Locust单机多核压测,以及主从节点的数据通信处理!

一、背景
这还是2个月前做的一次接口性能测试,关于locust脚本的单机多核运行,以及主从节点之间的数据通信。
先简单交代下背景,在APP上线之前,需要对登录接口进行性能测试。经过评估,我还是优先选择了locust来进行脚本开发,本次用到了locust的单机多核运行能力,只不过这里还涉及到主从节点之间数据通信。现成的可参考的有效文档甚少,所以还是自己摸着官方文档过河比较靠谱。
顺带提一下,学习框架这种东西最好的教程其实还得是官方文档以及框架源码了,这里贴上locust官方文档链接,需要的可以自行学习:https://docs.locust.io/en/stable/what-is-locust.html
二、代码编写
其实脚本代码的编写一大重点就是如何处理测试数据,不同的测试需求对于测试数据的处理是不同的。比如这次的需求,手机号不能重复。另外考虑到长时间的负载压力,数据量还得足够。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036【暗号:csdn999】
最后测试数据还需要处理,那么我使用的测试号段是非真实号码段,测试结束后可以查询对应号段内的手机号,进行相关业务数据的清理。
1. 代码概览
还是老样子,先附上全部代码,然后对其结构进行拆分讲解。
import random
import time
from collections import dequefrom locust import HttpUser, task, run_single_user, TaskSet, events
from locust.runners import WorkerRunner, MasterRunnerCURRENT_TIMESTAMP = str(round(time.time() * 1000))
RANDOM = str(random.randint(10000000, 99999999))
MOBILE_HEADER = {"skip-request-expired": "true","skip-auth": "true","skip-sign": "true","os": "IOS","device-id": "198EA6A4677649018708B400F3DF69FB","nonce": RANDOM,"sign": "12333","version": "1.2.0","timestamp": CURRENT_TIMESTAMP,"Content-Type": "application/json"
}last_mobile = ""
worker_mobile_deque = deque()# 13300120000, 13300160000 新用户注册号段@events.test_start.add_listener
def on_test_start(environment, **_kwargs):if not isinstance(environment.runner, WorkerRunner):mobile_list = []for i in range(13300120000, 13300160000):mobile_list.append(i)mobile_list_length = len(mobile_list)print("列表已生成,总计数量:", mobile_list_length)worker_count = environment.runner.worker_countchunk_size = int(mobile_list_length / worker_count)print(f"平均每个worker分得的手机号数量:{chunk_size}")for i, worker in enumerate(environment.runner.clients):start_index = i * chunk_sizeif i + 1 < worker_count:end_index = start_index + chunk_sizeelse:end_index = len(mobile_list)data = mobile_list[start_index:end_index]environment.runner.send_message("mobile_list", data, worker)def setup_mobile_list(environment, msg, **kwargs):len_msg_data = len(msg.data)print(f"worker收到的master传来的数据号段:{msg.data[0]} ~ {msg.data[len_msg_data-1]}")global worker_mobile_dequeworker_mobile_deque = deque(msg.data)@events.init.add_listener
def on_locust_init(environment, **_kwargs):if not isinstance(environment.runner, MasterRunner):environment.runner.register_message('mobile_list', setup_mobile_list)class VcodeLoginUser(TaskSet):# wait_time = between(5, 5)@taskdef vcode_login(self):test_mobile = worker_mobile_deque.popleft()print("当前获取的手机号:", test_mobile)# print("当前队列大小:", len(worker_mobile_deque))global last_mobilelast_mobile = test_mobilewith self.client.post("/g/sendMobileVcode",headers=MOBILE_HEADER,json={"busiType": "login", "mobile": str(test_mobile)}) as send_response:try:send_response_json = send_response.json()if send_response_json["message"] == "success":params = {"mobile": str(test_mobile), "vcode": "111111"}# print(test_mobile, "登录请求参数:", params)with self.client.post("/g/vcodeLogin",json=params,headers=MOBILE_HEADER,catch_response=True) as login_response:# print(login_response.json)login_response_json = login_response.json()if login_response_json["message"] != "success":login_response.failure("message not equal success")elif login_response_json["code"] != 0:login_response.failure("code not equal 0")elif login_response_json["data"]["rId"] == "":login_response.failure("rid is null")elif login_response_json["data"]["mobile"] != str(test_mobile):login_response.failure("mobile is error,入参手机号{},返回的手机号{}".format(test_mobile, login_response.json()["data"]["mobile"]))# print(test_mobile, "请求结果:", login_response.json())else:send_response.failure("{} send code fail".format(test_mobile))except Exception as e:send_response.failure("send code fail {}".format(e))@events.test_stop.add_listenerdef on_test_stop(environment, **kwargs):print("脚本结束")print("当前队列大小:", len(worker_mobile_deque))print("最后的手机号:", last_mobile)class LocustLogin(HttpUser):tasks = [VcodeLoginUser]host = "https://qa.test.com"if __name__ == '__main__':run_single_user(LocustLogin)2. 代码拆解-要加必要的断言
首先是基于locust开发的http请求的脚本大结构是不变的,依旧是两大块:HttpUser、TaskSet,这里不再对其讲解了,大伙看下官方文档就明白了。
接下来就是类VcodeLoginUser,可以看到在这里面是定义了单个用户的详细动作。注意这里要加上必要的断言。否则仅靠框架的非200外的错误断言还是不够的。
比如我这里关注登录成功后的几个必要字段:code、rId、mobile,这些一定是要符合断言的才可以。
果不其然,压测过程中就发现了并发情况下会出现的问题:入参手机号是a,接口返回的手机号是b。并发量越大错误越多。如果我只断言code=0,那么这个问题就不容易发现了,虽然接口返回的code都是成功的,但是业务上已经存在错误了。
...with self.client.post("/g/sendMobileVcode",headers=MOBILE_HEADER,json={"busiType": "login", "mobile": str(test_mobile)}) as send_response:try:send_response_json = send_response.json()if send_response_json["message"] == "success":params = {"mobile": str(test_mobile), "vcode": "111111"}# print(test_mobile, "登录请求参数:", params)with self.client.post("/g/vcodeLogin",json=params,headers=MOBILE_HEADER,catch_response=True) as login_response:# print(login_response.json)login_response_json = login_response.json()if login_response_json["message"] != "success":login_response.failure("message not equal success")elif login_response_json["code"] != 0:login_response.failure("code not equal 0")elif login_response_json["data"]["rId"] == "":login_response.failure("rid is null")elif login_response_json["data"]["mobile"] != str(test_mobile):login_response.failure("mobile is error,入参手机号{},返回的手机号{}".format(test_mobile, login_response.json()["data"]["mobile"]))# print(test_mobile, "请求结果:", login_response.json())else:send_response.failure("{} send code fail".format(test_mobile))except Exception as e:send_response.failure("send code fail {}".format(e))
...
3. 代码拆解-单机多核处理
接下来就是重点了,如何在单台机器上用到多cpu。最开始的时候我忽略了这点,后来发现负载上不去,一打开资源监视器才发现只有1个cpu在满负载运行。
这里示意图仅供参考,我的win笔记本是12c的。

