深度学习TensorFlow2基础知识学习后半部分
介绍几个重要操作:
1.范数
a = tf.fill([1,2], value=2.)
b = tf.norm(a)# 二范数#第二种计算方法
# 计算验证
a = tf.square(a)
log("a的平方:", a)
a = tf.reduce_sum(a)
log("a平方后的和:", a)
b = tf.sqrt(a)
log("a平方和后开根号:", b)#二者结果是一样的b = tf.norm(a,ord=1)#一范数
print(b)
print(tf.reduce_sum(tf.abs(a)))#所有值得绝对值之和
# 指定计算轴:axis=1
b = tf.norm(a, ord=1, axis=1)
log("a的axis=1的1范数b:", b)
2.最大最小平均值的计算
a = tf.range(12, dtype=tf.float32)
a = tf.reshape(a, (4,3))
log("a数组:", a)b = tf.reduce_min(a)
log("a数组最小值:", b)
b = tf.reduce_max(a)
log("a数组最大值:", b)
b = tf.reduce_mean(a)
log("a数组平均值:", b)b = tf.reduce_min(a, axis=0)
log("a数组axis=0最小值:", b)
b = tf.reduce_max(a, axis=0)
log("a数组axis=0最大值:", b)
b = tf.reduce_mean(a, axis=0)
log("a数组axis=0平均值:", b)b = tf.reduce_min(a, axis=1)
log("a数组axis=1最小值:", b)
b = tf.reduce_max(a, axis=1)
log("a数组axis=1最大值:", b)
b = tf.reduce_mean(a, axis=1)
log("a数组axis=1平均值:", b)其实都挺简单的,和numpy和torch都差不多。
3.索引
- tf.argmax
- tf.argmin
def log(prefix="", val=""):print(prefix, val, "\n")# 定义一个随机数组
a = tf.random.uniform((3,10), minval=0, maxval=10, dtype=tf.int32)
log("a", a)# 取最大索引位置数组,通常用于取得模型预测结果
b = tf.argmax(a, axis=1)
log("a数组axis=1的最大值索引位置:", b)# 取最小索引位置数组
b = tf.argmin(a, axis=1)
log("a数组axis=1的最小值索引位置:", b)4.数组比较
一些python基础语法
a = tf.random.uniform((1,10), minval=0, maxval=10, dtype=tf.int32)
b = tf.random.uniform((1,10), minval=0, maxval=10, dtype=tf.int32)log("a:", a)
log("b:", b)# a,b数组比较
log("a==b", a==b)
# 相同元素输出
log(a[a==b])
# 相同元素索引位置输出
log(tf.where(a==b))5.张量排序
- 张量数值排序:tf.sort
- 张量索引排序:tf.argsort
#################################################
# 声明数组a
a = tf.random.shuffle(tf.range(10))
log("a", a)
# a tf.Tensor([8 2 0 5 7 9 3 1 4 6], shape=(10,), dtype=int32) #################################################
# 升序排列
b = tf.sort(a, direction="ASCENDING")
log("b", b)
# 降序排列
b = tf.sort(a, direction="DESCENDING")
log("b", b)
# b tf.Tensor([0 1 2 3 4 5 6 7 8 9], shape=(10,), dtype=int32)
# b tf.Tensor([9 8 7 6 5 4 3 2 1 0], shape=(10,), dtype=int32) #################################################
# 升序排列,返回索引位置
b = tf.argsort(a, direction="ASCENDING")
