Revisiting Proposal-based Object Detection阅读笔记
Revisiting Proposal-based Object Detection阅读笔记
论文地址:link
Abstract
For any object detector, the obtained box proposals or queries need to be classified and regressed towards ground truth boxes.
对于任何物体检测器来说,获得的 box proposals或queries需要被分类并回归到真实框上。(也就是对于每个预测框与要找到相对应的GT)
The common solution for the final predictions is to directly maximize the overlap between each proposal and the ground truth box, followed by a winner-takes-all ranking or non-maximum suppression.
常见的最终预测解决方案是直接最大化每个proposal与真实框之间的重叠,然后通过winner-takes-all ranking或非最大值抑制进行分类。
本文提出了一个简单有效的替代方案。
对于Proposals回归,即回归到Proposals和真实边界框之间的交集区域。
交集区域就是Proposal中包含GT也就是目标的区域。
通过这种方式,每个Proposal只指定包含物体的部分,避免了一个盲目的修复问题,即需要将proposal回归到它们的视觉范围之外。反过来,我们替换了胜者通吃策略,并通过取一个围绕物体的proposal group的回归交集的并集来获得最终预测。

Introduction
文中提到目前物体检测常见设置的两个问题,并提出了一个简单的解决方案。
- 首先,任何物体检测器的目标,例如 [6, 34, 35],无论其架构如何,都是要准确地学习独立代表图像中真实物体的提议框。正如图1中所强调的,这通常是一个提出不当的问题。在检测器的前向传播过程中,生成的提议框通常只捕获其范围内的部分真实物体。学习进行完美的真实物体对齐导致了一个盲目的内部绘制挑战。
- 其次,在所有检测器的前向传播过程中,一个常见的现象是,总是有多个提议或查询与一个真实物体相关。==尽管它们为真实物体提供了互补的视角,但非最大值抑制或排名只是为了排除重复的检测。==这样做的同时,这些方法忽视了被丢弃提议中的宝贵信息。
本文decompose the problems of proposal-to-ground truth regression and proposal candidate selection into easier to solve intersection and union problems.
proposal-to-GT: intersection
proposal candidate: union
- Intersection-based Regression
我们为提议的回归设定了一个新目标:不是预测与真实物体的重叠,而是仅预测交集区域。因此,我们只在proposal的视觉范围内向真实物体回归。
- Intersection-based Groupin
给定一组预测了真实物体交集的提议,我们通过取交集区域的并集形成最终预测。换句话说,我们不仅选择一个区域中最有信心的提议,而是we use the wisdom of the crowd to form our final predictions.
这两个阶段对现有物体检测流程的改变很小。我们只改变了回归头目标为交集,并修改了winner-takes-all的后处理过程,加入了一个分组过程。因此,我们的方法可以直接插入到任何物体检测器中。尽管技术上简单,提出的分解直接提高了检测性能。我们展示了我们重新审视的方法如何提高多个数据集上的典型检测和实例分割方法,特别是在评估时的高重叠阈值
Method
Problem statement:
传统regression存在问题:the proposal boxes P are commonly badly aligned, with only a part of the ground truth G visible in the scope of the proposal. Consequently, the function f is compelled to extend P to regions beyond its initial coverage, essentially requiring it to predict beyond its visible scope. This scenario leads to an ill-posed problem
传统的proposal regression会将proposal拓展,像GT去回归,这本质上要求它预测超出其可见范围的部分。这种情况导致了一个不恰当的问题,因为 f 被迫推断出 P 内部不包含的 G 的部分。
记录Problem statement写作样本:
Problem statement
In traditional object detection, bounding box regression involves learning a mapping function
fthat transforms a proposal boxP=(P_{x1}, P_{y1}, P_{x2}, P_{y2})to closely approximate a ground truth boxG=(G_{x1}, G_{y1}, G_{x2}, G_{y2}), where(x1, y1, x2, y2)refers to the top-leftxandycoordinates and bottom-rightxandycoordinates respectively. Typically, this is achieved by minimizing theL1orL2loss between the predicted box and the ground truth. However, this approach often poses a challenge: the proposal boxesPare commonly badly aligned, with only a part of the ground truthGvisible in the scope of the proposal. Consequently, the functionfis compelled to extendPto regions beyond its initial coverage, essentially requiring it to predict beyond its visible scope. This scenario leads to an ill-posed problem, asfis forced to infer parts ofGnot contained withinP. Then, the set of all proposals for a ground truth objectP={P_1, P_2, ..., P_n}, providing complementary views, are sorted and only one candidate is picked via non-maximum suppression or ranking. This assumes that the intersection-over-union problem is already solved and only serves to exclude duplicate detections in the same region.To address these issues, first, we redefine the task as an intersection learning problem in Section 3.1. For individual proposal boxes, we only require solving the intersection alignment with ground truth boxes, i.e. we only need to regress to the part of the proposal that is shared with the ground truth. Then, instead of discarding complementary information from proposals, our method strategically learns to leverage these fragments in Section 3.2. Given a collection of proposal boxes and their identified intersection, we can replace the non-maximum suppression with a union operator, where we identify the final object as the union-over-intersection of all the proposals in the same region. Figure 2 shows how these two simpler tasks lead to a final object detection.
问题陈述
在传统的目标检测中,边界框回归涉及学习一个映射函数
f,该函数将一个提议框P=(P_{x1}, P_{y1}, P_{x2}, P_{y2})转换为与真实框G=(G_{x1}, G_{y1}, G_{x2}, G_{y2})非常接近,其中(x1, y1, x2, y2)分别指的是左上角的x和y坐标以及右下角的x和y坐标。通常,这是通过最小化预测框和真实框之间的L1或L2损失来实现的。然而,这种方法经常带来挑战:提议框P通常对齐得很差,只有部分真实物体G在提议的范围内可见。因此,函数f被迫将P扩展到其最初覆盖范围之外的区域,本质上要求它预测超出其可见范围的部分。这种情况导致了一个不恰当的问题,因为f被迫推断出P内部不包含的G的部分。然后,为一个真实物体G的所有提议P={P_1, P_2, ..., P_n}提供补充视角,它们被排序,并且通过非最大值抑制或排名只选择一个候选。这假设交并比问题已经解决,只是为了排除同一区域内的重复检测。为了解决这些问题,首先,我们在第3.1节中将任务重新定义为一个交集学习问题。对于单个提议框,我们只需要解决与真实框的交集对齐问题,即我们只需要回归到proposals与真实物体共享的部分。然后,我们的方法不是丢弃提议中的补充信息,而是在第3.2节中策略性地学习利用这些碎片。鉴于一系列提议框及其识别的交集,我们可以用并集操作符替换非最大值抑制,在这个操作符中,我们将最终物体识别为同一区域内所有提议的交集上的并集。图2展示了这两个更简单的任务是如何导致最终的目标检测的。

