【Python学习笔记】第二十四节 Python 正则表达式
一、正则表达式简介
正则表达式(regular expression)是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数
一、函数
1、re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
函数语法:
re.match(pattern, string, flags=0)函数参数说明:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 | 描述 |
group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例1
# coding=utf-8import reprint(re.match('www', 'www.baidu.com').span()) # 在起始位置匹配
print(re.match('com', 'www.baidu.com')) # 不在起始位置匹配
运行结果:
(0, 3)
None实例2
# coding=utf-8import reprint(re.match('www', 'www.baidu.com').span()) # 在起始位置匹配
print(re.match('com', 'www.baidu.com')) # 不在起始位置匹配line = "Cats are smarter than dogs"
matchObj = re.match(r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:print("matchObj.group() : ", matchObj.group())print("matchObj.group(1) : ", matchObj.group(1))print("matchObj.group(2) : ", matchObj.group(2))
else:print("No match!!")
运行结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter2、re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)函数参数说明:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 | 描述 |
group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例1
# coding=utf-8import re# search
print(re.search('www', 'www.baidu.com').span()) # 在起始位置匹配
print(re.search('com', 'www.baidu.com').span()) # 不在起始位置匹配
运行结果:
(10, 13)实例2
# coding=utf-8import reline = "Cats are smarter than dogs"# search
print(re.search('www', 'www.baidu.com').span()) # 在起始位置匹配
print(re.search('com', 'www.baidu.com').span()) # 不在起始位置匹配searchObj = re.search(r'(.*) are (.*?) .*', line, re.M | re.I)
if searchObj:print("searchObj.group() : ", searchObj.group())print("searchObj.group(1) : ", searchObj.group(1))print("searchObj.group(2) : ", searchObj.group(2))
else:print("Nothing found!!")
运行结果:
(10, 13)
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarterre.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
# coding=utf-8import reline = "Cats are smarter than dogs";
matchObj = re.match(r'dogs', line, re.M | re.I)
if matchObj:print("match --> matchObj.group() : ", matchObj.group())
else:print("No match!!")
matchObj = re.search(r'dogs', line, re.M | re.I)
if matchObj:print("search --> searchObj.group() : ", matchObj.group())
else:print("No match!!")
运行结果:
No match!!
search --> searchObj.group() : dogs3、检索和替换
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
实例
# coding=utf-8import rephone = "0898-66668888 # 这是一个固定电话号码"
# 删除字符串中的 Python注释
num = re.sub(r'#.*$', "", phone)
print("电话号码是: ", num)
# 删除非数字(-)的字符串
num = re.sub(r'\D', "", phone)
print("电话号码是 : ", num)
运行结果:
电话号码是: 0898-66668888
电话号码是 : 089866668888repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 3:
# coding=utf-8import re# 将匹配的数字乘以 3
def double(matched):value = int(matched.group('value'))return str(value * 3)s = 'A12G3HFD456'
print(re.sub('(?P<value>\d+)', double, s))
运行结果:
A36G9HFD13684、re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法:
re.compile(pattern[, flags])参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
实例1
import repattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12three34four') # 查找头部,没有匹配
print(m)
m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
print(m)
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print(m)
print(m.group(0)) # 可省略 0
print(m.start(0)) # 可省略 0
print(m.end(0)) # 可省略 0
print(m.span(0)) # 可省略 0
运行结果:
None
None
<re.Match object; span=(3, 5), match='12'>
12
3
5
(3, 5)在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
实例2
# coding=utf-8import repattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
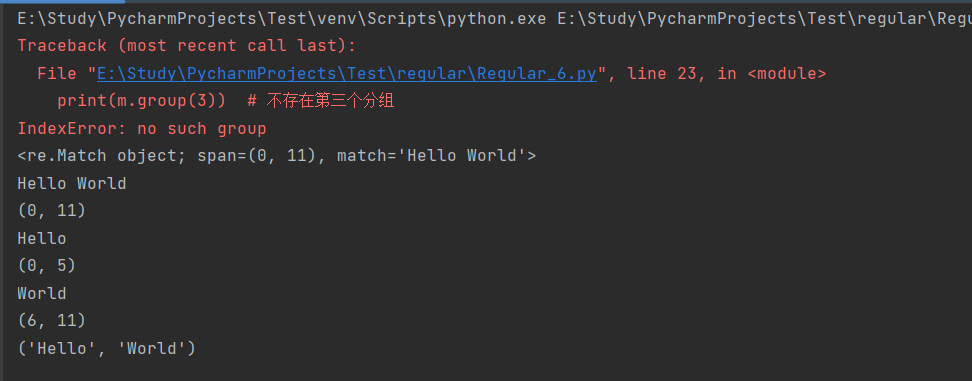
m = pattern.match('Hello World Wide Web')
