pytorch中的归一化:BatchNorm、LayerNorm 和 GroupNorm
1 归一化概述
训练深度神经网络是一项具有挑战性的任务。 多年来,研究人员提出了不同的方法来加速和稳定学习过程。 归一化是一种被证明在这方面非常有效的技术。

1.1 为什么要归一化
数据的归一化操作是数据处理的一项基础性工作,在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表示的,数据样本的不同特征可能会有不同的尺度,这样的情况会影响到数据分析的结果。为了解决这个问题,需要进行数据归一化处理。原始数据经过数据归一化后,各特征处于同一数量级,适合进行综合对比评价。
例如,我们现在用两个特征构建一个简单的神经网络模型。 这两个特征一个是年龄:范围在 0 到 65 之间,另一个是工资:范围从 0 到 10 000。我们将这些特征提供给模型并计算梯度。

不同规模的输入导致不同的权重更新和优化器的步骤向最小值的方向不均衡。这也使损失函数的形状不成比例。在这种情况下,就需要使用较低的学习速率来避免过冲,这就意味着较慢的学习过程。
所以我们的解决方案是输入进行归一化,通过减去平均值(定心)并除以标准偏差来缩小特征。
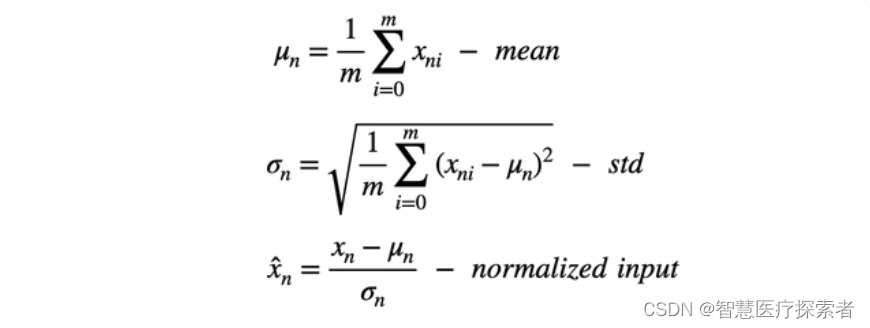
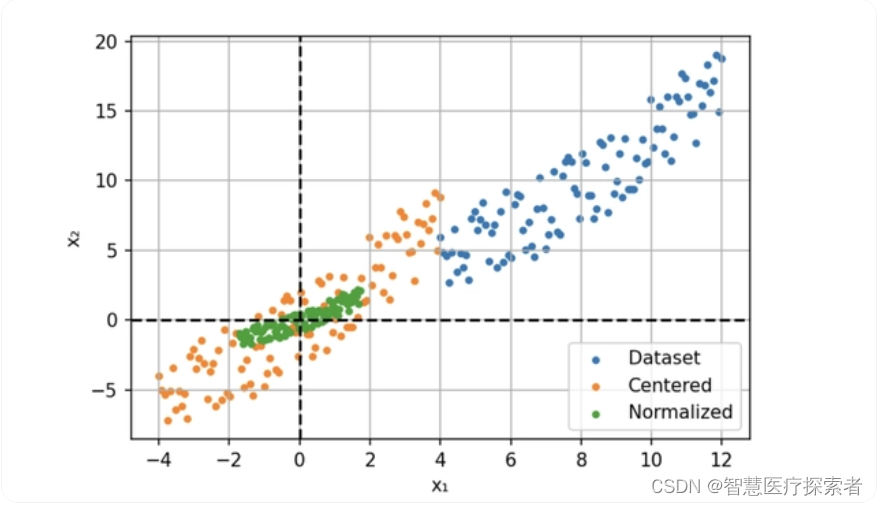
此过程也称为“漂白”,处理后所有的值具有 0 均值和单位方差,这样可以提供更快的收敛和更稳定的训练。
1.2 归一化的作用
在深度学习中,数据归一化是一项关键的预处理步骤,用于优化神经网络模型的训练过程和性能。归一化技术有助于解决梯度消失和梯度爆炸问题,加快模型的收敛速度,并提高模型的鲁棒性和泛化能力。详细介绍如下:
-
梯度消失和梯度爆炸问题:在深度神经网络中,梯度消失和梯度爆炸是常见的问题。数据归一化可以缓解这些问题,使得梯度在合理的范围内进行传播,有助于提高模型的训练效果。
-
特征尺度不一致:深度学习模型对特征的尺度非常敏感。如果不同特征具有不同的尺度范围,某些特征可能会主导模型的训练过程,而其他特征的影响可能被忽略。通过数据归一化,可以将不同特征的尺度统一到相同的范围,使得模型能够平衡地对待所有特征,避免尺度不一致带来的偏差。
-
模型收敛速度:数据归一化可以加快模型的收敛速度。当数据被归一化到一个较小的范围时,模型可以更快地找到合适的参数值,并减少训练过程中的震荡和不稳定性。这样可以节省训练时间,提高模型的效率。
-
鲁棒性和泛化能力:通过数据归一化,模型可以更好地适应不同的数据分布和噪声情况。归一化可以增加模型的鲁棒性,使得模型对输入数据的变化和扰动具有更好的容忍度。同时,归一化还有助于提高模型的泛化能力,使得模型在未见过的数据上表现更好。
1.3 归一化的步骤
归一化通过对数据的特定维度上进行归一化操作来调整输入数据的分布,使其具有零均值和单位方差。一般通过以下步骤对输入进行归一化:
-
对于给定的输入数据,在给定的维度上计算其均值和方差。
-
使用计算得到的均值和方差对输入数据进行标准化,将其零均值化并使其具有单位方差。
-
对标准化后的数据进行缩放和平移操作,通过可学习的参数进行调整,以恢复模型对数据的表达能力。
进一步地,在归一化中,通过缩放和平移操作,引入了可学习的参数,即缩放参数(scale)和平移参数(shift)。这些参数用于在标准化后的数据上进行线性变换,以恢复模型的表达能力。
具体而言,在每个特征维度上,假设归一化后的数据为,则通过以下公式计算最终的输出:
。其中,
是最终的输出,
是缩放参数(scale),
是平移参数(shift)。这两个参数是可学习的,它们可以通过反向传播和优化算法(如随机梯度下降)来进行更新。在训练过程中,模型会通过梯度下降的方式来调整这些参数,使得模型能够自适应地对不同的数据分布进行缩放和平移。这样,模型可以根据实际情况自由地调整每个特征的重要性和偏置,从而更好地适应不同的数据分布。
2 pytorch中的归一化
BatchNorm、LayerNorm 和 GroupNorm 都是深度学习中常用的归一化方式。它们通过将输入归一化到均值为 0 和方差为 1 的分布中,来防止梯度消失和爆炸,并提高模型的泛化能力。
2.1 BatchNorm
一般 CNN 中,卷积层后面会跟一个 BatchNorm 层,减少梯度消失和爆炸,提高模型的稳定性。
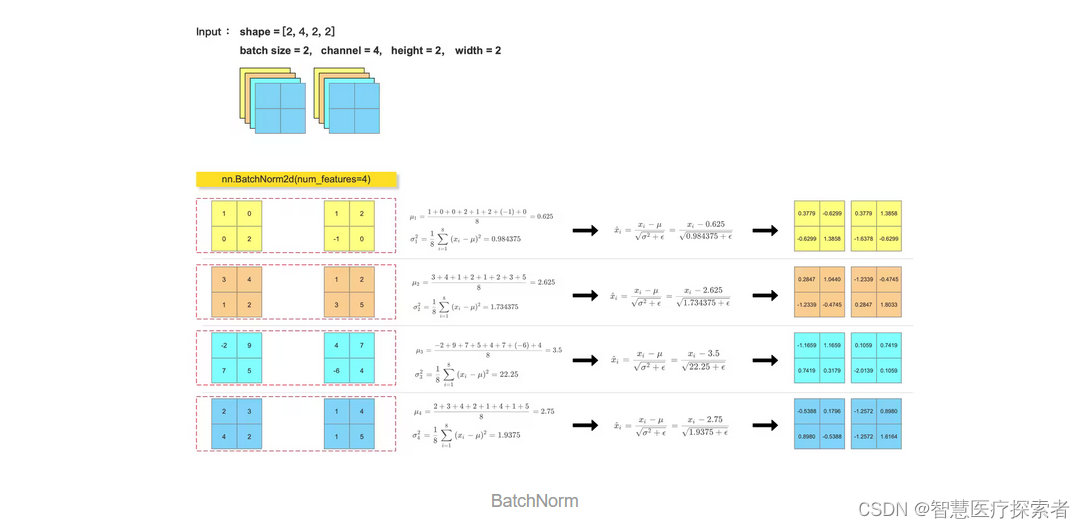
在PyTorch中,可以使用torch.nn.BatchNorm1d、torch.nn.BatchNorm2d或torch.nn.BatchNorm3d等批归一化层来实现批归一化。
