什么是让ChatGPT爆火的大语言模型(LLM)
什么是让ChatGPT爆火的大语言模型(LLM)

更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
文章目录
- 什么是让ChatGPT爆火的大语言模型(LLM)
- 大型语言模型有什么用?
- 大型语言模型如何工作?
- 大型语言模型的热门应用
- 在哪里可以找到大型语言模型
- 大型语言模型的挑战
AI 应用程序正在总结文章、撰写故事和进行长时间对话——而大型语言模型正在承担繁重的工作。
大型语言模型或 LLM 是一种深度学习算法,可以根据从海量数据集中获得的知识来识别、总结、翻译、预测和生成文本和其他内容。
大型语言模型是 Transformer 模型最成功的应用之一。 它们不仅用于教授 AI 人类语言,还用于理解蛋白质、编写软件代码等等。
除了加速自然语言处理应用程序——如翻译、聊天机器人和人工智能助手——大型语言模型还用于医疗保健、软件开发和许多其他领域的用例。
大型语言模型有什么用?

语言不仅仅用于人类交流。
代码是计算机的语言。 蛋白质和分子序列是生物学的语言。 大型语言模型可以应用于需要不同类型通信的语言或场景。
这些模型拓宽了 AI 在各行各业和企业中的应用范围,并有望引发新一轮的研究、创造力和生产力浪潮,因为它们可以帮助为世界上最棘手的问题生成复杂的解决方案。
例如,使用大型语言模型的人工智能系统可以从分子和蛋白质结构数据库中学习,然后利用这些知识提供可行的化合物,帮助科学家开发突破性的疫苗或治疗方法。
大型语言模型还有助于创建重新构想的搜索引擎、辅导聊天机器人、歌曲、诗歌、故事和营销材料等的创作工具。
大型语言模型如何工作?
大型语言模型从大量数据中学习。 顾名思义,LLM 的核心是它所训练的数据集的大小。 但随着人工智能的发展,“大”的定义也在不断扩大。
现在,大型语言模型通常是在足够大的数据集上训练的,这些数据集几乎可以包含很长一段时间内在互联网上编写的所有内容。
如此大量的文本被输入到使用无监督学习的 AI 算法中——当一个模型被赋予一个数据集而没有关于如何处理它的明确指示时。 通过这种方法,大型语言模型可以学习单词,以及它们之间的关系和背后的概念。 例如,它可以根据上下文学习区分“bark”一词的两种含义。
正如掌握一门语言的人可以猜测句子或段落中接下来会出现什么——甚至自己想出新词或概念——大型语言模型可以应用其知识来预测和生成内容。