print(m) # 匹配成功,返回一个 Match 对象print(m.group(0)) # 返回匹配成功的整个子串print(m.span(0)) # 返回匹配成功的整个子串的索引print(m.group(1)) # 返回第一个分组匹配成功的子串print(m.span(1)) # 返回第一个分组匹配成功的子串的索引print(m.group(2)) # 返回第二个分组匹配成功的子串print(m.span(2)) # 返回第二个分组匹配成功的子串print(m.groups()) # 等价于 (m.group(1), m.group(2), ...)print(m.group(3)) # 不存在第三个分组
运行结果
5、findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法:
findall(string[, pos[, endpos]])参数:
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
实例1:查找字符串中的所有数字:
# coding=utf-8import repattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('www.hao123.com haokan456.com')
result2 = pattern.findall('hao123qq123google456', 0, 10)
print(result1)
print(result2)
运行结果
['123', '456']
['123', '12']实例2:多个匹配模式,返回元组列表:
# coding=utf-8import reresult = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
运行结果
[('width', '20'), ('height', '10')]6、re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
语法:
re.finditer(pattern, string, flags=0)参数:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
实例
# coding=utf-8import reit = re.finditer(r"\d+", "12d32fak43mmij3")
for match in it:print(match.group())
运行结果
12
32
43
37、re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])参数:
参数 | 描述 |
pattern | 匹配的正则表达式 |
string | 要匹配的字符串。 |
maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 |
flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
实例
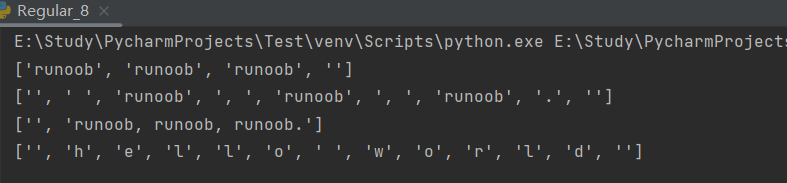
# coding=utf-8import reprint(re.split('\W+', 'runoob, runoob, runoob.'))
print(re.split('(\W+)', ' runoob, runoob, runoob.'))
print(re.split('\W+', ' runoob, runoob, runoob.', 1))
print(re.split('a*', 'hello world')) # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
运行结果
二、正则表达式对象
1、re.RegexObject
re.compile() 返回 RegexObject 对象。
2、re.MatchObject
group() 返回被 RE 匹配的字符串。
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
三、正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
修饰符 | 描述 |
re.I | 使匹配对大小写不敏感 |
re.L | 做本地化识别(locale-aware)匹配 |
re.M | 多行匹配,影响 ^ 和 $ |
re.S | 使 . 匹配包括换行在内的所有字符 |
re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
四、正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 '\\t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。
模式 | 描述 |
^ | 匹配字符串的开头 |
$ | 匹配字符串的末尾。 |
. | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
[...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
[^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
re* | 匹配0个或多个的表达式。 |
re+ | 匹配1个或多个的表达式。 |
re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
re{ n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
a| b | 匹配a或b |
(re) | 对正则表达式分组并记住匹配的文本 |
(?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
(?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
(?: re) | 类似 (...), 但是不表示一个组 |
(?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
(?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
(?#...) | 注释. |
(?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
(?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
(?> re) | 匹配的独立模式,省去回溯。 |
\w | 匹配字母数字及下划线 |
\W | 匹配非字母数字及下划线 |
\s | 匹配任意空白字符,等价于 [ \t\n\r\f]。 |
\S | 匹配任意非空字符 |
\d | 匹配任意数字,等价于 [0-9]. |
\D | 匹配任意非数字 |
\A | 匹配字符串开始 |
\Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
\z | 匹配字符串结束 |
\G | 匹配最后匹配完成的位置。 |
\b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
\B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
\n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
\1...\9 | 匹配第n个分组的内容。 |
\10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
相关文章:
【Python学习笔记】第二十四节 Python 正则表达式
一、正则表达式简介正则表达式(regular expression)是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特…...
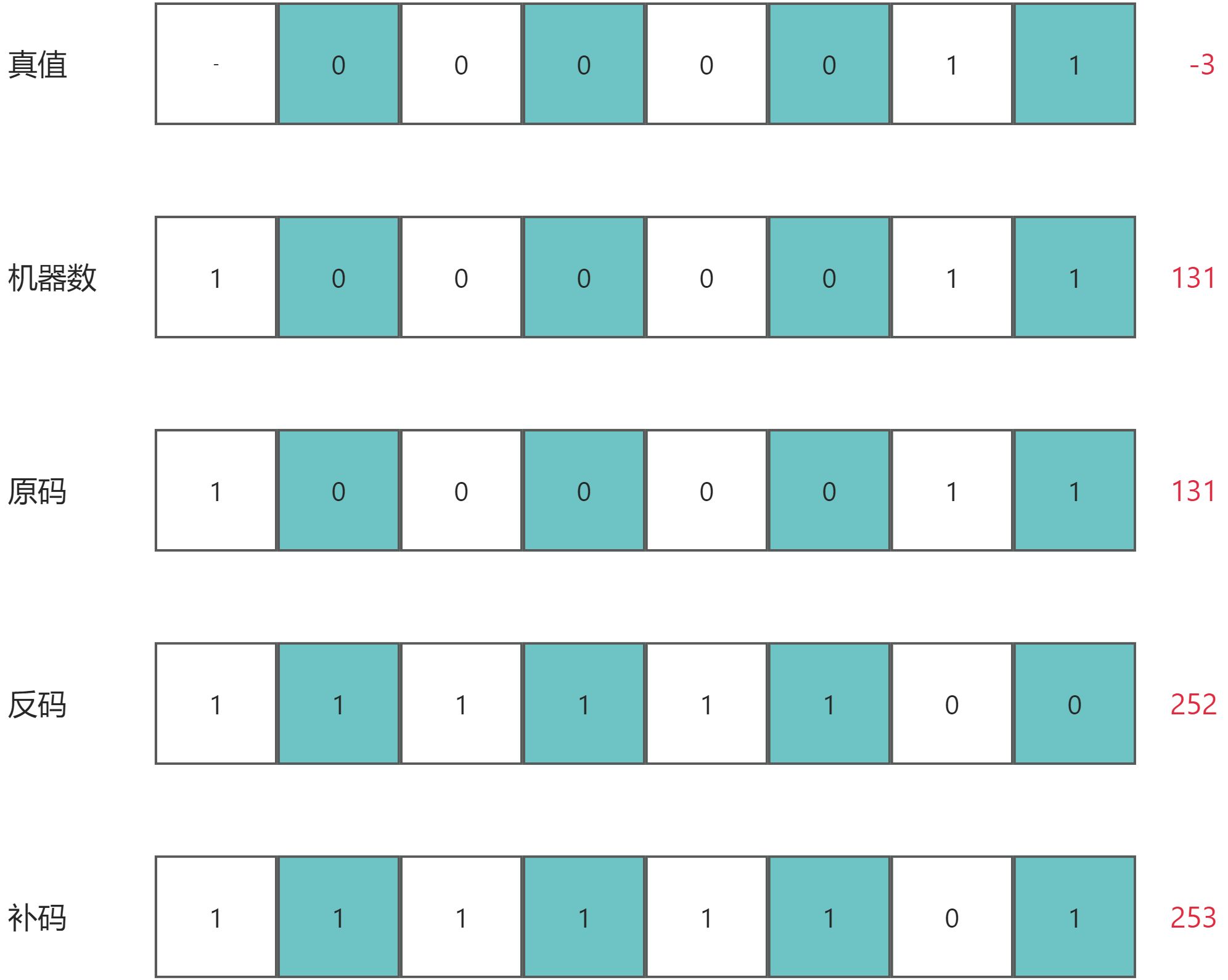
数字逻辑基础:原码、反码、补码
时间紧、不理解可以只看这里的结论 正数的原码、反码、补码相同。等于真值对应的机器码。 负数的原码等于机器码,反码为原码的符号位不变,其余各位按位取反。补码为反码1。 三种码的出现是为了解决计算问题并简化电路结构。 在原码和反码中,存…...

