CV计算机视觉每日开源代码Paper with code速览-2023.12.6
点击@计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
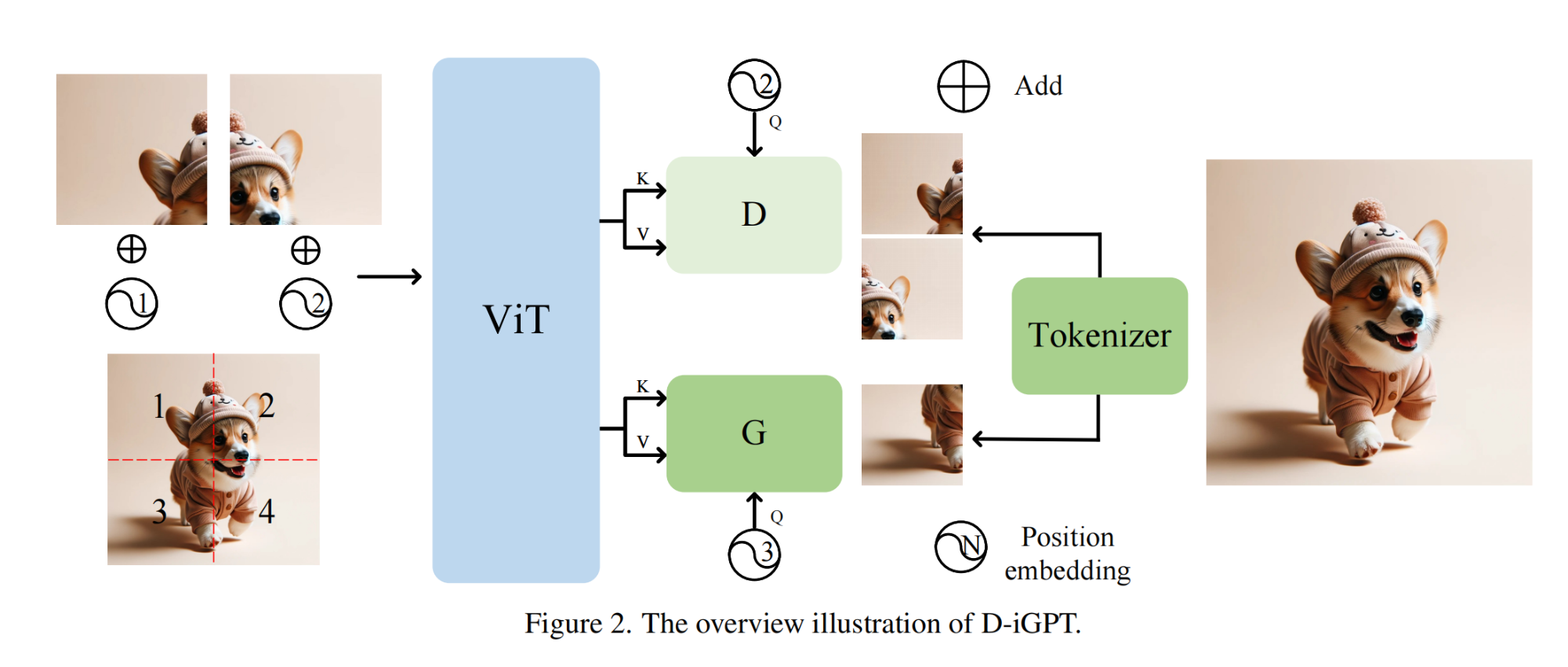
1.【基础网络架构:Transformer】Rejuvenating image-GPT as Strong Visual Representation Learners
-
论文地址:https://arxiv.org//pdf/2312.02147
-
开源代码:https://github.com/OliverRensu/D-iGPT
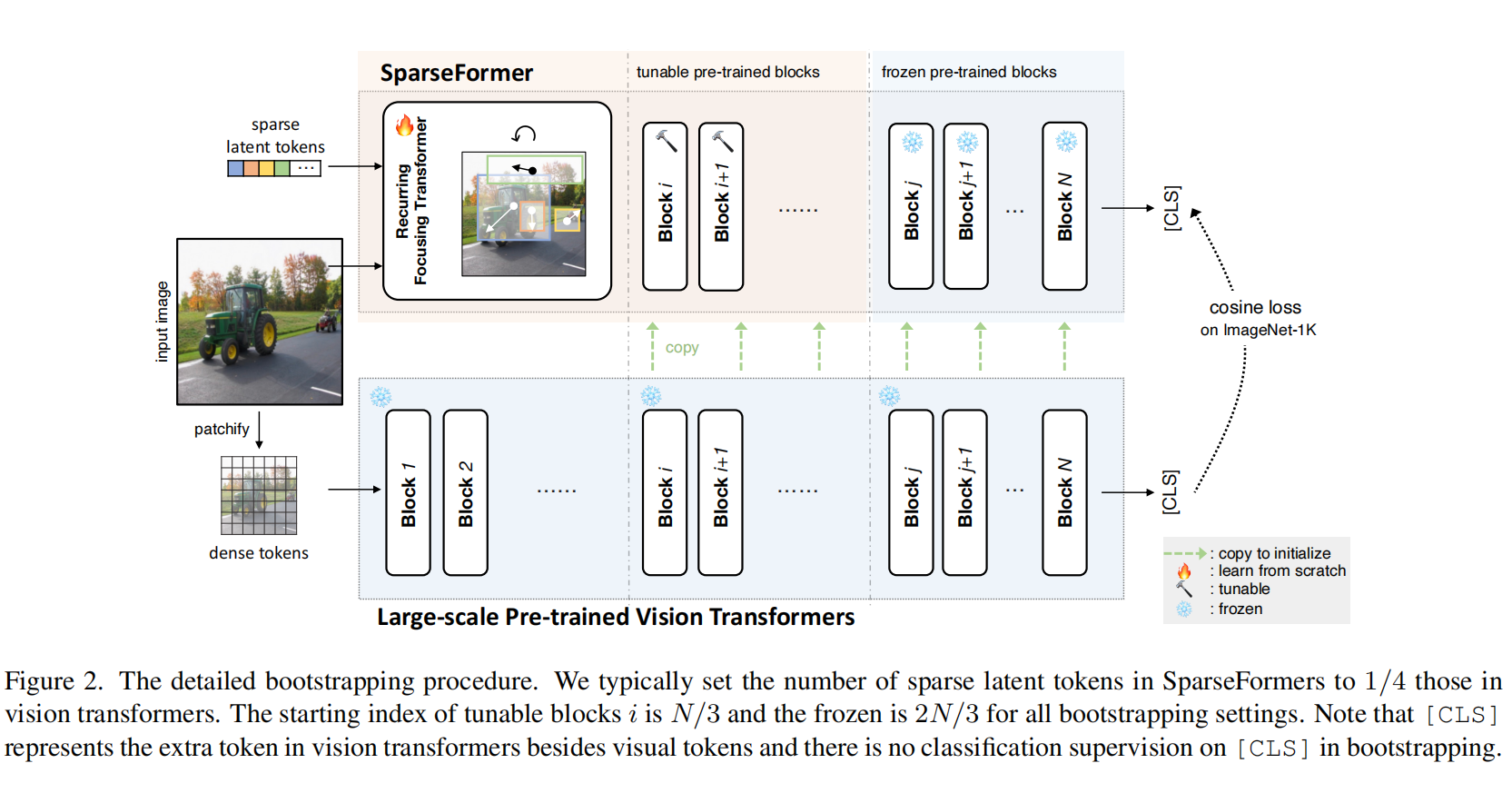
2.【基础网络架构:Transformer】Bootstrapping SparseFormers from Vision Foundation Models
-