大型语言模型也可以针对特定用例进行定制,包括通过微调或提示调整等技术,这是为模型提供少量数据以供关注的过程,以针对特定应用对其进行训练。
由于其在并行处理序列方面的计算效率,transformer 模型架构是最大和最强大的 LLM 背后的构建块。
大型语言模型的热门应用
大型语言模型正在开启搜索引擎、自然语言处理、医疗保健、机器人技术和代码生成等领域的新可能性。
流行的 ChatGPT AI 聊天机器人是大型语言模型的一种应用。 它可以用于无数的自然语言处理任务。
LLM 几乎无限的应用还包括:
- 零售商和其他服务提供商可以使用大型语言模型,通过动态聊天机器人、人工智能助手等提供更好的客户体验。
- 搜索引擎可以使用大型语言模型来提供更直接、更像人类的答案。
- 生命科学研究人员可以训练大型语言模型来理解蛋白质、分子、DNA 和 RNA。
- 开发人员可以使用大型语言模型编写软件并教机器人完成物理任务。
- 营销人员可以训练一个大型语言模型来将客户反馈和请求组织成集群,或者根据产品描述将产品分类。
- 财务顾问可以使用大型语言模型总结收益电话会议并创建重要会议的文字记录。 信用卡公司可以使用 LLM 进行异常检测和欺诈分析以保护消费者。
- 法律团队可以使用大型语言模型来帮助进行法律释义和抄写。
在生产环境中高效运行这些大型模型需要大量资源并需要专业知识等挑战,因此企业转向 NVIDIA Triton 推理服务器,该软件可帮助标准化模型部署并在生产环境中交付快速且可扩展的 AI。
在哪里可以找到大型语言模型
2020 年 6 月,OpenAI 发布了 GPT-3 作为一项服务,该服务由一个 1750 亿参数的模型提供支持,该模型可以生成带有简短书面提示的文本和代码。
2021 年,NVIDIA 和微软开发了 Megatron-Turing 自然语言生成 530B,这是世界上最大的阅读理解和自然语言推理模型之一,可简化摘要和内容生成等任务。
HuggingFace 去年推出了 BLOOM,这是一种开放的大型语言模型,能够以 46 种自然语言和十几种编程语言生成文本。
另一个 LLM,Codex,将文本转换为软件工程师和其他开发人员的代码。
NVIDIA 提供了一些工具来简化大型语言模型的构建和部署:
- NVIDIA NeMo LLM 服务提供了一种快速途径,可以使用 NVIDIA 的托管云 API 或通过私有云和公共云自定义大型语言模型并大规模部署它们。
