K8S集群优化的可执行优化
目录
前期环境优化
1.永久关闭交换分区
2.#加载 ip_vs 模块
3.调整内核参数
4.#使用Systemd管理的Cgroup来进行资源控制与管理
5.开机自启kubelet
6.内核参数优化方案
7.etcd优化
默认etcd空间配额大小为 2G,超过 2G 将不再写入数据。通过给etcd配置 --quota-backend-bytes 参数增大空间配额,最大支持 8G --quota-backend-bytes 8589934592 | header
7.2.提高etcd对于对等网络流量优先级
7.3.etcd被设计用于元数据的小键值对的处理。
7.4.etcd的备份
8.kubelet优化
8.1增加并发度
8.2.配置镜像拉取超时
8.3.单节点允许运行的最大 Pod 数
9.kube-apiserver优化
9.1.配置kube-apiserver的内存
10.kube-controller-manager优化
10.1.Controller参数配置
10.2.可通过 leader election 实现高可用
10.3.限制与kube-apiserver通信的qps
11.kube-scheduler优化
12.kube-proxy优化
13.pod优化
13.1.为容器设置资源请求和限制
14.如何设置k8s节点的CPU限制
验证:
1)k8s dashboard验证
2. 使用kubectl top命令验证:在Node所在的集群上运行以下命令:
前期环境优化
1.永久关闭交换分区
sed -ri 's/.*swap.*/#&/' /etc/fstab
2.#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
3.调整内核参数
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
//生效参数
sysctl --system
4.#使用Systemd管理的Cgroup来进行资源控制与管理
因为相对Cgroupfs而言,Systemd限制CPU、内存等资源更加简单和成熟稳定。
#日志使用json-file格式类型存储,大小为100M,保存在/var/log/containers目录下,方便ELK等日志系统收集和管理日志。配置好这里改成500M
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://6ijb8ubo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
systemctl daemon-reload
systemctl restart docker.service
systemctl enable docker.service 开机自启
5.开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
6.内核参数优化方案
cat > /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 #禁止使用 swap 空间,只有当系统内存不足(OOM)时才允许使用它
vm.overcommit_memory=1 #不检查物理内存是否够用
vm.panic_on_oom=0 #开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963 ##指定最大文件句柄数
fs.nr_open=52706963 #最大打数
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
补充:(#gc_thresh1 提高到较大的值;此设置的作用是,如果表包含的条目少于 gc_thresh1,内核将永远不会删除(超时)过时的条目。
net.core.netdev_max_backlog=16384 # 每CPU网络设备积压队列长度
net.core.rmem_max = 16777216 # 所有协议类型读写的缓存区大小
net.core.wmem_max = 16777216 # 最大的TCP数据发送窗口大小
kernel.pid_max = 4194303 #最大进程数
vm.max_map_count = 262144)
7.etcd优化
7.1.增大etcd的存储限制
默认etcd空间配额大小为 2G,超过 2G 将不再写入数据。通过给etcd配置 --quota-backend-bytes 参数增大空间配额,最大支持 8G
--quota-backend-bytes 8589934592 | header
7.2.提高etcd对于对等网络流量优先级
如果etcd leader处理大量并发客户端请求,可能由于网络拥塞而延迟处理follower对等请求。在follower 节点上可能会产生如下的发送缓冲区错误的消息:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full
7.3.etcd被设计用于元数据的小键值对的处理。
较大的请求将工作的同时,可能会增加其他请求的延迟。默认情况下,任何请求的最大大小为1.5 MiB。这个限制可以通过–max-request-bytesetcd服务器的标志来配置。
key的历史记录压缩 ETCD 会存储多版本数据,随着写入的主键增加,历史版本将会越来越多,并且 ETCD 默认不会自动清理历史数据。数据达到 –quota-backend-bytes 设置的配额值时就无法写入数据,必须要压缩并清理历史数据才能继续写入。
--auto-compaction-mode
--auto-compaction-retention
所以,为了避免配额空间耗尽的问题,在创建集群时候建议默认开启历史版本清理功能。
