论文阅读——Img2LLM(cvpr2023)
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org)
一、介绍
使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练的方法和以语言模型为媒介的VQA。
Multi-modal pretraining:训练一个额外的模块对齐视觉和语言向量。这类方法有两个很大的缺点,一是计算资源大,训练Flamingo需要1536 TPUv4,耗时两周。另外是灾难性遗Catastrophic forgetting. 如果LLM与视觉模型联合训练,则对齐步骤可能对LLM的推理能力不利。
Language-mediated VQA:这种VQA范式直接采用自然语言作为图像的中间表示,不再需要昂贵的预训练,不需要将图片向量化表示。PICa这种方法在few-shot setting中,为图片生成描述,然后从训练样本中选择in-context exemplars范例,但是当没有样本时,其性能会显著下降;另外还有一种方法生成与问题相关的标题。由于零样本的要求,它无法提供上下文中的范例,也无法获得上下文中学习的好处。因此,它必须依赖于特定QA的LLM,UnifiedQAv2,以实现高性能。
以语言为媒介的VQA,模态连接是通过将图片转化为语言描述,而不是稠密向量。任务连接是通过few-shot in-context exemplars或者大模型直接在文本问答上微调。
Img2LLM:本文提出的方法Img2LLM是,为图片生成问答范例,即从当前图像中生成合成的问答对作为上下文示例。也就是这些示例不仅演示了QA任务,而且还将图像的内容传达给LLM以回答问题Q。
三种方式比较:
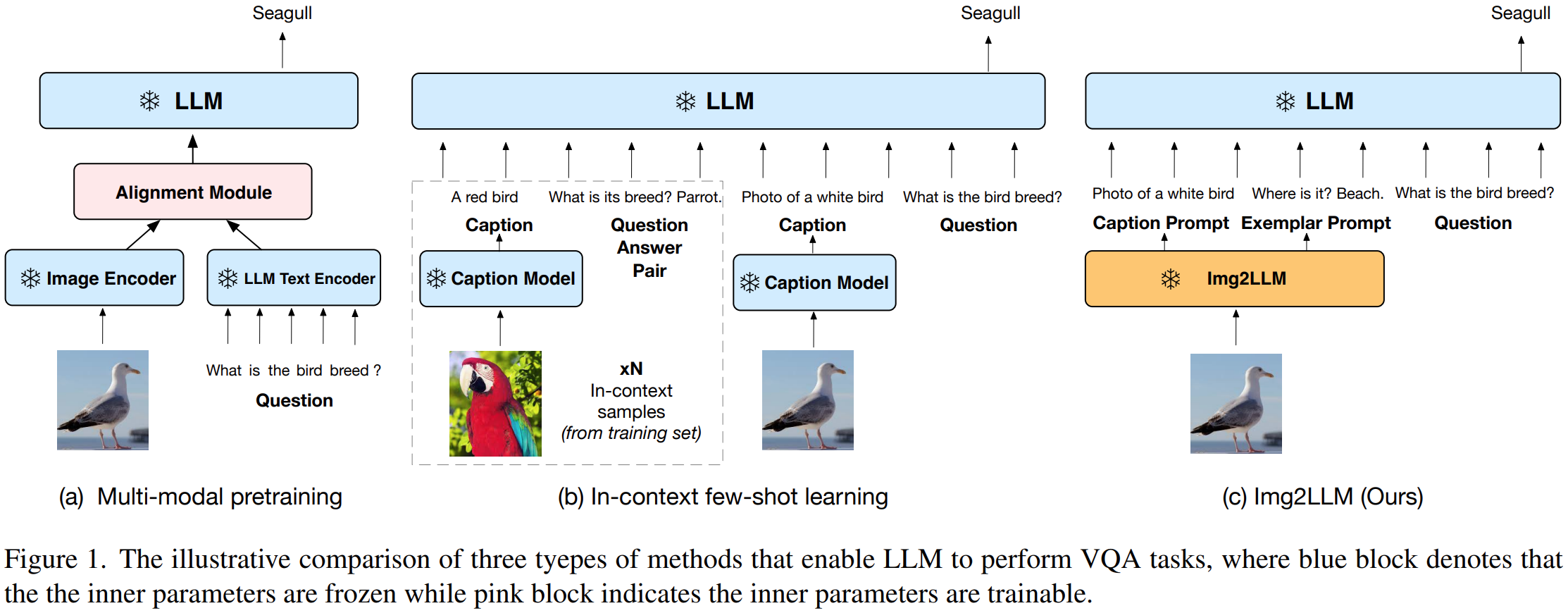
二、Method