- NVIDIA NeMo Megatron 是 NVIDIA AI 平台的一部分,是一个框架,用于简单、高效、经济高效地训练和部署大型语言模型。 NeMo Megatron 专为企业应用程序开发而设计,为自动化分布式数据处理提供端到端的工作流程; 训练大规模、定制的模型类型,包括 GPT-3 和 T5; 并部署这些模型以进行大规模推理。
- NVIDIA BioNeMo 是一种特定领域的托管服务和框架,适用于蛋白质组学、小分子、DNA 和 RNA 中的大型语言模型。 它基于 NVIDIA NeMo Megatron 构建,用于在超级计算规模上训练和部署大型生物分子变压器 AI 模型。
大型语言模型的挑战
扩展和维护大型语言模型可能既困难又昂贵。
构建基础大型语言模型通常需要数月的训练时间和数百万美元。
而且由于 LLM 需要大量的训练数据,开发人员和企业会发现访问足够大的数据集是一项挑战。
由于大型语言模型的规模,部署它们需要技术专长,包括对深度学习、转换器模型和分布式软件和硬件的深刻理解。
许多技术领域的领导者正在努力推进开发和构建资源,以扩大对大型语言模型的访问,让各种规模的消费者和企业都能从中获益。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
相关文章:
什么是让ChatGPT爆火的大语言模型(LLM)
什么是让ChatGPT爆火的大语言模型(LLM) 更多精彩内容: https://www.nvidia.cn/gtc-global/?ncidref-dev-876561 文章目录什么是让ChatGPT爆火的大语言模型(LLM)大型语言模型有什么用?大型语言模型如何工作?大型语言模型的热门应用在哪里可以找到大型语言…...
【监控】Linux部署postgres_exporter及PG配置(非Docker)
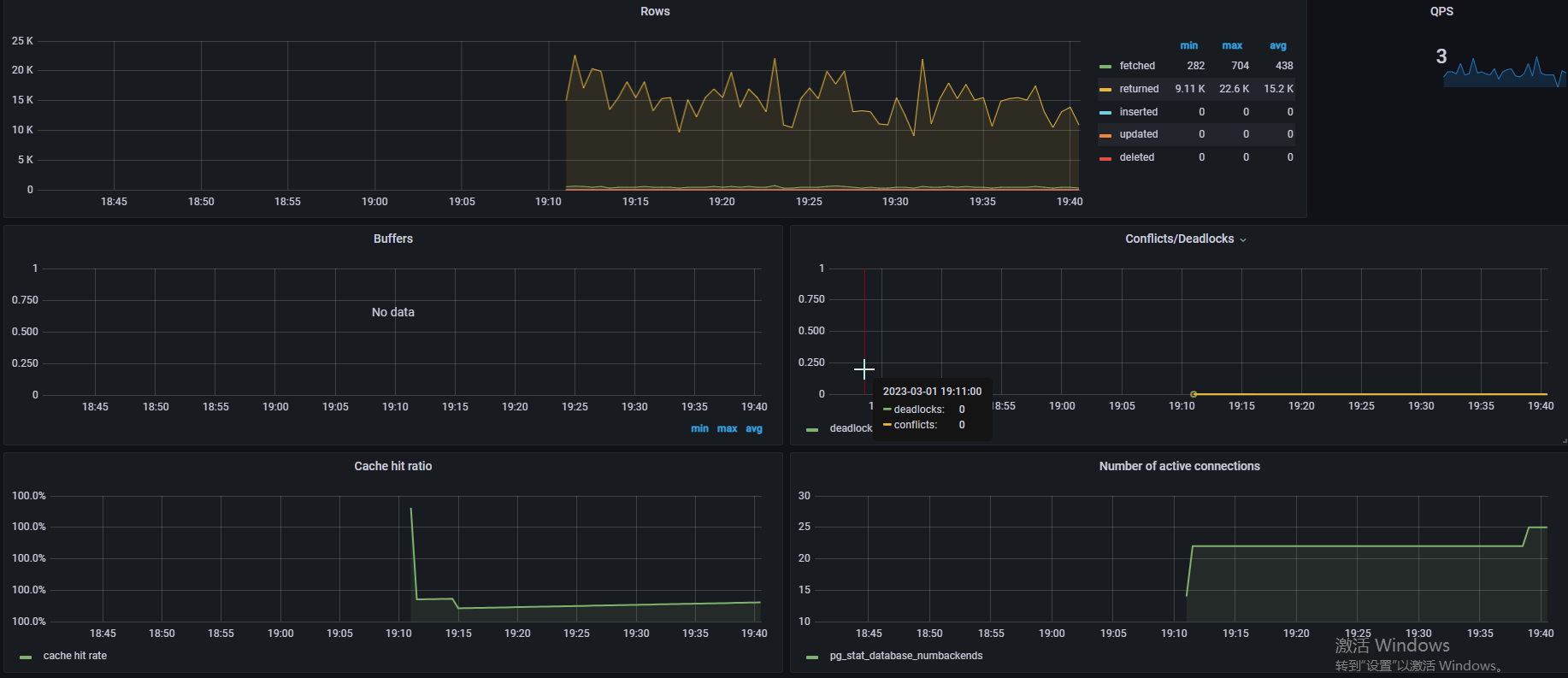
目录一、下载及部署二、postgres_exporter配置1. 停止脚本stop.sh2. 启动脚本start.sh3. queries.yaml三、PostgreSQL数据库配置1. 修改postgresql.conf配置文件2. 创建用户、表、扩展等四、参考一、下载及部署 下载地址 选一个amd64下载 上传至服务器,解压 tax…...