7.4.etcd的备份
所有 Kubernetes 对象都存储在 etcd 上。定期备份 etcd 集群数据对于在灾难场景(例如丢失所有主节点)下恢复 Kubernetes 集群非常重要。快照文件包含所有 Kubernetes 状态和关键信息。为了保证敏感的 Kubernetes 数据的安全,可以对快照文件进行加密。 备份 etcd 集群可以通过两种方式完成: etcd 内置快照和卷快照。
内置快照
etcd 支持内置快照,因此备份 etcd 集群很容易。快照可以从使用 etcdctl snapshot save 命令的活动成员中获取,也可以通过从 etcd 数据目录复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。获取快照通常不会影响成员的性能。
下面是一个示例,用于获取 $ENDPOINT 所提供的键空间的快照到文件 snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
# exit 0
# verify the snapshot
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
卷快照
如果 etcd 运行在支持备份的存储卷(如 Amazon Elastic Block 存储)上,则可以通过获取存储卷的快照来备份 etcd 数据。
etcd恢复
etcd 支持从 major.minor 或其他不同 patch 版本的 etcd 进程中获取的快照进行恢复。还原操作用于恢复失败的集群的数据。在启动还原操作之前,必须有一个快照文件。它可以是来自以前备份操作的快照文件,也可以是来自剩余数据目录的快照文件。 有关从快照文件还原集群的详细信息和示例,请参阅 etcd 灾难恢复文档。
如果还原的集群的访问URL与前一个集群不同,则必须相应地重新配置Kubernetes API 服务器。在本例中,使用参数 –etcd-servers=$NEW_ETCD_CLUSTER 而不是参数–etcd-servers=$OLD_ETCD_CLUSTER 重新启动 Kubernetes API 服务器。用相应的 IP 地址替换 $NEW_ETCD_CLUSTER 和 $OLD_ETCD_CLUSTER。如果在etcd集群前面使用负载平衡,则可能需要更新负载均衡器。
如果大多数etcd成员永久失败,则认为etcd集群失败。在这种情况下,Kubernetes不能对其当前状态进行任何更改。虽然已调度的 pod 可能继续运行,但新的pod无法调度。在这种情况下,恢复etcd 集群并可能需要重新配置Kubernetes API服务器以修复问题。
注意:
如果集群中正在运行任何 API 服务器,则不应尝试还原 etcd 的实例。相反,请按照以下步骤还原 etcd:停止 所有 kube-apiserver 实例
在所有 etcd 实例中恢复状态
重启所有 kube-apiserver 实例
8.kubelet优化
8.1增加并发度
设置 --serialize-image-pulls=false, 该选项配置串行拉取镜像,默认值时true,配置为false可以增加并发度。但是如果docker daemon 版本小于 1.9,且使用 aufs 存储则不能改动该选项。--serialize-image-pulls=false
8.2.配置镜像拉取超时
设置--image-pull-progress-deadline=30, 配置镜像拉取超时。默认值时1分,对于大镜像拉取需要适量增大超时时间。--image-pull-progress-deadline=30
8.3.单节点允许运行的最大 Pod 数
kubelet 单节点允许运行的最大 Pod 数:--max-pods=110(默认是 110,可以根据实际需要设置)--max-pods=110
9.kube-apiserver优化
ApiServer参数配置
--max-mutating-requests-inflight # 单位时间内的最大修改型请求数量,默认200
--max-requests-inflight # 单位时间内的最大非修改型(读)请求数量,默认400
--watch-cache-sizes # 各类resource的watch cache,默认100,资源数量较多时需要增加
9.1.配置kube-apiserver的内存
使用--target-ram-mb配置kube-apiserver的内存,按以下公式得到一个合理的值:--target-ram-mb=node_nums * 60
10.kube-controller-manager优化
10.1.Controller参数配置
--node-monitor-period # 检查当前node健康状态的周期间隔,默认5s--node-monitor-grace-period # 当前node超过了这个指定周期后,即视node为不健康,进入ConditionUnknown状态,默认40s
--pod-eviction-timeout # 当node进入notReady状态后,经过这个指定时间后,会开始驱逐node上的pod,默认5m
--large-cluster-size-threshold # 判断集群是否为大集群,默认为 50,即 50 个节点以上的集群为大集群。
--unhealthy-zone-threshold:# 故障节点数比例,默认为 55%
--node-eviction-rate # 开始对node进行驱逐操作的频率,默认0.1个/s,即每10s最多驱逐某一个node上的pod,避免当master出现问题时,会有批量的node出现异常,这时候如果一次性驱逐过多的node,对master造成额外的压力
