Hive 连接及使用
1. 连接
有三种方式连接 hive:
cli:直接输入bin/hive就可以进入clihiveserver2、beelinewebui
1.1 hiveserver2/beeline
1、开启 hiveserver2 服务
// 前台运行,当 beeline 输入命令时,服务端会返回 OK
[root@hadoop1 bin]# ./hiveserver2
OK// 后台运行,1:表示标准日志输出、2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做: nohup.xxx
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者:nohup hiveserver2 1>/dev/null 2>/dev/null &
或者:nohup hiveserver2 >/dev/null 2>&1 &
2、启动 beeline 客户端连接
[hadoop@hadoop1 bin]$ ./beeline// 这里为 hadoop 的用户名
beeline> !connect jdbc:hive2://hadoop1:10000
Connecting to jdbc:hive2://hadoop1:10000
Enter username for jdbc:hive2://hadoop1:10000: hadoop
Enter password for jdbc:hive2://hadoop1:10000: ******
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop1:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
| hive_1 |
+----------------+--+
2 rows selected (4.183 seconds)
0: jdbc:hive2://hadoop1:10000>// 指定用户名连接
beeline -u jdbc:hive2://hadoop1:10000 -n hadoop
参考文章:Hive学习之路 (四)Hive的连接3种连接方式
2. 交互式命令
// -e 不进入hive的交互窗口执行sql语句
bin/hive -e "select id from student;"// -f 执行脚本中的 sql 语句,hivef.sql 语句:select *from student;
bin/hive -f /opt/module/datas/hivef.sql
bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt// 退出
exit、quit// 查看 hdfs 文件系统
dfs -ls /;// 查看本地文件系统
! ls /opt/module/datas;// 查看在hive中输入的所有历史命令,一般为当前用户的根目录 /root 或 /home 目录
cat /home/hadoop/.hivehistory// 其他常用命令
show databases;
show tables;
drop table tableName;
desc tableName; // 查看表结构
use default; // 使用数据库
3. 常见属性配置
3.1 数据仓库位置
Default 数据仓库的最原始位置是在 hdfs 上的:/user/hive/warehouse 路径下,修改位置:
<!--hive-default.xml.template 拷贝到 hive-site.xml文件中--><property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
配置完后,需要修改同组用户权限:
bin/hdfs dfs -chmod g+w /user/hive/warehouse
注意:重启
hive cli才会生效
3.2 修改查询结果显示信息
1、新建一张表 student,并插入数据:
// 以 \t 作为分隔符
[hadoop@hadoop1 apps]$ vim my_code/student.txt// 检查分隔符
[hadoop@hadoop1 apps]$ cat -T my_code/student.txt
1001^Izhangshan
1002^Ilishi
1003^Izhaoliu// 创建一张表 student,数据以 \t 作为分隔符
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.463 seconds// 从本地导入数据
hive> load data local inpath '/home/hadoop/apps/my_code/student.txt' into table student;
Loading data to table hive_1.student
Table hive_1.student stats: [numFiles=1, totalSize=39]
OK
Time taken: 0.846 seconds// 查询(发现没有显示具体列名等信息)
hive> select * from student;
OK
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.229 seconds, Fetched: 3 row(s)2、修改 hive-site.xml文件中添加如下配置信息:
<property><name>hive.cli.print.header</name><value>true</value>
</property><property><name>hive.cli.print.current.db</name><value>true</value>
</property>
3、重启 hive:
// 显示列名
hive (hive_1)> select * from student;
OK
student.id student.name
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 1.636 seconds, Fetched: 3 row(s)
3.3 Hive 运行日志信息配置
1、默认日志路径:/tmp/hadoop/hive.log
2、修改 hive-log4j.properties:
[hadoop@hadoop1 apps]$ cd hive/conf/
[hadoop@hadoop1 conf]$ ls
beeline-log4j.properties.template hive-env.sh hive-exec-log4j.properties.template hive-site.xml
hive-default.xml.template hive-env.sh.template hive-log4j.properties.template ivysettings.xml
[hadoop@hadoop1 conf]$ cp hive-log4j.properties.template hive-log4j.properties
[hadoop@hadoop1 conf]$ vim hive-log4j.properties// 修改日志路径
hive.log.dir=/home/hadoop/apps/hive/logs
3、重启 hive
3.4 参数配置方式
参数配置有三种方式:
- 修改配置文件:对所有会话有效
- 命令行参数:仅对本次会话有效,即退出
cli就失效 - 参数声明:上同
优先级:配置文件 < 命令行参数 < 参数声明
系统级的参数,log4j,必须用前两种方式设定,因为参数的读取在会话建立之前就完成了,推荐使用第一种方式
配置文件
-
默认配置文件:
hive-default.xml -
用户自定义配置文件:
hive-site.xml
注意:用户自定义配置会覆盖默认配置,另外
hive配置会覆盖hadoop配置,因为它会读取hadoop配置
命令行参数
即在启动 hive时通过命令行来添加一些参数,如:
// 格式:-hiveconf param=value
bin/hive -hiveconf mapred.reduce.tasks=10;// 查看配置hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=-1
参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
hive (default)> set mapred.reduce.tasks=100;
相关文章:

Hive 连接及使用
1. 连接 有三种方式连接 hive: cli:直接输入 bin/hive 就可以进入 clihiveserver2、beelinewebui 1.1 hiveserver2/beeline 1、开启 hiveserver2 服务 // 前台运行,当 beeline 输入命令时,服务端会返回 OK [roothadoop1 bin]…...

android libavb深入解读
1、vbmeta结构解析 2、 libavb代码解读 代码地址https://cs.android.com/android/platform/superproject/+/master:external/avb/libavb/ 解析参考AVB源码学习(四):AVB2.0-libavb库介绍1_摸肚子的小胖子的博客-CSDN博客 这篇blog将会更加深入,掌握avb流程。 2.1、avb_slot_…...

【面试题】对闭包的理解?什么是闭包?
大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库闭包的背景由于js中只有两种作用域,全局作用域和函数作用域,而在开发场景下,将变量暴露在全局作用域下的时候…...

笔试题-2023-乐鑫-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.09.01应聘岗位:数字IC设计工程师笔试时长:60min笔试平台:nowcoder牛客网题目类型:单选题(2道)、不定项选择题(7题)、问答题(…...
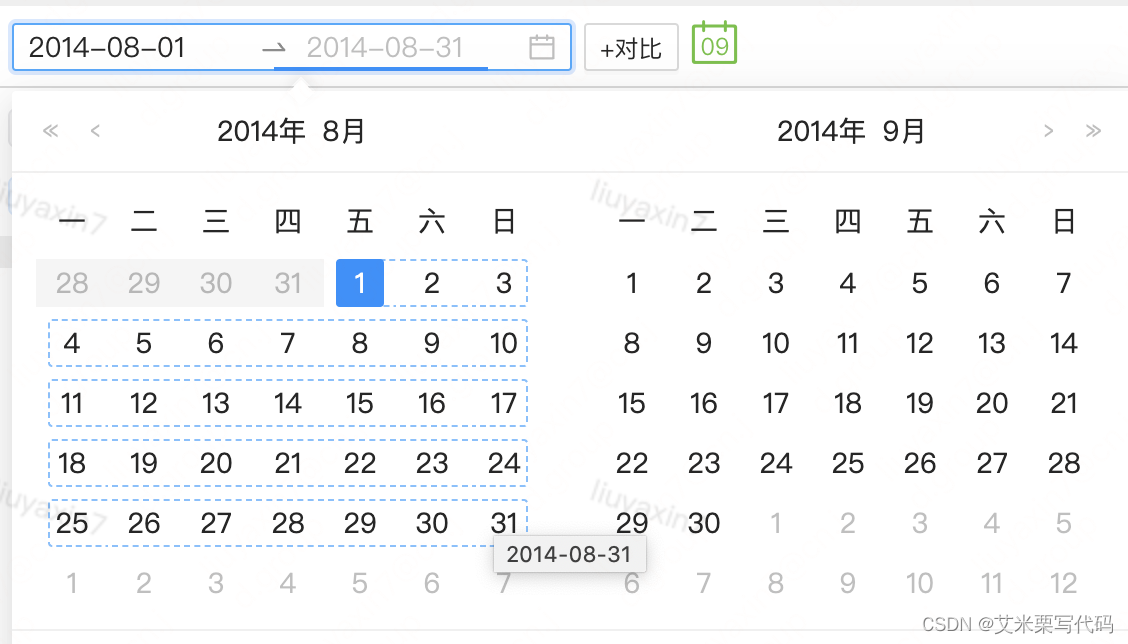
antd日期组件时间范围动态跟随
这周遇到了一个很诡异但又很合理的需求。掉了一周头发,死了很多脑细胞终于上线了。必须总结一下,不然对不起自己哈哈哈。 一、需求描述 默认当前日期时间不可清空。 功能 默认时间如下: 目的:将时间改为 2014-08-01 ~ 2014-08…...

