实战项目-用户评论数据情绪分析
目录
- 1、基于词典的方法
- 2、基于词袋或 Word2Vec 的方法
- 2.1 词袋模型
- 2.2 Word2Vec
- 3、案例:用户评论情绪分析
- 3.1 数据读取
- 3.2 语料库分词处理
- 3.3 Word2Vec 处理
- 3.4 训练情绪分类模型
- 3.5 对评论数据进行情绪判断
目的:去判断一段文本、评论的情绪偏向
在这里,我们针对文本进行情绪分析时,只处理两种情绪状态:积极和消极。
针对文本情绪分析的方法有两种,一种基于词典,另一种基于机器学习方法。
1、基于词典的方法
概括来讲,首先有一个人工标注好的词典。词典中的每一个词都对应着消极或积极的标签。
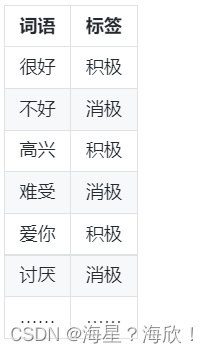
这个词典可能有上万条或者几十万条,当然是越多越好。
情绪分析流程:
1,收到评论:”这门课程很好啊!“
2,分词:”[‘这门’, ‘课程’, ‘很’, ‘好’, ‘啊’, ‘!’]“
3,拿分好的词依次去匹配词典。匹配的方法很简单:
- 如果词典中存在该词且为积极标签,那么我们记 +1+1;
- 如果词典中存在该词且为消极标签,那么我们记 -1−1;
- 如果词典中不存在该词,我们记 00。
4,匹配完一个句子之后,我们就可以计算整个句子的得分。总得分 >0>0 表示该句子情绪为积极,总得分小于零代表该句子为消极,总得分 =0=0 表示无法判断情绪。
此方法优点:简单,
缺点1:往往需要一个很大的词典,且不断更新。这对人力物力都是极大的考验。
缺点2:该方法还有无法通过扩充词典解决的情绪判断问题。
例如,当我们人类在判断一句话的清晰时,我们会往往更偏向于从整体把握(语言环境),尤其是在乎一些语气助词对情绪的影响。而基于词典进行情绪分析的方法就做不到这一点,将句子拆成词,就会影响句子的整体情绪表达。
缺点3:准确率并不高
目前,针对中文做情绪标注的词典少之又少。比较常用的有:
- 台湾大学 NTUSD 情绪词典。
- 《知网》情绪分析用 词语集。
以《知网》情绪词典举例,它包含有 5 个文件,分别列述了正面与负面的情绪词语以及程度词汇。
“正面情感”词语,如:爱,赞赏,快乐,感同身受,好奇,喝彩,魂牵梦萦,嘉许 …
“负面情感”词语,如:哀伤,半信半疑,鄙视,不满意,不是滋味儿,后悔,大失所望 …
“正面评价”词语,如:不可或缺,部优,才高八斗,沉鱼落雁,催人奋进,动听,对劲儿 …
“负面评价”词语,如:丑,苦,超标,华而不实,荒凉,混浊,畸轻畸重,价高,空洞无物 …
“程度级别”词语,
“主张”词语
2、基于词袋或 Word2Vec 的方法
2.1 词袋模型
词袋不再将一句话看做是单个词汇构成,而是当作一个 1 \times N1×N 的向量。
举例
我们现在有两句话需要处理,分别是:
我爱你,我非常爱你。 我喜欢你,我非常喜欢你。
我们针对这两句话进行分词之后,去重处理为一个词袋:
[‘我’, ‘爱’, ‘喜欢’, ‘你’, ‘非常’]
然后,根据词袋,我们对原句子进行向量转换。其中,向量的长度 N 为词袋的长度,而向量中每一个数值依次为词袋中的词出现在该句子中的次数。
我爱你,我非常爱你。 → [2, 2, 0, 2, 1]
我喜欢你,我非常喜欢你。 → [2, 0, 2, 2, 1]