log("b", b)
# 降序排列,返回索引位置
b = tf.argsort(a, direction="DESCENDING")
log("b", b)
# b tf.Tensor([2 7 1 6 8 3 9 4 0 5], shape=(10,), dtype=int32)
# b tf.Tensor([5 0 4 9 3 8 6 1 7 2], shape=(10,), dtype=int32) #################################################
# 按索引位置b, 从数组a中收集数据
c = tf.gather(a, b)
log("c", c)
# c tf.Tensor([9 8 7 6 5 4 3 2 1 0], shape=(10,), dtype=int32) 6.二维张量排序
- 2维张量数值排序:tf.sort
- 2维张量索引排序:tf.argsort
#################################################
# 声明2维数组a
a = tf.random.uniform([3,5], maxval=10, dtype=tf.int32)
log("a", a)
# a tf.Tensor(
# [[2 5 8 0 4]
# [1 7 2 4 5]
# [6 0 2 5 0]], shape=(3, 5), dtype=int32) #################################################
# 升序排列
b = tf.sort(a, axis=1, direction="ASCENDING")
log("b", b)
# 降序排列
b = tf.sort(a, axis=1, direction="DESCENDING")
log("b", b)
# b tf.Tensor(
# [[0 2 4 5 8]
# [1 2 4 5 7]
# [0 0 2 5 6]], shape=(3, 5), dtype=int32)
# b tf.Tensor(
# [[8 5 4 2 0]
# [7 5 4 2 1]
# [6 5 2 0 0]], shape=(3, 5), dtype=int32) #################################################
# 升序排列,返回索引位置
b = tf.argsort(a, axis=1, direction="ASCENDING")
log("b", b)
# 降序排列,返回索引位置
b = tf.argsort(a, axis=1, direction="DESCENDING")
log("b", b)
# b tf.Tensor(
# [[3 0 4 1 2]
# [0 2 3 4 1]
# [1 4 2 3 0]], shape=(3, 5), dtype=int32)
# b tf.Tensor(
# [[2 1 4 0 3]
# [1 4 3 2 0]
# [0 3 2 1 4]], shape=(3, 5), dtype=int32) 7.TopK值取得
################################################
# 2维数组定义
a = tf.random.uniform([3,5], maxval=10, dtype=tf.int32)
log("a", a)
# a tf.Tensor(
# [[1 2 5 8 7]
# [6 1 4 3 9]
# [5 9 6 5 5]], shape=(3, 5), dtype=int32) #################################################
# 取数组每行前3位
b = tf.math.top_k(a, k=3, sorted=True)
# 前3位数值
log("b", b.values)
# 前3位数值索引
log("b", b.indices)# b tf.Tensor(
# [[8 7 5]
# [9 6 4]
# [9 6 5]], shape=(3, 3), dtype=int32)
# b tf.Tensor(
# [[3 4 2]
# [4 0 2]
# [1 2 0]], shape=(3, 3), dtype=int32) 相关文章:

深度学习TensorFlow2基础知识学习后半部分
介绍几个重要操作: 1.范数 a tf.fill([1,2], value2.) b tf.norm(a)# 二范数#第二种计算方法 # 计算验证 a tf.square(a) log("a的平方:", a) a tf.reduce_sum(a) log("a平方后的和:", a) b tf.sqrt(a) log("a平方和后开根号:"…...
电脑系统重装Win10专业版操作教程
用户想给自己的电脑重新安装上Win10专业版系统,但不知道具体的重装步骤。接下来小编将详细介绍Win10系统重新安装的步骤方法,帮助更多的用户完成Win10专业版的重装,重装后用户即可体验到Win10专业版系统带来的丰富功能。 准备工作 1. 一台正常…...

打包Python项目
打包Python项目 本教程将指导您如何打包一个简单的Python项目。它将 向您展示如何添加必要的文件和结构来创建包,如何 构建包,以及如何将其上传到Python包索引(PyPI)。 尖端 如果您在运行本教程中的命令时遇到问题,请…...

使用Python实现爬虫IP负载均衡和高可用集群
做大型爬虫项目经常遇到请求频率过高的问题,这里需要说的是使用爬虫IP可以提高抓取效率,那么我们通过什么方法才能实现爬虫IP负载均衡和高可用集群,并且能快速的部署并且完成爬虫项目。 通常在Python中实现爬虫ip负载均衡和高可用集群需要一…...
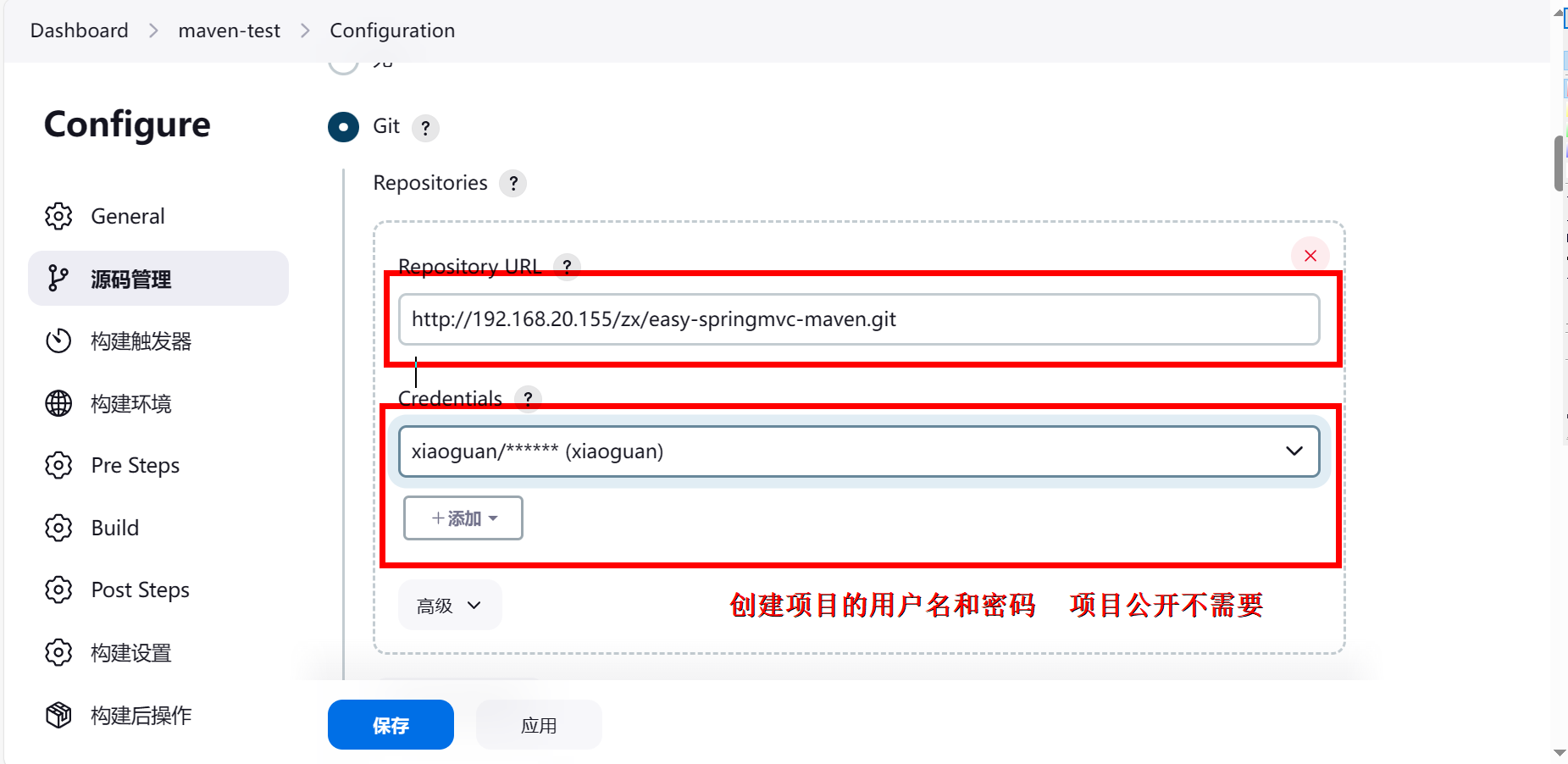
Jenkins+Maven+Gitlab+Tomcat 自动化构建打包,部署
环境准备 1、安装服务 Jenkins工具、环境、插件配置 全局变量配置 Manage Jenkins>tools>JDK 安装 安装插件 Deploy to container 安装此插件,才能将打好的包部署到tomcat上 配置国内mvn源 创建maven项目 1 2 3 4 5 6 7 8 9 10...
泰凌微(Telink)8258配置串口收发自定义数据
在官网下载SDK后(以Mesh SDK为例)使用Eclipse打开,对应MCU的配置文件在app_config_8258.h,默认的HCI接口是HCI_USE_NONE,如果改成HCI_USE_UART后可以通过串口收发数据,此时默认接收函数处理的是以Telink的协…...

