2015年五一杯数学建模C题生态文明建设评价问题解题全过程文档及程序
2015年五一杯数学建模
C题 生态文明建设评价问题
原题再现
随着我国经济的迅速发展,生态文明越来越重要,生态文明建设被提到了一个前所未有的高度。党的十八大报告明确提出要大力推进生态文明建设,报告指出“建设生态文明,是关系人民福祉、关乎民族未来的长远大计。面对资源约束趋紧、环境污染严重、生态系统退化的严峻形势,必须树立尊重自然、顺应自然、保护自然的生态文明理念,把生态文明建设放在突出地位,融入经济建设、政治建设、文化建设、社会建设各方面和全过程,努力建设美丽中国,实现中华民族永续发展”。党的十八届三中全会则进一步明确,建设生态文明,必须建立系统完整的生态文明制度体系。因此对生态文明建设评价体系的研究具有重要意义。
1、请通过查阅相关文献,了解我国生态文明建设的评价指标和评价模型,列举现有的生态文明建设的评价指标。
2、对现有生态文明建设的评价指标进行分析,选择其中几个重要的、可行的评价指标,结合经济发展的情况,建立评价我国生态文明建设状况的数学模型。
3、由于我国地理位置和经济条件的差异,各省(市)生态文明建设水平各有高低,请利用最新的数据,选取最具有代表性的十个省(市),根据前面建立的数学模型对这十个省(市)生态文明建设的程度进行评价。
4、根据上述评价结果,对生态文明建设相对落后的省(市)提出改进措施,建立数学模型预测未来几年这些措施的实施效果,最后请结合预测的结果给有关部门写一份政策建议(1~2 页)
整体求解过程概述(摘要)
本文针对于生态文明建设的评价问题,选取了评价生态建设文明的具有代表性的几个指标,并且通过建立城市生态文明建设指标预测模型,来判断地区生态文明建设程度。
对于第一问,针对我国现有的生态文明建设的评价指标问题,我们首先查阅了全国在省级生态文明建设评价方面较为权威的北京林业大学生态文明研究中心公布的中国省级生态文明建设评价报告,以及其他具体于各地区省市的生态文明建设的论文,在此基础上,列举出来了 6 大类,18 个较为重要的评价指标。
对于第二问,我们首先根据罗列出的指标中的重要程度以及数据获取的可行性和权威性和反映大类指标程度选择了单位 GDP 能耗、单位 GDP 水耗和单位 GDP 废水、废气排放量、绿化覆盖率、人均公共图书藏书量。然后通过熵值法确定了各项指标权重,大致通过三个步骤,分别是原始数据矩阵归一化,定义熵,定义熵权。其次根据国际标准、欧美等发达国家的现状值确定了各项指标的具体度量标准,借助这些度量标准我们通过标准比值法,进一步确定了每一项指标的发展水平指数,最后通过建立的综合评价模型得到我们的最终结果,也就是生态文明建设发展水平指数。为了更好的反映每个省份的情况,我们根据系统发展水平指数值得分范围将发展水平评价等级分为 7 个等级(A 为最优,G 为最差),更加将指标具体化。
对于第三问,首先我们综合考虑了各地区的生态活力,环境质量和经济发展水平,先将全国 31 个省(自治区、直辖市,不含港澳台)的生态文明建设归纳为 5 个类型,然后再加上地理条件的因素综合选择最终确定了河北、山西、山东、四川、北京、辽宁、甘肃、云南、福建和内蒙古十个省市自治区作为我们的研究对象,然后我们通过查阅统计年鉴以及登陆国家统计局下载等方式找到了各个地区从 2009~2013 的权威统计数据,最后带入我们建立的模型之中,通过计算得到了每个地区的生态文明建设发展水平指数。
对于第四问,我们首先根据问题三的评价结果,挑选出了生态文明建设相对落后并具有代表性的云南,在子系统层次,找出制约其生态文明建设的短板,有针对性地提出改进措施。在忽略重大自然突变和措施实施顺利的前提下,针对不同指标,利用灰色预测模型结合 logistic 的方法,外推出改进措施对各项指标的量化影响。将量化后的指标结果,代入到问题二建立的生态文明建设发展水平模型,检验措施实施后的效果。根据结果进一步完善生态文明建设的改进措施,并形成一份高效高可行性的生态文明建设政策建议。
我们建立的城市生态文明建设指标预测模型,与传统的评价相比,虽然在全面性上有所差距,但是简便易行,能够较好的反映地区的生态文明建设程度。
模型假设:
1.假设评价生态文明建设各指标之间相互作用关系忽略不计;
2.假设在预测模型中,未来几年没有重大自然突变;
3.假设从官方获取的各个省份的指标的统计数据信息真实可靠;
4.假设各个省市按照原有进程和规律对生态文明进行建设和发展;
