【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、Flink的23种算子说明及示例
- 9、first、distinct、join、outjoin、cross
- 10、Window
- 11、WindowAll
- 12、Window Apply
- 13、Window Reduce
- 14、Aggregations on windows
本文主要介绍Flink 的10种常用的operator(window、distinct、join等)及以具体可运行示例进行说明.
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
一、Flink的23种算子说明及示例
本文示例中使用的maven依赖和java bean 参考本专题的第一篇中的maven和java bean。
9、first、distinct、join、outjoin、cross
具体事例详见例子及结果。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.operators.Order;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.datastreamapi.User;/*** @author alanchan**/
public class TestFirst_Join_Distinct_OutJoin_CrossDemo {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();joinFunction(env);env.execute();}public static void unionFunction(StreamExecutionEnvironment env) throws Exception {List<String> info1 = new ArrayList<>();info1.add("team A");info1.add("team B");List<String> info2 = new ArrayList<>();info2.add("team C");info2.add("team D");List<String> info3 = new ArrayList<>();info3.add("team E");info3.add("team F");List<String> info4 = new ArrayList<>();info4.add("team G");info4.add("team H");DataStream<String> source1 = env.fromCollection(info1);DataStream<String> source2 = env.fromCollection(info2);DataStream<String> source3 = env.fromCollection(info3);DataStream<String> source4 = env.fromCollection(info4);source1.union(source2).union(source3).union(source4).print();
// team A
// team C
// team E
// team G
// team B
// team D
// team F
// team H}public static void crossFunction(ExecutionEnvironment env) throws Exception {// cross,求两个集合的笛卡尔积,得到的结果数为:集合1的条数 乘以 集合2的条数List<String> info1 = new ArrayList<>();info1.add("team A");info1.add("team B");List<Tuple2<String, Integer>> info2 = new ArrayList<>();info2.add(new Tuple2("W", 3));info2.add(new Tuple2("D", 1));info2.add(new Tuple2("L", 0));DataSource<String> data1 = env.fromCollection(info1);DataSource<Tuple2<String, Integer>> data2 = env.fromCollection(info2);data1.cross(data2).print();
// (team A,(W,3))
// (team A,(D,1))
// (team A,(L,0))
// (team B,(W,3))
// (team B,(D,1))
// (team B,(L,0))}public static void outerJoinFunction(ExecutionEnvironment env) throws Exception {// Outjoin,跟sql语句中的left join,right join,full join意思一样// leftOuterJoin,跟join一样,但是左边集合的没有关联上的结果也会取出来,没关联上的右边为null// rightOuterJoin,跟join一样,但是右边集合的没有关联上的结果也会取出来,没关联上的左边为null// fullOuterJoin,跟join一样,但是两个集合没有关联上的结果也会取出来,没关联上的一边为nullList<Tuple2<Integer, String>> info1 = new ArrayList<>();info1.add(new Tuple2<>(1, "shenzhen"));info1.add(new Tuple2<>(2, "guangzhou"));info1.add(new Tuple2<>(3, "shanghai"));info1.add(new Tuple2<>(4, "chengdu"));List<Tuple2<Integer, String>> info2 = new ArrayList<>();info2.add(new Tuple2<>(1, "深圳"));info2.add(new Tuple2<>(2, "广州"));info2.add(new Tuple2<>(3, "上海"));info2.add(new Tuple2<>(5, "杭州"));DataSource<Tuple2<Integer, String>> data1 = env.fromCollection(info1);DataSource<Tuple2<Integer, String>> data2 = env.fromCollection(info2);// left join
// eft join:7> (1,shenzhen,深圳)
// left join:2> (3,shanghai,上海)
// left join:8> (4,chengdu,未知)