1. Answer Extraction
寻找可以作为合成问题答案的单词。方法是,使用现成的描述模块生成图片描述,然后从里面提取候选答案。提取时,提取名词短语(包括命名实体)、动词短语、形容词短语、数字和布尔型单词(如“是”和“否”)作为候选答案。
2. Question Generation
有了候选答案后可以使用现成的任意的问题生成模型为每一个候选答案生成具体的问题。
生成问题有两中方式:基于模板的方式和基于神经网络的方式。
Template-based Question Generation
For example, for answers that are nouns, we use the question “What object is in this image?” For verb answers, we use the question “What action is being taken in this image?
就是有个模板,然后填文本,生成问题。
Neural Question Generation
微调一个T5-large模型从答案里面产生问题。
training 输入:“Answer: [answer]. Context: [context]”,[answer] denotes the answer text,[context] denotes the context text from textual QA datasets。
inference:replace [answer] with an extracted answer candidate and [context] with the generated caption from which the answer was extracted.
在5个textual QA数据集上训练:SQuAD2.0, MultiRC, BookQA, Common-senseQA and Social IQA
有一个prompt组成的对比数据:

3. Question-relevant Caption Prompt
除了合成的QA对,和问题相关的图片描述也会输入模型。
问的问题可能会询问图像中的特定对象或区域,但现有网络生成的通用描述可能不包含相关信息。比如,在图2中,“什么东西在后台旋转,可以用来控制电力?”这个问题只与风力涡轮机有关。然而,从整个图像中生成的描述可能会集中在突出或倾斜的船上,使LLM没有信息来回答这个问题。为了解决这个问题,我们生成关于图像中与问题相关的部分的标题,并将其包含在LLM的提示中。
那么,怎么做到生成关于图像中与问题相关的部分的标题?使用了两个模型:Imagegrounded Text Encoder (ITE) in BLIP,GradCAM。ITE可以计算图片和问题的相似度,GradCAM可以生成一个粗略的定位图,突出显示给定问题的匹配图像区域。得到每个块和问题的相关度之后,根据概率采样一些图像块,然后为每个图像块生成图像描述。但是由于采样的不确定性,图片描述模型可能会生成对性能有负面影响的噪声字幕。为了去除有噪声的字幕,我们使用ITE来计算生成的字幕和采样的问题相关图像补丁之间的相似性得分,并过滤匹配得分小于0.5的字幕。总的来说,这个过程产生了与问题相关的、多样化的、干净的合成字幕,在视觉和语言信息之间架起了一座桥梁。
4. Prompt Design
到现在为止,合成了QA对question-answer pairs,图片描述question-relevant captions。
把这些instruction, captions, and QA exemplars拼接concatenate成一个完整的prompt。
instruction:“Please reason the answers of question according to the contexts.”
Contexts:[all captions]
Question:[question] Answer: [answer]
最后一个要问的问题放到最后,不写答案:
Question: [question]. Answer:
因为LM有输入字数的限制,所以生成的这些答案】描述不能都输进去。所以有一些答案、描述选择策略。为了选择信息量最大的提示,我们首先统计100个生成的字幕中合成答案候选者的频率。然后,我们选择30个频率最高的候选答案,并为每个答案生成一个问题。此外,我们还包括30个频率最低的答案和一个包含每个答案的标题。
三、实验部分
use BLIP to generate captions and perform image-question matching.
To localize the image regions relevant to the question, we generate GradCam from the cross-attention layer of BLIP image-grounded text encoder. Then sample K′ = 20 image patches based on GradCam, and use them to obtain 100 question-relevant captions.
LLMs:opensource OPT model with multiple different sizes.
四、其他


相关文章:
论文阅读——Img2LLM(cvpr2023)
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org) 一、介绍 使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练…...

南京大学考研机试题DP
3. dp 求子序列的个数 https://www.acwing.com/problem/content/description/3716/ #include <iostream> #include <cstring> #include <algorithm> #include <unordered_set> #include <vector> using namespace std; const int N 1e4 10…...

如何进行多ip服务器租用?
如何进行多ip服务器租用? 对于网络时代来说,是需要很多设备才能维持的,比如说多ip服务器就是互联网时代常见的设备,所以我们需要对多ip服务器有足够的了解,这样才能更好的获取互联网上的信息,满足我们工作…...

