Python----网络爬虫
目录
1.Robots排除协议
2.request库的使用
3.beautifulsoup4库的使用
Python网络爬虫应用一般分为两部:
(1)通过网络连接获取网页内容
(2)对获得的网页内容进行处理
- 这两个步骤分别使用不同的函数库:requests 和beautifulsoup4
1.Robots排除协议
Robots 排除协议(Robots Exclusion Protocol),也被称为爬虫协议,它是网站管理者表达是否希望爬虫自动获取网络信息意愿的方法。管理者可以在网站根目录放置一个robots.txt 文件,并在文件中列出哪些链接不允许爬虫爬取。一般搜索引擎的爬虫会首先捕获这个文件,并根据文件要求爬取网站内容。Robots 排除协议重点约定不希望爬虫获取的内容,如果没有该文件则表示网站内容可以被爬虫获得,然而,Robots 协议不是命令和强制手段,只是国际互联网的一种通用道德规范。绝大部分成熟的搜索引擎爬虫都会遵循这个协议,建议个人也能按照互联网规范要求合理使用爬虫技术。
2.request库的使用
request 库支持非常丰富的链接访问功能,包括:国际域名和URL 获取、HTTP 长连接和连接缓存、HTTP 会话和Cookie 保持、浏览器使用风格的SSL 验证、基本的摘要认证、有效的键值对Cookie 记录、自动解压缩、自动内容解码、文件分块上传、HTTP(S)代理功能、连接超时处理、流数据下载等。
有关requests库的更多介绍可看:
Requests: HTTP for Humans™ — Requests 2.31.0 documentation
(1)安装request库
pip install requests 或 pip3 install requests
(2)request库中的请求函数
| 函数 | 描述 |
| get(url[,timeout=n]) | 对应于HTTP的GET方式,获取网页最常用的方法,可以增加timeout=n参数,设定每次请求超时时间为n秒 |
| post(url,data={‘key’:’value’}) | 对应于HTTP的POST方式,其中字典用于传递客户数据 |
| delete(url) | 向网页提交删除请求 |
| head(url) | 获取html网页头信息 |
| options(url) | 对应于HTTP的OPTIONs方式 |
| put(url, data={‘key’:’value’}) | 向网页提交put请求,其中字典用于传递客户数据 |
(3)get的用法
get()是获取网页最常用的方式,在调用requests.get()函数后,返回的网页内容会保存为一个Response 对象,其中,get()函数的参数url必须采用HTTP 或HTTPS方式访问
>>> import requests
>>> r = requests.get('http://www.baidu.com')#使用get方法打开链接
>>> type(r)
requests.models.Response #返回Response对象
(4)response对象的属性
•和浏览器的交互过程一样,requests.get()代表请求过程,它返回的Response 对象代表响应,Response 对象的属性如下表所示,需要采用<a>.<b>形式使用。
•status_code 属性返回请求HTTP 后的状态,在处理数据之前要先判断状态情况,如果请求未被响应,需要终止内容处理。
•text 属性是请求的页面内容,以字符串形式展示。
•encoding 属性非常重要,它给出了返回页面内容的编码方式,可以通过对encoding 属性赋值更改编码方式,以便于处理中文字符。
•content 属性是页面内容的二进制形式。
•json()方法能够在HTTP 响应内容中解析存在的JSON 数据,这将带来解析HTTP的便利。
•raise_for_status()方法能在非成功响应后产生异常,即只要返回的请求状态status_code 不是200,这个方法会产生一个异常,用于try…except 语句。只需要在收到响应调用这个方法,就可以避开状态字200 以外的各种意外情况。
表格总结如下:
| 函数 | 描述 |
| status_code | HTTP请求的返回状态,整数,200表示连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即,也是url对应的页面内容 |
| encoding | HTTP响应内容的编码方式 |
| content | HTTP响应内容的二进制形式 |
| json() | 如果HTTP响应内容包含JSON格式数据,该方法解析JSON数据 |
| raise_for_status() | 如果不是200,那么这个方法就会产出异常 |
示例:
>>> import requests
>>> r = requests.get('http://www.baidu.com')
>>> r.status_code #返回状态
200
>>> r.text #观察返回的内容,中文字符能否正常显示
(输出略)
>>> r.encoding
'ISO-8859-1'
>>> r.encoding = 'utf-8' #更改编码方式为utf-8
>>> r.text #更改完成,返回内容中的中文字符可以正常显示
(输出略)
(5)requests产生的异常
•当遇到网络问题时,如:DNS 查询失败、拒绝连接等,requests 会抛出ConnectionError 异常;
•遇到无效HTTP 响应时,requests 则会抛出HTTPError 异常;
•若请求url 超时,则抛出Timeout 异常;若请求超过了设定的最大重定向次数,则会抛出一个TooManyRedirects 异常。
(6)获取一个网页内容
import requests
def getHTMLText(url):
try:
r=request.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发异常
r.encoding='utf-8'
return r.text