论文地址:https://arxiv.org//pdf/2312.01987
-
开源代码:https://github.com/showlab/sparseformer
3.【异常检测】Unsupervised Anomaly Detection using Aggregated Normative Diffusion
-
论文地址:https://arxiv.org//pdf/2312.01904
-
开源代码:https://github.com/alexanderfrotscher/ANDi

4.【视频异常检测】Dynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
-
论文地址:https://arxiv.org//pdf/2312.01764
-
开源代码(即将开源):https://github.com/ArielZc/DE-Net

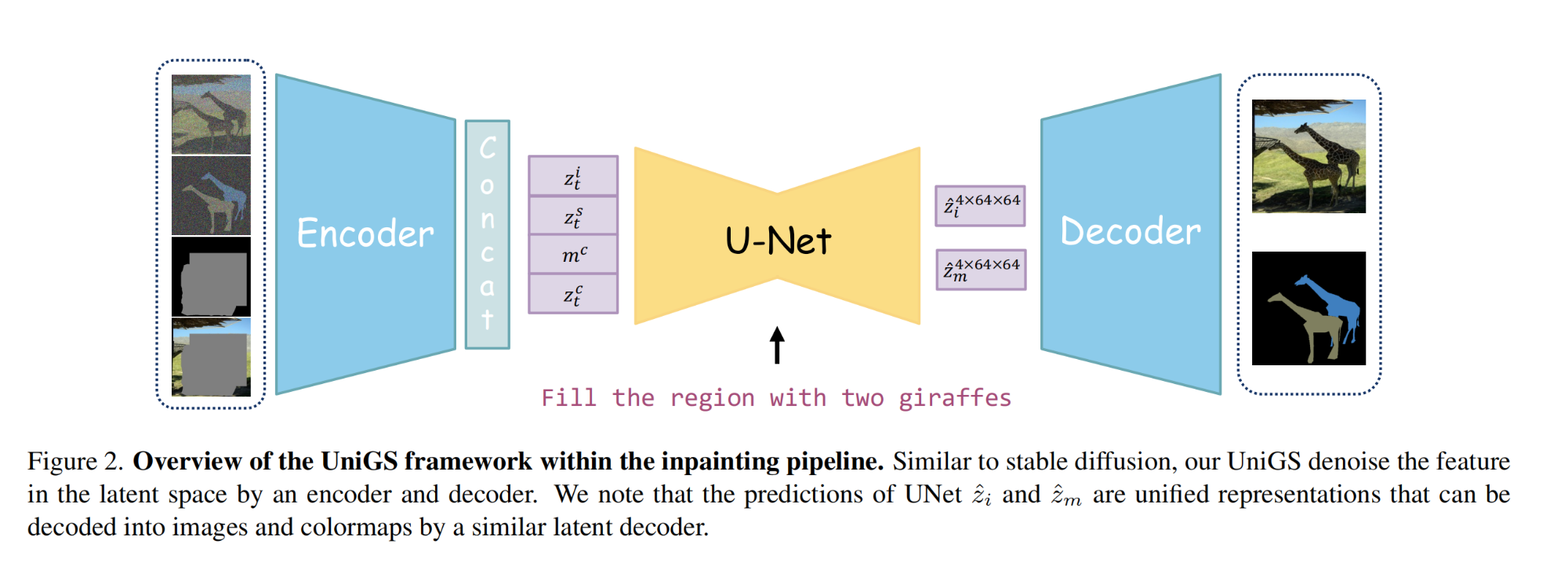