5.假设不受资源环境约束,未来 15 年内各省区生态文明建设按照当前趋势发展,各城市增长率保持相应的速度,考虑到随着高能耗高污染的企业减少,未来资源节约和污染控制各项指标效率难度不断加大的趋势;
问题分析:
对于问题一的分析
对于问题一,主要是让我们在了解现有的生态文明建设的评价指标和模型的基础上,首先列举出对于生态文明建设有影响的各种指标,以便于下面问题的分析。我们首先查阅了全国在省级生态文明建设评价方面较为权威的北京林业大学生态文明研究中心公布的中国省级生态文明建设评价报告,由于北林大生态文明研究中心承担了国家林业局“生态文明建设的评价体系与信息系统技术研究”项目,构建了中国省级生态文明建设评价指标体系(ECCI),它在评价指标和模型建立上有着很好的借鉴意义。除此之外,我们还查阅了具体于地区省市的生态文明建设的论文,在此基础上,列举出来了 18个较为重要的指标。
对于问题二的分析
问题二要求我们选取其中的一些典型的指标,建立评价我国生态文明建设状况的数学模型。首先我们需要选取最具有代表性的几个指标。由于在列举评价指标的时候我们已经对指标进行了初步的分类,所以我们对于每一大类,只在其子系统层中根据其重要程度以及数据的权威性选择了一个或多个指标来反映,我们选择了人均 GDP 来反映经济发展;选择城镇化率来反映社会进步;对于资源节约和环境控制,由于其较为重要,我们分别选取了单位 GDP 能耗、单位 GDP 水耗和单位 GDP 废水、废气排放量两项指标来反映;还选择了绿化覆盖率来反映生态环境;人均公共图书藏书量来反映生态文化。在建立模型时,我们首先需要确定每个指标的权重,确定权重的方法中,较为常用的有熵值法和层次分析法,由于在此次的模型之中,我们的层次较为简单,而且我们的数据都是具体的值,层次分析法不仅增加了过多的计算过程,而且对于结果也可能产生不好的影响,所以我们选择了熵值法来确定权重,主要通过三个步骤,分别是原始数据矩阵归一化;定义熵;定义熵权。最终确定各项指标的权重。其次我们需要建立评价指标度量标准来对我们的结果进行具体的评价。我们查阅了大量的数据,根据国际标准、欧美等发达国家的现状值来确定各项指标的具体度量标准。通过这些度量标准我们通过标准比值法,进一步确定了每一项指标的发展水平指数,然后通过我们建立的综合评价模型最终得到我们的最终结果,也就是生态文明建设发展水平指数。为了更好的反映每个省份的情况,我们根据系统发展水平指数值得分范围将发展水平评价等级分为 7 个等级(A 为最优,G 为最差),更加将指标具体化。
对于问题三的分析
问题三中要求选取最具有代表性的十个省(市),根据前面建立的数学模型对这十个省(市)生态文明建设的程度进行评价。首先要保证选择的十个省(市)具有一定的代表性,能够反映全国的情况,我们依据综合考虑了各地区的地区生态活力,环境质量和各地区的经济发展水平,先将全国 31 个省(自治区、直辖市,不含港澳台)的生态文明建设归纳为 5 个类型,然后再加上地理条件的因素综合选择最终确定了河北、山西、山东、四川、北京、辽宁、甘肃、云南、福建和内蒙古十个省市自治区作为我们的研究对象,然后我们通过查阅统计年鉴以及登陆国家统计局下载等方式找到了各个地区从2009~2013 的权威统计数据,然后带入我们建立的模型之中,通过计算得到了每个地区的生态文明建设发展水平指数。
对于问题四的分析
问题四要求我们对于落后的省份提出改进措施,然后建立数学模型预测未来几年这些措施的实施效果。我们首先根据问题三的评价结果,我们可以挑选出生态文明建设相对落后的省(市),在子系统层次,找出制约其生态文明建设的短板,有针对性地提出改进措施。在忽略重大自然突变和措施实施顺利的前提下,针对不同指标,利用灰色预测模型结合 logistic 的方法,外推出改进措施对各项指标的量化影响。将量化后的指标结果,代入到问题二建立的生态文明建设发展水平模型,检验措施实施后的效果显著性。根据结果进一步完善生态文明建设的改进措施,并形成一份高效高可行性的生态文明建设政策建议。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
clc;
clear;
A=[1 1.2 1.5 1.5;
0.833 1 1.2 1.2;
0.667 0.833 1 1.2;
0.667 0.833 0.833 1];
%因素
对比矩阵 A,只需要改变矩阵 A
