ChatGPT(GPT3.5) OpenAI官方API正式发布
OpenAI社区今天凌晨4点多发送的邮件,介绍了ChatGPT官方API的发布。官方介绍文档地址为“OpenAI API”和“OpenAI API”。

ChatGPT(GPT3.5)官方API模型名称为“gpt-3.5-turbo”和“gpt-3.5-turbo-0301”。API调用价格比GPT text-davinci-003模型便宜10倍。调用费用为0.002美元/1000tokens,折合下来差不多0.1元4000~5000字。这个字数包括问题和返回结果字数。
1 API调用方法
1.1 调用参数
ChatGPT(GPT3.5)官方API调用方式如下所示,与GPT3模型调用基本一致,输入主要有7个参数。预计今天晚上,这两个模型会集成到RdFast智能创作机器人小程序和RdChat桌面程序。大家可以随时体验一下,敬请关注。
- model:模型名称,gpt-3.5-turbo或gpt-3.5-turbo-0301
- messages:问题或待补全内容,下面重点介绍。
- temperature:控制结果随机性,0.0表示结果固定,随机性大可以设置为0.9。
- max_tokens:最大返回字数(包括问题和答案),通常汉字占两个token。假设设置成100,如果prompt问题中有40个汉字,那么返回结果中最多包括10个汉字。ChatGPT API允许的最大token数量为4096,即max_tokens最大设置为4096减去问题的token数量。
- top_p:设置为1即可。
- 6frequency_penalty:设置为0即可。
- presence_penalty:设置为0即可。
- stream。
需要注意,上述输入参数增加stream,即是否采用控制流的方式输出。
如果stream取值为False,那么返回结果与第1节GPT3接口一致,完全返回全部文字结果,可通过response["choices"][0]["text"]进行读取。但是,字数越多,等待返回时间越长,时间可参考控制流读出时的4字/每秒。
如果steam取值为True时,那么返回结果是一个Python generator,需要通过迭代获取结果,平均大约每秒钟4个字(33秒134字,39秒157字),读取程序如下所示。可以看到,读取结果的结束字段为“<|im_end|>”。
1.2 messages
messages字段组成部分包括角色role和content问题两个部分组成,如下所示:
model="gpt-3.5-turbo",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Who won the world series in 2020?"},{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},{"role": "user", "content": "Where was it played?"}]在gpt-3.5-turbo模型中,角色role包含system系统、assistant助手和用户user三种类型。System角色相当于告诉ChatGPT具体以何种角色回答问题,需要在content中指明具体的角色和问题内容。而gpt-3.5-turbo-0301主要区别在于更加关注问题内容,而不会特别关注具体的角色部分。gpt-3.5-turbo-0301模型有效期到6月1日,而gpt-3.5-turbo会持续更新。
assistant助手和用户user则相当于已经指明了角色,content直接写入关注的问题即可。
2 参考程序
示例参考程序如下所示:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 21 21:58:59 2022@author: Administrator
"""import openaidef openai_reply(content, apikey):openai.api_key = apikeyresponse = openai.ChatCompletion.create(model="gpt-3.5-turbo-0301",#gpt-3.5-turbo-0301messages=[{"role": "user", "content": content}],temperature=0.5,max_tokens=1000,top_p=1,frequency_penalty=0,presence_penalty=0,)# print(response)return response.choices[0].message.contentif __name__ == '__main__':content = '你是谁?'ans = openai_reply(content, '你的APIKEY')print(ans)3 API调用效果

