机器学习深度学学习分类模型中常用的评价指标总结记录与代码实现说明
在机器学习深度学习算法模型大开发过程中,免不了要对算法模型进行对应的评测分析,这里主要是总结记录分类任务中经常使用到的一些评价指标,并针对性地给出对应的代码实现,方便读者直接移植到自己的项目中。

【混淆矩阵】
混淆矩阵(Confusion Matrix)是评价分类模型性能的一种常用工具,它展示了模型的预测结果与真实标签之间的关系。混淆矩阵是一个二维矩阵,行表示真实标签,列表示模型的预测结果。
混淆矩阵的原理如下:
假设我们有一个二分类模型,类别分别为正例和负例。混淆矩阵的四个元素分别表示:
- 真正例(True Positive,TP):模型将正例正确地预测为正例的数量。
- 假正例(False Positive,FP):模型将负例错误地预测为正例的数量。
- 假负例(False Negative,FN):模型将正例错误地预测为负例的数量。
- 真负例(True Negative,TN):模型将负例正确地预测为负例的数量。
下面是一个示例混淆矩阵:
预测结果| 正例 | 负例 |
真实标签 正例 | TP | FN |负例 | FP | TN |混淆矩阵的优点:
- 提供了对分类模型性能的全面评估,可以直观地展示模型的预测结果和错误类型。
- 可以计算多种评价指标,如准确率、精确率、召回率等,从不同角度分析模型的性能。
混淆矩阵的缺点:
- 只适用于分类任务,对于回归任务无法直接使用。
- 当类别数量较多时,混淆矩阵会变得更加复杂,不易直观解读。
Demo代码实现如下所示:
import numpy as np
from sklearn.metrics import *# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果
predicted_labels = [0, 1, 0, 0, 1, 1, 0, 1, 1, 0]# 计算混淆矩阵
cm = confusion_matrix(true_labels, predicted_labels)
print("Confusion Matrix:")
print(cm)【准确率】
准确率(Accuracy)是评价分类模型性能的常用指标之一,它表示模型正确分类的样本数量与总样本数量之间的比例。
准确率的计算公式为:
准确率 = (TP + TN) / (TP + TN + FP + FN)
其中,TP表示真正例的数量,TN表示真负例的数量,FP表示假正例的数量,FN表示假负例的数量。
准确率的优点:
- 直观易懂:准确率可以直观地衡量模型的整体分类性能,它给出的是模型正确分类的比例。
- 平衡性:准确率考虑了模型对所有类别样本的分类情况,能够反映模型的整体性能。
准确率的缺点:
- 对样本不平衡敏感:当数据集中的样本分布不均衡时,准确率可能会给出误导性的结果。例如,在一个二分类问题中,如果负样本占大多数,模型只需预测为负样本即可获得很高的准确率,但对于正样本的分类效果可能很差。
- 忽略了错误类型:准确率无法区分模型的错误类型,无法告诉我们模型在预测中的具体偏差。
Demo代码实现如下所示:
from sklearn.metrics import accuracy_score# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果
predicted_labels = [0, 1, 0, 0, 1, 1, 0, 1, 1, 0]# 计算准确率
accuracy = accuracy_score(true_labels, predicted_labels)
print("Accuracy:", accuracy)【精确率】
精确率(Precision)是机器学习和深度学习分类模型常用的评价指标之一,它衡量的是模型在预测为正例的样本中真正为正例的比例。
精确率的计算公式为:
精确率 = TP / (TP + FP)
其中,TP表示真正例的数量,FP表示假正例的数量。
精确率的优点:
- 强调正例的准确性:精确率专注于模型将负例错误预测为正例的情况,它能够评估模型在预测为正例的样本中的准确性。
- 适用于正例重要的场景:在一些应用中,正例的预测结果更为重要,如罕见疾病的诊断。精确率可以帮助我们衡量模型在这些场景下的性能。
精确率的缺点:
- 忽略了假负例:精确率无法区分模型的假负例情况,即模型将正例错误地预测为负例的情况。在一些应用中,假负例的影响可能非常重要,如癌症的诊断。因此,仅仅使用精确率来评估模型可能会忽略这些重要的错误预测。
Demo代码实现如下所示:
from sklearn.metrics import precision_score# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果
predicted_labels = [0, 1, 0, 0, 1, 1, 0, 1, 1, 0]# 计算精确率
precision = precision_score(true_labels, predicted_labels)
print("Precision:", precision)【召回率】
召回率(Recall),也称为灵敏度(Sensitivity)或真正例率(True Positive Rate),是机器学习和深度学习分类模型常用的评价指标之一。它衡量的是模型在所有真实正例中能够正确预测为正例的比例。
召回率的计算公式为:
召回率 = TP / (TP + FN)
其中,TP表示真正例的数量,FN表示假负例的数量。
召回率的优点:
- 关注正例的识别能力:召回率可以评估模型对正例的识别能力,即模型能够正确找出多少个真实正例。
- 适用于假负例重要的场景:在一些应用中,假负例的影响较为重要,如癌症的诊断。召回率可以帮助我们衡量模型在这些场景下的性能。
召回率的缺点:
- 忽略了假正例:召回率无法区分模型的假正例情况,即模型将负例错误地预测为正例的情况。在一些应用中,假正例的影响可能非常重要,如垃圾邮件过滤。因此,仅仅使用召回率来评估模型可能会忽略这些重要的错误预测。
Demo代码实现如下所示:
from sklearn.metrics import recall_score# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果