mysql一条sql语句的执行过程
sql的具体执行过程 客户端发送一条查询给服务器服务器下先检查查询缓存,如果命中了缓存,返回缓存中的结果否则就需要服务器端进行sql的解析、预处理,再由优化器生成对应的执行计划根据执行计划,调用存储引擎的api来执行查询将结果…...

SaaS是什么,和多租户有什么关系?
空间数据又称几何数据,用来表示物体的位置,形态,大小分布等各方面的信息,是对现实世界中存在的具有定位意义的事物和现象的定量描述。 多租户是SaaS领域特有的产物。 SaaS服务是部署在云上的,客户可以按需购买&#…...

C语言---字符串函数总结
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...

MySQL-表的基本操作
一、创建数据表创建数据表是指在已经创建好的数据库中建立新表。创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性约束的过程。创建表之前应先使用语句{use 数据库名} 进入到指定的数据库,再执行表操作。创建表语法:CREATE TABLE <表…...

开篇之作—闲聊几句AUTOSAR
背景信息 步入职场已有些许年头,遇到过不少的人,经历过不算多的事情,也走过一些地方。现在坐下来想想,觉得一路走过总是行色匆匆,都来不及停下来驻足路边的风景,抑或是回头看看身后的精彩。 现在有些庆幸的是,加入了这个汽车这个行业,从事着汽车电子开发领域,也因此…...
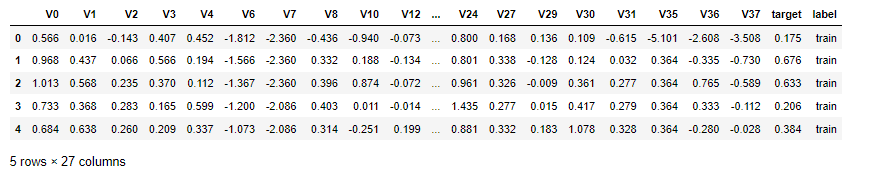
02- 天池工业蒸汽量项目实战 (项目二)
忽略警告: warnings.filterwarnings("ignore") import warnings warnings.filterwarnings("ignore") 读取文件格式: pd.read_csv(train_data_file, sep\t) # 注意sep 是 , , 还是\ttrain_data.info() # 查看是否存在空数据及数据类型train_data.desc…...