3.1 基于交集的回归
我们将回归任务重新定义为一个交集学习问题。与其回归到整个真实框,每个提议框的任务是仅回归到真实物体可见的部分,即提议框与真实框之间的交集。这使得映射函数 f 更加明确定义,从而更容易学习这样的转换。
设 I=(I_{x1}, I_{y1}, I_{x2}, I_{y2}) 为提议框 P 与真实框 G 的交集。新的任务是学习一个映射函数 f',使得 f'(P) ≈ I。为了监督目的,交集按以下方式计算:
I_{x1} = max(P_{x1}, G_{x1}), (1)
I_{y1} = max(P_{y1}, G_{y1}), (2)
I_{x2} = min(P_{x2}, G_{x2}), (3)
I_{y2} = min(P_{y2}, G_{y2}). (4)
这个任务的损失函数定义为:
L_t = ∑|f'(P_i) - I_{t_i}|, (5)
其中 t 取值1或2,分别对应于回归训练中应用 L1 或 L2 损失。
我们方法的第二个方面涉及策略性地利用为单一真实物体生成的多个提议框中包含的部分信息。
3.2 基于交集的分组
在传统的目标检测方法中,通常选择一个提议来代表最终检测,而其余的提议则被丢弃。我们的方法不是丢弃这些包含有价值但碎片化信息的提议,而是学会有效地合并这些片段。因此,我们的方法产生了一个更全面准确的真实物体的表征。
公式化
让我们将所有为一个真实物体提出的提议集合表示为 P={P_1, P_2, ..., P_n},与真实物体相交的对应交集表示为 T={I_1, I_2, ..., I_n}。我们的目标是找到这些交集的组合,最好地代表真实物体。我们定义一个组合函数 c : T → R^4,它接受一组交集并输出一个边界框。任务是学习这个函数,以最小化组合框和真实框 G 之间的损失:
L = ∑ |c_i(T) - G_i| . (6)
我们的模型旨在通过交集回归理解提议的部分性质。交集的组合分为两个阶段:分组和回归,如下所述。
分组
为了执行分组,我们引入一个分组函数 g : P → G,将proposals P 映射到一组组 G={g_1, g_2, ..., g_m}。每个组 g_j 是 P 的一个子集,并代表图像中的潜在物体。分组函数旨在将可能属于同一物体的proposals分组在一起。这是通过考虑提议之间的空间重叠和语义相似性来实现的。一旦提议被分组,我们结合每个组的提议对应的交集,得到一组组合框 B={B_1, B_2, ..., B_m}。每个组合框 B_j 是由组 g_j 代表的物体的候选边界框。
精炼
最后,我们执行一个回归步骤来精炼组合框。我们定义一个回归函数 r : B → R,将每个组合框映射到最终的目标框。回归函数学习最小化目标框和真实框之间的损失:
L = ∑ ∑ |r(B_{ji}) - T_{ji}| , (7)
其中 B_{ji} 是组合框 B_j 的第 i 个坐标,T_{ji} 是对应于 B_j 的真实框的第 i 个坐标。这种方法使得可以将多个提议中的有价值信息整合到一个增强的提议中。我们的方法不是选择一个最优候选并丢弃其他所有候选,而是提取并合并每个提议中最相关的方面,从而构建一个更准确代表目标真实物体的优越候选。
将这种分解整合到现有的目标检测器中只需要做少量的改动。对于基于交集的回归,我们只需要改变回归头中的目标坐标,从真实框改为提议和真实物体之间的交集区域。为了通过基于交集的分组获得最终的目标检测输出,我们对提议进行排序和聚类,类似于非最大值抑制。我们不仅保留最上面的框,还取同一簇中回归交集的并集作为输出。尽管这种方法的简单性,我们展示了在目标检测中分解交并比对齐直接影响性能。
相关文章:
Revisiting Proposal-based Object Detection阅读笔记
Revisiting Proposal-based Object Detection阅读笔记 论文地址:link Abstract For any object detector, the obtained box proposals or queries need to be classified and regressed towards ground truth boxes. 对于任何物体检测器来说,获得的…...

