深度学习(五):pytorch迁移学习之resnet50
1.迁移学习
迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。
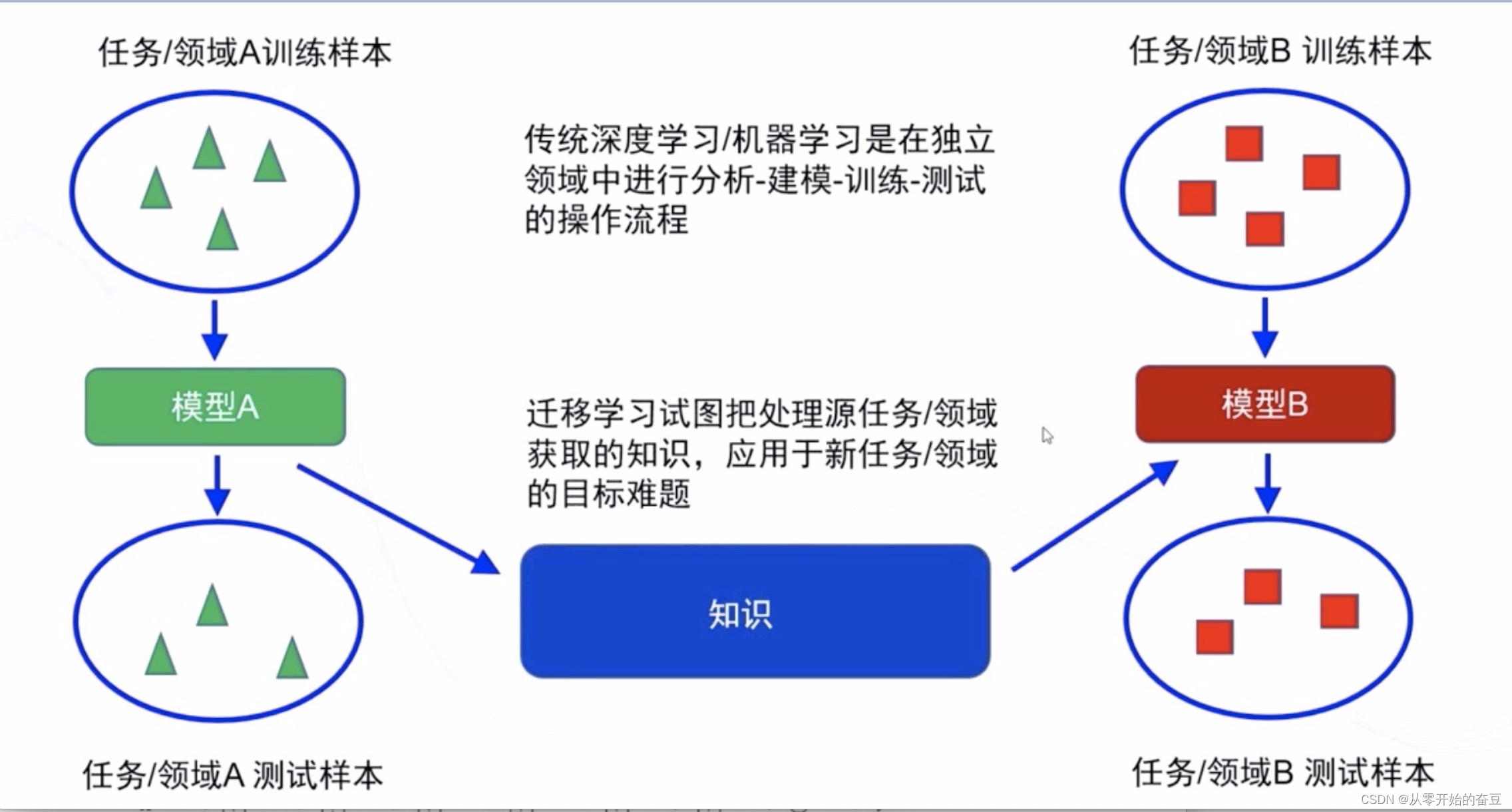
迁移学习的核心思想是将源领域的知识迁移到目标领域中。源领域是已经有大量标注数据的领域,而目标领域是需要解决的新问题。通过迁移学习,源领域的知识可以帮助目标领域的学习过程,提高模型的泛化能力和性能。
迁移学习可以通过多种方式实现,包括特征提取、模型微调和领域自适应等方法。特征提取是将源领域的特征应用到目标领域中,模型微调是在源模型的基础上对目标模型进行调整,领域自适应则是通过对目标领域进行适应性训练来提高性能。
迁移学习在计算机视觉、自然语言处理等领域都有广泛的应用。它可以帮助解决许多实际问题,提高模型的效果和效率。
1.1分类
-
基于实例的迁移学习(Instance-based Transfer Learning):
基于实例的迁移学习是将源任务中的实例样本直接应用于目标任务。这种方法通常通过调整实例的权重或选择一部分实例来实现。例如,如果源任务是图像分类,目标任务是目标检测,可以将源任务中的图像样本用作目标任务的训练数据,从而提供更多的样本和多样性。 -
基于特征的迁移学习(Feature-based Transfer Learning):
基于特征的迁移学习是将源任务的特征表示应用于目标任务。这种方法通常通过共享特征提取器或调整特征的权重来实现。例如,在计算机视觉中,可以使用预训练的卷积神经网络(CNN)作为特征提取器,将其冻结或微调,并将其特征用于目标任务的训练。 -
基于模型的迁移学习(Model-based Transfer Learning):
基于模型的迁移学习是将源任务的模型应用于目标任务。这种方法通常通过微调源模型或在源模型的基础上构建新模型来实现。例如,在自然语言处理中,可以使用预训练的语言模型(如BERT)作为源模型,然后在目标任务上微调该模型,以适应目标任务的特定要求。 -
基于关系的迁移学习(Relation-based Transfer Learning):
基于关系的迁移学习是通过学习源任务和目标任务之间的关系,来进行知识迁移和模型优化。这种方法通常通过学习源任务和目标任务之间的相似性、相关性或映射关系来实现。例如,在推荐系统中,可以通过学习用户和物品之间的关系,将源任务中学习到的用户兴趣模型应用于目标任务中,以提高推荐的准确性和个性化程度。
1.2训练技巧
-
预训练模型(Pretrained Models):使用在大规模数据集上预训练好的模型作为迁移学习的起点,可以帮助提取通用的特征表示。这些预训练模型可以是在类似任务上训练得到的,也可以是在其他领域的任务上训练得到的。
-
微调(Fine-tuning):在迁移学习中,可以将预训练模型的部分或全部参数作为初始参数,然后在目标任务上进行微调。通过在目标任务上进行有限的训练,可以使模型适应目标任务的特定要求,同时保留预训练模型的通用特征。