(动手学习深度学习)第13章 实战kaggle竞赛:树叶分类
文章目录 实战kaggle比赛:树叶分类1. 导入相关库2. 查看数据格式3. 制作数据集4. 数据可视化5. 定义网络模型6. 定义超参数7. 训练模型8. 测试并提交文件 竞赛技术总结1. 技术分析2. 数据方面模型方面3. AutoGluon4. 总结 实战kaggle比赛:树叶分类 kagg…...

vue中shift+alt+f格式化防止格式掉其它内容
好处就是使得提交记录干净,否则修改一两行代码,习惯性按了一下格式化快捷键,遍地飘红,下次找修改就费时间 1.点击设置图标-设置 2.点击这个转成配置文件 {"extensions.ignoreRecommendations": true,"[vue]":…...
WPS导出的PDF比较糊,和原始的不太一样,将带有SVG的文档输出为PDF
一、在WPS的PPT中 你直接输出PDF可能会导致一些问题(比如照片比原来糊)/ 或者你复制PPT中的图片到AI中类似的操作,得到的照片比原来糊,所以应该选择打印-->高级打印 然后再另存为PDF 最后再使用AI打开PDF文件再复制到你想用…...

Linux /etc/hosts文件
Linux的 /etc/hosts 文件用于静态地映射主机名到 IP 地址。 通常用于本地网络中的名称解析,它可以覆盖 DNS 的设置。当你访问一个域名时,系统会首先检查 /etc/hosts 文件,如果找到了匹配项,就会使用该 IP 地址,否则会…...
webpack学习-3.管理输出
webpack学习-3.管理输出 1.简单练手2.设置 HtmlWebpackPlugin3.清理 /dist 文件夹4.manifest5.总结 1.简单练手 官网的第一个预先准备,是多入口的。 const path require(path);module.exports {entry: {index: ./src/index.js,print: ./src/print.js,},output: …...

【Go语言反射reflect】
Go语言反射reflect 一、引入 先看官方Doc中Rob Pike给出的关于反射的定义: Reflection in computing is the ability of a program to examine its own structure, particularly through types; it’s a form of metaprogramming. It’s also a great source of …...

LC-1466. 重新规划路线(DFS、BFS)
1466. 重新规划路线 中等 n 座城市,从 0 到 n-1 编号,其间共有 n-1 条路线。因此,要想在两座不同城市之间旅行只有唯一一条路线可供选择(路线网形成一颗树)。去年,交通运输部决定重新规划路线,…...
自动数据增广论文笔记 | AutoAugment: Learning Augmentation Strategies from Data
谷歌大脑出品 paper: https://arxiv.org/abs/1805.09501 这里是个论文的阅读心得,笔记,不等同论文全部内容 文章目录 一、摘要1.1 翻译1.2 笔记 二、(第3部分)自动增强:直接在感兴趣的数据集上搜索最佳增强策略2.1 翻译2.2 笔记 三、跳出论文,…...

CTF 7
信息收集 存活主机探测 arp-scan -l 端口探测 nmap -sT --min-rate 10000 -p- 192.168.0.5 服务版本等信息 nmap -sT -sV -sC -O -p22,80,137,138,139,901,5900,8080,10000 192.168.0.5Starting Nmap 7.94 ( https://nmap.org ) at 2023-11-02 21:23 CST Stats: 0:01:30 elaps…...

无公网IP环境Windows系统使用VNC远程连接Deepin桌面
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...

java--枚举
1.枚举 枚举是一种特殊类 2.枚举类的格式 注意: ①枚举类中的第一行,只能写一些合法的标识符(名称),多个名称用逗号隔开。 ②这些名称,本质是常量,每个常量都会记住枚举类的一个对象。 3.枚举类的特点 ①枚举类的…...

JVM垃圾回收机制GC
一句话介绍GC: 自动释放不再使用的内存 一、判断对象是否能回收 思路一:引用计数 给这个对象里安排一个计数器, 每次有引用指向它, 就把计数器1, 每次引用被销毁,计数器-1,当计数器为0的时候…...