有限差分法-差商公式及其Matlab实现
2.1 有限差分法 有限差分法 (finite difference method)是一种数值求解偏微分方程的方法,它将偏微分方程中的连续变量离散化为有限个点上的函数值,然后利用差分逼近导数,从而得到一个差分方程组。通过求解差分方程组,可以得到原偏微分方程的数值解。 有限差分法是一种历史…...

高校就业信息管理系统
1引言 1.1编写目的 1.2背景 1.3定义 1.4参考资料 2程序系统的结构 3登录模块设计说明一 3.1程序描述 3.2功能 3.3性能 3.4输人项 3.5输出项 3.6算法 3.7流程逻辑 3.8接口 3.10注释设计 3.11限制条件 3.12测试计划 3.13尚未解决的问题 4注册模块设计说明 4.…...

【Java|golang】2373. 矩阵中的局部最大值
给你一个大小为 n x n 的整数矩阵 grid 。 生成一个大小为 (n - 2) x (n - 2) 的整数矩阵 maxLocal ,并满足: maxLocal[i][j] 等于 grid 中以 i 1 行和 j 1 列为中心的 3 x 3 矩阵中的 最大值 。 换句话说,我们希望找出 grid 中每个 3 x …...
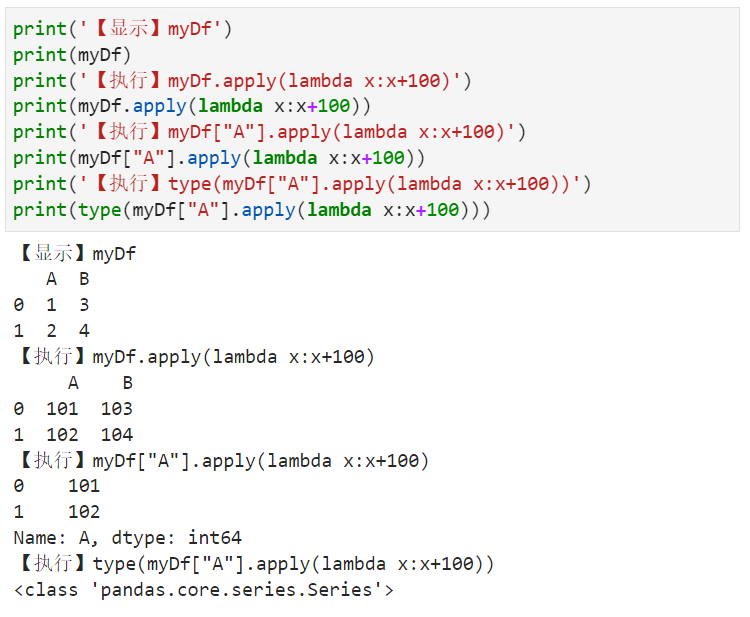
根据指定函数对DataFrame中各元素进行计算
【小白从小学Python、C、Java】【计算机等级考试500强双证书】【Python-数据分析】根据指定函数对DataFrame中各元素进行计算以下错误的一项是?import numpy as npimport pandas as pdmyDict{A:[1,2],B:[3,4]}myDfpd.DataFrame(myDict)print(【显示】myDf)print(myDf)print(【…...