因为Locust是单进程的,不能充分利用多核CPU,于是需要我们压力机上开启一个master进程,然后再开启多个slave进程,组成一个单机分布式系统即可。
开启的方式也很简单:
# 开启 master
locust -f locustfile.py --master# 开启 slave
locust -f locustfile.py --slave
这里我们开启 slave 节点的时候可以开启对应多个命令行窗口,当时没截图,借用网上的图片示意一下:
开启后,你的web界面就可以实时看到当前启动的节点数了。

4. 代码拆解-处理主从节点数据通信
开启主从节点倒是很容易,测试数据就需要针对性进行处理了。
因为我的测试登录用的手机号不可以重复,所以要保证不同 slave 节点上同时运行的代码产生的手机号都不可以重复。
继续扒了下官方文档,发现可以通过增加事件监听器来实现我的需求。
这里我加了三个监听器分别来处理不同的事情:
@events.init.add_listener:在locust运行初始化的时候执行@events.test_start.add_listener: 在测试代码开始运行的时候执行@events.test_stop.add_listener: 在测试代码结束运行的时候执行
@events.test_start.add_listener 首先,在@events.test_start.add_listener里,我主要处理全量数据的生成,以及把这些手机号平均分配给生成的 slave 节点。
@events.test_start.add_listener
def on_test_start(environment, **_kwargs):if not isinstance(environment.runner, WorkerRunner):mobile_list = []for i in range(13300120000, 13300160000):mobile_list.append(i)mobile_list_length = len(mobile_list)print("列表已生成,总计数量:", mobile_list_length)worker_count = environment.runner.worker_countchunk_size = int(mobile_list_length / worker_count)print(f"平均每个worker分得的手机号数量:{chunk_size}")for i, worker in enumerate(environment.runner.clients):start_index = i * chunk_sizeif i + 1 < worker_count:end_index = start_index + chunk_sizeelse:end_index = len(mobile_list)data = mobile_list[start_index:end_index]environment.runner.send_message("mobile_list", data, worker)
注意这里最后一行中定义的mobile_list,需要定义一个对应函数来接收这个数据。
def setup_mobile_list(environment, msg, **kwargs):len_msg_data = len(msg.data)print(f"worker收到的master传来的数据号段:{msg.data[0]} ~ {msg.data[len_msg_data-1]}")global worker_mobile_dequeworker_mobile_deque = deque(msg.data)
这样,不同的 slave 节点脚步分配到的手机号段就是不同的了,解决测试数据重复的问题。
另外,我定义另一个全局变量worker_mobile_deque,这样不同的 slave 节点接收的数据就可以放到队列里,运行的时候从队列里面取,用一个少一个,直到队列里的数据用完。
@events.init.add_listener 接着就是在@events.init.add_listener里要注册上面定义的数据字段和处理函数。
@events.init.add_listener
def on_locust_init(environment, **_kwargs):if not isinstance(environment.runner, MasterRunner):environment.runner.register_message('mobile_list', setup_mobile_list)
@events.test_stop.add_listener 最后,在@events.test_stop.add_listener这里可以做一些后置处理,我是简单起见,只是记录输出了本次测试用到了哪个号码段,这样我下次运行脚本的时候可以从后面的数据开始,最大化测试数据的使用,不浪费。
@events.test_stop.add_listenerdef on_test_stop(environment, **kwargs):print("脚本结束")print("当前队列大小:", len(worker_mobile_deque))print("最后的手机号:", last_mobile)
三、小结
脚本调试完后可以稳定运行,接下来就是测试的过程了,进行了服务器单节点、多节点负载能力的测试,水平拓展能力的测试,以及服务动态扩容、长时间高负载测试。测试的角度观察测试报告,服务各项指标的情况。只不过涉及到开发端,调优分析的工作并未能参与很多。不过大概还是那些常见问题,后续有机会可以再单独分享了。
从使用角度来看,locust深得我爱,比起 jemter真的太轻便了,代码灵活度也非常高,单机负载能力也是响当当的,这点比jemeter强太多了。我这个项目不需要非常高的量,所以单机只用了8c就够了。如果有小伙伴需要非常高的并发,locust 也支持多机器分布式,进一步扩大并发能力。
END今天的分享就到此结束了!点赞关注不迷路~
相关文章:
Locust单机多核压测,以及主从节点的数据通信处理!
一、背景 这还是2个月前做的一次接口性能测试,关于locust脚本的单机多核运行,以及主从节点之间的数据通信。 先简单交代下背景,在APP上线之前,需要对登录接口进行性能测试。经过评估,我还是优先选择了locust来进行脚…...

ERROR: [pool www] please specify user and group other than root
根据提供的日志信息,PHP-FPM 服务未能启动的原因是配置文件中的一个错误。错误消息明确指出了问题所在: [29-Nov-2023 14:28:26] ERROR: [pool www] please specify user and group other than root [29-Nov-2023 14:28:26] ERROR: FPM initialization …...

京东商品详情接口在电商行业中的重要性及实时数据获取实现
一、引言 随着电子商务的快速发展,商品信息的准确性和实时性对于电商行业的运营至关重要。京东作为中国最大的电商平台之一,其商品详情接口在电商行业中扮演着重要的角色。本文将深入探讨京东商品详情接口的重要性,并介绍如何通过API实现实时…...

WT2003H MP3语音芯片方案:强大、灵活且易于集成的音频解决方案
在当今的数字化时代,音频技术的普遍性已不容忽视。从简单的音乐播放,到复杂的语音交互,音频技术的身影无处不在。在这个背景下,WT2003H MP3语音芯片方案应运而生,它提供了一种强大、灵活且易于集成的音频解决方案。 1…...