except:
return ""
url = "http://www.baidu.com"
print(getHTMLText(url))
HTTP的GET和POST
HTTP 协议定义了客户端与服务器交互的不同方法,最基本的方法是GET 和POST。顾名思义,GET 可以根据某链接获得内容,POST 用于发送内容。然而,GET 也可以向链接提交内容。
注:使用 get() 方法访问百度页面时,可以通过 text 属性和 content 属性来获取网页的内容。这两种方法返回的内容长度可能会有所不同,原因如下:
text 属性返回的是经过解码后的字符串内容,通常是按照页面的字符编码(比如 UTF-8)进行解析的网页文本内容。因此,len() 函数返回的是网页文本的字符数。
content 属性返回的是未经解码的字节内容,即网页的原始字节数据。因此,len() 函数返回的是网页内容的字节数。
由于中文字符通常需要多个字节来表示,因此在使用 len() 函数计算时,text 属性返回的长度通常会大于 content 属性返回的长度。这就是长度差异产生的主要原因。
3.beautifulsoup4库的使用
使用requests 库获取HTML 页面并将其转换成字符串后,需要进一步解析HTML页面格式,提取有用信息,这需要处理HTML 和XML 的函数库。beautifulsoup4 库,也称为Beautiful Soup 库或bs4 库,用于解析和处理HTML和XML。
需要注意,它不是BeautifulSoup 库。它的最大优点是能根据HTML 和XML 语法建立解析树,进而高效解析其中的内容。
HTML 建立的Web 页面一般非常复杂,除了有用的内容信息外,还包括大量用于页面格式的元素,直接解析一个Web 网页需要深入了解HTML 语法,而且比较复杂。beautifulsoup4 库将专业的Web 页面格式解析部分封装成函数,提供了若干有用且便捷的处理函数。
(1)beautifulsoup4的安装
pip install beautifulsoup4 或 pip3 install beautifulsoup4
(2)beautifulsoup4的应用
beautifulsoup4 库采用面向对象思想实现,简单说,它把每个页面当做一个对象,通过<a>.<b>的方式调用对象的属性(即包含的内容),或者通过<a>.<b>()的方式调用方法(即处理函数)。
在使用beautifulsoup4 库之前,需要进行引用,由于这个库的名字非常特殊且采用面向对象方式组织,可以用from…import 方式从库中直接引用BeautifulSoup 类,方法如下:
>>> from bs4 import BeautifulSoup
有关beautifulsoup4库的使用可以看:
Beautiful Soup: We called him Tortoise because he taught us.
•beautifulsoup4 库中最主要的是BeautifulSoup 类,每个实例化的对象相当于一个页面。采用from…import 导入库中类后,使用BeautifulSoup()创建一个BeautifulSoup对象。
>>> import requests
>>> from bs4 import BeautifulSoup
>>> r = requests.get('http://www.baidu.com')
>>> r.encoding = 'utf-8'
>>> soup = BeautifulSoup(r.text)
>>> print(type(soup))
<class 'bs4.BeautifulSoup'>
•创建的BeautifulSoup 对象是一个树形结构,它包含HTML 页面里的每一个Tag(标签)元素,如<head>、<body>等。具体来说,HTML 中的主要结构都变成了BeautifulSoup 对象的一个属性,可以直接用<a>.<b>形式获得,其中<b>的名字采用HTML 中标签的名字。
•beautifulsoup对象常用属性:
| 属性 | 描述 |
| head | HTML页面的<head>内容 |
| title | HTML页面标题,在<head>之中,由<title>标记 |
| body | HTML页面的<body>内容 |
| p | HTML页面中第一个<p>内容 |
| strings | HTML页面所有呈现在web上的字符串,即标签的内容,可迭代 |
| stripped_strings | HTML页面所有呈现在web上的非空字符串(自动去掉空白字符串),可迭代 |
示例:
>>> import requests
>>> from bs4 import BeautifulSoup
>>> r = requests.get('http://www.baidu.com')
>>> r.encoding = 'utf-8'
>>> soup = BeautifulSoup(r.text)
>>> soup.head
<head><meta content="text/html;charset=utf-8" (省略...)
>>> title = soup.title
<title>百度一下,你就知道</title>
>>> type(title)
bs4.element.Tag
>>> soup.p
<p id="lh"> <a href="http://home.baidu.com">关于百度</a>
<a href="http://ir.baidu.com">About Baidu</a> </p>
•Tag标签
每一个Tag 标签在beautifulsoup4 库中也是一个对象,称为Tag 对象。上例中,title 是一个标签对象。每个标签对象在HTML 中都有以下类似的结构:
<a class="mnav" href="http://www.nuomi.com">糯米</a>
其中,尖括号(<>)中的标签的名字是name,尖括号内其他项是attrs,尖括号之间的内容是string。因此,可以通过Tag 对象的name、attrs 和string 属性获得相应内容,采用<a>.<b>的语法形式。