Docker部署NFS服务
创建基础镜像 mkdir /data/nfs -p chmod 755 /data/nfs# NFS默认端口: 111、2049、20048 docker run -d \ --privileged \ --name nfs_server \ -p 111:111/tcp \ -p 111:111/udp \ -p 2049:2049/tcp \ -p 2049:2049/udp \ -p 30001-30005:30001-30005/tcp \ -p 30001-30005:3…...

深度学习TensorFlow2基础知识学习后半部分
介绍几个重要操作: 1.范数 a tf.fill([1,2], value2.) b tf.norm(a)# 二范数#第二种计算方法 # 计算验证 a tf.square(a) log("a的平方:", a) a tf.reduce_sum(a) log("a平方后的和:", a) b tf.sqrt(a) log("a平方和后开根号:"…...
电脑系统重装Win10专业版操作教程
用户想给自己的电脑重新安装上Win10专业版系统,但不知道具体的重装步骤。接下来小编将详细介绍Win10系统重新安装的步骤方法,帮助更多的用户完成Win10专业版的重装,重装后用户即可体验到Win10专业版系统带来的丰富功能。 准备工作 1. 一台正常…...

打包Python项目
打包Python项目 本教程将指导您如何打包一个简单的Python项目。它将 向您展示如何添加必要的文件和结构来创建包,如何 构建包,以及如何将其上传到Python包索引(PyPI)。 尖端 如果您在运行本教程中的命令时遇到问题,请…...

