时间序列预测实战(二十五)PyTorch实现Seq2Seq进行多元和单元预测(附代码+数据集+完整解析)
一、本文介绍
本文给大家带来的时间序列模型是Seq2Seq,这个概念相信大家都不陌生了,网上的讲解已经满天飞了,但是本文给大家带来的是我在Seq2Seq思想上开发的一个模型和新的架构,架构前面的文章已经说过很多次了,其是专门为新手开发的,而且为了方便大家使用只定义了一个文件方便大家复制粘贴,架构功能包括:结果可视化、支持单元预测、多元预测、模型拟合效果检测、预测未知数据、以及滚动长期预测功能。Seq2Seq模型是一种处理序列数据的深度学习模型,广泛用于机器翻译、语音识别和文本摘要等任务(也能用于时间序列)。其核心思想是编码器-解码器。
需要注意得是本文的模型和结构均为自研,在Seq2Seq的思想上进行了一定的扩展。
专栏目录:时间序列预测目录:深度学习、机器学习、融合模型、创新模型实战案例
专栏: 时间序列预测专栏:基础知识+数据分析+机器学习+深度学习+Transformer+创新模型
预测功能效果展示(不是测试集是预测未知数据,所以图中没有对比的数据)->
损失截图(损失这里我先展示一个训练过程中的后面会自动生成损失图像)->
根据损失来看模型的拟合效果还是很好的,但后面还是做了检验模型拟合效果的功能让大家真正的评估模型的效果。

测试集状况->
这个结构是我发这么多基础模型里效果最好的,模型拟合和测试集表现均为最好。

目录
一、本文介绍
二、Seq2Seq思想原理
2.1 Seq2Seq的基本原理
2.1.1 编码器-解码器介绍
2.1.2 编码器-解码器结构图
三、数据集介绍
四、参数讲解
五、完整代码
六、训练模型
七、预测结果
7.1 预测未知数据效果图
7.2 测试集效果图
7.3 CSV文件生成效果图
7.4 检验模型拟合效果图
八、全文总结
二、Seq2Seq思想原理

