MySQL进阶_EXPLAIN重点字段解析
文章目录
- 第一节.准备
- 1.1 版本信息
- 1.2 准备
- 第二节.type
- 2.1 system
- 2.2 const
- 2.3 eq_ref
- 2.4 ref
- 2.5 ref_or_null
- 2.6 index_merge
- 2.7 unique_subquery
- 2.8 range
- 2.9 index
- 2.10 all
- 第三节. Extra
- 3.1 No tables used
- 3.2 No tables used
- 3.3 Using where
- 3.4 No matching min/max row
- 3.5 Using index
- 3.6 Using index condition
- 3.7 Using filesort
- 3.8 Using temporary
- 第四节. Explain总结
第一节.准备
1.1 版本信息
- MySQL 5.6.3以前只能
EXPLAIN SELECT;MYSQL 5.6.3以后就可以EXPLAIN SELECT,UPDATE,DELETE - 在5.7以前的版本中,想要显示 partitions 需要使用
explain partitions命令;想要显示filtered 需要使用explain extended命令。在5.7版本后,默认explain直接显示partitions和filtered中的信息。
1.2 准备
创建两张表,利用函数和存储过程各在两张表中插入10000条数据。
CREATE TABLE s1 (id INT AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),INDEX idx_key1 (key1),UNIQUE INDEX idx_key2 (key2),INDEX idx_key3 (key3),INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
CREATE TABLE s2 (id INT AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),INDEX idx_key1 (key1),UNIQUE INDEX idx_key2 (key2),INDEX idx_key3 (key3),INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;
第二节.type
完整的访问方法如下: system , const , eq_ref , ref , fulltext , ref_or_null ,index_merge , unique_subquery , index_subquery , range , index , ALL 。
2.1 system
当表中只有一条记录,并且该表使用的存储引擎的统计数据是精确的,比如:MyISAM、Memory, 那么对该表的访问方法就是system。
CREATE TABLE t(i INT) ENGINE=MYISAM;
INSERT INTO t VALUES(1);
EXPLAIN SELECT * FROM t;

#换成InnoDBCREATE TABLE tt(i INT) ENGINE=INNODB;INSERT INTO tt VALUES(1);EXPLAIN SELECT * FROM tt;

2.2 const
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const
EXPLAIN SELECT * FROM s1 WHERE id = 10005;

EXPLAIN SELECT * FROM s1 WHERE key2 = 10066;

2.3 eq_ref
在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_ref
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;

2.4 ref
当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是ref
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';

2.5 ref_or_null
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key1 IS NULL;

2.6 index_merge
单表访问方法时在某些场景下可以使用Intersection、Union、Sort-Union这三种索引合并的方式来执行查询
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

2.7 unique_subquery
unique_subquery是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的type列的值就是unique_subquery
EXPLAIN SELECT * FROM s1 WHERE key2 IN (SELECT id FROM s2 WHERE s1.key1 = s2.key1) OR key3 = 'a';

2.8 range
如果使用索引获取某些范围区间的记录,那么就可能使用到range访问方法
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');

EXPLAIN SELECT * FROM s1 WHERE key1 > 'a' AND key1 < 'b';

2.9 index
当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是index
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

按照常理,因为联合索引是以key_part1开头的,所以此查询无法使用索引。但是要查询的列key_part2的信息包含在此联合索引中,所以解析结果的key列显示使用了联合索引,这就是覆盖索引。但是想找到key_part3 = 'a’的信息,需要扫描全部的索引记录。
2.10 all
最熟悉的全表扫描
EXPLAIN SELECT * FROM s1;

结果值从最好到最坏依次是:
system > const > eq_ref> ref > fulltext > ref_or_null >> index_merge >unique_subquery > index_subquery >range > index > ALL。> 其中比较重要的几个提取出来(红色的字体)。SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是> const级别。(阿里巴巴开发手册要求)
第三节. Extra
更准确的理解MySQL到底将如何执行给定的查询语句
3.1 No tables used
当查询语句的没有FROM子句时将会提示该额外信息
EXPLAIN SELECT 1;