// left join:16> (2,guangzhou,广州)data1.leftOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {@Overridepublic Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {Tuple3<Integer, String, String> tuple = new Tuple3();if (second == null) {tuple.setField(first.f0, 0);tuple.setField(first.f1, 1);tuple.setField("未知", 2);} else {// 另外一种赋值方式,和直接用构造函数赋值相同tuple.setField(first.f0, 0);tuple.setField(first.f1, 1);tuple.setField(second.f1, 2);}return tuple;}}).print("left join");// right join
// right join:2> (3,shanghai,上海)
// right join:7> (1,shenzhen,深圳)
// right join:15> (5,--,杭州)
// right join:16> (2,guangzhou,广州)data1.rightOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {@Overridepublic Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {Tuple3<Integer, String, String> tuple = new Tuple3();if (first == null) {tuple.setField(second.f0, 0);tuple.setField("--", 1);tuple.setField(second.f1, 2);} else {// 另外一种赋值方式,和直接用构造函数赋值相同tuple.setField(first.f0, 0);tuple.setField(first.f1, 1);tuple.setField(second.f1, 2);}return tuple;}}).print("right join");// fullOuterJoin
// fullOuterJoin:2> (3,shanghai,上海)
// fullOuterJoin:8> (4,chengdu,--)
// fullOuterJoin:15> (5,--,杭州)
// fullOuterJoin:16> (2,guangzhou,广州)
// fullOuterJoin:7> (1,shenzhen,深圳)data1.fullOuterJoin(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {@Overridepublic Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {Tuple3<Integer, String, String> tuple = new Tuple3();if (second == null) {tuple.setField(first.f0, 0);tuple.setField(first.f1, 1);tuple.setField("--", 2);} else if (first == null) {tuple.setField(second.f0, 0);tuple.setField("--", 1);tuple.setField(second.f1, 2);} else {// 另外一种赋值方式,和直接用构造函数赋值相同tuple.setField(first.f0, 0);tuple.setField(first.f1, 1);tuple.setField(second.f1, 2);}return tuple;}}).print("fullOuterJoin");}public static void joinFunction(ExecutionEnvironment env) throws Exception {List<Tuple2<Integer, String>> info1 = new ArrayList<>();info1.add(new Tuple2<>(1, "shenzhen"));info1.add(new Tuple2<>(2, "guangzhou"));info1.add(new Tuple2<>(3, "shanghai"));info1.add(new Tuple2<>(4, "chengdu"));List<Tuple2<Integer, String>> info2 = new ArrayList<>();info2.add(new Tuple2<>(1, "深圳"));info2.add(new Tuple2<>(2, "广州"));info2.add(new Tuple2<>(3, "上海"));info2.add(new Tuple2<>(5, "杭州"));DataSource<Tuple2<Integer, String>> data1 = env.fromCollection(info1);DataSource<Tuple2<Integer, String>> data2 = env.fromCollection(info2);//// join:2> ((3,shanghai),(3,上海))
// join:16> ((2,guangzhou),(2,广州))
// join:7> ((1,shenzhen),(1,深圳))data1.join(data2).where(0).equalTo(0).print("join");// join2:2> (3,上海,shanghai)
// join2:7> (1,深圳,shenzhen)