2.1 Seq2Seq的基本原理
Seq2Seq(Sequence-to-Sequence)模型是一种处理序列数据的深度学习模型,广泛用于机器翻译、语音识别和文本摘要等任务。其核心思想是将一个序列(如一句话)转换成另一个序列,这两个序列的长度可以不同。
Seq2Seq模型主要包括以下几个机制和原理:
1. 编码器-解码器架构:Seq2Seq模型通常由两部分组成,编码器和解码器。编码器负责读取并理解输入序列,将其转换成一个固定长度的上下文向量(context vector)。解码器则利用这个上下文向量生成目标序列(其实最核心的就是这个,下面都是具体的应用了)。
2. 循环神经网络(RNN):在传统的Seq2Seq模型中,编码器和解码器通常是循环神经网络(如LSTM或GRU)。RNN可以处理不同长度的输入序列,并在其隐藏层保持序列的状态信息。
3.注意力机制(Attention):注意力机制是后来引入Seq2Seq模型的一项重要改进。它允许模型在生成每个目标词时“关注”输入序列的不同部分,从而提高了模型处理长句子时的效果和准确性。
4. 长短期记忆网络(LSTM)/门控循环单元(GRU):为了解决RNN中的长期依赖问题,LSTM和GRU这样的网络结构被引入。它们能更好地捕捉序列中的长期依赖关系。
个人总结:我个人觉得Seq2Seq模型就像是学习语言的人。首先通过“编码器”理解输入的句子,然后用“解码器”来表达新的句子。就像我们学外语时先理解一句话的意思,再用自己的语言表达出来。加上“注意力机制”,模型还能更聪明地关注输入句子中最重要的部分,就好比我们在听别人说话时会注意对方重点强调的内容。
2.1.1 编码器-解码器介绍
通过上面我们知道Seq2Seq的主要核心思想是编码器和解码器,Seq2Seq一开始被发明出来是用于一些本文处理的,但是本文是时间序列领域的文章,所以我主要讲解一下编码器-解码器在时间序列领域的应用(大家需要注意的是这里的编码器和解码器和Transformer当中的还不一样是有着根本的区别的)。Seq2Seq模型的编码器和解码器如下工作:
编码器在时间序列领域的作用是理解和编码输入序列的历史数据。
1. 处理时间序列输入:编码器接收时间序列数据,例如过去几天的股票价格或气温记录。这些数据通常是连续的数值。
2. 特征提取:通过RNN(本文是用的GRU,类似于LSTM和RNN以后也会单独出文章)网络,编码器可以捕捉时间序列的特征和内在模式。RNN通过其时间递归结构,有效地处理时间序列数据中的时序依赖关系。
3. 上下文向量:编码器输出一个上下文向量,该向量是输入时间序列的压缩表示,包含了对过去数据的理解和总结。
解码器在时间序列领域的作用是基于编码器提供的信息来预测未来的时间序列数据。
1. 初始状态和输入:解码器的初始状态通常由编码器的最终状态设置。解码器的第一个输入可能是序列的最后一个观测值或特殊标记(我设置为解码器的输入是编码器的最后一个输出,因为我觉得这个状态的过去信息是最足的)。
2. 逐步预测:在每个时间步,解码器基于当前状态和前一步的预测输出(或初始输入)来生成下一个时间点的预测值。
3. 迭代更新:解码器的输出用于更新其状态,并作为下一个时间步的输入。这个过程在生成整个预测序列期间重复进行。
4. 序列生成:这个过程持续进行,直到生成了预定长度的预测序列。
总结:在时间序列领域,Seq2Seq模型的编码器-解码器结构使其能够有效处理具有复杂时间依赖性的序列数据。编码器学习并压缩历史数据的关键信息,而解码器则利用这些信息来预测未来的趋势和模式。
2.1.2 编码器-解码器结构图
下面的图是我编码器-解码器的结构图,其中包含了编码器(Encoder)和解码器(Decoder)的具体实现细节(需要注意的是这个图和本文模型无关,这里举出来只是为了让大家对编码器和解码器的流程有一个更清晰的认知)。下面是对这个图示的详细解释:
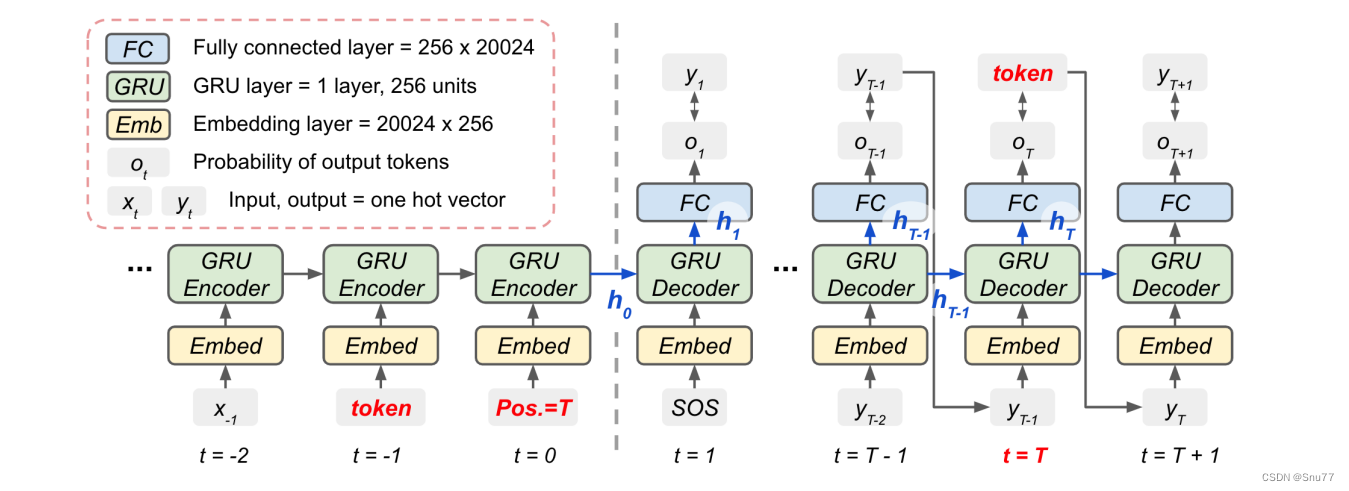
编码器部分(左侧)
-
嵌入层(Embed):这个层将输入的一热编码(one-hot vector)转换为嵌入向量。在此图中,嵌入层将每个输入token转换为一个256维的向量。
-
GRU层:门控循环单元(Gated Recurrent Unit,GRU)是RNN的一种变体,可以捕捉长期依赖关系,同时缓解了传统RNN的梯度消失问题。在此模型中,每个时间步的GRU层接收前一时间步的隐藏状态和当前时间步的嵌入向量,然后输出新的隐藏状态。
-
时间步(t):时间步是序列中的位置指示,从t=−2开始,直至t=0,表示输入序列的处理进程。
-
位置标记(Pos. = T):这可能表示当前处理的token位于输入序列的最后一个位置,意味着编码器即将完成对输入序列的处理。
解码器部分(右侧)
-
嵌入层:解码器的嵌入层将一热编码的输出token转换为嵌入向量。
-
GRU层:解码器的GRU层接收来自上一时间步的隐藏状态和当前时间步的嵌入向量(或初始状态从编码器传来的上下文向量),然后输出新的隐藏状态。
-
全连接层:在每个时间步,全连接层将GRU的输出转换为词汇表大小的向量,这个向量包含了输出序列中下一个token的概率分布。
-
输出概率:这是解码器产生的,表示下一个可能输出token的概率分布。
-
SOS:这是“Start of Sequence”的缩写,表示解码器开始生成序列的信号。
-
时间步(t):在解码器部分,时间步从t=1开始,直至t=T+1,其中T可能表示目标序列的长度。
整个过程是这样的:编码器读取输入序列的token,并逐个更新其隐藏状态。当编码器读取完所有的输入token后,最后的隐藏状态(ℎ0)被传递到解码器作为其初始状态。解码器从一个特殊的SOS token开始,逐步生成输出序列的token。在每一步,解码器基于当前的隐藏状态和上一步产生的token,预测下一个token,直到生成EOS token,表示序列生成结束。
概念部分的就讲这么多,网上有很多概念理解的好博客,大家有兴趣都可以自己查找看看,本文是实战博客内容不多讲啦~
三、数据集介绍
本文是实战讲解文章,上面主要是简单讲解了一下网络结构比较具体的流程还是很复杂的涉及到很多的数学计算,下面我们来讲一讲模型的实战内容,第一部分是我利用的数据集。
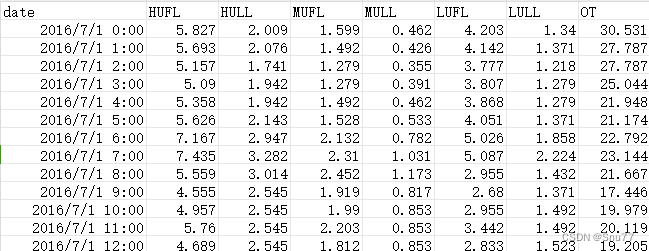
本文我们用到的数据集是ETTh1.csv,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
parser.add_argument('-model', type=str, default='RNN', help="模型持续更新")parser.add_argument('-window_size', type=int, default=126, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-feature', type=str, default='M', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=16, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden_size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel_sizes', type=int, default=3)parser.add_argument('-laryer_num', type=int, default=2)# deviceparser.add_argument('-use_gpu', type=bool, default=True)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-test', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)为了大家方便理解,文章中的参数设置我都用的中文,所以大家应该能够更好的理解。下面我在进行一遍讲解。
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 1 | model | str | 模型名称 |
| 2 | window_size | int | 时间窗口大小,用多少条数据去预测未来的数据 |
| 3 | pre_len | int | 预测多少条未来的数据 |
| 4 | shuffle | store_true | 是否打乱输入dataloader中的数据,不是数据的顺序 |
| 5 | data_path | str | 你输入数据的地址 |
| 6 | target | str | 你想要预测的特征列 |
| 7 | input_size | int | 输入的特征数不包含时间那一列!!! |
| 8 | feature | str | [M, S, MS],多元预测多元,单元预测单元,多元预测单元 |
| 9 | lr | float | 学习率大小 |
| 10 | drop_out | float | 丢弃概率 |
| 11 | epochs | int | 训练轮次 |
| 12 | batch_size | int | 批次大小 |
| 13 | svae_path | str | 模型的保存路径 |
| 14 | hidden_size | int | 隐藏层大小 |
| 15 | kernel_size | int | 卷积核大小 |
| 16 | layer_num | int | lstm层数 |