[m,n]=size(A); %获取指标个数
RI=[0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51];
R=rank(A); %求判断矩阵的秩
[V,D]=eig(A); %求判断矩阵的特征
值和特征向量,V 特征值,D 特征向量;
tz=max(D);
B=max(tz); %最大特征值
[row, col]=find(D==B); %最大特征值所在位置
C=V(:,col); %对应特征向量
CI=(B-n)/(n-1); %计算一致性检验指标
CI
CR=CI/RI(1,n);
if CR<0.10
disp('CI=');disp(CI);
disp('CR=');disp(CR);
disp('对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:');
Q=zeros(n,1);
for i=1:n
Q(i,1)=C(i,1)/sum(C(:,1)); %特征向量标准化
end
Q %输出
权重向量
else
disp('对比矩阵 A 未通过一致性检验,需对对比矩阵 A 重新构造');
end
CI=
0.0014
CR=
0.0016对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:
Q =
0.3158
0.2579
0.2229
0.2034
>> clear;
>> A=[1 1/3 1/5 1/5
3 1 1/3 1/5
5 3 1 1/3
5 5 3 1];
>> [m,n]=size(A); %获取指标个数
>> RI=[0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51];
>> R=rank(A); %求判断矩阵
的秩
>> [V,D]=eig(A); %求判断矩阵的
特征值和特征向量,V 特征值,D 特征向量;
>> tz=max(D);
>> B=max(tz); %最大特征值
>> [row, col]=find(D==B); %最大特征值所在位置
>> C=V(:,col); %对应特征向
量
>> CI=(B-n)/(n-1); %计算一致性检验
指标 CI
>> CR=CI/RI(1,n);
>> if CR<0.10
disp('CI=');disp(CI);
disp('CR=');disp(CR);
disp('对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:');
Q=zeros(n,1);
for i=1:n
Q(i,1)=C(i,1)/sum(C(:,1)); %特征向量标准化
end
else
disp('对比矩阵 A 未通过一致性检验,需对对比矩阵 A 重新构造');
end
CI=
0.0660
CR=
0.0734
对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:
Q =
0.0636
0.1219
0.2706
0.5439
clc;
clear;
A=[1 1/2 1/3 1/5
2 1 1/4 1/5
3 4 1 1/3
5 5 3 1];
%因素
对比矩阵 A,只需要改变矩阵 A
[m,n]=size(A); %获取指标个数
RI=[0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51];
R=rank(A); %求判断矩阵的秩
[V,D]=eig(A); %求判断矩阵的特征
值和特征向量,V 特征值,D 特征向量;
tz=max(D);
B=max(tz); %最大特征值
[row, col]=find(D==B); %最大特征值所在位置
C=V(:,col); %对应特征向量
CI=(B-n)/(n-1); %计算一致性检验指标
CI
CR=CI/RI(1,n);
if CR<0.10
disp('CI=');disp(CI);
disp('CR=');disp(CR);
disp('对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:');
Q=zeros(n,1);
for i=1:n
Q(i,1)=C(i,1)/sum(C(:,1)); %特征向量标准化