3.2 No tables used
查询语句的WHERE子句永远为FALSE时将会提示该额外信息
EXPLAIN SELECT * FROM s1 WHERE 1 != 1;

3.3 Using where
当我们使用全表扫描来执行对某个表的查询,并且该语句的WHERE子句中有针对该表的搜索条件时,在Extra列中会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE common_field = 'a';

当使用索引访问来执行对某个表的查询,并且该语句的WHERE子句中有除了该索引包含的列之外的其他搜索条件时,在Extra列中也会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' AND common_field = 'a';

3.4 No matching min/max row
当查询列表处有MIN或者MAX聚合函数,但是并没有符合WHERE子句中的搜索条件的记录时,将会提示该额外信息
# 此时表中不存在这样的数据EXPLAIN SELECT MIN(key1) FROM s1 WHERE key1 = 'abcdefg';

3.5 Using index
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在Extra列将会提示该额外信息。比方说下边这个查询中只需要用到idx_key1而不需要回表操作:
EXPLAIN SELECT key1 FROM s1 WHERE key1 = 'a';

EXPLAIN SELECT key1,id FROM s1 WHERE key1 = 'a';

此时查询列表中多了id列,由于key1的二级索引中含有id信息,所以还是using index;
EXPLAIN SELECT key1,id,key2 FROM s1 WHERE key1 = 'a';

再加一个查询列key2就不能走覆盖索引了。
3.6 Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引。
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';

按照正常逻辑,where后的查询条件无法使用索引。但是结果显示使用到了索引,这就是索引下推。
3.7 Using filesort
有一些情况下对结果集中的记录进行排序是可以使用到索引的。
EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;

这个查询语句可以利用idx_key1索引直接取出key1列的10条记录,然后再进行回表操作就好了。但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中〈(记录较多)的时候进行排序,MySQL把这种在内存中或者磁盘上进行排序的方式统称为文件排序(英文名: filesort)。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort提示,比如这样:
EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;

3.8 Using temporary
在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行计划的Extra列将会显示Using temporary提示:
EXPLAIN SELECT DISTINCT common_field FROM s1;

EXPLAIN SELECT common_field, COUNT(*) AS amount FROM s1 GROUP BY common_field;

执行计划中出现Using temporary并不是一个好的征兆,因为建立与维护临时表要付出很大成本的,所以我们最好能使用索引来替代掉使用临时表。比如:扫描指定的索引idx_key1即可
EXPLAIN SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;