| 17 | use_gpu | bool | 是否使用GPU |
| 18 | device | int | GPU编号 |
| 19 | train | bool | 是否进行训练 |
| 20 | predict | bool | 是否进行预测 |
| 21 | inspect_fit | bool | 是否进行检验模型 |
| 22 | lr_schduler | bool | 是否使用学习率计划 |
五、完整代码
复制粘贴到一个文件下并且按照上面的从参数讲解配置好参数即可运行~(极其适合新手和刚入门的读者)
import argparse
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from tqdm import tqdm
import torch.nn.functional as F# 随机数种子
np.random.seed(0)class StandardScaler():def __init__(self):self.mean = 0.self.std = 1.def fit(self, data):self.mean = data.mean(0)self.std = data.std(0)def transform(self, data):mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.meanstd = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.stdreturn (data - mean) / stddef inverse_transform(self, data):mean = torch.from_numpy(self.mean).type_as(data).to(data.device) if torch.is_tensor(data) else self.meanstd = torch.from_numpy(self.std).type_as(data).to(data.device) if torch.is_tensor(data) else self.stdif data.shape[-1] != mean.shape[-1]:mean = mean[-1:]std = std[-1:]return (data * std) + meandef plot_loss_data(data):# 使用Matplotlib绘制线图plt.figure()plt.figure(figsize=(10, 5))plt.plot(data, marker='o')# 添加标题plt.title("loss results Plot")# 显示图例plt.legend(["Loss"])plt.show()class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def create_inout_sequences(input_data, tw, pre_len, config):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + pre_len) > len(input_data):breakif config.feature == 'MS':train_label = input_data[:, -1:][i + tw:i + tw + pre_len]else:train_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seqdef calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return maedef create_dataloader(config, device):print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列pre_len = config.pre_len # 预测未来数据的长度train_window = config.window_size # 观测窗口# 将特征列移到末尾target_data = df[[config.target]]df = df.drop(config.target, axis=1)df = pd.concat((df, target_data), axis=1)cols_data = df.columns[1:]df_data = df[cols_data]# 这里加一些数据的预处理, 最后需要的格式是pd.seriestrue_data = df_data.values# 定义标准化优化器scaler = StandardScaler()scaler.fit(true_data)train_data = true_data[int(0.3 * len(true_data)):]valid_data = true_data[int(0.15 * len(true_data)):int(0.30 * len(true_data))]test_data = true_data[:int(0.15 * len(true_data))]print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))# 进行标准化处理train_data_normalized = scaler.transform(train_data)test_data_normalized = scaler.transform(test_data)valid_data_normalized = scaler.transform(valid_data)# 转化为深度学习模型需要的类型Tensortrain_data_normalized = torch.FloatTensor(train_data_normalized).to(device)test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)# 定义训练器的的输入train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len, config)test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len, config)valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len, config)# 创建数据集train_dataset = TimeSeriesDataset(train_inout_seq)test_dataset = TimeSeriesDataset(test_inout_seq)valid_dataset = TimeSeriesDataset(valid_inout_seq)# 创建 DataLoadertrain_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)print("通过滑动窗口共有训练集数据:", len(train_inout_seq), "转化为批次数据:", len(train_loader))print("通过滑动窗口共有测试集数据:", len(test_inout_seq), "转化为批次数据:", len(test_loader))print("通过滑动窗口共有验证集数据:", len(valid_inout_seq), "转化为批次数据:", len(valid_loader))print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")return train_loader, test_loader, valid_loader, scalerclass RNNEncoder(nn.Module):def __init__(self, rnn_num_layers=1, input_feature_len=1, sequence_len=168, hidden_size=100, bidirectional=False):super().__init__()self.sequence_len = sequence_lenself.hidden_size = hidden_sizeself.input_feature_len = input_feature_lenself.num_layers = rnn_num_layersself.rnn_directions = 2 if bidirectional else 1self.gru = nn.GRU(num_layers=rnn_num_layers,input_size=input_feature_len,hidden_size=hidden_size,batch_first=True,bidirectional=bidirectional)def forward(self, input_seq):ht = torch.zeros(self.num_layers * self.rnn_directions, input_seq.size(0), self.hidden_size, device='cuda')if input_seq.ndim < 3:input_seq.unsqueeze_(2)gru_out, hidden = self.gru(input_seq, ht)if self.rnn_directions > 1:gru_out = gru_out.view(input_seq.size(0), self.sequence_len, self.rnn_directions, self.hidden_size)gru_out = torch.sum(gru_out, axis=2)return gru_out, hidden.squeeze(0)class AttentionDecoderCell(nn.Module):def __init__(self, input_feature_len, out_put, sequence_len, hidden_size):super().