-
冻结层(Freezing Layers):在微调过程中,可以选择冻结预训练模型的一部分或全部层,只更新目标任务相关的层。这样可以防止过拟合和减少训练时间,尤其在目标任务数据较少的情况下效果更明显。
-
数据增强(Data Augmentation):通过对目标任务的数据进行增强,如旋转、翻转、裁剪等操作,可以扩充数据集的多样性,提高模型的泛化能力。
-
领域自适应(Domain Adaptation):当源任务和目标任务的数据分布存在差异时,可以通过领域自适应技术来减小领域间的差距。例如,使用领域自适应方法对源领域和目标领域进行特征对齐或实例重权,以提高模型在目标领域上的性能。
-
多任务学习(Multi-task Learning):当源任务和目标任务之间存在相关性时,可以将它们作为多个任务一起进行训练。通过共享模型参数和学习任务间的关系,可以提高模型的泛化能力和效果。
2.resnet50
ResNet-50是一种深度残差网络(Residual Network),是ResNet系列中的一种经典模型。它由微软研究院的Kaiming He等人于2015年提出,被广泛应用于计算机视觉任务,如图像分类、目标检测和图像分割等。
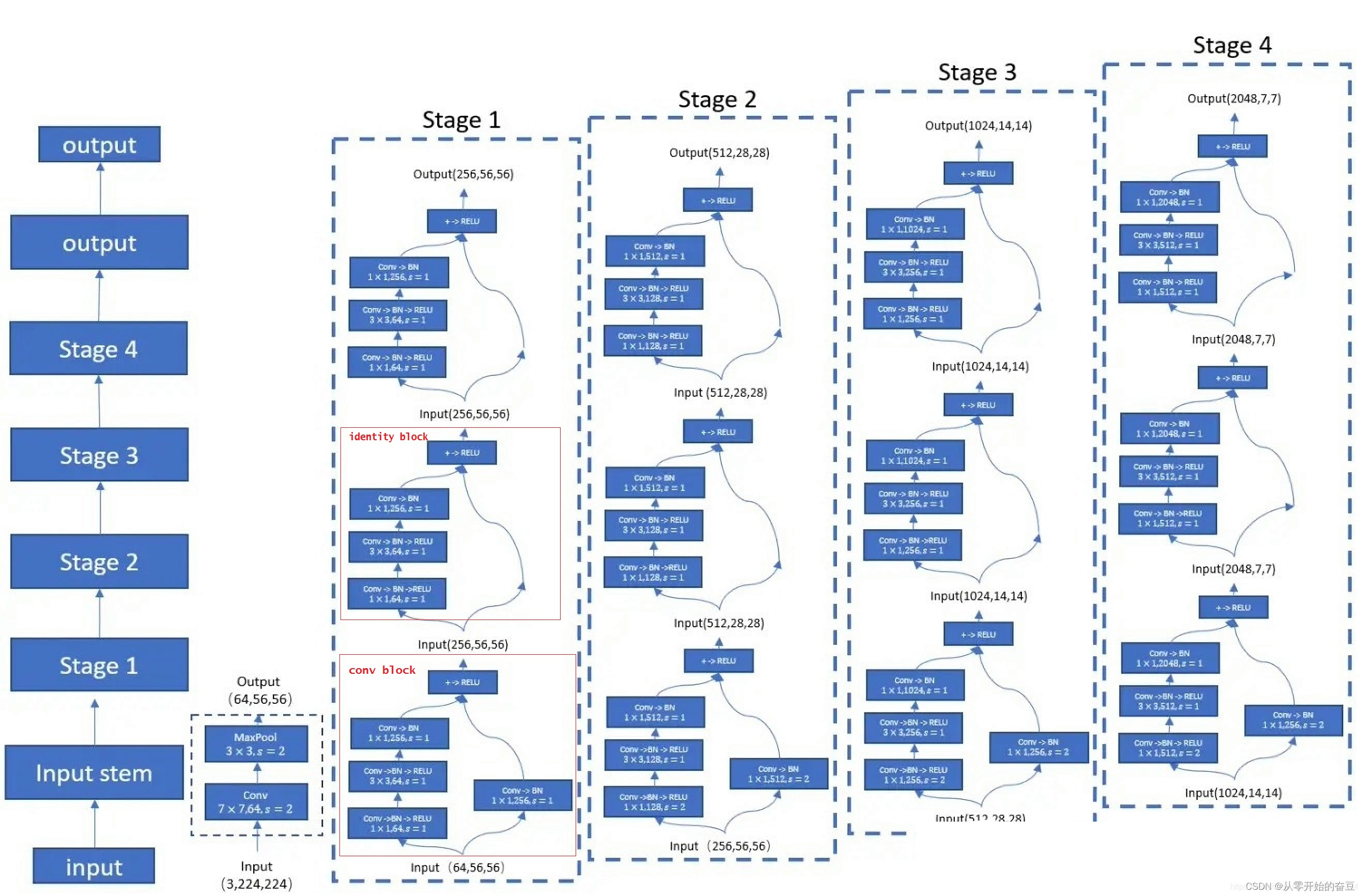
2.1 Convolutional Block和Identity Block
ResNet-50有两个基本块Convolutional Block和Identity Block。
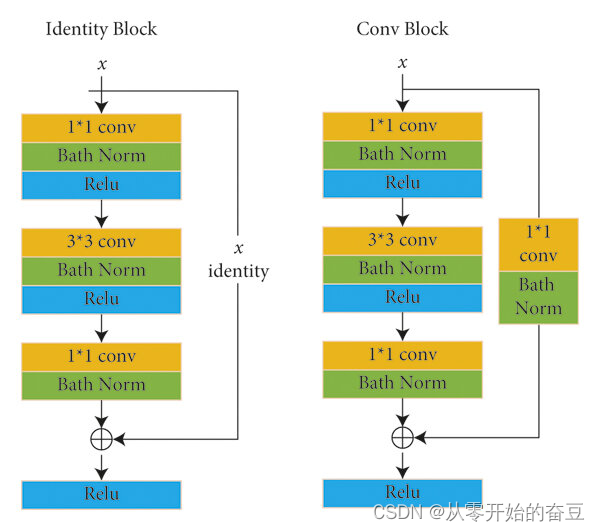
-
Convolutional Block(卷积块):Convolutional Block由一系列卷积层组成,用于学习图像的特征。它的典型结构是:
- 1x1卷积层:用于减少通道数,降低计算复杂度。
- 3x3卷积层:用于学习特征。
- 1x1卷积层:用于恢复通道数,保持特征图的维度一致
Convolutional Block通常在网络的开始部分使用,用于提取图像的低级特征。
-
Identity Block(恒等块):Identity Block由三个卷积层组成,其中第一个和第三个卷积层是1x1卷积层,中间的卷积层是3x3卷积层。它的结构如下:
- 1x1卷积层:用于减少或恢复通道数。
- 3x3卷积层:用于学习特征。
- 1x1卷积层:用于恢复通道数。
Identity Block的输入和输出具有相同的维度,通过跳跃连接(skip connection)将输入直接添加到输出上,保留了原始输入的信息。
ResNet-50通过堆叠Convolutional Block和Identity Block来构建整个网络。这些块的设计使得ResNet-50能够更深更容易训练,并且在图像分类等任务上取得了很好的性能。
2.2 批归一化(Batch Normalization)层
ResNet-50使用了对批归一化(Batch Normalization)层。

