日志收集笔记(Filebeat 日志收集、Logstash 日志过滤)
1 FileBeat
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。
1.1 FileBeat 安装与使用
从 官网 下载对应的版本,我这里的 ElasticSearch 版本号是 6.4.3,所以下载 FileBeat 的版本也是 6.4.3。
下载后解压:
cd /home/software
tar -zxvf filebeat-6.4.3-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv filebeat-6.4.3-linux-x86_64/ filebeat-6.4.3
配置 Filebeat,可以参考 filebeat.full.yml 中的配置
vim /usr/local/filebeat-6.4.3/filebeat.yml
内容如下:
###################### Filebeat Configuration Example #########################
filebeat.prospectors:- input_type: logpaths:## 定义了日志文件路径,可以采用模糊匹配模式,如*.log- /workspaces/logs/logCollector/app-collector.log#定义写入 ES 时的 _type 值document_type: "app-log"multiline:#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)pattern: '^\[' # 指定匹配的表达式(匹配以 [ 开头的字符串)negate: true # 是否需要匹配到match: after # 不匹配的行,合并到上一行的末尾max_lines: 2000 # 最大的行数timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志fields: ## topic 对应的消息字段或自定义增加的字段logbiz: collectorlogtopic: app-log-collector ## 按服务划分用作kafka topic,会在logstash filter 过滤数据时候作为 判断参数 [fields][logtopic]evn: dev- input_type: logpaths:## 定义了日志文件路径,可以采用模糊匹配模式,如*.log- /workspaces/logs/logCollector/error-collector.log#定义写入 ES 时的 _type 值document_type: "error-log"multiline:#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)pattern: '^\[' # 指定匹配的表达式(匹配以 [ 开头的字符串)negate: true # 是否匹配到match: after # 不匹配的行,合并到上一行的末尾max_lines: 2000 # 最大的行数timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志,直接进行推送操作fields: ## topic 对应的消息字段或自定义增加的字段logbiz: collectorlogtopic: error-log-collector ## 按服务划分用作kafka topicevn: devoutput.kafka: ## filebeat 支持多种输出,支持向 kafka,logstash,elasticsearch 输出数据,此处设置数据输出到 kafka。enabled: true ## 启动这个模块hosts: ["192.168.212.128:9092"] ## 地址topic: '%{[fields.logtopic]}' ## 主题(使用动态变量)partition.hash: ## kafka 分区 hash 规则reachable_only: truecompression: gzip ## 数据压缩max_message_bytes: 1000000 ## 最大容量required_acks: 1 ## 是否需要 ack
logging.to_files: true
检查配置是否正确:
./filebeat -c filebeat.yml -configtest
启动filebeat:
/usr/local/filebeat-6.4.3/filebeat &
注:需要启动 kafka
2 Logstash 日志过滤
在 《Elasticsearch入门笔记(Logstash数据同步)》 这边文章中已经介绍过任何安装配置 Logstash 了,不过那时输入的数据源是来自于 MySQL,此时输入的数据源是 Kafka。
在 /usr/local/logstash-6.4.3 目录下新建一个 script 用于存放对接 Kafka 的配置文件。
以下是该目录下创建的 logstash-script.conf 文件:
## multiline 插件也可以用于其他类似的堆栈式信息,比如 linux 的内核日志。
input {kafka {topics_pattern => "app-log-.*" ## kafka 主题 topicbootstrap_servers => "192.168.212.128:9092" ## kafka 地址codec => json ## 数据格式consumer_threads => 1 ## 增加consumer的并行消费线程数(数值可以设置为 kafka 的分片数)decorate_events => truegroup_id => "app-log-group" ## kafka 组别}kafka {topics_pattern => "error-log-.*" ## kafka 主题 topicbootstrap_servers => "192.168.212.128:9092" ## kafka 地址codec => json ## 数据格式consumer_threads => 1 ## 增加consumer的并行消费线程数(数值可以设置为 kafka 的分片数)decorate_events => truegroup_id => "error-log-group" ## kafka 组别}
