AIGC-文生视频
stable diffusion的前传:
轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型 - 知乎近两年,有许多图像生成类任务的前沿工作都使用了一种叫做"codebook"的机制。追溯起来,codebook机制最早是在VQ-VAE论文中提出的。相比于普通的VAE,VQ-VAE能利用codebook机制把图像编码成离散向量,为图…![]() https://zhuanlan.zhihu.com/p/633744455
https://zhuanlan.zhihu.com/p/633744455
VQGAN是一个改进版的VQVAE,它将感知误差和GAN引入了图像压缩模型,把压缩图像生成模型替换成了更强大的Transformer。相比纯种的GAN(如StyleGAN),VQGAN的强大之处在于它支持带约束的高清图像生成。VQGAN借助NLP中"decoder-only"策略实现了带约束图像生成,并使用滑动窗口机制实现了高清图像生成。虽然在某些特定任务上VQGAN还是落后于其他GAN,但VQGAN的泛化性和灵活性都要比纯种GAN要强。它的这些潜力直接促成了Stable Diffusion的诞生。
如果你是读完了VQVAE再来读的VQGAN,为了完全理解VQGAN,你只需要掌握本文提到的4个知识点:VQVAE到VQGAN的改进方法、使用Transformer做图像生成的方法、使用"decoder-only"策略做带约束图像生成的方法、用滑动滑动窗口生成任意尺寸的图片的思想。
VQGAN 论文与源码解读:前Diffusion时代的高清图像生成模型 - 知乎2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVA…![]() https://zhuanlan.zhihu.com/p/637705399?utm_id=0
https://zhuanlan.zhihu.com/p/637705399?utm_id=0
改进版的vqgen:maskgit
[CVPR2022]MaskGIT: Masked Generative Image Transformer阅读笔记 - 知乎arxiv: MaskGIT: Masked Generative Image Transformergithub: google-research/maskgit: Official Jax Implementation of MaskGIT (github.com)笔记链接: https://occipital-aphid-dee.notion.site/MaskGIT-Ma…![]() https://zhuanlan.zhihu.com/p/618235198
https://zhuanlan.zhihu.com/p/618235198
stable diffusion:
stable diffusion原理解读通俗易懂,史诗级万字爆肝长文,喂到你嘴里 - 知乎个人网站一、前言(可跳过)hello,大家好我是 Tian-Feng,今天介绍一些stable diffusion的原理,内容通俗易懂,因为我平时也玩Ai绘画嘛,所以就像写一篇文章说明它的原理,这篇文章写了真滴挺久的,如果对你有用…![]() https://zhuanlan.zhihu.com/p/634573765
https://zhuanlan.zhihu.com/p/634573765
文生图相关的一些原理:
https://zhuanlan.zhihu.com/p/645939505前言传送门: stable diffusion:Git|论文 stable-diffusion-webui:Git Google Colab Notebook部署stable-diffusion-webui:Git kaggle Notebook部署stable-diffusion-webui:Git今年AIGC实在是太火了,让人大呼…![]() https://zhuanlan.zhihu.com/p/645939505
https://zhuanlan.zhihu.com/p/645939505
stable diffusion的相关介绍与代码展示:CLIP text encoder、UNet、文生图、文生视频、inpainting
https://zhuanlan.zhihu.com/p/617134893通向AGI之路码字真心不易,求点赞! https://zhuanlan.zhihu.com/p/6424968622022年可谓是 AIGC(AI Generated Content)元年,上半年有文生图大模型DALL-E2和Stable Diffusion,下半年有OpenAI的文本对话大模型Ch…![]() https://zhuanlan.zhihu.com/p/617134893
https://zhuanlan.zhihu.com/p/617134893
AnimateDiff:
https://blog.csdn.net/qq_41994006/article/details/132011849
https://blog.csdn.net/shadowcz007/article/details/131757666
https://www.zhihu.com/pin/1685665464804700161
部署:https://blog.csdn.net/weixin_51330846/article/details/133795764
https://huggingface.co/guoyww/animatediff/discussions/5
Dreambooth
https://zhuanlan.zhihu.com/p/620577688这个系列会分享下stable diffusion中比较常用的几种训练方式,分别是Dreambooth、textual inversion、LORA和Hypernetworks。在 https://civitai.com/选择模型时也能看到它们的身影。本文该系列的第一篇Dreambooth1…![]() https://zhuanlan.zhihu.com/p/620577688
https://zhuanlan.zhihu.com/p/620577688
Reuse-And-Diffuse
ReuseAndDiffuse笔记-CSDN博客文章浏览阅读111次。Long video classification datasets:一些较长的视频,如VideoLT数据集,用MiniGPT-4等大模型,来先分类出哪些帧是可以剪出来用的,然后再理解这些帧。平常的stable-diffusion,是图片的解码器,这样的话帧间还是有差别的,文章在解码器中间也加入了Temp-Conv,以提高帧间的连贯性。对于Unet,每层都加入两个可训练的,包含时间维度的层,Temp-Conv是针对视频数据的三维卷积,Temp-Attn是时间维度上的注意力机制。https://blog.csdn.net/pc9803/article/details/134131805?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22134131805%22%2C%22source%22%3A%22pc9803%22%7D