【蓝桥杯集训·每日一题】AcWing 3502. 不同路径数
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴一、题目 1、原题链接 3502. 不同路径数 2、题目描述 给定一个 nm 的二维矩阵,其中的每个元素都是一个 [1,9] 之间的正整数。 从矩阵中的任意位置出发…...
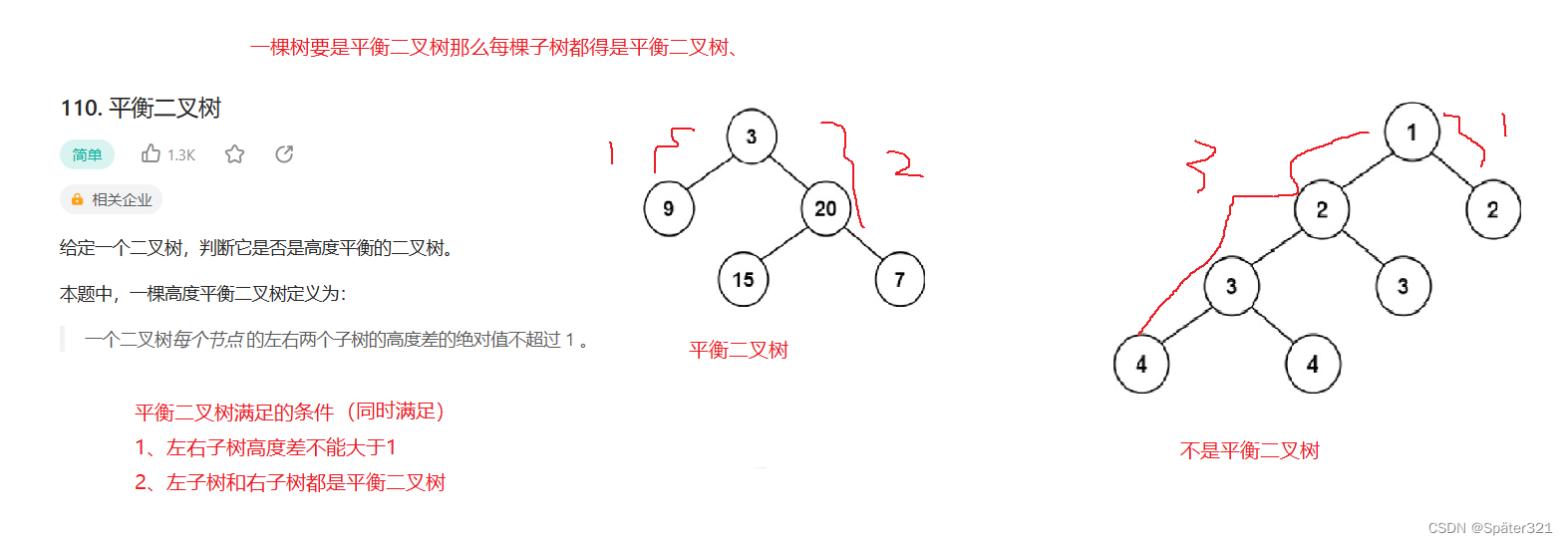
Java - 数据结构,二叉树
一、什么是树 概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点: 1、有…...
模拟QQ登录-课后程序(JAVA基础案例教程-黑马程序员编著-第十一章-课后作业)
【案例11-3】 模拟QQ登录 【案例介绍】 1.案例描述 QQ是现实生活中常用的聊天工具,QQ登录界面看似小巧、简单,但其中涉及的内容却很多,对于初学者练习Java Swing工具的使用非常合适。本案例要求使用所学的Java Swing知识,模拟实…...
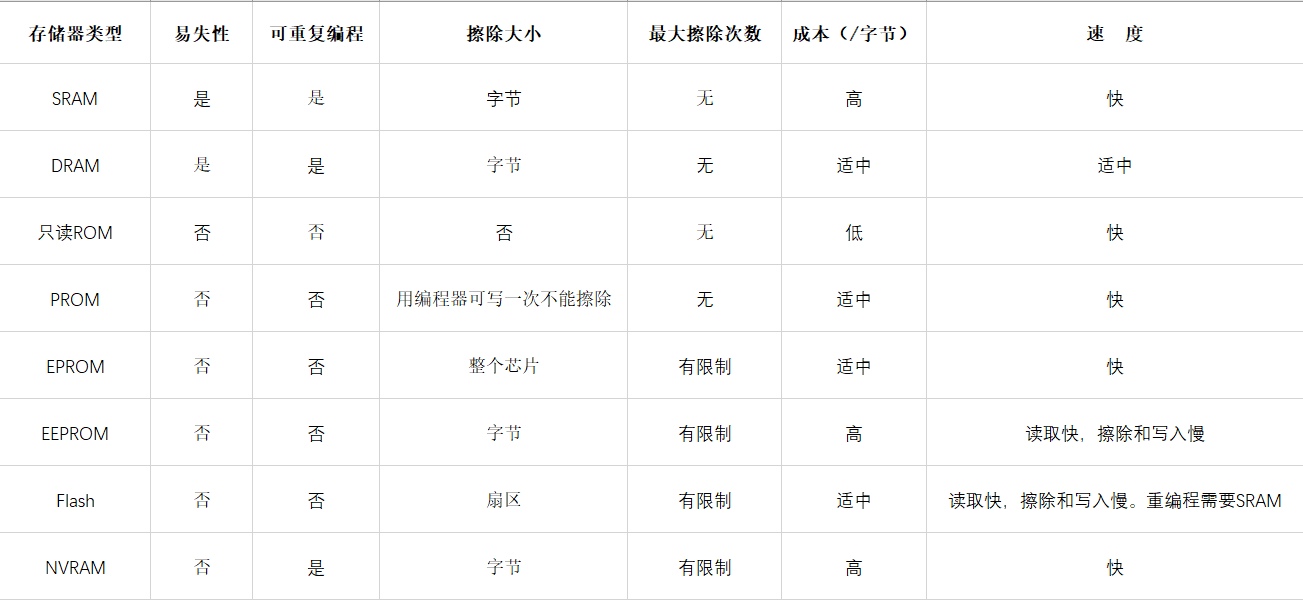
【壹】嵌入式系统硬件基础
随手拍拍💁♂️📷 日期: 2023.2.28 地点: 杭州 介绍: 日子像旋转毒马🐎,在脑海里转不停🤯 🌲🌲🌲🌲🌲 往期回顾 🌲🌲🌲…...
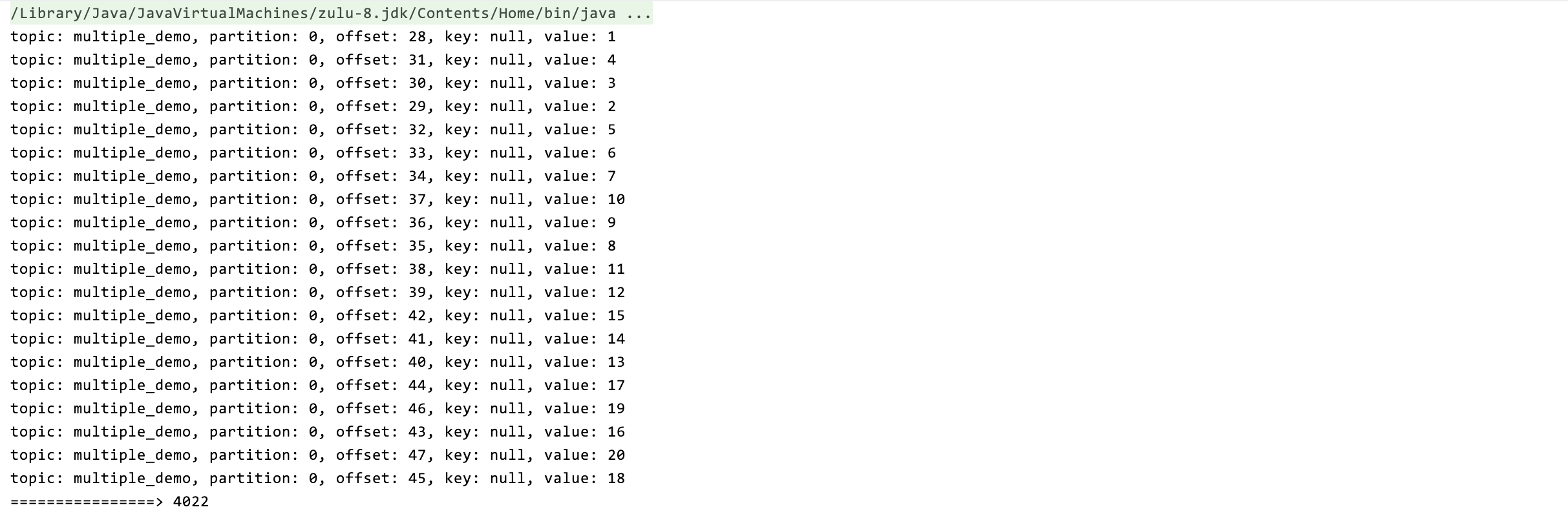
当参数调优无法解决kafka消息积压时可以这么做
今天的议题是:如何快速处理kafka的消息积压 通常的做法有以下几种: 增加消费者数增加 topic 的分区数,从而进一步增加消费者数调整消费者参数,如max.poll.records增加硬件资源 常规手段不是本文的讨论重点或者当上面的手段已经使…...