有了词袋,有了已经人工标注好的句子,就组成了我们的训练数据。再根据机器学习方法来构建分类预测模型。从而判断新输入句子的情绪。
词袋模型和独热编码非常相似。其实这里就是将之前独热编码里的词变成了句子而已。
词袋模型固然比简单的词典对比方法更好,但独热编码无法度量上下文之间的距离,也就无法结合上下文进行情绪判断。引入词向量的 Word2Vec 处理方法,来克服这个缺点。
2.2 Word2Vec
Word2Vec,故名思意就是将句子转换为向量,也就是词向量。它是由浅层神经网络组成的词向量转换模型。
Word2Vec 的输入一般为规模庞大的语料库,输出为向量空间。Word2Vec 的特点在于,语料库中的每个词都对应了向量空间中的一个向量,拥有上下文关系的词,映射到向量空间中的距离会更加接近。
Word2Vec 的主要结构是 CBOW(Continuous Bag-of-Words Model)模型和 Skip-gram(Continuous Skip-gram)模型结合在一起。简单来讲,二者都是想通过上下文得到一个词出现的概率。
CBOW 模型通过一个词的上下文(各 N 个词)预测当前词。而 Skip-gram 则恰好相反,他是用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
CBOW(N=2)和 Skip-gram 的结构如下图所示:
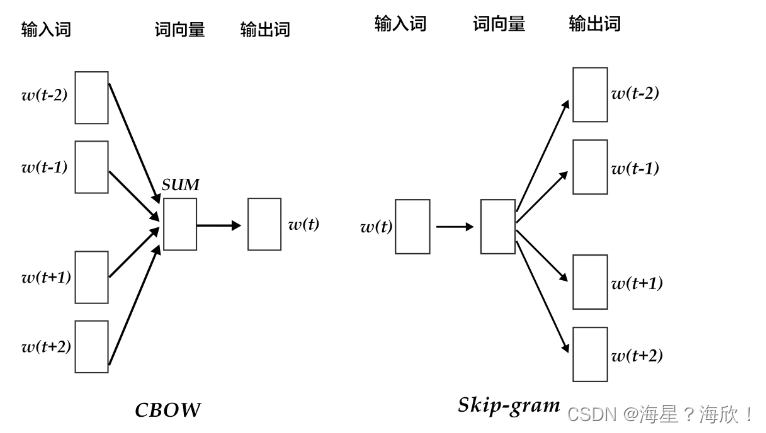
图中 w(t)w(t) 表示当前的词汇,而 w(t−n)w(t−n),w(t+n)w(t+n) 等则用来表示上下文词汇。
3、案例:用户评论情绪分析
方法: Word2Vec 结合决策树的文本情绪分析方法
思路:需要使用 Word2Vec 来建立向量空间,之后再使用决策树训练文本情绪分类模型。
3.1 数据读取
由于我们未人工针对案例评论数据进行语料库标注,所以这里需要选择其他的已标注语料库进行模型训练。这里,我们选用了网友苏剑林提供的语料库。该语料库整合了书籍、计算机等 7 个领域的评论数据。
获取数据:
!wget -nc "http://labfile.oss.aliyuncs.com/courses/764/data_09.zip"
!unzip -o "data_09.zip"
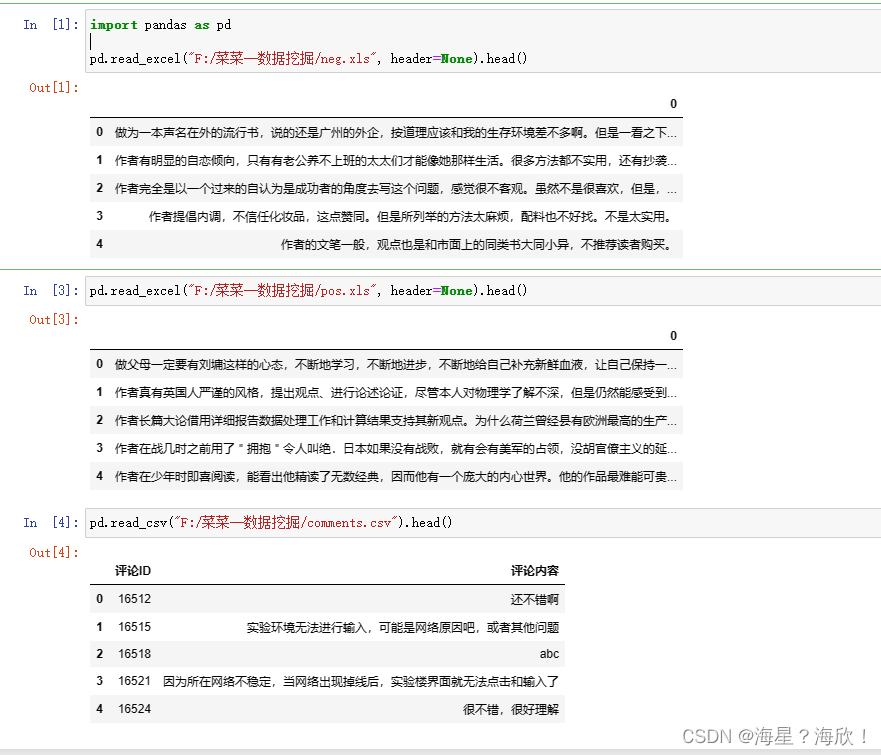
三个数据文本预览:
import pandas as pd
#消极情绪文本 neg.xls 共有 10428 行。
pd.read_excel("data_09/data/neg.xls", header=None).head()
#积极情绪文本 pos.xls 共有 10679 行
pd.read_excel("data_09/data/pos.xls", header=None).head()
#蓝桥云课用户评论文本 comments.csv 共有 12377 行。
pd.read_csv("data_09/comments.csv").head()
3.2 语料库分词处理
在使用 Word2Vec 之前,我们需要先对训练语料库进行分词处理。这里使用 jieba 分词。
import jieba
import numpy as np# 加载语料库文件,并导入数据
neg = pd.read_excel('data_09/data/neg.xls', header=None, index=None)
