Spring Kafka常用配置详解
目录
- 前言
- producer配置
- consumer 配置
- listener 配置
前言
在 Spring Kafka 中,主要的配置分为三大块,分别是producer、consumer、listener,下面我们就按模块介绍各个模块的常用配置
producer配置
在 Spring Kafka 中,spring.kafka.producer 用于配置 Kafka 生产者相关属性。下面是一些常用的 spring.kafka.producer 配置项的详解:
spring.kafka.producer.bootstrap-servers: 指定 Kafka 服务器的地址列表,格式为 host:port,多个地址使用逗号分隔。
spring.kafka.producer.key-serializer: 用于配置 Kafka 生产者发送消息中键(key)的序列化器。可以是字符串形式的完全限定类名,也可以是一个实现 org.apache.kafka.common.serialization.Serializer 接口的自定义序列化器类。
常见的键序列化器包括:
org.apache.kafka.common.serialization.StringSerializer:将键对象作为字符串进行序列化。
org.apache.kafka.common.serialization.IntegerSerializer:将键对象作为整数进行序列化。
org.apache.kafka.common.serialization.ByteArraySerializer:将键对象直接作为字节数组进行序列化。
自定义的序列化器:根据自己的需求实现键的序列化逻辑。
在 Kafka 中,每条消息都由一个键(key)和一个值(value)组成。键是一个可选的、用于标识消息的数据,而值则是实际的消息内容。在发送消息时,Kafka 生产者需要将键和值进行序列化,以便能够在网络上传输和存储到 Kafka 服务器。
spring.kafka.producer.value-serializer: 用于配置 Kafka 生产者发送消息中值(value)的序列化器类,用法同上。
spring.kafka.producer.acks:生产者发送消息的确认模式。可选的值有 “0”(不需要任何确认)、“1”(只需要 Leader 确认)和 “all”(需要 Leader 和所有副本确认)。
spring.kafka.producer.retries:配置生产者在发生错误时的重试次数。
spring.kafka.producer.retry-backoff-ms:配置重试之间的延迟时间(默认为 100 毫秒)。重试的间隔时间会随着重试次数的增加而指数级增长,以避免过度负载和大量的重复请求。
spring.kafka.producer.batch-size:配置每个批次中包含的消息大小。当应用程序使用 Kafka 生产者发送消息时,发送单个消息可能会带来一些性能开销。为了减少这种开销,可以将多个消息进行批量发送。spring.kafka.producer.batch-size 参数就是用来指定每个批次中包含的消息大小。
spring.kafka.producer.buffer-memory:用于配置 Kafka 生产者的缓冲区内存大小的属性,Kafka 生产者在发送消息时,不会立即将消息发送到服务器,而是先将消息缓存在生产者的缓冲区中。当缓冲区中的消息达到一定大小或达到一定时间限制时,生产者才会批量地将消息发送到 Kafka 服务器。
该参数的单位是字节,默认值是 33554432 字节(32MB)。
spring.kafka.producer.client-id:配置生产者的客户端 ID,如果你没有显式地设置该属性,则 Kafka 生产者会自动生成一个随机的客户端 ID。使用自定义的客户端 ID 可以帮助你更好地追踪和监控不同的生产者实例
spring.kafka.producer.compression-type:指定生产者使用的消息压缩类型
常见的压缩类型包括:
none:表示不使用压缩,消息以原始的形式发送。
gzip:表示使用 GZIP 压缩算法对消息内容进行压缩。
snappy:表示使用 Snappy 压缩算法对消息内容进行压缩。
lz4:表示使用 LZ4 压缩算法对消息内容进行压缩。
spring.kafka.producer.enable-idempotence:启用生产者的幂等性,确保消息的唯一性和顺序性。
在消息系统中,幂等性是指多次执行同一个操作所产生的影响与执行一次操作的影响相同。而在 Kafka 中,启用幂等性可以确保生产者发送的消息具有幂等性特性,即无论发送多少次相同的消息,最终的影响都是一样的。
启用幂等性可以提供以下好处:
1、消息去重:当生产者发送重复的消息时,Kafka 会自动去重,保证只有一条消息被写入。
2、顺序保证:Kafka 会确保相同键的消息按照发送顺序进行处理,保证消息的顺序性。
3、提高可靠性:当发生网络故障或生产者重试时,启用幂等性可以确保消息不会被重复发送,避免出现重复消费的问题。
需要注意的是,启用幂等性会对性能产生一定的影响,因为 Kafka 生产者会为每个分区维护序列号和重试缓冲区。因此,在性能和可靠性之间需要进行权衡,根据具体的业务需求来决定是否启用幂等性。
spring.kafka.producer.max-in-flight-requests-per-connection:指定在单个连接上允许的未完成请求的最大数目。
consumer 配置
pring.kafka.consumer 用于配置 Kafka 消费者相关属性,下面是一些常见的 spring.kafka.consumer 配置属性及其作用:
spring.kafka.consumer.bootstrap-servers:指定 Kafka 服务器的地址列表,格式为 host:port,多个地址使用逗号分隔。