基于Java+SpringBoot+Vue+Uniapp(有教程)前后端分离健身预约系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《Spring家族及…...

【2023】DevOps、SRE、运维开发面试宝典之Redis相关面试题
文章目录 1、redis主从复制原理2、redis哨兵模式的原理3、reids集群原理4、Redis 哈希表进行的触发时机是什么?5、Redis 的 RDB 和 AOF 机制各自的优缺点是什么?这两种机制是否可以混合使用?6、Redis 经常被称为单线程的系统,你如何理解 Redis 的单线程模型7、redis 的事务…...

十五、MyBatis使用PageHelper
1.limit分页 limit分页原理 mysql的limit后面两个数字: 第一个数字:startIndex(起始下标。下标从0开始。) 第二个数字:pageSize(每页显示的记录条数) 假设已知页码pageNum,还有每页…...

【MySQL】B+ 树索引
一、索引是什么 ? 为什么需要索引 ? 索引就是目录,目录就是索引。 索引从 InnoDB 存储引擎数据存储结构上来看,就是为各个页建立的目录。保证我们在查询时,可以通过二分法快速定位到页,再在页内通过二分法…...

Android Gradle Plugin Version 和 Gradle Version 的对应关系
官网参考 以下是插件版本和Gradle 版本对应关系: 插件版本所需的最低 Gradle 版本Android Gradle Plugin VersionGradle Version1.0.0 - 1.1.32.2.1 - 2.31.2.0 - 1.3.12.2.1 - 2.91.5.02.2.1 - 2.132.0.0 - 2.1.22.10 - 2.132.1.3 - 2.2.32.14.1 - 3.52.3.03.33.0…...
)
更多单词/词组/短语补充和总结(二)
auto 美 /[ˈɔːtoʊ] n.汽车adj.与汽车有关的,汽车的。不要记成“自动的” mobile 美 /[ˈmoʊbl] adj.可移动的;流动的;不要记成“手机”,手机是mobile phone automobile 美 /[ˈɔːtəməbiːl] n.汽车adj.自动的 automatic 美 /[ˌɔːtəˈmtɪk]…...

HEC-HMS和HEC-RAS快速入门、防洪评价报告编制及洪水建模、洪水危险性评价等应用
目录 ①HEC-RAS一维、二维建模方法及实践技术应用 ②HEC-HMS水文模型实践技术应用 ③新导则下的防洪评价报告编制方法及洪水建模实践技术应用 ④基于ArcGIS水文分析、HEC-RAS模拟技术在洪水危险性及风险评估 ⑤山洪径流过程模拟及洪水危险性评价 ①HEC-RAS一维、二维建模方…...

全面了解 B 端产品设计 — 基础扫盲篇
在今天,互联网的影响力与作用与日俱增,除了我们日常生活领域的改变以外,对于商业领域的渗透也见效颇丰。 越来越多的企业开始使用数字化的解决方案来助力企业发展,包括日常管理、运营、统计等等。或者通过互联网的方式开发出新的业务形态,进行产业升级,如这几年风头正劲的…...
)
顺序表(增删查改)
目录一、什么是顺序表二、顺序表的增删查改2.1 结构体的声明2.2 顺序表的初始化2.3 顺序表检查容量2.4 顺序表尾部插入数据2.5 顺序表头部插入数据2.6 顺序表尾部删除数据2.7 顺序表头部删除数据2.8 顺序表查找数据2.9 顺序表任意位置插入数据2.10 顺序表任意位置删除数据2.11 …...