pos = pd.read_excel('data_09/data/pos.xls', header=None, index=None)# jieba 分词def word_cut(x): return jieba.lcut(x)pos['words'] = pos[0].apply(word_cut)
neg['words'] = neg[0].apply(word_cut)# 使用 1 表示积极情绪,0 表示消极情绪,并完成数组拼接
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)), np.zeros(len(neg))))# 将 Ndarray 保存为二进制文件备用
np.save('X_train.npy', x)
np.save('y_train.npy', y)print('done.')
预览一下数组的形状,以 x 为例:
np.load('X_train.npy', allow_pickle=True)
3.3 Word2Vec 处理
有了分词之后的数组,我们就可以开始 Word2Vec 处理,将其转换为词向量了。
目前,很多开源工具都提供了 Word2Vec 方法,比如 Gensim,TensorFlow,PaddlePaddle 等。这里我们使用 Gensim。
from gensim.models.word2vec import Word2Vec
import warnings
warnings.filterwarnings('ignore') # 忽略警告# 导入上面保存的分词数组
X_train = np.load('X_train.npy', allow_pickle=True)# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(size=300, min_count=10)
w2v.build_vocab(X_train)
w2v.train(X_train, total_examples=w2v.corpus_count, epochs=w2v.epochs)def sum_vec(text):# 对每个句子的词向量进行求和计算vec = np.zeros(300).reshape((1, 300))for word in text:try:vec += w2v[word].reshape((1, 300))except KeyError:continuereturn vec# 将词向量保存为 Ndarray
train_vec = np.concatenate([sum_vec(z) for z in X_train])
# 保存 Word2Vec 模型及词向量
w2v.save('w2v_model.pkl')
np.save('X_train_vec.npy', train_vec)
print('done.')
3.4 训练情绪分类模型
有了词向量,我们就有了机器学习模型的输入,那么就可以训练情绪分类模型。
选择速度较快的决策树方法,并使用 scikit-learn 完成。
from sklearn.externals import joblib
from sklearn.tree import DecisionTreeClassifier# 导入词向量为训练特征