实例代码:
import torch
import torch.nn as nn
import numpy as npfeature_array = np.array([[[[1, 0], [0, 2]],[[3, 4], [1, 2]],[[-2, 9], [7, 5]],[[2, 3], [4, 2]]],[[[1, 2], [-1, 0]],[[1, 2], [3, 5]],[[4, 7], [-6, 4]],[[1, 4], [1, 5]]]], dtype=np.float32)feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)
bn_out = nn.BatchNorm2d(num_features=4, eps=1e-5)(feature_tensor)
print(bn_out)for i in range(feature_array.shape[1]):channel = feature_array[:, i, :, :]mean = feature_array[:, i, :, :].mean()var = feature_array[:, i, :, :].var()print(mean)print(var)feature_array[:, i, :, :] = (feature_array[:, i, :, :] - mean) / np.sqrt(var + 1e-5)
print(feature_array)运行结果显示:
tensor([[[[ 0.3780, -0.6299],[-0.6299, 1.3859]],[[ 0.2847, 1.0441],[-1.2339, -0.4746]],[[-1.1660, 1.1660],[ 0.7420, 0.3180]],[[-0.5388, 0.1796],[ 0.8980, -0.5388]]],[[[ 0.3780, 1.3859],[-1.6378, -0.6299]],[[-1.2339, -0.4746],[ 0.2847, 1.8034]],[[ 0.1060, 0.7420],[-2.0140, 0.1060]],[[-1.2572, 0.8980],[-1.2572, 1.6164]]]], grad_fn=<NativeBatchNormBackward0>)
0.625
0.984375
2.625
1.734375
3.5
22.25
2.75
1.9375
[[[[ 0.37796253 -0.6299376 ][-0.6299376 1.3858627 ]][[ 0.28474656 1.0440707 ][-1.2339017 -0.4745776 ]][[-1.1659975 1.1659975 ][ 0.7419984 0.3179993 ]][[-0.53881454 0.17960484][ 0.8980242 -0.53881454]]][[[ 0.37796253 1.3858627 ][-1.6378376 -0.6299376 ]][[-1.2339017 -0.4745776 ][ 0.28474656 1.8033949 ]][[ 0.10599977 0.7419984 ][-2.0139956 0.10599977]][[-1.2572339 0.8980242 ][-1.2572339 1.6164436 ]]]]2.2 LayerNorm
Transformer block 中会使用到 LayerNorm , 一般输入尺寸形为 :(batch_size, token_num, dim),会在最后一个维度做 归一化: nn.LayerNorm(dim)
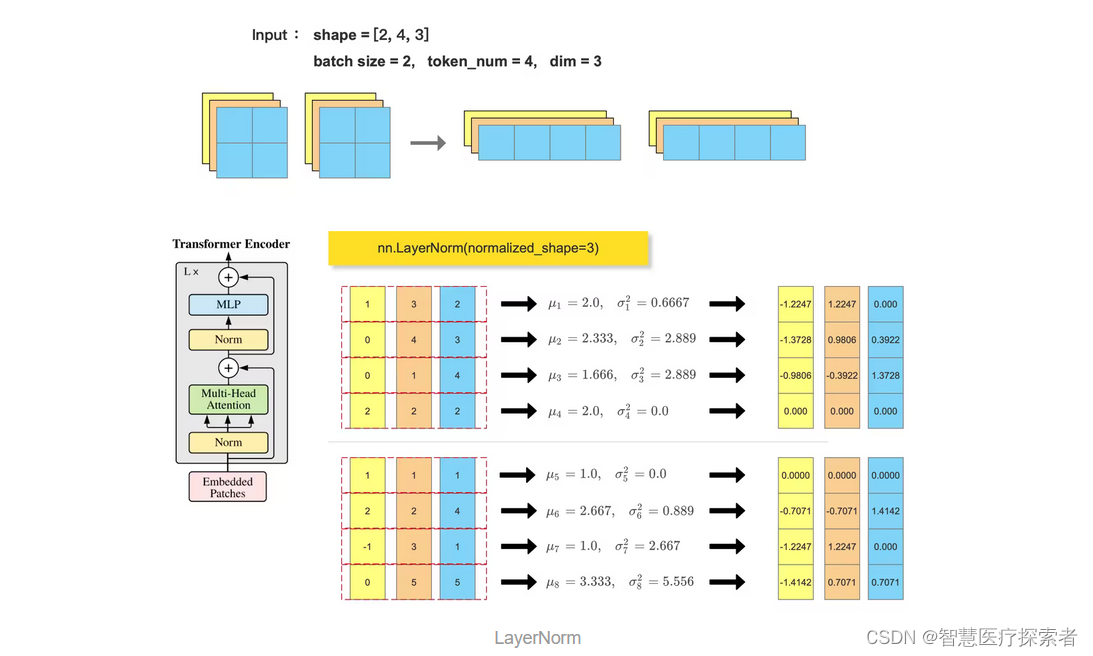
与批归一化不同,层归一化的计算是针对单个样本的特征维度进行的,其目的是将每个样本在单个层内的特征维度进行归一化,以增强特征之间的独立性,并提供更稳定的特征表示。具有以下优点:
-
适用于处理单个样本:相比于批归一化,层归一化的计算是基于单个样本在单个层内的特征维度进行的,而不依赖于小批量样本的统计信息。这使得层归一化适用于处理单个样本的情况,例如在循环神经网络(RNN)中,每个时间步的输入可以被看作是一个单独的样本。
-
适用于动态计算图和序列数据:由于层归一化的计算不依赖于小批量样本的统计信息,它更适合在动态计算图和序列数据上进行计算。在处理变长序列数据或使用动态计算图的场景下,层归一化可以提供更好的性能和效果。