LeetCode-111. 二叉树的最小深度
目录题目分析递归法题目来源111. 二叉树的最小深度题目分析 这道题目容易联想到104题的最大深度,把代码搬过来 class Solution {public int minDepth(TreeNode root) {return dfs(root);}public static int dfs(TreeNode root){if(root null){return 0;}int left…...

git常用命令
(一)克隆代码(clone):将远程仓库代码克隆到本地仓库 克隆远程仓库某个分支 git clone -b 远程分支名称 https://github.com/master/master.git 本地文件名称 克隆远程仓库默认分支 git clone https://github.com/mas…...

2022年12月电子学会Python等级考试试卷(一级)答案解析
青少年软件编程(Python)等级考试试卷(一级) 一、单选题(共25题,共50分) 1. 关于Python语言的注释,以下选项中描述错误的是?( ) A. Python语言有两种注释方式&…...

大数据未来会如何发展
大数据应用的重要性,自全国提出“数据中国”的概念以来,我们周围默默地在发挥作用的大数据逐渐深入人们的心中,大数据的应用也越来越广泛,具体到金融、汽车、餐饮、电信、能源、体育和娱乐等领域 为什么大数据技术那么火…...

2022黑马Redis跟学笔记.基础篇(一)
2022黑马Redis跟学笔记.基础篇 一1.Redis入门1.1.认识NoSQL1.1.1.结构化与非结构化1.1.2.关联和非关联1.1.3.查询方式1.1.4.事务1.1.5.总结1.2.认识Redis1.3.安装Redis步骤一:安装Redis依赖步骤二:上传安装包并解压步骤三:启动(1).默认启动(2…...
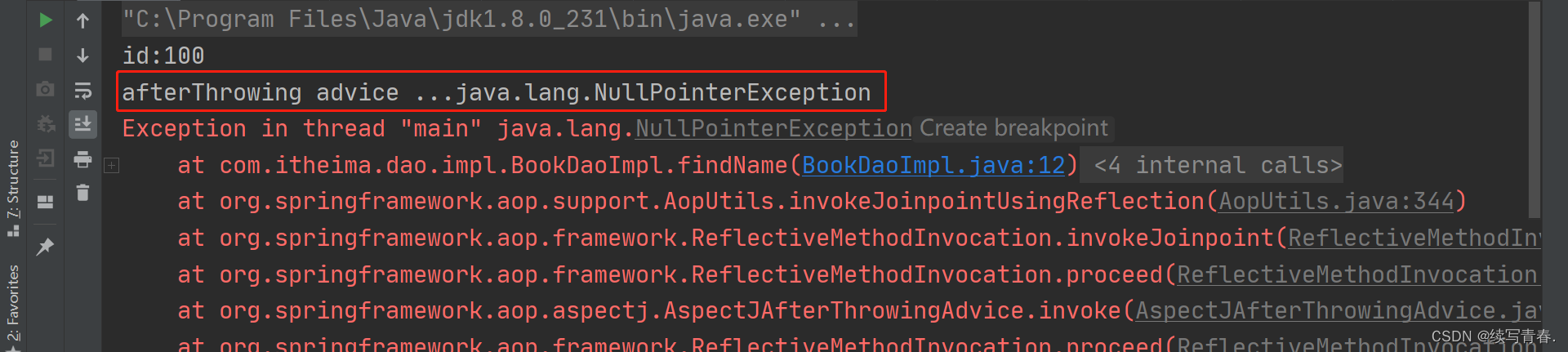
【Spring(十一)】万字带你深入学习面向切面编程AOP
文章目录前言AOP简介AOP入门案例AOP工作流程AOP切入点表达式AOP通知类型AOP通知获取数据总结前言 今天我们来学习AOP,在最初我们学习Spring时说过Spring的两大特征,一个是IOC,一个是AOP,我们现在要学习的就是这个AOP。 AOP简介 AOP:面向切面编程,一种编程范式&#…...

基于Java+SpringBoot+Vue+uniapp前后端分离图书阅读系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建、毕业项目实战、项目定制✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《S…...