入门低代码开发:快速构建应用程序的方法
一、什么是低代码 低代码开发是一种通过可视化建模和拖拽式设计工具来快速构建应用程序的方法。传统软件开发通常需要编写大量的代码,而低代码开发则提供了更高层次的抽象,使开发过程更加简单和高效。通过可视化界面,用户可以通过拖拽组件、配…...

常见客户端消息推送服务【Java后端】
客户端消息推送 1、推送服务 苹果 APNs(Apple Push Notification service) 谷歌 FCM(Firebase Cloud Messaging)GCM(Google Cloud Messaging) 第三方 个推(Getui)UniAppÿ…...

C++11(下)
可变参数模板 C11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板. 相比C98/03, 类模版和函数模版中只能含固定数量的模版参数, 可变模版参数无疑是一个巨大的改进, 然而由于可变模版参数比较抽象, 使用起来需要一定的技巧, 所以这块还是比较晦涩的.掌握一些基…...

深度学习与逻辑回归模型的融合--TensorFlow多元分类的高级应用
手写数字识别 文章目录 手写数字识别1、线性回归VS逻辑回归Sigmoid函数 2、逻辑回归的基本模型-神经网络模型3、多元分类基本模型4、TensorFlow实战解决手写数字识别问题准备数据集数据集划分 特征数据归一化归一化方法归一化场景 标签数据独热编码One-Hot编码构建模型损失函数…...

水库大坝安全监测参数与设备
智慧水利中,水库大坝的安全监测必不可少。做好水库大坝的安全监测,是确保水库大坝结构安全和预防灾害的重要手段。对于预防灾害、保护人民生命财产安全、优化工程管理、改进工程设计、保护环境资源和提高公众信任等方面有着重要的意义。 水利水库大坝安全…...

要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示 情感分析是一种可以让模型确定一段文字的情感基调或态度的技术,比如它是正面的、负面的还是中性的。 要在 ChatGPT 中使用情感分析提示,应向模型提…...

数据清洗、特征工程和数据可视化、数据挖掘与建模的主要内容
1.4 数据清洗、特征工程和数据可视化、数据挖掘与建模的内容 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.4节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学…...

C++ STL容器与常用库函数
STL是提高C编写效率的一个利器 STL容器: 一、#include <vector> 英文翻译:vector :向量 vector是变长数组(动态变化),支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾…...

Nmap脚本简介
什么是Nmap脚本 Nmap脚本是一种由Nmap扫描器使用的脚本语言,用于扫描目标网络中的主机、端口、服务等信息,并提供一系列自动化的测试和攻击功能。从渗透测试工程师的角度来看,Nmap脚本是一种非常有用的工具,能够帮助渗透测试工程师…...
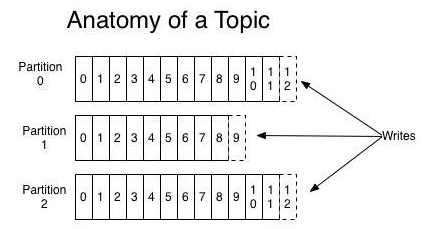
Kafka -- 初识
目录 kafka是什么 Topic Partition Broker Cousumer CousumerGroup Offset reblance broker 消息存储 Isr kafka是什么 Kafka 是一个分布式的消息引擎,能够发布和订阅消息流(类似于消息队列) 以容错的、持久的方式存储消息流 多分区…...

玩转Sass:掌握数据类型!
当我们在进行前端开发的时候,有时候需要使用一些不同的数据类型来处理样式,Sass 提供的这些数据类型可以帮助我们更高效地进行样式开发,本篇文章将为您详细介绍 Sass 中的数据类型。 布尔类型 在 Sass 中,布尔数据类型可以表示逻…...