phenaki
GitHub - lucidrains/phenaki-pytorch: Implementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in PytorchImplementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in Pytorch - GitHub - lucidrains/phenaki-pytorch: Implementation of Phenaki Video, which uses Mask GIT to produce text guided videos of up to 2 minutes in length, in Pytorch![]() https://github.com/lucidrains/phenaki-pytorchhttps://huggingface.co/obvious-research/phenaki-cvivit/tree/main
https://github.com/lucidrains/phenaki-pytorchhttps://huggingface.co/obvious-research/phenaki-cvivit/tree/main![]() https://huggingface.co/obvious-research/phenaki-cvivit/tree/main
https://huggingface.co/obvious-research/phenaki-cvivit/tree/main
【项目部署调试】 AnimateDiff-CSDN博客文章浏览阅读674次。717行,原来是直接改为路径本来,一切到这就结束了,可是726行却总是报错原本是百思不得其解,知道在 github 的 issue 里的某个问题的某个评论看到了改为OK ,结束,跑起来了~p.s. 按照默认的16帧跑要12G显存。https://blog.csdn.net/weixin_51330846/article/details/133795764
maskgit
自回归解码加速64倍,谷歌提出图像合成新模型MaskGIT![]() https://m.thepaper.cn/baijiahao_17087787
https://m.thepaper.cn/baijiahao_17087787
[CVPR2022]MaskGIT: Masked Generative Image Transformer阅读笔记 - 知乎arxiv: MaskGIT: Masked Generative Image Transformergithub: google-research/maskgit: Official Jax Implementation of MaskGIT (github.com)笔记链接: https://occipital-aphid-dee.notion.site/MaskGIT-Ma…![]() https://zhuanlan.zhihu.com/p/618235198
https://zhuanlan.zhihu.com/p/618235198
ViViT
ViViT: A Video Vision Transformer阅读和代码 - 知乎文章地址: https://arxiv.org/pdf/2103.15691.pdf文章代码: https://github.com/google-research/scenic/tree/main/scenic/projects/vivit依旧是Google的作品,Google算法上确实是领跑世界。在视频理解上使用了T…![]() https://zhuanlan.zhihu.com/p/506607332(动作分类篇)ViViT: A Video Vision Transformer - 知乎在阅读完VT综述后的第一篇正式的视频理解论文阅读笔记,ViViT作为纯transformer结构,在动作分类方向提出了四个模型,以及不同的embedding和参数初始化方式等等,并且做了丰富的实验。接下来直接从模型介绍开始总…
https://zhuanlan.zhihu.com/p/506607332(动作分类篇)ViViT: A Video Vision Transformer - 知乎在阅读完VT综述后的第一篇正式的视频理解论文阅读笔记,ViViT作为纯transformer结构,在动作分类方向提出了四个模型,以及不同的embedding和参数初始化方式等等,并且做了丰富的实验。接下来直接从模型介绍开始总…![]() https://zhuanlan.zhihu.com/p/505287712【ViViT】A Video Vision Transformer 用于视频数据特征提取的ViT详解_vit 视频_萝卜社长的博客-CSDN博客文章浏览阅读2.5k次,点赞5次,收藏36次。VIVIT详解_vit 视频
https://zhuanlan.zhihu.com/p/505287712【ViViT】A Video Vision Transformer 用于视频数据特征提取的ViT详解_vit 视频_萝卜社长的博客-CSDN博客文章浏览阅读2.5k次,点赞5次,收藏36次。VIVIT详解_vit 视频https://blog.csdn.net/lym823556031/article/details/127939000
IQA--VQA
不同的图像质量评价指标(IQA)_LanceHang的博客-CSDN博客文章浏览阅读800次。NRQM(Non-Reference Quality Metric)是一种非参考图像质量评价指标,用于自动评估图像的质量,而不需要参考图像(即原始或真实图像)。总的来说,NIMA 是一种基于深度学习的图像质量评价方法,它利用深度CNN模型从图像中提取特征,并能够输出图像的质量分数,使其成为自动化图像质量评估的有力工具。LPIPS 在计算机视觉和图像处理领域中被广泛应用,特别是在图像生成、超分辨率、图像风格迁移等任务中,用于评估生成的图像与原始图像之间的相似性和质量。https://blog.csdn.net/LanceHang/article/details/132802874
相关文章:
AIGC-文生视频
stable diffusion的前传: 轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型 - 知乎近两年,有许多图像生成类任务的前沿工作都使用了一种叫做"codebook"的机制。追溯起来,codebook机制最早是在VQ-VAE论文中提出的。相比…...