Tag有4个常用属性:
| 属性 | 描述 |
| name | 字符串,标签的名字,比如div |
| attrs | 字典,包含了原来页面Tag所有的属性,比如href |
| contents | 列表,这个Tag下所有子Tag的内容 |
| string | 字符串,Tag所包围的文本,网页中真实的文字 |
示例:
>>> soup.a
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
>>> soup.a.attrs
{'href': 'http://news.baidu.com', 'name': 'tj_trnews', 'class': ['mnav']}
>>> soup.a.string
'新闻'
>>> title = soup.title
>>> title.string
'百度一下,你就知道'
>>> soup.p.contents
[' ',<a href="http://home.baidu.com">关于百度</a>,' ',<a href="http://ir.baidu.com">About Baidu</a>,' ']
注:
由于HTML 语法可以在标签中嵌套其他标签,所以,string 属性的返回值遵循如下原则:
•如果标签内部没有其他标签,string 属性返回其中的内容;
•如果标签内部有其他标签,但只有一个标签,string 属性返回最里面标签的内容;
•如果标签内部有超过1 层嵌套的标签,string 属性返回None(空字符串)。
•HTML 语法中同一个标签会有很多内容,例如<a>标签,百度首页一共有54 处,直接调用soup.a 只能返回第一个。
查找对应标签
•当需要列出标签对应的所有内容或者需要找到非第一个标签时,需要用到BeautifulSoup 的find()和find_all()方法。这两个方法会遍历整个HTML 文档,按照条件返回标签内容。
find_all()属性:
| 属性 | 描述 |
| BeautifulSoup.find_all(name, attrs, recursive, string, limit) | 根据参数找到对应标签,返回列表类型。 |
| name: 按照Tag标签名字检索,名字用字符串形式表示,例如:dvi, li; | |
| attrs: 按照Tag标签属性值检索,需要列出属性名称和值,采用JSON表示; | |
| recursive: 设置查找层次,只查找当前标签下一层时使用recursive=False | |
| string:按照关键字检索string属性内容,采用string=开始; | |
| limit:返回结果的个数,默认返回全部结果 |
>>> a = soup.find_all('a') #查找所有的标签a
>>> len(a) #本页标签<a>的数量
54
>>> soup.find_all('script') #查找所有标签script
[<script>(function(){var hashMatch=document.location...(省略)
>>> soup.find_all('script',{'src':"https://pss.bdstatic.com/static/
superman/js/components/hotsearch-5af0f864cf.js"}) #筛选,只查找src=字符串的标签
[<script src="https://pss.bdstatic.com/static/superman/js/
components/hotsearch-5af0f864cf.js"></script>]'百度一下,你就知道'
>>> import re #使用正则表达式库,可用这个库实现字符串片段匹配
>>> soup.find_all('script',{'src':re.compile('jquery')})
[<script src="https://pss.bdstatic.com/static/superman/js/lib/
jquery-1-edb203c114.10.2.js" type="text/javascript"></script>]
>>> soup.find_all(string=re.compile('百度')) #检索string属性的内容
['百度一下,你就知道', '百度首页', '查看全部百度产品 >',
'关于百度', '使用百度前必读', '百度APP扫码登录', '百度一下\xa0生活更好']
简单说,BeautifulSoup 的find_all()方法可以根据标签名字、标签属性和内容检索并返回标签列表,通过片段字符串检索时需要使用正则表达式re 函数库,re 是Python 标准库,直接通过import re 即可使用。
采用re.compile('jquery')实现对片段字符串(如'jquery')的检索。当对标签属性检索时,属性和对应的值采用JSON格式,例如:
'src':re.compile('jquery')
其中,键值对中值的部分可以是字符串或者正则表达式。
find()属性
除了find_all()方法,BeautifulSoup 类还提供一个find()方法,它们的区别只是前者返回全部结果而后者返回找到的第一个结果,find_all()函数由于可能返回更多结果,所以采用列表形式;find()函数返回字符串形式。
| 属性 | 描述 |
| BeautifulSoup.find(name, attrs, recursive, string) | 根据参数找到对应标签,返回找到的第一个值,字符串。 |
| name: 按照Tag标签名字检索,名字用字符串形式表示,例如:dvi, li; | |
| attrs: 按照Tag标签属性值检索,需要列出属性名称和值,采用JSON表示; | |
| recursive: 设置查找层次,只查找当前标签下一层时使用recursive=False | |
| string:按照关键字检索string属性内容,采用string=开始; |
以下是爬虫的示例:
http://t.csdnimg.cn/ywftG
相关文章:

Python----网络爬虫
目录 1.Robots排除协议 2.request库的使用 3.beautifulsoup4库的使用 Python网络爬虫应用一般分为两部: (1)通过网络连接获取网页内容 (2)对获得的网页内容进行处理 - 这两个步骤分别使用不同的函数库:requests …...
【微信小程序】上传头像 微信小程序内接小程序客服
这里写目录标题 微信小程序上传头像使用button按钮包裹img 微信小程序内接小程序客服使用button按钮跳转客服 微信小程序上传头像 使用button按钮包裹img 原本思路是只使用image标签再加上chooseImg,但发现使用button标签上传头像这种方法更实用。微信小程序文档上…...

【c++随笔15】c++常用第三方库
【c随笔15】c常用第三方库 一、数据库相关:HDFS、libpq、SQLite、RocksDB、unixODBC、Nanobdc、Ignite ; 二、网络通信相关:libcurl、libevent、libssh、mosquitto、nghttp2、libuv; 三、加密和安全相关:1、OpenSSL 四…...

数据结构 | 查漏补缺之ASL、
目录 ASL 情形之一:二分查找 线索二叉树 哈夫曼树 大根堆 邻接表&邻接矩阵 ASL 参考博文 关于ASL(平均查找长度)的简单总结_平均查找长度asl-CSDN博客 情形之一:二分查找 线索二叉树 参考博文 线索二叉树(线索链表遍历,二叉树…...