spring.kafka.consumer.group-id:指定消费者所属的消费组的唯一标识符。
在 Kafka 中,每个消费者都必须加入一个消费组(Consumer Group)才能进行消息的消费。消费组的作用在于协调多个消费者对消息的处理,以实现负载均衡和容错机制。
具体来说,spring.kafka.consumer.group-id 的作用包括以下几点:
消费者协调:Kafka 会根据 group-id 将不同的消费者分配到不同的消费组中,不同的消费组之间相互独立。消费组内的消费者协调工作由 Kafka 服务器自动完成,确保消息在消费组内得到均匀地分发。
负载均衡:当多个消费者加入同一个消费组时,Kafka 会自动对订阅的主题进行分区分配,以实现消费者之间的负载均衡。每个分区只会分配给消费组内的一个消费者进行处理,从而实现并行处理和提高整体的消息处理能力。
容错机制:在消费组内,如果某个消费者出现故障或者新的消费者加入,Kafka 会自动重新平衡分区的分配,确保各个分区的消息能够被有效地消费。
需要注意的是,同一个消费组内的消费者共享消费位移(offset),即每个分区的消息只会被消费组内的一个消费者处理。因此,同一个主题下的不同消费组是相互独立的,不会进行负载均衡和消费位移的共享。
spring.kafka.consumer.key-deserializer:指定键(key)的反序列化器。将从 Kafka 中读取的键字节流反序列化为对象。
spring.kafka.consumer.value-deserializer:指定值(value)的反序列化器。将从 Kafka 中读取的值字节流反序列化为对象。
spring.kafka.consumer.enable-auto-commit:指定是否开启自动提交消费位移(offset)的功能。设置为 true 则开启自动提交,设置为 false 则需要手动调用 Acknowledgment 接口的 acknowledge() 方法进行位移提交。
spring.kafka.consumer.auto-commit-interval:当开启自动提交时,指定自动提交的间隔时间(以毫秒为单位)。
spring.kafka.consumer.auto-offset-reset:指定当消费者加入一个新的消费组或者偏移量无效时的重置策略。常见的取值有 earliest(从最早的偏移量开始消费)和 latest(从最新的偏移量开始消费)。
spring.kafka.consumer.auto-offset-reset 属性有以下几种取值:
latest:表示从当前分区的最新位置开始消费,即只消费从启动之后生产的消息,不消费历史消息。
earliest:表示从该分区的最早位置开始消费,即包含历史消息和当前的消息。
none:表示如果没有找到先前的消费者偏移量,则抛出异常。
需要注意的是,spring.kafka.consumer.auto-offset-reset 的默认值是 latest,如果不设置该属性,则新加入消费组的消费者将从该主题的最新位置开始消费。
spring.kafka.consumer.max-poll-records:指定每次拉取的最大记录数。用于控制每次消费者向服务器拉取数据的数量,默认为 500。
listener 配置
在 Spring 中,是使用 Kafka 监听器来进行消息消费的,spring.kafka.listener用来配置监听器的相关配置,以下是一些常见的 spring.kafka.listener 相关配置及作用:
spring.kafka.listener.concurrency:指定监听器容器中并发消费者的数量。默认值为 1。通过设置并发消费者的数量,可以实现多个消费者同时处理消息,提高消息处理的吞吐量。
spring.kafka.listener .autoStartup:指定容器是否在启动时自动启动。默认值为 true。可以通过设置为 false 来在应用程序启动后手动启动容器。
spring.kafka.listener.clientIdPrefix:指定用于创建消费者的客户端 ID 的前缀。默认值为 “spring”.
spring.kafka.listener .ackMode:指定消息确认模式,包括 RECORD、BATCH 和 MANUAL_IMMEDIATE等。可根据需求选择不同的确认模式,用于控制消息的确认方式。
spring.kafka.listener.ackCount:当ackMode为"COUNT”或者"COUNT_TIME"时,处理多少个消息后才进行消息确认。
ackMode的详细介绍可以看我上一篇文章: ackMode详解
spring.kafka.listener.missing-topics-fatal:配置当消费者订阅的主题不存在时的行为
当将 spring.kafka.listener.missing-topics-fatal 设置为 true 时,如果消费者订阅的主题在 Kafka 中不存在,应用程序会立即失败并抛出异常,阻止消费者启动。这意味着应用程序必须依赖于确保所有订阅的主题都存在,否则应用程序将无法正常运行。
当将 spring.kafka.listener.missing-topics-fatal 设置为 false 时,如果消费者订阅的主题在 Kafka 中不存在,应用程序将继续启动并等待主题出现。一旦主题出现,消费者将开始正常地消费消息。这种情况下,应用程序需要能够处理主题缺失的情况,并在主题出现后自动适应。
默认情况下,spring.kafka.listener.missing-topics-fatal 属性的值为 false,这意味着如果消费者订阅的主题不存在,应用程序将会等待主题出现而不会立刻失败。
spring.kafka.listener.syncCommits:指定是否在关闭容器时同步提交偏移量。默认值为 false。可以通过设置为 true 来确保在关闭容器时同步提交偏移量。
相关文章:

Spring Kafka常用配置详解
目录 前言producer配置consumer 配置listener 配置 前言 在 Spring Kafka 中,主要的配置分为三大块,分别是producer、consumer、listener,下面我们就按模块介绍各个模块的常用配置 producer配置 在 Spring Kafka 中,spring.kaf…...

跨域的多种方案详解
浏览器的同源策略是为了保护用户的安全,限制了跨域请求。同源策略要求请求的域名、协议和端口必须完全一致,只要有一个不同就会被认为是跨域请求。 本文列举了一些处理跨域请求的解决方案: JSONPCORS跨域资源共享http proxynginx反向代理web…...
Java / Scala - Trie 树简介与应用实现
目录 一.引言 二.Tire 树简介 1.树 Tree 2.二叉搜索树 Binary Search Tree 3.字典树 Trie Tree 3.1 基本概念 3.2 额外信息 3.3 结点实现 3.4 查找与存储 三.Trie 树应用 1.应用场景 2.Java / Scala 实现 2.1 Pom 依赖 2.2 关键词匹配 四.总结 一.引言 Trie 树…...

JS/jQuery 获取 HTTPRequest 请求标头?
场景:在jquery封装的ajax请求中,默认是异步请求。 需要定一个秘钥进行解密,所以只能存放在请求头中。然后需要值的时候去请求头中读取。 注意:dataType设置,根据请求参数的格式设置,如果是加密字符串&…...
Leetcode—2034.股票价格波动【中等】
2023每日刷题(五十二) Leetcode—2034.股票价格波动 算法思想 实现代码 class StockPrice { public:int last 0;multiset<int> total;unordered_map<int, int> m;StockPrice() {}void update(int timestamp, int price) {if(m.count(time…...