X = np.load('X_train_vec.npy')
# 导入情绪分类作为目标特征
y = np.load('y_train.npy')
# 构建支持向量机分类模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X, y)
# 保存模型为二进制文件
joblib.dump(model, 'dt_model.pkl')
3.5 对评论数据进行情绪判断
# 读取 Word2Vec 并对新输入进行词向量计算
def sum_vec(words):# 读取 Word2Vec 模型w2v = Word2Vec.load('w2v_model.pkl')vec = np.zeros(300).reshape((1, 300))for word in words:try:vec += w2v[word].reshape((1, 300))except KeyError:continuereturn vec
# 读取蓝桥云课评论
df = pd.read_csv("data_09/comments.csv", header=0)
comment_sentiment = []
for string in df['评论内容']:# 对评论分词words = jieba.lcut(str(string))words_vec = sum_vec(words)# 读取支持向量机模型model = joblib.load('dt_model.pkl')result = model.predict(words_vec)comment_sentiment.append(result[0])# 实时返回积极或消极结果if int(result[0]) == 1:print(string, '[积极]')else:print(string, '[消极]')# 将情绪结果合并到原数据文件中
merged = pd.concat([df, pd.Series(comment_sentiment, name='用户情绪')], axis=1)
pd.DataFrame.to_csv(merged, 'comment_sentiment.csv') # 储存文件以备后用
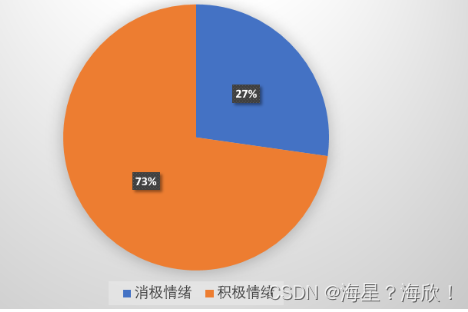
饼状图看一下蓝桥云课用户的情绪分布。总体看来,73% 都为积极评论:
相关文章:
实战项目-用户评论数据情绪分析
目录1、基于词典的方法2、基于词袋或 Word2Vec 的方法2.1 词袋模型2.2 Word2Vec3、案例:用户评论情绪分析3.1 数据读取3.2 语料库分词处理3.3 Word2Vec 处理3.4 训练情绪分类模型3.5 对评论数据进行情绪判断目的:去判断一段文本、评论的情绪偏向在这里&a…...
文本编辑快捷键 发展史)
day02 DOS(续)文本编辑快捷键 发展史
day02课堂笔记 1、常用的DOS命令(续) 1.1、del命令,删除一个或者多个文件 删除T1.class文件 C:\Users\Administrator>del T1.class 删除所有.class结尾的文件,支持模糊匹配 C:\Users\Administrator>del *.class T1.classT1…...