批归一化是一种常用的正则化技术,用于加速神经网络的训练过程并提高模型的性能。在ResNet-50中,批归一化层通常在卷积层之后、激活函数之前应用。
批归一化的作用是对每个小批量的输入进行归一化处理,使得输入的均值接近于0,方差接近于1。这有助于缓解梯度消失和梯度爆炸问题,提高网络的稳定性和收敛速度。
在ResNet-50中,批归一化层的操作如下:
- 对于每个通道,计算小批量输入的均值和方差。
- 使用计算得到的均值和方差对小批量输入进行归一化。
- 对归一化后的输入进行缩放和平移,通过可学习的参数进行调整。
- 最后,通过激活函数对调整后的输入进行非线性变换。
批归一化层的引入有助于加速训练过程,提高模型的泛化能力,并且可以允许使用更高的学习率。在ResNet-50中,批归一化层的使用有助于网络的训练和性能的提升。
3.代码实现
3.1数据集
选取imagenet数据集
# 下载数据集
dataset_url = "https://s3.amazonaws.com/fast-ai-imageclas/imagewoof2-160.tgz"
download_url(dataset_url, '.')# 提取压缩文件
with tarfile.open('./imagewoof2-160.tgz', 'r:gz') as tar:tar.extractall(path='./data')# 查看数据目录中的内容
data_dir = './data/imagewoof2-160'
print(os.listdir(data_dir))
classes = os.listdir(data_dir + "/train")
print(classes)