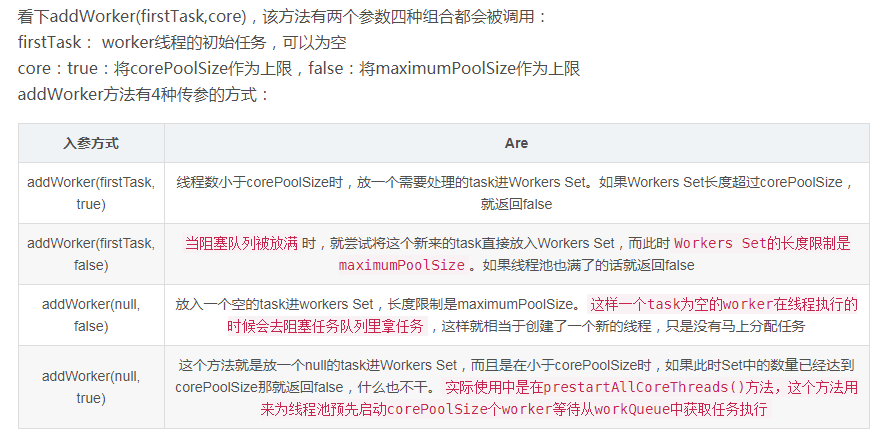
Java线程池源码分析
Java 线程池的使用,是面试必问的。下面我们来从使用到源码整理一下。 1、构造线程池 通过Executors来构造线程池 1、构造一个固定线程数目的线程池,配置的corePoolSize与maximumPoolSize大小相同, 同时使用了一个无界LinkedBlockingQueue存…...
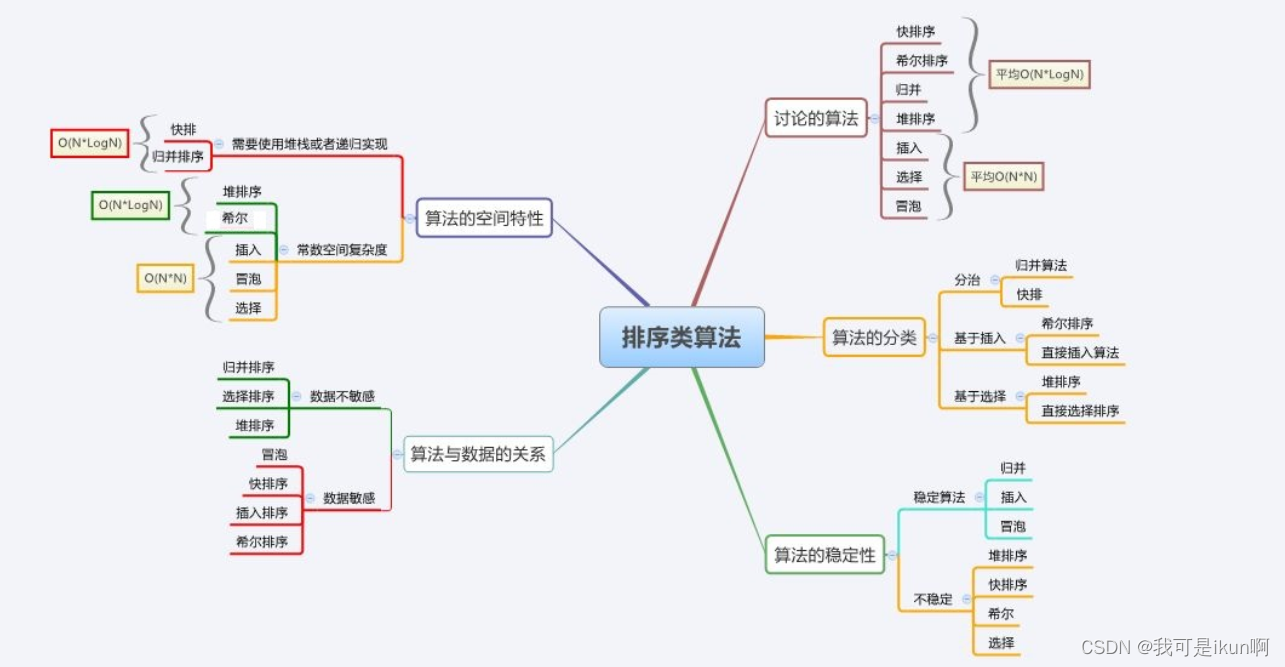
手撕八大排序(下)
目录 交换排序 冒泡排序: 快速排序 Hoare法 挖坑法 前后指针法【了解即可】 优化 再次优化(插入排序) 迭代法 其他排序 归并排序 计数排序 排序总结 结束了上半章四个较为简单的排序,接下来的难度将会大幅度上升&…...
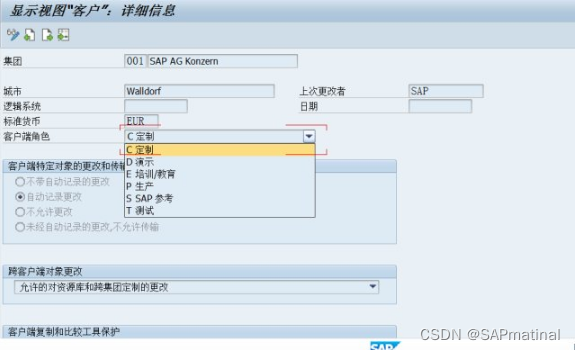
SAP 详细解析SCC4
事务代码:SCC4,选择一个客户端,点击进入,如图: 一、客户端角色 客户控制:客户的角色(生产性,测试,...) 此属性表示 R/3 系统中的客户端角色。其中可能包括…...
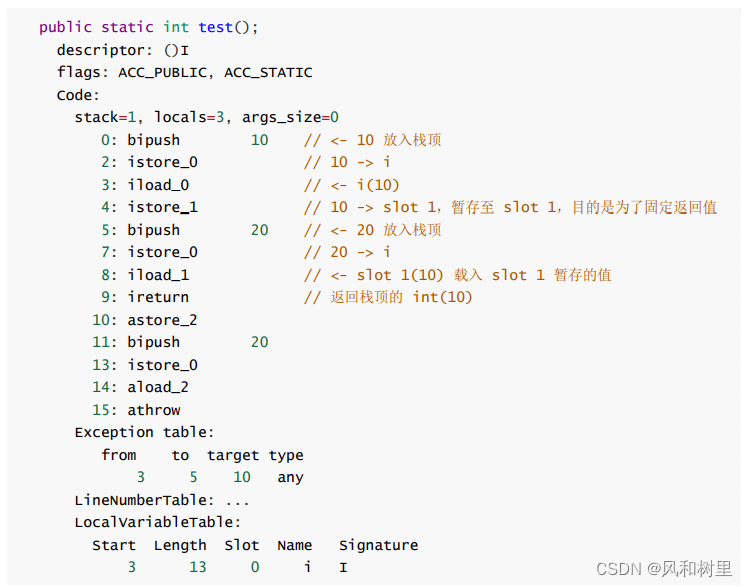
java异常分类和finally代码块中return语句的影响
首先看一下java中异常相关类的继承关系: 引用 1、分类 异常可以分为受查异常和非受查异常,Error和RuntimeException及其所有的子类都是非受查异常,其他的是受查异常。 两者的区别主要在: 受检的异常是由编译器(编译…...