另外,在Transformer模型中使用层归一化(Layer Normalization)主要是因为其独立的特征维度归一化的性质:Transformer模型的核心是自注意力机制,它在每个位置对输入序列中的所有位置进行关注。由于每个位置的特征维度可以看作是独立的,对每个位置进行层归一化可以提供更稳定的特征表示,减少特征之间的耦合,这有助于模型更好地学习位置之间的依赖关系,提高模型的表示能力。并且,减少了特征之间的内部协变量转移,这有助于缓解深度神经网络中常见的梯度消失和梯度爆炸问题,提高模型的训练效果和收敛速度。
层归一化(Layer Normalization)一般来说在激活函数之前应用:在层归一化之后应用激活函数可以使得激活函数的输入保持在归一化后的范围内,避免激活函数的输入过大或过小。这种方式与批标准化的应用顺序相似。
例如:在传统的RNN中,通常是将输入序列经过线性变换后再应用激活函数(如tanh或ReLU)进行非线性变换。然而,这样的操作可能会导致梯度消失或梯度爆炸问题,并且不同时间步的输入之间可能存在较大的变化。通过在激活函数之前应用层归一化,可以解决上述问题。
示例代码:
import torch
import torch.nn as nn
import numpy as npfeature_array = np.array([[[[1, 0], [0, 2]],[[3, 4], [1, 2]],[[2, 3], [4, 2]]],[[[1, 2], [-1, 0]],[[1, 2], [3, 5]],[[1, 4], [1, 5]]]], dtype=np.float32)feature_array = feature_array.reshape((2, 3, -1)).transpose(0, 2, 1)
feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)ln_out = nn.LayerNorm(normalized_shape=3)(feature_tensor)
print(ln_out)b, token_num, dim = feature_array.shape
feature_array = feature_array.reshape((-1, dim))
for i in range(b*token_num):mean = feature_array[i, :].mean()var = feature_array[i, :].var()print(mean)print(var)feature_array[i, :] = (feature_array[i, :] - mean) / np.sqrt(var + 1e-5)
print(feature_array.reshape(b, token_num, dim))代码运行显示:
tensor([[[-1.2247, 1.2247, 0.0000],[-1.3728, 0.9806, 0.3922],[-0.9806, -0.3922, 1.3728],[ 0.0000, 0.0000, 0.0000]],[[ 0.0000, 0.0000, 0.0000],[-0.7071, -0.7071, 1.4142],[-1.2247, 1.2247, 0.0000],[-1.4142, 0.7071, 0.7071]]], grad_fn=<NativeLayerNormBackward0>)
2.0
0.6666667
2.3333333
2.888889
1.6666666
2.888889
2.0
0.0
1.0
0.0
2.6666667
0.88888884
1.0
2.6666667
3.3333333
5.555556
[[[-1.2247357 1.2247357 0. ][-1.3728105 0.980579 0.3922316 ][-0.98057896 -0.39223155 1.3728106 ][ 0. 0. 0. ]][[ 0. 0. 0. ][-0.70710295 -0.70710295 1.4142056 ][-1.2247427 1.2247427 0. ][-1.4142123 0.7071062 0.7071062 ]]]2.3 GroupNorm
batch size 过大或过小都不适合使用 BN,而是使用 GN。
(1)当 batch size 过大时,BN 会将所有数据归一化到相同的均值和方差。这可能会导致模型在训练时变得非常不稳定,并且很难收敛。
(2)当 batch size 过小时,BN 可能无法有效地学习数据的统计信息。
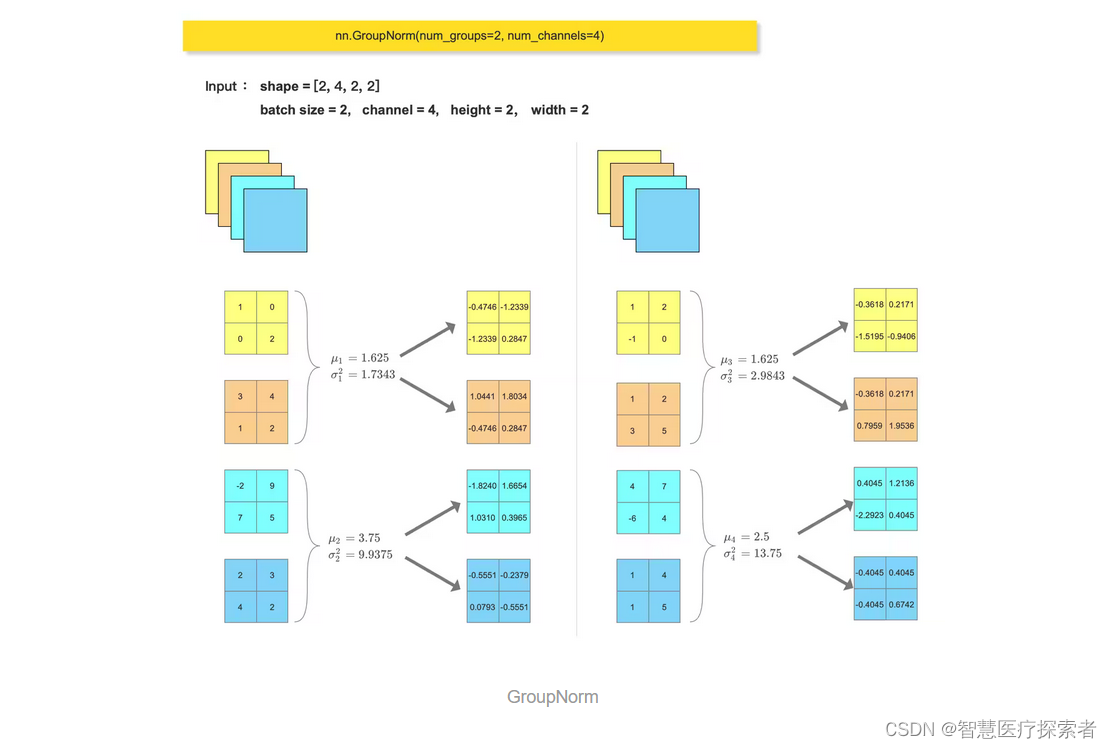
比如,Deformable DETR 中,就用到了 GroupNorm

