HBase-架构与设计
HBase架构与设计
- 一、背景
- 二、HBase概述
- 1.设计特点
- 2.适用场景
- 2.1 海量数据
- 2.2 稀疏数据
- 2.3 多版本数据
- 2.4 半结构或者非结构化数据
- 三、数据模型
- 1.表逻辑结构
- 2.RowKey
- 3.Column Family
- 4.TimeStamp
- 5.存储结构
- 四、HBase架构图
- 1.Client
- 2.Zookeeper
- 3.HMaster
- 4.HRegionServer
- 5.HRegion
- 6.Store
- 7.StoreFile
- 8.HLog
- 五、元数据存储
- 1.元数据表
- 2.数据结构
- 六、写流程
- 1.获取Meta元数据
- 2.获取RegionServer
- 3.发送写入请求
- 七、读流程
- 1.获取Meta元数据
- 2.获取RegionServer
- 3.发送读请求
- 八、持久化
- 1.恢复机制
- 2.MemStore 刷盘
- 2.1 Memstore级别限制
- 2.2 Region级别限制
- 2.3 Region Server级别限制
- 2.4 HLog数量上限
- 2.5 定期刷新Memstore
- 2.6 手动flush
- 3.HFile 合并
- 3.1 合并原理
- 3.2 Minor Compaction
- 3.3 Major Compaction
- 总结
- 参考链接
一、背景
HBase是一个基于java的NoSQL分布式列存储数据库,主要用于存储非结构化和半结构化的松散数据。将Hadoop中的HDFS作为底层文件存储系统,来提供容错和可靠性,以及存储系统的拓展性。
HBase的设计思想来自Google的Bigtable论文,是分布式数据库的实现。HDFS是一个高可靠、高延迟的分布式文件系统,但是不支持对数据的随机访问和更新,因此不适合实时计算系统。HBase是一个可以提供实时计算的大数据分布式数据库,支持对数据的随机访问和更新。
二、HBase概述
HBase的底层存储引擎是基于LSM-Tree数据结构设计的,存储是基于HDFS。而针对数据的更新和删除,不是修改原有记录而是新增一条记录,这样可以充分发挥顺序写的性能,但是查询的时候就需要查询磁盘中的文件和内存中的操作,读取所有数据版本。因此HBase写性能比读性能提高了两个数量级。
1.设计特点
- 强一致性读写:HBase时强一致性读写,适合高速计数聚合之类的任务。
- 自动分片:HBase表会按照水平方向拆分成Region分布在集群上,Region会随着数据增长自动拆分和重新均衡。
- 故障转移:RegionServer如果发生故障会自动恢复
- 集成HDFS:HBase内部集成HDFS作为其持久化存储组件
- 支持MapReduce:HBase支持MapReduce进行大规模并行处理,支持写入和读取。
- 查询优化:HBase通过块缓存和布隆过滤器来优化大容量查询
2.适用场景
2.1 海量数据
传递RDRMS当数据量增大时,需要读写分离策略来解决服务器压力。如果数据量继续增加就需要分库分表,这就限制了一些关联查询并引入中间层。每次变动都需要很多准备工作和业务代码修改验证。而且即使分库分表也无法解决一些数据倾斜和热点问题。HBase支持自动水平拓展,内部集成HDFS解决数据可靠性,还支持利用MapReduce进行海量数据分析。
2.2 稀疏数据
HBase作为列式存储适合稀疏数据,针对为null的列不会进行存储,这样可以节约存储空间并提高读性能。
2.3 多版本数据
HBase的更新和删除操作不会修改原有记录而是通过新增记录实现。通过RowKey和ColumnKey定位到多个TimeStamp相关的Value值,因此可以存储变动历史记录。可以通过设置版本数量,来确定HBase保留几次变动记录。
2.4 半结构或者非结构化数据
HBase无固定模式,不需要停机进行维护,支持半结构和非结构化的数据。
三、数据模型
作为一个面向列的分布式数据库,存储的数据是稀疏、多维、有序的。HBase表中的一条数据是由全局唯一的键(RowKey)和任意数量的列(Column),一列或者多列组成一个列族(Column Family)。