2021年新公开工业控制系统严重漏洞汇总
声明 本文是学习ITOT一体化工业信息安全态势报告(2019). 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 工业互联网安全威胁 2021年新公开工业控制系统严重漏洞 缓冲区溢出漏洞 缓冲区溢出(buffer overflow&…...
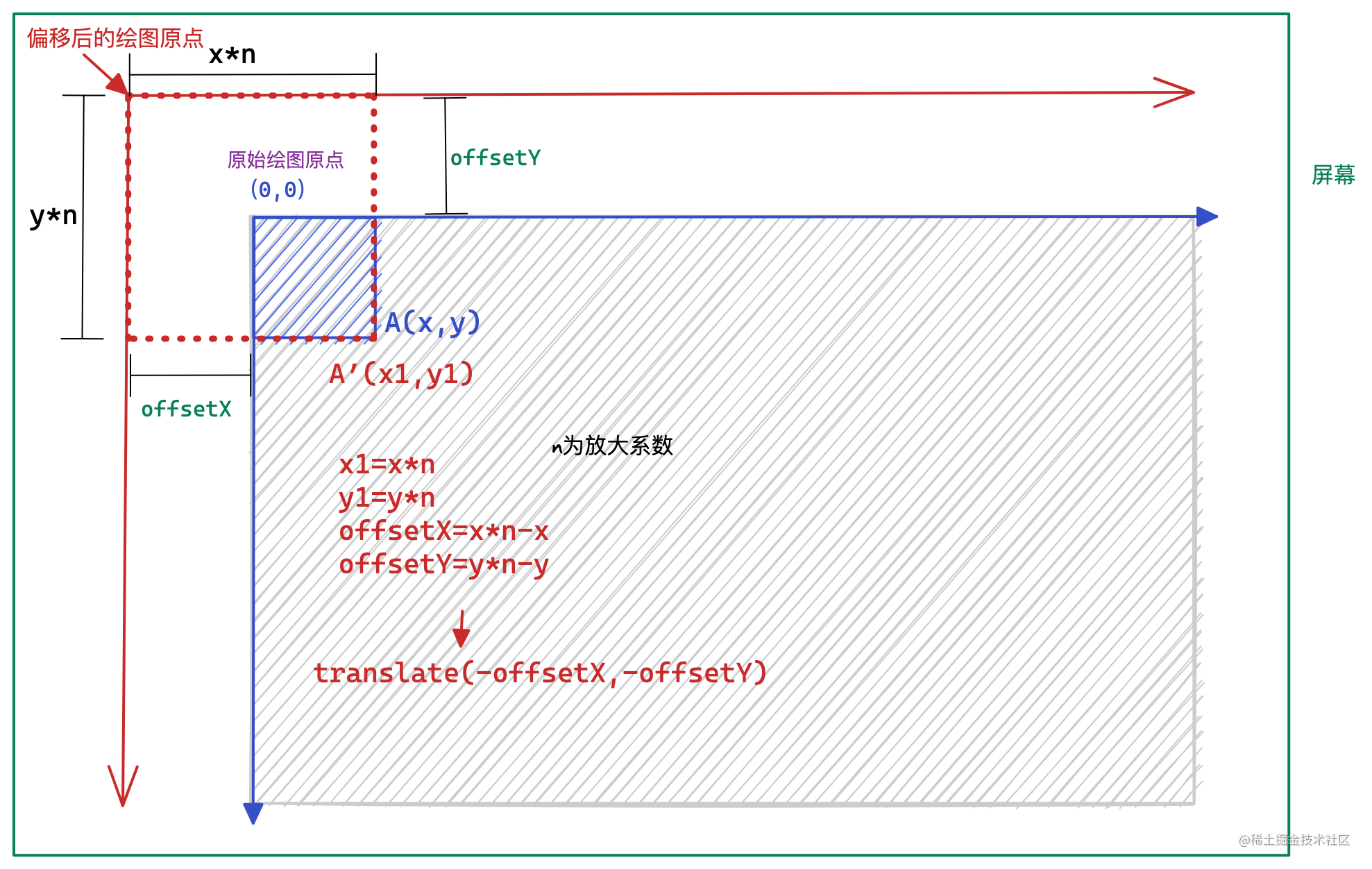
Canvas鼠标滚轮缩放以及画布拖动(图文并茂版)
Canvas鼠标滚轮缩放以及画布拖动 本文会带大家认识Canvas中常用的坐标变换方法 translate 和 scale,并结合这两个方法,实现鼠标滚轮缩放以及画布拖动功能。 Canvas的坐标变换 Canvas 绘图的缩放以及画布拖动主要通过 CanvasRenderingContext2D 提供的 …...

