StarRocks 存算分离最佳实践,让降本增效更简单
StarRocks 存算分离自版本 3.0.0 开放使用,已经历过多个大版本迭代,在众多客户生产环境中得到验证。但在用户使用过程中也反馈了一些问题,大多源自对新能力不够熟悉导致无法达到最佳效果。因而,本文提供 StarRocks 存算分离最佳实践,建议测试前仔细阅读,并按照最佳实践的指导来实施,以达到事半功倍的效果。
部署
用户在部署时需要在部署模式上二选一,存算一体或者存算分离,目前尚不支持在一个集群中同时支持两种运行模式。
StarRocks 目前支持各种类型对象存储,如所有兼容 AWS S3 协议的对象存储(如 S3、OSS、COS、OBS、GCP、Ceph-S3 等),Azure Blob Storage、Google GCP 以及传统的 HDFS 等,用户可以根据实际情况自由选择。
StarRocks 集群内添加了众多的监控指标,且可以被 Prometheus 采集并通过 Grafana 展示,借助这些指标,可以实时观察集群运行情况。因此,对于所有的用户,我们建议您在实际使用 StarRocks 存算分离集群前,先配置好监控,详细可参考文档 StarRocks 存算分离监控部署[1]。
建表
在存算分离集群中,用户建表时需要关注分桶数的设置,要想获得最佳性能,合理的分桶数选择必不可少。如果分桶数设置的过少,可能会导致计算时无法充分利用硬件资源,如果分桶数设置过多,在存算分离集群中可能会产生大量的小文件导致 I/O 效率低下。在实践中,我们建议按照数据量来决定分桶数,一般建议每个分桶容纳的数据规模在 1 ~ 5GB 左右较为合适。
另外,自 3.1.0 版本后,StarRocks 支持为每个表指定不同的存储桶(对象存储中的概念,存储容器),用户可以为不同的表设定不同的存储桶以实现物理资源的隔离,具体可以通过创建 Storage Volume 来配置不同的存储桶[2];创建表时,通过 Storage Volume PROPERTIES 指定存储桶[3]。
Tips
1,根据表实际数据量合理选择分桶数量
2,对于分桶数较多的表,创建可能耗时较长,此时可适当调整参数来观察是否有改善
3,使用 Storage Volume 能让您的建表更为灵活,强烈推荐
导入
当前 StarRocks 存算分离表支持存算一体模式中的所有数据导入方式,离线数据推荐 Broker Load,实时数据同步推荐 DataX,Flink Connector 等,用法与存算一体保持一致。
为了保证数据可靠性,存算分离中数据写入使用同步模式,即保证数据完整写入后端对象存储后方才给用户返回成功。考虑到对象存储的延迟(高出本地磁盘 1 ~ 2 个数量级),用户可能会观察到单一任务导入延迟相比存算一体表有所增加(增加的比例取决于多种因素),这属于正常现象。因此,在存算分离表中,我们建议,如果条件允许,尽量攒批大一点,一次性导入更多的数据量,以更好地利用对象存储高吞吐特性,对于部分存储系统(如 HDFS),过多的小文件也会给元数据服务带来极大压力。
其次,在实践中我们推荐增大 flush memtable 的线程数(flush_thread_num_per_store),多线程并发写数据可以充分利用对象存储的高吞吐特性。
具体的导入参数调优可参考 StarRocks 存算分离 3.1 性能调优手册[4]。
Tips
1,攒批大一点可以获得更好的吞吐,同时也能减少对象存储小文件数量
2,提高 flush memtable 线程数,可以充分利用对象存储的高吞吐特性,取得更好的写入性能
查询
经过我们实际测试和众多用户实践,在缓存命中(Local Disk and Page Cache)情况下,StarRocks 存算分离表的查询性能与存算一体基本一致,因此,我们推荐,条件允许情况下建议开启 Data Cache 以获得更好的查询性能。
对于直接查询位于远端对象存储的数据,取决于实际的查询类型,相比缓存命中情况下,可能有3 ~ 5 倍左右的性能差距,目前社区正在不断优化该场景下的查询性能,期望能不断缩小这种差距。
即使开启了 Data Cache,在某些场景下依然可能会出现 Cache Miss 情况(例如升降级导致了 Tablet 迁移),我们需要尽量保证不触发 Tablet 迁移。
如果出现查询性能超出预期范围,用户可选择通过自主分析 Profile 来定位具体原因。
具体的查询参数调优可参考 StarRocks 存算分离 3.1 性能调优手册[4]。
Tips
1,如果可以,尽量为所有的表开启 Data Cache(建表时默认行为)
2,在 BE/CN 常规重启或者版本升级时,关闭 Tablet Balance(在 Leader FE 上执行 admin set frontend config("disable_balance"="true"))避免触发 Tablet 迁移,避免造成 Cache Miss,影响查询性能
3,冷数据查询社区正在积极优化,如果您遇到这种问题,请及时反馈
4,学会自主分析 Profile,快速定位性能问题
Cache
Cache 是提升查询效率的主要方式,我们也推荐为所有的表开启 Data Cache(指的是基于计算节点本地磁盘的作为数据缓存),将热数据缓存在磁盘上,提升 I/O 效率。
StarRocks 存算分离建表时默认会开启 Data Cache,当然您也可以通过参数关闭。开启 Cache 后,导入时,数据会同时写入本地缓存与后端对象存储,只有两者都写入成功后方才给用户返回成功。
StarRocks 支持自动的 LRU 淘汰,当缓存磁盘接近满时会自动将最冷的数据淘汰掉,原则上您无需担心磁盘写满造成写入失败的情况,但某些极端场景下可能也会出现淘汰不及时造成了磁盘满情况,建议您配置磁盘监控报警,关注磁盘容量。
StarRocks 支持多块盘作为缓存,目前的策略是会将不同的 Partition 数据打散放置到多个缓存盘上(3.1.4版本后),因而,基本上多块缓存盘磁盘空间使用应该是比较均衡的,建议您也适当关注。