示例代码:
import torch
import torch.nn as nn
import numpy as npfeature_array = np.array([[[[1, 0], [0, 2]],[[3, 4], [1, 2]],[[-2, 9], [7, 5]],[[2, 3], [4, 2]]],[[[1, 2], [-1, 0]],[[1, 2], [3, 5]],[[4, 7], [-6, 4]],[[1, 4], [1, 5]]]], dtype=np.float32)feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)
gn_out = nn.GroupNorm(num_groups=2, num_channels=4)(feature_tensor)
print(gn_out)feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((4, 2, 2, 2))for i in range(feature_array.shape[0]):channel = feature_array[i, :, :, :]mean = feature_array[i, :, :, :].mean()var = feature_array[i, :, :, :].var()print(mean)print(var)feature_array[i, :, :, :] = (feature_array[i, :, :, :] - mean) / np.sqrt(var + 1e-5)
feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((2, 4, 2, 2))
print(feature_array)运行结果显示:
tensor([[[[-0.4746, -1.2339],[-1.2339, 0.2847]],[[ 1.0441, 1.8034],[-0.4746, 0.2847]],[[-1.8240, 1.6654],[ 1.0310, 0.3965]],[[-0.5551, -0.2379],[ 0.0793, -0.5551]]],[[[-0.3618, 0.2171],[-1.5195, -0.9406]],[[-0.3618, 0.2171],[ 0.7959, 1.9536]],[[ 0.4045, 1.2136],[-2.2923, 0.4045]],[[-0.4045, 0.4045],[-0.4045, 0.6742]]]], grad_fn=<NativeGroupNormBackward0>)
1.625
1.734375
3.75
9.9375
1.625
2.984375
2.5
13.75
[[[[-0.4745776 -1.2339017 ][-1.2339017 0.28474656]][[ 1.0440707 1.8033949 ][-0.4745776 0.28474656]][[-1.8240178 1.6654075 ][ 1.0309665 0.3965256 ]][[-0.55513585 -0.23791535][ 0.07930512 -0.55513585]]][[[-0.3617867 0.21707201][-1.5195041 -0.9406454 ]][[-0.3617867 0.21707201][ 0.79593074 1.9536481 ]][[ 0.40451977 1.2135593 ][-2.2922788 0.40451977]][[-0.40451977 0.40451977][-0.40451977 0.67419964]]]]
相关文章:
pytorch中的归一化:BatchNorm、LayerNorm 和 GroupNorm
1 归一化概述 训练深度神经网络是一项具有挑战性的任务。 多年来,研究人员提出了不同的方法来加速和稳定学习过程。 归一化是一种被证明在这方面非常有效的技术。 1.1 为什么要归一化 数据的归一化操作是数据处理的一项基础性工作,在一些实际问题中&am…...
--顺序消息)
RocketMq源码分析(九)--顺序消息
文章目录 一、顺序消息二、顺序消息消费过程1、消息队列负载2、消息拉取3、消息消费4、消息进度存储 三、总结 一、顺序消息 RocketMq在同一个队列中可以保证消息被顺序消费,所以如果要做到消息顺序消费,可以将消费主题(topic)设置…...
Windows下nginx的启动,重启,关闭等功能bat脚本
echo off rem 提供Windows下nginx的启动,重启,关闭功能echo begincls ::ngxin 所在的盘符 set NGINX_PATHG:::nginx 所在目录 set NGINX_DIRG:\projects\nginx-1.24.0\ color 0a TITLE Nginx 管理程序增强版CLSecho. echo. ** Nginx 管理程序 *** echo.…...
之间的区别)
Python 字典:dic = {} 和 dic = defaultdict(list)之间的区别
d defaultdict(list) 和 d {} 在Python中代表了两种不同类型的字典初始化方式,它们之间有几个关键的区别: 1、类型 d defaultdict(list):这里使用的是 collections 模块中的 defaultdict 类。它是一个字典的子类,提供了一个默…...