5.【图像分割】UniGS: Unified Representation for Image Generation and Segmentation
-
论文地址:https://arxiv.org//pdf/2312.01985
-
开源代码(即将开源):https://github.com/qqlu/Entity
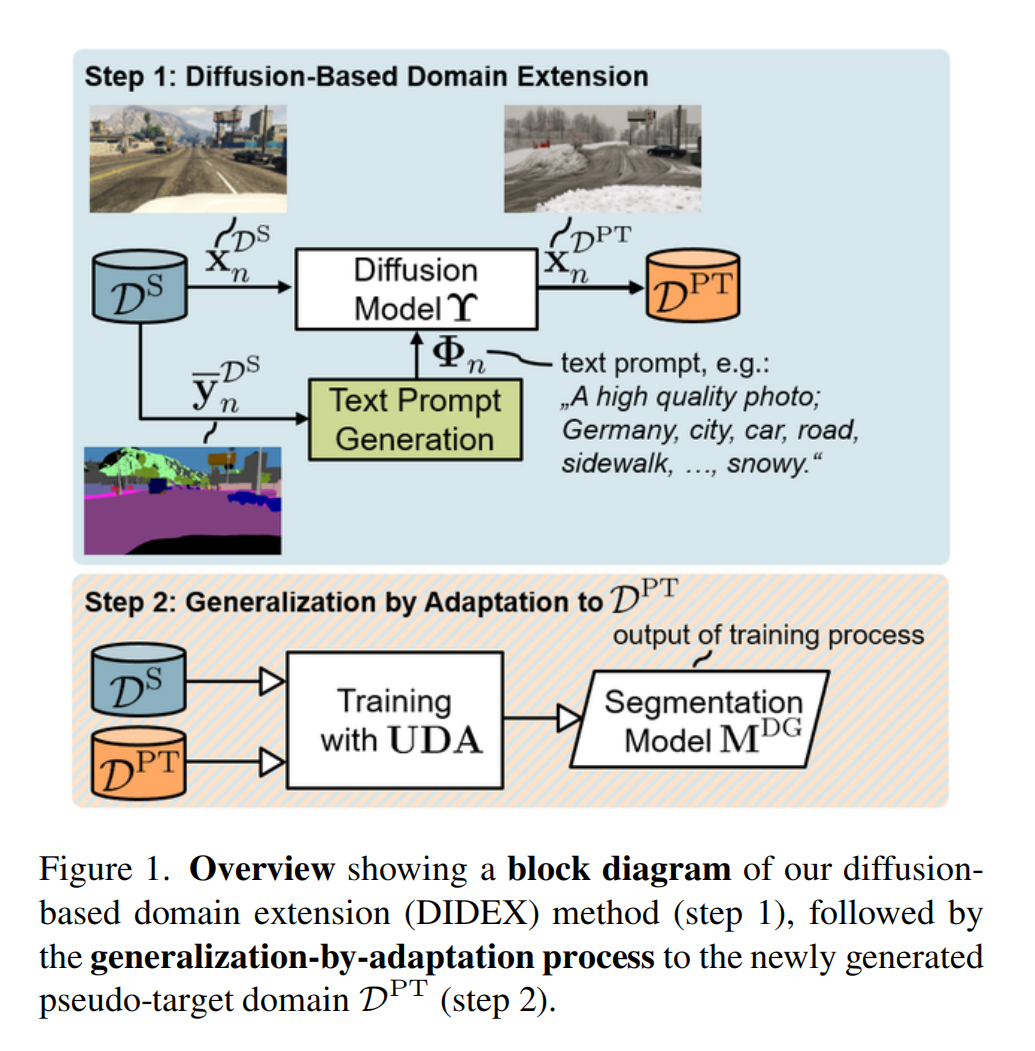
6.【语义分割】Generalization by Adaptation: Diffusion-Based Domain Extension for Domain-Generalized Semantic Segmentation
-
论文地址:https://arxiv.org//pdf/2312.01850
-
开源代码(即将开源):https://github.com/JNiemeijer/DIDEX