【Linux】diff命令使用
diff命令 是一个用于比较两个文件或目录之间差异的命令。它可以显示两个文件之间的行级别差异,并以易于阅读的格式输出结果。 著者 由保罗艾格特、迈克海特尔、大卫海耶斯、理查德史泰尔曼和Len Tower撰写。 diff命令 -Linux手册页 语法 diff [选项] [文件1]…...

讯飞星火认知大模型与软件测试结合,提升软件质量与效率
随着人工智能技术的不断发展,越来越多的企业开始将其应用于软件开发过程中。其中,讯飞星火认知大模型作为一种基于深度学习的自然语言处理技术,已经在语音识别、机器翻译、智能问答等领域取得了显著的成果。而在软件测试领域,讯飞…...

【Flink on k8s】- 4 - 在 Kubernetes 上运行容器
目录 1、准备 k8s 集群环境、Docker 环境 2、启用 kubernetes 2.1 查询 k8s 集群基本状态...

软件重装或系统重装后避免重复踩坑
1. Office软件的坑在于字体又没了 Word字体库默认没有仿宋_GB2312和楷体仿宋_GB2312,需要手动添加。 提供如下两个下载链接,亲测有效: 仿宋_GB2312 楷体_GB2312 安装步骤:解压-复制.ttf文件至C:\Windows\Fonts 持续更新贴~...

【Jmeter】JSON Extractor变量包含转义字符,使用Beanshell脚本来消除
如果使用Jmeter的JSON Extractor提取的变量包含特殊字符,直接引用时会包含转义字符。可以使用Beanshell脚本来进行字符串转换,从而消除这些转义字符。 import com.alibaba.fastjson.JSONObject; import com.alibaba.fastjson.JSONArray; import com.ali…...
)
GO设计模式——5、建造者模式(创建型)
目录 建造者模式(Builder Pattern) 建造者模式的核心角色 优缺点 使用场景 注意事项 代码实现 建造者模式(Builder Pattern) 建造者模式(Builder Pattern)是将一个复杂对象的构建与它的表示分离&…...
)
《LeetCode力扣练习》代码随想录——字符串(反转字符串II---Java)
《LeetCode力扣练习》代码随想录——字符串(反转字符串II—Java) 刷题思路来源于 代码随想录 541. 反转字符串 II 模拟过程 class Solution {public String reverseStr(String s, int k) {if(s.length()1){return s;}char[] chs.toCharArray();for(int i…...

WMMSE方法的使用笔记
标题很帅 原论文的描述WMMSE的简单应用 无线蜂窝通信系统的预编码设计问题中,经常提到用WMMSE方法设计多用户和速率最大化的预编码,其中最为关键的一步是将原和速率最大化问题转化为均方误差最小化问题,从而将问题由非凸变为关于三个新变量的…...

