一个完整的手工构建的cuda动态链接库工程 03记
1, 源代码
仅仅是加入了模板函数和对应的 .cuh文件,当前的目录结构如下:
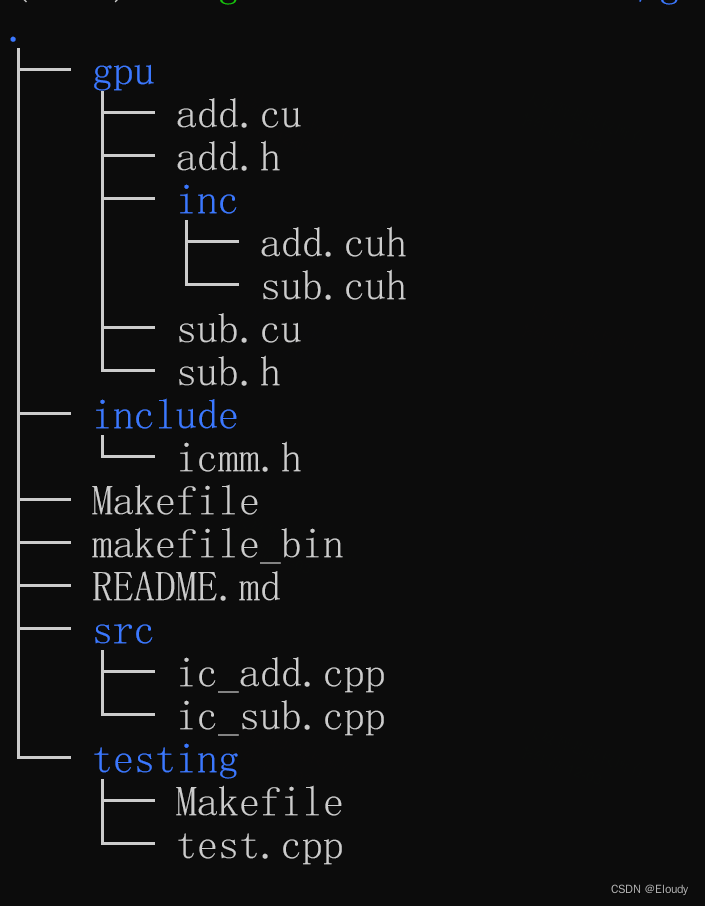
icmm/gpu/add.cu
#include <stdio.h>
#include <cuda_runtime.h>#include "inc/add.cuh"// different name in this level for different typename, as extern "C" can not decorate template function that is in C++;extern "C" void vector_add_gpu_s(float *A, float *B, float *C, int n)
{dim3 grid, block;block.x = 256;grid.x = (n + block.x - 1) / block.x;printf("CUDA kernel launch with %d blocks of %d threads\n", grid.x, block.x);vector_add_kernel<><<<grid, block>>>(A, B, C, n);
}extern "C" void vector_add_gpu_d(double* A, double* B, double* C, int n)
{dim3 grid, block;block.x = 256;grid.x = (n + block.x - 1) / block.x;printf("CUDA kernel launch with %d blocks of %d threads\n", grid.x, block.x);vector_add_kernel<><<<grid, block>>>(A, B, C, n);
}
icmm/gpu/add.h
#pragma onceextern "C" void vector_add_gpu_s(float *A, float *B, float *C, int n);
extern "C" void vector_add_gpu_d(double* A, double* B, double* C, int n);
icmm/gpu/inc/add.cuh
#pragma oncetemplate<typename T>
__global__ void vector_add_kernel(T *A, T *B, T *C, int n)
{int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < n){C[i] = A[i] + B[i] + 0.0f;}
}icmm/gpu/inc/sub.cuh
#pragma oncetemplate<typename T>
__global__ void vector_sub_kernel(T *A, T *B, T *C, int n)
{int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < n){C[i] = A[i] - B[i] + 0.0f;}
}icmm/gpu/sub.cu
#include <stdio.h>
#include <cuda_runtime.h>
#include "inc/sub.cuh"extern "C" void vector_sub_gpu_s(float *A, float *B, float *C, int n)
{dim3 grid, block;block.x = 256;grid.x = (n + block.x - 1) / block.x;printf("CUDA kernel launch with %d blocks of %d threads\n", grid.x, block.x);vector_sub_kernel<><<<grid, block>>>(A, B, C, n);
}extern "C" void vector_sub_gpu_d(double *A, double *B, double *C, int n)
{dim3 grid, block;block.x = 256;grid.x = (n + block.x - 1) / block.x;printf("CUDA kernel launch with %d blocks of %d threads\n", grid.x, block.x);vector_sub_kernel<><<<grid, block>>>(A, B, C, n);
}
icmm/gpu/sub.h
#pragma onceextern "C" void vector_sub_gpu_s(float *A, float *B, float *C, int n);
extern "C" void vector_sub_gpu_d(double *A, double *B, double *C, int n);
icmm/include/icmm.h
#pragma once
#include<cuda_runtime.h>void hello_print();
void ic_S_add(float* A, float* B, float *C, int n);
void ic_D_add(double* A, double* B, double* C, int n);void ic_S_sub(float* A, float* B, float *C, int n);
void ic_D_sub(float* A, float* B, float *C, int n);icmm/Makefile
#libicmm.soTARGETS = libicmm.so
GPU_ARCH= -arch=sm_70all: $(TARGETS)sub.o: gpu/sub.cunvcc -Xcompiler -fPIC $(GPU_ARCH) -c $<add.o: gpu/add.cunvcc -Xcompiler -fPIC $(GPU_ARCH) -c $<
#-dc
#-rdc=trueadd_link.o: add.onvcc -Xcompiler -fPIC $(GPU_ARCH) -dlink -o $@ $< -L/usr/local/cuda/lib64 -lcudart -lcudadevrtic_add.o: src/ic_add.cppg++ -fPIC -c $< -L/usr/local/cuda/lib64 -I/usr/local/cuda/include -lcudart -lcudadevrt -I./ic_sub.o: src/ic_sub.cppg++ -fPIC -c $< -L/usr/local/cuda/lib64 -I/usr/local/cuda/include -lcudart -lcudadevrt -I./$(TARGETS): sub.o ic_sub.o add.o ic_add.o add_link.omkdir -p libg++ -shared -fPIC $^ -o lib/libicmm.so -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -lcudadevrt -rm -f *.o.PHONY:clean
clean:-rm -f *.o lib/*.so test ./bin/test-rm -rf lib bin
icmm/makefile_bin
# executable
TARGET = test
GPU_ARCH = -arch=sm_70all: $(TARGET)add.o: gpu/add.cunvcc -dc -rdc=true $(GPU_ARCH) -c $<sub.o: gpu/sub.cunvcc -dc -rdc=true $(GPU_ARCH) -c $<add_link.o: add.onvcc $(GPU_ARCH) -dlink -o $@ $< -L/usr/local/cuda/lib64 -lcudart -lcudadevrtsub_link.o: sub.onvcc $(GPU_ARCH) -dlink -o $@ $< -L/usr/local/cuda/lib64 -lcudart -lcudadevrtic_add.o: src/ic_add.cppg++ -c $< -L/usr/local/cuda/lib64 -I/usr/local/cuda/include -lcudart -lcudadevrt -I./ic_sub.o: src/ic_sub.cppg++ -c $< -L/usr/local/cuda/lib64 -I/usr/local/cuda/include -lcudart -lcudadevrt -I./test.o: testing/test.cppg++ -c $< -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -lcudadevrt -I./includetest: sub.o ic_sub.o sub_link.o add.o ic_add.o test.o add_link.og++ $^ -L/usr/local/cuda/lib64 -lcudart -lcudadevrt -o testmkdir ./bincp ./test ./bin/-rm -f *.o.PHONY:clean