predicted_labels = [0, 1, 0, 0, 1, 1, 0, 1, 1, 0]# 计算召回率
recall = recall_score(true_labels, predicted_labels)
print("Recall:", recall)【F1值】
F1值是机器学习和深度学习分类模型中常用的综合评价指标,它同时考虑了模型的精确率(Precision)和召回率(Recall)。F1值的计算公式为:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
其中,精确率和召回率的计算方式如下:
精确率 = TP / (TP + FP)
召回率 = TP / (TP + FN)
F1值的优点:
- 综合考虑了精确率和召回率:F1值综合了精确率和召回率,可以更全面地评估模型的分类性能。它能够同时衡量模型的正例识别能力和负例识别能力,对于不平衡数据集和分类任务来说是一个较好的评价指标。
- 适用于正负样本不平衡的场景:在一些分类任务中,正负样本的比例可能会存在较大的不平衡。F1值对于这类场景非常有用,因为它能够平衡考虑模型对正负样本的预测能力。
F1值的缺点:
- 对精确率和召回率平衡要求较高:F1值假设精确率和召回率具有相同的重要性,并且对两者的平衡要求较高。在某些应用场景下,精确率和召回率的重要性可能不同,因此仅仅使用F1值来评估模型的性能可能会忽略这种差异。
- 受数据分布影响较大:F1值的计算受到数据分布的影响,特别是在正负样本不平衡的情况下。当数据分布发生变化时,F1值的结果也会随之变化,因此在评估模型时需要谨慎考虑数据的分布情况。
Demo代码实现如下所示:
from sklearn.metrics import f1_score# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果
predicted_labels = [0, 1, 0, 0, 1, 1, 0, 1, 1, 0]# 计算F1值
f1 = f1_score(true_labels, predicted_labels)
print("F1 Score:", f1)【ROC曲线】
ROC曲线(Receiver Operating Characteristic curve)是机器学习和深度学习分类模型中常用的评价指标,用于衡量分类模型的性能。ROC曲线通过绘制真正例率(True Positive Rate,TPR)和假正例率(False Positive Rate,FPR)之间的关系图来评估模型的分类准确性。
TPR和FPR的计算方式如下:
- TPR = TP / (TP + FN)
- FPR = FP / (FP + TN)
其中,TP表示真正例(模型正确预测为正例的样本数),FN表示假负例(模型错误预测为负例的样本数),FP表示假正例(模型错误预测为正例的样本数),TN表示真负例(模型正确预测为负例的样本数)。
ROC曲线的绘制过程如下:
- 计算模型预测结果的置信度(概率或得分)。
- 选择不同的阈值将置信度映射为二分类的预测结果。
- 根据不同的阈值计算对应的TPR和FPR。
- 绘制TPR-FPR曲线,横轴为FPR,纵轴为TPR。
ROC曲线的优点:
- 不受分类阈值的影响:ROC曲线通过绘制TPR和FPR之间的关系图,不依赖于分类阈值的选择,能够全面地评估模型在不同阈值下的性能。
- 直观反映分类模型的性能:ROC曲线能够直观地展示模型在正负样本之间的权衡关系,帮助我们理解模型的分类能力。
ROC曲线的缺点:
- 无法直接比较模型的性能:ROC曲线可以用于比较同一模型在不同阈值下的性能,但不能直接比较不同模型之间的性能差异。为了比较不同模型的性能,需要使用其他指标,如曲线下面积(AUC)。
- 受样本分布影响较大:ROC曲线的计算受到样本分布的影响,特别是在正负样本不平衡的情况下。当数据分布发生变化时,ROC曲线的形状和结果也会随之变化,因此在评估模型时需要注意数据的分布情况。
Demo代码实现如下所示:
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score# 真实标签
true_labels = [0, 1, 1, 0, 1, 0, 0, 1, 1, 1]
# 模型预测结果的置信度(概率或得分)
predicted_scores = [0.2, 0.8, 0.6, 0.3, 0.7, 0.4, 0.1, 0.9, 0.7, 0.5]# 计算TPR和FPR
fpr, tpr, thresholds = roc_curve(true_labels, predicted_scores)# 计算AUC
auc = roc_auc_score(true_labels, predicted_scores)# 绘制ROC曲线
plt.plot(fpr, tpr, label=f'AUC = {auc:.2f}')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()【AUC值】
AUC(Area Under the Curve)是机器学习模型评价中常用的指标之一,用于评估二分类模型的性能。AUC值表示了分类模型在不同阈值下的预测能力,即正确地将正例排在负例前面的能力。AUC的取值范围在0到1之间,数值越接近1表示模型的性能越好,数值越接近0.5则表示模型的性能越差。
AUC的计算方法是通过绘制ROC曲线(Receiver Operating Characteristic curve)来得到的。ROC曲线以模型的真正例率(True Positive Rate,也称为召回率)作为纵轴,以模型的假正例率(False Positive Rate)作为横轴,将模型在不同阈值下的表现绘制成曲线。AUC值则表示ROC曲线下的面积大小。
AUC的优点包括:
- 对分类器的输出结果不敏感:AUC值只受到模型的排序能力影响,而不受到具体的分类阈值影响,因此对于不同的阈值选择不敏感。
- 适用于不平衡数据集:AUC在处理不平衡数据集时比准确率(Accuracy)等指标更加稳定,能够更好地评估模型的性能。
AUC的缺点包括:
- 无法直接解释模型的性能:AUC仅仅是对模型的排序能力进行评估,无法提供模型在实际任务中的准确性。