}filter {## 时区转换,这里使用 ruby 语言,因为 logstash 本身是东八区的,这个时区比北京时间慢8小时,所以这里采用 ruby 语言设置为北京时区ruby {code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"}## [fields][logtopic] 这个是从 FileBeat 定义传入 Kafka 的if "app-log" in [fields][logtopic]{grok {## 表达式,这里对应的是Springboot输出的日志格式match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]}}## [fields][logtopic] 这个是从 FileBeat 定义传入 Kafka 的if "error-log" in [fields][logtopic]{grok {## 表达式match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]}}
}## 测试输出到控制台:
## 命令行输入 ./logstash -f /usr/local/logstash-6.4.3/script/logstash-script.conf --verbose --debug
output {stdout { codec => rubydebug }
}## elasticsearch:
output {if "app-log" in [fields][logtopic]{## es插件elasticsearch {# es服务地址hosts => ["192.168.212.128:9200"]## 索引名,%{index_time} 是由上面配置的 ruby 脚本定义的日期时间,即每天生成一个索引index => "app-log-%{[fields][logbiz]}-%{index_time}"# 是否嗅探集群ip:一般设置true# 只需要知道一台 elasticsearch 的地址,就可以访问这一台对应的整个 elasticsearch 集群sniffing => true# logstash默认自带一个mapping模板,进行模板覆盖template_overwrite => true}}if "error-log" in [fields][logtopic]{elasticsearch {hosts => ["192.168.212.128:9200"]index => "error-log-%{[fields][logbiz]}-%{index_time}"sniffing => truetemplate_overwrite => true} }
}
查看一下其中的过滤规则,这需要结合 《日志收集笔记(架构设计、Log4j2项目初始化、Lombok)》 文章中的定义日志输出格式一起看:
["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
"message":logstash 固定的格式,统一叫传入的数据为message\[%{NOTSPACE:currentDateTime}\]:匹配[为开头,]为结尾,NOTSPACE表示不能有空格,赋值变量名为currentDateTime\[%{NOTSPACE:level}\]:匹配[为开头,]为结尾,NOTSPACE表示不能有空格,赋值变量名为level,日志级别\[%{NOTSPACE:thread-id}\]:匹配[为开头,]为结尾,NOTSPACE表示不能有空格,赋值变量名为thread-id,线程ID\[%{NOTSPACE:class}\]:匹配[为开头,]为结尾,NOTSPACE表示不能有空格,赋值变量名为class,创建对应logger实例传入的class\[%{DATA:hostName}\]:匹配[为开头,]为结尾,DATA表示数据,可为空,赋值变量名为level,当前应用主机名称\[%{DATA:ip}\]:匹配[为开头,]为结尾,DATA表示数据,可为空,赋值变量名为level,当前应用的 IP\[%{DATA:applicationName}\]:匹配[为开头,]为结尾,DATA表示数据,可为空,赋值变量名为level,当前应用的applicationName\[%{DATA:location}\]:匹配[为开头,]为结尾,DATA表示数据,可为空,赋值变量名为location\[%{DATA:messageInfo}\]:匹配[为开头,]为结尾,DATA表示数据,可为空,赋值变量名为messageInfo,日志输出的自定义内容(\'\'|%{QUOTEDSTRING:throwable}):两个'单引号之间的|表示,之间可为空,不为空就是throwable异常信息
启动 logstash:
/usr/local/logstash-6.4.3/bin/logstash -f /usr/local/logstash-6.4.3/script/logstash-script.conf
## 如果测试时,想要控制台输出日志,输入以下命令
/usr/local/logstash-6.4.3/bin/logstash -f /usr/local/logstash-6.4.3/script/logstash-script.conf --verbose --debug
相关文章:
)
日志收集笔记(Filebeat 日志收集、Logstash 日志过滤)
1 FileBeat Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。 1.1 FileBeat 安装与使用 …...
字节二面,原来是我对自动化测试的理解太浅薄了..
如何使用Python实现自动化测试 如果你入职一家新的公司,领导让你开展自动化测试,作为一个新人,你肯定会手忙脚乱,你会如何落地自动化测试呢?资深测试架构师沉醉将告诉你如何落地自动kan化测试,本次话题主要…...
2023雅虎邮箱不能注册?别急,这份教程教你成功注册雅虎邮箱
这几年,跨境电商的迅猛发展,越来越多人加入这片蓝海,跨境人拥有一个专业的邮箱账户显得尤为重要,它是商业交流和日常工作的必备工具。因此,雅虎邮箱成为了许多人的首选,全球范围内使用雅虎邮箱的人数是非常…...