泊车功能专题介绍 ———— 汽车全景影像监测系统性能要求及试验方法(国标未公布)
文章目录 术语和定义一般要求功能要求故障指示 性能要求响应时间图像时延单视图视野范围平面拼接视图视野平面拼接效果总体要求行列畸变拼接错位及拼接无效区域 试验方法环境条件仪器和设备车辆条件系统响应时间试验图像时延试验单视图视野范围试验平面拼接视图视野试验平面拼接…...
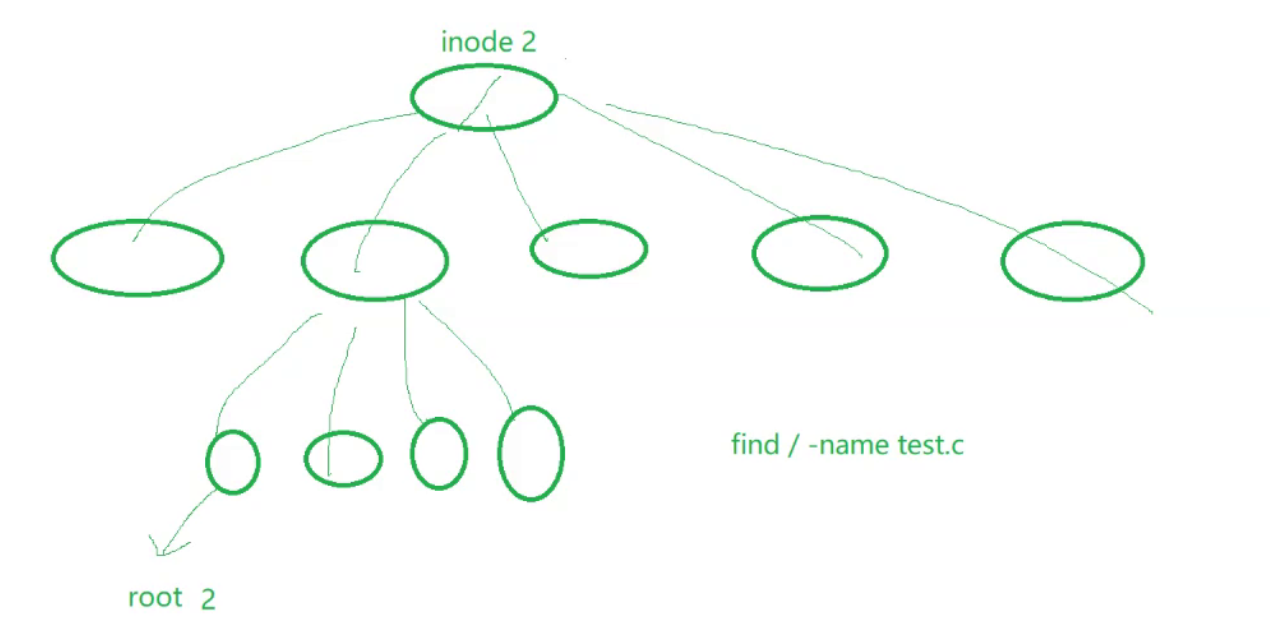
【Linux】第二十六站:软硬链接
文章目录 一、软链接二、硬链接三、ln命令四、该如何理解硬链接?五、如何理解软链接六、为什么要用软硬链接1.软链接的应用场景2.硬链接的应用场景 一、软链接 如下所示,我们创建一个文件以后,然后执行下面的指令 ln -s file.txt soft-link…...
开源播放器GSYVideoPlayer + ViewPager2 源码解析
开源播放器GSYVideoPlayer ViewPager2 源码解析 前言一、GSYVideoPlayer🔥🔥🔥是什么?二、源码解析1.ViewPager2Activity 总结 前言 本文介绍GSYVideoPlayer源码中关于ViewPager2 GSYVideoPlayer 实现的滑动播放列表的实现原理。…...