- 对于类别不平衡的数据集,AUC可能会高估模型的性能:当数据集中的正例和负例比例严重失衡时,AUC可能会给出不准确的评估结果。
Demo代码实现如下所示:
from sklearn.metrics import roc_auc_score# 假设y_true是真实的标签,y_pred是模型的预测概率
y_true = [0, 1, 0, 1]
y_pred = [0.2, 0.8, 0.3, 0.6]# 计算AUC值
auc = roc_auc_score(y_true, y_pred)
print("AUC:", auc)【KS( Kolmogorov-Smirnov)曲线】
KS(Kolmogorov-Smirnov)曲线是机器学习模型评价中常用的指标之一,用于评估二分类模型的性能。KS曲线基于累积分布函数(CDF)的比较,可以帮助我们确定最佳的分类阈值。
KS曲线的原理是通过比较正例和负例的累积分布函数来评估模型的分类能力。具体而言,KS曲线以模型的预测概率作为横轴,以累积正例比例和累积负例比例的差值(也称为KS统计量)作为纵轴,绘制出模型在不同阈值下的性能曲线。KS统计量表示了模型在不同概率阈值下正例和负例之间的最大差异。
KS曲线的优点包括:
- 直观易懂:KS曲线直观地展示了正例和负例之间的差异,可以帮助我们选择最佳的分类阈值。
- 对于不平衡数据集较为敏感:KS曲线能够更好地评估模型在不平衡数据集中的性能,因为它关注的是正例和负例之间的差异。
KS曲线的缺点包括:
- 无法直接解释模型的性能:KS曲线仅仅是对模型在不同阈值下的分类能力进行评估,无法提供模型在实际任务中的准确性。
- 对于类别不平衡的数据集,KS曲线可能会高估模型的性能:当数据集中的正例和负例比例严重失衡时,KS曲线可能会给出不准确的评估结果。
Demo代码实现如下所示:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve# 假设y_true是真实的标签,y_pred是模型的预测概率
y_true = np.array([0, 1, 0, 1])
y_pred = np.array([0.2, 0.8, 0.3, 0.6])# 计算正例和负例的累积分布函数
fpr, tpr, thresholds = roc_curve(y_true, y_pred)
ks = np.max(np.abs(tpr - fpr))# 绘制KS曲线
plt.plot(thresholds, tpr, label="TPR")
plt.plot(thresholds, fpr, label="FPR")
plt.xlabel("Threshold")
plt.ylabel("Rate")
plt.title("KS Curve (KS = {:.3f})".format(ks))
plt.legend()
plt.show()【PR曲线】
PR(Precision-Recall)曲线是机器学习分类模型中常用的性能评价指标之一,用于评估二分类模型的性能。PR曲线以召回率(Recall)为横轴,精确率(Precision)为纵轴,描述了在不同阈值下模型的性能变化。
PR曲线的原理是通过比较模型在不同阈值下的精确率和召回率来评估模型的性能。精确率定义为模型预测为正例的样本中真正为正例的比例,召回率定义为模型正确预测为正例的样本占所有真实正例样本的比例。通过改变分类阈值,可以得到一系列精确率和召回率的值,从而绘制PR曲线。
PR曲线的优点包括:
- 对于不平衡数据集较为敏感:PR曲线能够更好地评估模型在不平衡数据集中的性能,因为它关注的是正例样本的预测准确性和召回率。
- 直观易懂:PR曲线直观地展示了模型在不同阈值下的性能变化,可以帮助我们选择最佳的分类阈值。
PR曲线的缺点包括:
- 不适用于比较不同模型:PR曲线不能直接用于比较不同模型的性能,因为不同模型的基准线可能不同。在比较模型性能时,可以使用PR曲线下面积(AUC-PR)作为指标。
- 无法直接解释模型的准确性:PR曲线仅仅是对模型在不同阈值下的性能进行评估,无法提供模型在实际任务中的准确性。
Demo代码实现如下所示:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve# 假设y_true是真实的标签,y_pred是模型的预测概率
y_true = np.array([0, 1, 0, 1])
y_pred = np.array([0.2, 0.8, 0.3, 0.6])# 计算精确率和召回率
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)# 绘制PR曲线
plt.plot(recall, precision)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("PR Curve")
plt.show()【Lift值】
Lift值是机器学习和数据挖掘领域中常用的评价指标之一,用于评估分类模型的性能。Lift值可以帮助我们了解模型在不同预测概率范围内的效果相比于随机选择的效果有多好。
Lift值的原理是通过比较模型预测结果与随机选择结果之间的差异来评估模型的性能。具体而言,Lift值是用模型的预测结果中正例比例与随机选择结果中正例比例的比值表示。这个比值可以告诉我们模型在不同预测概率范围内相比于随机选择的效果有多好。
Lift值的优点包括:
- 直观易懂:Lift值可以直观地表示模型的性能相对于随机选择的提升程度。
- 可解释性:Lift值可以帮助我们了解模型在不同预测概率范围内的效果,对于业务场景的解释具有一定的帮助。
Lift值的缺点包括:
- 无法直接解释模型的准确性:Lift值仅仅是对模型相对于随机选择的效果进行评估,无法提供模型在实际任务中的准确性。
- 受数据分布影响较大:Lift值对数据分布敏感,当数据分布发生变化时,Lift值的解释可能会有所变化。
Demo代码实现如下所示:
import numpy as np# 假设y_true是真实的标签,y_pred是模型的预测概率
y_true = np.array([0, 1, 0, 1])
y_pred = np.array([0.2, 0.8, 0.3, 0.6])# 将预测概率按从大到小排序
sorted_indices = np.argsort(y_pred)[::-1]