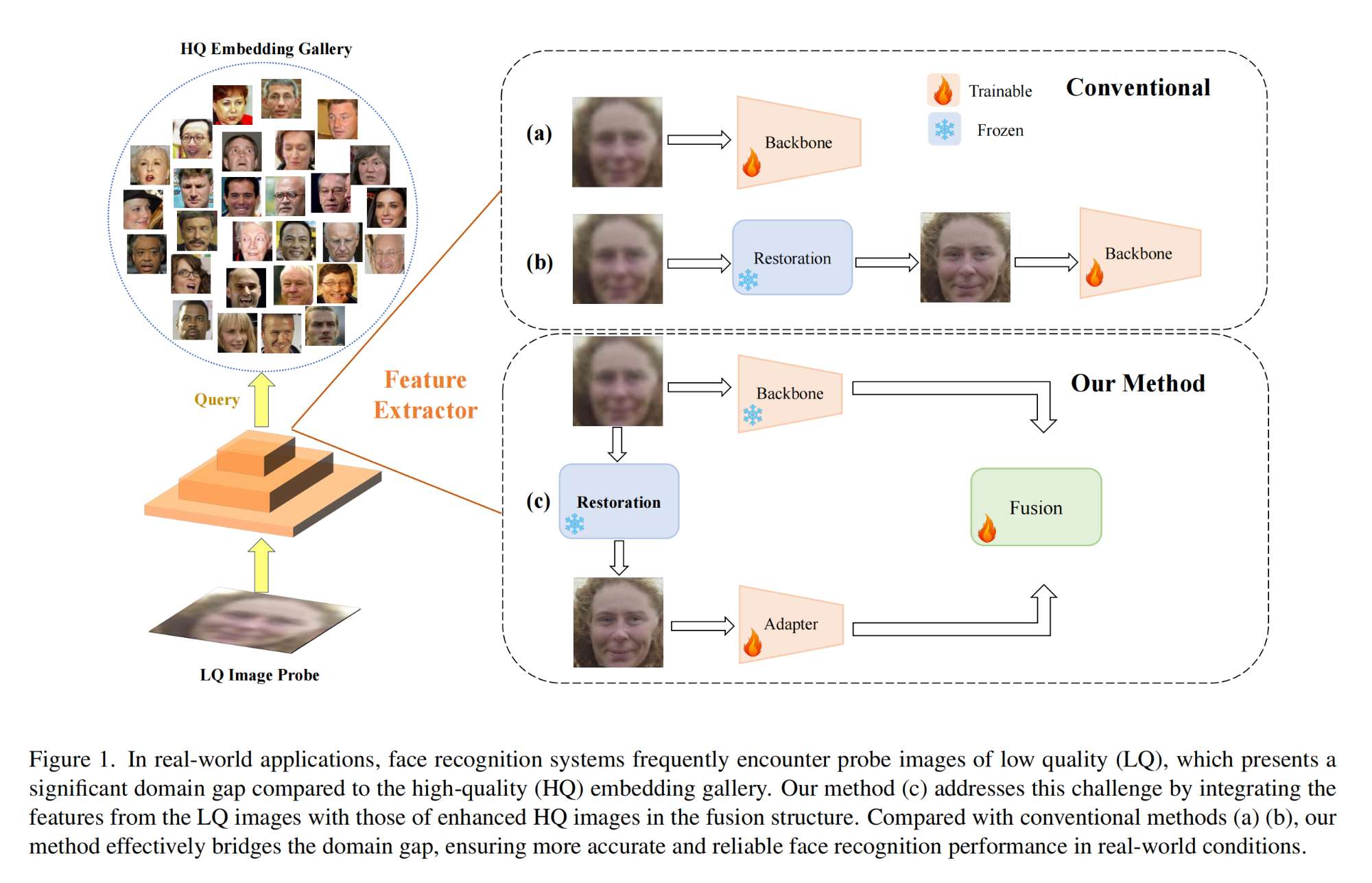
7.【人脸识别】Effective Adapter for Face Recognition in the Wild
-
论文地址:https://arxiv.org//pdf/2312.01734
-
工程主页:Effective Adapter for Face Recognition in the Wild
-
开源代码(即将开源):https://github.com/liuyunhaozz/faceadapter/
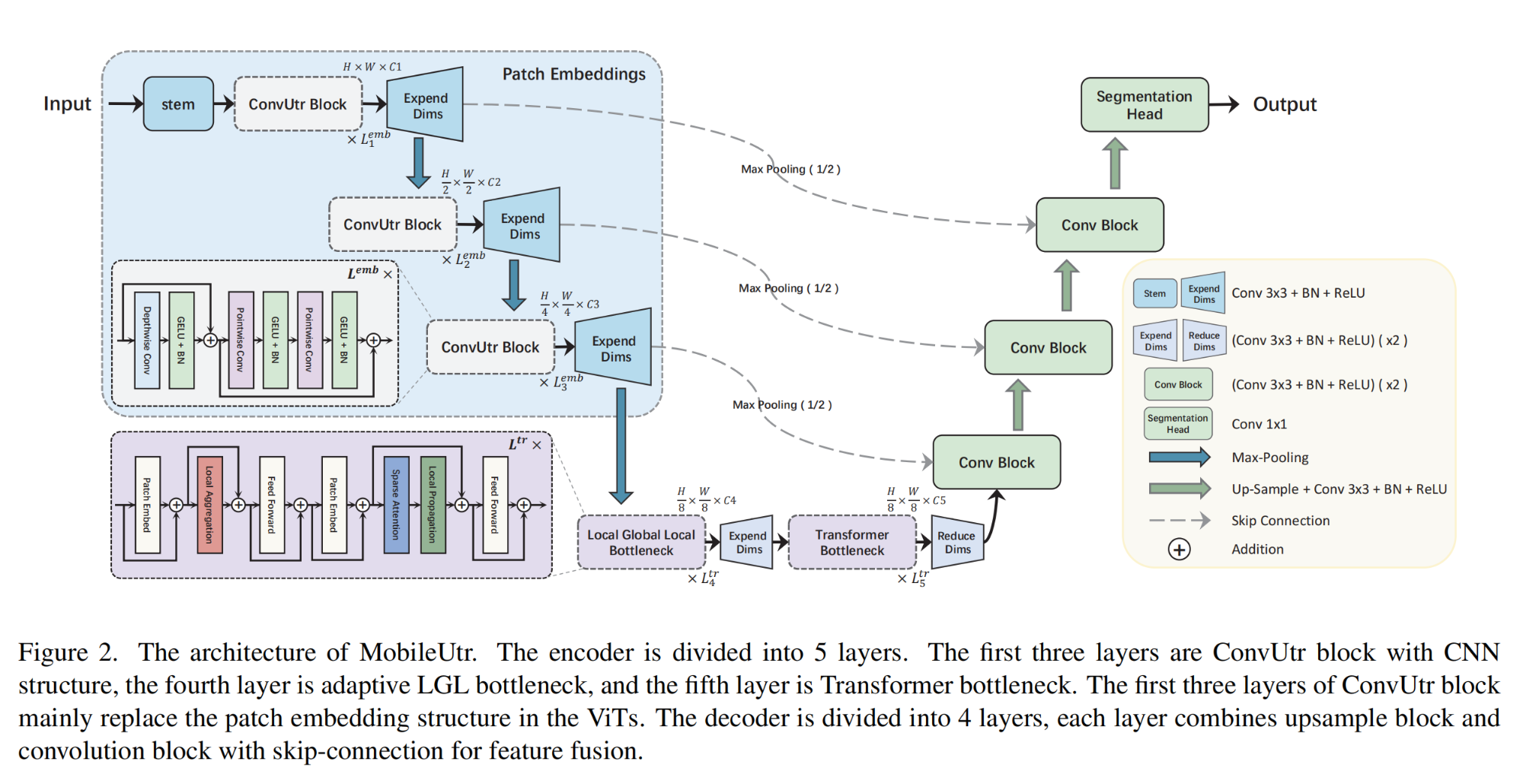
8.【医学图像分割】MobileUtr: Revisiting the relationship between light-weight CNN and Transformer for efficient medical image segmentation
-