第四节. Explain总结
- EXPLAIN不考虑各种Cache,只针对SQL语句做分析
- EXPLAIN不能显示MySQL在执行查询时所作的优化工作,只显示最终结果
- EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
部分统计信息是估算的,并非精确值(比如rows,filted)
相关文章:
MySQL进阶_EXPLAIN重点字段解析
文章目录 第一节.准备1.1 版本信息1.2 准备 第二节.type2.1 system2.2 const2.3 eq_ref2.4 ref2.5 ref_or_null2.6 index_merge2.7 unique_subquery2.8 range2.9 index2.10 all 第三节. Extra3.1 No tables used3.2 No tables used3.3 Using where3.4 No matching min/max row3…...
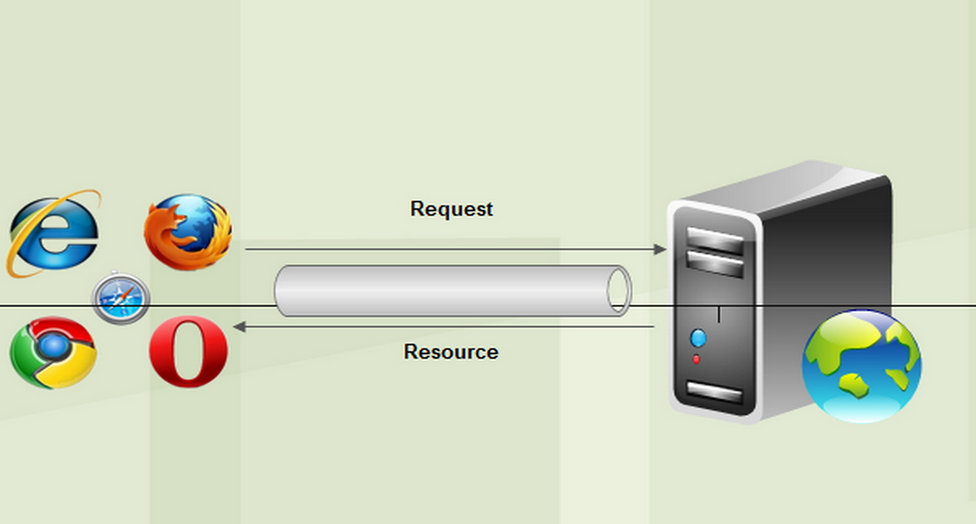
视图层与模板层
视图层 1 视图函数 一个视图函数,简称视图,是一个简单的Python 函数,它接受Web请求并且返回Web响应。响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片. . . 是…...
)
MySQL数据库——触发器-案例(Insert类型、Update类型和Delete类型)
目录 表结构准备 插入数据触发器 代码 测试 修改数据触发器 代码 测试 删除数据触发器 代码 测试 通过触发器记录 tb_user 表的数据变更日志,将变更日志插入到日志表user_logs中,包含增加,修改,删除。 表结构准备 根据…...
)
快速创建桌面端(electron-egg)
介绍 | electron-egg electron-egg: 一个入门简单、跨平台、企业级桌面软件开发框架。 electron-egg是一个基于Electron和Egg.js的框架,可以用于快速构建跨平台的桌面应用程序。 1.兼容平台:electron-egg可以在Windows、MacOS和Linux等多个平台上运行…...