clean:-rm -f *.o bin/* $(TARGET)
icmm/src/ic_add.cpp
#include <stdio.h>
#include <cuda_runtime.h>
#include "gpu/add.h"
//extern void vector_add_gpu(float *A, float *B, float *C, int n);void hello_print()
{printf("hello world!\n");
}//void ic_add(float* A, float* B, float *C, int n){ vector_add_gpu(A, B, C, n);}
void ic_S_add(float* A, float* B, float *C, int n)
{vector_add_gpu_s(A, B, C, n);
}void ic_D_add(double* A, double* B, double* C, int n)
{vector_add_gpu_d(A, B, C, n);
}icmm/src/ic_sub.cpp
#include <stdio.h>
#include <cuda_runtime.h>#include "gpu/sub.h"
//extern void vector_add_gpu(float *A, float *B, float *C, int n);
void ic_S_sub(float* A, float* B, float *C, int n)
{vector_sub_gpu_s(A, B, C, n);
}void ic_D_sub(double* A, double* B, double *C, int n)
{vector_sub_gpu_d(A, B, C, n);
}icmm/testing/Makefile
#testTARGET = testall: $(TARGET)CXX_FLAGS = -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -lcudadevrt -I../include -L../test.o: test.cppg++ -c $< $(CXX_FLAGS)$(TARGET):test.og++ $< -o $@ -L/usr/local/cuda/lib64 -lcudart -lcudadevrt -L../lib -licmm@echo "to execute: export LD_LIBRARY_PATH=${PWD}/../lib".PHONY:clean
clean:-rm -f *.o $(TARGET)
icmm/testing/test.cpp
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>#include "icmm.h"void add_test_s(float* A, float* B, float* C, int n)
{ic_S_add(A, B, C, n);printf("Copy output data from the CUDA device to the host memory\n");float* h_C = (float*)malloc(n*sizeof(float));cudaMemcpy(h_C, C, n*sizeof(float), cudaMemcpyDeviceToHost);for (int i = 0; i < n; ++i){printf("%3.2f ", h_C[i]);// if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) { fprintf(stderr, "Result verification failed at element %d!\n", i); exit(EXIT_FAILURE); }}printf("\nTest PASSED\n");free(h_C);
}/**/
void add_test_d(double* A, double* B, double* C, int n)
{ic_D_add(A, B, C, n);printf("Copy output data from the CUDA device to the host memory\n");float *h_C = (float *)malloc(n*sizeof(double));cudaMemcpy(h_C, C, sizeof(double), cudaMemcpyDeviceToHost);for (int i = 0; i < n; ++i){printf("%3.2f ", h_C[i]);// if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) { fprintf(stderr, "Result verification failed at element %d!\n", i); exit(EXIT_FAILURE); }}printf("\nTest PASSED\n");free(h_C);
}/**/
void sub_test_s(float* A, float* B, float* C, int n)
{ic_S_sub(A, B, C, n);printf("Copy output data from the CUDA device to the host memory\n");float* h_C = (float*)malloc(n*sizeof(float));cudaMemcpy(h_C, C, n*sizeof(float), cudaMemcpyDeviceToHost);for (int i = 0; i < n; ++i){printf("%3.2f ", h_C[i]);// if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) { fprintf(stderr, "Result verification failed at element %d!\n", i); exit(EXIT_FAILURE); }}printf("\nTest PASSED\n");free(h_C);
}int main(void)
{int n = 50;size_t size = n * sizeof(float);float *h_A = (float *)malloc(size);float *h_B = (float *)malloc(size);float *h_C = (float *)malloc(size);for (int i = 0; i < n; ++i){h_A[i] = rand() / (float)RAND_MAX;h_B[i] = rand() / (float)RAND_MAX;}float *d_A = NULL;float *d_B = NULL;float *d_C = NULL;cudaMalloc((void **)&d_A, size);cudaMalloc((void **)&d_B, size);cudaMalloc((void **)&d_C, size);cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
/*int threadsPerBlock = 256;int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);vector_add_kernel<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, n);
*///ic_add(d_A, d_B, d_C, n);add_test_s(d_A, d_B, d_C, n);sub_test_s(d_A, d_B, d_C, n);cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);free(h_A);free(h_B);free(h_C);printf("Done\n");return 0;
}
2. 总结
.cu 代码给 g++ 的 .cpp 的代码需要使用 extern "C" 来修饰,所以一template 函数的实例化不能一直贯彻到 .cu 源代码的最顶层;
相关文章:
一个完整的手工构建的cuda动态链接库工程 03记
1, 源代码 仅仅是加入了模板函数和对应的 .cuh文件,当前的目录结构如下: icmm/gpu/add.cu #include <stdio.h> #include <cuda_runtime.h>#include "inc/add.cuh"// different name in this level for different type…...