论文地址:https://arxiv.org//pdf/2312.01740
-
开源代码(即将开源):https://github.com/FengheTan9/MobileUtr
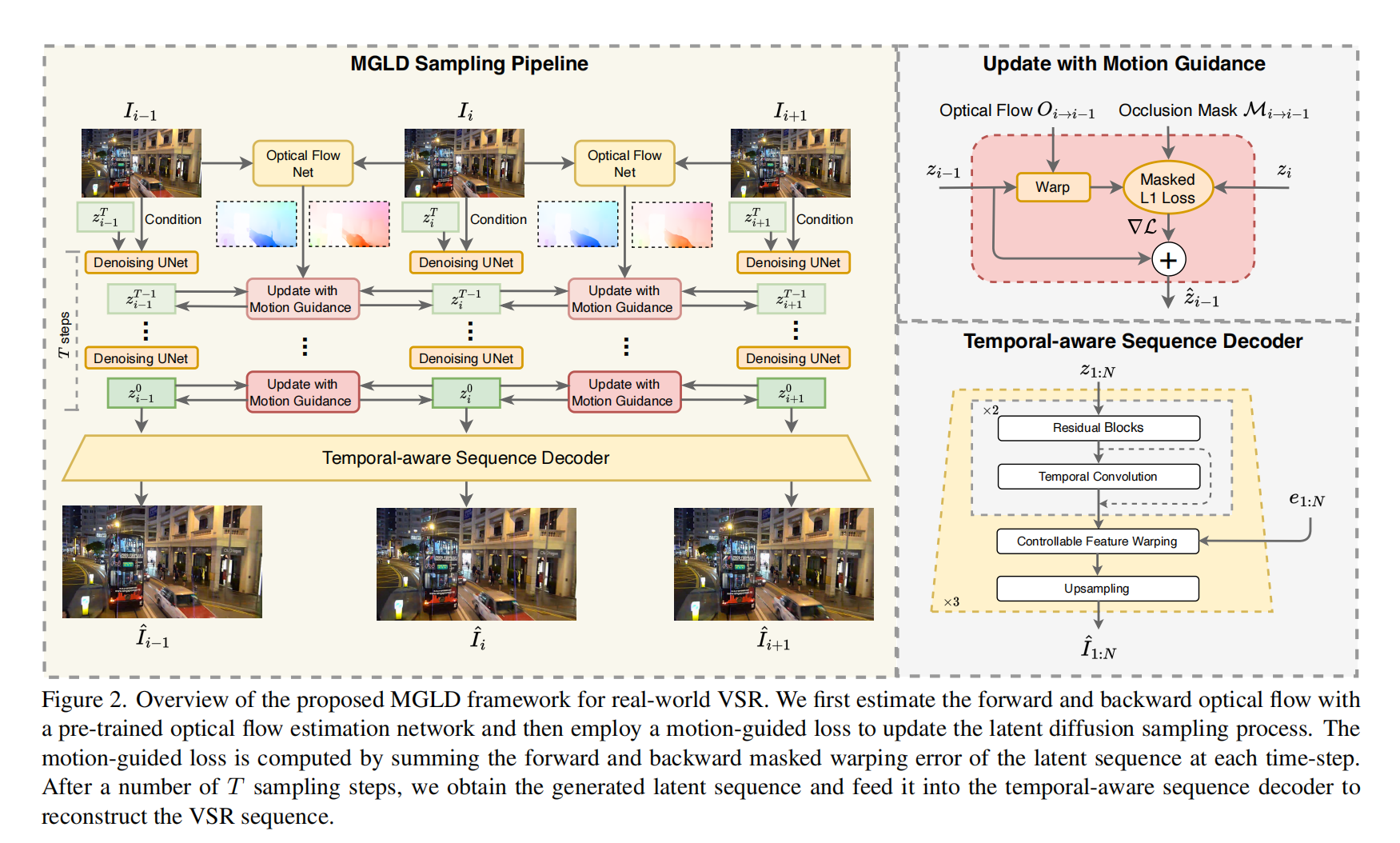
9.【视频超分辨率重建】Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
-
论文地址:https://arxiv.org//pdf/2312.00853
-
开源代码(即将开源):https://github.com/IanYeung/MGLD-VSR
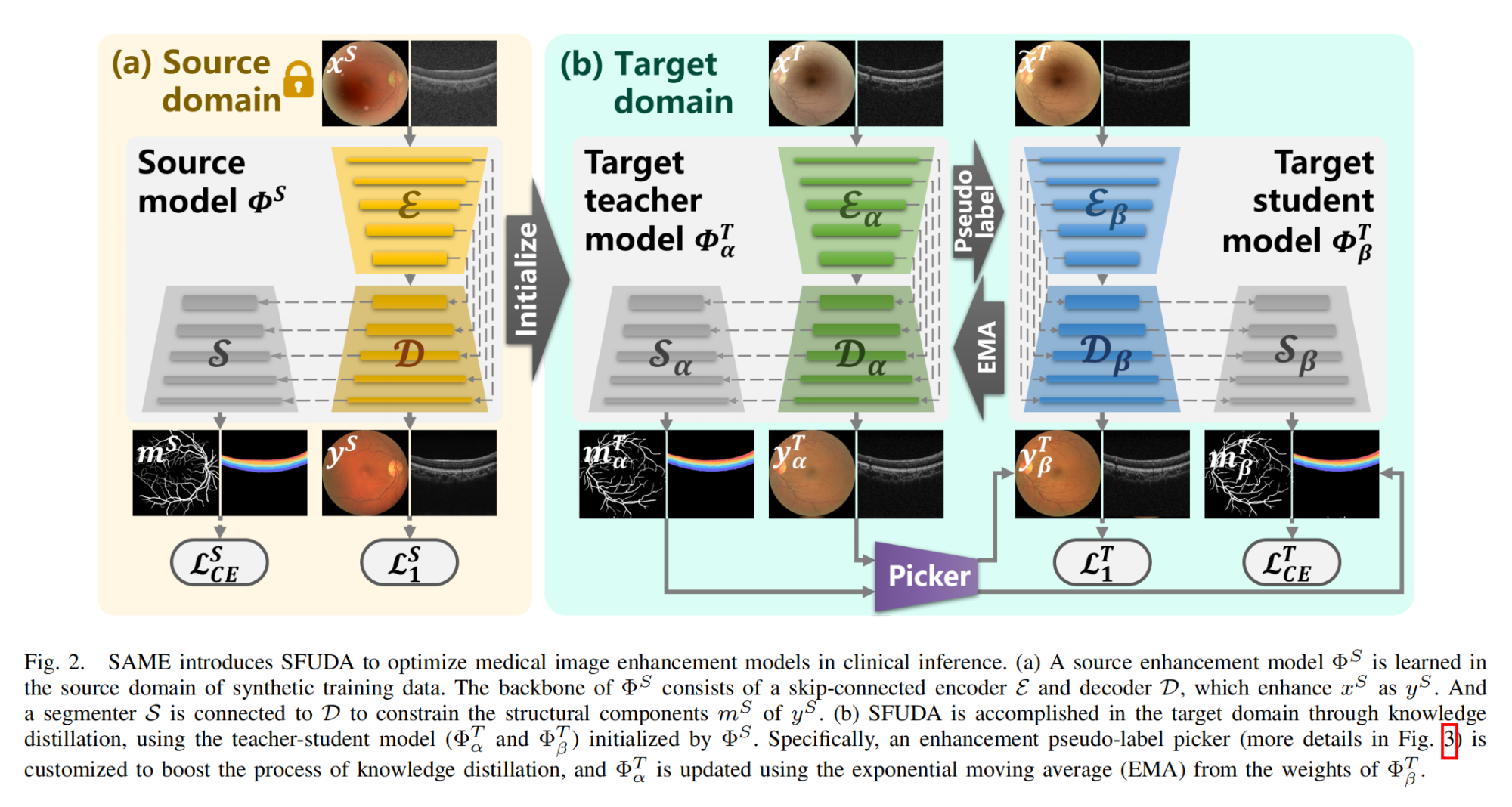
10.【图像增强】Enhancing and Adapting in the Clinic: Source-free Unsupervised Domain Adaptation for Medical Image Enhancement