使用Python实现爬虫IP负载均衡和高可用集群
做大型爬虫项目经常遇到请求频率过高的问题,这里需要说的是使用爬虫IP可以提高抓取效率,那么我们通过什么方法才能实现爬虫IP负载均衡和高可用集群,并且能快速的部署并且完成爬虫项目。 通常在Python中实现爬虫ip负载均衡和高可用集群需要一…...
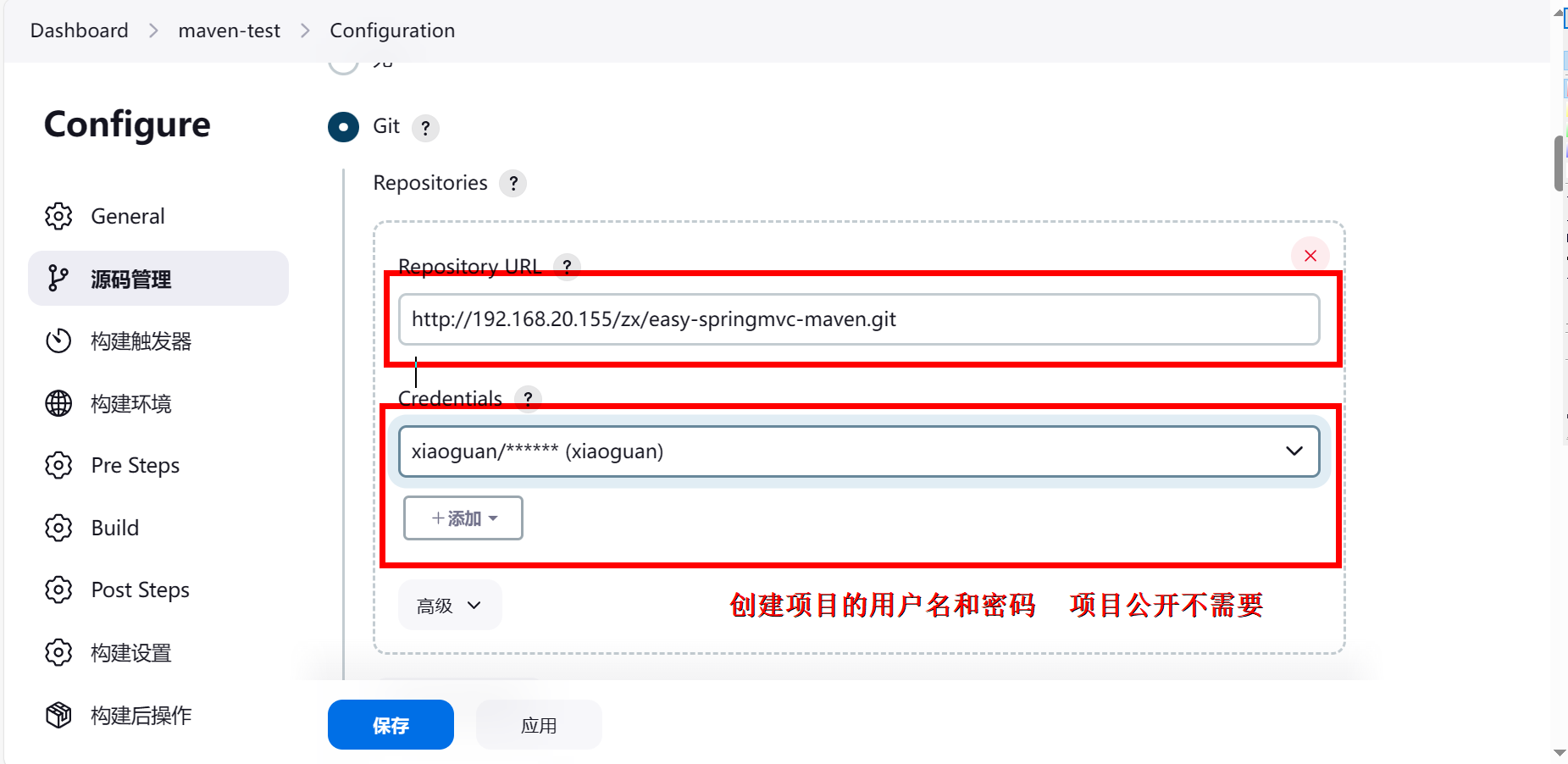
Jenkins+Maven+Gitlab+Tomcat 自动化构建打包,部署
环境准备 1、安装服务 Jenkins工具、环境、插件配置 全局变量配置 Manage Jenkins>tools>JDK 安装 安装插件 Deploy to container 安装此插件,才能将打好的包部署到tomcat上 配置国内mvn源 创建maven项目 1 2 3 4 5 6 7 8 9 10...
泰凌微(Telink)8258配置串口收发自定义数据
在官网下载SDK后(以Mesh SDK为例)使用Eclipse打开,对应MCU的配置文件在app_config_8258.h,默认的HCI接口是HCI_USE_NONE,如果改成HCI_USE_UART后可以通过串口收发数据,此时默认接收函数处理的是以Telink的协…...

入门低代码开发:快速构建应用程序的方法
一、什么是低代码 低代码开发是一种通过可视化建模和拖拽式设计工具来快速构建应用程序的方法。传统软件开发通常需要编写大量的代码,而低代码开发则提供了更高层次的抽象,使开发过程更加简单和高效。通过可视化界面,用户可以通过拖拽组件、配…...

常见客户端消息推送服务【Java后端】
客户端消息推送 1、推送服务 苹果 APNs(Apple Push Notification service) 谷歌 FCM(Firebase Cloud Messaging)GCM(Google Cloud Messaging) 第三方 个推(Getui)UniAppÿ…...