数据进行增强和归一化,创建数据加载器,划分数据集,这里由于我的设备跑不动,所以只加载了25分之一。
# 数据转换(归一化和数据增强)
stats = ((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
train_tfms = tt.Compose([tt.RandomCrop(160, padding=4, padding_mode='reflect'), tt.RandomHorizontalFlip(), tt.ToTensor(), tt.Normalize(*stats,inplace=True)])
valid_tfms = tt.Compose([tt.Resize([160,160]),tt.ToTensor(), tt.Normalize(*stats)])# 创建ImageFolder对象
train_ds = ImageFolder(data_dir+'/train', train_tfms)
valid_ds = ImageFolder(data_dir+'/val', valid_tfms)
print(f'训练数据集长度 = {len(train_ds)}')
print(f'验证数据集长度 = {len(valid_ds)}')
# 计算数据集中的样本数量
num_samples = int(len(train_ds)/25)print(num_samples)
# 创建一个随机索引
indices = list(range(num_samples))# 打乱索引
random.shuffle(indices)# 设置训练集的大小
train_size = int(0.8 * num_samples)# 创建训练集和验证集的索引
train_indices = indices[:train_size]
valid_indices = indices[train_size:]# 创建训练集和验证集的随机抽样器
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)# 设置批量大小
batch_size = 64# 创建训练集和验证集的数据加载器
train_dl = DataLoader(train_ds, batch_size=32, sampler=train_sampler)
valid_dl = DataLoader(valid_ds, batch_size=32, sampler=valid_sampler)""" # PyTorch数据加载器
# 创建数据加载器train_dl = DataLoader(train_ds, batch_size, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size*2) """#展示数据
def show_batch(dl):for images, labels in dl:fig, ax = plt.subplots(figsize=(12, 12))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images[:64], nrow=8, normalize=True).permute(1, 2, 0))breakplt.show()show_batch(train_dl)
3.2 设置设备
#设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def get_default_device():"""Pick GPU if available, else CPU"""if torch.cuda.is_available():return torch.device('cuda')else:return torch.device('cpu')def to_device(data, device):"""Move tensor(s) to chosen device"""if isinstance(data, (list,tuple)):return [to_device(x, device) for x in data]return data.to(device, non_blocking=True)class DeviceDataLoader():"""Wrap a dataloader to move data to a device"""def __init__(self, dl, device):self.dl = dlself.device = devicedef __iter__(self):"""Yield a batch of data after moving it to device"""for b in self.dl: yield to_device(b, self.device)def __len__(self):"""Number of batches"""return len(self.dl)train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)3.3加载resnet50网络结构
这里调整网络结构,写了一个冻结层的函数
def accuracy(outputs, labels):_, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batch out = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batch out = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))class Resnet50(ImageClassificationBase):def __init__(self):super().__init__()# Use a pretrained modelself.network = models.resnet50(pretrained=True)# Replace last layernum_ftrs = self.network.fc.in_featuresself.network.fc = nn.Linear(num_ftrs, 10)def forward(self, xb):return torch.sigmoid(self.network(xb))def freeze(self):# To freeze the residual layersfor param in self.network.parameters():param.require_grad = Falsefor param in self.network.fc.parameters():param.require_grad = Truedef unfreeze(self):# Unfreeze all layersfor param in self.network.parameters():param.require_grad = Truemodel = to_device(Resnet50(), device)
3.4训练及保存模型
# Set up cutom optimizer with weight decayoptimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)# Set up one-cycle learning rate schedulersched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs, steps_per_epoch=len(train_loader))
这段代码首先定义了一个优化器 optimizer,它使用余弦退火(Cosine Annealing)策略进行学习率调度。余弦退火是一种常用的学习率调度策略,它可以在训练过程中缓慢增加学习率,然后在训练过程中缓慢减小学习率,从而实现更高效的训练。
接着,代码定义了一个 OneCycleLR 学习率调度器,它根据余弦退火策略调整学习率。max_lr 参数表示最大学习率,epochs 参数表示总共有多少个训练 epoch,steps_per_epoch 参数表示每个 epoch 中有多少个迭代步骤。
最后,代码将优化器 optimizer 和学习率调度器 sched 分别赋值给模型 model。
@torch.no_grad()
def evaluate(model, val_loader):model.eval()outputs = [model.validation_step(batch) for batch in val_loader]with torch.no_grad():for data,target in val_loader:output = model(data)pred = output.argmax(dim=1,keepdim=True)return model.validation_epoch_end(outputs),preddef get_lr(optimizer):for param_group in optimizer.param_groups:return param_group['lr']def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader, weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):torch.cuda.empty_cache()history = []# Set up cutom optimizer with weight decayoptimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)# Set up one-cycle learning rate schedulersched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs, steps_per_epoch=len(train_loader))for epoch in range(epochs):# Training Phase model.train()train_losses = []lrs = []print("Epoch: ", epoch+1)for batch in tqdm(train_loader):loss = model.training_step(batch)train_losses.append(loss)loss.backward()# Gradient clippingif grad_clip: nn.utils.clip_grad_value_(model.parameters(), grad_clip)optimizer.step()optimizer.zero_grad()# Record & update learning ratelrs.append(get_lr(optimizer))sched.step()# Validation phaseresult,pred = evaluate(model, val_loader)result['train_loss'] = torch.stack(train_losses).mean().item()result['lrs'] = lrsmodel.epoch_end(epoch, result)history.append(result)return historyhistory = []
print(history)
#训练model.freeze()epochs = 10
max_lr = 0.0001
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam""" history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl, grad_clip=grad_clip, weight_decay=weight_decay, opt_func=opt_func)
def plot_accuracies(history):accuracies = [x['val_acc'] for x in history]plt.plot(accuracies, '-x')plt.xlabel('epoch')plt.ylabel('accuracy')plt.title('Accuracy vs. No. of epochs')plt.show()
plot_accuracies(history)
torch.save(model.state_dict(), 'RES.pth') """
3.5预测
model.load_state_dict(torch.load('RES.pth'))
r,result=evaluate(model, valid_dl)
print(result)
data_loader_iter = iter(valid_dl)
while True:try:item = next(data_loader_iter)# 对 item 进行处理image, label = itemexcept StopIteration:break
images=image.numpy()
labels=label.numpy()fig = plt.figure(figsize=(25,4))
for idx in np.arange(9):ax = fig.add_subplot(1,9, idx+1, xticks=[], yticks=[])ax.imshow(images[idx][0])ax.set_title('real:'+str(labels[idx].item())+'ped:'+str(result[idx].item()))
plt.show()