sorted_y_true = y_true[sorted_indices]# 计算正例比例和随机选择结果中的正例比例
positive_ratio = np.cumsum(sorted_y_true) / np.sum(sorted_y_true)
random_positive_ratio = np.arange(1, len(y_true) + 1) / len(y_true)# 计算Lift值
lift = positive_ratio / random_positive_ratioprint("Lift values:", lift)【Kappa系数】
Kappa系数(Kappa coefficient)是一种用于评估分类模型性能的指标,常用于衡量分类器的准确性与判断的一致性。Kappa系数考虑了分类器的准确性与随机选择之间的差异,可以帮助我们判断模型的性能是否超过了随机选择的水平。
Kappa系数的原理是通过比较分类器的预测结果与真实标签之间的一致性来评估模型的性能。Kappa系数的取值范围为[-1, 1],其中1表示完全一致,0表示与随机选择一样,-1表示完全不一致。Kappa系数的计算考虑了分类器的预测结果与真实标签之间的一致性,同时考虑了随机选择的效果。
Kappa系数的优点包括:
- 考虑了随机选择的效果:Kappa系数通过与随机选择进行比较,可以帮助我们判断模型的性能是否优于随机选择的水平。
- 对不平衡数据集较为鲁棒:Kappa系数相对于准确率等指标对不平衡数据集更为鲁棒,因为它考虑了分类器的预测结果与真实标签之间的一致性。
Kappa系数的缺点包括:
- 无法解释模型的准确性:Kappa系数仅仅是对分类器的一致性进行评估,无法提供模型在实际任务中的准确性。
- 受类别不平衡的影响:Kappa系数对类别不平衡较为敏感,当类别不平衡较为严重时,Kappa系数的解释可能会受到影响。
Demo代码实现如下所示:
from sklearn.metrics import cohen_kappa_score# 假设y_true是真实的标签,y_pred是模型的预测结果
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 1]# 计算Kappa系数
kappa = cohen_kappa_score(y_true, y_pred)print("Kappa coefficient:", kappa)【宏平均、维平均】
宏平均(Macro-average)和微平均(Micro-average)是常用的评价分类模型性能的指标,用于计算多类别分类模型的准确率、召回率和F1值等指标。
宏平均的原理是先计算每个类别的准确率、召回率和F1值,然后对所有类别的指标进行平均。宏平均对每个类别都赋予了相同的权重,无论类别的样本数量多少,都被视为同等重要。宏平均适用于各个类别的重要性相同的情况。
宏平均的优点包括:
- 公平性:宏平均对每个类别都赋予了相同的权重,能够平等对待各个类别,适用于各个类别的重要性相同的情况。
- 直观易懂:宏平均计算简单,对于理解模型在不同类别上的性能有一定帮助。
宏平均的缺点包括:
- 不考虑类别的样本数量:宏平均不考虑类别的样本数量差异,对于样本数量不平衡的情况,可能无法准确反映模型的性能。
- 对小类别影响较大:宏平均对每个类别都赋予相同的权重,对于小类别的性能表现可能会被大类别的性能表现所主导。
微平均的原理是将所有类别的预测结果合并后计算准确率、召回率和F1值。微平均将所有类别的样本都视为一个整体,对每个样本赋予相同的权重。微平均适用于样本数量不平衡的情况。
微平均的优点包括:
- 考虑样本数量差异:微平均将所有类别的样本视为一个整体,能够考虑样本数量的差异,适用于样本数量不平衡的情况。
- 对大类别影响较大:微平均对每个样本都赋予相同的权重,对于大类别的性能表现可能会对整体性能有较大影响。
微平均的缺点包括:
- 不公平性:微平均将所有类别的样本都视为一个整体,对每个样本赋予相同的权重,可能不公平对待样本数量较少的类别。
- 可能无法准确反映各个类别的性能:由于将所有类别的样本合并计算指标,微平均可能无法准确反映各个类别的性能。
Demo代码实现如下所示:
from sklearn.metrics import precision_score, recall_score, f1_score# 假设y_true是真实的标签,y_pred是模型的预测结果
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 1]# 计算宏平均
macro_precision = precision_score(y_true, y_pred, average='macro')
macro_recall = recall_score(y_true, y_pred, average='macro')
macro_f1 = f1_score(y_true, y_pred, average='macro')# 计算微平均
micro_precision = precision_score(y_true, y_pred, average='micro')
micro_recall = recall_score(y_true, y_pred, average='micro')
micro_f1 = f1_score(y_true, y_pred, average='micro')print("Macro Precision:", macro_precision)
print("Macro Recall:", macro_recall)
print("Macro F1:", macro_f1)
print("Micro Precision:", micro_precision)
print("Micro Recall:", micro_recall)
print("MicroF1:", micro_f1)如果还有其他相关的指标欢迎评论区留言补充,我一并补充进来。
相关文章:
机器学习深度学学习分类模型中常用的评价指标总结记录与代码实现说明
在机器学习深度学习算法模型大开发过程中,免不了要对算法模型进行对应的评测分析,这里主要是总结记录分类任务中经常使用到的一些评价指标,并针对性地给出对应的代码实现,方便读者直接移植到自己的项目中。 【混淆矩阵】 混淆矩阵…...