docker配置redis插件
docker配置redis插件 运行容器redis_6390 docker run -it \ --name redis_6390 \ --privileged \ -p 6390:6379 \ --network wn_docker_net \ --ip 172.18.12.19 \ --sysctl net.core.somaxconn1024 \ -e TIME_ZONE"Asia/Shanghai" -e TZ"Asia/Shanghai"…...
前端入口教程_web01
web标准 记得看! html:表示整个页面 head: titile: body: 常用标签 1.标题标签 2.段落标签 3.换行标签 4.文本格式化标签 5. 和 标签 6.图像标签 相对路径–用来插自己本地的图片 #### 绝对路径–用来插网上找的图…...
Win7 SP1 x64 Google Chrome 字体模糊
1 打开 Google Chrome ,地址栏输入 chrome://version/ ,字体模糊。 2 Microsoft Update Catalog 搜索更新 kb2670838,下载,安装,重启电脑。 3 打开 Google Chrome,地址栏输入 chrome://version/ ࿰…...
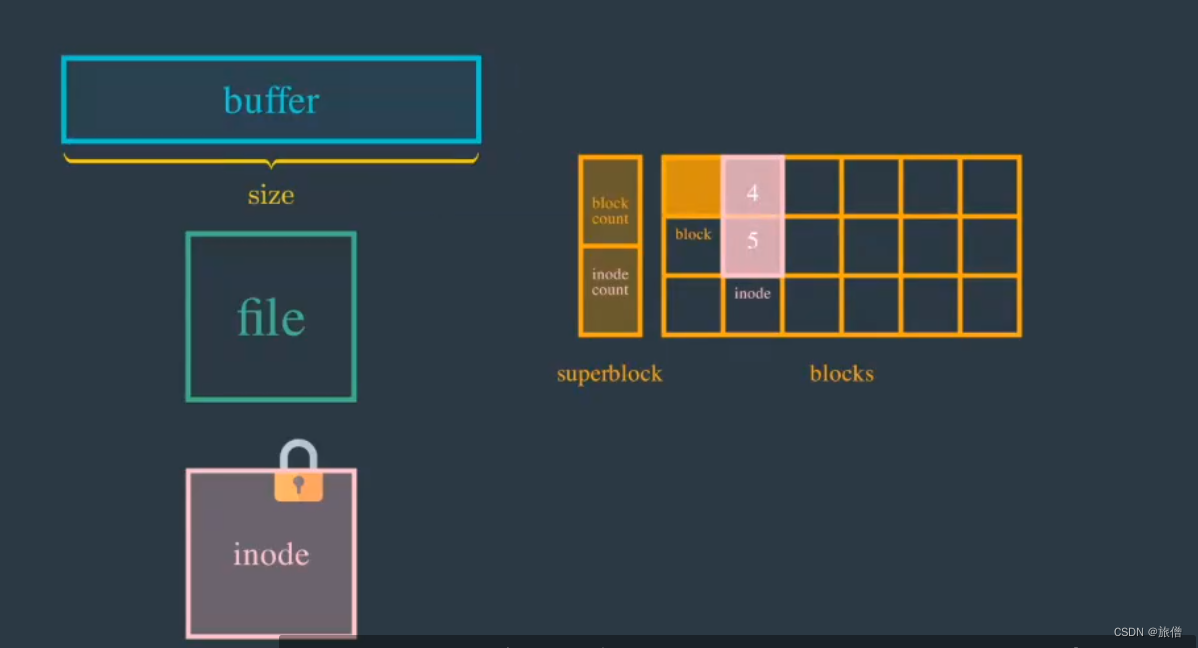
read()之后操作系统都干了什么
首先说明三个参数 file文件 buff从内存中开辟一段缓冲区用来接收读取的数据 size表示这个缓冲区的大小 有关file的参数: 状态:被打开 被关闭权限:可读可写最重要的是inode: 他包含了 文件的元数据(比如文件大小 文件类型 文件在访问前需要加…...
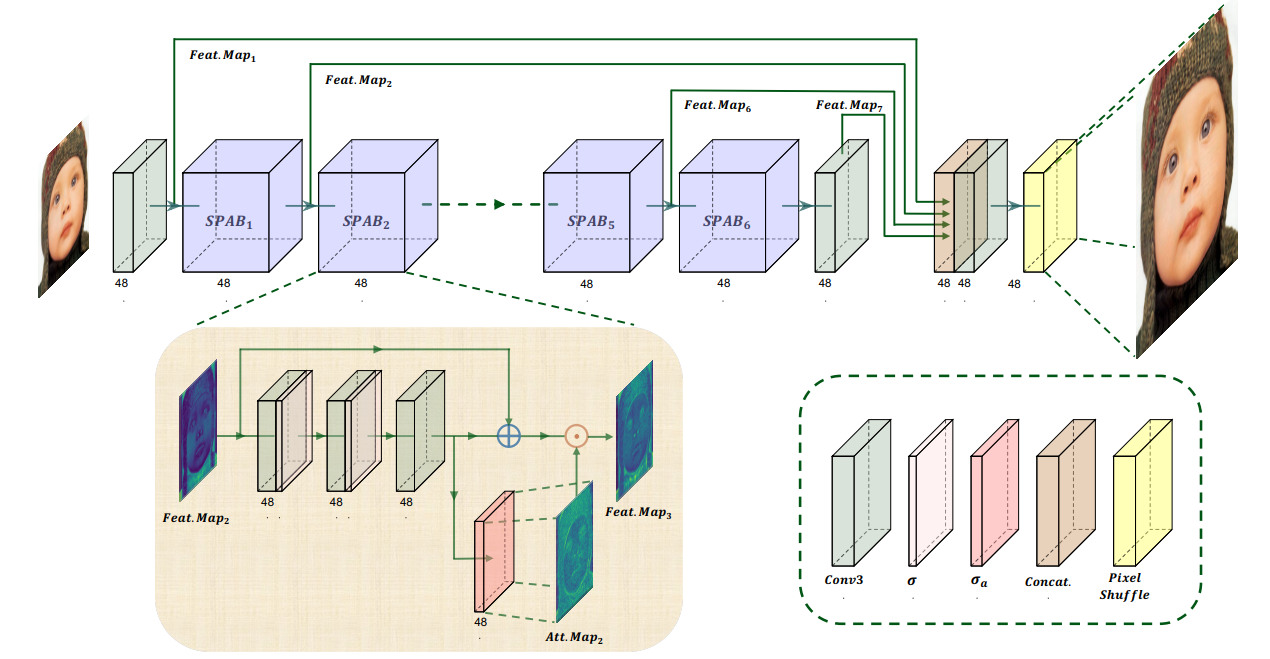
YoloV8改进策略:Swift Parameter-free Attention,无参注意力机制,超分模型的完美迁移
摘要 https://arxiv.org/pdf/2311.12770.pdf https://github.com/hongyuanyu/SPAN SPAN是一种超分网络模型。SPAN模型通过使用参数自由的注意力机制来提高SISR的性能。这种注意力机制能够增强重要信息并减少冗余,从而在图像超分辨率过程中提高图像质量。 具体来说,SPAN模…...