绘图 Seaborn 10个示例
绘图 Seaborn 是什么安装使用显示中文及负号散点图箱线图小提琴图堆叠柱状图分面绘图分类散点图热力图成对关系图线图直方图 是什么 Seaborn 是一个Python数据可视化库,它基于Matplotlib。Seaborn提供了高级的绘图接口,可以用来绘制各种统计图形…...
airserver mac 7.27官方破解版2024最新安装激活图文教程
airserver mac 7.27官方破解版是一款好用的airplay投屏工具,可以轻松将ios荧幕镜像(airplay)至mac上,在mac平台上实现视频、音频、幻灯片等文件资源的接收及投放演示操作,解决iphone或ipad的屏幕录像问题,满…...
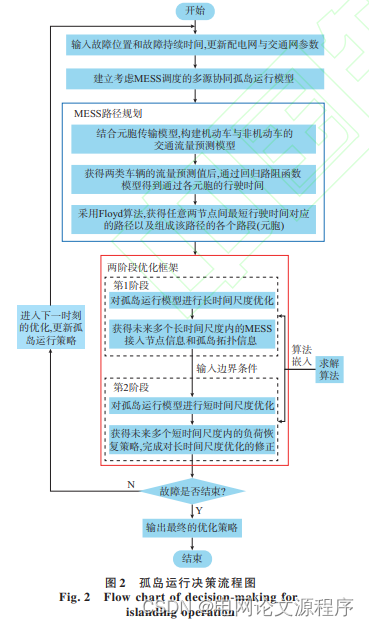
文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《考虑移动式储能调度的配电网灾后多源协同孤岛运行策略》
这篇文章的标题表明研究的主题是在配电网发生灾害后,采用一种策略来实现多源协同孤岛运行,并在这个过程中特别考虑了移动式储能的调度。 让我们逐步解读标题的关键词: 考虑移动式储能调度: 文章关注的焦点之一是移动式储能系统的…...

