【深度学习】KMeans中自动K值的确认方法
1 前言
聚类常用于数据探索或挖掘前期,在没有做先验经验的背景下做的探索性分析,也适用于样本量较大情况下的数据预处理等方面工作。例如针对企业整体用户特征,在未得到相关知识或经验之前先根据数据本身特点进行用户分群,然后再针对不同群体做进一步分析;例如将连续数据做离散化,便于做后续分类分析应用。
KMeans是聚类方法中非常常用的方法,并且在正确确定K的情况下,KMeans对类别的划分跟分类算法的差异性非常小,这也意味着KMeans是一个准确率非常接近实际分类的算法。本文将讨论如下基于自动化的方法确立K值。
本案例是《Python数据分析与数据化运营》中“7.11案例-基于自动K值的KMeans广告效果聚类分析”的一部分,其ad_performance.txt和源代码chapter7_code2.py位于“附件-chapter7”中,该附件可以在可从http://www.dataivy.cn/book/python_book.zip或https://pan.baidu.com/s/1kUUBWNX下载。
2 实现思路
K值的确定一直是KMeans算法的关键,而由于KMeans是一个非监督式学习,因此没有所谓的“最佳”K值。但是,从数据本身的特征来讲,最佳K值对应的类别下应该是类内距离最小化并且类间距离最大化。有多个指标可以用来评估这种特征,比如平均轮廓系数、类内距离/类间距离等都可以做此类评估。基于这种思路,我们可以通过枚举法计每个K下的平均轮廓系数值,然后选出平均轮廓系数最大下的K值。
3 核心过程
假设我们已经拥有一份预处理过的数据集,其中的异常值、缺失值、数据标准化等前期工作都已经完成。下面是完成自动K值确定的核心流程:
- score_list = list() # 用来存储每个K下模型的平局轮廓系数
- silhouette_int = -1 # 初始化的平均轮廓系数阀值
- for n_clusters in range(2, 10): # 遍历从2到10几个有限组
- model_kmeans =KMeans(n_clusters=n_clusters, random_state=0) # 建立聚类模型对象
- cluster_labels_tmp =model_kmeans.fit_predict(X) # 训练聚类模型
- silhouette_tmp =metrics.silhouette_score(X, cluster_labels_tmp) # 得到每个K下的平均轮廓系数
- if silhouette_tmp >silhouette_int: # 如果平均轮廓系数更高
- best_k =n_clusters # 将最好的K存储下来
- silhouette_int =silhouette_tmp # 将最好的平均轮廓得分存储下来
- best_kmeans =model_kmeans # 将最好的模型存储下来
- cluster_labels_k =cluster_labels_tmp # 将最好的聚类标签存储下来
- score_list.append([n_clusters, silhouette_tmp]) # 将每次K及其得分追加到列表
- print ('{:^60}'.format(‘K value and silhouette summary:’))
- print (np.array(score_list)) # 打印输出所有K下的详细得分
- print (‘Best K is:{0} with average silhouette of{1}’.format(best_k, silhouette_int.round(4)))
该步骤的主要实现过程如下:
定义初始变量score_list和silhouette_int。score_list用来存储每个K下模型的平局轮廓系数,方便在最终打印输出详细计算结果;silhouette_int的初始值设置为-1,每个K下计算得到的平均轮廓系数如果比该值大,则将其值赋值给silhouette_int。
提示:对于平均轮廓系数而言,其值域分布式[-1,1]。因此silhouette_int的初始值可以设置为-1或比-1更小的值。
使用for循环遍历每个K值,这里的K的范围确定为从2-10.一般而言,用于聚类分析的K值的确定不会太大。如果值太大,那么聚类效果可能不明显,因为大量信息的都会被分散到各个小类之中,会导致数据的碎片化。
通过KMeans(n_clusters=n_clusters, random_state=0)建立KMeans模型对象model_kmeans,设置聚类数为循环中得到的K值,设置固定的初始状态。
对model_kmeans使用fit_predict得到其训练集的聚类标签。该步骤其实无需通过predict获得标签,可以先使用fit方法对模型做训练,然后使用模型对象model_kmeans的label_属性获得其训练集的标签分类。
使用metrics.silhouette_score方法对数据集做平均轮廓系数得分检验,将其得分赋值给silhouette_tmp,输入参数有两个:
- X:为原始输入的数组或矩阵
- cluster_labels:训练集对应的聚类标签
接下来做判断,如果计算后的得分大于初始化变量的得分,那么:
- 将最佳K值存储下来,便于后续输出展示
- 将最好的平均轮廓得分存储下来,便于跟其他后续得分做比较以及输出展示
- 将最好的模型存储下来,这样省去了后续再做最优模型下fit(训练)的工作
- 将最好的聚类标签存储下来,这样方便下面将原始训练集与最终标签合并
每次循环结束后,将当次循环的K值以及对应的评论轮廓得分使用append方法追加到列表。
最后打印输出每个K值下详细信息以及最后K值和最优评论轮廓得分,返回数据如下:
- K value and silhouette summary:
- [[ 2. 0.46692821]
- [ 3. 0.54904646]
- [ 4. 0.56968547]
- [ 5. 0.48186604]
- [ 6. 0.45477667]
- [ 7. 0.48204261]
- [ 8. 0.50447223]
- [ 9. 0.52697493]]
- Best K is:4 with average silhouette of 0.5697
上述结果显示了不同K下的平均轮廓得分。就经验看,如果平均轮廓得分值小于0,意味着聚类效果不佳;如果值大约0且小于0.5,那么说明聚类效果一般;如果值大于0.5,则说明聚类效果比较好。本案例在K=4时,得分为0.5697,说明效果较好。
对于上述得到的结果,将最优K值下得到的KMeans模型的结果,可以通过各类别的类内、外数据的对比以及配合雷达图或极坐标图做分析解释。
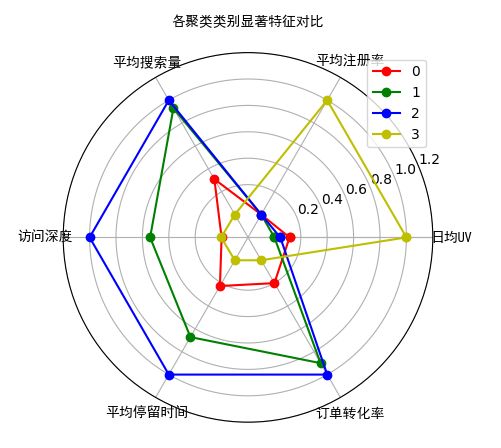
各聚类类别显著特征对比
4 引申思考
注意,即使在数据上聚类特征最明显,也并不意味着聚类结果就是有效的,因为这里的聚类结果用来分析使用,不同类别间需要具有明显的差异性特征并且类别间的样本量需要大体分布均衡。而确定最佳K值时却没有考虑到这些“业务性”因素。
案例中通过平均轮廓系数的方法得到的最佳K值不一定在业务上具有明显的解读和应用价值。如果最佳K值的解读无效怎么办?有两种思路:
- 扩大K值范围,例如将K的范围调整为[2,12],然后再次运算看更大范围内得到的K值是否更加有效并且能符合业务解读和应用需求。
- 得到平均轮廓系数“次要好”(而不是最好)的K值,再对其结果做分析。
对于不同类别的典型特征的对比,除了使用雷达图直观的显示外,还可以使用多个柱形图的形式,将每个类别对应特征的值做柱形图统计,这样也是一个非常直观的对比方法。具体参考下图:

相关文章:
【深度学习】KMeans中自动K值的确认方法
1 前言 聚类常用于数据探索或挖掘前期,在没有做先验经验的背景下做的探索性分析,也适用于样本量较大情况下的数据预处理等方面工作。例如针对企业整体用户特征,在未得到相关知识或经验之前先根据数据本身特点进行用户分群,然后再…...

github问题解决(持续更新中)
1、ssh: connect to host github.com port 22: Connection refused 从.ssh文件夹中新建文件名为config,内容为: Host github.com Hostname ssh.github.com Port 4432、解决 git 多用户提交切换问题 使用系统命令ssh创建rsa公私秘钥 C:\Users\fyp01&g…...
如何创建一个vue工程
1.打开vue安装网址:安装 | Vue CLI (vuejs.org) 2.创建一个项目文件夹 3.复制地址 4.打开cmd,进入这个地址 5.复制粘贴vue网页的安装命令 npm install -g vue/cli 6.创建vue工程 vue create vue这里可以通过上下键来进行选择。选最后一个选项按回车。 …...
50 代码审计-PHP无框架项目SQL注入挖掘技巧
目录 演示案例:简易SQL注入代码段分析挖掘思路QQ业务图标点亮系统挖掘-数据库监控追踪74CMS人才招聘系统挖掘-2次注入应用功能(自带转义)苹果CMS影视建站系统挖掘-数据库监控追踪(自带过滤) 技巧分析:总结: demo段指的是代码段,先…...

基于Spring、SpringMVC、MyBatis的企业博客网站
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring、SpringMVC、MyBatis的企业博…...
spring日志输出到elasticsearch
1.maven <!--日志elasticsearch--><dependency><groupId>com.agido</groupId><artifactId>logback-elasticsearch-appender</artifactId><version>3.0.8</version></dependency><dependency><groupId>net.l…...

谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通
本心、输入输出、结果 文章目录 谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通前言由谷歌 CEO 桑达尔・皮查伊做出决策从一开始,Gemini 的目标就是多模态、高效集成工具、API花有重开日,人无再少年实践是检验真理的唯一标准 谷歌…...

Ubuntu显卡及内核更新问题
显卡安装(2023.12.04) # 查看显卡型号 lspci | grep -i nvidia # 卸载原nvidia 显卡驱动 sudo apt-get --purge remove nvidia*# 禁用nouveau(nouveau是ubuntu自带显卡驱动) sudo gedit /etc/modprobe.d/blacklist.conf # 新增2行…...

SpringBoot错误处理机制解析
SpringBoot错误处理----源码解析 文章目录 1、默认机制2、使用ExceptionHandler标识一个方法,处理用Controller标注的该类发生的指定错误1).局部错误处理部分源码2).测试 3、 创建一个全局错误处理类集中处理错误,使用Controller…...
牛客剑指offer刷题模拟篇
文章目录 顺时针打印矩阵题目思路代码实现 扑克牌顺子题目思路代码实现 把字符串转换成整数题目思路代码实现 表示数值的字符串题目思路代码实现 顺时针打印矩阵 题目 描述 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如…...

Locust单机多核压测,以及主从节点的数据通信处理!
一、背景 这还是2个月前做的一次接口性能测试,关于locust脚本的单机多核运行,以及主从节点之间的数据通信。 先简单交代下背景,在APP上线之前,需要对登录接口进行性能测试。经过评估,我还是优先选择了locust来进行脚…...

ERROR: [pool www] please specify user and group other than root
根据提供的日志信息,PHP-FPM 服务未能启动的原因是配置文件中的一个错误。错误消息明确指出了问题所在: [29-Nov-2023 14:28:26] ERROR: [pool www] please specify user and group other than root [29-Nov-2023 14:28:26] ERROR: FPM initialization …...

京东商品详情接口在电商行业中的重要性及实时数据获取实现
一、引言 随着电子商务的快速发展,商品信息的准确性和实时性对于电商行业的运营至关重要。京东作为中国最大的电商平台之一,其商品详情接口在电商行业中扮演着重要的角色。本文将深入探讨京东商品详情接口的重要性,并介绍如何通过API实现实时…...

WT2003H MP3语音芯片方案:强大、灵活且易于集成的音频解决方案
在当今的数字化时代,音频技术的普遍性已不容忽视。从简单的音乐播放,到复杂的语音交互,音频技术的身影无处不在。在这个背景下,WT2003H MP3语音芯片方案应运而生,它提供了一种强大、灵活且易于集成的音频解决方案。 1…...