Python----练习:使用面向对象实现报名系统开发
第一步:分析哪些动作是由哪些实体发出的 学生提出报名 学生提供相关资料 学生缴费 机构收费 教师分配教室 班级增加学生信息 于是,在整个过程中,一共有四个实体:学生、机构、教师、班级!在现实中的一个具体的实…...

1.什么是html
1.什么是html什么是html? 一.基础信息 英文名字:HyperText Markup Language 中文名字:超文本标记语言 简称:html 文件格式:.htm 或 .html 结尾 作用:描述网页的语言。通过各种各样的标签,组…...
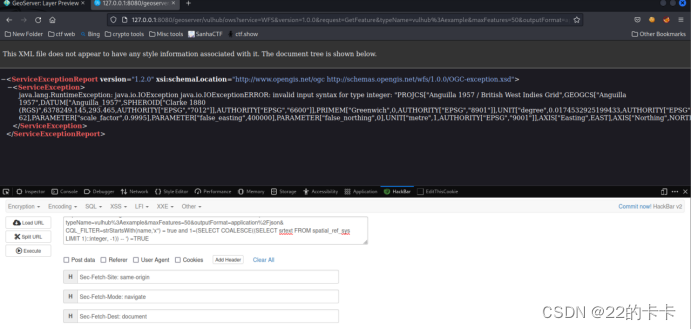
GeoServer漏洞(CVE-2023-25157)
前半部分是sql注入一些语句的测试,后面是漏洞的复现和利用 Sql注入漏洞 1.登入mysql。 2.查看默认数据库 3.使用mysql数据库 4.查看表 1.查看user 表 2.写注入语句 创建数据库 时间注入语句 布尔注入语句 报错注入语句 Geoserver漏洞ÿ…...
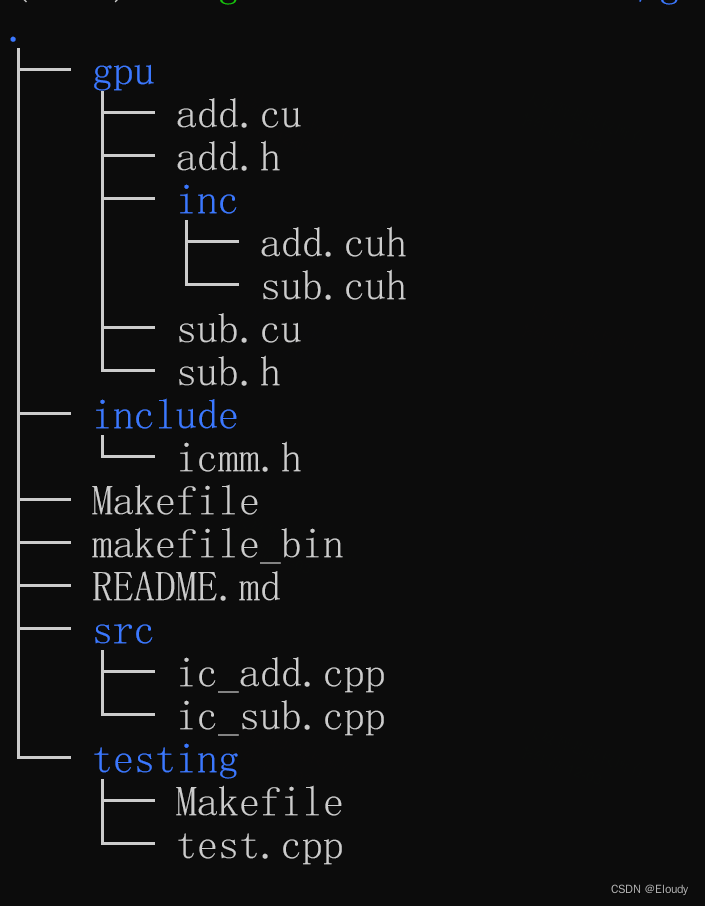
一个完整的手工构建的cuda动态链接库工程 03记
1, 源代码 仅仅是加入了模板函数和对应的 .cuh文件,当前的目录结构如下: icmm/gpu/add.cu #include <stdio.h> #include <cuda_runtime.h>#include "inc/add.cuh"// different name in this level for different type…...