其中列族名和数量需要在建表确定,但一个列族下面可以增加任意个列限定名。一个列限定名代表了实际中的一列,HBase将同一个列族下面的所有列存储在一起,所以HBase是一种面向列族式的数据库。
1.表逻辑结构
以下是一个HBase表的实例。其中有一个唯一主键,包含PersonalInfo列族、其中包括三个列name、age、phone;包含OfficeInfo列族、其中包括列tel和city。并且根据时间戳TimeStamp会存储多版本数据。
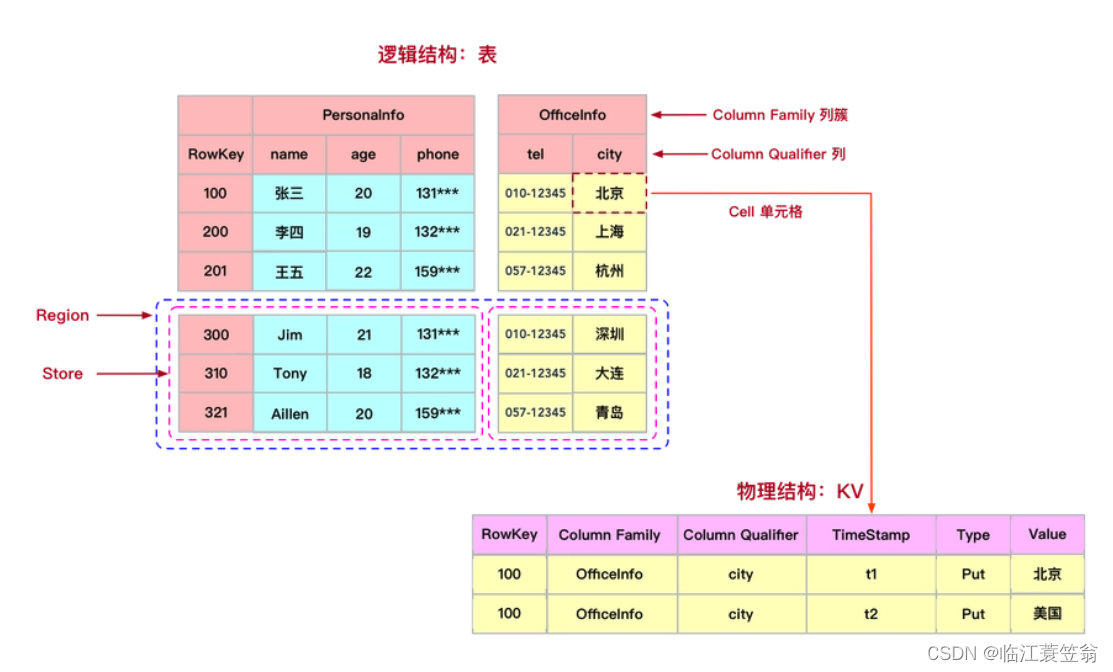
2.RowKey
RowKey与关系型数据库中的主键类似,用来唯一标识某行数据。整个表是按照RowKey进行排序。HBase按照RowKey划分为多个Region存储在不同的Region Server上,可以分布式对表进行存储和读取。
3.Column Family
Column Family是列族,一个列族可以包含多列。同一个列族中列数据都存储在Region的一个Store中。
4.TimeStamp
TimeStamp 是实现 HBase 多版本的关键。在HBase 中,使用不同 TimeStamp 来标识相同RowKey对应的不同版本的数据。
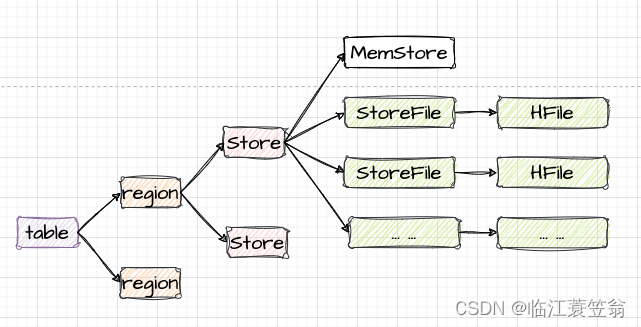
5.存储结构
HBase表根据主键水平拆分成多个region,每个region根据列族拆分为Store,每个Store包含一个内存MemStore和零个或者多个StoreFile,StoreFile以HFile文件形式存储在HDFS上。
HBase表的存储结构如下图:
四、HBase架构图
HBase采用Master/Slave架构搭建集群,属于Hadoop生态系统的一部分。由HMaster节点、HRegionServer节点、Zookeeper集群组成,而数据会存储在HDFS中。整体架构如下图:
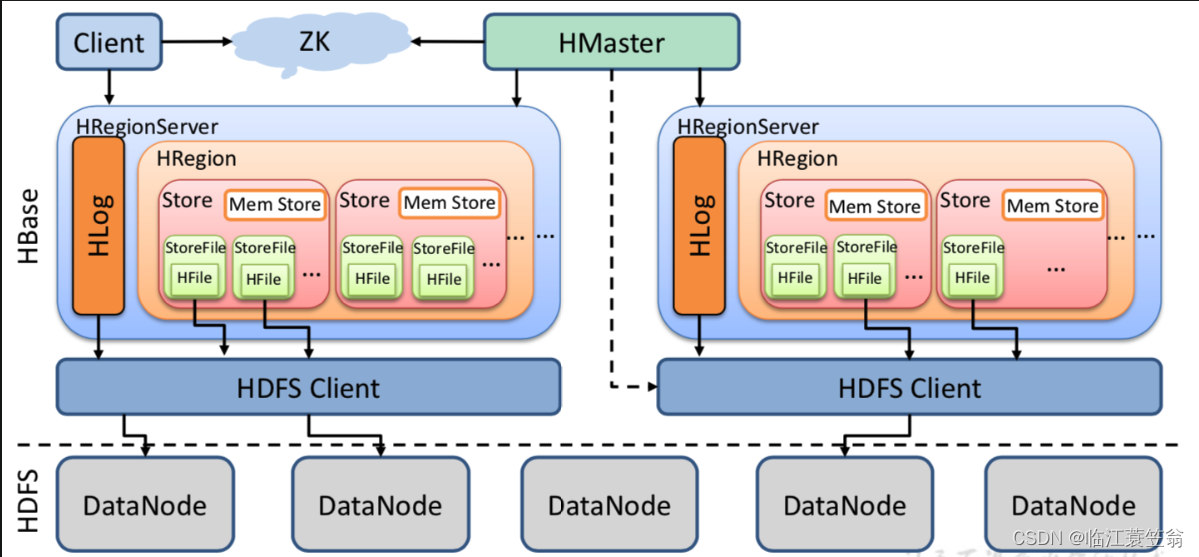
对HBase架构组成的每一个部分介绍如下。
1.Client
用户访问HBase的客户端,主要是包含HBase的接口,会缓存元数据来加快对HBase的访问。
2.Zookeeper
Zookeeper主要协调和管理HMaster和HRegionServer。HMaster和HRegionServer启动时会向Zookeeper进行注册。作用如下:
- 保证任何时候,集群中只有一个HMaster。
- 存储所有HRegion的寻址入口。
- 实时监控HRegionServer的上线和下线信息,并通知给HMaster
- 存储HBase的Schema和Table元数据
3.HMaster
负责管理RegionServer并实现负载均衡,管理和分配Region,管理namespace和table元数据。
4.HRegionServer
用来维护HMaster分配的region,处理这些region的读写请求,并且负责将运行过程中过的region进行切分。
5.HRegion
Region是HBase中分布式存储和负责均衡的最小单位。HBase表按照行方向被拆分为多个Region。不同的Region可以分布在不同的HRegionServer上,同一个Region只能在同一个HRegionServer上。当Region的某个列族达到一定阀值会被拆分成两个新的Region。
6.Store
每个Region按照ColumnFamily拆分成Store,一个Region由一个或者多个Store组成。每个ColumnFamliy会建一个Store,一个Store由一个memStore和多个StoreFile组成。
7.StoreFile
memStore中的数据写到文件之后就是StoreFile。StoreFIle底层就是HFile的格式保存在存储系统中。
8.HLog
记录数据的所有变更和操作日志,用来故障恢复。当Region Server出现故障,可以通过HLog恢复数据
五、元数据存储
1.元数据表