fastapi 后端项目目录结构 mysql fastapi 数据库操作
原文:fastapi 后端项目目录结构 mysql fastapi 数据库操作_mob6454cc786d85的技术博客_51CTO博客 一、安装sqlalchemy、pymysql模块 pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pymysql -i https://pypi.tuna.tsinghua.edu.…...

研习代码 day47 | 动态规划——子序列问题3
一、判断子序列 1.1 题目 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde&…...

L1-017:到底有多二
题目描述 一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是…...
)
Python多线程使用(二)
使用多个线程的时候容易遇到一个场景:多个线程处理一份数据 使用多线程的时候同时处理一份数据,在threading中提供了一个方法:线程锁 Demo:下订单 现在有多笔订单下单,库存减少 from threading import Thread from t…...

记录一次docker搭建tomcat容器的网页不能访问的问题
tomcat Tomcat是Apache软件基金会的Jakarta项目中的一个重要子项目,是一个Web服务器,也是Java应用服务器,是开源免费的软件。它是一个兼容Java Servlet和JavaServer Pages(JSP)的Web服务器,可以作为独立的W…...

GPT3年终总结
User You 程序员年度绩效总结 ChatGPT ChatGPT 程序员年度绩效总结通常包括以下几个方面: 目标达成情况: 回顾年初设定的目标,评估在项目完成、技能提升等方面的达成情况。 工作贡献: 强调在项目中的个人贡献,包括…...