一款优秀的低代码开发平台是什么样的?
目录 一、一款优秀的低代码平台应该是什么样的? 二、低代码核心能力 01、全栈可视化编程: 02、全生命周期管理: 03、低代码扩展能力: 三、小结 一、一款优秀的低代码平台应该是什么样的? 从企业角度来说&#x…...
ElasticSearch 学习笔记总结(四)
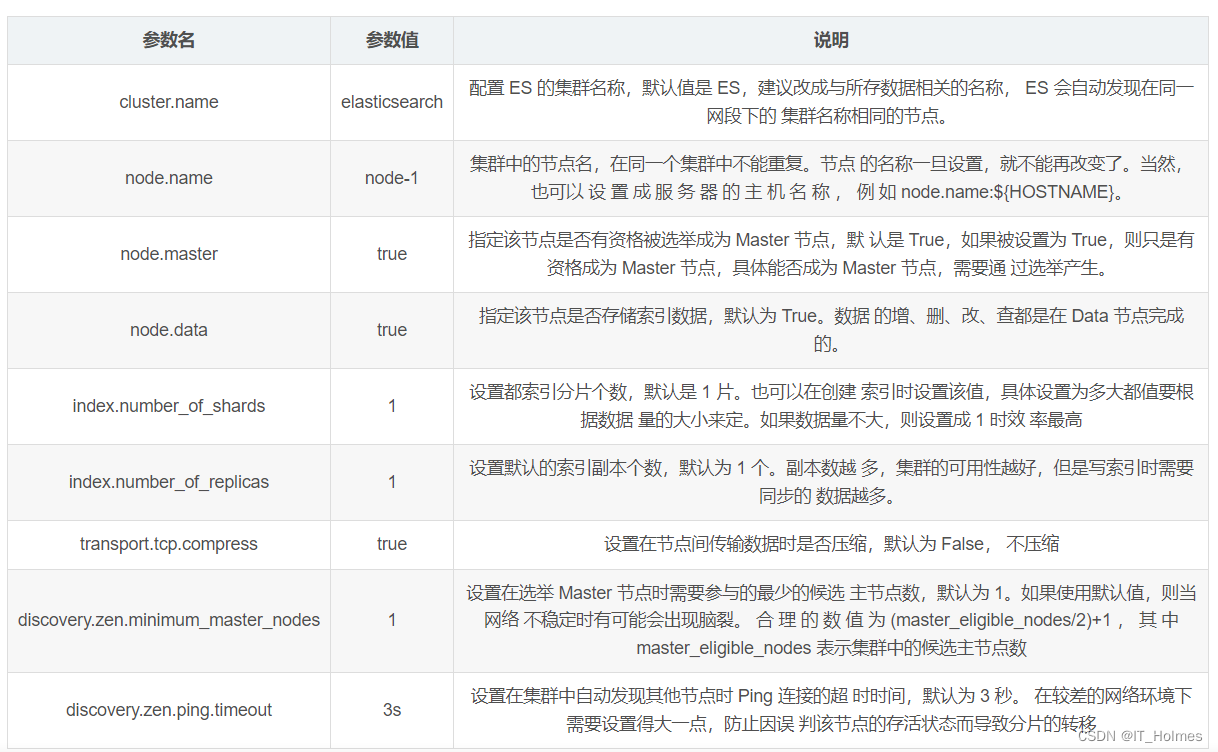
文章目录一、ES继承 Spring Data 框架二、SpringData 功能集成三、ES SpringData 文档搜索四、ES 优化 硬件选择五、ES 优化 分片策略六、ES 优化 路由选择七、ES 优化 写入速度优化七、ES 优化 内存设置八、ES 优化 重要配置一、ES继承 Spring Data 框架 Spring Data 是一个用…...

HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadooop2X版本中是128M,老版本中是64M。 思考:为什么块的大小不能设置太小&…...

C++——优先级队列(priority_queue)的使用及实现
目录 一.priority_queue的使用 1.1、基本介绍 1.2、优先级队列的定义 1.3、基本操作(常见接口的使用) 1.4、重写仿函数支持自定义数据类型 二.priority_queue的模拟实现 2.1、构造&&重要的调整算法 2.2、常见接口的实现 push() pop() top() empt…...