【实战】RJ45连接器选型与设计:从集成架构到户外防护的11个避坑指南
一句话速览:RJ45选型不是只看几块钱的物料成本,而是一个涉及架构决策(集成/分离)、PoE功率等级、屏蔽接地方式、防水等级和压接工艺的系统工程。本文结合真实故障案例,梳理出11个最常见的选型与设计“坑”,…...

OpenUsage:一站式AI订阅用量监控工具的设计与实战
1. 项目概述:为什么我们需要一个AI订阅用量监控器? 如果你和我一样,是个重度依赖AI编程工具的开发者,那你肯定对下面这个场景不陌生:为了搞清楚自己这个月还剩多少Claude的会话额度,得先打开浏览器&#x…...

如何在5分钟内用Blender创建专业级分子可视化效果
如何在5分钟内用Blender创建专业级分子可视化效果 【免费下载链接】blender-chemicals Draws chemicals in Blender using common input formats (smiles, molfiles, cif files, etc.) 项目地址: https://gitcode.com/gh_mirrors/bl/blender-chemicals 还在为制作分子结…...
)
别再踩坑了!Ubuntu 20.04下用Docker一键编译OLLVM 4.0(附完整Dockerfile)
基于Docker的OLLVM 4.0高效编译指南:Ubuntu 20.04最佳实践 在移动安全与逆向工程领域,OLLVM作为代码混淆的黄金标准工具链,其环境搭建一直是开发者面临的痛点。传统源码编译方式需要处理复杂的依赖关系、版本冲突和系统污染风险,而…...

如何提升co项目代码质量:ESLint规则与异步检查完整指南
如何提升co项目代码质量:ESLint规则与异步检查完整指南 【免费下载链接】co The ultimate generator based flow-control goodness for nodejs (supports thunks, promises, etc) 项目地址: https://gitcode.com/gh_mirrors/co/co co作为Node.js生态中基于生…...

# 软考软件设计师每日精练 | 2026-04-25
📝 软考软件设计师每日精练 | 2026-04-25📅 距离2026年5月23日软考还有 28天! 今日重点:算法策略辨析 线性规划 知识产权深化 项目管理工具🎯 模块一:算法策略辨析(必考 ★★★★★ÿ…...

从接入到稳定运行Taotoken在延迟与容灾方面的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从接入到稳定运行:Taotoken在延迟与容灾方面的实际体验 对于将大模型能力集成到生产系统的开发者而言,服务…...

VMware macOS 虚拟机终极解锁指南:Unlocker 3.0 完整使用教程
VMware macOS 虚拟机终极解锁指南:Unlocker 3.0 完整使用教程 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 在虚拟化技术日益普及的今天,VMware Workstation 和 Player 用户经…...

基于Rust构建命令行任务监控与通知工具:openclaw-tui-notify实践
1. 项目概述与核心价值最近在折腾一个后台数据处理脚本,它经常一跑就是好几个小时。问题来了,我总不能一直盯着终端看它什么时候结束吧?有时候去开个会、吃个饭,回来发现脚本早就跑完了,白白浪费了时间等结果。更头疼的…...

如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南
如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio MIKE IO是一个功能强大的Python开源库…...