Elasticsearch 自动补全 completion type
Elasticsearch 自带一种自动补全类型 completion 这种类型不在mapping文档里面有点坑。 先直接上例子。 建立 index,把我们要自动补全的字段设置为 completion 类型 或者直接设置为子类型 PUT /blogs_completion/ {"mappings": {"tech": {"properties…...

GB28181协议实现源码Android源码
一、GB28181规范 尽管在国标GB28181中并没有对“平台”进行明确的定义,但在规范中却多次提到“系统平台”、“管理平台”等词汇,在具体项目中、网络上的交流学习中,平台概念也是无处不在。笔者认为,GB28181平台就是视频联网系统中的上级平台、中间平台或下级平台,用于实现…...

HNU工训中心: 三人表决器及八人抢答器实验报告
工训中心的牛马实验 三人表决器: 实验目的 1) 辨识数字IC功能说明。 2) 测试数字集成门电路,掌握输出故障排除、使用注意事项。 3) 掌握逻辑函数搭建三人表决器。 2.实验资源 HBE硬件基础电路实验箱、万用表 74LS00与非门、74LS10 三个3输入与非门…...
用法注意事项)
split()用法注意事项
split()用法注意事项 这个要注意有些特殊的分割符,比如.,这个表示匹配任何字符,如果在split()中调用的话,会将任何字符都分隔开,比如: String[] split "se.lll".split("."); System…...
centos7配置静态网络常见问题归纳
系列相似配置与安装软件问题整理与归纳文章目录 安装pymysql库_pymysql库安装_张小鱼༒的博客-CSDN博客 解决pip更新的代码_pip更新代码_张小鱼༒的博客-CSDN博客 python当中的第三方wxPython库的安装解答_pip install wx_张小鱼༒的博客-CSDN博客 spark里面配置jdk后的编程…...

产品经理修炼指南【01】
最近看了点产品经理的书,觉得产品经理这个位置和程序员不太一样,程序员唯一考核的标准就是能不能完成工作任务、是否能完成工作代码,但是产品经理貌似不一样,就像我给刘曼说的,产品经理上可以接领导,下可以…...

NCRE计算机等级考试Python真题(十一)
第十一套试题1、以下选项对于import保留字描述错误的是:A.import可以用于导入函数库或者库中的函数B.可以使用from jieba import lcut 引入 jieba库C.使用import jieba as jb,引入函数库jieba,取别名jbD.使用import jieba 引入jieba库正确答案…...

cglib代理解析
工作原理 使用 <dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version></dependency>对类和接口分别进行代理 DemoService package com.fanqiechaodan.user.service;/*** author fa…...

GFD563A101 3BHE046836R0101
GFD563A101 3BHE046836R0101关于高端涂布机张力控制系统方案的介绍高端涂布机张力控制系统方案涂布机是将具有某种功效的胶,或者油墨类物质均匀粘连在塑料薄膜、铝箔、纺织品等表面的机械设备。本系统从放卷到收卷共采用七台变频器,其中收放卷采用闭环张…...
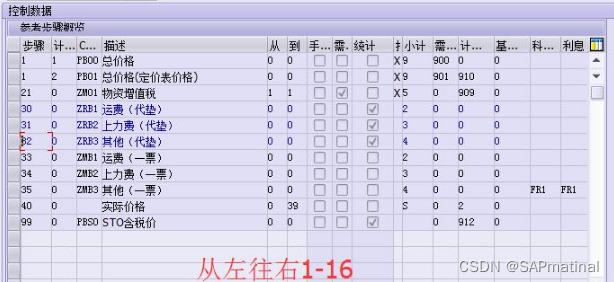
SAP 采购定价过程字段解析
下面我们针对每一个字段进行解释和用途分析 : 1、 步骤:代表了创建PO时,哪个条件类型放到前面,哪个放到后面,如果步骤号相同,那就以谁先选择出来谁就在前面。 2、 计数:没有任何实际意义&a…...
一篇搞懂tcp,http,socket,socket连接池之间的关系
前言 作为一名开发人员我们经常会听到HTTP协议、TCP/IP协议、UDP协议、Socket、Socket长连接、Socket连接池等字眼,然而它们之间的关系、区别及原理并不是所有人都能理解清楚,这篇文章就从网络协议基础开始到Socket连接池,一步一步解释他们之…...

【JavaSE】对象的比较
哈喽,大家好!我是保护小周ღ,本期为大家带来的是Java中自定义类型(对象)的三种比较方式,equals 方法, Comparable 泛型接口, Comparator 泛型接口 。在日常编程中,我们常常会需要比较的问题&…...