HBase中有一个系统表hbase:meta来存储HBase元数据。该表保存了所有的Region信息,hbase:meta也是一个HBase表被HRegionServer管理,hbase:meta表的位置信息保存在Zookeeper中。
2.数据结构
元数据表有一个RowKey和一个ColumnFamily组成,其中RowKey包括表名、起始Key、region编号。只包含一个info列族,包含三列:
- info:regioninfo:regionId,tableName,startKey,endKey,offline,split,replicaId;
- info:server:HRegionServer对应的server:port;
- info:serverstartcode:HRegionServer的启动时间戳。
六、写流程
HBase的写入过程由于相当于添加新记录,因此写数据比读数据快,整体流程如下:
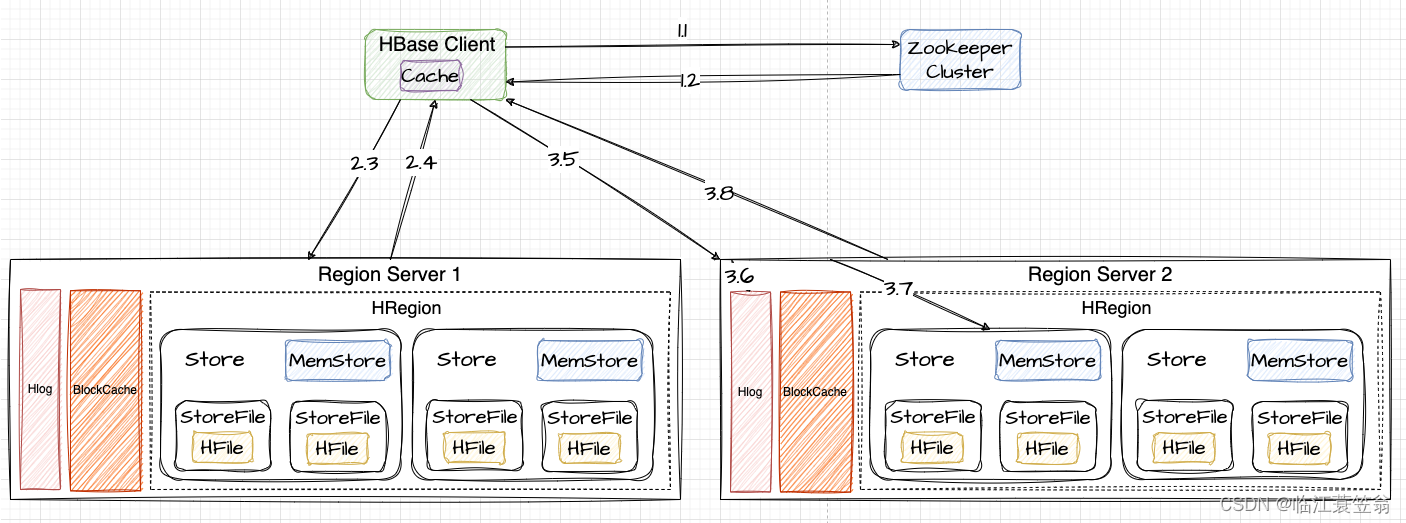
1.获取Meta元数据
首先需要知道表的元数据,也就是要知道表的region列表,这个信息时维护在meta表中。
1.1 client访问zookeeper获取Meta表所在的RegionServer信息
1.2 从zookeeper节点返回meta的RegionServer1信息
2.获取RegionServer
从Meta表中查询表的Region信息以及负责Region维护的RegionServer信息。
2.3 根据表名和RowKey向meta所在的RegionServer1发送查询请求
2.4 RegionServer1找到对应的meta的记录,返回对应Region信息,其中包括RegionServer2信息。Client会缓存此Region信息。
3.发送写入请求
向RegionServer2发送写请求。
3.5 向Region所在的RegionServer2发送写请求
3.6 RegionServer2将数据先写入到HLog,为了数据的持久化和恢复
3.7 RegionServer2将数据写入到MemStore。
3.8 RegionServer2返回给Client告知写入成功。
七、读流程
HBase读取数据需要返回所有版本数据,所以可能需要查询所有HFile文件,读性能比写慢了两个数量级。读取流程获取Meta元数据和RegionServer的过程和写过程一致。
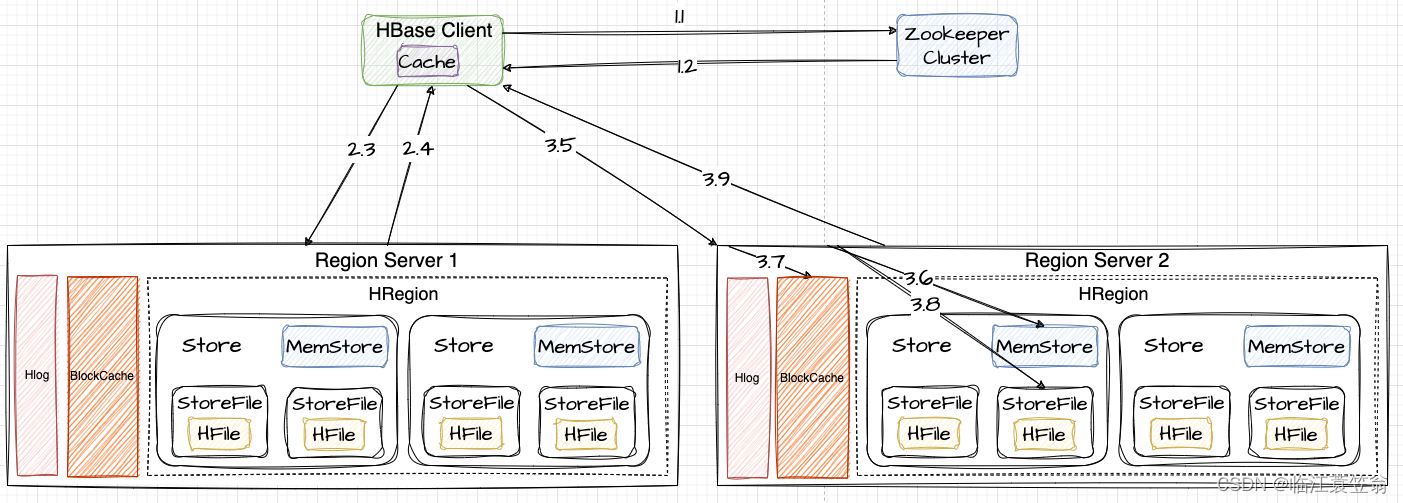
1.获取Meta元数据
跟写过程一致
2.获取RegionServer
跟写过程一致
3.发送读请求
向RegionServer2发送写请求。
3.5 向Region所在的RegionServer2发送写请求
3.6 先在MemStore进行查找
3.7 如果MemStore没有,则需要在BlockCache中查找
3.8 如果BlockCache没有,则需要在StoreFile上查找
3.9 如果StoreFile查到到数据,需要将数据写入到BlockCache,再返回给Client。
八、持久化
1.恢复机制
上边的写请求过程可知,数据会先写入到HLog,然后再写入到内存MemStore。
- HLog保存的是RegionServer上所有的日志操作,是记录操作的一种日志。当MemStore数据还没有持久化时,可以通过HLog进行故障恢复,保证数据正确性和持久化。
- MemStore是在内存中维持列族数据按照RowKey顺序排列,然后顺序写入到磁盘中。主要是为了将来检索优化,将数据写入到HDFS之前在内存中将数据完成排序。
2.MemStore 刷盘
MemStore维持当前在内存中的同一个列族数据按照RowKey有序,当MemStore达到一定时机时会将MemStore中数据以HFile形式持久化到文件系统中。Flush触发条件如下:
2.1 Memstore级别限制
当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新
<property><name>hbase.hregion.memstore.flush.size</name><value>134217728</value>
</property>