StarRocks 当前版本采用 File 级别 Cache,即一旦查询出现 Cache Miss,计算节点会将单个数据文件全部拉回本地磁盘(即使计算节点可能只访问文件中的某些数据页面),可能会造成网络流量较大,使用的计算和 I/O 资源较多以及缓存拉取较慢的问题,建议多加关注。从 3.2 版本后,StarRocks 将使用更细粒度的缓存机制来彻底解决该问题。 StarRocks 社区目前正在设计缓存预热方案,敬请期待。具体的 Cache 调优可参考 StarRocks 存算分离 3.1 性能调优手册[4]。
Tips
1,关注缓存磁盘的容量,并配置监控报警应对异常
2,如果计算节点使用多块缓存磁盘,建议关注缓存磁盘使用是否均衡
3,使用 File Cache 机制在 Cache Miss 时可能会有大量拉缓存的情况,将在 3.2.0版本彻底解决
4,缓存预热正在设计中,敬请期待
Compaction
Compaction 是 StarRocks 的后台任务(存算一体与存算分离均存在),目的是将小文件合并成为大文件,以减少 I/O 次数,加速查询性能。
作为后台任务,用户一般情况下无需感知 Compaction 任务的执行情况,但当出现查询较慢时,我们建议您优先关注下慢查询涉及的表的 Compaction Score 情况,排除是 Compaction 不及时造成的慢查询。
StarRocks 存算分离集群中,系统会根据 Partition 下的文件数量来决定是否发起 Compaction 任务,系统会自动根据当前计算节点规模来决定同时执行的 Compaction 任务数,基本能做到自适应。但 Compaction 本质上也需要消耗系统资源(CPU、Memory、I/O 等),当系统资源紧张时,需要适当降低 Compaction 的频率来减少对正常业务请求的影响。
具体的 Compaction 运维可参考 StarRocks 存算分离 Compaction 运维手册[5]。
Tips
1,关注 Partition 的 Compaction Score 非常重要,尤其是在出现慢查询时
2,Compaction 会消耗系统资源,如果资源紧张,建议降低 Compaction 频率
GC
同 Compaction 一样,GC 也是 StarRocks 的后台任务(存算一体与存算分离均存在),目的是删除那些不再需要的文件版本,降低存储容量与成本(对象存储会根据存储容量收费)。
作为后台任务,用户一般情况下无需感知 GC 任务的执行情况,但我们建议您定期关注后端对象存储容量以确定 GC 任务正确运行。
如果您观察到对象存储容量远超表实际数据容量,此时可以观察监控指标来观察是否有 GC 任务积压等现象,如果有,可以参照 StarRocks 存算分离垃圾回收运维手册[6]调整部分参数值来加速 GC 任务回收。
Tips
1,关注表的容量和实际对象存储容量,如果后者超出太多,建议仔细分析 如果存在大查询,建议适当延长文件回收时间,避免查询失败
Primary Key 表
StarRocks 存算分离自版本 3.1.0 后开始支持 Primary Key 表模型,其使用方式与存算一体模式下完全一致,用户可以放心使用。
自 3.1.4版本后,Primary key 表开始支持索引持久化能力,但仅限持久化至本地缓存磁盘,因此,如果想使用持久化索引,需要配置本地磁盘。 如果未开启索引持久化,可能会存在使用内存较多的问题,请及时关注内存使用情况,如有必要,使用 3.1.4以及之后的版本来开启索引持久化。
Tips
1,未开启索引持久化时可能会消耗较多内存,请及时监控内存使用,如果内存不足,可以开启索引持久化
数据迁移
当前 StarRocks 存算一体与存算分离无法在同集群共存,用户需要将存算一体集群数据迁移至存算分离集群,存在如下几种方案:
1,将存算一体集群数据通过 export 导出至 S3、HDFS 等系统,然后再通过 Broker Load 等方式导入至存算分离集群
2,在存算分离集群配置 StarRocks 外表并指向存算一体集群,然后通过 insert into select 方式从外表中向存算分离集群内表导入数据,但要求存算一体集群版本在 3.0.0 以上
3,利用社区提供的迁移工具完成一键式迁移,简单且高效(预计12月中旬发布)
弹性
StarRocks 存算分离的一个核心优势在于可以快速弹性,我们实测也显示弹性效果非常优秀且避免了存算一体在弹性时存在的数据迁移导致弹性时间过长的问题,弹性测试可参考 StarRocks 存算分离弹性能力测试[7]。 StarRocks 存算分离支持快速弹性,节点的上下线会触发 Tablet 迁移,这会导致部分查询出现 Cache Miss,不过只要经过第一次查询冷数据后,第二次即可命中 Cache,性能也会相应恢复。
Tips
1,增加节点可相应提升性能
2,弹性时由于 Tablet 迁移会存在首次查询 Cache Miss,但第二次就会恢复
相关链接:
[1]https://starrocks.feishu.cn/docx/ZwkcdCl00oHMMFxNwK7cg20Bnje
[2]https://docs.starrocks.io/zh-cn/latest/sql-reference/sql-statements/Administration/CREATE_STORAGE_VOLUME#%E7%9B%B8%E5%85%B3-sql
[3]https://docs.starrocks.io/zh-cn/latest/deployment/deploy_shared_data#%E5%88%9B%E5%BB%BA%E6%95%B0%E6%8D%AE%E5%BA%93%E5%92%8C%E4%BA%91%E5%8E%9F%E7%94%9F%E8%A1%A8
[4]https://starrocks.feishu.cn/docx/GEZpdCPchoVL67xTMOPcKjCrneg
[5]https://starrocks.feishu.cn/docx/GvgmdyK03olcFoxCs7rcHjKVnod
[6]https://starrocks.feishu.cn/docx/XZ8edURRvoDbOnxigCocsLzNnyh
[7]https://starrocks.feishu.cn/docx/Dd3AdQ9ujoYKHsxXxeNcB8oBn9d
本文由 mdnice 多平台发布
相关文章:

StarRocks 存算分离最佳实践,让降本增效更简单
StarRocks 存算分离自版本 3.0.0 开放使用,已经历过多个大版本迭代,在众多客户生产环境中得到验证。但在用户使用过程中也反馈了一些问题,大多源自对新能力不够熟悉导致无法达到最佳效果。因而,本文提供 StarRocks 存算分离最佳实…...
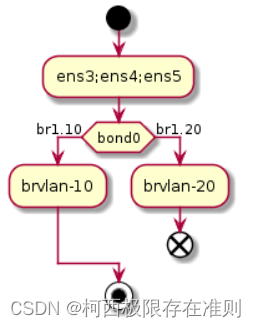
虚拟网络技术:bond技术
网卡bond也称为网卡捆绑,就是将两个或者更多的物理网卡绑定成一个虚拟网卡。 bond的作用: 1.提高网卡的吞吐量 2.增加网络的高可用,实现负载均衡。 一、bond简介 bond技术即bonding,能将多块物理网卡绑定到一块虚拟网卡上&…...

【Android】解决安卓中并不存在ActivityMainBinding
安卓中并不存在ActivityMainBinding这个类,这个类是在XML布局的最外层加入就会自动生成。但是你在最后绑定主布局时会报错获取不到根节点getRoot(). 最好的办法就是,删除原来的最外层节点,再重新添加,感觉是因为复制时并没有让系…...