重启路由器可以解决N多问题?
为什么重启始终是路由器问题的首要解决方案? 在日常的工作学习工作中,不起眼的路由器是一种相对简单的设备,但这仍然是我们谈论的计算机。 这种廉价的塑料外壳装有 CPU、随机存取存储器 (RAM)、只读存储器 (ROM) 和许多其他组件。 该硬件运行预装的软件(或固件)来管理连接…...

Python WebSocket 客户端教程
WebSocket 是一种在客户端和服务器之间实现双向通信的协议,常用于实时聊天、实时数据更新等场景。Python 提供了许多库来实现 WebSocket 客户端,本教程将介绍如何使用 Python 构建 WebSocket 客户端。 什么是 WebSocket WebSocket 是一种基于 TCP 协议…...

洛谷 P2984 [USACO10FEB] Chocolate Giving S
文章目录 [USACO10FEB] Chocolate Giving S题面翻译题目描述输入格式输出格式 题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 题意解析CODE给点思考 [USACO10FEB] Chocolate Giving S 题面翻译 题目链接:https://www.luogu.com.cn/problem/P2984 题目描…...

【专题】【数列极限】
【整体思路】 【常用不等式】...

oracle基础系统学习文章目录
oracle基础系统学习——点击标题可跳转对应文章 01.CentOS7静默安装oracle11g 02.Oracle的启动过程 03.从简单的sql开始 04.Oracle的体系架构 05.Oracle数据库对象 06.Oracle数据备份与恢复 07.用户和权限管理 08.Oracle的表 09.Oracle表的分区 10.Oracle的同义词与序列 11.Or…...
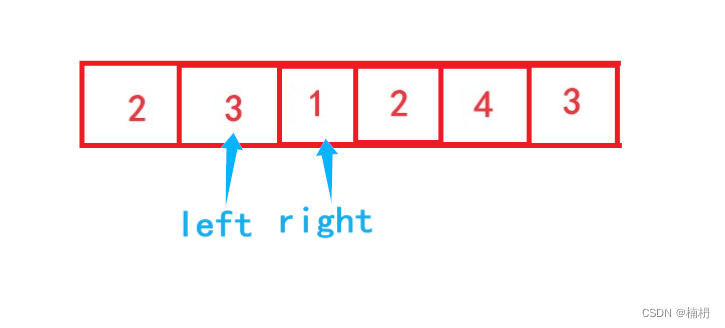
长度最小的子数组(Java详解)
目录 题目描述 题解 思路分析 暴力枚举代码 滑动窗口代码 题目描述 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条…...

计算机组成学习-数据的表示和运算总结
复习本章时,思考以下问题: 1)在计算机中,为什么要采用二进制来表示数据?2)计算机在字长足够的情况下能够精确地表示每个数吗?若不能,请举例说明。3)字长相同的情况下,浮点数和定点数的表示范围…...
(八))
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(八)
目录 前言 知识储备 机器视觉学习路线 视觉算法流程...

【4】基于多设计模式下的同步异步日志系统-框架设计
7. 日志系统框架设计 本项⽬实现的是⼀个多日志器日志系统,主要实现的功能是让程序员能够轻松的将程序运行日志信息落地到指定的位置,且⽀持同步与异步两种方式的日志落地方式。 项目的框架设计将项目分为以下几个模块来实现。 日志等级模块 日志等级模…...
Jupyter Markdown 插入图片
首先截图 注意 这一步是关键的!! 它需要使用电脑自带的截图,用qq啊vx啊美图秀秀那些都不行哦。 截图之后复制: 然后快捷键粘贴到jupyter里面,它会生成一段代码(没有代码就是说截图形式不对)&a…...
web自动化 -- pyppeteer
由于Selenium流行已久,现在稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易就可以判断出是真人访问还是webdriver。虽然也可以通过中间代理的方式进行js注入屏蔽webdriver检测,但…...
Java 数组另类用法(字符来当数组下标使用)
一、原因 看力扣的时候发现有位大佬使用字符来当数组下标使用。 class Solution {public int lengthOfLongestSubstring(String s) {int result 0;int[] hash new int[130];int i 0;for(int j 0; j < s.length(); j) {while(hash[s.charAt(j)] > 0) {hash[s.charAt…...