2.2 Region级别限制
当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新
<property><name>hbase.hregion.memstore.flush.size</name><value>134217728</value>
</property>
<property><name>hbase.hregion.memstore.block.multiplier</name><value>4</value>
</property>
2.3 Region Server级别限制
当一个Region Server中所有Memstore的大小总和超过低水位阈值hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size(前者默认值0.95),RegionServer开始强制flush
<property><name>hbase.regionserver.global.memstore.size.lower.limit</name><value>0.95</value>
</property>
<property><name>hbase.regionserver.global.memstore.size</name><value>0.4</value>
</property>
- 先Flush Memstore最大的Region,再执行次大的,依次执行;
- 如写入速度大于flush写出的速度,导致总MemStore大小超过高水位阈值,此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值
2.4 HLog数量上限
当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
2.5 定期刷新Memstore
默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
2.6 手动flush
用户可以通过shell命令flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
3.HFile 合并
memstore每次刷新都会生成一个新的HFile文件,由于触发机制导致可能生成的大部分新HFile文件都是小文件。这样会导致查询过程中需要遍历非常多的小文件,导致维护困难、影响查询性能和效率。为了查询优化和清理过期数据,所以会对HFile进行合并。Compaction分为两类:Minor Compaction和Major Compaction。
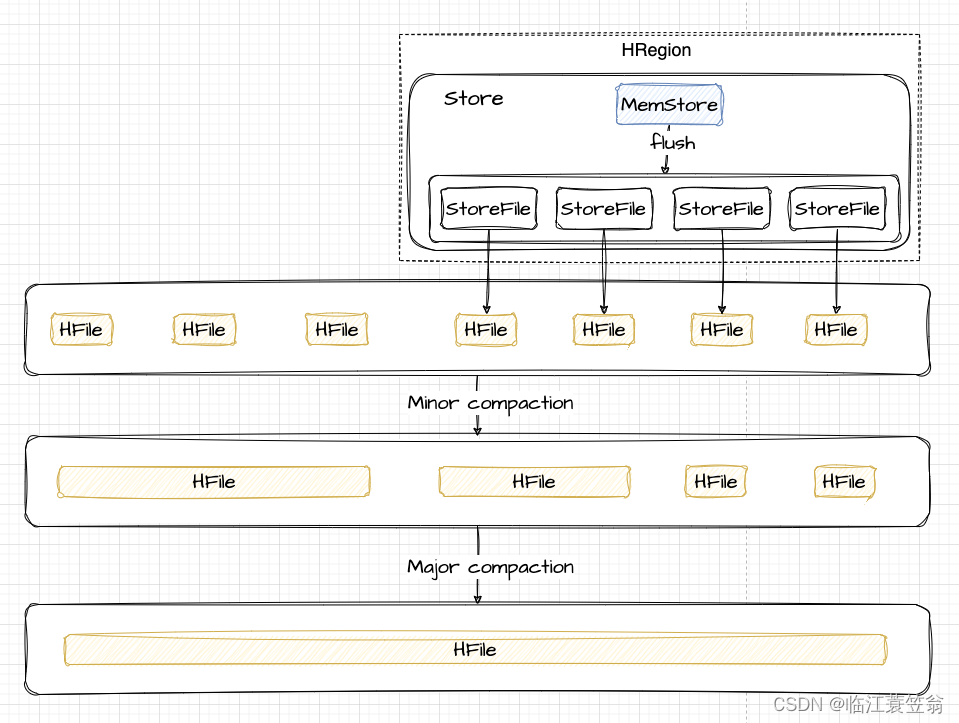
3.1 合并原理
合并原理是指从一个Store中的部分HFile文件整合成一个新的HFile文件,其中会从待合并数据从文件读出,然后按照由小到达排序后写入新文件。
3.2 Minor Compaction
选取部分小的相邻的HFile,将他们合并成一个更大的HFile。
3.3 Major Compaction
将一个Store中所有的HFile合并成一个HFile。同时会清理掉过期、删除、多版本数据。
总结
HBase是基于分布式文件系统HDFS构建的一个大数据、NoSQL、可拓展分布式数据库。采用Master/Slave架构、用Zookeeper进行元数据保存和协调工作。采用LSM-TREE作为存储引擎,由于HDFS不支持修改和更新,所以HBase中将修改和更新作为新记录存储到HDFS中。HBase用牺牲读性能来提升大数据写入能力。
参考链接
1.Hbase原理
2.HBase教程
相关文章:
HBase-架构与设计
HBase架构与设计 一、背景二、HBase概述1.设计特点2.适用场景2.1 海量数据2.2 稀疏数据2.3 多版本数据2.4 半结构或者非结构化数据 三、数据模型1.表逻辑结构2.RowKey3.Column Family4.TimeStamp5.存储结构 四、HBase架构图1.Client2.Zookeeper3.HMaster4.HRegionServer5.HRegi…...