// join2:16> (2,广州,guangzhou)DataSet<Tuple3<Integer, String, String>> data3 = data1.join(data2).where(0).equalTo(0).with(new JoinFunction<Tuple2<Integer, String>, Tuple2<Integer, String>, Tuple3<Integer, String, String>>() {@Overridepublic Tuple3<Integer, String, String> join(Tuple2<Integer, String> first, Tuple2<Integer, String> second) throws Exception {return new Tuple3<Integer, String, String>(first.f0, second.f1, first.f1);}});data3.print("join2");}public static void firstFunction(ExecutionEnvironment env) throws Exception {List<Tuple2<Integer, String>> info = new ArrayList<>();info.add(new Tuple2(1, "Hadoop"));info.add(new Tuple2(1, "Spark"));info.add(new Tuple2(1, "Flink"));info.add(new Tuple2(2, "Scala"));info.add(new Tuple2(2, "Java"));info.add(new Tuple2(2, "Python"));info.add(new Tuple2(3, "Linux"));info.add(new Tuple2(3, "Window"));info.add(new Tuple2(3, "MacOS"));DataSet<Tuple2<Integer, String>> dataSet = env.fromCollection(info);// 前几个
// dataSet.first(4).print();
// (1,Hadoop)
// (1,Spark)
// (1,Flink)
// (2,Scala)// 按照tuple2的第一个元素进行分组,查出每组的前2个
// dataSet.groupBy(0).first(2).print();
// (3,Linux)
// (3,Window)
// (1,Hadoop)
// (1,Spark)
// (2,Scala)
// (2,Java)// 按照tpule2的第一个元素进行分组,并按照倒序排列,查出每组的前2个dataSet.groupBy(0).sortGroup(1, Order.DESCENDING).first(2).print();
// (3,Window)
// (3,MacOS)
// (1,Spark)
// (1,Hadoop)
// (2,Scala)
// (2,Python)}public static void distinctFunction(ExecutionEnvironment env) throws Exception {List list = new ArrayList<Tuple3<Integer, Integer, Integer>>();list.add(new Tuple3<>(0, 3, 6));list.add(new Tuple3<>(0, 2, 5));list.add(new Tuple3<>(0, 3, 6));list.add(new Tuple3<>(1, 1, 9));list.add(new Tuple3<>(1, 2, 8));list.add(new Tuple3<>(1, 2, 8));list.add(new Tuple3<>(1, 3, 9));DataSet<Tuple3<Integer, Integer, Integer>> source = env.fromCollection(list);// 去除tuple3中元素完全一样的source.distinct().print();
// (1,3,9)
// (0,3,6)
// (1,1,9)
// (1,2,8)
// (0,2,5)// 去除tuple3中第一个元素一样的,只保留第一个// source.distinct(0).print();
// (1,1,9)
// (0,3,6)// 去除tuple3中第一个和第三个相同的元素,只保留第一个// source.distinct(0,2).print();
// (0,3,6)
// (1,1,9)
// (1,2,8)
// (0,2,5)}public static void distinctFunction2(ExecutionEnvironment env) throws Exception {DataSet<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 18, 3000), new User(2, "alan2", "2", "2@2.com", 19, 200),new User(3, "alan1", "3", "3@3.com", 18, 1000), new User(5, "alan1", "5", "5@5.com", 28, 1500), new User(4, "alan2", "4", "4@4.com", 20, 300)));// source.distinct("name").print();
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=3000.0)source.distinct("name", "age").print();
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=3000.0)
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=5, name=alan1, pwd=5, email=5@5.com, age=28, balance=1500.0)
// User(id=4, name=alan2, pwd=4, email=4@4.com, age=20, balance=300.0)}public static void distinctFunction3(ExecutionEnvironment env) throws Exception {DataSet<User> source = env.fromCollection(Arrays.asList(new User(1, "alan1", "1", "1@1.com", 18, -1000), new User(2, "alan2", "2", "2@2.com", 19, 200),new User(3, "alan1", "3", "3@3.com", 18, -1000), new User(5, "alan1", "5", "5@5.com", 28, 1500), new User(4, "alan2", "4", "4@4.com", 20, -300)));// 针对balance增加绝对值去重source.distinct(new KeySelector<User, Double>() {@Overridepublic Double getKey(User value) throws Exception {return Math.abs(value.getBalance());}}).print();
// User(id=5, name=alan1, pwd=5, email=5@5.com, age=28, balance=1500.0)
// User(id=2, name=alan2, pwd=2, email=2@2.com, age=19, balance=200.0)