mysql的几种索引
mysql索引的介绍可以mysql官网的词汇表中搜索: https://dev.mysql.com/doc/refman/8.0/en/glossary.html mysql可以在表的一列、或者多列上创建索引,索引的类型可以选择,如下: 普通索引(KEY) 普通索引可…...
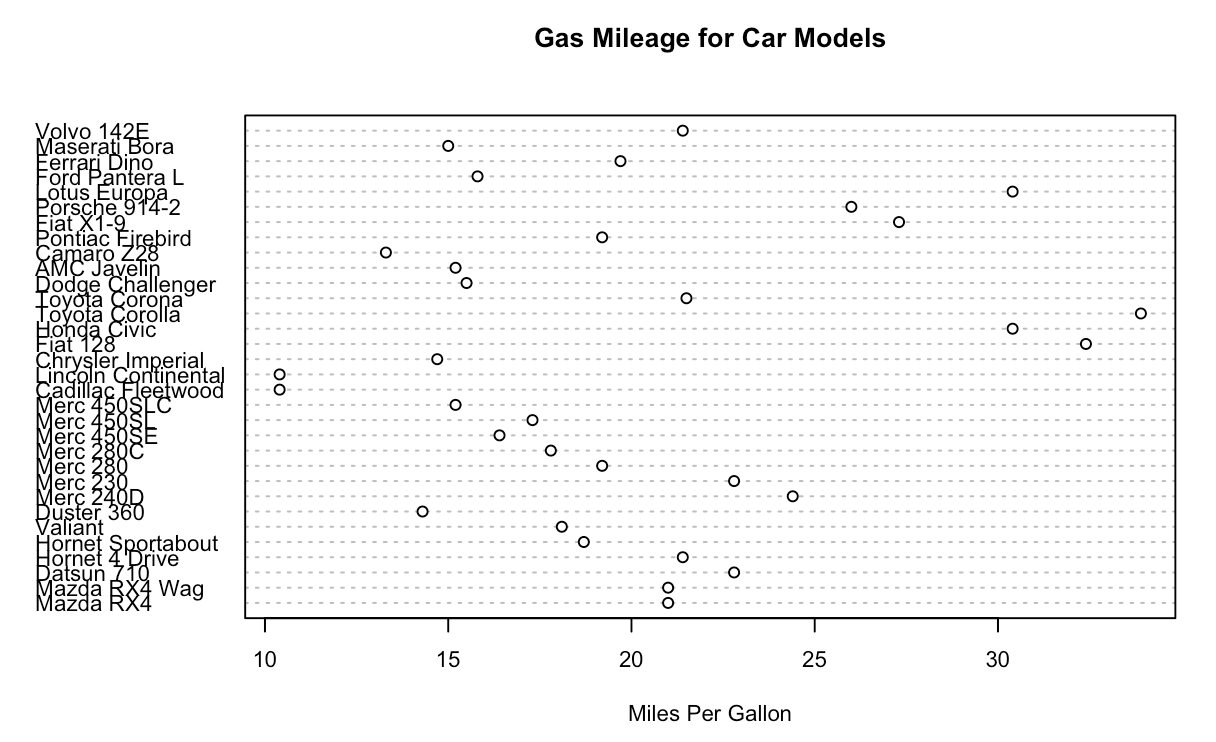
R语言手册30分钟上手
文章目录 1. 环境&安装1.1. rstudio保存工作空间 2. 创建数据集2.1. 数据集概念2.2. 向量、矩阵2.3. 数据框2.3.1. 创建数据框2.3.2. 创建新变量2.3.3. 变量的重编码2.3.4. 列重命名2.3.5. 缺失值2.3.6. 日期值2.3.7. 数据框排序2.3.8. 数据框合并(合并沪深300和中证500收盘…...