MySQL核心知识点整理大全1-笔记
目录 MySQL 一、MySQL的基本概念 1.数据库 2.表 3.列 4.行 5.主键 6.索引 二、MySQL的安装与配置 1.下载MySQL安装包 2.安装MySQL 3.启动MySQL 4.配置MySQL a.设置监听端口和IP地址 b.设置数据存储路径 c.设置字符集和排序规则 5.测试MySQL 三、MySQL的基本操…...
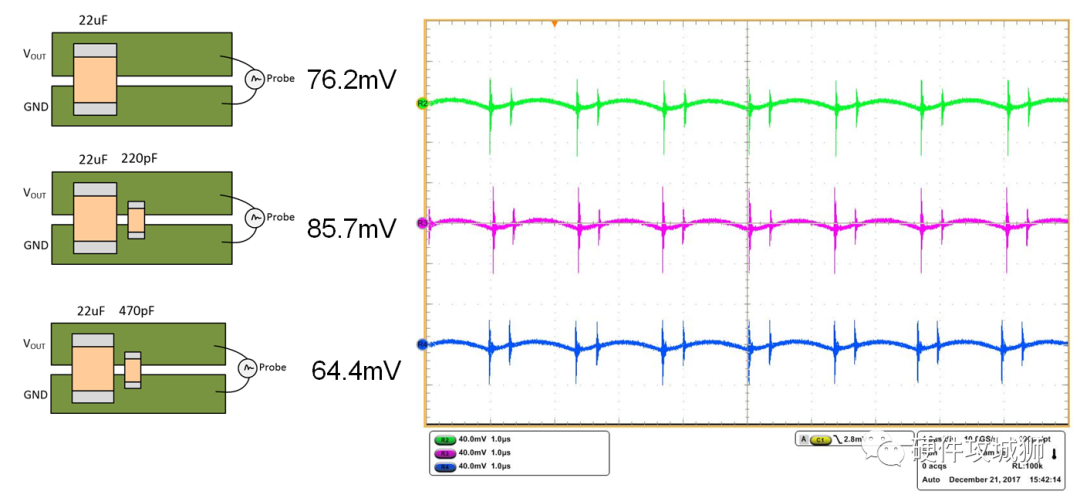
理解输出电压纹波和噪声:来源与抑制
医疗设备、测试测量仪器等很多应用对电源的纹波和噪声极其敏感。理解输出电压纹波和噪声的产生机制以及测量技术是优化改进电路性能的基础。 1:输出电压纹波 以Buck电路为例,由于寄生参数的影响,实际Buck电路的输出电压并非是稳定干净的直流…...
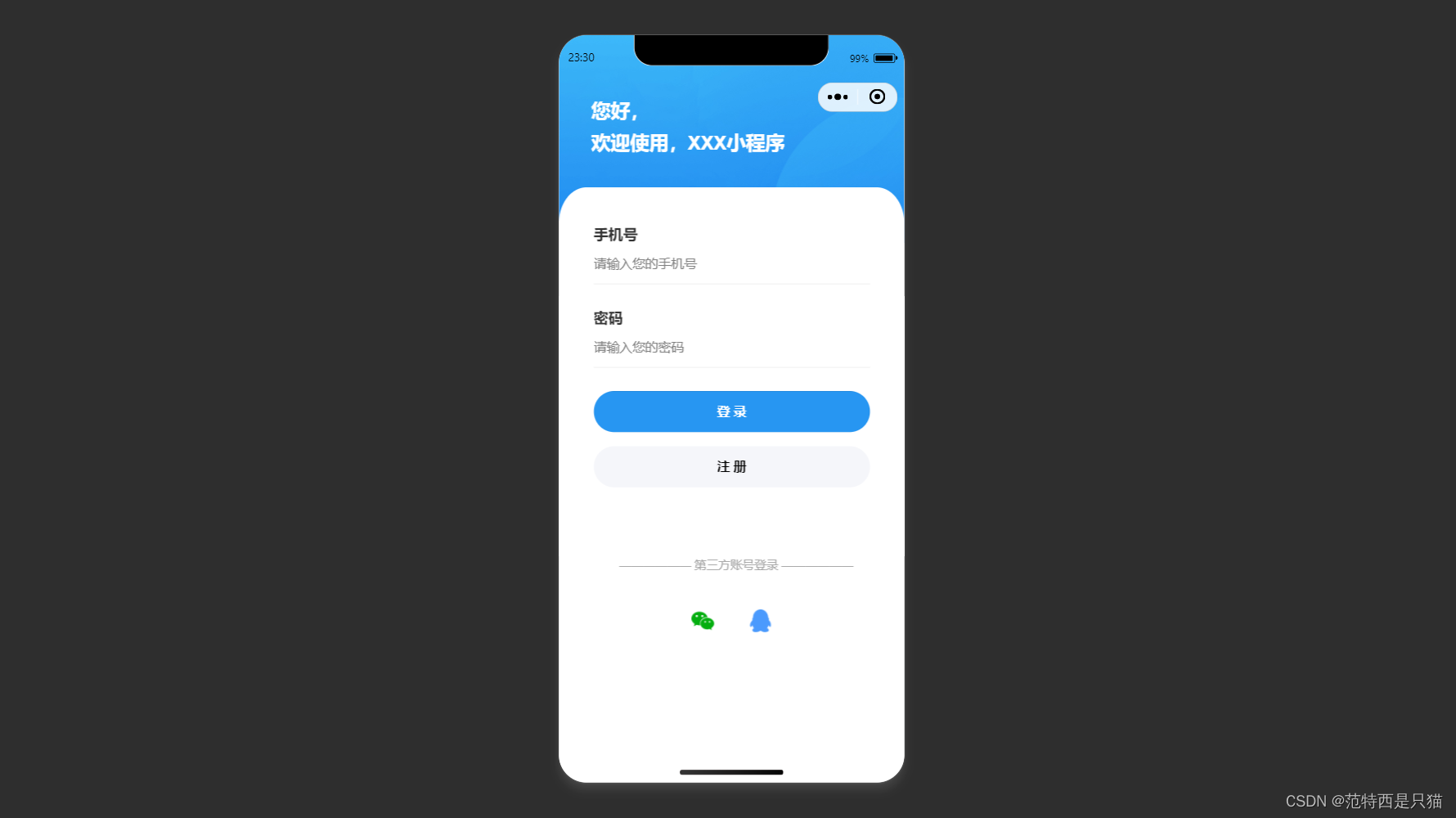
uni-app 微信小程序之好看的ui登录页面(二)