4.总代码
import os
import torch
import torchvision
import tarfile
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from torchvision.datasets.utils import download_url
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torchvision.transforms as tt
from torchvision.utils import make_grid
import torchvision.models as models
import matplotlib.pyplot as plt
from tqdm import tqdm
from torch.utils.data.sampler import SubsetRandomSampler
import random#matplotlib inline
# 下载数据集
dataset_url = "https://s3.amazonaws.com/fast-ai-imageclas/imagewoof2-160.tgz"
download_url(dataset_url, '.')# 提取压缩文件
with tarfile.open('./imagewoof2-160.tgz', 'r:gz') as tar:tar.extractall(path='./data')# 查看数据目录中的内容
data_dir = './data/imagewoof2-160'
print(os.listdir(data_dir))
classes = os.listdir(data_dir + "/train")
print(classes)# 数据转换(归一化和数据增强)
stats = ((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
train_tfms = tt.Compose([tt.RandomCrop(160, padding=4, padding_mode='reflect'), tt.RandomHorizontalFlip(), tt.ToTensor(), tt.Normalize(*stats,inplace=True)])
valid_tfms = tt.Compose([tt.Resize([160,160]),tt.ToTensor(), tt.Normalize(*stats)])# 创建ImageFolder对象
train_ds = ImageFolder(data_dir+'/train', train_tfms)
valid_ds = ImageFolder(data_dir+'/val', valid_tfms)
print(f'训练数据集长度 = {len(train_ds)}')
print(f'验证数据集长度 = {len(valid_ds)}')
# 计算数据集中的样本数量
num_samples = int(len(train_ds)/25)print(num_samples)
# 创建一个随机索引
indices = list(range(num_samples))# 打乱索引
random.shuffle(indices)# 设置训练集的大小
train_size = int(0.8 * num_samples)# 创建训练集和验证集的索引
train_indices = indices[:train_size]
valid_indices = indices[train_size:]# 创建训练集和验证集的随机抽样器
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)# 设置批量大小
batch_size = 64# 创建训练集和验证集的数据加载器
train_dl = DataLoader(train_ds, batch_size=32, sampler=train_sampler)
valid_dl = DataLoader(valid_ds, batch_size=32, sampler=valid_sampler)""" # PyTorch数据加载器
# 创建数据加载器train_dl = DataLoader(train_ds, batch_size, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size*2) """#展示数据
def show_batch(dl):for images, labels in dl:fig, ax = plt.subplots(figsize=(12, 12))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images[:64], nrow=8, normalize=True).permute(1, 2, 0))breakplt.show()show_batch(train_dl)#设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def get_default_device():"""Pick GPU if available, else CPU"""if torch.cuda.is_available():return torch.device('cuda')else:return torch.device('cpu')def to_device(data, device):"""Move tensor(s) to chosen device"""if isinstance(data, (list,tuple)):return [to_device(x, device) for x in data]return data.to(device, non_blocking=True)class DeviceDataLoader():"""Wrap a dataloader to move data to a device"""def __init__(self, dl, device):self.dl = dlself.device = devicedef __iter__(self):"""Yield a batch of data after moving it to device"""for b in self.dl: yield to_device(b, self.device)def __len__(self):"""Number of batches"""return len(self.dl)train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)#基于批量归一化的预训练 ResNet 模型的定义
def accuracy(outputs, labels):_, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batch out = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batch out = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))class Resnet50(ImageClassificationBase):def __init__(self):super().__init__()# Use a pretrained modelself.network = models.resnet50(pretrained=True)# Replace last layernum_ftrs = self.network.fc.in_featuresself.network.fc = nn.Linear(num_ftrs, 10)def forward(self, xb):return torch.sigmoid(self.network(xb))def freeze(self):# To freeze the residual layersfor param in self.network.parameters():param.require_grad = Falsefor param in self.network.fc.parameters():param.require_grad = Truedef unfreeze(self):# Unfreeze all layersfor param in self.network.parameters():param.require_grad = Truemodel = to_device(Resnet50(), device)
print(model)#fit函数
@torch.no_grad()
def evaluate(model, val_loader):model.eval()outputs = [model.validation_step(batch) for batch in val_loader]with torch.no_grad():for data,target in val_loader:output = model(data)pred = output.argmax(dim=1,keepdim=True)return model.validation_epoch_end(outputs),preddef get_lr(optimizer):for param_group in optimizer.param_groups:return param_group['lr']def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader, weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):torch.cuda.empty_cache()history = []# Set up cutom optimizer with weight decayoptimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)# Set up one-cycle learning rate schedulersched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs, steps_per_epoch=len(train_loader))for epoch in range(epochs):# Training Phase model.train()train_losses = []lrs = []print("Epoch: ", epoch+1)for batch in tqdm(train_loader):loss = model.training_step(batch)train_losses.append(loss)loss.backward()# Gradient clippingif grad_clip: nn.utils.clip_grad_value_(model.parameters(), grad_clip)optimizer.step()optimizer.zero_grad()# Record & update learning ratelrs.append(get_lr(optimizer))sched.step()# Validation phaseresult,pred = evaluate(model, val_loader)result['train_loss'] = torch.stack(train_losses).mean().item()result['lrs'] = lrsmodel.epoch_end(epoch, result)history.append(result)return historyhistory = []
print(history)
#训练model.freeze()epochs = 10
max_lr = 0.0001
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam""" history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl, grad_clip=grad_clip, weight_decay=weight_decay, opt_func=opt_func)
def plot_accuracies(history):accuracies = [x['val_acc'] for x in history]plt.plot(accuracies, '-x')plt.xlabel('epoch')plt.ylabel('accuracy')plt.title('Accuracy vs. No. of epochs')plt.show()
plot_accuracies(history)
torch.save(model.state_dict(), 'RES.pth') """
model.load_state_dict(torch.load('RES.pth'))
r,result=evaluate(model, valid_dl)
print(result)
data_loader_iter = iter(valid_dl)
while True:try:item = next(data_loader_iter)# 对 item 进行处理image, label = itemexcept StopIteration:break
images=image.numpy()
labels=label.numpy()fig = plt.figure(figsize=(25,4))
for idx in np.arange(9):ax = fig.add_subplot(1,9, idx+1, xticks=[], yticks=[])ax.imshow(images[idx][0])ax.set_title('real:'+str(labels[idx].item())+'ped:'+str(result[idx].item()))
plt.show()相关文章:
深度学习(五):pytorch迁移学习之resnet50
1.迁移学习 迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。 迁移学习的核心思想是将源领域的知识迁…...