机器学习深度学学习分类模型中常用的评价指标总结记录与代码实现说明
在机器学习深度学习算法模型大开发过程中,免不了要对算法模型进行对应的评测分析,这里主要是总结记录分类任务中经常使用到的一些评价指标,并针对性地给出对应的代码实现,方便读者直接移植到自己的项目中。 【混淆矩阵】 混淆矩阵…...

fastapi 后端项目目录结构 mysql fastapi 数据库操作
原文:fastapi 后端项目目录结构 mysql fastapi 数据库操作_mob6454cc786d85的技术博客_51CTO博客 一、安装sqlalchemy、pymysql模块 pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pymysql -i https://pypi.tuna.tsinghua.edu.…...

研习代码 day47 | 动态规划——子序列问题3
一、判断子序列 1.1 题目 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde&…...

L1-017:到底有多二
题目描述 一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是…...
)
Python多线程使用(二)
使用多个线程的时候容易遇到一个场景:多个线程处理一份数据 使用多线程的时候同时处理一份数据,在threading中提供了一个方法:线程锁 Demo:下订单 现在有多笔订单下单,库存减少 from threading import Thread from t…...

记录一次docker搭建tomcat容器的网页不能访问的问题
tomcat Tomcat是Apache软件基金会的Jakarta项目中的一个重要子项目,是一个Web服务器,也是Java应用服务器,是开源免费的软件。它是一个兼容Java Servlet和JavaServer Pages(JSP)的Web服务器,可以作为独立的W…...

GPT3年终总结
User You 程序员年度绩效总结 ChatGPT ChatGPT 程序员年度绩效总结通常包括以下几个方面: 目标达成情况: 回顾年初设定的目标,评估在项目完成、技能提升等方面的达成情况。 工作贡献: 强调在项目中的个人贡献,包括…...

Kafka生产者发送消息的流程
Kafka 生产者发送消息的流程涉及多个步骤,从消息的创建到成功存储在 Kafka 集群中。以下是 Kafka 生产者发送消息的主要步骤: 1. 创建消息 生产者首先创建一个消息,消息通常包含一个键(可选)和一个值,以及…...
基于SSM的数学竞赛网站设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

01-使用Git操作本地库,如初始化本地库,提交工作区文件到暂存区和本地库,查看版本信息,版本切换命令等
Git的使用 概述 Git是一个分布式版本控制工具, 通常用来管理项目中的源代码文件(Java类、xml文件、html页面等)进行管理,在软件开发过程中被广泛使用 Git可以记录文件修改的历史记录并形成备份从而实现代码回溯, 版本切换, 多人协作, 远程备份的功能Git具有廉价的本地库,方便…...
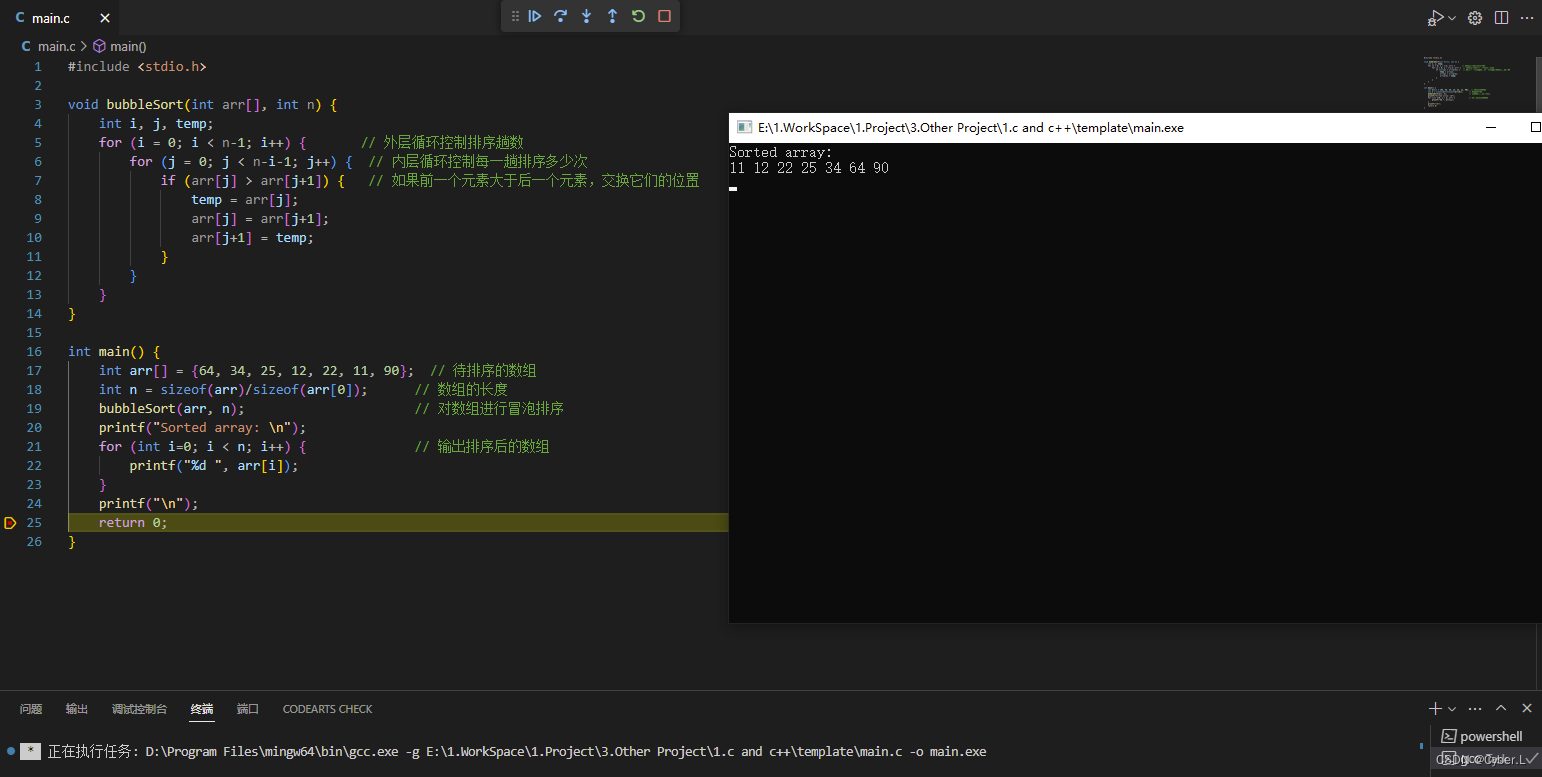
排序算法介绍(二)冒泡排序
0. 简介 冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排…...