Kafka生产者发送消息的流程
Kafka 生产者发送消息的流程涉及多个步骤,从消息的创建到成功存储在 Kafka 集群中。以下是 Kafka 生产者发送消息的主要步骤: 1. 创建消息 生产者首先创建一个消息,消息通常包含一个键(可选)和一个值,以及…...
基于SSM的数学竞赛网站设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

01-使用Git操作本地库,如初始化本地库,提交工作区文件到暂存区和本地库,查看版本信息,版本切换命令等
Git的使用 概述 Git是一个分布式版本控制工具, 通常用来管理项目中的源代码文件(Java类、xml文件、html页面等)进行管理,在软件开发过程中被广泛使用 Git可以记录文件修改的历史记录并形成备份从而实现代码回溯, 版本切换, 多人协作, 远程备份的功能Git具有廉价的本地库,方便…...
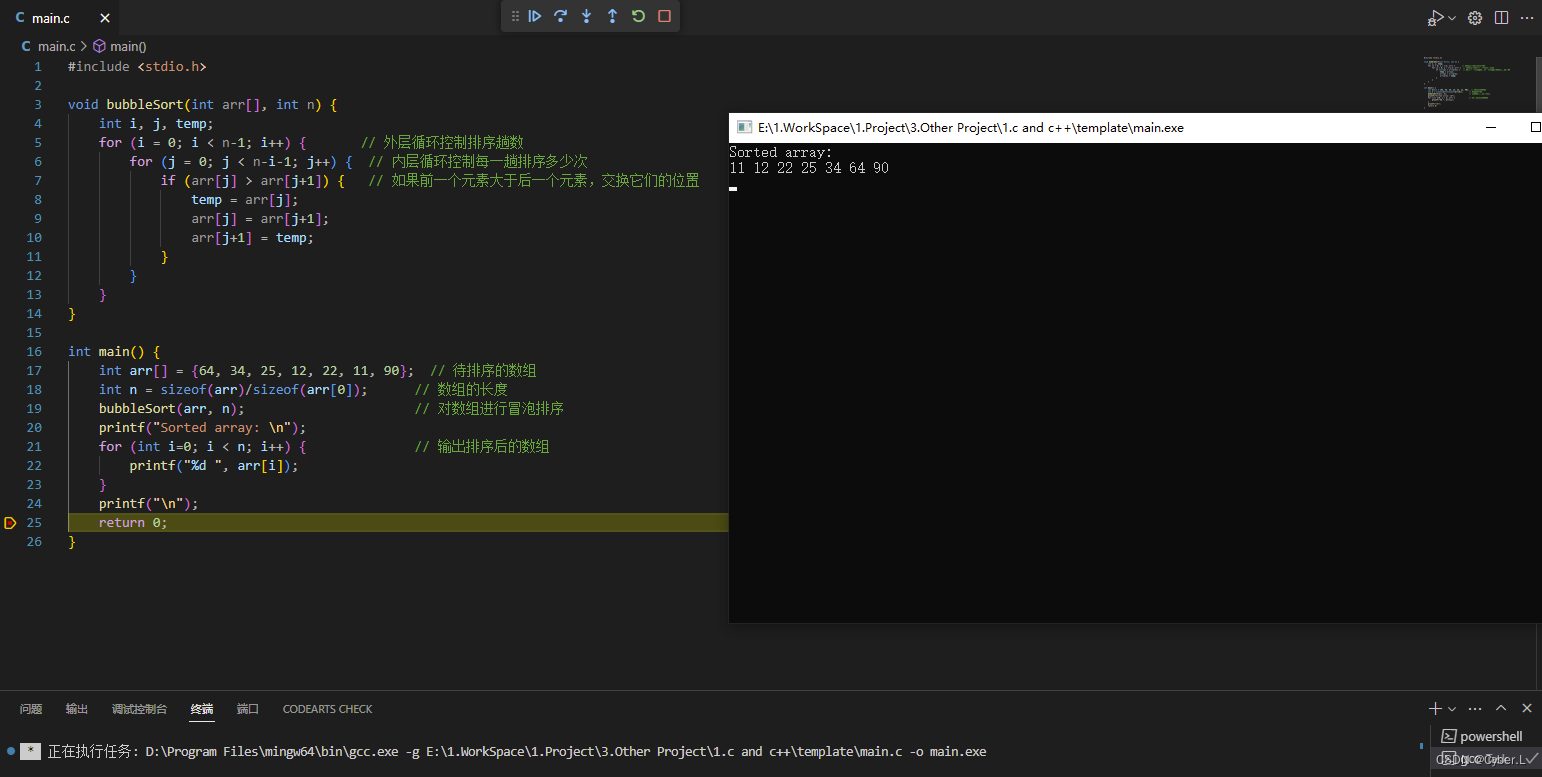
排序算法介绍(二)冒泡排序
0. 简介 冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排…...