相关文章:
ChatGPT(GPT3.5) OpenAI官方API正式发布
OpenAI社区今天凌晨4点多发送的邮件,介绍了ChatGPT官方API的发布。官方介绍文档地址为“OpenAI API”和“OpenAI API”。 ChatGPT(GPT3.5)官方API模型名称为“gpt-3.5-turbo”和“gpt-3.5-turbo-0301”。API调用价格比GPT text-davinci-003模型便宜10倍。调用费用为…...
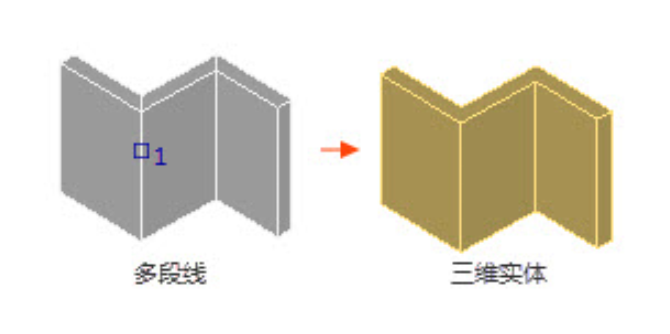
CAD中如何将图形对象转换为三维实体?
有些小伙伴在CAD绘制完图纸后,想要将图纸中的某些图形对象转换成三维实体,但却不知道该如何操作,其实很简单,本节CAD绘图教程就和小编一起来了解一下浩辰CAD软件中将符合条件的对象转换为三维实体的相关操作步骤吧! 将…...
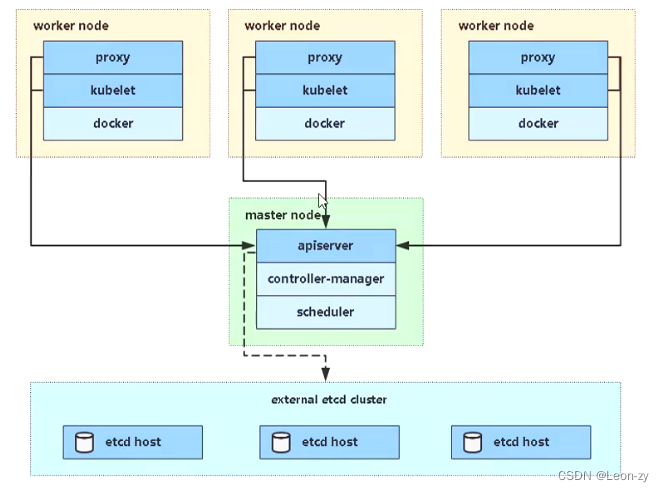
【K8S笔记】Kubernetes 集群架构与组件介绍
K8S 官方文档 https://kubernetes.io/zh/docs/home ##注重关注 概念和任务 板块。 K8S 集群架构 K8S也是运用了分布式集群架构: 管理节点/Master 整个集群的管理,任务协作。工作节点/Node 容器运行、删除。 K8S 组件介绍 管理节点/Master 相关组件 …...
9 怎么登录VNC
1)首先在ssh登录后启动vncserver。登陆后输入下面的指令来创建自己的VNC。 命令vncserver :16 –geometry 1900x1000 其中:16是分配的端口号,1900x1000是分辨率。如果没有响应,建议执行下面操作后再次重复上面操作。 命令…...
MPI ubuntu安装,mpicc,mpicxx,mpif90的区别
介绍 MPI是并行计算的一个支持库,支持对C、C、fortran语言进行并行计算。 安装基础环境 ubuntu进行gcc/g/gfortran的安装: gcc: ubuntu下自带gcc编译器。可以通过gcc -v命令来查看是否安装。 g: sudo apt-get install buil…...

移动端笔记
目录 一、移动端基础 二、视口 三、二倍图/多倍图 四、移动端开发 (一)开发选择 (二)常见布局 (三)移动端技术解决方案 五、移动WEB开发之flex布局 六、移动WEB开发之rem适配布局 #END(…...

操作系统笔记、面试八股(一)—— 进程、线程、协程
文章目录1. 进程、线程、协程1.1 进程1.1.1 进程间的通信方式1.1.2 进程同步方式1.1.3 进程的调度算法1.1.4 优先级反转1.1.5 进程状态1.1.6 PCB进程控制块1.1.7 进程的创建和撤销过程1.1.8 为什么要有进程1.2 线程1.2.1 为什么要有线程1.2.2 线程间的同步方式1.3 协程1.3.1 什…...
Python每日一练(20230302)
目录 1. 字符串统计 2. 合并两个有序链表 3. 下一个排列 附录 Python字典内置方法 增 删 改 查 其它 1. 字符串统计 从键盘输入一个包含有英文字母、数字、空格和其它字符的字符串,并分别实现下面的功能:统计字符串中出现2次的英文字母&#…...

Numpy课后练习
Numpy课后练习 文章目录 Numpy课后练习一、前言二、题目及答案一、前言 答案仅供参考,谢谢大家! 二、题目及答案 导入Numpy包并设置随机数种子为666 import numpy as np np.random.seed(666)创建并输出一个包含12个元素的随机整数数组r1,元素的取值范围在[30,100)之间 r1 …...