机器学习深度学学习分类模型中常用的评价指标总结记录与代码实现说明
在机器学习深度学习算法模型大开发过程中,免不了要对算法模型进行对应的评测分析,这里主要是总结记录分类任务中经常使用到的一些评价指标,并针对性地给出对应的代码实现,方便读者直接移植到自己的项目中。 【混淆矩阵】 混淆矩阵…...

fastapi 后端项目目录结构 mysql fastapi 数据库操作
原文:fastapi 后端项目目录结构 mysql fastapi 数据库操作_mob6454cc786d85的技术博客_51CTO博客 一、安装sqlalchemy、pymysql模块 pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple pip install pymysql -i https://pypi.tuna.tsinghua.edu.…...

研习代码 day47 | 动态规划——子序列问题3
一、判断子序列 1.1 题目 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde&…...

L1-017:到底有多二
题目描述 一个整数“犯二的程度”定义为该数字中包含2的个数与其位数的比值。如果这个数是负数,则程度增加0.5倍;如果还是个偶数,则再增加1倍。例如数字-13142223336是个11位数,其中有3个2,并且是负数,也是…...
)
Python多线程使用(二)
使用多个线程的时候容易遇到一个场景:多个线程处理一份数据 使用多线程的时候同时处理一份数据,在threading中提供了一个方法:线程锁 Demo:下订单 现在有多笔订单下单,库存减少 from threading import Thread from t…...

记录一次docker搭建tomcat容器的网页不能访问的问题
tomcat Tomcat是Apache软件基金会的Jakarta项目中的一个重要子项目,是一个Web服务器,也是Java应用服务器,是开源免费的软件。它是一个兼容Java Servlet和JavaServer Pages(JSP)的Web服务器,可以作为独立的W…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

树莓派+Kali Linux+PiTFT打造便携式安全测试平台全攻略
1. 项目概述如果你和我一样,对网络安全和嵌入式硬件都抱有浓厚的兴趣,那么将Kali Linux与树莓派结合,再配上一块小巧的触摸屏,绝对是一个能让你兴奋起来的项目。这不仅仅是把两个热门技术拼在一起,更是打造一个真正便携…...

AI绘图技能解析:用自然语言驱动Excalidraw自动生成图表
1. 项目概述:一个为Excalidraw注入AI灵魂的绘图技能如果你经常用Excalidraw画流程图、架构图或者白板草图,那你一定体会过那种“想法很丰满,画笔很骨感”的尴尬。脑子里明明有一个清晰的系统架构,但落到画布上,光是调整…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

μSR技术中的双量子Rabi振荡优化与应用
1. 实验背景与核心原理 在量子物理和凝聚态物理研究中,μ子自旋共振(μSR)技术是一种独特的探测手段。这项技术利用正μ子(μ)作为微观探针,通过观测其自旋极化行为来研究材料的局部磁环境。当μ子注入样品…...

Godot游戏引擎与强化学习结合:从零构建AI智能体的实战指南
1. 项目概述:当游戏开发遇上强化学习如果你是一名游戏开发者,或者对游戏AI的实现抱有浓厚兴趣,那么“edbeeching/godot_rl_agents”这个项目绝对值得你花时间深入研究。简单来说,这是一个将当下最热门的强化学习技术与免费、开源的…...

DIY智能电机推子:从闭环控制到MIDI交互的硬件实战
1. 项目概述与核心价值如果你玩过专业的音频混音台,或者在一些高端的灯光控制台上见过那种会自己“嗖”一下滑到指定位置的推子,那你一定对电机推子(Motorized Fader)不陌生。这东西的魅力在于,它既是精准的模拟输入设…...

数据分析师GitHub作品集构建指南:从项目架构到技术实现
1. 项目概述:一个数据分析师的作品集仓库意味着什么? 在数据驱动的时代,简历上的“精通Python/SQL”已经不够看了。面试官,尤其是那些懂行的技术面试官,更想看到的是你如何用这些工具解决真实世界的问题。这就是为什么…...

在济宁,随着设备搬运服务需求的持续增长,市面上涌现出众多设
在济宁,设备搬运服务需求不断增加,众多厂家纷纷涌现,选择一家口碑良好的设备搬运厂家成为不少人的关注焦点。本次测评旨在通过客观的评估,为对济宁设备搬运厂家感兴趣的人群提供有价值的参考。参与本次测评的厂家为山东荣上机械设…...