文章目录 1. 页面效果2. 页面样式代码 更多登录ui页面 uni-app 微信小程序之好看的ui登录页面(一) uni-app 微信小程序之好看的ui登录页面(二) uni-app 微信小程序之好看的ui登录页面(三) uni-app 微信小程…...
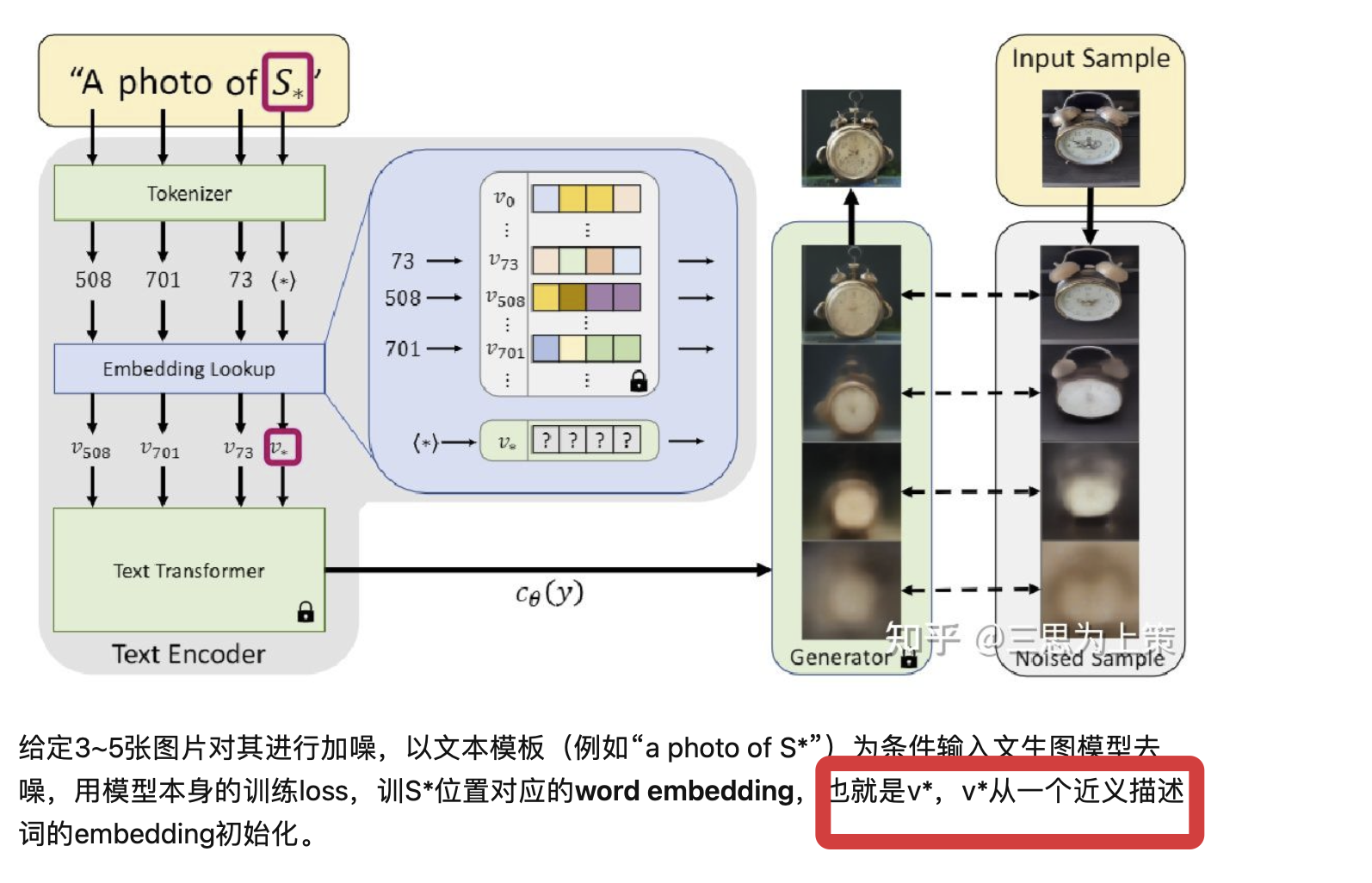
Textual Inversion
参考博客1:https://www.bilibili.com/read/cv25430752/...
)
笙默考试管理系统-MyExamTest----codemirror(47)
笙默考试管理系统-MyExamTest----codemirror(44) 目录 笙默考试管理系统-MyExamTest----codemirror(44) 一、 笙默考试管理系统-MyExamTest----codemirror 二、 笙默考试管理系统-MyExamTest----codemirror 三、 笙默考试…...