Spring Boot 优雅地处理重复请求
前 言 对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。 重复的场…...

TailwindCSS 多主题色配置
TailwindCSS 多主题色配置 现在大多数网站都支持主题色变换,比如切换深色模式。那么我们该如何进行主题色配置呢? tailwind dark tailwind 包含一个 dark变体,当启用深色模式时,可以为网站设置不同样式 <div class"bg-whi…...
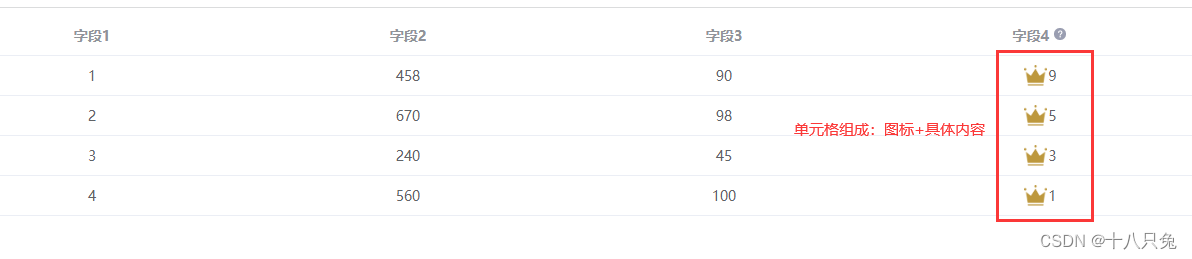
Vue3:表格单元格内容由:图标+具体内容 构成
一、背景 在Vue3项目中,想让单元格的内容是由 :图标具体内容组成的,类似以下效果: 二、图标 Element-Plus 可以在Element-Plus里面找是否有符合需求的图标iconfont 如果Element-Plus里面没有符合需求的,也可以在这…...