java中Collectors.groupingBy返回实例?
在Java中,Collectors.groupingBy()是一个用于对流元素进行分组的收集器。它可以根据指定的分类函数对流元素进行分组,并返回一个Map对象,其中键是分组的标准,值是属于相应组的元素列表。 下面是一个使用Collectors.groupingBy()方…...

uniapp打包的h5项目多了接口调用https://api.next.bspapp.com/client
产生跨域问题。 这个实际上是因为该项目在manifest.json文件中勾选了‘uni统计配置’导致的,取消勾选就可以了。 如果是小程序项目,在小程序开发者工具中添加可信任域名就可以了。 可以看看下面这个链接内容 uni-app H5跨域问题解决方案(…...

探索跨境建站:如何借助软骨鱼SaaS平台快速搭建独立站
随着全球电子商务的蓬勃发展,作为一名资深的跨境电商从业者,我深知跨境建站服务需要与时俱进,不断迈向更高效、更智能的2.0时代。今天,我想和大家分享一个让我眼前一亮的解决方案——软骨鱼SaaS平台,这个平台彻底颠覆了…...

C语言-字符串输入输出
字符串赋值 char *t “title”;char *s;s t;并没有产生新的字符串,只是让指针s指向了t所指的字符串, 对s的任何操作就是对t做的 字符串输入输出 char string[8];scanf(“%s”, string);printf(“%s”, string);scanf读入一个单词(到空格…...
OpenHarmony 设备启动Logo和启动视频替换指南
前言 OpenHarmony源码版本:4.0release 开发板:DAYU / rk3568 一、Logo替换 替换其中的logo.bmp 和 logo_kernel.bmp文件 注意事项: 1、图片的分辨率需要和设备匹配 2、如果是非首次编译(存在缓存)需要将out目录删…...