面试官:说说synchronized与ReentrantLock的区别
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
数据结构学习笔记——广义表
目录 一、广义表的定义二、广义表的表头和表尾三、广义表的深度和长度四、广义表与二叉树(一)广义表表示二叉树(二)广义表表示二叉树的代码实现 一、广义表的定义 广义表是线性表的进一步推广,是由n(n≥0&…...
)
为什么每次optimizer.zero_grad()
当你训练一个神经网络时,每一次的传播和参数更新过程可以被分解为以下步骤: 1前向传播:网络对输入数据进行操作,最终生成输出。这个过程会基于当前的参数(权重和偏差)计算出一个或多个损失函数的值。 2计…...

一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么
一个页面从输入URL到加载显示完成经历了以下过程: DNS解析:浏览器会解析URL中的域名,将其转换为对应的IP地址。如果浏览器缓存中存在该域名的IP地址,则跳过DNS解析步骤。 建立TCP连接:通过解析得到的IP地址࿰…...

iOS ------ UICollectionView
一,UICollectionView的简介 UICollectionView是iOS6之后引入的一个新的UI控件,它和UITableView有着诸多的相似之处,其中许多代理方法都十分类似。简单来说,UICollectionView是比UITbleView更加强大的一个UI控件,有如下…...
ElasticSearch知识体系详解
1.介绍 ElasticSearch是基于Lucene的开源搜索及分析引擎,使用Java语言开发的搜索引擎库类,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。 它可以被下面这样准确的形容: 一个分布式的实时文档存储…...