__init__()# attention - inputs - (decoder_inputs, prev_hidden)self.attention_linear = nn.Linear(hidden_size + input_feature_len, sequence_len)# attention_combine - inputs - (decoder_inputs, attention * encoder_outputs)self.decoder_rnn_cell = nn.GRUCell(input_size=hidden_size,hidden_size=hidden_size,)self.out = nn.Linear(hidden_size, input_feature_len)def forward(self, encoder_output, prev_hidden, y):if prev_hidden.ndimension() == 3:prev_hidden = prev_hidden[-1] # 保留最后一层的信息attention_input = torch.cat((prev_hidden, y), axis=1)attention_weights = F.softmax(self.attention_linear(attention_input), dim=-1).unsqueeze(1)attention_combine = torch.bmm(attention_weights, encoder_output).squeeze(1)rnn_hidden = self.decoder_rnn_cell(attention_combine, prev_hidden)output = self.out(rnn_hidden)return output, rnn_hiddenclass EncoderDecoderWrapper(nn.Module):def __init__(self, input_size, output_size, hidden_size, num_layers, pred_len, window_size, teacher_forcing=0.3):super().__init__()self.encoder = RNNEncoder(num_layers, input_size, window_size, hidden_size)self.decoder_cell = AttentionDecoderCell(input_size, output_size, window_size, hidden_size)self.output_size = output_sizeself.input_size = input_sizeself.pred_len = pred_lenself.teacher_forcing = teacher_forcingself.linear = nn.Linear(input_size,output_size)def __call__(self, xb, yb=None):input_seq = xbencoder_output, encoder_hidden = self.encoder(input_seq)prev_hidden = encoder_hiddenif torch.cuda.is_available():outputs = torch.zeros(self.pred_len, input_seq.size(0), self.input_size, device='cuda')else:outputs = torch.zeros(input_seq.size(0), self.output_size)y_prev = input_seq[:, -1, :]for i in range(self.pred_len):if (yb is not None) and (i > 0) and (torch.rand(1) < self.teacher_forcing):y_prev = yb[:, i].unsqueeze(1)rnn_output, prev_hidden = self.decoder_cell(encoder_output, prev_hidden, y_prev)y_prev = rnn_outputoutputs[i, :, :] = rnn_outputoutputs = outputs.permute(1, 0, 2)if self.output_size == 1:outputs = self.linear(outputs)return outputsdef train(model, args, scaler, device):start_time = time.time() # 计算起始时间model = modelloss_function = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.005)epochs = args.epochsmodel.train() # 训练模式results_loss = []for i in tqdm(range(epochs)):losss = []for seq, labels in train_loader:optimizer.zero_grad()y_pred = model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()losss.append(single_loss.detach().cpu().numpy())tqdm.write(f"\t Epoch {i + 1} / {epochs}, Loss: {sum(losss) / len(losss)}")results_loss.append(sum(losss) / len(losss))torch.save(model.state_dict(), 'save_model.pth')time.sleep(0.1)# valid_loss = valid(model, args, scaler, valid_loader)# 尚未引入学习率计划后期补上# 保存模型print(f">>>>>>>>>>>>>>>>>>>>>>模型已保存,用时:{(time.time() - start_time) / 60:.4f} min<<<<<<<<<<<<<<<<<<")plot_loss_data(results_loss)def valid(model, args, scaler, valid_loader):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式losss = []for seq, labels in valid_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy().cpu(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)print("验证集误差MAE:", losss)return sum(losss) / len(losss)def test(model, args, test_loader, scaler):# 加载模型进行预测losss = []model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式results = []labels = []for seq, label in test_loader:pred = model(seq)mae = calculate_mae(pred.detach().cpu().numpy(),np.array(label.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)pred = pred[:, 0, :]label = label[:, 0, :]pred = scaler.inverse_transform(pred.detach().cpu().numpy())label = scaler.inverse_transform(label.detach().cpu().numpy())for i in range(len(pred)):results.append(pred[i][-1])labels.append(label[i][-1])plt.figure(figsize=(10, 5))print("测试集误差MAE:", losss)# 绘制历史数据plt.plot(labels, label='TrueValue')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(results, label='Prediction')# 添加标题和图例plt.title("test state")plt.legend()plt.show()# 检验模型拟合情况