搜索引擎高级用法总结: 谷歌、百度、必应
搜索引擎高级用法总结: 谷歌、百度、必应 google search 基本搜索 逻辑与:and逻辑或: or逻辑非: -完整匹配:“关键词”通配符:* ?高级搜索 intext:后台登录 将只返回正文中包含 后台登录 的网页 intitle intitle:后台登录 将只返回标题中包含 后台登录 的网页,intitle…...

com.intellij.openapi.application.ApplicationListener使用
一般监听期通过如下代码生效 <applicationListeners> <!-- <listener class"com.itheima.taunt.MyApplicationListener"--> <!-- topic"com.intellij.openapi.application.ApplicationListener"…...

常见js hook脚本
一.js hook 过无限debugger var _constructor constructor; Function.prototype.constructor function(s) {if (s "debugger") {console.log(s);return null;}return _constructor(s); }//去除无限debugger Function.prototype.__constructor_back Function.pro…...

Java——SpringLayout弹簧布局
import java.awt.*;import javax.swing.*;public class a {public static void main(String[] args) {new a();}public a() {JFrame JF new JFrame("弹簧布局");// 创建JFrame窗口//设置JPanel的布局管理器为SpringLayoutJPanel JP new JPanel(new SpringLayout())…...
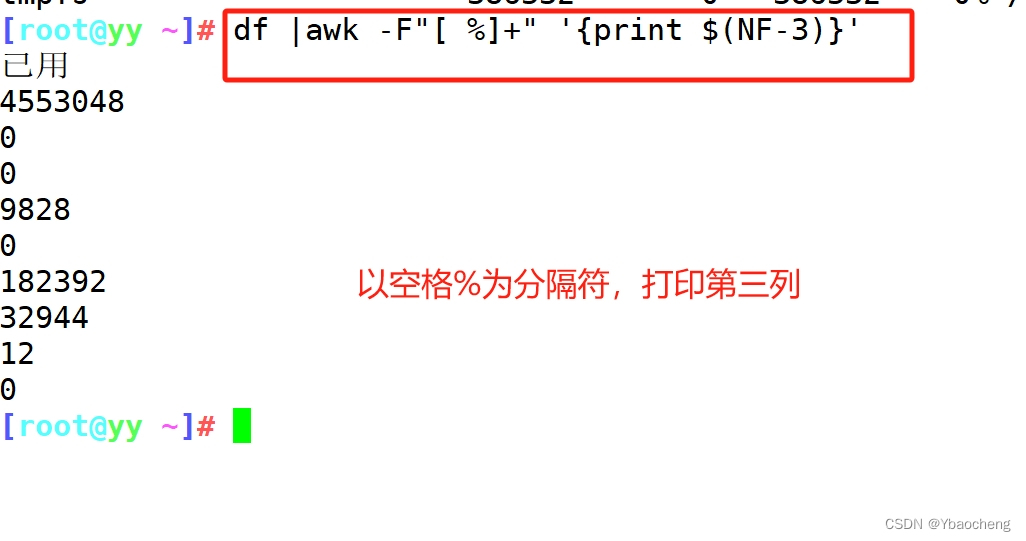
正则表达式及文本三剑客grep sed awk
目录 正则表达式 1.元字符 2.表示次数 3.位置锚定 4.分组或其他 grep sed 语法: 常用选项 脚本格式 例: 查找11点56到12点10的日志 修改文件,找到文件并给其后缀加上er 提取IP地址 提取版本号 提取文件权限 awk 工作原理&…...

python爬虫之创建属于自己的ip代理池
在后续需求数据量比较大的情况下,自建一个ip代理池可以帮助我们获得更多的数据。 下面我来介绍一下整个过程 1.找到目标代理网站 https://www.dailiservers.com/go/webshare https://proxyscrape.com/ https://spys.one/ https://free-proxy-list.net/ http://fr…...