搜索引擎高级用法总结: 谷歌、百度、必应
搜索引擎高级用法总结: 谷歌、百度、必应 google search 基本搜索 逻辑与:and逻辑或: or逻辑非: -完整匹配:“关键词”通配符:* ?高级搜索 intext:后台登录 将只返回正文中包含 后台登录 的网页 intitle intitle:后台登录 将只返回标题中包含 后台登录 的网页,intitle…...

com.intellij.openapi.application.ApplicationListener使用
一般监听期通过如下代码生效 <applicationListeners> <!-- <listener class"com.itheima.taunt.MyApplicationListener"--> <!-- topic"com.intellij.openapi.application.ApplicationListener"…...

常见js hook脚本
一.js hook 过无限debugger var _constructor constructor; Function.prototype.constructor function(s) {if (s "debugger") {console.log(s);return null;}return _constructor(s); }//去除无限debugger Function.prototype.__constructor_back Function.pro…...

Java——SpringLayout弹簧布局
import java.awt.*;import javax.swing.*;public class a {public static void main(String[] args) {new a();}public a() {JFrame JF new JFrame("弹簧布局");// 创建JFrame窗口//设置JPanel的布局管理器为SpringLayoutJPanel JP new JPanel(new SpringLayout())…...
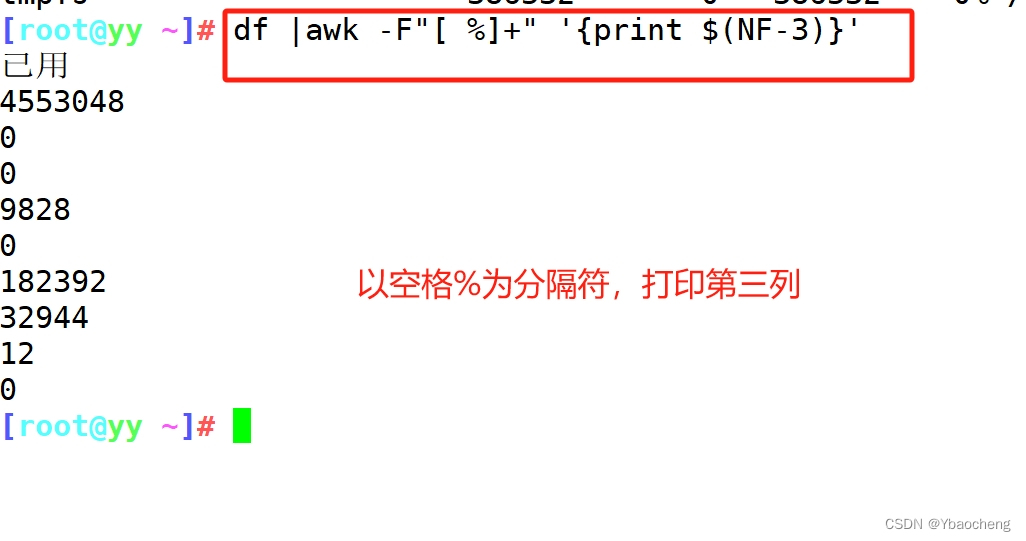
正则表达式及文本三剑客grep sed awk
目录 正则表达式 1.元字符 2.表示次数 3.位置锚定 4.分组或其他 grep sed 语法: 常用选项 脚本格式 例: 查找11点56到12点10的日志 修改文件,找到文件并给其后缀加上er 提取IP地址 提取版本号 提取文件权限 awk 工作原理&…...