--secondary-node-eviction-rate: # 当集群规模大于large-cluster-size-threshold个node时,视为大集群, 集群中只要有55%的node不健康, 就会认为master出现了故障, 会将驱逐速率从0.1降为0.001; 如果集群规模小于large-cluster-size-threshold个node, 集群中出现55%的node不健康,就会停止驱逐。
10.2.可通过 leader election 实现高可用
kube-controller-manager可以通过 leader election 实现高可用,添加以下命令行参数:
--leader-elect=true
--leader-elect-lease-duration=15s
--leader-elect-renew-deadline=10s
--leader-elect-resource-lock=endpoints
--leader-elect-retry-period=2s
10.3.限制与kube-apiserver通信的qps
调大 –kube-api-qps 值:可以调整至 100,默认值为 20
调大 –kube-api-burst 值:可以调整至 150,默认值为 30
禁用不需要的 controller:kubernetes v1.14 中已有 35 个 controller,默认启动为--controllers,即启动所有 controller,可以禁用不需要的 controller
调整 controller 同步资源的周期:避免过多的资源同步导致集群资源的消耗,所有带有 --concurrent 前缀的参数
限制与kube-apiserver通信的qps,添加以下命令行参数:--kube-api-qps=100
--kube-api-burst=150
11.kube-scheduler优化
scheduler的配置项比较少,因为调度规则已经是很明确了,不过可以自定义预选和优选策略
--kube-api-qps # 请求apiserver的最大qps,默认50
--policy-config-file # json文件,不指定时使用默认的调度预选和优选策略,可以自定义指定kube-scheduler可以通过 leader election 实现高可用,添加以下命令行参数:
--leader-elect=true
--leader-elect-lease-duration=15s
--leader-elect-renew-deadline=10s
--leader-elect-resource-lock=endpoints
--leader-elect-retry-period=2s限制与kube-apiserver通信的qps
限制与kube-apiserver通信的qps,添加以下命令行参数:--kube-api-qps=100
--kube-api-burst=150
12.kube-proxy优化
使用 ipvs 模式
由于 iptables 匹配时延和规则更新时延在大规模集群中呈指数增长,增加以及删除规则非常耗时,所以需要转为 ipvs,ipvs 使用 hash 表,其增加或者删除一条规则几乎不受规则基数的影响。
13.pod优化
13.1.为容器设置资源请求和限制
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
spec.containers[].resources.limits.ephemeral-storage
spec.containers[].resources.requests.ephemeral-storage
在k8s中,会根据pod的limit 和 requests的配置将pod划分为不同的qos类别:
- Guaranteed
- Burstable
- BestEffort当机器可用资源不够时,kubelet会根据qos级别划分迁移驱逐pod。被驱逐的优先级:BestEffort > Burstable > Guaranteed。
使用控制器管理容器
14.如何设置k8s节点的CPU限制
k8s节点的CPU限制可以通过设置k8s调度器的参数来实现,具体步骤如下:1)打开k8s调度器的配置文件 kube-scheduler.yaml;
2)在spec configuration parameters中找到--kube-reserved参数,并添加如下配置项: --kube-reserved cpu=1000m,memory=1Gi,ephemeral-storage=1Gi
3)修改配置参数--cpu-limit-percent的数值,将其设置为一个合理的值;
4)保存并退出文件。
这里需要注意的是,对于k8s节点的CPU调度限制的设置,需要根据实际情况进行调整,比如内存大小、容器数量、容器类型等因素。一般情况下,k8s节点的CPU调度限制默认为100%,而实际调度节点的CPU利用率一般不会超过80%左右,因此,合理的CPU限制数值应该小于80%。同时为了保证一定的CPU资源用于Node的正常运行,建议将CPU限制调低一些。
验证:
1)k8s dashboard验证
进入k8s dashboard,选择Pods - Nodes选项卡,在Nodes列表中选择需要验证的Node,在该Node的Details选项中找到Allocated Resources的CPU信息,可以看到该节点的CPU利用率是否达到了限制值。
kubectl proxy
http://localhost:8001/api/v1/nodes/your_node_name_here/proxy/
访问dashboard即可。
2. 使用kubectl top命令验证:在Node所在的集群上运行以下命令:
kubectl top node
该命令将返回Node的CPU和内存使用情况,以及节点的CPU利用率。
相关文章:

K8S集群优化的可执行优化
目录 前期环境优化 1.永久关闭交换分区 2.#加载 ip_vs 模块 3.调整内核参数 4.#使用Systemd管理的Cgroup来进行资源控制与管理 5.开机自启kubelet 6.内核参数优化方案 7.etcd优化 默认etcd空间配额大小为 2G,超过 2G 将不再写入数据。通过给etcd配置 --quo…...

Remix IDE 快速开始Starknet
文章目录 一、Remix 项目二、基于Web的开发环境Remix 在线 IDE三、Starknet Remix 插件如何使用使用 Remix【重要】通过 Starknet by Example 学习一、Remix 项目 Remix 项目网站 在以太坊合约开发领域,Remix 项目享有很高的声誉,为各个级别的开发人员提供功能丰富的工具集…...

SQL中limit与分页的结合
select * from test limit 2,10; 这条语句的含义:从第3条语句开始查询,共显示10条语句。 select * from test limit a,b; a0,第一条记录。 a1,第二条记录。 a2,第三条记录。 这条语句的含义:从第a1条语句开始查询,共显示b条…...

KALI LINUX信息收集
预计更新 第一章 入门 1.1 什么是Kali Linux? 1.2 安装Kali Linux 1.3 Kali Linux桌面环境介绍 1.4 基本命令和工具 第二章 信息收集 1.1 网络扫描 1.2 端口扫描 1.3 漏洞扫描 1.4 社交工程学 第三章 攻击和渗透测试 1.1 密码破解 1.2 暴力破解 1.3 漏洞利用 1.4 …...
联想电脑重装系统Win10步骤和详细教程
联想电脑拥有强大的性能,很多用户办公都喜欢用联想电脑。有使用联想电脑的用户反映系统出现问题了,想重新安装一个正常的系统,但是不知道重新系统的具体步骤。接下来小编详细介绍给联想电脑重新安装Win10系统系统的方法步骤。 推荐下载 系统之…...

PET(Point-Query Quadtree for Crowd Counting, Localization, and More)
PET(Point-Query Quadtree for Crowd Counting, Localization, and More) 介绍实验记录训练阶段推断阶段 介绍 论文:Point-Query Quadtree for Crowd Counting, Localization, and More 实验记录 训练阶段 TODO 推断阶段 下面是以一张输…...

NgRx中dynamic reducer的原理和用法?
在 Angular 应用中,使用 NgRx 状态管理库时,动态 reducer 的概念通常是指在运行时动态添加或移除 reducer。这样的需求可能源于一些特殊的场景,比如按需加载模块时,你可能需要添加相应的 reducer。 以下是动态 reducer 的一般原理…...