SpringBoot基础系列:工具类使用
断言 Assert // 要求参数 object 必须为非空(Not Null),否则抛出异常,不予放行 // 参数 message 参数用于定制异常信息。 void notNull(Object object, String message) // 要求参数必须空(Null)ÿ…...

使用 nohup java - jar 不输出日志
要在使用nohup java -jar命令时不输出日志,可以将标准输出和标准错误输出重定向到特殊设备文件/dev/null。这样做将会丢弃所有的输出。 以下是在Linux中使用nohup java -jar命令并禁止输出日志的示例: 复制代码 nohup java -jar your-application.jar …...
前端开发学习 (五) 生命周期函数、Ajax请求
关于vue实例的声明周期,从Vue实例创建、运行、到销毁期间,总是伴随着各种各样的事件,这些事件,统称为生命周期 (https://cn.vuejs.org/v2/guide/instance.html#实例生命周期 ) 而声明周期勾子就是生命周期…...
TypeScript中的单件设计模式
基本概念 (1) 了解设计模式 设计模式通俗的讲,就是一种更好的编写代码方案,打个比喻:从上海到武汉,你可以选择做飞机,做轮船,开车,骑摩托车多种方式,把出行…...

【无标题】安装环境
这里写目录标题 清华镜像加速 安装cuda11.3 PyTorch 1.10.1https://pytorch.org/get-started/previous-versions/[如果没有可以点Previous pyTorch Versions,这里面有更多的更早的版本](https://pytorch.org/get-started/locally/) 复制非空文件夹cp: -r not specif…...