// User(id=1, name=alan1, pwd=1, email=1@1.com, age=18, balance=-1000.0)
// User(id=4, name=alan2, pwd=4, email=4@4.com, age=20, balance=-300.0)}public static void distinctFunction4(ExecutionEnvironment env) throws Exception {List<String> info = new ArrayList<>();info.add("Hadoop,Spark");info.add("Spark,Flink");info.add("Hadoop,Flink");info.add("Hadoop,Flink");DataSet<String> source = env.fromCollection(info);source.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {System.err.print("come in ");for (String token : value.split(",")) {out.collect(token);}}});source.distinct().print();}}10、Window
KeyedStream → WindowedStream
Window 函数允许按时间或其他条件对现有 KeyedStream 进行分组。 以下是以 10 秒的时间窗口聚合:
inputStream.keyBy(0).window(Time.seconds(10));
Flink 定义数据片段以便(可能)处理无限数据流。 这些切片称为窗口。 此切片有助于通过应用转换处理数据块。 要对流进行窗口化,需要分配一个可以进行分发的键和一个描述要对窗口化流执行哪些转换的函数。要将流切片到窗口,可以使用 Flink 自带的窗口分配器。 我们有选项,如 tumbling windows, sliding windows, global 和 session windows。
具体参考系列文章
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
11、WindowAll
DataStream → AllWindowedStream
windowAll 函数允许对常规数据流进行分组。 通常,这是非并行数据转换,因为它在非分区数据流上运行。
与常规数据流功能类似,也有窗口数据流功能。 唯一的区别是它们处理窗口数据流。 所以窗口缩小就像 Reduce 函数一样,Window fold 就像 Fold 函数一样,并且还有聚合。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data
这适用于非并行转换的大多数场景。所有记录都将收集到 windowAll 算子对应的一个任务中。
具体参考系列文章
6、Flink四大基石之Window详解与详细示例(一)
6、Flink四大基石之Window详解与详细示例(二)
7、Flink四大基石之Time和WaterMaker详解与详细示例(watermaker基本使用、kafka作为数据源的watermaker使用示例以及超出最大允许延迟数据的接收实现)
12、Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
将通用 function 应用于整个窗口。下面是一个手动对窗口内元素求和的 function。
如果你使用 windowAll 转换,则需要改用 AllWindowFunction。
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {public void apply (Tuple tuple,Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
});// 在 non-keyed 窗口流上应用 AllWindowFunction
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {public void apply (Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
});
13、Window Reduce
WindowedStream → DataStream
对窗口应用 reduce function 并返回 reduce 后的值。
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);}
});
14、Aggregations on windows
WindowedStream → DataStream
聚合窗口的内容。min和minBy之间的区别在于,min返回最小值,而minBy返回该字段中具有最小值的元素(max和maxBy相同)。
windowedStream.sum(0);
windowedStream.sum("key");
windowedStream.min(0);
windowedStream.min("key");
windowedStream.max(0);
windowedStream.max("key");
windowedStream.minBy(0);
windowedStream.minBy("key");
windowedStream.maxBy(0);
windowedStream.maxBy("key");
以上,本文主要介绍Flink 的10种常用的operator(window、distinct、join等)及以具体可运行示例进行说明.
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为五篇,即:
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter
【flink番外篇】1、flink的23种常用算子介绍及详细示例(2)- keyby、reduce和Aggregations
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
【flink番外篇】1、flink的23种常用算子介绍及详细示例(4)- union、window join、connect、outputtag、cache、iterator、project
【flink番外篇】1、flink的23种常用算子介绍及详细示例(完整版)
相关文章:
-window、distinct、join等)
【flink番外篇】1、flink的23种常用算子介绍及详细示例(3)-window、distinct、join等
Flink 系列文章 一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…...