前缀和例题:子矩阵的和AcWing796-Java版
//前缀和模板提,在读入数据的时候就可以先算好前缀和的大小 //计算前缀的时候用:g[i][j] g[i][j-1] g[i-1][j] - g[i-1][j-1] Integer.parseInt(init[j-1]); //计算结果的时候用:g[x2][y2] - g[x1 - 1][y2]- g[x2][y1-1] g[x1 -1][y1 - 1] "\n" //一些重复加的地…...

前端传参中带有特殊符号导致后端接收时乱码或转码失败的解决方案
文章目录 bug背景解决思路1:解决思路2解决思路3(最终解决方案)后记 bug背景 项目中采用富文本编辑器后传参引起的bug,起因如下: 数据库中存入的数据会变成这种未经转码的URL编码 解决思路1: 使用JSON方…...

【扩散模型】深入理解图像的表示原理:从像素到张量
【扩散模型】深入理解图像的表示原理:从像素到张量 在深度学习中,图像是重要的数据源之一,而图像的表示方式对于算法的理解和处理至关重要。本文将带你深入探讨图像的底层表示原理,从像素到张量,让你对图像表示有更清…...

WPS论文写作——公式和公式序号格式化
首先新建一个表格,表格尺寸按你的需求来确定,直接 插入--》表格 即可。 然后在表格对应位置填上公式(公式要用公式编辑器)和公式序号,然后可以按照单独的单元格或者整行或整列等来设置样式,比如居中对齐、…...