error转string
1 概述 在golang中,error类型是非常常见的一种数据类型。在开发过程中,经常会遇到需要将error类型转换成string类型的情况。本文主要介绍几种常见的golang error转string的方法。 2 使用Error()函数 在golang中,Error()函数是error类型的一…...

Eviews面板数据建模保姆级教程:从Hausman检验到模型选择,一次讲透固定效应与随机效应
Eviews面板数据建模实战指南:从数据导入到模型选择的完整流程 面板数据分析作为计量经济学中的重要工具,能够同时捕捉时间和个体维度的信息。对于刚接触Eviews的研究者来说,如何正确建立面板模型往往令人困惑——从数据准备到模型选择&#x…...

远程办公总掉线?四大远控软件横测:谁才是“不断连之王”?
远程办公总掉线?四大远控软件横测:谁才是“不断连之王”? 远程办公最怕 “关键时刻掉链子”:写方案写到一半断连、远程运维突然掉线、跨城开会画面卡死…… 连接稳定性早已成为远控软件的核心生命线。本次横测聚焦ToDesk、向日葵、…...

Nordic nRF52832蓝牙串口实战:手把手教你用SDK 15.3.0实现手机与设备双向通信
Nordic nRF52832蓝牙串口开发实战:从SDK配置到双向通信全解析 在嵌入式蓝牙开发领域,Nordic的nRF52832芯片凭借其优异的射频性能和丰富的外设资源,成为物联网设备开发的明星选择。但对于刚接触这款芯片的开发者来说,如何快速实现手…...

容器化GUI自动化:基于Xvfb与xdotool的无头点击测试实践
1. 项目概述与核心价值最近在折腾一些自动化测试和模拟操作的项目,发现了一个挺有意思的镜像:instavm/clickclickclick。光看名字,你大概能猜到它的核心功能——点击。没错,这是一个专门用于模拟鼠标点击、键盘输入等图形界面&…...

【信息科学与工程学】【制造工程】【通信工程】第一百零一篇 2nm 200Tbps+核心交换机全尺度参数宇宙构建框架05
围绕芯片、单板、交换网卡等层级,重点扩展“信息处理”中的“内存/存储器”子系统相关参数,并覆盖其他关键方面。 衬底、互连、介质,但光刻胶、清洗液、研磨液、封装胶、键合线、TIM材料、探针卡、载带、保护涂层、清洗溶剂、掺杂剂、气体、抗反射涂层、对准标记、硅化物、…...
)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧) 在大型Qt/C项目中,调试往往像在迷宫中摸索——图形化界面提供了便利,但当问题隐藏在动态库或第三方代码深处时,频繁点击"下一…...

Termius中文版:安卓SSH客户端的完整汉化解决方案
Termius中文版:安卓SSH客户端的完整汉化解决方案 【免费下载链接】Termius-zh_CN 汉化版的Termius安卓客户端 项目地址: https://gitcode.com/alongw/Termius-zh_CN 对于需要频繁管理远程服务器的中文用户来说,英文界面的SSH客户端常常成为技术操…...

Cursor Pro功能完全解锁指南:三步实现免费无限使用终极方案
Cursor Pro功能完全解锁指南:三步实现免费无限使用终极方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列创意软件
Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列创意软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud用…...

3分钟掌握Illustrator批量替换神器:ReplaceItems.jsx终极效率指南
3分钟掌握Illustrator批量替换神器:ReplaceItems.jsx终极效率指南 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Illustrator中重复的替换操作烦恼吗?…...