麒麟V10服务器安装Apache+PHP
安装PHP yum install php yum install php-curl php-gd php-json php-mbstring php-exif php-mysqlnd php-pgsql php-pdo php-xml 配置文件 /etc/php.ini 修改参数 date.timezone Asia/Shanghai max_execution_time 60 memory_limit 1280M post_max_size 200M file_upload…...

DOS 批处理 (一)
DOS 批处理 1. 批处理是什么?2. DOS和MS-DOS3. 各种操作系统shell的区别Shell 介绍图形用户界面(GUI)shell命令行界面(CLI)的 shell命令区别 1. 批处理是什么? 批处理(Batch),也称为批处理脚本…...

P1047 [NOIP2005 普及组] 校门外的树题解
题目 某校大门外长度为 l 的马路上有一排树,每两棵相邻的树之间的间隔都是1 米。我们可以把马路看成一个数轴,马路的一端在数轴 00 的位置,另一端在l 的位置;数轴上的每个整数点,即0,1,2,…,l,都种有一棵树…...

pip的常用命令
安装、卸载、更新包:pip install [package-name],pip uninstall [package-name],pip install --upgrade [package-name]。升级pip:pip install --upgrade pip。查看已安装的包:pip list,pip list --outdate…...
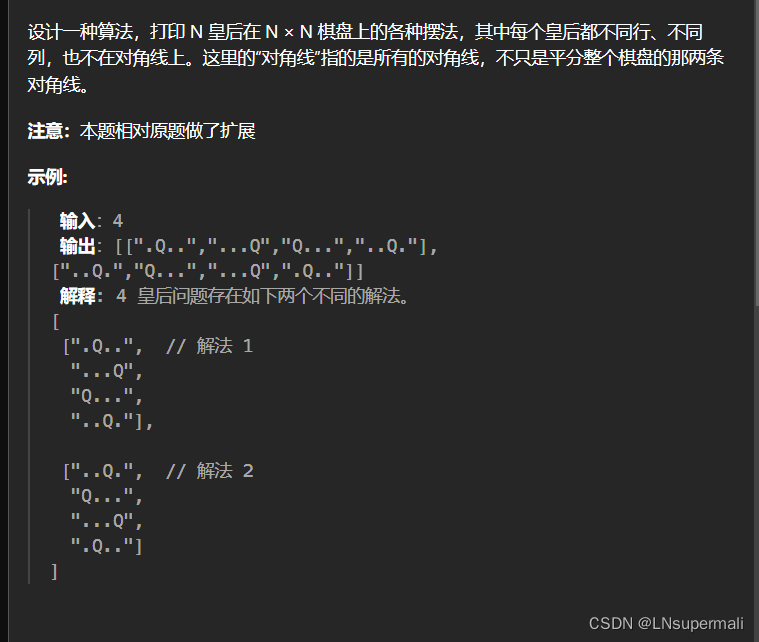
力扣面试题 08.12. 八皇后(java回溯解法)
Problem: 面试题 08.12. 八皇后 文章目录 题目描述思路解题方法复杂度Code 题目描述 思路 八皇后问题的性质可以利用回溯来解决,将大问题具体分解成如下待解决问题: 1.以棋盘的每一行为回溯的决策阶段,判断当前棋盘位置能否放置棋子 2.如何判…...

