项目国际化:多语言配置全流程指南 【免费下载链接】pivottable Open-source Javascript Pivot Table (aka Pivot Grid, Pivot Chart, Cross-Tab) implementation with dragndrop. 项目地址: https://gitcode.com/gh_mirrors/pi/pivottable 跨国团队如何让…...

WebPlotDigitizer图表数据提取工具:科研工作者的终极数字化解决方案
WebPlotDigitizer图表数据提取工具:科研工作者的终极数字化解决方案 【免费下载链接】WebPlotDigitizer WebPlotDigitizer: 一个基于 Web 的工具,用于从图形图像中提取数值数据,支持 XY、极地、三角图和地图。 项目地址: https://gitcode.c…...

【大模型工程实践③】RAG 基础架构与完整实现
【大模型工程实践③】RAG 基础架构与完整实现:从0到1跑通 作者:AI学习者 | 来源:大模型工程实践学习系列 | 更新:2026年3月 【理论要点速览】 学习本篇前,建议先掌握以下核心理论(点击跳转): ① 为什么需要RAG? ② RAG vs Fine-tuning vs Long Context的决策框架 ③ …...

Debugging torch.distributed.DistBackendError: NCCL Communicator Setup and ncclUniqueId Retrieval Iss
1. 理解NCCL通信错误的核心问题 当你看到torch.distributed.DistBackendError: [2] is setting up NCCL communicator and retrieving ncclUniqueId这个错误时,本质上是在说GPU之间的"对讲机"无法正常建立连接。想象一下你正在组织一场多房间的线上会议&…...

Ubuntu系统下Intel D405深度相机与Realsense-viewer的初次邂逅与配置实战
1. 开箱初体验:Intel D405深度相机的硬件揭秘 第一次拿到Intel D405深度相机时,那个黑色包装盒比想象中要小巧。拆开包装后,你会看到相机本体、USB数据线和几份纸质文档。相机重量约100克,尺寸和一副扑克牌相当,非常适…...
的获取与设置,一个例子讲透)
别再死记硬背公式了!Cesium中Entity姿态(HPR)的获取与设置,一个例子讲透
Cesium中Entity姿态控制的本质:从HPR到四元数的思维跃迁 当你第一次在Cesium中加载一个3D模型,却发现它头朝下或者背对镜头时,那种挫败感我深有体会。传统教程往往直接扔给你一堆转换公式,却很少解释为什么需要这些看似复杂的数学…...
)
别再被ToggleGroup坑了!手把手教你写一个不自动选首项的CustomToggleGroup组件(附完整代码)
深度定制Unity ToggleGroup:打造无默认选中行为的智能组件 引言 在Unity UI开发中,ToggleGroup组件是构建选项卡式界面的常见选择,但许多开发者都遇到过这样的困扰:当ToggleGroup激活时,系统总会自动选中第一个Toggle项…...

微信小程序--动态切换登录注册标签页
1、try.js的 1.1、data函数 添加 activeTab: login, // 当前激活的标签,默认为登录 1.2、添加一个函数 // 切换登录/注册标签switchTab(e) {const tab e.currentTarget.dataset.tab;this.setData({activeTab: tab});}, 2、try.wxml的代码 <!--pages/try/…...

开源风扇控制工具FanControl全攻略:从问题诊断到散热方案优化
开源风扇控制工具FanControl全攻略:从问题诊断到散热方案优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

手把手教你用丹青识画:智能影像雅鉴系统保姆级入门教程
手把手教你用丹青识画:智能影像雅鉴系统保姆级入门教程 1. 认识丹青识画系统 "以科技之眼,点画意之睛。"这句话完美诠释了丹青识画系统的核心理念。这是一款将人工智能技术与东方美学相结合的创新工具,能够自动分析图像内容并生成…...