def inspect_model_fit(model, args, train_loader, scaler):model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式results = []labels = []for seq, label in train_loader:pred = model(seq)[:, 0, :]label = label[:, 0, :]pred = scaler.inverse_transform(pred.detach().cpu().numpy())label = scaler.inverse_transform(label.detach().cpu().numpy())for i in range(len(pred)):results.append(pred[i][-1])labels.append(label[i][-1])plt.figure(figsize=(10, 5))# 绘制历史数据plt.plot(labels, label='History')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(results, label='Prediction')# 添加标题和图例plt.title("inspect model fit state")plt.legend()plt.show()def predict(model, args, device, scaler):# 预测未知数据的功能df = pd.read_csv(args.data_path)df = df.iloc[:, 1:][-args.window_size:].values # 转换为nadarrypre_data = scaler.transform(df)tensor_pred = torch.FloatTensor(pre_data).to(device)tensor_pred = tensor_pred.unsqueeze(0) # 单次预测 , 滚动预测功能暂未开发后期补上model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式pred = model(tensor_pred)[0]pred = scaler.inverse_transform(pred.detach().cpu().numpy())# 假设 df 和 pred 是你的历史和预测数据# 计算历史数据的长度history_length = len(df[:, -1])# 为历史数据生成x轴坐标history_x = range(history_length)plt.figure(figsize=(10, 5))# 为预测数据生成x轴坐标# 开始于历史数据的最后一个点的x坐标prediction_x = range(history_length - 1, history_length + len(pred[:, -1]) - 1)# 绘制历史数据plt.plot(history_x, df[:, -1], label='History')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(prediction_x, pred[:, -1], marker='o', label='Prediction')plt.axvline(history_length - 1, color='red') # 在图像的x位置处画一条红色竖线# 添加标题和图例plt.title("History and Prediction")plt.legend()if __name__ == '__main__':parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='RNN', help="模型持续更新")parser.add_argument('-window_size', type=int, default=126, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-feature', type=str, default='M', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=16, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden_size', type=int, default=128, help="隐藏层单元数")parser.add_argument('-laryer_num', type=int, default=1)# deviceparser.add_argument('-use_gpu', type=bool, default=True)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-test', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()if isinstance(args.device, int) and args.use_gpu:device = torch.device("cuda:" + f'{args.device}')else:device = torch.device("cpu")print("使用设备:", device)train_loader, test_loader, valid_loader, scaler = create_dataloader(args, device)if args.feature == 'MS' or args.feature == 'S':args.output_size = 1else:args.output_size = args.input_size# 实例化模型try:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")model = EncoderDecoderWrapper(args.input_size, args.output_size, args.hidden_size, args.laryer_num, args.pre_len, args.window_size).to(device)print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型成功<<<<<<<<<<<<<<<<<<<<<<<<<<<")except:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型失败<<<<<<<<<<<<<<<<<<<<<<<<<<<")# 训练模型if args.train:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")train(model, args, scaler, device)if args.test:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型测试<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")test(model, args, test_loader, scaler)if args.inspect_fit:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始检验{args.model}模型拟合情况<<<<<<<<<<<<<<<<<<<<<<<<<<<")inspect_model_fit(model, args, train_loader, scaler)if args.predict:print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")predict(model, args, device, scaler)plt.show()
六、训练模型
我们配置好所有参数之后就可以开始训练模型了,根据我前面讲解的参数部分进行配置,不懂得可以评论区留言。
七、预测结果
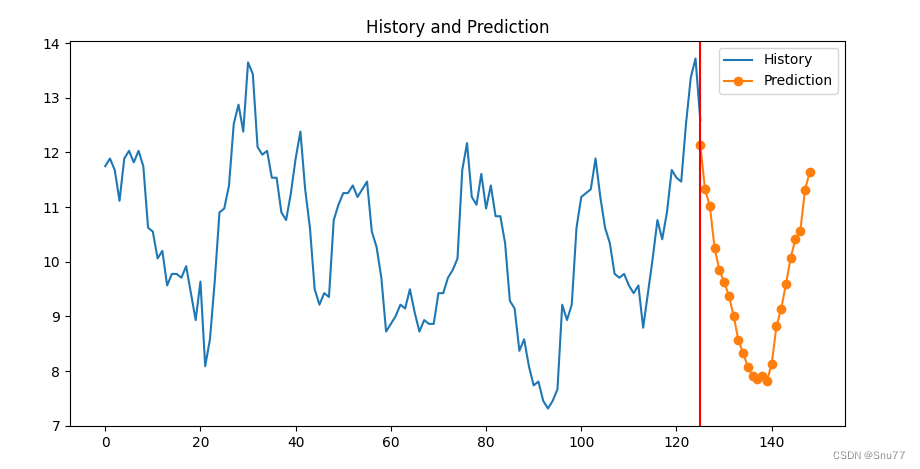
7.1 预测未知数据效果图
Seq2Seq(GRU)的预测效果图(这里我只预测了未来24个时间段的值为未来一天的预测值)->
7.2 测试集效果图
测试集上的表现->
7.3 CSV文件生成效果图
同时我也可以将输出结果用csv文件保存,但是功能还没有做,我在另一篇informer的文章里实习了这个功能大家如果有需要可以评论区留言,有时间我会移植过来,最近一直在搞图像领域的文章因为时间序列看的人还是太少了。
另一篇文章链接->时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本,结果可视化)
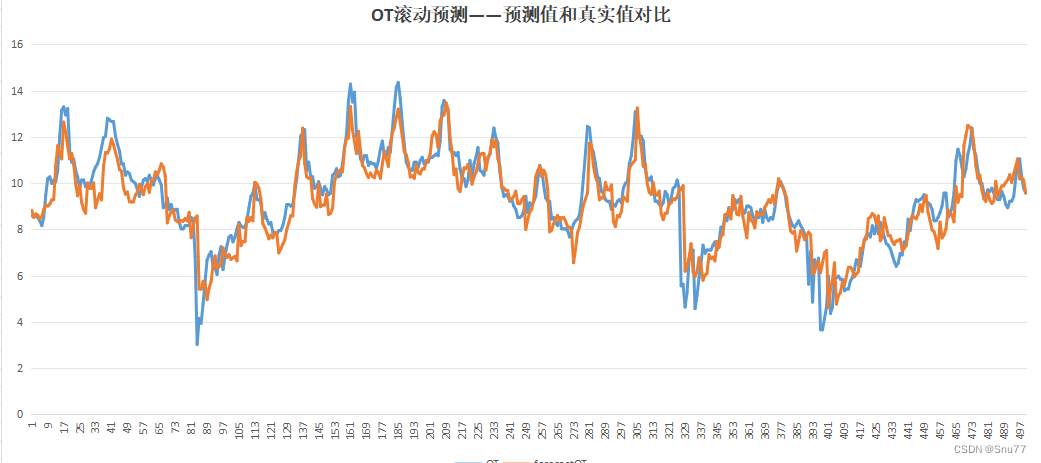
将滚动预测结果生成了csv文件方便大家对比和评估,以下是我生成的csv文件可以说是非常的直观。