-
论文地址:https://arxiv.org//pdf/2312.01338
-
开源代码:https://github.com/liamheng/Annotation-free-Medical-Image-Enhancement
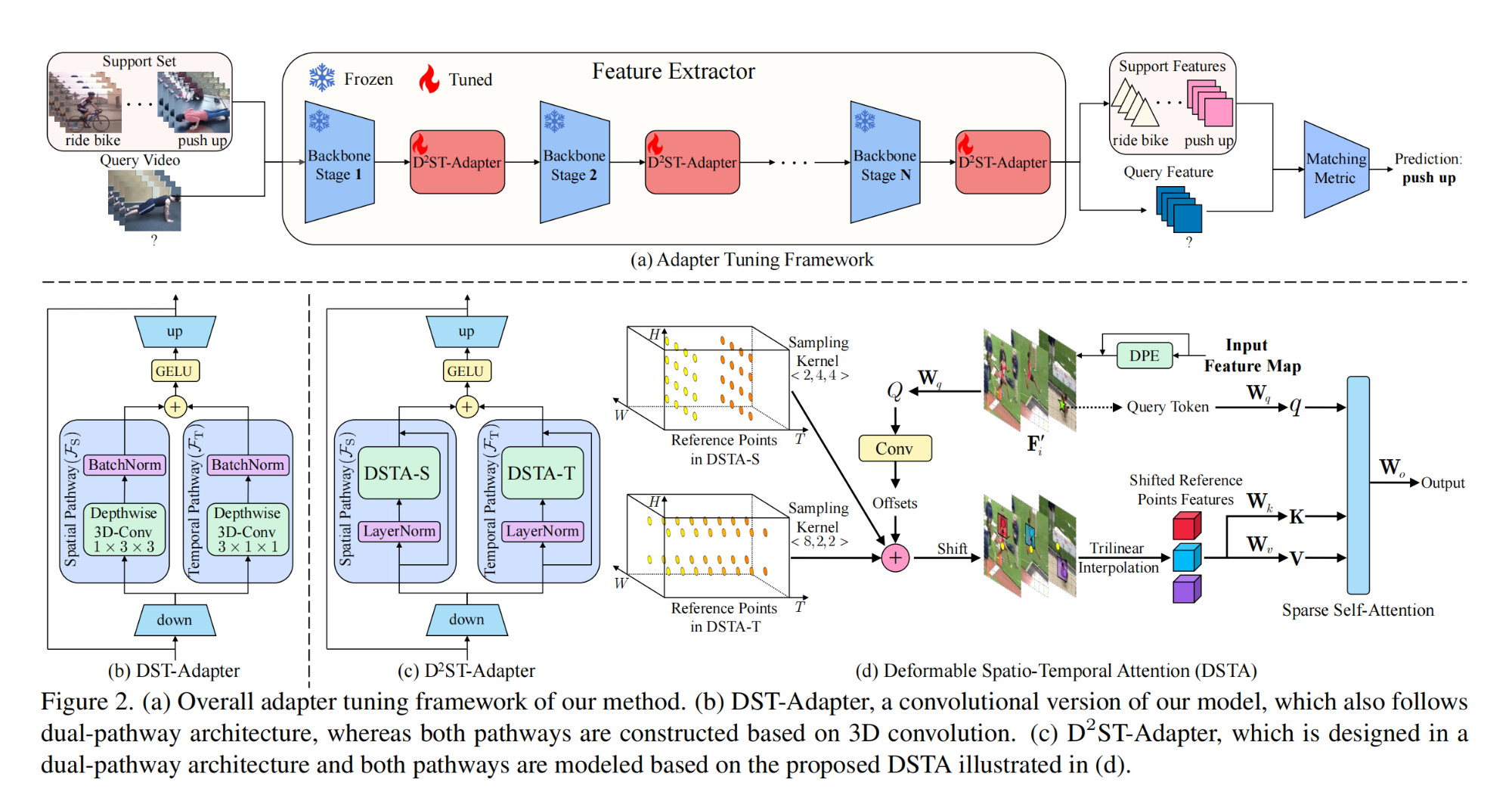
11.【动作识别】DST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
-
论文地址:https://arxiv.org//pdf/2312.01431
-
开源代码(即将开源):https://github.com/qizhongtan/D2ST-Adapter
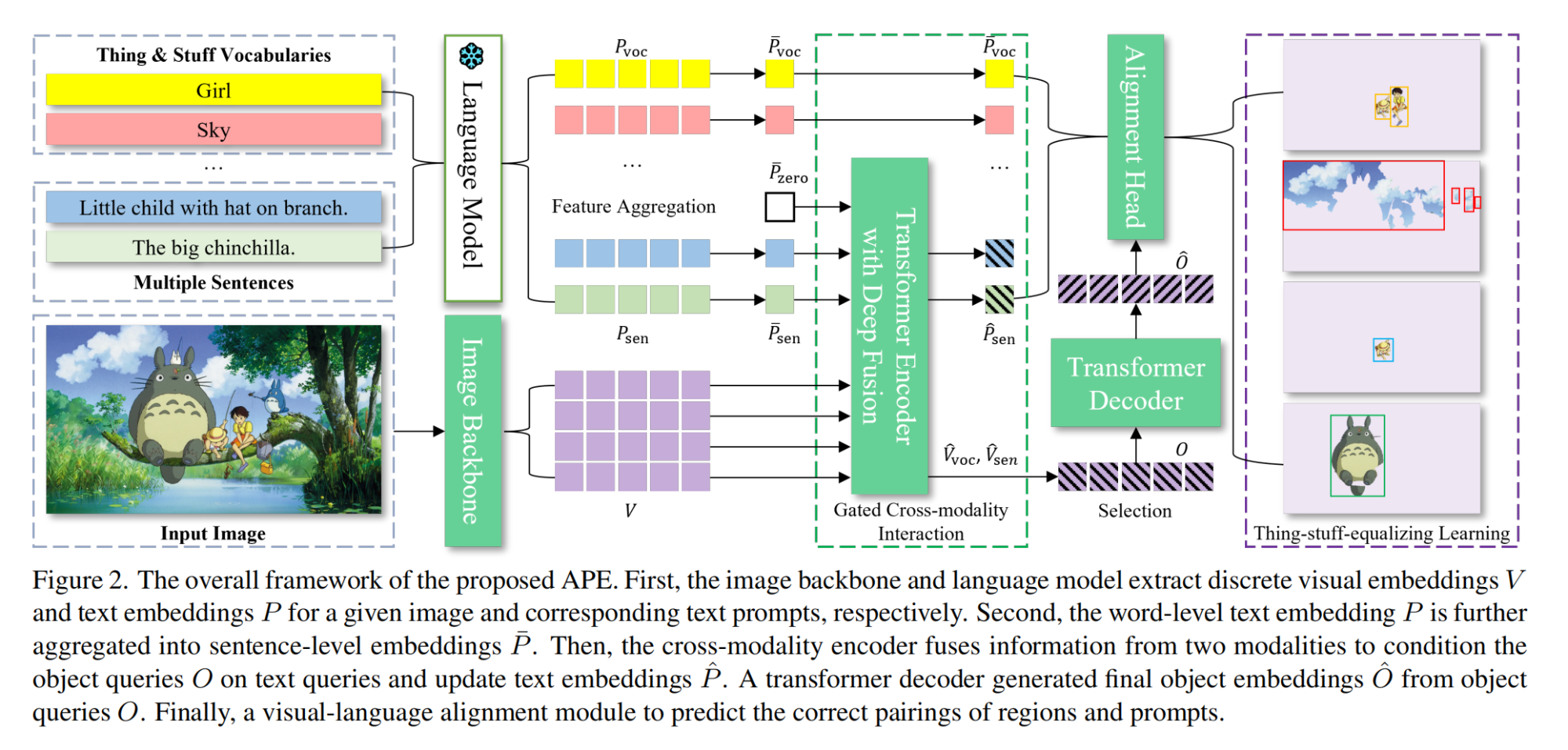
12.【多模态】Aligning and Prompting Everything All at Once for Universal Visual Perception