Python中函数添加超时时间,Python中signal使用
from time import time, sleepimport signal# 模拟要删除5条数据,中间有超时的i 5# 超时后执行的方法def timeout_handler(signal, frame):# 引发异常raise TimeoutError("删除第" str(i) "条,超时!")# 或者执行其他操作,不往外抛异常(超时的函数不会被…...
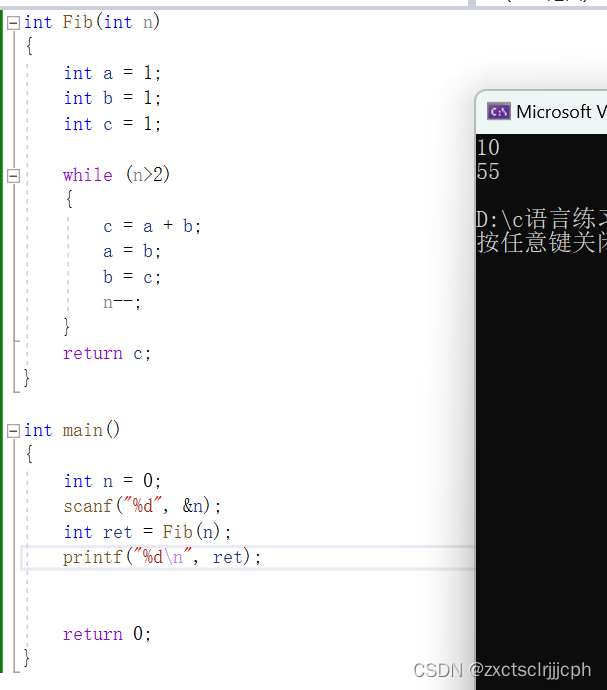
【C语言】递归详解
目录 1.前言2. 递归的定义3. 递归的限制条件4. 递归举例4.1 求n的阶乘4.1.1 分析和代码实现4.1.2 画图演示 4.2 顺序打印一个整数的每一位4.2.1 分析和代码实现4.2.2 画图推演 4.3 求第n个斐波那契数 5. 递归与迭代5.1 迭代求第n个斐波那契数 1.前言 这次博客内容是与递归有关&…...
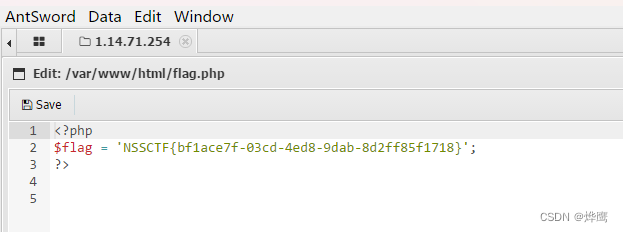
NSSCTF 文件上传漏洞题目
目录 [SWPUCTF 2021 新生赛]easyupload1.0 [SWPUCTF 2021 新生赛]easyupload2.0 [SWPUCTF 2021 新生赛]easyupload3.0 [SWPUCTF 2021 新生赛]easyupload1.0 这是一个文件上传漏洞的题目 我们的思路是上传一句话木马,用工具进行连接 先编写一句话木马 将文件后缀…...
layui+ssm实现数据表格双击编辑更新数据
layui实现数据表格双击编辑数据更新 在使用layui加载后端数据请求时,对数据选项框进行双击即可实现数据的输入编辑更改 代码块 var form layui.form, table layui.table,layer parent.layer undefined ? layui.layer : parent.layer,laypage layui.laypag…...
windows下DSS界面本地集成linkis管理台
说明:当前开发环境为windows,node版本使用16.15.1。启动web时,确保后端服务已准备就绪。 1.linkis web编译 #进入项目WEB根目录 $ cd linkis/linkis-web #安装项目所需依赖 $ npm install参考官方编译说明,windows下编译一直异常…...
基于PaddleSeg开发的人像抠图web api接口
前言 基于PaddleSeg开发的人像抠图web api接口,提取官方代码,适配各种系统,通过api的接口进行访问。 环境要求 1、Python3.7以上 2、源码(文章最后下载) 源码结构 测试module.py中添加如下代码: if __na…...
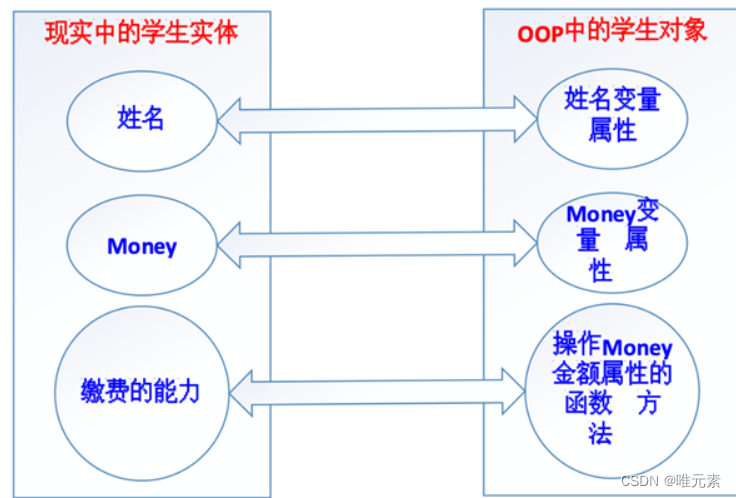
Python---面向对象的基本概念
对象 对象,object,现实业务逻辑的一个动作实体就对应着OOP编程中的一个对象! 所以:① 对象使用属性(property)保存数据!② 对象使用方法(method)管理数据! …...