centos7做gitlab数据灾备项目地址指向问题
如果你在 CentOS 7 上使用 GitLab 时,它回复的数据指向了另一个服务器的地址,可能是因为配置文件中的一些设置不正确。 要解决这个问题,可以尝试以下几个步骤: 检查 GitLab 配置文件:打开 GitLab 的配置文件…...

leetcode:93. 复原 IP 地址
复原 IP 地址 中等 1.4K 相关企业 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。 例如:“0.1.2.201” 和 “192.168.1.1” 是 有效 IP 地址,但…...

玄子Share-CSS3 弹性布局知识手册
玄子Share-CSS3 弹性布局知识手册 Flexbox Layout(弹性盒布局)是一种在 CSS 中用于设计复杂布局结构的模型。它提供了更加高效、简便的方式来对容器内的子元素进行排列、对齐和分布 主轴和交叉轴 使用弹性布局,最重要的一个概念就是主轴与…...
Nat easy IP ACL
0表示匹配,1表示任意(主机位0.0.0.255(255主机位)) rule deny source 192.168.2.1 0 设置拒绝192.168.2.1的主机通过 记住将其应用到接口上 [AR2]acl 2000 //创建基本ACL [AR2-acl-basic-2000]rule deny source 192…...

Numpy数组的数据类型汇总 (第4讲)
Numpy数组的数据类型 (第4讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ�…...

通讯app:
为了开发一个即时通讯的app,包含发送文字、语音、视频以及视频通话的功能,我们需要考虑以下的技术栈和实现步骤: 技术栈建议: 前端:React Native 或 Flutter 用于跨平台移动应用开发。后端:ThinkPHP Wor…...

【Backbone】TransNeXt:最新ViT模型(原理+常用神经网络汇总)
文章目录 一、近几年神经网络 Backbone 回顾1.Densenet 与 Resnet2.CBP3.SENet4.GCNet5.DANet6.PANet 与 FPN7.ASPP8.SPP-net9.PSP-net10.ECA-Net 二、TransNeXt(2023)1.提出问题2.Aggregated Pixel-focused Attention2.1 Pixel-focused Attention&#…...
使用Java将图片添加到Excel的几种方式
1、超链接 使用POI,依赖如下 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version></dependency>Java代码如下,运行该程序它会在桌面创建ImageLinks.xlsx文件。 …...

用什么台灯对眼睛最好?考公护眼台灯推荐
之前我一直觉得,孩子近视,是因为玩手机太多,看电子产品的时间过长,但后来控制孩子看电子产品时间的触底反弹与越来越深的度数告诉我,孩子近视的真正原因,我根本没有找到,后来看到一篇报告&#…...

【嵌入式开发 Linux 常用命令系列 4.2 -- .repo 各个目录介绍】
文章目录 概述.repo 目录结构manifests/default.xmlManifest 文件的作用default.xml 文件内容示例linkfile 介绍 .repo/projects 子目录配置和管理configHEADhooksinfo/excludeobjectsrr-cache 工作区中的对应目录 概述 repo 是一个由 Google 开发的版本控制工具,它…...

【C++学习手札】基于红黑树封装模拟实现map和set
🎬慕斯主页:修仙—别有洞天 💜本文前置知识: 红黑树 ♈️今日夜电波:漂流—菅原纱由理 2:55━━━━━━️💟──────── 4:29 …...

linux查看当前路径的所有文件大小;linux查看当前文件夹属于什么文件系统
1:指令查看当前路径所有文件内存空间大小;这样可以方便查询每个文件大小情况,根据需要进行删除 df -h // 根目录 du -ah --max-depth1 // 一级目录 虚拟机 du -ah -d 1 // 一级目录 设备使用 du -ah --max-depth2 // 二…...
PPT插件-好用的插件-超级文本-大珩助手
常用字体 内置了大量的常用字体,方便快捷的一键更换字体,避免系统字体过多卡顿 文字整理 包含删空白行、清理编号、清理格式,便于处理从网络上复制的资料 文本打散与合并 包含文本打散、文本合并,文本打散可实现将一个文本打散…...