Linux自启服务提示:systemd[1]: *.service: main process exited, code=exited, status=1问题
这两天一直在沉迷于配脚本,由于服务器很多,所以我都是从一台服务器上配置好的脚本直接copy到另一台服务器,按说完全一样的脚本一样的操作,那么应该是一样的执行结果 but, Gul’dan,代…我重启服务器后服务并没有正常启…...
LoadBalancer将服务暴露到外部实现负载均衡purelb-layer2模式配置介绍
目录 一.purelb简介 1.简介 2.purelb的layer2工作模式特点 二.layer2的配置演示 1.首先准备ipvs和arp配置环境 2.purelb部署开始 (1)下载purelb-complete.yaml文件并应用 (2)查看该有的资源是否创建完成并运行 ÿ…...
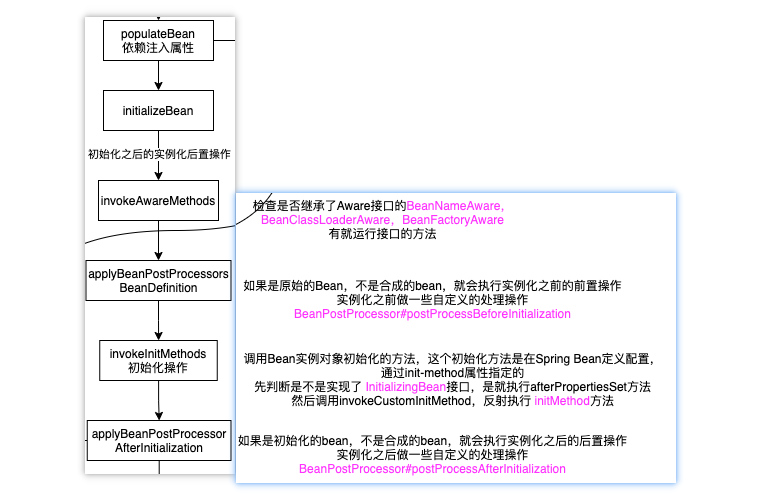
Spring Bean的生命周期各阶段详解附源码
目录 Bean的生命周期Bean定义阶段Bean实例化阶段Bean属性注入阶段Bean初始化阶段Bean销毁阶段 Bean的生命周期 bean的生命周期,我们都知道大致是分为:bean定义,bean的实例化,bean的属性注入,bean的初始化以及bean的销毁…...
LoadBalancer将服务暴露到外部实现负载均衡Openelb-layer2模式配置介绍
目录 一.openelb简介 二.主要介绍layer2模式 1.简介 2.原理 3.部署 (1)先在集群master上开启kube-proxy的strictARP (2)应用下载openelb.yaml(需要修改镜像地址) (3)编写yam…...

Android异步之旅:探索IntentService
1.介绍IntentService IntentService是Android中的一个Service类,用于在后台执行耗时操作,而不会阻塞UI线程。它封装了HandlerThread和Handler,使得我们可以方便地在后台执行任务,而不需要自己管理线程和消息处理。 以下是 Intent…...
)
131.类型题-计算数学序列的和,请编写函数fun,其功能是S=……【满分解题代码+详细分析】(数学序列的和类型题-C/C++JavaPython实现)
文章目录 131.类型题-计算数学序列的和:计算并输出一.题目1.1 解题思路二.解题代码2.1 C/C++解题代码2.2 python解题代码2.3 Java解题代码三.解题代码仔细分析3.1 C/C++解题代码仔细分析3.2 Java解题代码仔细分析3.3 Python解题代码仔细分析四.本类型题解题诀窍五.寄语131.类型…...
【Unity动画】状态机中层的融合原理与用法详解
1. 状态机概念介绍 在Unity中,动画状态机(Animator State Machine)是一种强大的工具,用于控制游戏对象的动画行为。动画状态机由多个动画状态Animation和过渡条件Transition、层组成!而层(Layersÿ…...

等保之道:从基础出发,解密网站防护的重要性
随着数字化时代的推进,网站安全问题日益凸显。网站被攻击不仅会导致信息泄漏、服务中断,还可能损害用户信任和企业声誉。为了更好地解决这一问题,我们需从等保的角度审视网站防护,全面提升网络安全水平。 等保背景 等保࿰…...

7. 系统信息与系统资源
7. 系统信息与系统资源 1. 系统信息1.1 系统标识 uname()1.2 sysinfo()1.3 gethostname()1.4 sysconf() 2. 时间、日期2.1 Linux 系统中的时间2.1.1 Linux 怎么记录时间2.1.2 jiffies 的引入 2.2 获取时间 time/gettimeofday2.2.1 time()2.2.2 gettimeofday() 2.3 时间转换函数…...