Leetcode DAY 49~50:买卖股票的最佳时机 1 2 3 4
121. 买卖股票的最佳时机 1、贪心算法 class Solution { public:int maxProfit(vector<int>& prices) {//贪心int low INT_MAX;int res 0;for(int i 0; i < prices.size(); i) {low min(low, prices[i]); //左最小价格res max(res, prices[i] - low); //当前…...
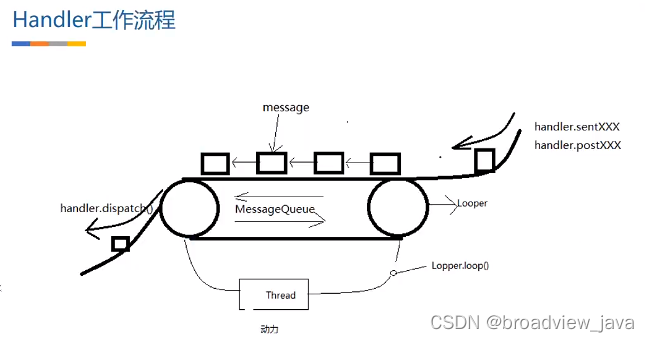
Android Handler机制(二) Handler 实现原理
一. 前言 接上一篇文章为什么设计Handler , 我们来继续讲解一下Handler的实现原理, 俗话说一个好汉三个帮, 接下来一步一步引入各个主角,并说明它们在Handler机制中扮演的角色和作用. 二. Handler实现原理 首先我们先确定一个结论: 使用 Handler 是希望它被实例化在哪个线程&a…...
 详解mapping之keyword)
Elasticsearch教程(19) 详解mapping之keyword
Elasticsearch已升级,新版Elasticsearch keyword博客参考下面这篇【Elasticsearch教程8】Mapping字段类型之keyword_elasticsearch的keyword_亚瑟弹琴的博客-CSDN博客 1 前言 本文基于ES7.6,如果是之前版本,是有区别的。 ES支持的字段类型很…...
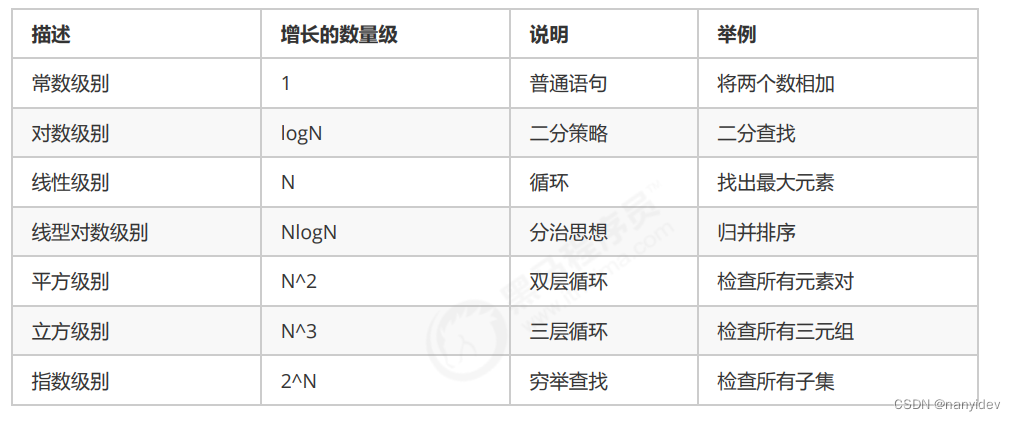
LeetCode算法复杂度分析(时间复杂度空间复杂度)
文章目录前言时间复杂度1.概述2.大O记法3.常见类型空间复杂度1.概述2.常见类型典型算法的复杂度分析1.递归算法2.哈希表前言 我们知道,研究算法的最终目的就是如何花更少的时间,如何占用更少的内存去完成相同的需求。 时间复杂度 1.概述 我们要计算算…...
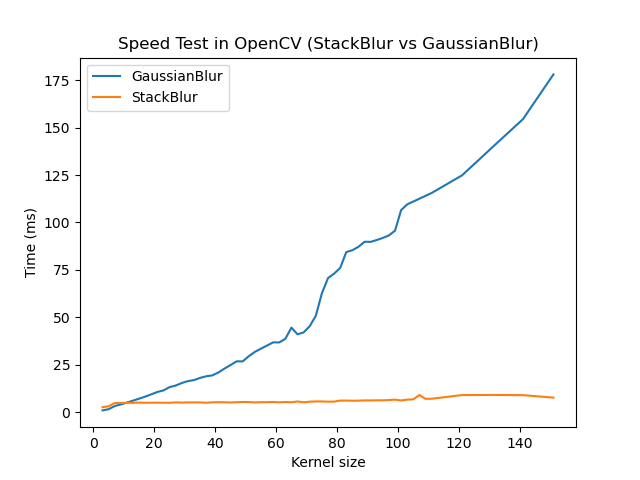
Android OpenCV(七十三):吊打高斯模糊的StackBlur Android 实践
前言 OpenCV 4.7.0 2022年12月28日Release,ChangeLog中提到 Stackblur algorithm implementation. Stackblur是一种高斯模糊的快速近似,由Mario Klingemann发明。其计算耗时不会随着kernel size的增大而增加,专为大kernel size的模糊滤波场景量身定制。 使用建议:当kerne…...