ChatGPT一周年,奥特曼官宣 OpenAI 新动作!
大家好,我是二狗。 今天是11月30日,一转眼,ChatGPT 发布已经一周年了! 而就在刚刚,ChatGPT一周年之际。 OpenAI 正式宣布Sam Altman回归重任CEO, Mira Murati 重任CTO,Greg Brockman重任总裁,O…...
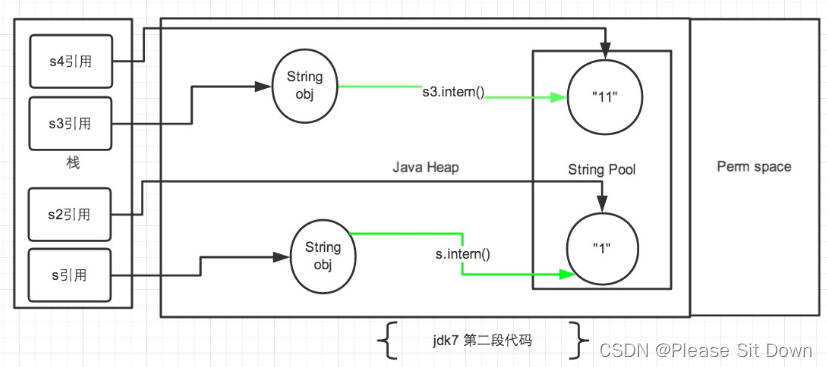
JVM 运行时内存篇
面试题: 讲一下为什么JVM要分为堆、方法区等?原理是什么?(UC、智联) JVM的分区了解吗,内存溢出发生在哪个位置 (亚信、BOSS) 简述各个版本内存区域的变化࿱…...
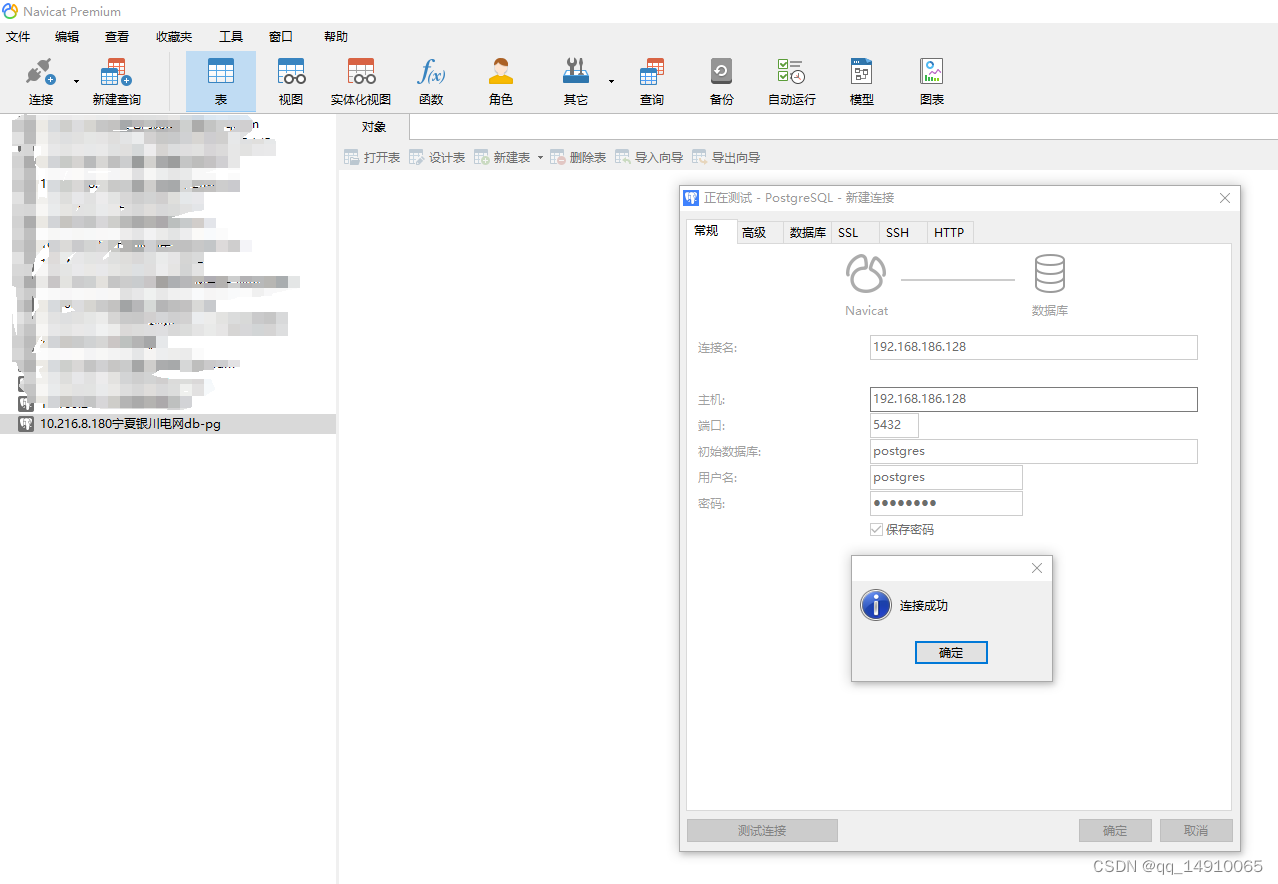
Docker安装postgres最新版
1. postgres数据库 PostgreSQL是一种开源的关系型数据库管理系统(RDBMS),它是一种高度可扩展的、可靠的、功能丰富的数据库系统。以下是关于PostgreSQL的一些介绍: 开源性:PostgreSQL是一个开源项目,可以…...