【链表OJ题(二)】链表的中间节点
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(二)1. 链表…...
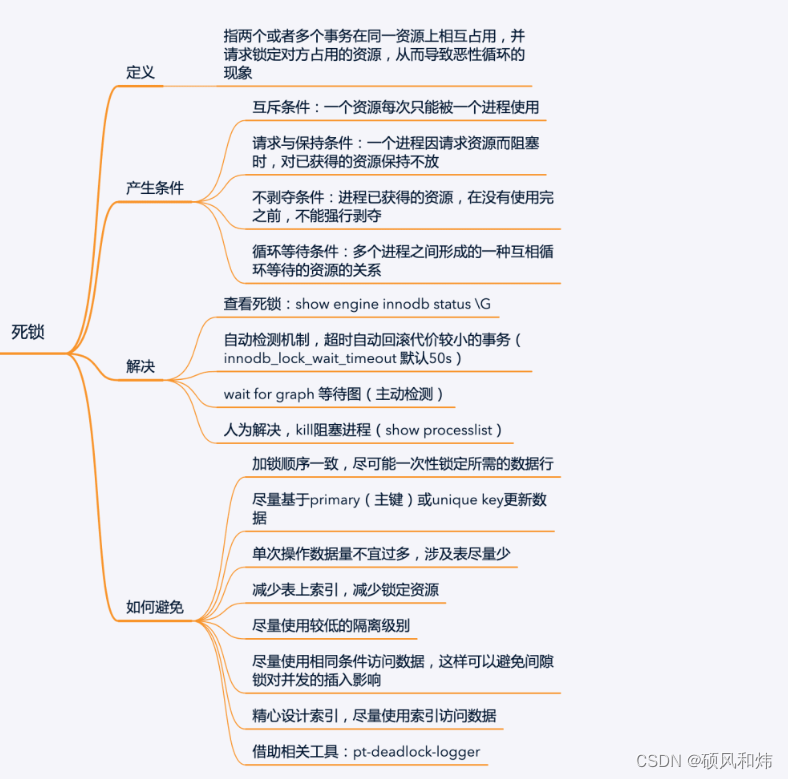
【强烈建议收藏:MySQL面试必问系列之并发事务锁专题】
一.知识回顾 上节课我们一起学习了MySQL面试必问系列之事务,没有学习的同学可以看一下上一篇文章,肯定对你会有帮助,学习过的同学肯定知道,上节课我们留了一个小尾巴,这个小尾巴是什么呢?就是没有详细展开…...
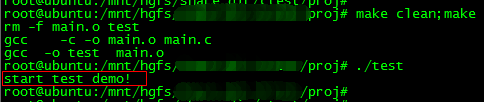
Linux下使用Makefile实现条件编译
在Linux系统下Makefile和C/C语言都有提供条件选择编译的语法,就是在编译源码的时候,可以选择性地编译指定的代码。这种条件选择编译的使用场合有好多,例如我们开发一个兼容标准版本与定制版本兼容的项目,那么,一些与需…...