rdf-file:SM2加解密
一:SM2简介 SM2是中国密码学算法标准中的一种非对称加密算法(包括公钥和私钥)。SM2主要用于数字签名、密钥交换和加密解密等密码学。 生成秘钥:用于生成一对公钥和私钥。公钥:用于加密数据和验证数字签名。私钥&…...

harmonyOS学习笔记之@Styles装饰器与@Extend装饰器
Styles装饰器 定义组件重用样式 自定义样式函数使用装饰器 可以定义在组件内或全局,内部优先级>外部,内部不需要function,外部需要function 定义在组件内的styles可以通过this访问组件内部的常量和状态变量,可以在styles里通过事件来改变状态变量 弊端:只支持通用属性和通用…...
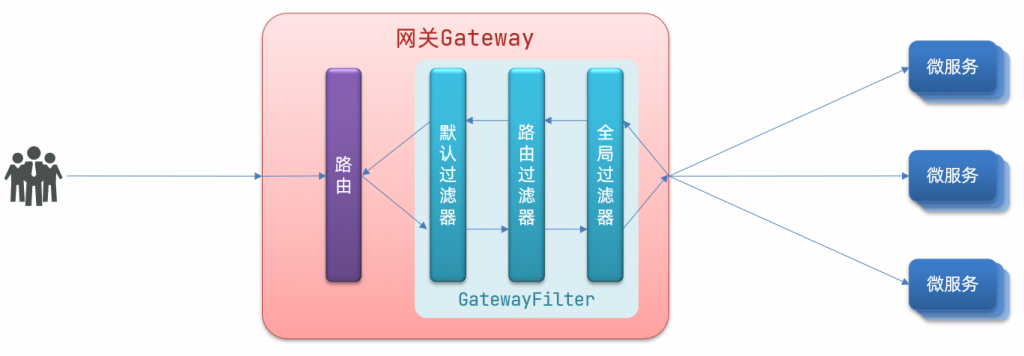
GateWay的路由与全局过滤器
1.断言工厂 我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件 例如Path/user/**是按照路径匹配,这个规则是由 org.springframework.cloud.gateway.handler.predicate.PathRoutePr…...