【项目日记(一)】高并发内存池项目介绍
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:项目日记-高并发内存池⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 项目日记 1. 前言2. 什么是高并发内存池…...

4-Docker命令之docker commit
1.docker commit介绍 docker commit命令是用于根据docker容器的改变创建一个新的docker镜像 2.docker commit用法 docker commit [参数] container [repository[:tag]] [rootcentos79 ~]# docker commit --helpUsage: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG…...

RabbitMQ学习笔记10 综合实战 实现新商家规定时间内上架商品检查
配置文件: 记住添加这个。 加上这段代码,可以自动创建队列和交换机以及绑定关系。 我们看到了我们创建的死信交换机和普通队列。 我们可以看到我们队列下面绑定的交换机。 我们创建一个controller包进行测试: 启动: 过一段时间会变成死信队列…...

Project Euler 865 Triplicate Numbers(线性dp)
题目 能通过每次消除3个一样的数字,最终把数字消成空的数字是合法的, 求串长度不超过n的,没有前导0的数字中,合法的数字的个数 n10000,答案对998244353取模,只需要输出数字 思路来源 乱搞AC 题解 暴力…...

计算机网络测试题第二部分
前言:如果没有做在线测试请自主独立完成,本篇文章只作为学习计算机网络的参考,题库中的题存在一定错误和不完整,请学习时,查找多方书籍论证,独立思考,如果存在疑虑可以评论区讨论。查看时,请分清…...
linux 15day apache apache服务安装 httpd服务器 安装虚拟主机系统 一个主机 多个域名如何绑定
目录 一、apache安装二、访问控制总结修改默认网站发布目录 三、虚拟主机 一、apache安装 [rootqfedu.com ~]# systemctl stop firewalld [rootqfedu.com ~]# systemctl disable firewalld [rootqfedu.com ~]# setenforce 0 [rootqfedu.com ~]# yum install -y httpd [rootqfe…...
Linux和Windows环境下如何使用gitee?
1. Linux 1.1 创建远程仓库 1.2 安装git sudo yum install -y git 1.3 克隆远程仓库到本地 git clone 地址 1.4 将文件添加到git的暂存区(git三板斧之add) git add 文件名 # 将指定文件添加到git的暂存区 git add . # 添加新文件和修改过的…...