Kafka中的Topic
在Kafka中,Topic是消息的逻辑容器,用于组织和分类消息。本文将深入探讨Kafka Topic的各个方面,包括创建、配置、生产者和消费者,以及一些实际应用中的示例代码。 1. 介绍 在Kafka中,Topic是消息的逻辑通道࿰…...
LAMP部署
目录 一、安装apache 二、配置mysql 三、安装php 四、搭建论坛 4、安装另一个网站 一、安装apache 1.关闭防火墙,将安装Apache所需软件包传到/opt目录下 systemctl stop firewalld systemctl disable firewalld setenforce 0 httpd-2.4.29.tar.gz apr-1.6.2.t…...

DouyinAPI接口开发系列丨商品详情数据丨视频详情数据
电商API就是各大电商平台提供给开发者访问平台数据的接口。目前,主流电商平台如淘宝、天猫、京东、苏宁等都有自己的API。 二、电商API的应用价值 1.直接对接原始数据源,数据提取更加准确和完整。 2.查询速度更快,可以快速响应用户请求实现…...
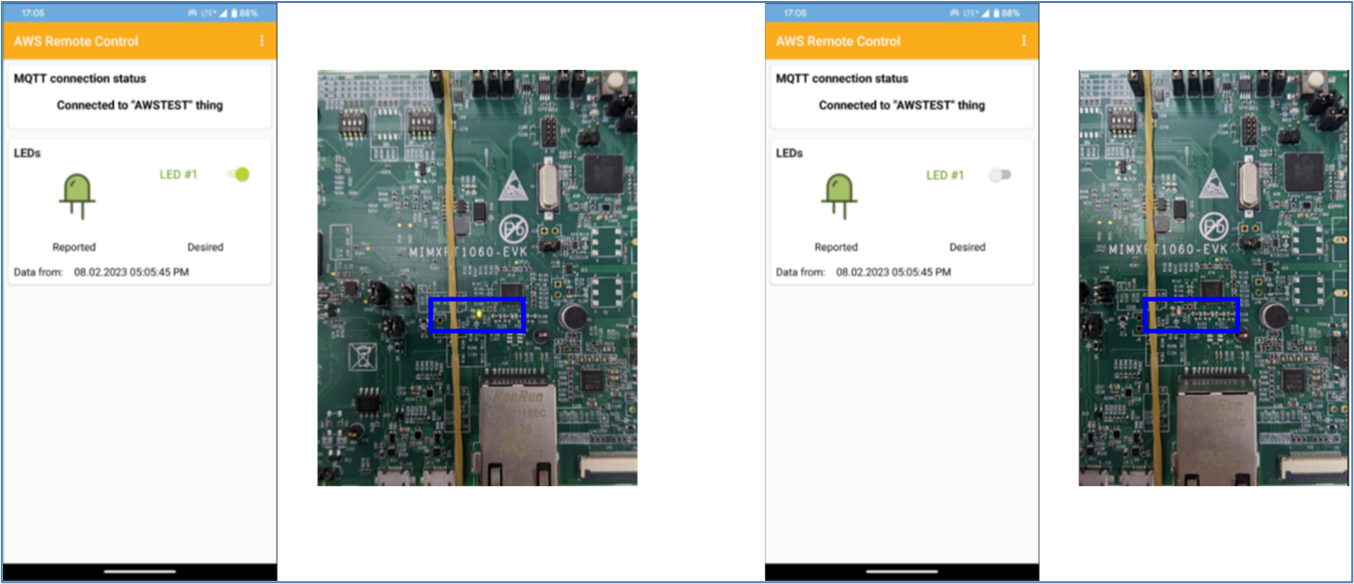
AWS Remote Control ( Wi-Fi ) on i.MX RT1060 EVK - 3 “编译 NXP i.MX RT1060”( 完 )
此章节叙述如何修改、建构 i.MX RT1060 的 Sample Code“aws_remote_control_wifi_nxp” 1. 点击“Import SDK example(s)” 2. 选择“MIMXRT1062xxxxA”>“evkmimxrt1060”,并确认 SDK 版本后,点击“Next>” 3. 选择“aws_examples”>“aw…...