详解JAVA中的@ApiModel和@ApiModelProperty注解
目录 前言1. ApiModel注解2. ApiModelProperty注解3. 实战 前言 在Java中,ApiModel和ApiModelProperty是Swagger框架(用于API文档的工具)提供的注解,用于增强API文档的生成和展示。这两者搭配使用更佳 使用两者注解,…...
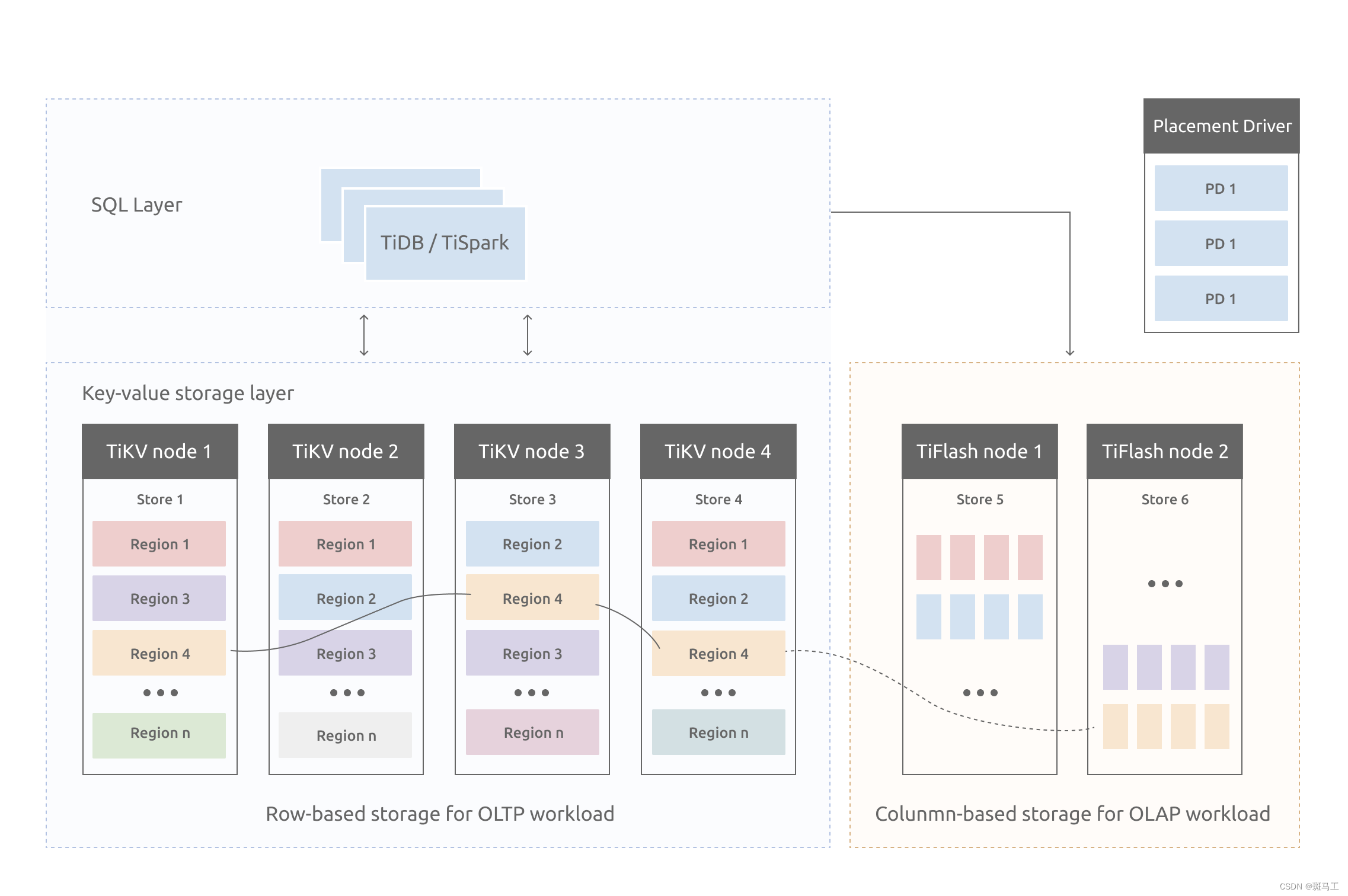
TiDB专题---2、TiDB整体架构和应用场景
上个章节我们讲解了TiDB的发展和特性,这节我们讲下TiDB具体的架构和应用场景。首先我们回顾下TiDB的优势。 TiDB的优势 与传统的单机数据库相比,TiDB 具有以下优势: 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容…...
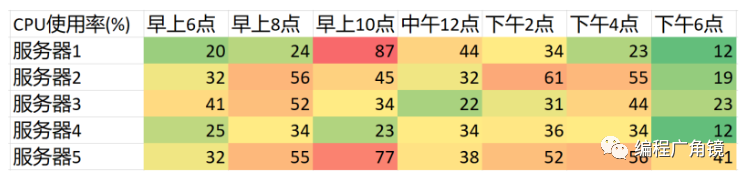
性能调优入门
从公众号转载,关注微信公众号掌握更多技术动态 --------------------------------------------------------------- 一、性能定律和数理基础 1.三个定律法则 (1)帕累托法则 我它也被称为 80/20 法则、关键少数法则,或者八二法则。人们在生活中发现很多…...