end
Q %输出
权重向量
else
disp('对比矩阵 A 未通过一致性检验,需对对比矩阵 A 重新构造');
end
CI=
0.0540
CR=
0.0600
对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:
Q =
0.0796
0.1061
0.2673
0.5471
clc;
clear;
A=[1 1/2 1/4 1/6
2 1 1/4 1/5
4 4 1 1/2
6 5 2 1];
%因素
对比矩阵 A,只需要改变矩阵 A
[m,n]=size(A); %获取指标个数
RI=[0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51];
R=rank(A); %求判断矩阵的秩
[V,D]=eig(A); %求判断矩阵的特征
值和特征向量,V 特征值,D 特征向量;
tz=max(D);
B=max(tz); %最大特征值
[row, col]=find(D==B); %最大特征值所在位置
C=V(:,col); %对应特征向量
CI=(B-n)/(n-1); %计算一致性检验指标
CI
CR=CI/RI(1,n);
if CR<0.10
disp('CI=');disp(CI);
disp('CR=');disp(CR);
disp('对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:');
Q=zeros(n,1);
for i=1:n
Q(i,1)=C(i,1)/sum(C(:,1)); %特征向量标准化
end
Q %输出
权重向量
else
disp('对比矩阵 A 未通过一致性检验,需对对比矩阵 A 重新构造');
end
CI=
0.0219
CR=
0.0244
对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:
Q =
0.0704
0.1048
0.3122
0.5125
clc;
clear;
A=[1 1/5 1/5 1/3;
5 1 1 3;
5 1 1 3;
3 1/3 1/3 1];
%因素
对比矩阵 A,只需要改变矩阵 A
[m,n]=size(A); %获取指标个数
RI=[0 0 0.58 0.90 1.12 1.24 1.32 1.41 1.45 1.49 1.51];
R=rank(A); %求判断矩阵的秩
[V,D]=eig(A); %求判断矩阵的特征
值和特征向量,V 特征值,D 特征向量;
tz=max(D);
B=max(tz); %最大特征值
[row, col]=find(D==B); %最大特征值所在位置
C=V(:,col); %对应特征向量
CI=(B-n)/(n-1); %计算一致性检验指标
CI
CR=CI/RI(1,n);
if CR<0.10
disp('CI=');disp(CI);
disp('CR=');disp(CR);
disp('对比矩阵 A 通过一致性检验,各向量权重向量 Q 为:');
Q=zeros(n,1);
for i=1:n
Q(i,1)=C(i,1)/sum(C(:,1)); %特征向量标准化
end
Q %输出
权重向量
else
disp('对比矩阵 A 未通过一致性检验,需对对比矩阵 A 重新构造');
end
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2015年五一杯数学建模C题生态文明建设评价问题解题全过程文档及程序
2015年五一杯数学建模 C题 生态文明建设评价问题 原题再现 随着我国经济的迅速发展,生态文明越来越重要,生态文明建设被提到了一个前所未有的高度。党的十八大报告明确提出要大力推进生态文明建设,报告指出“建设生态文明,是关系…...
java:slf4j、log4j、log4j2、logback日志框架的区别与示例
文章目录 背景SLF4J - 简单日志门面:Log4j - 强大而古老的日志框架:Log4j2 - Log4j的升级版:Logback - Log4j的继任者:比较Springboot集成slf4j、log4j2参考 背景 在Java开发中,日志记录是一个不可或缺的组成部分。为了满足不同的需求,Java社区涌现出多…...