arm64与aarch64
结论: 目前arm64和aarch64概念已合并,新版64位arm程序统称aarch64. 问题引入: 存在部分机器,安装arm版本ss,会报错,提示 rootlocalhost ~]# rpm -ivh senseshiel50 59130arm64.rpm Verifying... ########…...

QString详解
QString存储16位Qchar(Unicode)字符串 QString使用隐式共享(copy-on-write)来提高性能。 什么是Unicode? unicode是一种国际标准,支持当今使用的大多数操作系统,他是US-ASCII和Latin-1的超集(与子集相同字符编码相同…...
SpringCloud微服务
一、微服务架构 1.1、单体应用架构 将项目所有模块(功能)打成jar或者war,然后部署一个进程 优点: 1:部署简单:由于是完整的结构体,可以直接部署在一个服务器上即可。 2:技术单一:项目不需要复杂的技术栈,往往一套熟悉的技术栈就可以完成开…...

Hive 连接及使用
1. 连接 有三种方式连接 hive: cli:直接输入 bin/hive 就可以进入 clihiveserver2、beelinewebui 1.1 hiveserver2/beeline 1、开启 hiveserver2 服务 // 前台运行,当 beeline 输入命令时,服务端会返回 OK [roothadoop1 bin]…...

android libavb深入解读
1、vbmeta结构解析 2、 libavb代码解读 代码地址https://cs.android.com/android/platform/superproject/+/master:external/avb/libavb/ 解析参考AVB源码学习(四):AVB2.0-libavb库介绍1_摸肚子的小胖子的博客-CSDN博客 这篇blog将会更加深入,掌握avb流程。 2.1、avb_slot_…...

【面试题】对闭包的理解?什么是闭包?
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库闭包的背景由于js中只有两种作用域,全局作用域和函数作用域,而在开发场景下,将变量暴露在全局作用域下的时候…...

笔试题-2023-乐鑫-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.09.01应聘岗位:数字IC设计工程师笔试时长:60min笔试平台:nowcoder牛客网题目类型:单选题(2道)、不定项选择题(7题)、问答题(…...
antd日期组件时间范围动态跟随
这周遇到了一个很诡异但又很合理的需求。掉了一周头发,死了很多脑细胞终于上线了。必须总结一下,不然对不起自己哈哈哈。 一、需求描述 默认当前日期时间不可清空。 功能 默认时间如下: 目的:将时间改为 2014-08-01 ~ 2014-08…...

mysql一条sql语句的执行过程
sql的具体执行过程 客户端发送一条查询给服务器服务器下先检查查询缓存,如果命中了缓存,返回缓存中的结果否则就需要服务器端进行sql的解析、预处理,再由优化器生成对应的执行计划根据执行计划,调用存储引擎的api来执行查询将结果…...

SaaS是什么,和多租户有什么关系?
空间数据又称几何数据,用来表示物体的位置,形态,大小分布等各方面的信息,是对现实世界中存在的具有定位意义的事物和现象的定量描述。 多租户是SaaS领域特有的产物。 SaaS服务是部署在云上的,客户可以按需购买&#…...

C语言---字符串函数总结
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...

MySQL-表的基本操作
一、创建数据表创建数据表是指在已经创建好的数据库中建立新表。创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性约束的过程。创建表之前应先使用语句{use 数据库名} 进入到指定的数据库,再执行表操作。创建表语法:CREATE TABLE <表…...

开篇之作—闲聊几句AUTOSAR
背景信息 步入职场已有些许年头,遇到过不少的人,经历过不算多的事情,也走过一些地方。现在坐下来想想,觉得一路走过总是行色匆匆,都来不及停下来驻足路边的风景,抑或是回头看看身后的精彩。 现在有些庆幸的是,加入了这个汽车这个行业,从事着汽车电子开发领域,也因此…...
02- 天池工业蒸汽量项目实战 (项目二)
忽略警告: warnings.filterwarnings("ignore") import warnings warnings.filterwarnings("ignore") 读取文件格式: pd.read_csv(train_data_file, sep\t) # 注意sep 是 , , 还是\ttrain_data.info() # 查看是否存在空数据及数据类型train_data.desc…...

LeetCode-111. 二叉树的最小深度
目录题目分析递归法题目来源111. 二叉树的最小深度题目分析 这道题目容易联想到104题的最大深度,把代码搬过来 class Solution {public int minDepth(TreeNode root) {return dfs(root);}public static int dfs(TreeNode root){if(root null){return 0;}int left…...

git常用命令
(一)克隆代码(clone):将远程仓库代码克隆到本地仓库 克隆远程仓库某个分支 git clone -b 远程分支名称 https://github.com/master/master.git 本地文件名称 克隆远程仓库默认分支 git clone https://github.com/mas…...