-
论文地址:https://arxiv.org//pdf/2312.02153
-
开源代码:https://github.com/shenyunhang/APE
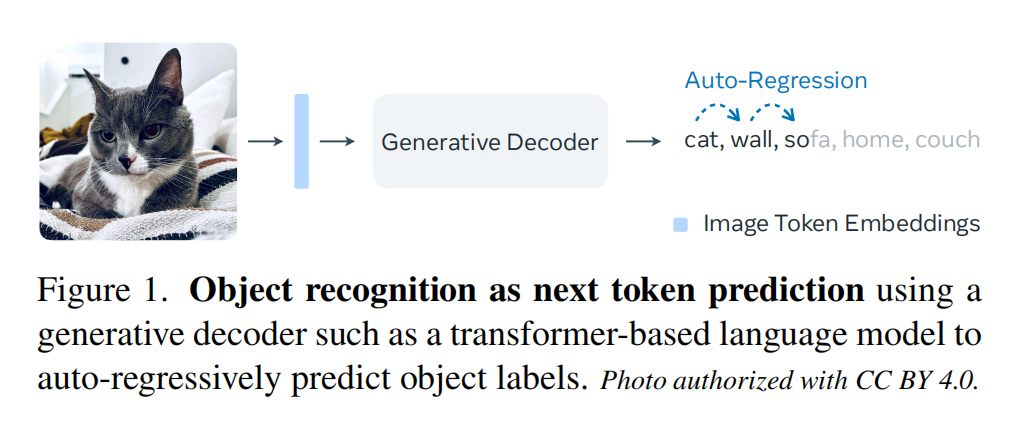
13.【多模态】Object Recognition as Next Token Prediction
-
论文地址:https://arxiv.org//pdf/2312.02142
-
开源代码:https://github.com/kaiyuyue/nxtp
14.【多模态】Mitigating Fine-Grained Hallucination by Fine-Tuning Large Vision-Language Models with Caption Rewrites
-
论文地址:https://arxiv.org//pdf/2312.01701
-