一. 初识数据结构和算法
数据结构与算法是一个达到高级程序员的敲门砖。当你脱离了语言的应用层面,去思考他的设计层面时,你就依旧已经开始初识数据结构与算法了 数据结构 什么是数据结构 对于数据结构的定义官方并没有统一的解释,在各个百科以及算法的书中…...

qt 使用百度在线地图 方法1
在使用Qt和百度在线地图时,你需要从百度地图开放平台获取API密钥,并使用该密钥在Qt应用程序中集成百度地图。以下是一个简单的示例,演示了如何在Qt中使用百度在线地图: 1,首先,从百度地图开放平台获取API密…...
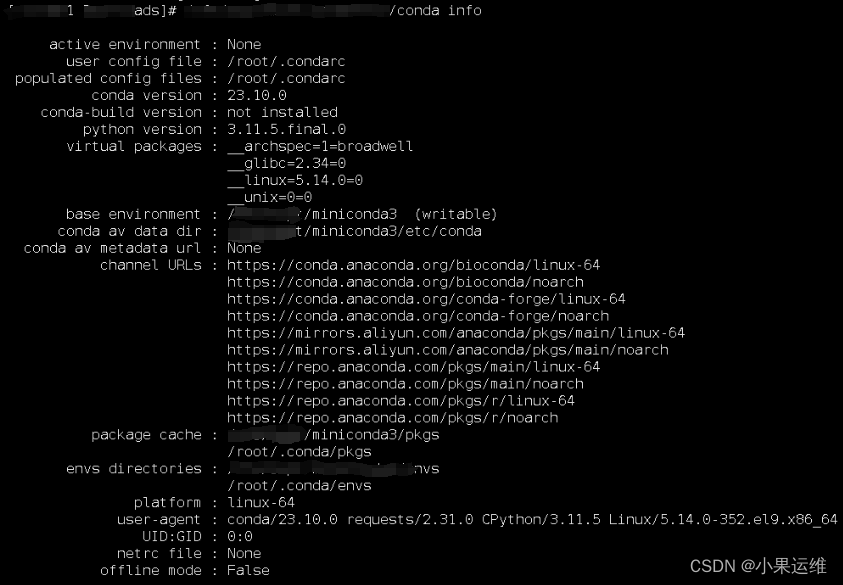
轻快小miniconda3在linux下的安装配置-centos9stream-Miniconda3 Linux 64-bit
miniconda与anaconda的区别: Miniconda 和 Anaconda 是用于管理环境和安装软件包的 Python 发行版。它们之间的主要区别在于以下几点: 1. 安装内容和大小: Anaconda: Anaconda 是一个完整的 Python 数据科学平台,包含…...
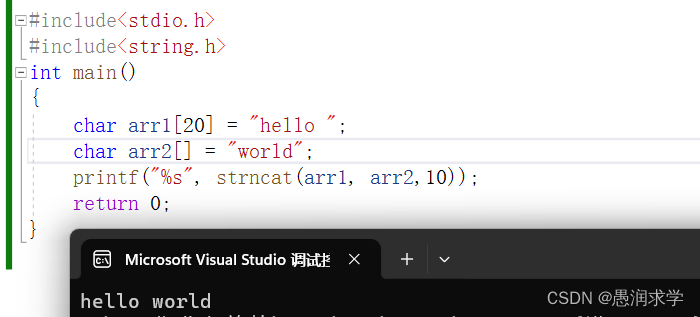
C语言——字符函数和字符串函数(一)
📝前言: 这篇文章对我最近学习的有关字符串的函数做一个总结和整理,主要讲解字符函数和字符串函数(strlen,strcpy和strncpy,strcat和strncat)的使用方法,使用场景和一些注意事项&…...
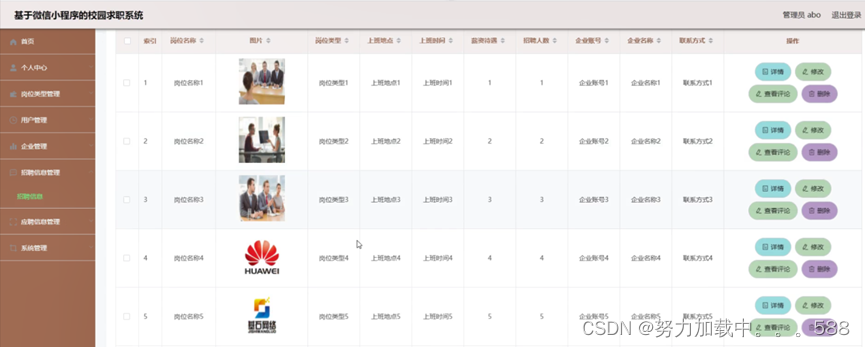
15.Java程序设计-基于SSM框架的微信小程序校园求职系统的设计与实现
摘要: 本研究旨在设计并实现一款基于SSM框架的微信小程序校园求职系统,以提升校园求职流程的效率和便捷性。通过整合微信小程序平台和SSM框架的优势,本系统涵盖了用户管理、职位发布与搜索、简历管理、消息通知等多个功能模块,为…...
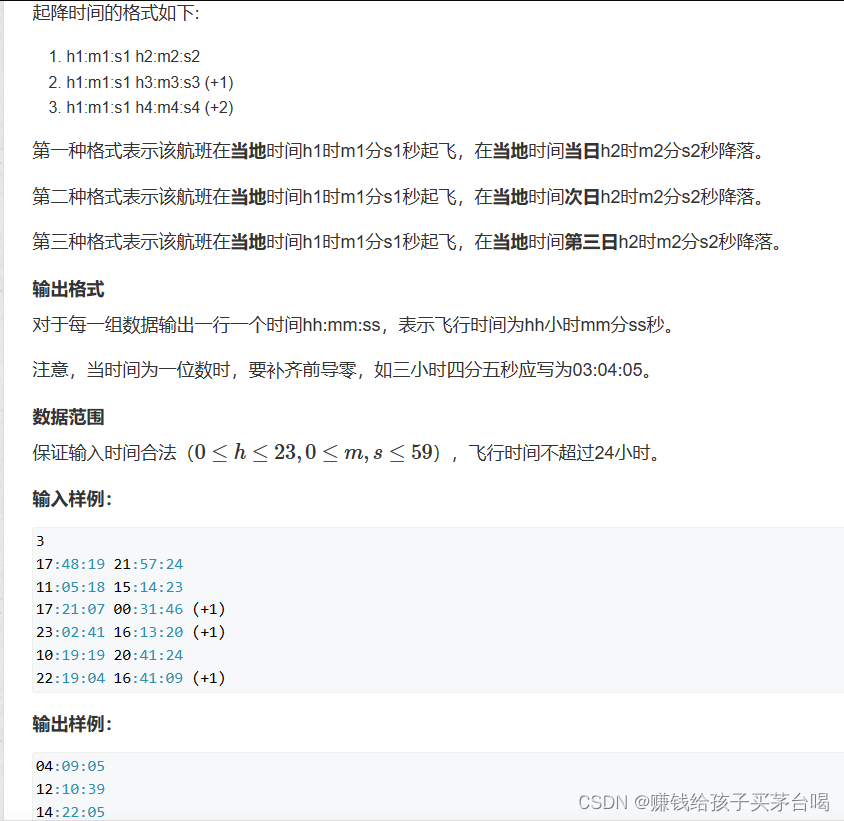
蓝桥杯航班时间
蓝桥杯其他真题点这里👈 //飞行时间 - 时差 已过去的时间1 //飞行时间 时差 已过去的时间2 //两个式子相加会发现 飞行时间 两段时间差的和 >> 1import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader;public cl…...