2022年12月电子学会Python等级考试试卷(一级)答案解析
青少年软件编程(Python)等级考试试卷(一级) 一、单选题(共25题,共50分) 1. 关于Python语言的注释,以下选项中描述错误的是?( ) A. Python语言有两种注释方式&…...

大数据未来会如何发展
大数据应用的重要性,自全国提出“数据中国”的概念以来,我们周围默默地在发挥作用的大数据逐渐深入人们的心中,大数据的应用也越来越广泛,具体到金融、汽车、餐饮、电信、能源、体育和娱乐等领域 为什么大数据技术那么火…...

Pearcleaner:开源透明的Mac应用清理工具,彻底释放存储空间
Pearcleaner:开源透明的Mac应用清理工具,彻底释放存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾发现删除Mac应用后…...
)
保姆级图解:用Wireshark抓包分析PCI总线读写的完整时序(附信号解读)
保姆级图解:用Wireshark抓包分析PCI总线读写的完整时序(附信号解读) 在嵌入式开发和硬件调试领域,能够直观观察总线通信时序是每个工程师梦寐以求的能力。传统上我们只能通过示波器观察波形或查阅芯片手册中的时序图,但…...
的设计与优化)
Verilog实战:从零构建高效仲裁器(Arbiter)的设计与优化
1. 仲裁器基础概念与设计需求 在数字系统中,当多个主设备(Master)需要共享同一总线或存储资源时,仲裁器就像交通警察一样协调访问顺序。我遇到过这样一个真实案例:某AI芯片设计中使用8个计算单元共享DDR控制器…...

3个技巧让Clipy彻底改变你的macOS剪贴板使用体验
3个技巧让Clipy彻底改变你的macOS剪贴板使用体验 【免费下载链接】Clipy Clipboard extension app for macOS. 项目地址: https://gitcode.com/gh_mirrors/cl/Clipy 你是不是经常遇到这样的情况:刚刚复制了一段重要信息,又复制了其他内容…...

高通Android音频HAL揭秘:从AudioFlinger到libaudiohal.so的加载与设备打开流程
高通Android音频HAL深度解析:从框架设计到硬件交互的全链路实现 在Android系统的多媒体生态中,音频子系统扮演着至关重要的角色。作为连接应用层与物理硬件的桥梁,音频硬件抽象层(HAL)的设计直接决定了设备的音频性能…...

PheroPath:基于规则与数据库比对的生物信息素合成通路预测工具解析
1. 项目概述与核心价值 最近在生物信息学和药物发现领域,一个名为“PheroPath”的项目在GitHub上引起了我的注意。这个项目由用户starpig1129开源,其核心目标是构建一个用于预测和可视化信息素(Pheromone)生物合成通路的工具。乍一…...

2026届学术党必备的六大AI论文工具推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 撰写AI毕业论文之时,需一直坚守学术伦理底线,严格禁止直接靠着生成式…...

手机市场饱和下的细分突围:从功能过剩到场景化专用设备
1. 市场饱和与行业焦虑的根源手机销量下滑,这已经不是新闻,而是悬在所有制造商头顶的一把达摩克利斯之剑。当全球73亿人口中,手机用户数达到惊人的68亿时,市场饱和的警钟就已经敲响。这不是一个简单的周期性波动,而是整…...

AI舞蹈生成实战:从扩散模型原理到seedance-2.0部署与调优
1. 项目概述:从种子到舞蹈的AI生成革命最近在AI生成领域,一个名为“seedance-2.0”的项目引起了我的注意。这个项目名本身就很有意思,“seedance”可以拆解为“seed”(种子)和“dance”(舞蹈)&a…...

如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀
如何用Sticky便签应用提升Linux桌面工作效率的5个秘诀 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否厌倦了在多个窗口间切换查找笔记?是否经常忘记重要的待办事项&#x…...