浅析计算机网络安全的的防范与措施
摘 要 随着信息和通讯的高速发展使得人们对计算机的依赖逐渐增强,生活与工作当中计算机都担任着那个不可或缺的角色,已经是人们生活当中的一部分,充分影响着我们生活和工作中的很多关键点,但计算机过多地在工作和生活中使用也带来…...
多表操作、其他字段和字段参数、django与ajax(回顾)
多表操作 1 基于对象的跨表查 子查询----》执行了两句sql,没有连表操作 2 基于双下滑线的连表查 一次查询,连表操作 3 正向和反向 放在ForeignKey,OneToOneField,ManyToManyField的-related_namebooks:双下滑线连表查询,反向…...

您知道计算机是怎么分类的嘛
地表最强计算机 第 61 版全球最强大的超级计算机已经发布。名为 Top500,顾名思义,该列表列出了全球 500 台最强大的超级计算机。榜单显示,美国的AMD、英特尔和IBM处理器是超级计算系统的首选。在 TOP10 中,有四个系统使用 AMD 处理…...

[MTK]安卓8 ADB执行ota升级
需求 adb 推送update.zip进行安卓的OTA升级 环境 平台:mtk SDK:Android 8 命令方式 需要root adb root adb remount adb push update.zip /data/media/0/ adb shell uncrypt /data/media/0/update.zip /cache/recovery/block.map adb shell echo /data/media/0/update.zi…...

python-比较Excel两列数据,并分别显示差异
利用 openpyxl 模块,操作Excel,比较Excel两列数据,并分别显示差异 表格数据样例如下图 A,B两列是需要进行比较的数据(数据源为某网站公开数据);C,D两列是比较结果的输出列 A&#…...