我们可以利用其进行画图从而评估结果->
7.4 检验模型拟合效果图
检验模型拟合情况->
(从下面的图片可以看出模型拟合的情况还行,上一篇RNN的有一点过拟合了其实,则会个表现还是很正常的)

八、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的时间序列专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的模型进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾: 时间序列预测专栏——持续复习各种顶会内容——科研必备
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!最后希望大家工作顺利学业有成!

相关文章:
时间序列预测实战(二十五)PyTorch实现Seq2Seq进行多元和单元预测(附代码+数据集+完整解析)
一、本文介绍 本文给大家带来的时间序列模型是Seq2Seq,这个概念相信大家都不陌生了,网上的讲解已经满天飞了,但是本文给大家带来的是我在Seq2Seq思想上开发的一个模型和新的架构,架构前面的文章已经说过很多次了,其是…...

电子学会C/C++编程等级考试2022年09月(三级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:课程冲突 小 A 修了 n 门课程, 第 i 门课程是从第 ai 天一直上到第 bi 天。 定义两门课程的冲突程度为 : 有几天是这两门课程都要上的。 例如 a1=1,b1=3,a2=2,b2=4 时, 这两门课的冲突程度为 2。 现在你需要求的是这 n 门课…...

【数据库】基于时间戳的并发访问控制,乐观模式,时间戳替代形式及存在的问题,与封锁模式的对比
使用时间戳的并发控制 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会…...
Python 日志(略讲)
日志操作 日志输出: # 输出日志信息 logging.debug("调试级别日志") logging.info("信息级别日志") logging.warning("警告级别日志") logging.error("错误级别日志") logging.critical("严重级别日志")级别设置…...
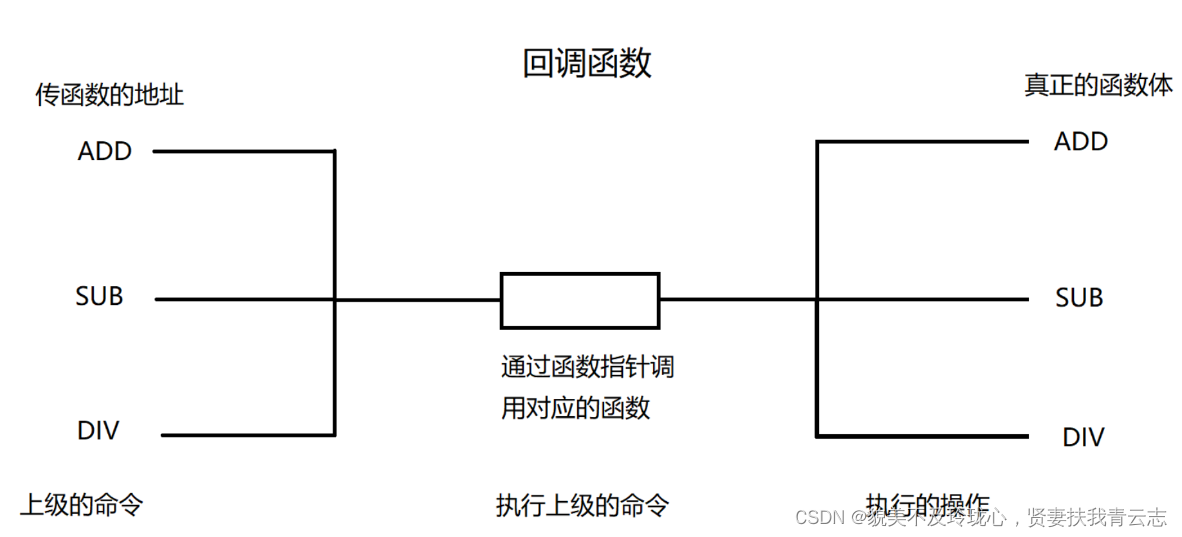
C++ 指针进阶
目录 一、字符指针 二、指针数组 三、数组指针 数组指针的定义 &数组名 与 数组名 数组指针的使用 四、数组参数 一维数组传参 二维数组传参 五、指针参数 一级指针传参 二级指针传参 六、函数指针 七、函数指针数组 八、指向函数指针数组的指针 九、回调函…...

stm32中滴答定时器与普通定时器的区别
1、两者在单片机中的位置不一样 滴答定时器在内核上,普通定时器在外设上。 由于位置不同,滴答定时器的程序可以移植到所有相同内核的芯片上,但普通定时器的程序却不可以。 2、两者的中断优先级不一样 滴答定时器优先级高,普通定…...
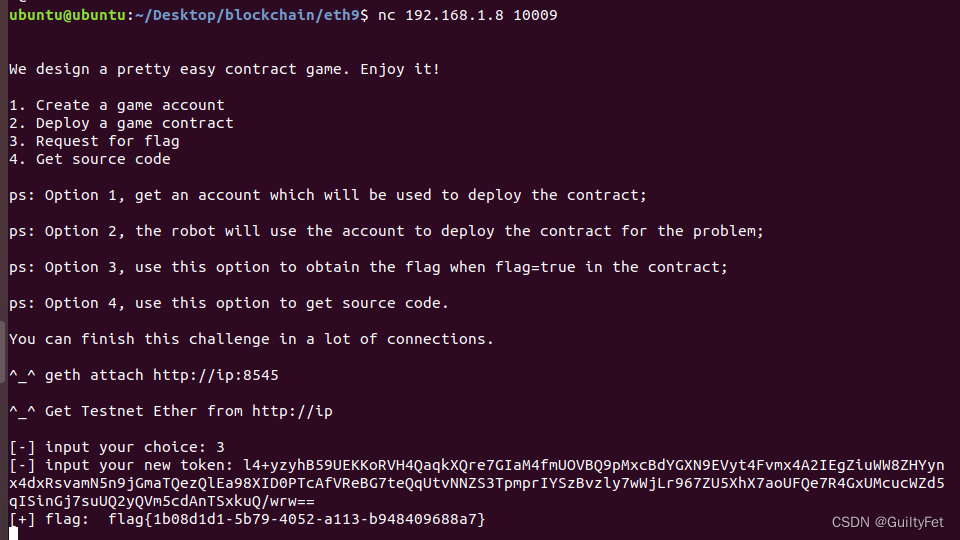
某60区块链安全之薅羊毛攻击实战一学习记录
区块链安全 文章目录 区块链安全薅羊毛攻击实战一实验目的实验环境实验工具实验原理实验内容薅羊毛攻击实战一 实验步骤EXP利用 薅羊毛攻击实战一 实验目的 学会使用python3的web3模块 学会分析以太坊智能合约薅羊毛攻击漏洞 找到合约漏洞进行分析并形成利用 实验环境 Ubun…...