C++11(下)
可变参数模板 C11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板. 相比C98/03, 类模版和函数模版中只能含固定数量的模版参数, 可变模版参数无疑是一个巨大的改进, 然而由于可变模版参数比较抽象, 使用起来需要一定的技巧, 所以这块还是比较晦涩的.掌握一些基…...

深度学习与逻辑回归模型的融合--TensorFlow多元分类的高级应用
手写数字识别 文章目录 手写数字识别1、线性回归VS逻辑回归Sigmoid函数 2、逻辑回归的基本模型-神经网络模型3、多元分类基本模型4、TensorFlow实战解决手写数字识别问题准备数据集数据集划分 特征数据归一化归一化方法归一化场景 标签数据独热编码One-Hot编码构建模型损失函数…...

水库大坝安全监测参数与设备
智慧水利中,水库大坝的安全监测必不可少。做好水库大坝的安全监测,是确保水库大坝结构安全和预防灾害的重要手段。对于预防灾害、保护人民生命财产安全、优化工程管理、改进工程设计、保护环境资源和提高公众信任等方面有着重要的意义。 水利水库大坝安全…...

要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 22 章:情感分析提示 情感分析是一种可以让模型确定一段文字的情感基调或态度的技术,比如它是正面的、负面的还是中性的。 要在 ChatGPT 中使用情感分析提示,应向模型提…...

数据清洗、特征工程和数据可视化、数据挖掘与建模的主要内容
1.4 数据清洗、特征工程和数据可视化、数据挖掘与建模的内容 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.4节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学…...

C++ STL容器与常用库函数
STL是提高C编写效率的一个利器 STL容器: 一、#include <vector> 英文翻译:vector :向量 vector是变长数组(动态变化),支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾…...

Nmap脚本简介
什么是Nmap脚本 Nmap脚本是一种由Nmap扫描器使用的脚本语言,用于扫描目标网络中的主机、端口、服务等信息,并提供一系列自动化的测试和攻击功能。从渗透测试工程师的角度来看,Nmap脚本是一种非常有用的工具,能够帮助渗透测试工程师…...
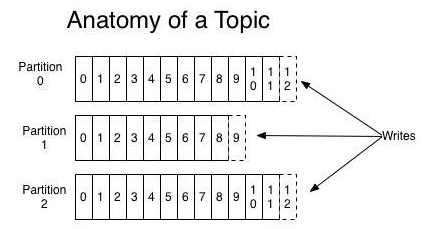
Kafka -- 初识
目录 kafka是什么 Topic Partition Broker Cousumer CousumerGroup Offset reblance broker 消息存储 Isr kafka是什么 Kafka 是一个分布式的消息引擎,能够发布和订阅消息流(类似于消息队列) 以容错的、持久的方式存储消息流 多分区…...

玩转Sass:掌握数据类型!
当我们在进行前端开发的时候,有时候需要使用一些不同的数据类型来处理样式,Sass 提供的这些数据类型可以帮助我们更高效地进行样式开发,本篇文章将为您详细介绍 Sass 中的数据类型。 布尔类型 在 Sass 中,布尔数据类型可以表示逻…...

Django + Matplotlib:实现数据分析显示与下载为PDF或SVG
写作背景 首先,数据分析在当前的信息时代中扮演着重要的角色。随着数据量的增加和复杂性的提高,人们对于数据分析的需求也越来越高。 其次,笔者也确确实实曾经接到过一个这样的开发需求,甲方是一个医疗方面的科研团队࿰…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...

嵌入式测试学习第 12天:串口基础概念:UART、波特率、数据位、校验位
串口基础概念:UART、波特率、数据位、校验位一、串口整体基础概念1、什么是UART串口2、串口实物真实图片① 主板/开发板排针串口② USB转TTL串口模块③ 老式DB9工业串口公头母头二、串口四大核心参数1、波特率概念常用标准固定值通俗理解测试场景2、数据位概念作用3…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

3个技巧让SD-PPP插件提升Photoshop设计效率300%
3个技巧让SD-PPP插件提升Photoshop设计效率300% 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 还在为Photoshop和AI工具之间的频繁切换而烦恼吗?每次都要导出PSD、上传到AI平台、等待生成、再导回Phot…...

复杂系统交付中的风险治理与经济模型转型
1. 复杂系统交付中的风险本质与治理转型在航空航天、国防军工等复杂系统开发领域,项目失败率长期居高不下。根据IBM对全球500个大型系统的调研,73%的项目存在严重进度延迟,平均超支达到原始预算的189%。这种系统性失效的根源在于传统工程治理…...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...