2023年第十二届数学建模国际赛小美赛A题太阳黑子预测求解分析
2023年第十二届数学建模国际赛小美赛 A题 太阳黑子预测 原题再现: 太阳黑子是太阳光球上的一种现象,表现为比周围区域暗的暂时斑点。它们是由抑制对流的磁通量浓度引起的表面温度降低区域。太阳黑子出现在活跃区域内,通常成对出现ÿ…...

jsp 分页查询展示,实现按 上一页或下一页实现用ajax刷新内容
要实现按上一页或下一页使用 Ajax 刷新内容,可以按照以下步骤进行操作: 1. 在前端页面中添加两个按钮,分别为“上一页”和“下一页”。当用户点击按钮时,触发 Ajax 请求。 2. 在后端控制器中接收 Ajax 请求,并根据传…...
基于ssm在线云音乐系统的设计与实现论文
摘 要 随着移动互联网时代的发展,网络的使用越来越普及,用户在获取和存储信息方面也会有激动人心的时刻。音乐也将慢慢融入人们的生活中。影响和改变我们的生活。随着当今各种流行音乐的流行,人们在日常生活中经常会用到的就是在线云音乐系统…...

简谈PostgreSQL的wal_level=logic
一、PostgreSQL的wal_levellogic的简介 wal_levellogic 是 PostgreSQL 中的一个配置选项,用于启用逻辑复制(logical replication)功能。逻辑复制是一种高级的数据复制技术,它允许您将变更(例如插入、更新和删除&#…...
自动化巡检实现方法 (一)------- 思路概述
一、自动化巡检需要会的技能 1、因为巡检要求一天24小时全天在线,因此巡检程序程序一定会放在服务器上跑,所以要对linux操作熟悉哦 2、巡检的代码要在git上管理,所以git的基本操作要熟悉 3、为了更方便不会代码的同学操作,所以整个…...

mysql获取时间异常
1.查看系统时间 时区是上海,本地时间正常 [roottest etc]# timedatectlLocal time: 一 2023-12-04 17:00:35 CSTUniversal time: 一 2023-12-04 09:00:35 UTCRTC time: 一 2023-12-04 09:00:34Time zone: Asia/Shanghai (CST, 0800)NTP enabled: no NTP synchroni…...
维基百科文章爬虫和聚类:高级聚类和可视化
一、说明 维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。 在我的上一篇文章中,KMeans 聚类应用于一组大约 300 篇维基百科文…...
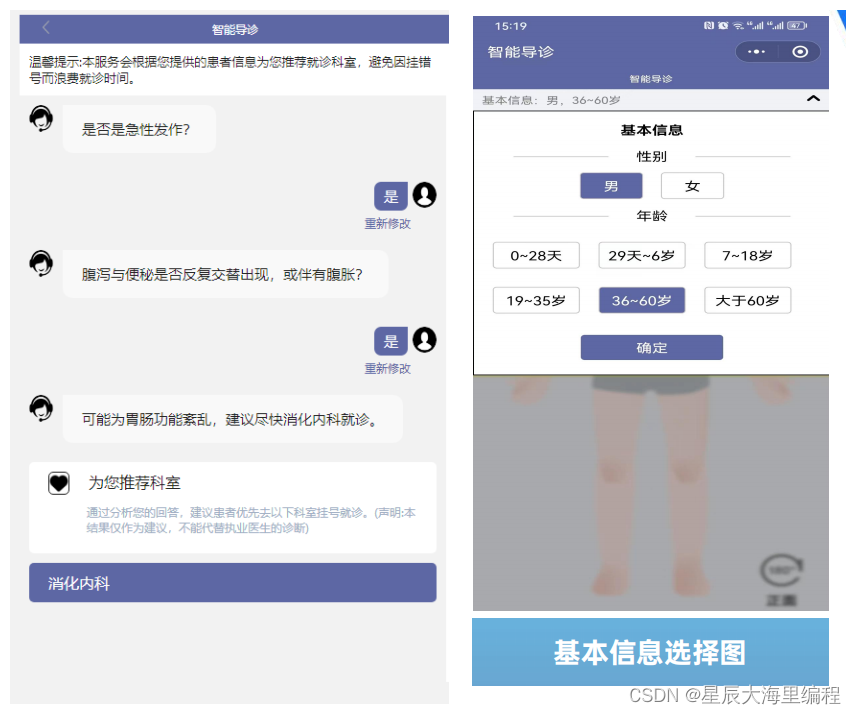
springboot智慧导诊系统源码:根据患者症状匹配挂号科室
一、系统概述 医院智慧导诊系统是在医疗中使用的引导患者自助就诊挂号,在就诊的过程中有许多患者不知道需要挂什么号,要看什么病,通过智慧导诊系统,可输入自身疾病的症状表现,或选择身体部位,在经由智慧导诊…...