Linux学习记录——십일 环境变量
文章目录1、认识2、通过代码获取环境变量1、手动获取2、函数获取3、重新认识环境变量1、认识 在云服务器上写程序时,最终的执行需要./文件名,点表示当前目录,/是文件分隔符,之后就会打印程序,这是用户的操作ÿ…...
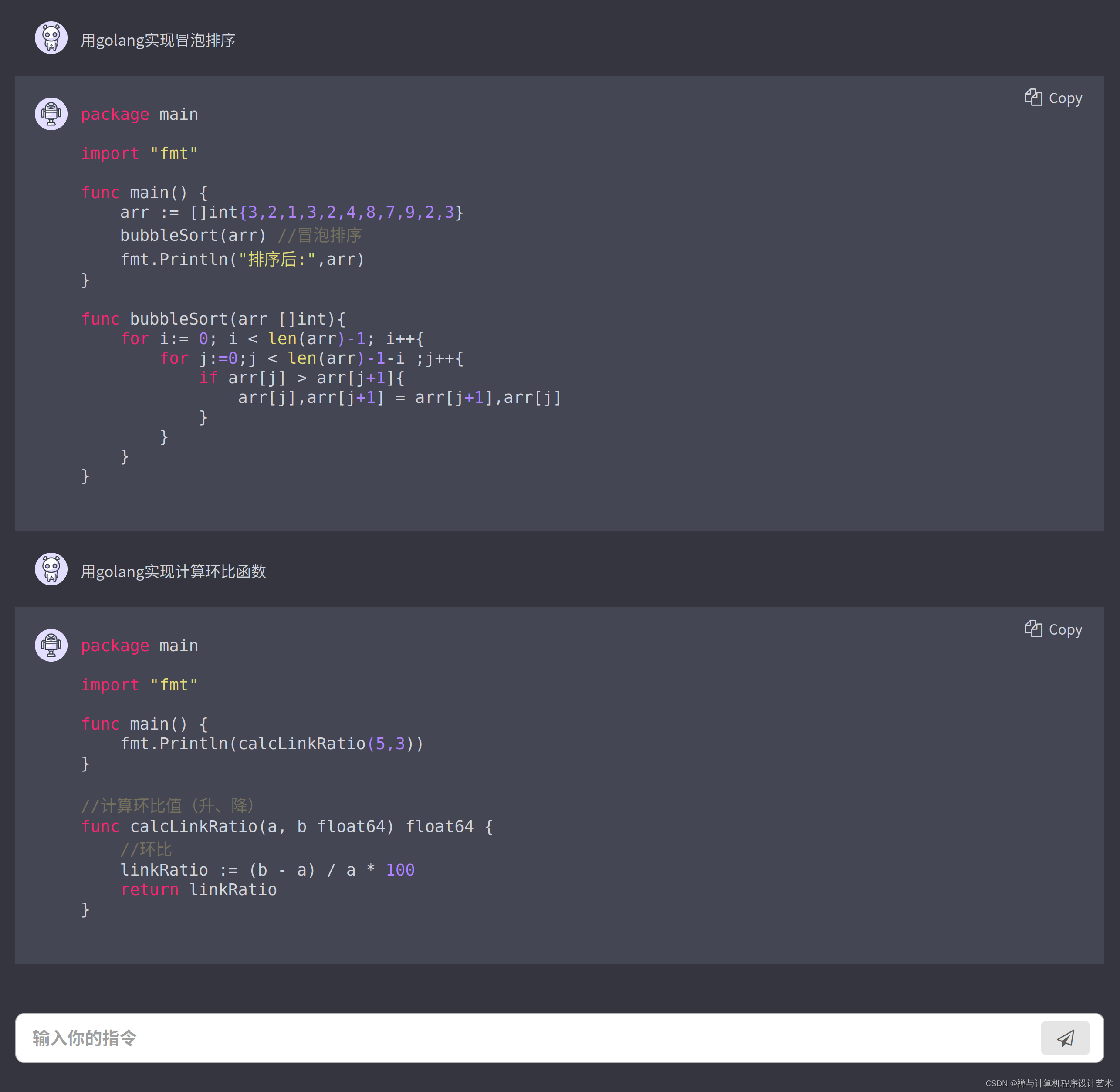
【人工智能 Open AI 】我们程序员真的要下岗了- 全能写Go / C / Java / C++ / Python / JS 人工智能机器人
文章目录[toc]人工智能 AI Code 写代码测试用golang实现冒泡排序用golang实现计算环比函数goroutine and channel用golang实现二叉树遍历代码用golang实现线程安全的HashMap操作代码using C programming language write a tiny Operation Systemuse C language write a tiny co…...