Java程序员,你掌握了多线程吗?(文末送书)
目录 01、多线程对于Java的意义02、为什么Java工程师必须掌握多线程03、Java多线程使用方式04、如何学好Java多线程送书规则 摘要:互联网的每一个角落,无论是大型电商平台的秒杀活动,社交平台的实时消息推送,还是在线视频平台的流…...

排序算法——桶排序/基数排序/计数排序
桶排序 是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理: 假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使…...

FFmpeg之将视频转为16:9(横屏)或9:16(竖屏)(三十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒体系统工程师系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只…...
git学习笔记02(小滴课堂)
window 安装教程:https://www.yuque.com/u1106272/cai80g/skawco 查看: 创建文件夹: 我们把这个文件夹当作我们的暂存区。 这样就进入了工作区。 初始化: 可以看到.git文件夹。 查看本地仓库状态: 我们进入这个ide…...
2022 RedisDays 内容揭秘
上个月,Redis举办了3场线上会议,分别介绍了即将正式发布的Redis 7中包括的重要更新的内容,还有Redis完全重写的RedisJSON 2.0模块,和新发布的Redis Stack模块。除此之外,在此次线上会议中还介绍了现代化的软件架构与Re…...

论文阅读——Img2LLM(cvpr2023)
arxiv:[2212.10846] From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models (arxiv.org) 一、介绍 使用大语言模解决VQA任务的方法大概两种:multi-modal pretraining and language-mediated VQA,即多模态预训练…...

南京大学考研机试题DP
3. dp 求子序列的个数 https://www.acwing.com/problem/content/description/3716/ #include <iostream> #include <cstring> #include <algorithm> #include <unordered_set> #include <vector> using namespace std; const int N 1e4 10…...

如何进行多ip服务器租用?
如何进行多ip服务器租用? 对于网络时代来说,是需要很多设备才能维持的,比如说多ip服务器就是互联网时代常见的设备,所以我们需要对多ip服务器有足够的了解,这样才能更好的获取互联网上的信息,满足我们工作…...

(动手学习深度学习)第13章 实战kaggle竞赛:树叶分类
文章目录 实战kaggle比赛:树叶分类1. 导入相关库2. 查看数据格式3. 制作数据集4. 数据可视化5. 定义网络模型6. 定义超参数7. 训练模型8. 测试并提交文件 竞赛技术总结1. 技术分析2. 数据方面模型方面3. AutoGluon4. 总结 实战kaggle比赛:树叶分类 kagg…...

vue中shift+alt+f格式化防止格式掉其它内容
好处就是使得提交记录干净,否则修改一两行代码,习惯性按了一下格式化快捷键,遍地飘红,下次找修改就费时间 1.点击设置图标-设置 2.点击这个转成配置文件 {"extensions.ignoreRecommendations": true,"[vue]":…...
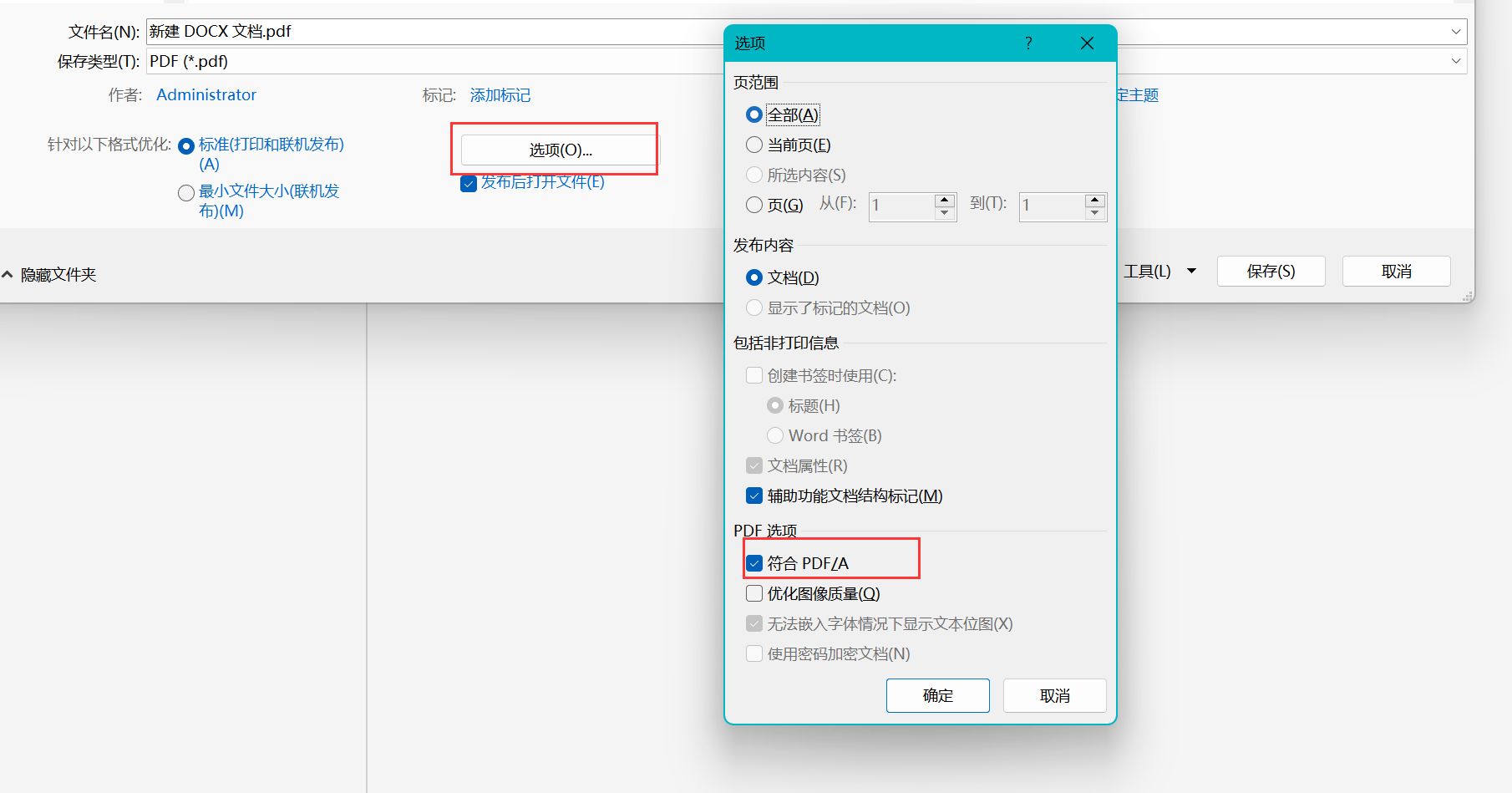
WPS导出的PDF比较糊,和原始的不太一样,将带有SVG的文档输出为PDF
一、在WPS的PPT中 你直接输出PDF可能会导致一些问题(比如照片比原来糊)/ 或者你复制PPT中的图片到AI中类似的操作,得到的照片比原来糊,所以应该选择打印-->高级打印 然后再另存为PDF 最后再使用AI打开PDF文件再复制到你想用…...