Mysql学习查缺补漏----02 mysql之DCL 数据控制语言
查看数据库里都有哪些用户。 使用root任何一个用户都可以登录。 本机登录。 也可以这样登录其他的机器。 、 修改user表。 刷新权限: 现在我们看到了只有本机才能登陆。 我们这样就可以限制这个mysql指定某台服务器登录。 详解忘记密码以及如何修改用户密码 我们…...

【Flink基础】-- 延迟数据的处理
目录 一、关于延迟的一些概念 1、什么是延迟? 2、什么导致互联网延迟?...

通过keepalived+nginx实现 k8s apiserver节点高可用
一、环境准备 K8s 主机配置: 配置: 4Gib 内存/4vCPU/60G 硬盘 网络:机器相互可以通信 k8s 实验环境网络规划: podSubnet(pod 网段) 10.244.0.0/16 serviceSubnet(service 网段): 1…...

JavaScript 数组
JavaScript 数组 用来存储一系列相关数据的一种数据类型 创建数组 字面量方式 ----- [1,2,3,4,5,6];实例化构造函数 ----- new Array(1,2,3,4,5,6);组成数组的元素可以是任意的数据类型包括数组本身; new Array(n): n 表示数组的长度 内容操作 获取(查…...
【数据结构】二叉树的实现
目录 1. 前言2. 二叉树的实现2.1 创建一棵树2.2 前序遍历2.2.1 分析2.2.2 代码实现2.2.3 递归展开图 2.3 中序遍历2.3.1 分析2.3.2 代码实现2.3.3 递归展开图 2.4 后序遍历2.4.1 分析2.4.2 代码实现2.4.3 递归展开图 2.5 求节点个数2.5.1 分析2.5.2 代码实现 2.6 求叶子节点个数…...

振弦采集仪在土体与岩体监测中的可靠性与精度分析
振弦采集仪在土体与岩体监测中的可靠性与精度分析 振弦采集仪是一种用于土体和岩体监测的重要设备,它可以通过测量振动信号来获取土体或岩体的力学参数,如应力、应变、弹性模量等。而振弦采集仪的可靠性和精度是影响其应用效果的关键因素。 首先&#x…...

C语言进阶之路-指针、数组等混合小boss篇
目录 一、学习目标: 二、指针、数组的组合技能 引言 指针数组 语法 数组指针 三、勇士闯关秘籍 四、大杂脍 总结 一、学习目标: 知识点: 明确指针数组的用法和特点掌握数组指针的用法和特点回顾循环等小怪用法和特点 二、指针、数…...

【矩阵论】Chapter 7—Hermite矩阵与正定矩阵知识点总结复习
文章目录 1 Hermite矩阵2 Hermite二次型3 Hermite正定(非负定矩阵)4 矩阵不等式 1 Hermite矩阵 定义 设 A A A为 n n n阶方阵,如果称 A A A为Hermite矩阵,则需满足 A H A A^HA AHA,其中 A H A^H AH表示 A A A的共轭转…...

Golang语言基础之切片
概述 数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性 func arraySum(x [3]int) int{sum : 0for _, v : range x{sum sum v}return sum } 这个求和函数只能接受 [3]int 类型,其他的都不支持。 切片 切片(Slic…...