openEuler学习05-kernel升级
周末没事,尝试下openEuler的kernel升级 [rootlocalhost ~]# more /etc/os-release NAME"openEuler" VERSION"20.03 (LTS-SP3)" ID"openEuler" VERSION_ID"20.03" PRETTY_NAME"openEuler 20.03 (LTS-SP3)" ANSI_…...

Linux-centos上如何配置管理NFS服务器?
Linux/centos上如何配置管理NFS服务器? 1 NFS基础了解 NFS(Network File System)即文件操作系统;NFS允许网络中不同计算机相互之间共享资源。 1.1 NFS概述 1980年由SUN发展出来的在UNIX&Linux系统间实现文件共享的一种方法…...

自然语言处理第2天:自然语言处理词语编码
☁️主页 Nowl 🔥专栏 《自然语言处理》 📑君子坐而论道,少年起而行之 文章目录 一、自然语言处理介绍二、常见的词编码方式1.one-hot介绍缺点 2.词嵌入介绍说明 三、代码演示四、结语 一、自然语言处理介绍 自然语言处理…...

ES6中的Promise
Promise 是一种异步编程解决方案,Promise是一个容器,保存着将来才会执行的代码;从语法角度来说Promise是一个对象,可以用来获取异步操作的消息。异步操作,同步解决,避免了层层嵌套的回调函数,可…...

载入了名字空间‘htmltools’ 0.5.6,但需要的是>= 0.5.7解决方案
解决方案:删除之前的旧版本安装包,安装新的包 1.卸载之前的安装包 2.关闭R,重新打开 3. # install.packages("htmltools") library(htmltools)...