D26: 向下负责——保护团队免受 AI 焦虑影响
文章目录 D26: 向下负责——保护团队免受 AI 焦虑影响 🎯 为什么这个话题重要? 现实痛点:团队 AI 焦虑的三种表现 一个真实场景 一、理解 AI 焦虑的本质 1.1 焦虑从何而来? 1.2 焦虑的恶性循环 1.3 一个心理学视角 二、建立团队心理安全网 2.1 心理安全:团队韧性的基石 2…...

黄仁勋CMU演讲:取代你的是会AI的人,所有人同一起跑线,奔跑吧
老黄又当博士了。这是他的第7个荣誉博士学位,而且英特尔CEO陈立武亲自为其授袍。卡内基梅隆大学(CMU)最新一届毕业典礼上,黄仁勋向5800多名毕业生发表演讲。面对AI浪潮的冲击,所有人都在焦虑、都在担心会不会被AI取代&…...

保姆级教程:用Intel官方工具搞定Realsense D435深度不准和黑点问题
深度视觉优化实战:Intel RealSense D435深度校准全流程解析 刚拆封的RealSense D435摄像头在深度模式下出现零星黑点?深度图某些区域数值明显失真?这些问题往往不是硬件缺陷,而是出厂校准参数与实际使用环境不匹配导致的。作为计算…...

B站命令行工具bilibili-cli:极客的终端视频浏览与自动化方案
1. 项目概述:在终端里逛B站,是一种什么体验? 如果你和我一样,是个重度命令行爱好者,或者单纯觉得在浏览器里点来点去效率太低,那么今天聊的这个工具可能会让你眼前一亮。 bilibili-cli ,顾名思…...

开源物联网平台SiteWhere:微服务架构下的设备管理与数据流实战
1. 项目概述:一个开源的物联网应用平台如果你正在寻找一个能帮你快速搭建、管理和扩展物联网应用的核心平台,而不是从零开始造轮子,那么SiteWhere这个开源项目绝对值得你花时间深入了解。它不是一个简单的设备连接网关,而是一个功…...

马斯克诉奥尔特曼案第三周:微软与 OpenAI 举证反击,争议焦点浮出水面
【案件进展概述】智东西 5 月 12 日消息,今天,马斯克诉奥尔特曼案进入第三周,被告方关键证人相继出庭,微软 CEO 萨提亚纳德拉 (Satya Nadella)、OpenAI 联合创始人兼前首席科学家 伊利亚苏茨克维 ÿ…...

掌握AI专著撰写技巧,借助工具3天完成20万字专著创作!
学术专著的生命力在于逻辑的严谨性,而逻辑论证正是写作中最容易出现问题的地方。专著的撰写必须围绕核心观点展开系统的论证,既需要对每一个论点进行详细的阐述,还要面对不同学派的争议观点,同时保证理论框架的自洽,避…...

告别爬虫:使用trendsmcp API稳定获取多平台趋势数据
1. 项目概述:告别爬虫,拥抱稳定的趋势数据API如果你曾经尝试过用Python抓取Google Trends、新闻提及量或者社交媒体趋势数据,那你一定对“429 Too Many Requests”这个错误代码深恶痛绝。半夜两点,数据管道突然中断,你…...

3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南
3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS用户设计的开源桌面歌词显示…...

5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南
5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 你…...