基于smartcat的智能文件自动分类与归档系统实践
1. 项目概述:一个智能化的文件分类与归档工具最近在整理个人电脑和服务器上的文件时,我又一次陷入了混乱。下载文件夹里混杂着PDF、图片、代码压缩包、安装程序;项目文档和历史备份散落在各处。手动分类不仅耗时,而且容易出错。我…...

设计程序统计共享单车使用分布数据,优化投放点位,解决市民短途出行找不到车辆出行难题。
构建一个共享单车使用分布统计与投放点位优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在城市短途出行场景中,共享单车已成为重要补充:- 覆盖公交、地铁“最后一公里”- 解决 1–3 公…...

Open-Meteo:高性能开源天气API架构深度解析与技术实践
Open-Meteo:高性能开源天气API架构深度解析与技术实践 【免费下载链接】open-meteo Free Weather Forecast API for non-commercial use 项目地址: https://gitcode.com/GitHub_Trending/op/open-meteo 技术痛点与解决方案定位 传统天气数据服务面临三大技术…...

告别日志硬编码:BizLog组件在SpringBoot中的实战应用指南
1. 为什么我们需要BizLog组件 记得去年接手一个电商项目时,遇到一个典型问题:产品经理要求在用户下单、修改订单、取消订单等关键操作时,都要记录详细的操作日志。刚开始我直接在业务代码里写日志记录逻辑,结果不到一个月就发现代…...

VN5640硬件驱动从11.1升级后必看:Network-base访问模式的完整配置流程与避坑指南
VN5640硬件驱动升级至11.1后的Network-base访问模式全流程配置与实战避坑指南 当车载以太网测试工程师将VN5xxx系列硬件驱动升级到11.1版本后,一个关键但容易被忽视的变化是Network-base访问模式的引入。这种新模式彻底改变了传统channel-base的配置逻辑࿰…...

绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪
绝地求生罗技鼠标宏终极教程:5分钟实现完美压枪 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的后坐…...

ReID跨镜需人工复核,镜像视界无感定位实现全自动全链路闭环
ReID跨镜需人工复核,镜像视界无感定位实现全自动全链路闭环在全域视频感知与人员动态管控行业应用落地进程中,传统依托ReID行人重识别搭建的跨镜追踪体系,长期深陷算法识别偏差大、数据容错率低、最终必须依赖人工二次复核的运营困局…...

赣州威视智投GEO优化服务
在数字化浪潮席卷的当下,赣州本地商家面临着线上曝光不足、流量少、排名靠后的经营难题。如何在激烈的市场竞争中脱颖而出,实现精准获客与稳定引流,成为众多商家亟待解决的问题。赣州威视智投科技有限公司(以下简称“威视智投”&a…...

抓到涨停后的“财富密码”:次日去留的5条离场铁律
引言:涨停之后的焦虑与狂欢在股市里,最让散户热血沸腾也最揪心的时刻,莫过于抓到一个涨停板。那种追涨进去、刚吃两三个点就封死涨停的兴奋感,往往转瞬就会被对次日的恐惧所取代。很多投资者在涨停次日常常陷入纠结:走…...

Rust构建的跨平台数据备份工具relic:安全高效的快照管理与自动化策略
1. 项目概述:一个面向未来的跨平台数据备份与同步工具最近在整理个人工作流时,我一直在寻找一个能让我在不同设备、不同操作系统之间无缝同步项目配置、文档和代码片段的工具。市面上的云盘虽然方便,但总感觉不够“程序员友好”——要么同步粒…...