MuleSoft 中的细粒度与粗粒度 API
API 设计是一个令人着迷的话题。API 设计的一个重要方面是根据 API 的特性和功能确定正确的“大小”。所有建筑师都必须在某个时候解决过这个问题。在本文中,我将尝试对我们在获得“正确的”粒度 API 之前需要考虑的各种参数进行一些深入的探讨: 可维护…...
【笔记】2023最新Python安装教程(Windows 11)
🎈欢迎加群交流(备注:csdn)🎈 ✨✨✨https://ling71.cn/hmf.jpg✨✨✨ 🤓前言 作为一名经验丰富的CV工程师,今天我将带大家在全新的Windows 11系统上安装Python。无论你是编程新手还是老手&…...

Android Wifi断开问题分析和802.11原因码
Android Wifi连接和断链分析思路。 1.密码错误导致的连接失败 2.关联被拒绝 3.热点未回复AUTH_RSP或者STA未收到 AUTH_RSP 4.热点未回复ASSOC_RSP或者STA未收到ASSOC_RSP 5.DHCP FAILURE 6.发生roaming 7.AP发送了DEAUTH帧导致断开连接 8.被AP踢出,这个原因…...
【Cell Signaling + 神经递质(neurotransmitter) ; 神经肽 】
Neuroscience EndocytosisExcitatory synapse pathwayGlutamatergic synapseInflammatory PainInhibitors of axonal regenerationNeurotrophin signaling pathwaySecreted Extracellular VesiclesSynaptic vesicle cycle...