STM32 EXTI外部中断
本文代码使用 HAL 库。 文章目录前言一、什么是外部中断?二、外部中断中断线三、STM32F103的引脚复用四、相关函数:总结前言 一、什么是外部中断? 外部中断 是单片机实时地处理外部事件的一种内部机制。当某种外部事件发生时,单片…...
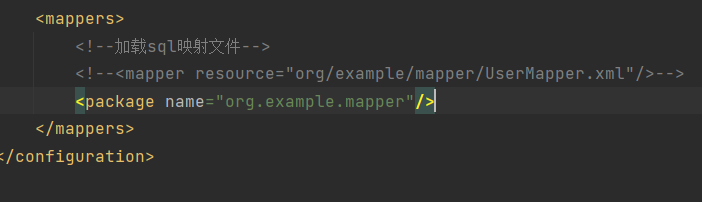
Mapper代理开发——书接MaBatis的简单使用
在这个mybatis的普通使用中依旧存在硬编码问题,虽然静态语句比原生jdbc都写更少了但是还是要写,Mapper就是用来解决原生方式中的硬编码还有简化后期执行SQL UserMapper是一个接口,里面有很多方法,都是一一和配置文件里面的sql语句的id名称所对…...

实体对象说明
1.工具类层Utilutil 工具顾明思义,util层就是存放工具类的地方,对于一些独立性很高的小功能,或重复性很高的代码片段,可以提取出来放到Util层中。2.数据层POJO对象(概念比较大) 包含了以下POJO plain ord…...

面向非技术人员的AI智能体实战:零代码自动化工作流构建指南
1. 项目概述:面向非工程师的AI智能体实战训练营如果你是一名市场、销售、运营或行政人员,每天被重复性的文档处理、数据分析、内容制作和跨平台沟通所淹没,看着工程师同事用代码自动化一切,自己却只能手动操作,那么你很…...

架构范式转移:DeepSeek-Coder-V2如何重构企业级代码智能的ROI模型
架构范式转移:DeepSeek-Coder-V2如何重构企业级代码智能的ROI模型 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Code…...

pdf2pptx:LaTeX到PowerPoint的无缝转换终极方案
pdf2pptx:LaTeX到PowerPoint的无缝转换终极方案 【免费下载链接】pdf2pptx Convert your (Beamer) PDF slides to (Powerpoint) PPTX 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2pptx 还在为LaTeX Beamer制作的精美学术幻灯片无法在PowerPoint中完美展…...

Stata 数据处理实战:时间序列数据的日期转换与聚合
1. 时间序列数据处理的常见痛点 刚接触时间序列分析的朋友们,经常会遇到这样的困扰:从Excel导入的数据明明是日期格式,到了Stata里却变成了看不懂的字符;想按周汇总销售数据,却发现系统根本不认识"2023-W15"…...

构建可靠AI智能体:从提示词工程到结构化内容生成的实战指南
1. 项目概述与核心思路最近在折腾AI应用开发,特别是想搞一个能稳定输出、逻辑清晰、还能带点“人味儿”的文本生成工具。市面上现成的方案要么太“机械”,要么定制化程度不够,总感觉差点意思。后来,我在一个开发者社区里看到了一个…...

OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案
OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record 你是否曾经在直播或录制视频时,想要单独保存某个特定的画面源…...

基于本地大模型与Playwright的隐私优先求职自动化助手RedClaw实践
1. 项目概述:一个真正为你掌控的本地化求职AI助手在求职季,我们常常面临一个两难困境:一方面,海投简历耗时耗力,重复填写那些大同小异的在线申请表让人筋疲力尽;另一方面,市面上一些所谓的“自动…...

终极KMS激活指南:如何一键永久激活Windows和Office
终极KMS激活指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统弹出激活警告而烦恼吗?或者Office软件突然变成只读模…...

CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件
CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 还在为重复的Java和Scala编码工作而烦恼…...

从ST-Ericsson案例剖析半导体合资企业的战略困境与生存法则
1. 从一篇旧文看半导体合资企业的生存逻辑最近在整理行业历史资料时,翻到了一篇2011年发布于EE Times的文章,标题是《ST-Ericsson还能撑多久?》。这篇文章像一枚时间胶囊,精准地记录了一家曾经备受瞩目的无线芯片合资公司在特定时…...