Docker安装教程
docker官网 1.卸载旧版 yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine2.配置Docker的yum库 安装yum工具 yum install -y yum-utils配置Docker的yum源 yum-config-ma…...

【PWN】学习笔记(二)【栈溢出基础】
课程教学 课程链接:https://www.bilibili.com/video/BV1854y1y7Ro/?vd_source7b06bd7a9dd90c45c5c9c44d12e7b4e6 课程附件: https://pan.baidu.com/s/1vRCd4bMkqnqqY1nT2uhSYw 提取码: 5rx6 C语言函数调用栈 一个栈帧保存的是一个函数的状态信息&…...

02-Nacos和Eureka的区别与联系
Nacos和Eureka的区别 联系 Nacos和Eureka整体结构类似: 都支持服务注册, 服务拉取, 采用心跳方式对服务提供者做健康监测的功能 区别 Nacos支持服务端主动检测服务提供者状态: 临时实例采用心跳模式,非临时实例采用主动检测模式但对服务器压力比较大(不推荐) 心跳模式: 服务…...

Unity中大型项目架构选型:GameFramework与QFramework实战对比
1. 为什么这两个框架值得你花时间搞懂——不是“又一个Unity插件”,而是项目基建的分水岭 在Unity中写过三个以上正式项目的人都会遇到同一个临界点:当功能模块超过20个、脚本数量突破500、团队从1人扩展到5人时,原本“拖拽组件写MonoBehavi…...

GPT-4的1.8T参数与2%激活率:MoE架构原理与工程真相
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的佐证,也常被误读为“GPT-4只用360亿参数&#x…...

给电力行业装上“地理大脑”:百度智能云图云做了一次“地址大模型”变革
“我家在老三中对面那条巷子,供电局以前的老院子旁边……”当95598客服接到这样的报修电话时,系统该如何精准定位?这并非个例。城市快速扩张、街巷小区不断新建更名,而电力系统的地址数据往往跟不上现实变化。同时,传统…...

成都制造企业供应链价格波动频繁,AI智能体该先预警哪些信号?
一、价格波动不是采购一个部门能扛住的问题很多制造企业谈供应链价格波动,第一反应是让采购去谈价、催报价、找替代供应商。但在真实经营里,价格风险很少只停留在采购单价上。铜、铝、钢材、塑料、电子元器件、包装材料、运费、汇率和供应商产能变化&…...

从概率拟合到内生心智:七层投影架构重构AGI数字生命新范式
自2017年Transformer架构问世以来,人工智能领域正式迈入大模型迭代时代。十余年间,千亿、万亿参数模型不断涌现,依托自注意力机制的概率拟合算法,AI在文本生成、多模态交互、逻辑问答等领域实现了规模化突破,彻底改变了…...
)
一文读懂如何申报国家企业技术中心(条件、流程、好处)
一、什么是企业技术中心?是指企业根据市场竞争需要设立的技术研发与创新机构,负责制定企业技术创新规划、开展产业技术研发、创造运用知识产权、建立技术标准体系、凝聚培养创新人才,推进技术创新全过程实施,是企业技术创新体系的…...

大学生几种职业资格证书有哪些?2026年高含金量考证指南与就业规划
你好呀!👋 看到你在这个时间点搜索关于证书的话题,我完全能理解你的心情。转眼间我们已经步入 2026年,当下的就业环境比起几年前,确实发生了不少变化。我也接触过很多像你一样的同学,大家都有点焦虑&#x…...

RK3588开发板Ubuntu系统深度解析:架构设计与性能优化指南
RK3588开发板Ubuntu系统深度解析:架构设计与性能优化指南 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 在嵌入式开发领域,Rockchip RK3588处理器凭借其强…...

用随机森林实现手写大写字母识别的完整实践
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常典型、…...

Supermask:冻结权重+二值掩码的神经网络子结构发现方法
1. 什么是 Supermasks?——不是“超级面具”,而是神经网络里的“先天直觉” 你有没有试过教一个刚学会走路的孩子认苹果?你不需要从零开始教他光谱分析、细胞结构或者植物分类学,只要拿个红彤彤的苹果在他眼前晃一晃,再…...