当springsecurity出现SerializationException问题
当springsecurity出现SerializationException问题 01 异常发生场景 当我使用springsecurity时,登录成功后携带token访问接口出了问题 org.springframework.data.redis.serializer.SerializationException: Could not read JSON: Unrecognized field "userna…...
[SaaS] 广告创意中stable-diffusion的应用
深度对谈:广告创意领域中 AIGC 的应用这个领域非常快速发展,所以你应该保持好奇心,不断尝试新事物,不断挑战自己。https://mp.weixin.qq.com/s/ux9iEABNois3y4wwyaDzAQ我对AIGC领域应用调研,除了MaaS服务之外ÿ…...
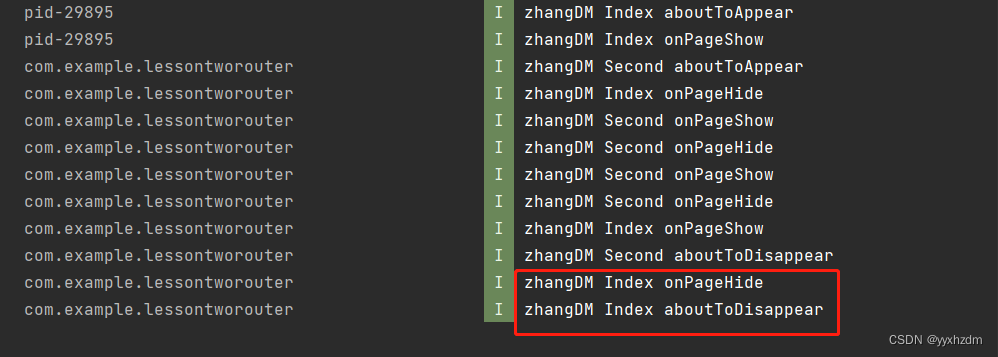
第八节HarmonyOS @Component自定义组件的生命周期
在开始之前,我们先明确自定义组件和页面的关系: 1、自定义组件:Component装饰的UI单元,可以组合多个系统组件实现UI的复用。 2、页面:即应用的UI页面。可以由一个或者多个自定义组件组成,Entry装饰的自定…...
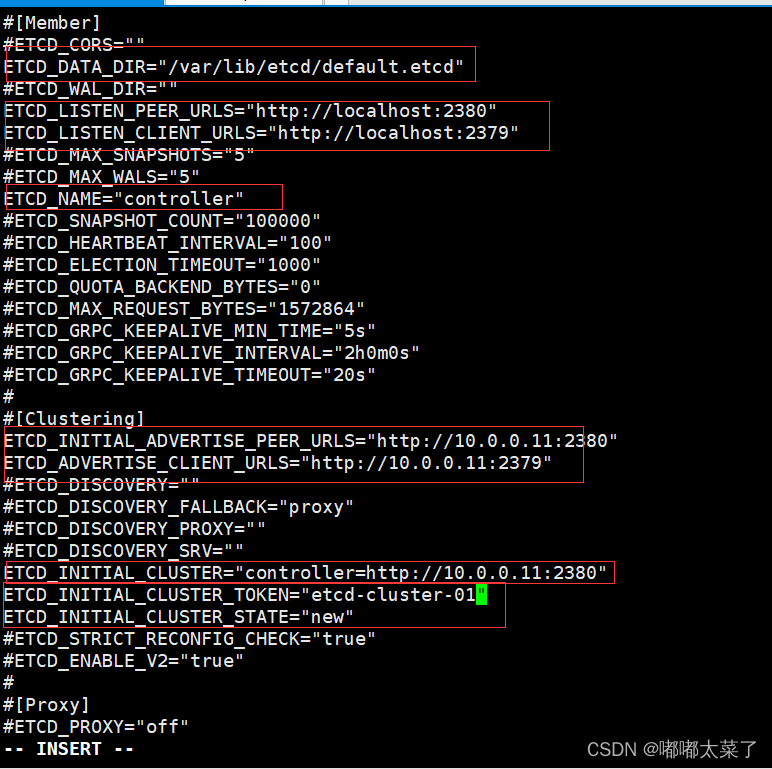
【Openstack Train安装】五、Memcached/Etcd安装
本文介绍Memcached/Etcd安装步骤,Memcached/Etcd仅需在控制节点安装。 在按照本教程安装之前,请确保完成以下配置: 【Openstack Train安装】一、虚拟机创建 【Openstack Train安装】二、NTP安装 【Openstack Train安装】三、openstack安装…...

29 kafka动态配置
为什么需要动态配置 线上运行的kafka broker修改配置需要重启的话,影响比较大。需要一个不需要重启就能使参数生效的功能 使用的场景 配置优先级: per-broker参数 > cluster-wide参数 > static参数 > 默认参数 1.动态调整network线程数和工…...