Linux /etc/hosts文件
Linux的 /etc/hosts 文件用于静态地映射主机名到 IP 地址。 通常用于本地网络中的名称解析,它可以覆盖 DNS 的设置。当你访问一个域名时,系统会首先检查 /etc/hosts 文件,如果找到了匹配项,就会使用该 IP 地址,否则会…...
webpack学习-3.管理输出
webpack学习-3.管理输出 1.简单练手2.设置 HtmlWebpackPlugin3.清理 /dist 文件夹4.manifest5.总结 1.简单练手 官网的第一个预先准备,是多入口的。 const path require(path);module.exports {entry: {index: ./src/index.js,print: ./src/print.js,},output: …...

终极解决方案:3分钟轻松解决腾讯游戏ACE-Guard卡顿问题
终极解决方案:3分钟轻松解决腾讯游戏ACE-Guard卡顿问题 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 还在为腾讯游戏中的ACE-Guard进程占用…...

ncmdump终极NCM解密转换完全指南
ncmdump终极NCM解密转换完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾遇到过这样的困扰?从网易云音乐下载的歌曲只能在特定播放器中播放,想要在其他设备上欣赏却束手无策。这种被格式限制的…...

Claude插件开发实战:从架构设计到生产部署的完整指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你和我一样,长期在AI应用开发的一线摸爬滚打,那你一定对Claude这个AI模型不陌生。它强大的推理能力和对长文本的友好处理,让很多开发者都将其作为构建智能应用的核心引擎。但一个模型…...

2026年IPA防破解安全加固公司怎么选?这份iOS加固服务商横向对比清单请收好
当你的iOS应用核心代码被逆向、商业逻辑被剽窃、盗版版本在分发平台泛滥时,寻找一家靠谱的IPA防破解安全加固公司就成了技术负责人的当务之急。但面对市面上众多服务商,如何判断哪家方案真正有效,且不影响App Store过审?本文基于多…...

书成紫微动,律定凤凰驯:千古诗句留伏笔,只为海棠山铁哥而来
世间文字千万,唯有谶语藏岁月天机; 文坛更迭千载,唯有天命待当世真人。一、诗谶降世:「书成紫微动,律定凤凰驯」这不是文采佳句, 是华夏预埋千载的 隐秘伏笔, 是一场跨越世代的 天命预约。千年之…...

ClawLink:配置驱动的数据抓取与链接工具实战解析
1. 项目概述与核心价值最近在折腾一些自动化流程和跨平台数据同步时,发现了一个挺有意思的项目,叫 ClawLink。乍一看这个名字,可能有点摸不着头脑,但如果你也在为如何把不同平台、不同格式的数据“抓取”并“链接”起来而头疼&…...

LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗?
LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗? 在分子动力学模拟领域,LAMMPS因其开源特性和强大的计算能力成为研究者的首选工具。然而,许多用户在使用过程中常遇到一个令人沮丧的现象——明明配置了多核…...

基于Go与Croc构建Telegram文件传输机器人:原理、部署与优化
1. 项目概述:一个基于Go的轻量级文件传输机器人 如果你经常需要在不同的设备、服务器或者聊天群组之间快速分享文件,并且对安全性、速度和便捷性有一定要求,那么你很可能已经厌倦了那些需要注册账号、上传到第三方服务器、或者操作繁琐的命令…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...

从SDRAM到DDR3:给FPGA开发者的内存进化史与选型避坑指南
从SDRAM到DDR3:FPGA开发者的内存技术演进与实战选型策略 在FPGA开发中,外部存储器的选择往往决定了整个系统的性能上限。当面对OV5640摄像头每秒数百兆的像素数据流,或是高速ADC采集的连续波形时,一个不合适的内存选型可能导致系统…...