Django + Matplotlib:实现数据分析显示与下载为PDF或SVG
写作背景 首先,数据分析在当前的信息时代中扮演着重要的角色。随着数据量的增加和复杂性的提高,人们对于数据分析的需求也越来越高。 其次,笔者也确确实实曾经接到过一个这样的开发需求,甲方是一个医疗方面的科研团队࿰…...

【Rust】第一节:安装
1 说明 一些学习记录 环境:MacOS 2 步骤 1、执行curl --proto https --tlsv1.2 https://sh.rustup.rs -sSf | sh 2、看到打印 info: downloading installerWelcome to Rust!... ...This path will then be added to your PATH environment variable by modifyin…...
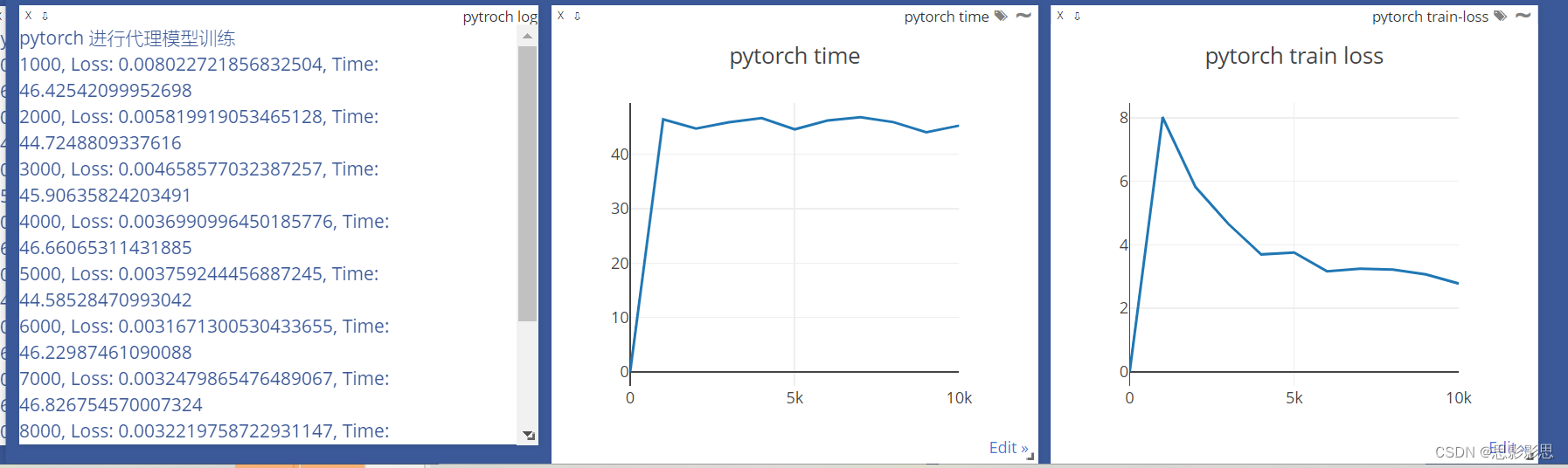
12-07 周四 Pytorch 使用Visdom 进行可视化
简介 在完成了龙良曲的Pytroch视频课程之后,楼主对于pytroch有了进一步的理解,比如,比之前更加深刻的了解了BP神经网络的反向传播算法,梯度、损失、优化器这些名词更加熟悉。这个博客简要介绍一下在使用Pytorch进行数据可视化的一…...

一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单
一键获取Steam游戏清单:Onekey工具让游戏管理变得如此简单 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 你是否曾为管理Steam游戏文件而烦恼?想备份心爱的游戏却不知从…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备
Netgear路由器终极救援指南:用nmrpflash免费快速修复变砖设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器在固件升级过程中意外断电,或者刷入错误固件导致…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

Boss直聘职位数据自动化采集:Python爬虫架构设计与工程实践
1. 项目概述与核心价值最近在技术社区里,看到不少朋友在讨论一个叫longsizhuo/BossZhiPin_Job_Search的项目。光看名字,你大概就能猜到,这是一个跟“Boss直聘”和“职位搜索”相关的自动化工具。作为一个在招聘数据分析和自动化领域摸爬滚打了…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...