动态规划dp中的子序列、子数组问题总结
目录 定义dp数组 初始化dp数组 状态转移方程 最终结果 题目 定义dp数组 这类问题的共性是会提供两个数组,寻找他们共同的子序列、子数组。设第一个数组为s,第二个数组为t。则可以设二维dp数组,其大小为len(s + 1)*len(t + 1) dp[i][j]表示 s 前 i 个长度,...
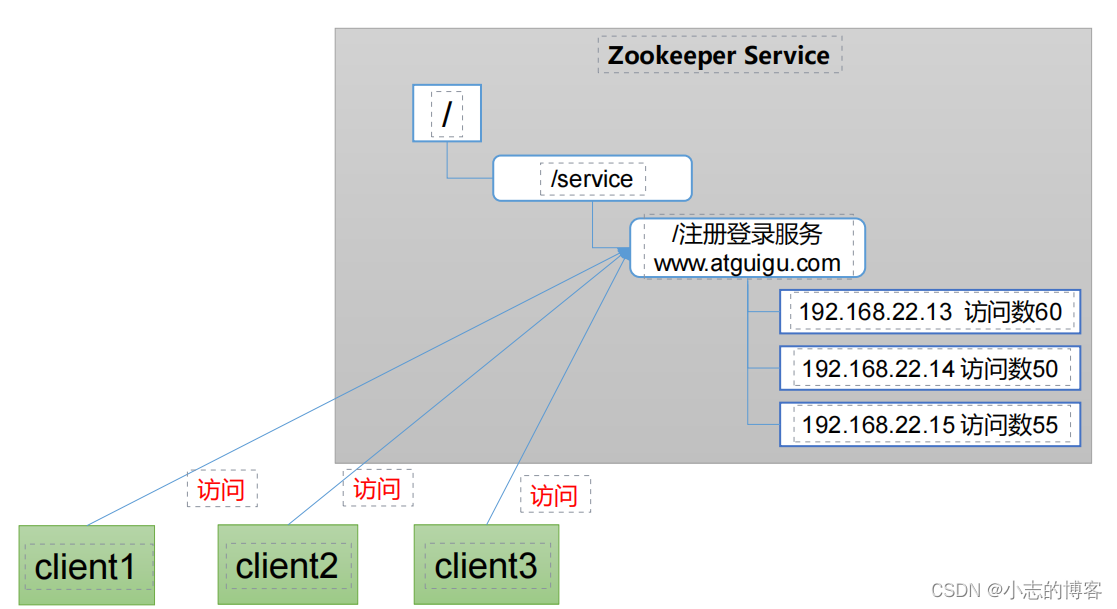
Zookeeper3.5.7版本——Zookeeper的概述、工作机制、特点、数据结构及应用场景
目录一、Zookeeper的概述二、Zookeeper的工作机制三、Zookeeper的特点四、Zookeeper的数据结构五、Zookeeper的应用场景5.1、统一命名服务5.2、统一配置管理5.3、统一集群管理5.4、服务器动态上下线5.5、软负载均衡一、Zookeeper的概述 Zookeeper 是一个开源的分布式的&#x…...
安卓逆向学习及APK抓包(二)--Google Pixel一代手机的ROOT刷入面具
注意:本文仅作参考勿跟操作,root需谨慎,本次测试用的N手Pixel,因参考本文将真机刷成板砖造成的损失与本人无关 1 Google Pixel介绍 1.1手机 google Pixel 在手机选择上,优先选择谷歌系列手机,Nexus和Pixel系列&…...

线程池的基本认识与使用
线程池的基本认识与使用线程池线程池工作原理:优点:传统的创建线程方式线程池创建线程使用线程池 池化思想:线程池、字符串常量池、数据库连接池可以提高资源的利用率 线程池工作原理: 预先创建多个线程对象 放入线程池种&#…...
小家电品牌私域增长解决方案来了
小家电品牌的私域优势 01、行业线上化发展程度高 相对于大家电动辄上千上万元的价格,小家电的客单价较低。而且与大家电偏刚需属性不同的是,小家电的消费需求侧重场景化,用户希望通过购买小家电来提高自身的生活品质。这就决定了用户的决策…...

什么是让ChatGPT爆火的大语言模型(LLM)
什么是让ChatGPT爆火的大语言模型(LLM) 更多精彩内容: https://www.nvidia.cn/gtc-global/?ncidref-dev-876561 文章目录什么是让ChatGPT爆火的大语言模型(LLM)大型语言模型有什么用?大型语言模型如何工作?大型语言模型的热门应用在哪里可以找到大型语言…...
【监控】Linux部署postgres_exporter及PG配置(非Docker)
目录一、下载及部署二、postgres_exporter配置1. 停止脚本stop.sh2. 启动脚本start.sh3. queries.yaml三、PostgreSQL数据库配置1. 修改postgresql.conf配置文件2. 创建用户、表、扩展等四、参考一、下载及部署 下载地址 选一个amd64下载 上传至服务器,解压 tax…...