rdf-file:SM2加解密
一:SM2简介 SM2是中国密码学算法标准中的一种非对称加密算法(包括公钥和私钥)。SM2主要用于数字签名、密钥交换和加密解密等密码学。 生成秘钥:用于生成一对公钥和私钥。公钥:用于加密数据和验证数字签名。私钥&…...

harmonyOS学习笔记之@Styles装饰器与@Extend装饰器
Styles装饰器 定义组件重用样式 自定义样式函数使用装饰器 可以定义在组件内或全局,内部优先级>外部,内部不需要function,外部需要function 定义在组件内的styles可以通过this访问组件内部的常量和状态变量,可以在styles里通过事件来改变状态变量 弊端:只支持通用属性和通用…...
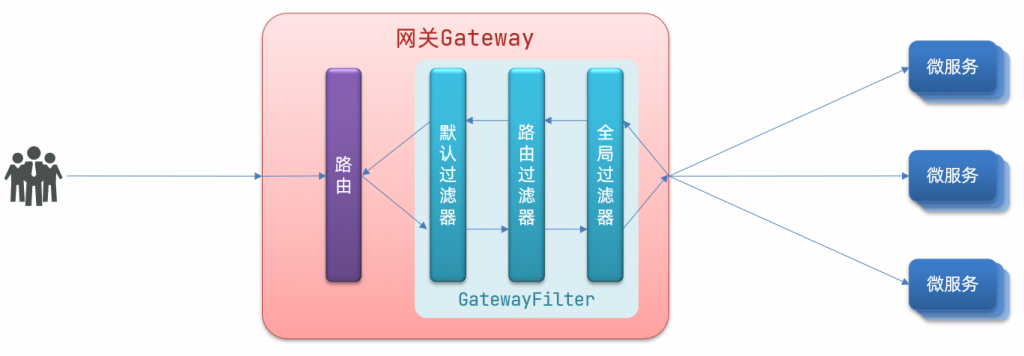
GateWay的路由与全局过滤器
1.断言工厂 我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件 例如Path/user/**是按照路径匹配,这个规则是由 org.springframework.cloud.gateway.handler.predicate.PathRoutePr…...

MuleSoft 中的细粒度与粗粒度 API
API 设计是一个令人着迷的话题。API 设计的一个重要方面是根据 API 的特性和功能确定正确的“大小”。所有建筑师都必须在某个时候解决过这个问题。在本文中,我将尝试对我们在获得“正确的”粒度 API 之前需要考虑的各种参数进行一些深入的探讨: 可维护…...
【笔记】2023最新Python安装教程(Windows 11)
🎈欢迎加群交流(备注:csdn)🎈 ✨✨✨https://ling71.cn/hmf.jpg✨✨✨ 🤓前言 作为一名经验丰富的CV工程师,今天我将带大家在全新的Windows 11系统上安装Python。无论你是编程新手还是老手&…...