JavaWeb | 验证码 、 文件的“上传”与“下载”
目录: 验证码 和 文件的“上传”与“下载”1.验证码1.1在JSP上开发验证码 2.“文件上传” 和 “文件下载”2.1“文件上传 ”2.2“文件下载” 验证码 和 文件的“上传”与“下载” 1.验证码 验证码:就是由服务器生成的一串随机数字或符号形成一幅图片&am…...

服务器感染了.halo勒索病毒,如何确保数据文件完整恢复?
导言: 随着科技的不断发展,网络安全问题日益突出,而.halo勒索病毒正是这个数字时代的一大威胁。本文将深入介绍.halo勒索病毒的特点,解释在受到攻击后如何有效恢复被加密的数据文件,并提供一些建议以预防未来可能的威…...

不用登录!3 步把 Excel 进度表变成甘特图
很多团队并不是缺项目管理工具,而是缺时间:领导下午要进度图,表格还在同事电脑里,甘特图只能熬夜手画。PJMan 提供了一条「先出图、再决策」的轻路径:免登录 Excel 一键可视化。 为什么值得试? 零注册门槛&…...
)
NotebookLM智能摘要失效真相(附Google内部测试报告·仅限本期公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM智能摘要失效的底层归因分析 NotebookLM 的智能摘要功能在部分场景下出现语义断裂、关键信息遗漏或摘要长度异常(如仅输出“…”),其根本原因并非模型随机…...

保利商旅诺雅品牌首作,长沙保利橘洲诺雅酒店开业
美通社消息:5月15日,由保利发展湖南公司投资兴建、保利商旅产业发展有限公司运营管理的豪华城市度假品牌——诺雅(ORYARD)首店:长沙保利橘洲诺雅酒店,于湘江之畔正式盛大开业。该项目自2026年2月试营业以来,历经数月的…...

给单片机新手的福利:拆解一个经典的篮球计分器项目,附Keil C代码逐行分析
51单片机篮球计分器项目深度解析:从状态机设计到数码管驱动实战 当你第一次拿到一个完整的单片机项目源码时,是否曾被那些看似复杂的函数调用和中断处理搞得一头雾水?本文将带你深入剖析一个经典的篮球计分器项目,不仅理解每行代…...

终极HiveWE魔兽地图编辑器:从新手到高手的完整指南
终极HiveWE魔兽地图编辑器:从新手到高手的完整指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器缓慢的加载速度和繁琐的操作而烦恼吗?HiveWE魔兽…...

iOS激活锁完美绕过:AppleRa1n完整教程与操作指南
iOS激活锁完美绕过:AppleRa1n完整教程与操作指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 如果您正面临iPhone设备被激活锁困扰的困境,这篇AppleRa1n完整指南将为您提供专…...

PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码
PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码 【免费下载链接】pyinstxtractor PyInstaller Extractor 项目地址: https://gitcode.com/gh_mirrors/py/pyinstxtractor 你是否曾经面对一个PyInstaller打包的可执行文件,想要查看其中…...

NotebookLM脑机接口安全红线清单,3类合规风险已致2家医疗AI公司终止临床试验
更多请点击: https://intelliparadigm.com 第一章:NotebookLM脑机接口研究 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,其核心能力在于语义锚定(semantic grounding)与多源文档交叉推…...
)
STM32驱动段码屏实战:手把手教你用HT1621B做个简易电子钟(附完整代码)
STM32与HT1621B打造高精度电子钟:从硬件连接到动态显示全解析 在嵌入式开发领域,能够将理论知识转化为实际项目的能力至关重要。本文将带您完成一个完整的电子钟项目,使用STM32微控制器和HT1621B驱动器来驱动段码液晶屏。不同于简单的驱动演示…...

在Windows上直接安装APK的完整指南:告别模拟器时代
在Windows上直接安装APK的完整指南:告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过,在Windows电脑上直接运行Andro…...