cv2.threshold 图像二值化
图像二值化 whatparameters示例 what cv2.threshold是OpenCV中用于进行图像二值化的函数。它的作用是将输入图像的像素值转换为两个可能的值之一,通常是0(黑色)或255(白色),根据一个设定的阈值。图像二值化…...
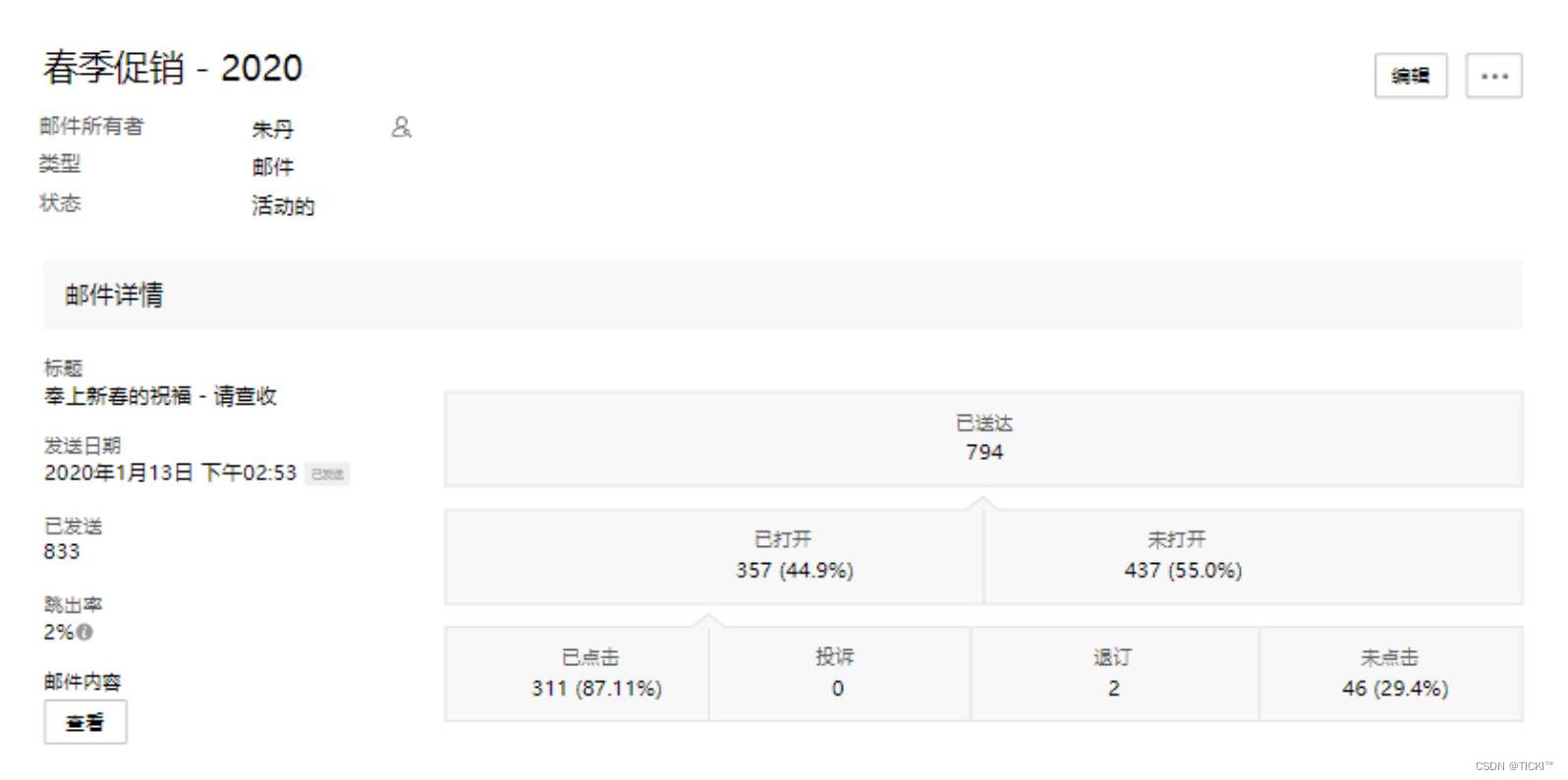
CRM:提升营销效果的关键
一场成功的营销活动,可以帮助企业扩大知名度,获取大量的优质商机。作为专业的管理软件,CRM系统同样具备营销管理的能力,帮助企业实现营销活动的规划、执行和监控,提高营销效果。下面说说,CRM营销自动化对企…...