【重点】【滑动窗口】239. 滑动窗口最大值
题目 也可参考:剑指offer——面试题65:滑动窗口的最大值 class Solution {public int[] maxSlidingWindow(int[] nums, int k) {int[] res new int[nums.length - k 1];Deque<Integer> q new LinkedList<>();int inx 0;while (inx <…...

d3dx9_43.dll丢失原因以及5个解决方法详解
在电脑使用过程中,我们可能会遇到一些错误提示,其中之一就是“d3dx9_43.dll缺失”。这个错误提示通常表示我们的电脑上缺少了DirectX的一个组件,而DirectX是游戏和多媒体应用所必需的软件。本文将介绍d3dx9_43.dll缺失对电脑的影响以及其原因…...
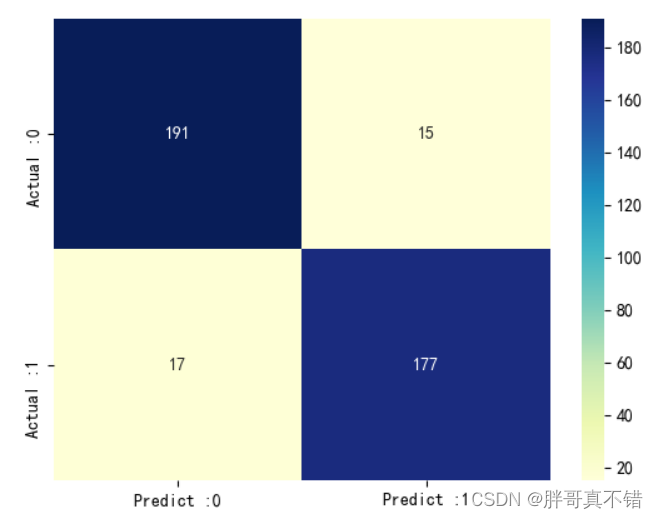
Python实现FA萤火虫优化算法优化卷积神经网络分类模型(CNN分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 萤火虫算法(Fire-fly algorithm,FA)由剑桥大学Yang于2009年提出 , …...

不瞒各位,不安装软件也能操作Xmind文档
大家好,我是小悟 作为搞技术的一个人群,时不时就要接收产品经理发过来的思维脑图,而此类文档往往是以Xmind编写的,如果你的电脑里面没有安装Xmind的话,不好意思,是打不开这类后缀结尾的文档。 打不开的话…...

利用Taotoken多模型能力为AIGC应用动态选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型能力为AIGC应用动态选择最佳模型 在构建内容生成类应用时,开发者常常面临一个核心挑战:…...

企业级应用如何通过taotoken统一管理多个大模型api调用与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken统一管理多个大模型API调用与成本 对于需要集成多种大语言模型的企业技术团队而言,直接对接…...
)
【限时解密】DeepSeek内部SSO安全加固白皮书(含JWT签名验签绕过防护方案)
更多请点击: https://codechina.net 第一章:DeepSeek SSO单点登录体系概览 DeepSeek SSO 是面向企业级 AI 开发平台构建的统一身份认证与访问控制中枢,支持 OAuth 2.0、OpenID Connect 及 SAML 2.0 多协议接入,实现跨服务&#x…...

抖音视频批量下载工具终极指南:3分钟实现高效无水印下载
抖音视频批量下载工具终极指南:3分钟实现高效无水印下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback sup…...

ToastFish:如何在Windows通知栏中偷偷背单词的终极指南
ToastFish:如何在Windows通知栏中偷偷背单词的终极指南 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish 你是否曾经在忙碌的工作间隙想要学习英语,却又担心被同事或老板…...

Beyond Compare 5密钥生成解决方案:告别评估模式限制的专业工具
Beyond Compare 5密钥生成解决方案:告别评估模式限制的专业工具 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当你的文件对比工具Beyond Compare 5弹出"评估模式错误"提…...

AMD Ryzen嵌入式COM Express模块:工业边缘计算的高性能解决方案
1. 项目概述:当工业计算遇上“锐龙”芯在工业自动化、边缘计算和高端嵌入式领域,COM Express(Computer-On-Module Express)模块一直是构建紧凑、高性能、高可靠性系统的基石。它就像一台浓缩的、标准化的“电脑主板核心”…...

VisualCppRedist AIO:一站式解决Windows C++运行库依赖问题
VisualCppRedist AIO:一站式解决Windows C运行库依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中许多应用程序…...

集成测试实战
软件测试理论:https://blog.csdn.net/2402_88266590/article/details/160966638?spm1011.2415.3001.5331 单元测试实战:https://blog.csdn.net/2402_88266590/article/details/161017518?spm1001.2014.3001.5502 下面就开始进入集成测试的学习吧&…...
)
中国航空器拥有者及驾驶员协会:我国低空经济重点政策制度汇编(2025)
这份文档是2025 年中国低空经济重点政策制度汇编,由中国航空器拥有者及驾驶员协会编制,全面梳理国家 地方两级低空经济相关法律法规、规章标准与产业政策,核心是构建低空经济 “法律 - 规章 - 标准 - 政策” 四层制度体系,为低空…...