Cisco 思科路由交换网络设备 安全基线 安全加固操作
目录 账号管理、认证授权 本机认证和授权ELK-Cisco-01-01-01 设置特权口令 ELK-Cisco-01-02-01 ELK-Cisco-01-02-02 登录要求 ELK-Cisco-01-03-01 ELK-Cisco-01-03-02 ELK-Cisco-01-03-03 日志配置 ELK-Cisco-02-01-01 通信协议 ELK-Cisco-…...
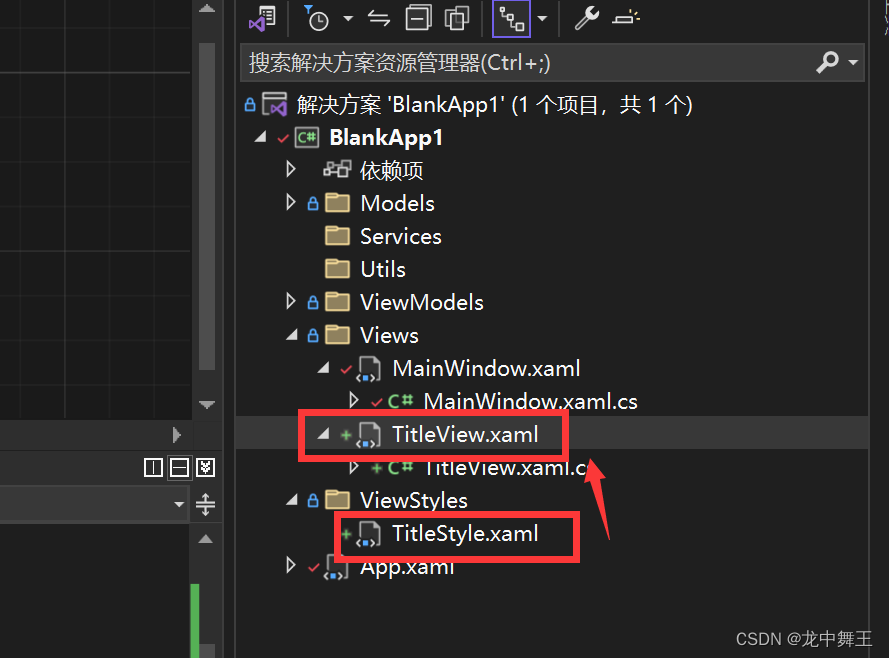
WPF仿网易云搭建笔记(0):项目搭建
文章目录 前言项目地址项目Nuget包搭建项目初始化项目架构App.xaml引入MateralDesign资源包 项目初步分析将标题栏去掉DockPanel初步布局 资源字典举例 结尾 前言 最近在找工作,发现没有任何的WPF可以拿的出手的工作经验,打算仿照网易云搭建一个WPF版本…...

Python爬虫利器:BeautifulSoup库详解
BeautifulSoup是Python中最流行的HTML解析库之一,它可以方便地从HTML文档中提取数据,并且支持多种解析器,可以适应不同的HTML文档格式。本文将介绍BeautifulSoup库的作用、用途和基本用法,帮助读者了解如何使用BeautifulSoup进行H…...

AI安全实战:生成式AI安全防御的实战技巧
AI安全实战:生成式AI安全防御的实战技巧📝 本章学习目标:本章聚焦实战应用,通过案例帮助读者将理论转化为实践能力。通过本章学习,你将全面掌握"AI安全实战:生成式AI安全防御的实战技巧"这一核心…...

Herqles架构:量子比特读取的硬件高效判别器设计与FPGA实现
1. 项目概述:量子比特读取的精度与速度困局在量子计算的世界里,有一个操作看似基础,却直接决定了整个系统的上限:量子比特的读取。你可以把它想象成计算机的“内存读取”指令,但这里读取的不是0或1的确定性电压&#x…...

Bittensor:去中心化AI网络的架构、挑战与激励模型优化
1. 项目概述:当AI遇上去中心化,Bittensor在解决什么核心问题?最近几年,AI模型的能力突飞猛进,但一个越来越明显的趋势是,顶尖的AI能力正快速向少数几家科技巨头集中。无论是训练所需的算力、高质量的数据集…...

从/dev/snd文件看起:手把手教你理解Linux ALSA声卡驱动的设备命名规则
从/dev/snd文件看起:手把手教你理解Linux ALSA声卡驱动的设备命名规则当你第一次打开/dev/snd目录,看到诸如controlC0、pcmC0D0p这样神秘的文件名时,是否感到困惑?这些看似随意的字符串背后,其实隐藏着ALSA驱动对音频硬…...

C#根据时间加密和防止反编译的两种方案
时间加密 用当前时间做密钥 / 校验,防反编译 混淆 加壳,配套用)一、C# 时间加密 2 种核心实现(直接用)都是可直接运行的完整代码,适合做注册验证、临时授权方案 1:时间戳 AES 加密ÿ…...

用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程
用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程自动驾驶感知系统的核心挑战在于如何有效融合多模态传感器数据。本文将手把手带你实现论文《CDSM: Cross-Domain Spatial Matching for Camera-Radar Fusion in 3D Object Detection》的核…...

根据lab1.pdf总结的知识点
第一题:简单的应用程序(Hello.java)类与主方法:Java程序入口必须是public static void main(String args[]),public表示该方法能被JVM访问,static表示无需创建对象即可调用,void表示无返回值&am…...

SLAM技术路线收敛?不,多模态融合正在重启路线之争
过去几年,SLAM技术路线确实呈现出明确的收敛趋势:纯视觉SLAM逐渐成熟,基于3DGS的实时建图成为新范式,激光SLAM也固化为工业场景的稳健选择。大家一度认为,算法架构的选择题已经做完。然而,多模态融合的深入…...

大脑规则:为什么你学不进去?10个科学方法提升学习效率
大脑规则:为什么你学不进去?10个科学方法提升学习效率 副标题: 从进化论到认知科学,附实战学习方案 一、痛点:为什么你总是学不进去? 你有没有这样的经历: 坐在书桌前,书翻开了,但脑子一片空白 熬夜学习,第二天效率更低,形成恶性循环 一边看视频一边回消息,结果什…...

Deepseek-V4-Flash-20260423 深度评测与实战指南
文章目录 ① 核心参数解析与架构初印象② 多轮对话响应速度与并发实测③ 复杂逻辑推理与代码生成质量解剖④ 长文本处理与关键信息提取案例⑤ 垂直领域知识准确性验证集锦⑥ 模型幻觉识别与能力边界测试⑦ 极端输入下的稳定性与避坑指南⑧ 不同场景下的性价比与选型建议 在开发…...