SpringCloud-服务消费者Fegin调用时无法获取异常信息
一、前言 假设有以下需求: 服务消费者A调用服务提供者B往MySQL新增一条人员信息服务提供者做了一个逻辑判断:若无该人员信息则新增,若已存在该人员信息,则返回给消费者异常状态码及异常信息:“请勿添加重复数据” 问…...
re:invent 2023 Amazon Q 初体验
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre,知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 前言 亚马逊云科技在2023 re:Invent全球大会上宣布推出 Amazon…...
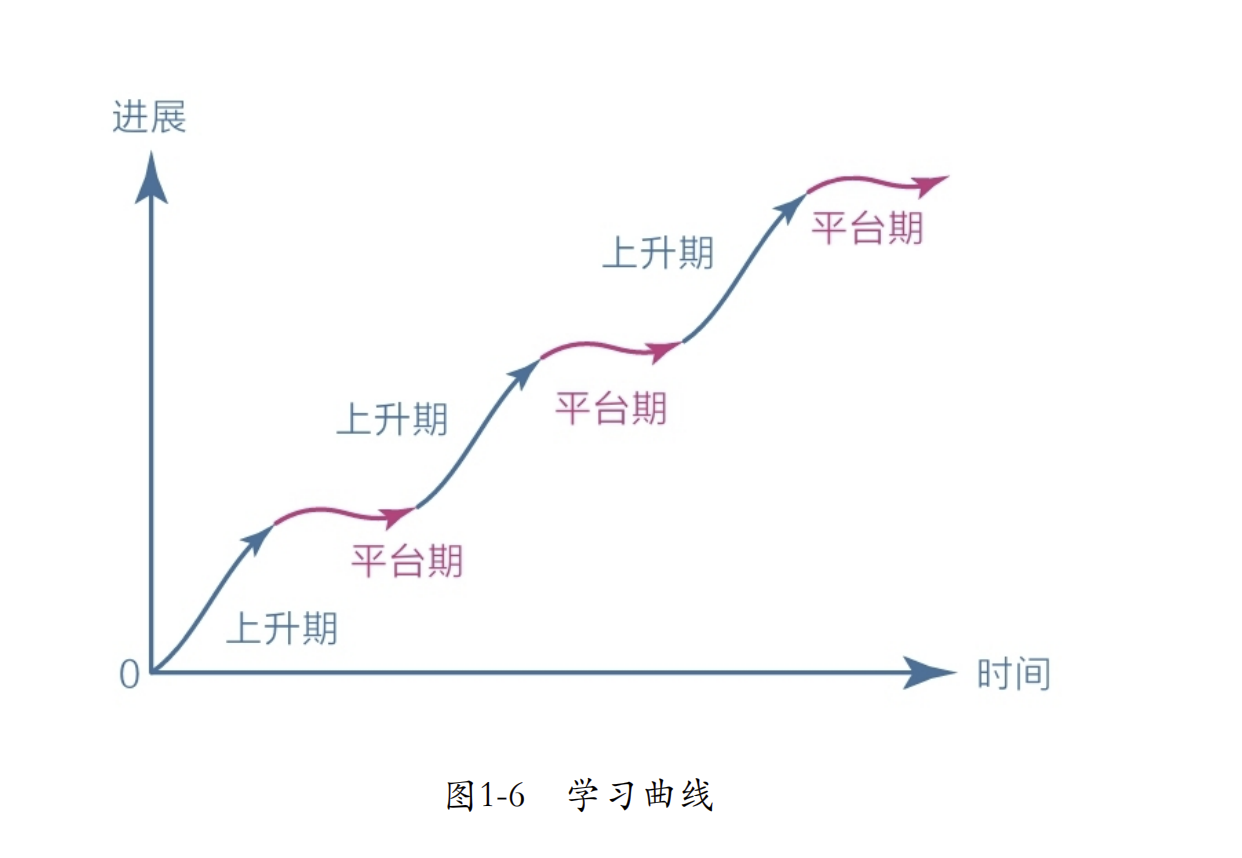
认知觉醒(四)
认知觉醒(四) 第三节 耐心:得耐心者得天下 20世纪八九十年代,金庸的武侠小说风靡全国。如今,虽然几十年过去了,金庸先生也已与世长辞,但他留下的作品依然广受欢迎,被奉为经典。如此成就,自然…...
AI模型部署 | onnxruntime部署YOLOv8分割模型详细教程
本文首发于公众号【DeepDriving】,欢迎关注。 0. 引言 我之前写的文章《基于YOLOv8分割模型实现垃圾识别》介绍了如何使用YOLOv8分割模型来实现垃圾识别,主要是介绍如何用自定义的数据集来训练YOLOv8分割模型。那么训练好的模型该如何部署呢?…...

模拟电路学习笔记(一)之芯片篇(持续更新)
模拟电路学习笔记(一)之芯片篇(持续更新) 1.CD4047BE芯片 CD4047是一种包含高电压的多谐振荡器,该器件的操作可以在两种模式下完成,分别是单稳态和非稳态。CD4047需要一个外部电阻器和电容器来决定单稳态…...

如何利用CentOS7+docker+jenkins+gitee部署springboot+vue前后端项目(保姆教程)
博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。 🍅文末获取源码下载地址🍅 👇🏻 精彩专栏推荐订阅👇🏻…...

qt 5.15.2 主窗体事件及绘制功能
qt 5.15.2 主窗体事件及绘制功能 显示主窗体效果图如下所示: main.cpp #include "mainwindow.h"#include <QApplication>int main(int argc, char *argv[]) {QApplication a(argc, argv);MainWindow w;w.setFixedWidth(600);w.setFixedHeight(6…...

(2)(2.4) TerraRanger Tower/Tower EVO(360度)
文章目录 前言 1 安装传感器并连接 2 通过地面站进行配置 3 参数说明 前言 TeraRanger Tower 可用于在 Loiter 和 AltHold 模式下进行目标规避。传感器的最大可用距离约为 4.5m。 TeraRanger Tower EVO 可用于在 Loiter 和 AltHold 模式下进行目标规避。传感器的最大可用…...