RT-DETR手把手教程:NEU-DET钢材表面缺陷检测任务 | 不同网络位置加入EMA注意力进行魔改
💡💡💡本文独家改进:本文首先复现了将EMA引入到RT-DETR中,并跟不同模块进行结合创新;1)多种Rep C3结合;2)直接作为注意力机制放在网络不同位置; NEU-DET钢材表面缺陷检测: 原始 rtdetr-r18 map0.5为0.67 rtdetr-r18-EMA_attention map0.5为0.691 rtdetr-r18-…...
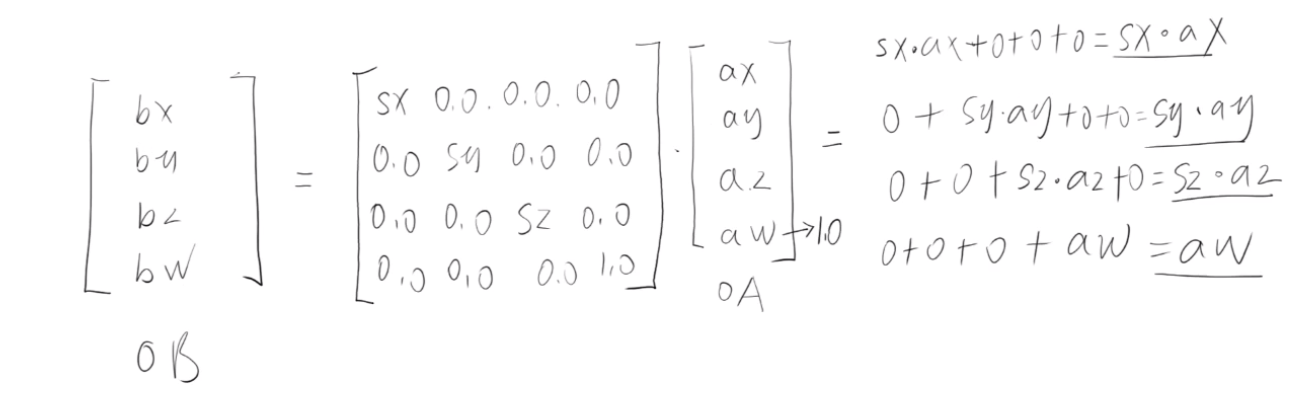
WebGL笔记:矩阵缩放的数学原理和实现
矩阵缩放的数学原理 和平移一样,以同样的原理,也可以理解缩放矩阵让向量OA基于原点进行缩放 x方向上缩放:sxy方向上缩放:syz方向上缩放:sz 最终得到向量OB 矩阵缩放的应用 比如我要让顶点在x轴向缩放2,y轴…...
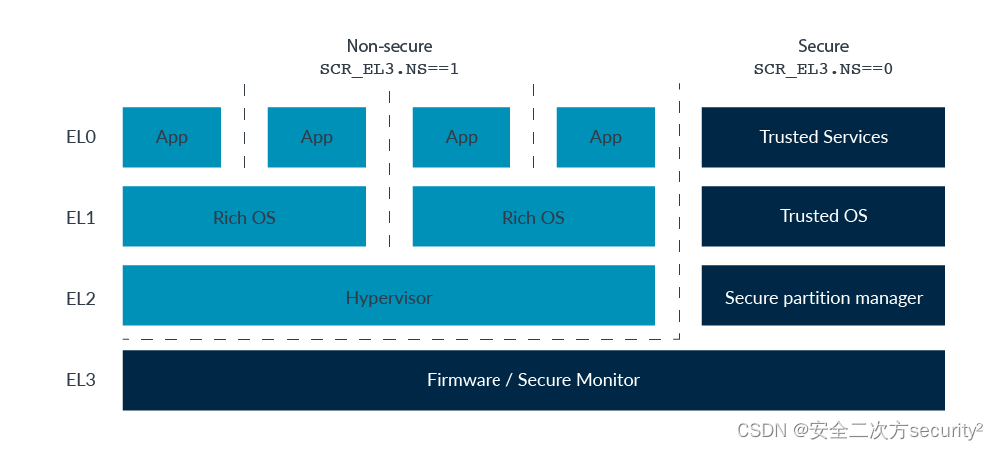
处理器中的TrustZone之安全状态
在这篇博客中,我们将讨论处理器内对TrustZone的支持。其他部分则涵盖了在内存系统中的支持,以及建立在处理器和内存系统支持基础上的软件情况。 3.1 安全状态 在Arm架构中,有两个安全状态:安全状态和非安全状态。这些安全状态映射…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...

LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼
LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼 【免费下载链接】LrcHelper 从网易云音乐下载带翻译的歌词 Walkman 适配 项目地址: https://gitcode.com/gh_mirrors/lr/LrcHelper 你是否曾为找不到心爱歌曲的歌词而烦恼?或…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...

如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程
如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本(Onmyoji Auto Script,…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

基于PyPortal与CircuitPython的物联网游戏数据显示器开发实战
1. 项目概述 如果你和我一样,既是《英雄联盟》的忠实玩家,又对嵌入式硬件开发充满热情,那么把这两者结合起来,做一个能实时展示自己召唤师等级的“实体奖杯”,绝对是一件既酷又有成就感的事情。这个项目就是基于Adafr…...

【最新 v2.7.1 版本安装包】零基础也能流畅使用,OpenClaw 无需命令一键部署保姆级教程
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...