JIRA部分数据库结构
表jiraissue(问题表) 字段 数据类型 是否为空 KEY 说明 ID decimal(18,0) NO PRI 主键 pkey varchar(255) YES MUL 查看主键,“项目ID” PROJECT decimal(18,0) YES MUL 项目外键,项目表外键 REPORTER varch…...
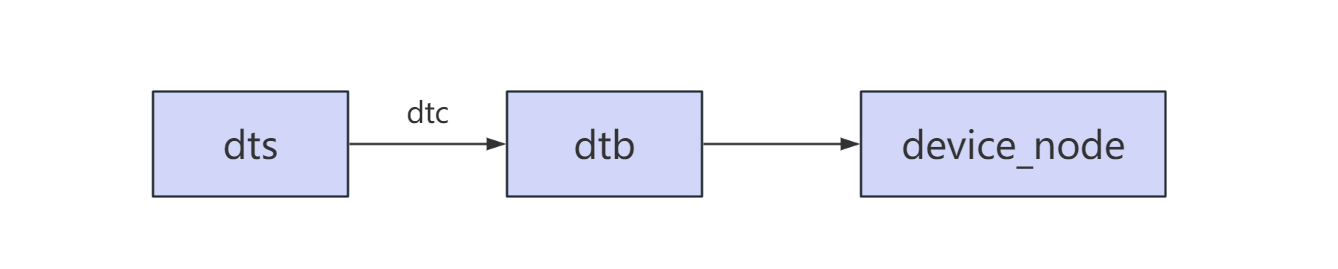
RK3568平台开发系列讲解(Linux系统篇) dtb 到 device_node 的转化
🚀返回专栏总目录 文章目录 一、dtb 展开流程二、dtb 解析过程源码分析沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将介绍通过设备树 dtb 如何展开成 device_node 一、dtb 展开流程 设备树源文件编写: 根据设备树的基本语法和相关知识编写符合规范的设备树。…...

屏幕的刷新率和分辨率
一、显示器刷新率和分辨率的区别 1、显示器刷新率是什么意思? 刷新率是指电子束对屏幕上的图像重复扫描的次数。刷新率越高,所显示的图像(画面)稳定就越好。 刷新率高低直接决定其价格,但是由于刷新率与分辨率两者相互制约,因此只有在高分辨率下达到…...

面试官:请说说JS中的防抖和节流
给大家推荐一个实用面试题库 1、前端面试题库 (面试必备) 推荐:★★★★★ 地址:web前端面试题库 前言 为什么要做性能优化?性能优化到底有多重要? 性能优化是为了提供更好的用户体验、加…...

[足式机器人]Part4 南科大高等机器人控制课 Ch00 课程简介
本文仅供学习使用 本文参考: B站:CLEAR_LAB 课程主讲教师: Prof. Wei Zhang 南科大高等机器人控制课 Ch00 课程简介 1. What is this course about?2. Tentative Schedule暂定时间表 1. What is this course about? Develop a solid found…...
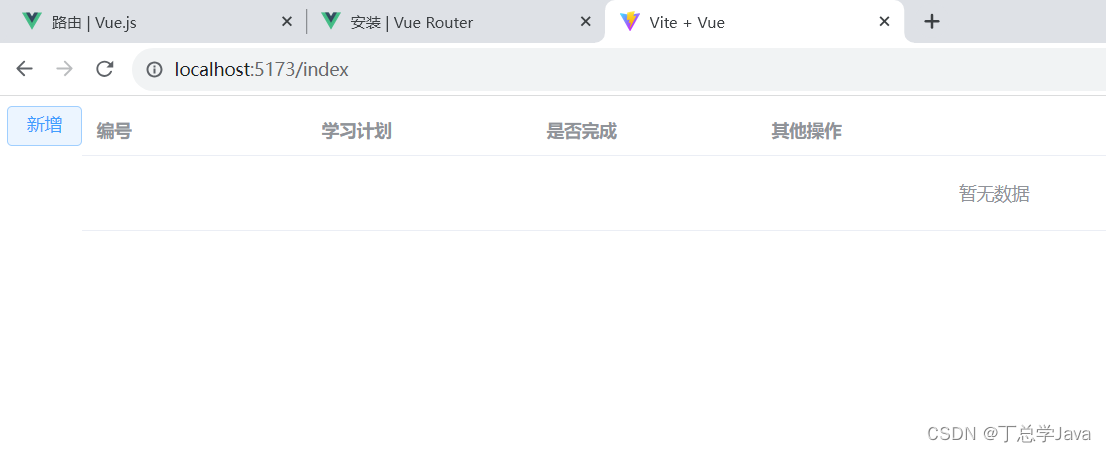
SSM项目实战-登录验证成功并路由到首页面,Vue3+Vite+Axios+Element-Plus技术
1、util/request.js import axios from "axios";let request axios.create({baseURL: "http://localhost:8080",timeout: 50000 });export default request 2、api/sysUser.js import request from "../util/request.js";export const login (…...