Redis_主从复制、哨兵模式、集群模式详解
Redis的主从复制 为什么Redis要引入主从复制?what? 在这里博主为小伙伴们简单的做下解释,可以了解一下 实际生产环境下,单机的redis服务器是无法满足实际的生产需求的。 第一,单机的redis服务器很容易发生单点故障&am…...
)
从命令行到自动化:用xrandr和shell脚本打造你的Linux多屏工作流(含常见错误排查)
从命令行到自动化:用xrandr和shell脚本打造你的Linux多屏工作流(含常见错误排查) 每天早晨,当我从笔记本单屏切换到办公室的三显示器阵列时,只需按下CtrlAltW,所有显示器就会自动按预设排列亮起——这种流畅…...

Claude Code 工具提示词全拆解:AI Agent、Prompt Engineering、工具调用、上下文工程、自动化编程的底层逻辑
开篇导读很多人做 AI Agent 时,最容易盯着模型参数、系统提示词、工具数量,却忽略了一个非常关键的细节:每一个工具自己的提示词。它看起来只是一个 description 字段,实际上却在悄悄决定模型什么时候用工具、怎样用工具、不能做什…...

【AI面试临阵磨枪-56】大模型服务部署:Docker、K8s、GPU 调度、推理加速
一、 面试题目在生产环境中部署大模型服务时,你是如何结合 Docker 和 K8s 实现高效治理的?特别是在 GPU 调度(如共享、切分) 和 推理加速(如 vLLM, TensorRT-LLM) 方面有哪些实战经验?二、 知识…...

SuperPNG:解决Photoshop PNG导出痛点的高效解决方案
SuperPNG:解决Photoshop PNG导出痛点的高效解决方案 【免费下载链接】SuperPNG SuperPNG plug-in for Photoshop 项目地址: https://gitcode.com/gh_mirrors/su/SuperPNG 你是否曾为Photoshop导出的PNG文件体积过大而烦恼?是否在寻找既能保持图像…...

2026专业灯具照明包装设计公司权威排名榜单推荐:照明产品包装设计首选哲仕设计
2026专业灯具照明包装设计公司权威排名榜单推荐:照明产品包装设计首选哲仕设计灯具照明、灯饰配件属于家装工程通用品类,涵盖家用照明灯具、商业工程灯饰、LED光源、智能照明设备、户外防水灯具、灯饰五金配件等品类。灯饰产品属于易碎光电类产品&#x…...
)
RAG向量存储原理(余弦相似度、欧氏距离、ANN近似最近邻、HNSW原理、混合检索)
文章目录深入理解 RAG 向量存储原理一、什么是 RAG?二、RAG 的核心流程三、什么是向量(Vector)四、Embedding 的本质五、向量空间(Vector Space)六、为什么高维向量能表达语义七、Chunk(文本切块࿰…...

day15 C语言 指针3
13.字符指针的常见错误#include<stdio.h>#if 0int main(int argc, char **argv){//char *p"hello"; //error,会发生段错误 hello在内存中只有一份,只能读取不能修改char p[]"hello"; //char [] 开辟空间,会把hello复制一份给…...

开发者技能图谱工具SkillBrain:构建结构化知识体系与个人技术成长导航
1. 项目概述:一个面向开发者的技能图谱与知识管理工具在技术领域摸爬滚打十几年,我见过太多开发者(包括我自己)都面临一个共同的困境:知识碎片化。今天学个新框架,明天看个新工具,笔记散落在各个…...

AI短剧角色和场景总不一致?用辰入梦 v2.8.0 先固定创作资产
很多 AI 短剧项目卡在模型配置上:剧本、分镜图和视频生成混在一起调,结果每一步都难复现。更稳的方式是把文本模型、图片模型和视频模型分层管理。 文本模型负责剧本结构、角色对白和分集节奏。图片模型用于角色参考、场景设计和 GPT Image-2 导演故事板…...

如何破解Wallpaper Engine资源文件:终极RePKG工具指南
如何破解Wallpaper Engine资源文件:终极RePKG工具指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 想要修改Wallpaper Engine动态壁纸却打不开PKG资源包?…...