JVM中 Minor GC 和 Full GC 的区别
Java中的垃圾回收(Garbage Collection, GC)是自动内存管理的一部分,其主要职责是识别并清除程序中不再使用的对象来释放内存。Java虚拟机(JVM)在运行时进行垃圾回收,主要分为两种类型:Minor GC和…...
二十一章(网络通信)
计算机网络实现了多台计算机间的互联,使得它们彼此之间能够进行数据交流。网络应用程序就是在已连接的不同计算机上运行的程序,这些程序借助于网络协议,相互之间可以交换数据。编写网络应用程序前,首先必须明确所要使用的网络协议…...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

终极免费换肤方案:R3nzSkin国服版完整使用教程
终极免费换肤方案:R3nzSkin国服版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤&#x…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...

AI模型GUI开发实战:从架构设计到部署的完整指南
1. 项目概述:一个为AI模型打造的图形化交互界面最近在GitHub上看到一个挺有意思的项目,叫GrahamMiranda-AI/openclaw-model-gui。光看名字,就能猜个八九不离十:这大概率是一个为某个名为“OpenClaw”的AI模型配套开发的图形用户界…...

低配置电脑适配 OpenClaw 搭配 Ollama 流畅使用技巧
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑已成功安装运行 OpenClaw 客户端,顶部 Gateway 状态保持在线网络正常,可顺利访问 Ollama 官方网站电脑空余磁盘空间充足,本地 AI 模型占用体积较大提…...

基于MCP协议构建个人AI工作流:模块化套件配置与隐私优先实践
1. 项目概述:一个为个人工作流注入AI智能的MCP套件 最近在折腾AI Agent和自动化工作流的朋友,应该都绕不开一个词: MCP 。全称是Model Context Protocol,你可以把它理解成AI模型(比如Claude、ChatGPT)和外…...