Android Wifi断开问题分析和802.11原因码
Android Wifi连接和断链分析思路。 1.密码错误导致的连接失败 2.关联被拒绝 3.热点未回复AUTH_RSP或者STA未收到 AUTH_RSP 4.热点未回复ASSOC_RSP或者STA未收到ASSOC_RSP 5.DHCP FAILURE 6.发生roaming 7.AP发送了DEAUTH帧导致断开连接 8.被AP踢出,这个原因…...
【Cell Signaling + 神经递质(neurotransmitter) ; 神经肽 】
Neuroscience EndocytosisExcitatory synapse pathwayGlutamatergic synapseInflammatory PainInhibitors of axonal regenerationNeurotrophin signaling pathwaySecreted Extracellular VesiclesSynaptic vesicle cycle...

Python 3.14.5 发布:多项改进,垃圾回收器回滚,还有这些新特性!
Python 3.14.5 发布Python 3.14.5 现已发布,这是 3.14 的第五个维护版本。自 3.14.4 以来,包含约 154 项错误修复、构建改进和文档更改。垃圾回收器回滚值得注意的是,Python 3.14.5 中的垃圾回收器 (GC) 发生了变化。由于一些原因,…...

OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案
OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record 你是否曾经在直播或录制视频时,想要单独保存某个特定的画面源…...

嵌入式开发中的编程规范实践与行业标准解析
1. 编程规范的本质与价值在嵌入式汽车电子领域干了十五年,我见过太多因为代码不规范导致的惨痛教训。有一次,某车企的ECU控制模块在零下30度环境突然死机,排查三周后发现是未初始化的指针在低温环境下产生了非预期行为——这种问题本可以通过…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

Windows上的APK安装革命:如何用开源工具无缝运行安卓应用
Windows上的APK安装革命:如何用开源工具无缝运行安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows和安卓生态之间的鸿沟而烦恼吗&…...

从MATLAB到FPGA:高效生成三种波形COE文件的实战指南
1. COE文件格式解析与FPGA应用场景 COE文件是Xilinx FPGA设计中用于初始化Block RAM(BRAM)的标准文件格式。我第一次接触这种文件时,发现它其实就是一个带有特定格式要求的文本文件,但正是这种简单的结构,让它成为MATL…...

FcμR识别IgM复杂机制的揭示:解锁人体免疫早期应答之谜
一、引言免疫系统是机体抵御病原体入侵、维持内环境稳定的关键防线。在免疫应答过程中,不同类型的免疫球蛋白发挥着独特的作用。其中,IgM作为人体五类免疫球蛋白之一,在免疫应答早期起着至关重要的作用。而Fc受体作为免疫系统中的重要组成部分…...

CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件
CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 还在为重复的Java和Scala编码工作而烦恼…...

羽毛球每天必练的基本功:拉吊四方球战术、吊杀结合战术
文章目录 引言 I 羽毛球每天必练的基本功 1. 握拍练习 2. 挥拍动作 3. 步法训练 4. 球感练习 5. 发力技巧 II 发力 正确发力 握拍 反手发力 III 羽毛球单打战术 拉吊四方球战术 直线变斜线战术 重复落点战术 吊杀结合战术 追身球压制战术 防守反击战术 引言 打球前必须热身(活…...

为什么选择这个Windows键盘记录工具?3个让你无法拒绝的理由
为什么选择这个Windows键盘记录工具?3个让你无法拒绝的理由 【免费下载链接】keylogger Keylogger for Windows. 项目地址: https://gitcode.com/gh_mirrors/keylogg/keylogger 你是否曾经需要监控自己的电脑使用情况,或者为技术研究寻找一个轻量…...