AIGC: 关于ChatGPT中基于API实现一个StreamClient流式客户端
Java版GPT的StreamClient 可作为其他编程语言的参考注意: 下面包名中的 xxx 可以换成自己的代码基于java,来源于网络,可修改成其他编程语言实现参考前文: https://blog.csdn.net/Tyro_java/article/details/134748994 1 )核心代码结构设计 …...
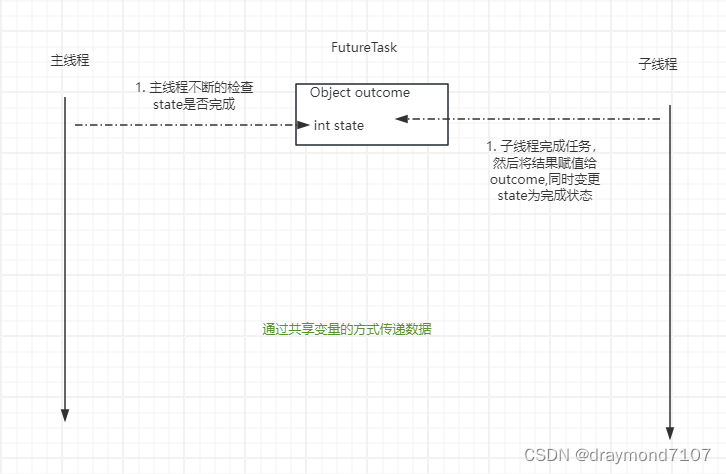
FutureTask
1. 作用 异步操作获取执行结果取消任务执行,判断是否取消执行判断任务执行是否完毕 2. demo public static void main(String[] args) throws Exception {Callable<String> callable () -> search();FutureTask<String> futureTasknew FutureTask&…...
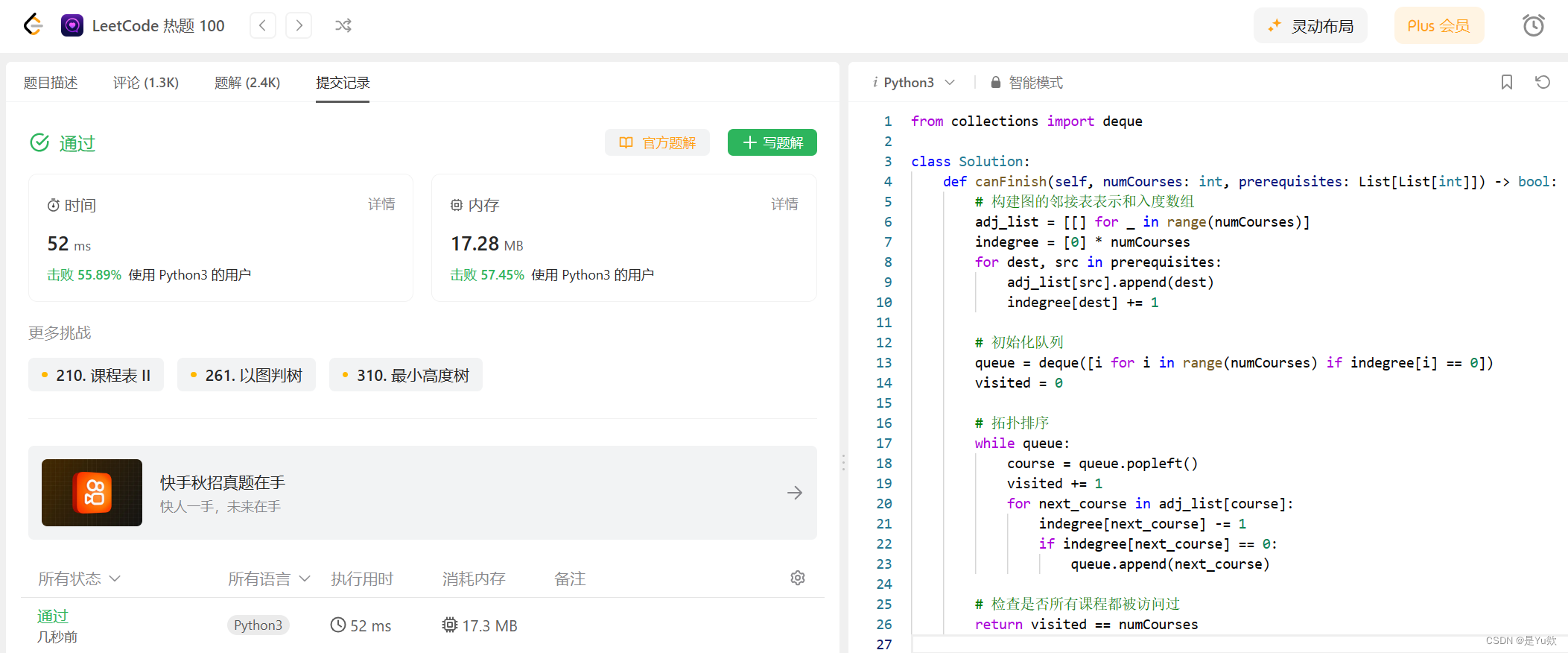
【力扣热题100】207. 课程表 python 拓扑排序
【力扣热题100】207. 课程表 python 拓扑排序 写在最前面207. 课程表解决方案:判断是否可以完成所有课程的学习方法:拓扑排序实现步骤Python 实现性能分析结论 写在最前面 刷一道力扣热题100吧 难度中等 https://leetcode.cn/problems/course-schedule…...