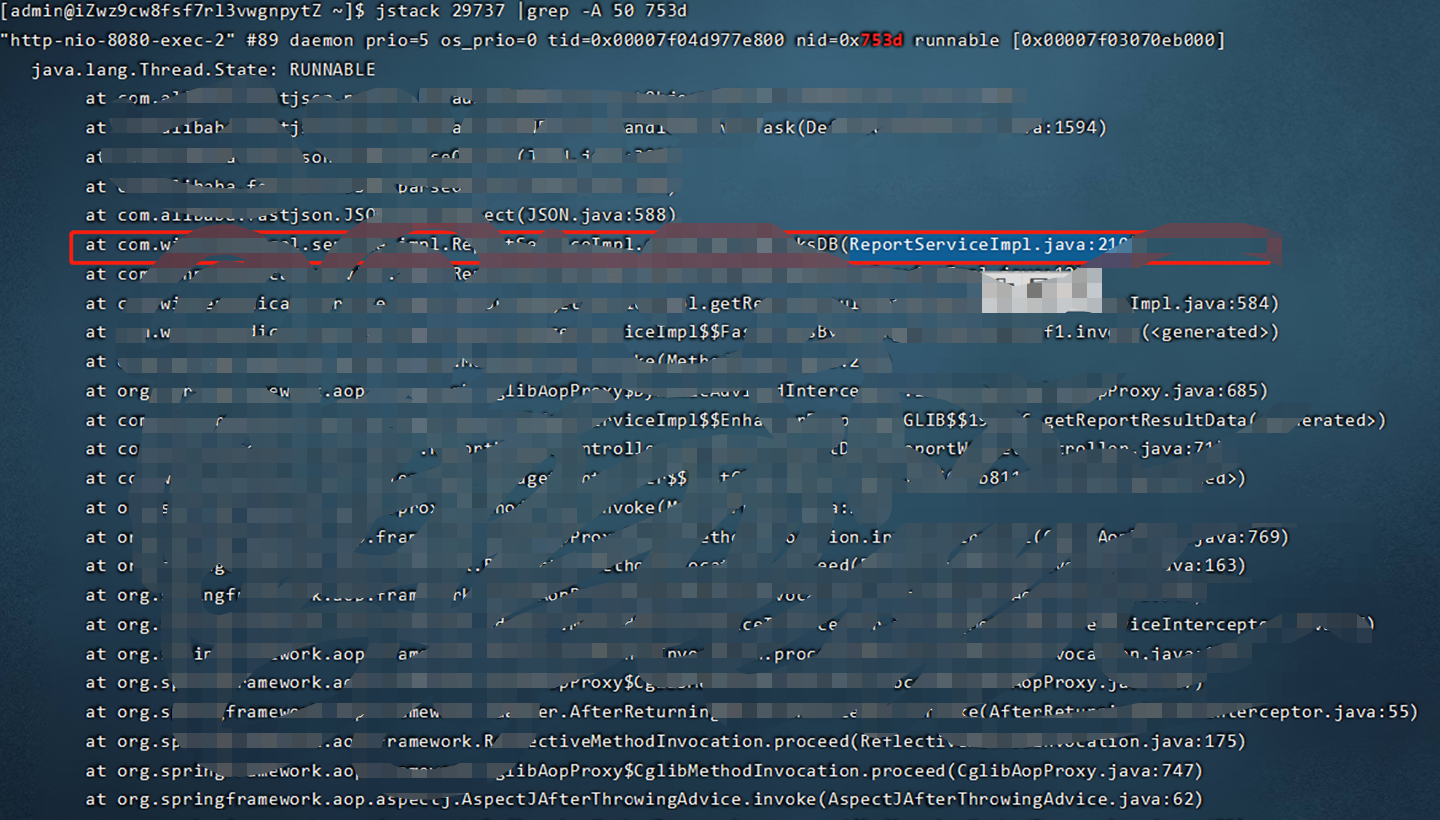
java 应用cpu飙升(超过100%)故障排查
前言害。。。昨天刚写完一份关于jvm问题排查相关的博客,今天线上项目就遇到了一个突发问题。现象是用户反映系统非常卡,无法操作。然后登录服务器查看发现cpu 一直100%以上。具体排查步骤:1,首先top命令查看服务器cpu等情况&#…...
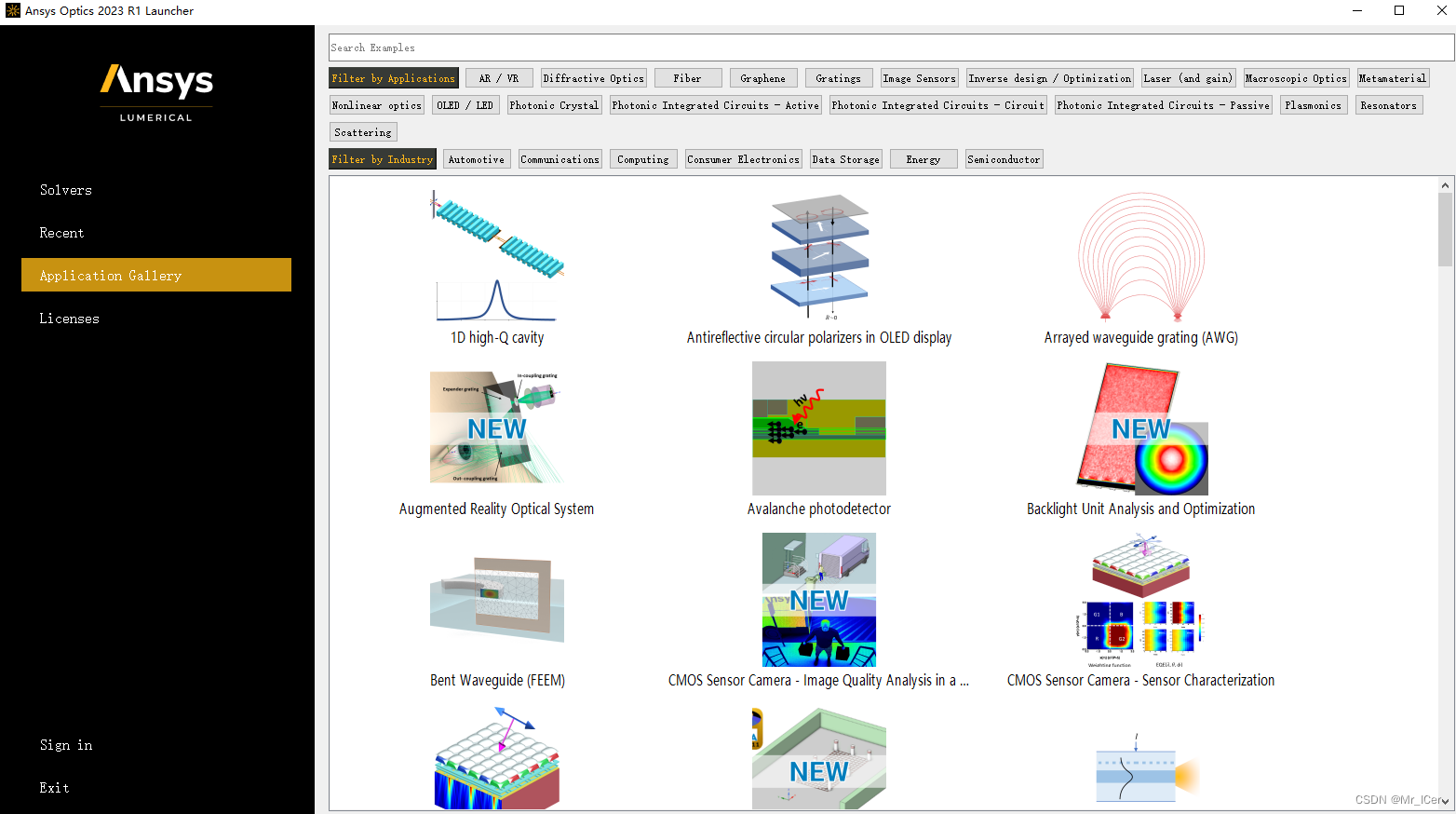
光学设计软件Ansys的Lumerical 2023版本下载与安装使用
文章目录前言一、许可管理工具安装二、许可管理器配置三、Lumerical安装四、工具使用配置总结前言 Lumerical是一款功能强大的软件,用于设计和分析从组件到系统阶段的光子学和电磁学。这个版本的Lumerical改进了电子和光子学设计工具,用于复杂光子学&am…...