Python----网络爬虫
目录 1.Robots排除协议 2.request库的使用 3.beautifulsoup4库的使用 Python网络爬虫应用一般分为两部: (1)通过网络连接获取网页内容 (2)对获得的网页内容进行处理 - 这两个步骤分别使用不同的函数库:requests …...

如何高效处理RPG Maker加密资源:纯前端解密方案深度解析
如何高效处理RPG Maker加密资源:纯前端解密方案深度解析 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://gitco…...

systemverilog学习
1.数据类型 1.1logic类型和双状态数据类型 logic类型:在实际电路中,信号只有0和1两种状态,但是在电路设计中,能有四种状态,0、1、Z和X,X代表未知态,当给它两个驱动时(一边给0&#x…...

1.7.3 掌握Scala函数 - 神奇占位符
本次Scala函数实战主要聚焦于“神奇占位符”下划线(_)的灵活运用,通过三个递进的案例深入理解其简化代码的核心作用。 演示过滤列表:利用 filter 方法,对比了常规匿名函数与使用占位符的写法,直观展示了如何…...

量子计算中CV-DV混合门集原理与应用
1. 量子计算中的CV-DV门集基础在混合量子系统中,连续变量(CV)和离散变量(DV)门集的协同工作为量子算法设计提供了独特优势。CV系统通常由量子谐振荡器实现,其状态存在于无限维希尔伯特空间中,而DV系统则以量子比特为基本单元。这两类系统的结…...

AI增强自动化工作流:从规则驱动到意图驱动的智能决策实践
1. 项目概述:当AI遇见自动化工作流最近在GitHub上看到一个挺有意思的项目,叫“NitroRCr/AIaW”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现它其实是一个将人工智能(AI)与自动化工…...
)
面试记录 (2026/5/12)
问题一:java并发包下的AQS,了解多少? 这个真是没看过源码,就不班门弄斧了 直接学习下 大佬的经验 https://blog.csdn.net/qq_45772447/article/details/149126295?fromshareblogdetail&sharetypeblogdetail&sharerId149126295&…...

Deep Lake:面向AI的统一数据湖仓,重塑深度学习数据管理
1. 从数据湖到AI数据库:为什么我们需要Deep Lake?如果你在搞AI项目,尤其是涉及大语言模型(LLM)或者计算机视觉,数据管理这块儿大概率让你头疼过。我自己的经验是,项目初期,数据量小&…...

Redis_7_Streams与高可用集群实战
Redis 7.0 Streams与高可用集群部署实战 从消息队列到分布式架构,全面掌握Redis核心能力 前言 Redis不只是一个缓存数据库。Redis 5.0引入的Streams让它具备了消息队列的能力,Redis 7.0进一步增强了Streams的稳定性和性能。很多团队在用Kafka/RabbitMQ处理消息队列时,其实R…...

Python ORM实战:SQLAlchemy深度解析
Python ORM实战:SQLAlchemy深度解析 引言 在Python后端开发中,ORM(对象关系映射)是连接应用程序和数据库的重要桥梁。作为一名从Rust转向Python的后端开发者,我深刻体会到SQLAlchemy在处理数据库操作方面的强大能力。S…...

基于LLM的智能体驱动文字冒险游戏引擎设计与实现
1. 项目概述:一个AI驱动的文字冒险游戏引擎最近在GitHub上闲逛,发现了一个挺有意思的项目,叫droxey/agentadventure。光看名字,大概能猜到它和“智能体”(Agent)以及“冒险”(Adventure…...