观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现 在开发与测试环境中,虚拟机(VM)是常见的…...
)
分享!关于虚拟机性能优化实战的技术文(进击篇 学习资料自提取)
一、 综述与基础理论类文献 (帮助构建背景和原理部分大纲) 虚拟化技术综述: 查找标题包含“虚拟化技术综述”、“虚拟化原理与发展”等关键词的中文学术论文或书籍章节。这些文献通常会涵盖CPU虚拟化、内存虚拟化、I/O虚拟化等核心技术,为理解性能瓶颈和…...

从DO-178标准演进看多核系统耦合分析:隐式要求显式化与可视化实践
1. 从文学课堂到工程标准:隐式与显式的分野在大学里,我的文学课老师总是不厌其烦地强调“隐式”与“显式”含义的区别。理解这种区别,是读懂一部小说深层隐喻、体会作者言外之意的关键。当时觉得这不过是文学分析的技巧,直到我踏入…...

为什么92%的DeepSeek部署项目在上线30天内遭遇Prompt注入?4个被忽视的配置陷阱全曝光
更多请点击: https://intelliparadigm.com 第一章:DeepSeek prompt注入防护的严峻现实与认知重构 近年来,DeepSeek系列大模型在开源社区广泛部署,但其默认推理接口(如/v1/chat/completions)对用户输入缺乏…...

castAR混合现实头显:从光学投影到空间锚定的技术解析
1. 项目概述:从Kickstarter到技术现实,castAR的独特魅力2013年,当Oculus Rift在虚拟现实领域掀起第一波热潮时,一封来自技术爱好者的邮件,将一个名为castAR的项目推到了我的视野中心。这不仅仅是一个头戴显示设备&…...

C#怎么使用LINQ OrderBy排序 C#如何用LINQ对集合按多个字段进行升序降序排列【语法】
OrderBy必须唯一且首置,后续字段用ThenBy/ThenByDescending链式调用;null默认排最前(升序)或最后(降序);延迟执行,避免重复ToList。OrderBy 和 ThenBy 怎么连用才对多个字段排序不能…...

OpenClaw机械爪MuJoCo仿真沙盒:从算法验证到仿真到现实迁移
1. 项目概述:一个为开源机械爪打造的“数字沙盘”如果你对机器人、开源硬件或者DIY自动化项目感兴趣,最近可能听说过“OpenClaw”这个名字。它是一款设计精巧、成本可控的开源机械爪,社区里不少爱好者都在用它来搭建自己的机器人手臂或者自动…...

Shoelace主题定制终极指南:掌握CSS变量覆盖与扩展技巧的10个秘诀
Shoelace主题定制终极指南:掌握CSS变量覆盖与扩展技巧的10个秘诀 【免费下载链接】shoelace Shoelace is now Web Awesome. Come see what’s new! 项目地址: https://gitcode.com/gh_mirrors/sh/shoelace Shoelace是一个功能强大的Web组件库,现已…...

产品竞争策略方法论:构建“差异化 + 结构化 + 系统化”的竞争优势
目录 一、问题与背景 二、本文将系统讲解 三、产品竞争的本质与底层逻辑 3.1 竞争的本质 3.2 竞争的三层结构(必须理解) 3.3 IoT竞争的特殊性 四、IoT产品竞争结构模型(核心框架) 4.1 五层竞争模型(核心体系) 4.2 竞争演进路径 五、五大竞争策略模型(核心方法…...
)
【AI 越强越离不开工具】:2026 年大模型开发者必备的工具链全景实战(附代码 + 架构图)
前言 目录 前言 一、核心悖论:为什么 AI 越强大,反而越依赖工具? 二、核心拆解:从 Tool 到 Skill 到 Agent,工具链的三层进化逻辑 三、2026 年 AI 工具链全景架构图 四、四大核心工具模块实战(附可直…...