使用Node.js在虚拟机后端服务中集成Taotoken多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js在虚拟机后端服务中集成Taotoken多模型调用 在虚拟机环境中部署Node.js后端服务时,直接对接多个大模型厂商…...

从昆虫飞行到机器人导航:碰撞容忍型Gimbal机器人的仿生设计哲学
1. 项目概述:从“硬闯”到“巧过”的机器人导航哲学 在机器人导航领域,我们似乎已经习惯了“感知-规划-行动”的经典范式。从激光雷达、深度相机到复杂的SLAM算法,工程师们投入海量资源,只为让机器人像人一样,优雅地识…...

AI产品技能库:将顶尖产品智慧注入Claude Code的实战指南
1. 项目概述:当AI助手遇上产品大师的智慧如果你是一名产品经理、创业者,或者任何需要与产品打交道的人,最近可能已经感受到了AI助手带来的效率革命。无论是用Claude Code写代码,还是用ChatGPT梳理思路,这些工具正在成为…...

化工仿真神器 Aspen 15.0:AI 赋能 + 绿氢专项,附下载安装教程
Aspen 15.0 是 工业流程模拟与数字化平台,核心为化工、石化、炼油、能源等行业提供全生命周期解决方案,从工艺设计、模拟优化到生产运维、绿色转型全覆盖,15.0 版本重点强化工业 AI、生成式 AI 能力,适配绿色能源与可持续发展需求…...

Proxmox VE – 修复 LVM Thin Pool “pve/data” 激活失败
逐步诊断与恢复操作指南适用范围:PVE 宿主机,LVM thin pool pve/data 状态异常,错误信息: TASK ERROR: activating LV pve/data failed: Check of pool pve/data failed (status:1). Manual repair required! 风险提示:…...

如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧
如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经遇到过想要查看Godot游戏内部资源却无从下手的困境?那些神秘…...

基于Azure SQL与Semantic Kernel的RAG应用实战:低成本实现向量搜索与智能问答
1. 项目概述:当SQL数据库遇上向量搜索如果你正在用.NET技术栈构建智能应用,并且数据已经躺在Azure SQL Database里,那么“如何低成本、高效率地实现语义搜索和RAG(检索增强生成)”很可能就是你当前最头疼的问题。传统的…...

开源技术如何驱动物联网创新:从硬件到软件的平民化革命
1. 物联网与开源:一场全民工程的序章十年前,如果有人告诉我,一个没有任何电子工程背景的艺术家,能自己动手做一个能联网、能自动浇花、还能在社交媒体上发照片的智能花盆,我大概会觉得他在讲科幻故事。但今天ÿ…...

Deep Lake:统一多模态AI数据存储与向量检索的实践指南
1. 项目概述:Deep Lake,一个为AI而生的数据湖 如果你正在构建一个需要处理图像、文本、音频、PDF,甚至医学影像DICOM文件的大模型应用,或者你在训练一个需要高效加载海量数据的深度学习模型,那么你很可能正被数据管理…...

观测云 4 月产品升级报告 | 统一目录、Obsy AI 全新上线,基础设施、场景、监控告警、管理多项能力升级
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...