基于Java+SpringBoot+Vue+Uniapp(有教程)前后端分离健身预约系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《Spring家族及…...

【2023】DevOps、SRE、运维开发面试宝典之Redis相关面试题
文章目录 1、redis主从复制原理2、redis哨兵模式的原理3、reids集群原理4、Redis 哈希表进行的触发时机是什么?5、Redis 的 RDB 和 AOF 机制各自的优缺点是什么?这两种机制是否可以混合使用?6、Redis 经常被称为单线程的系统,你如何理解 Redis 的单线程模型7、redis 的事务…...

十五、MyBatis使用PageHelper
1.limit分页 limit分页原理 mysql的limit后面两个数字: 第一个数字:startIndex(起始下标。下标从0开始。) 第二个数字:pageSize(每页显示的记录条数) 假设已知页码pageNum,还有每页…...

【MySQL】B+ 树索引
一、索引是什么 ? 为什么需要索引 ? 索引就是目录,目录就是索引。 索引从 InnoDB 存储引擎数据存储结构上来看,就是为各个页建立的目录。保证我们在查询时,可以通过二分法快速定位到页,再在页内通过二分法…...

量子误差缓解技术与BBGKY层次结构的应用
1. 量子误差缓解的现状与挑战在当前的NISQ(噪声中等规模量子)时代,量子计算机的实际应用面临着一个根本性障碍:量子噪声。与经典计算机不同,量子比特极易受到环境干扰,导致计算错误。这种噪声主要来源于量子…...

Degrees of Lewdity 本地化实践指南
Degrees of Lewdity 本地化实践指南 Degrees of Lewdity 作为一款开源游戏,其本地化实践是打破语言壁垒、实现文化适配的关键环节。本文将从本地化价值定位、环境适配、执行蓝图、故障诊断、进阶优化到生态导航,为零基础用户提供一套完整的本地化技术方…...

LLM Wiki Bridge:将Markdown知识库编译为AI可操作的概念图谱
1. 项目概述:将你的知识库变成AI的“第二大脑” 如果你和我一样,是个重度笔记用户,大概率也经历过这样的场景:在Obsidian、Logseq或者任何你喜欢的Markdown编辑器里,日积月累了成百上千篇笔记。你清楚地记得自己写过某…...

感应照明技术:从工业到家用,一场技术降维的工程冒险
1. 项目概述:当感应照明技术走进寻常百姓家最近在整理一些老旧的行业资料时,翻到了2014年的一则新闻,讲的是当时一家初创公司“Finally Light Bulb Company”宣布要推出一款售价低于10美元的感应灯泡,用来替代传统的白炽灯。这让我…...

LLM长文本处理实战:模块化分割策略与向量化预处理指南
1. 项目概述:一个为LLM打造的文本处理中心如果你和我一样,经常和大型语言模型打交道,无论是用它来总结文档、分析代码,还是处理客服对话,那你肯定遇到过这个痛点:喂给模型的文本太长了怎么办?模…...

泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南
泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets y…...

保姆级教程:用Lumerical FDTD参数扫描功能,分析WO3薄膜厚度对反射率的影响
从零到精通:Lumerical FDTD参数扫描在薄膜光学设计中的实战指南 在光电材料研究和器件设计中,薄膜厚度的精确控制往往直接影响器件的光学性能。以三氧化钨(WO₃)薄膜为例,其厚度变化会显著改变反射光谱特性,…...

中文知识管理利器:本地化部署与向量检索实践指南
1. 项目概述:一个面向中文用户的知识管理利器 最近在折腾个人知识库,发现了一个挺有意思的开源项目,叫 RomeoSY/zh-knowledge-manager 。乍一看名字,你可能觉得这又是一个“知识管理”工具,市面上不是有 Notion、Ob…...

基于MCP协议构建AI知识库:解决会话失忆,实现知识持久化
1. 项目概述:让AI拥有自己的“亚历山大图书馆”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手打交道,一定会遇到一个核心痛点:会话失忆。每次开启一个新对话,AI助手就像一张白纸,它对你项目的历…...

保姆级避坑指南:用GGCNN源码处理Cornell抓取数据集,解决tiff文件生成失败问题
GGCNN源码实战:Cornell数据集预处理深度排错指南 第一次运行GGCNN的Cornell数据集预处理脚本时,我盯着毫无反应的终端窗口足足等了十分钟——没有进度条,没有错误提示,只有光标在无情地闪烁。这大概是每个复现论文的开发者都会经历…...