【滑动窗口】LeetCode2953:统计完全子字符串
作者推荐 [二分查找]LeetCode2040:两个有序数组的第 K 小乘积 本题其它解法 【离散差分】LeetCode2953:统计完全子字符串 题目 给你一个字符串 word 和一个整数 k 。 如果 word 的一个子字符串 s 满足以下条件,我们称它是 完全字符串: s 中每个字符…...

base64转PDF
今天做皖事通的对接,下载电子证照后发现回传的是base64,调试确认是个麻烦事,网上搜了一下没有base64转PDF的在线预览功能,只能自己写个调试工具了,以下是通过纯JS方式写的代码,可直接拿去使用: …...

如何在Windows上轻松安装APK文件?APK Installer完整指南
如何在Windows上轻松安装APK文件?APK Installer完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装安卓应用而烦恼吗?…...

3大技术突破:APK Installer如何重新定义Windows上的安卓应用体验
3大技术突破:APK Installer如何重新定义Windows上的安卓应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK Installer是一款革命性的Windows平台安…...

Keep架构深度解析:企业级AIOps告警管理平台的设计与实践
Keep架构深度解析:企业级AIOps告警管理平台的设计与实践 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep Keep作为开源AIOps告警管理平台,采用现代化的微服…...
,让开源检索进入“所想即所得”时代)
别再Ctrl+F GitHub了!Perplexity高级提示词工程(含18个已验证模板),让开源检索进入“所想即所得”时代
更多请点击: https://intelliparadigm.com 第一章:Perplexity GitHub资源检索的范式革命 从关键词匹配到语义理解的跃迁 传统 GitHub 搜索依赖精确的仓库名、文件路径或正则表达式,而 Perplexity 引入的 LLM 驱动检索将自然语言查询&#x…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管
用Arduino实验破解三极管的三大工作状态之谜 记得第一次翻开电子学教材看到三极管章节时,那些密密麻麻的曲线图和公式让我头皮发麻。"截止区"、"放大区"、"饱和区"——这些抽象概念就像天书一样难以理解。直到有一天,我拿…...

Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器
Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器 【免费下载链接】ms-nfs41-client NFSv4.1 Client for Windows 项目地址: https://gitcode.com/gh_mirrors/ms/ms-nfs41-client 想要在Windows系统中像操作本地文件一样访问远程NFS服务器吗&a…...

如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 [特殊字符]
如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 🔥 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mi…...

OpencvSharp 算子学习教案之 - Cv2.Sobel
OpencvSharp 算子学习教案之 - Cv2.Sobel 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因此…...

手把手教你用GD32F303定时器PWM驱动LED,从寄存器配置到CubeMX生成代码
GD32F303定时器PWM开发全攻略:寄存器配置与图形化工具实战对比 在嵌入式开发领域,PWM(脉冲宽度调制)技术如同一位无声的指挥家,精准控制着LED亮度、电机转速等关键参数。对于GD32F303这款高性能ARM Cortex-M4内核微控制…...

PyQt-Fluent-Widgets导航组件深度解析:打造专业级侧边栏与选项卡界面
PyQt-Fluent-Widgets导航组件深度解析:打造专业级侧边栏与选项卡界面 【免费下载链接】PyQt-Fluent-Widgets A fluent design widgets library based on C Qt/PyQt/PySide. Make Qt Great Again. 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Fluent-Widget…...