5G - NR物理层解决方案支持6G非地面网络中的高移动性
文章目录 非地面网络场景链路仿真参数实验仿真结果 非地面网络场景 链路仿真参数 实验仿真结果 Figure 5 && Figure 6:不同信噪比下的BER和吞吐量 变量 SISO 2x2MIMO 2x4MIMO 2x8MIMOReyleigh衰落、Rician衰落、多径TDL-A(NLOS) 、TDL-E(LOS)(a)QPSK (b)16…...

python epub文件解析
python epub文件解析 代码BeautifulSoup 介绍解释 代码 import ebooklib from bs4 import BeautifulSoup from ebooklib import epubbook epub.read_epub("逻辑思维训练1200题.epub")# 解析 for item in book.get_items():# 提取书中的文本内容if item.get_type() …...

AI智能体记忆系统构建指南:从向量检索到混合搜索的工程实践
1. 项目概述:构建一个能“记住”的智能体最近在折腾AI智能体(Agent)开发的朋友,估计都遇到过同一个头疼的问题:这玩意儿怎么跟金鱼似的,聊两句就忘?你让它帮你整理一份周报,它吭哧吭…...

免费国产模型清单
下面给你整理了能在国内稳定使用、可通过中转接入 Claude Code 的国产免费模型,同时附接入方式和适配说明,帮你快速替换驱动👇 一、免费国产模型清单(公开 API / 兼容格式) 这些模型支持 OpenAI/Anthropic 兼容接口&a…...

基于MCP协议构建专属AI开发助手:从原理到实践
1. 项目概述:一个为开发者定制的MCP服务器最近在折腾AI应用开发,特别是想给Claude、Cursor这类智能助手增加一些“超能力”,让它们能直接操作我本地的开发环境。比如,让AI帮我直接运行单元测试、查看最近的Git提交、或者分析某个目…...

基于MCP与Apify构建自动化特许经营尽职调查智能体
1. 项目概述与核心价值最近在梳理一些自动化数据采集和商业智能分析的项目时,我遇到了一个非常有意思的工具:apifyforge/franchise-due-diligence-mcp。这个项目名字听起来有点长,但拆解一下就能明白它的核心价值——它是一个基于MCP…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

CircuitPython嵌入式开发:从代码编辑、串口调试到库管理的完整工作流
1. 从零开始:CircuitPython的嵌入式开发哲学如果你和我一样,是从Arduino或者传统的C语言嵌入式开发转过来的,第一次接触CircuitPython的感觉,大概就像从手动挡汽车换到了电动车。那种“拧钥匙、挂挡、踩离合”的繁琐步骤ÿ…...

Wwise音频文件处理终极指南:3步完成游戏音效解包与替换
Wwise音频文件处理终极指南:3步完成游戏音效解包与替换 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为游戏音频文件无法编辑而烦恼…...

LILY-W131-00B,支持USB与SDIO双高速主机接口的IEEE 802.11b/g/n模块
简介今天我要向大家介绍的是 u-blox 的前端模块——LILY-W131-00B。这是一款专为高要求工业设备及蜂窝网络回传应用而设计的超紧凑高性价比模块。该模块基于高性能 NXP 88W8801 芯片组,支持 IEEE 802.11b/g/n 标准;具备外部天线引脚,支持天线…...

写给读者看的从来不是 Markdown:Anthropic 停用 MD 背后,这个本地 HTML 编辑器解决多平台发布之苦
写完一篇东西,发布时 Markdown 的短板才显出来——渲染器各行其是,同一段文字在公众号、知乎、X 上各是一副面孔,代码块的样式、标题的缩进、引用块的背景,没有一处能跨平台保持一致,你只能逐平台手调,或者…...

基于OpenClaw构建AI智能体:从RAG到自动化工作流的实战指南
1. 项目概述:一个开源AI应用案例的“藏宝图”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫awesome-openclaw-usecases-zh。光看名字,就能拆解出几个关键信息:“awesome”系列(意味着是精选合集…...