又添三位“信伙伴”,亚信安慧AntDB数据库与南京一鸣、广东鸿数、北京数见完成兼容互认
近日,亚信安慧AntDB数据库与南京一鸣科技有限公司(简称:南京一鸣)学生工作管理与服务平台软件、广东鸿数科技有限公司(简称:广东鸿数)隐私数据保护系统V5.0、北京数见科技有限公司(简…...
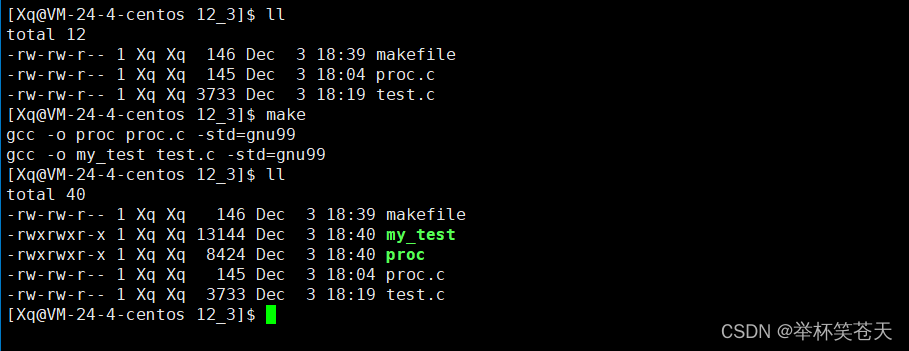
Linux --- 进程控制
目录 1. 进程创建 1.1. 内核数据结构的处理 1.2. 代码的处理 1.3. 数据的处理: 方案一:fork创建子进程的时候,直接对数据进行拷贝处理,让父子进程各自私有一份 方案二:写实拷贝(copy on write) 1.4. fork常规用…...

SVG-椭圆弧-参数转换-计算公式-标准解读
文章目录 1.简介2.基本参数2.1.椭圆的表达2.2.参数变换2.3.注意事项 3.参考资料4.总结 1.简介 为了与其他路径段表示法保持一致, SVG 路径中的圆弧是根据曲线上的起点和终点定义的。椭圆弧的这种端点参数化。优点是它允许与其它路径一致的语法,其中所有…...

VSCode毛玻璃效果实现:CSS backdrop-filter原理与性能调优指南
1. 项目概述:当代码编辑器遇上毛玻璃美学如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(以下简称VSCode)中度过的,那么你肯定不止一次地折腾过它的主题和外观。从默认的深色主题到各种炫酷的Material D…...

十年后,编程还会是人类的工作吗?
一个正在被重写的职业剧本站在2026年的中点眺望2036年,没有人能准确预言未来。但作为软件测试从业者,我们或许是离“编程工作是否会被取代”这个答案最近的一群人。因为我们每天的工作,就是审视代码的边界、挖掘逻辑的漏洞、评估系统的风险。…...

开源OmenSuperHub:解决惠普OMEN笔记本性能限制的完整技术方案
开源OmenSuperHub:解决惠普OMEN笔记本性能限制的完整技术方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 第一部分:技术挑战分…...

LangGraph 持久化深度解析:Checkpoint 机制如何实现对话记忆和断点续跑
很多同学在第一次接入 LangGraph 时,会发现图默认是「无状态」的——每次 invoke,上一轮的消息就消失了。你以为加了 MessagesState 就有记忆了,结果测试一问,Agent 完全不知道「你叫什么名字」。 更惨的是什么?生产环…...

Alph:一键统一配置AI编程助手MCP服务器的命令行工具
1. 项目概述:告别手动配置的混乱时代 如果你和我一样,日常开发中同时用着 Cursor、Claude Code、Gemini CLI 这些 AI 编程助手,那你一定对下面这个场景深恶痛绝:每次想给它们接入一个新的 MCP 服务器,都得像个考古学家…...

算法将驱动一切:边缘AI智能体如何重塑智能系统
仓库装卸区的安全摄像头每天采集86400秒的视频数据。长途卡车上的车队远程信息记录仪在两次加油之间积累了数GB的行车影像。外科手术机器人的立体摄像头以每秒60帧的速度生成密集点云。所有这些数据都产生于数字世界与现实世界的交界处,但几乎没有任何一条被用于智能…...

保边滤波深度学习红外可见光融合算法【附程序】
✨ 长期致力于红外与可见光图像融合、快速引导滤波器、交替引导滤波器、深度学习、卷积神经网络研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)双支流…...

Nodejs后端服务如何稳定调用Claude并避免封号风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs后端服务如何稳定调用Claude并避免封号风险 1. 后端集成Claude的常见挑战 在Node.js后端服务中集成Claude模型,…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...

谷歌seo付费外链是什么? 深度拆解5种主流的外链买卖方式
在目前的搜索环境下,想要让网站在没有外部引荐的情况下出现在搜索结果前排,难度不亚于在一座无人的深山里开店却希望客流量爆满。链接建设,或者说大家心照不宣的“外链买卖”,已经变成了提升排名的必经之路。一、 揭开付费外链的真…...