开源代码:https://github.com/Anonymousanoy/FOHE

15.【多模态】Good Questions Help Zero-Shot Image Reasoning
-
论文地址:https://arxiv.org//pdf/2312.01598
-
开源代码:https://github.com/kai-wen-yang/QVix

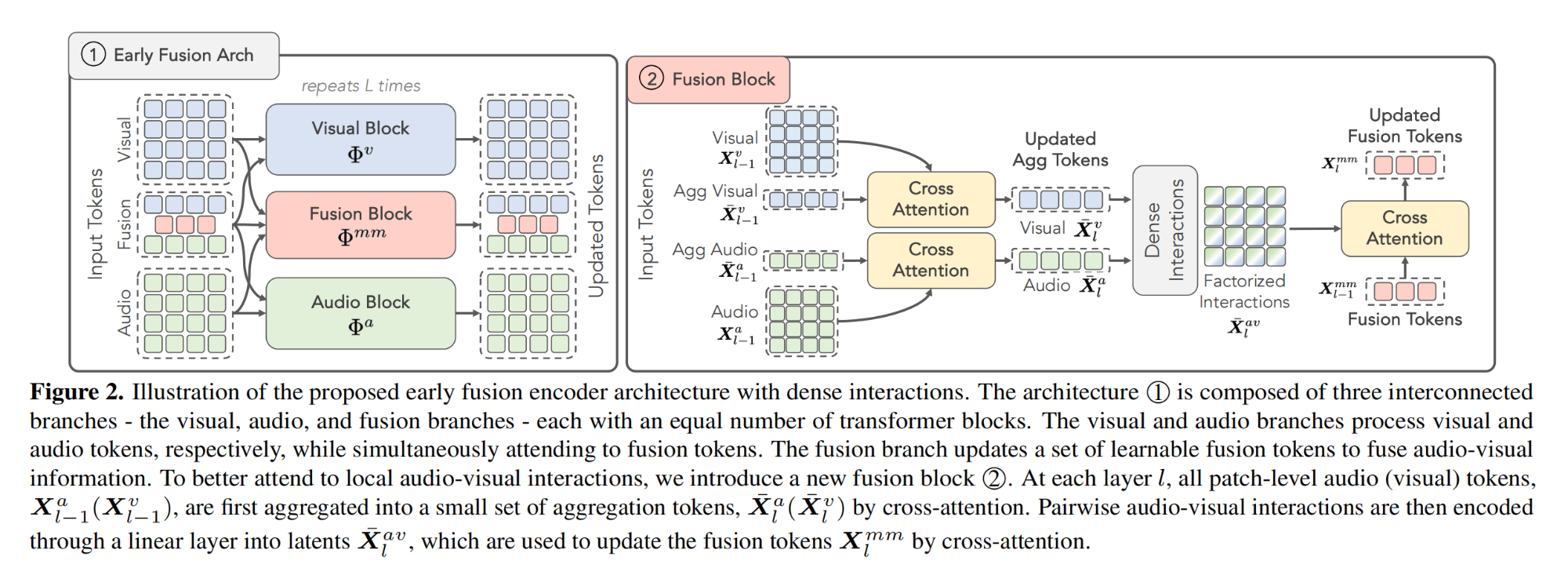
16.【多模态】Unveiling the Power of Audio-Visual Early Fusion Transformers with Dense Interactions through Masked Modeling
-
论文地址:https://arxiv.org//pdf/2312.01017
-
开源代码(即将开源):https://github.com/stoneMo/DeepAVFusion
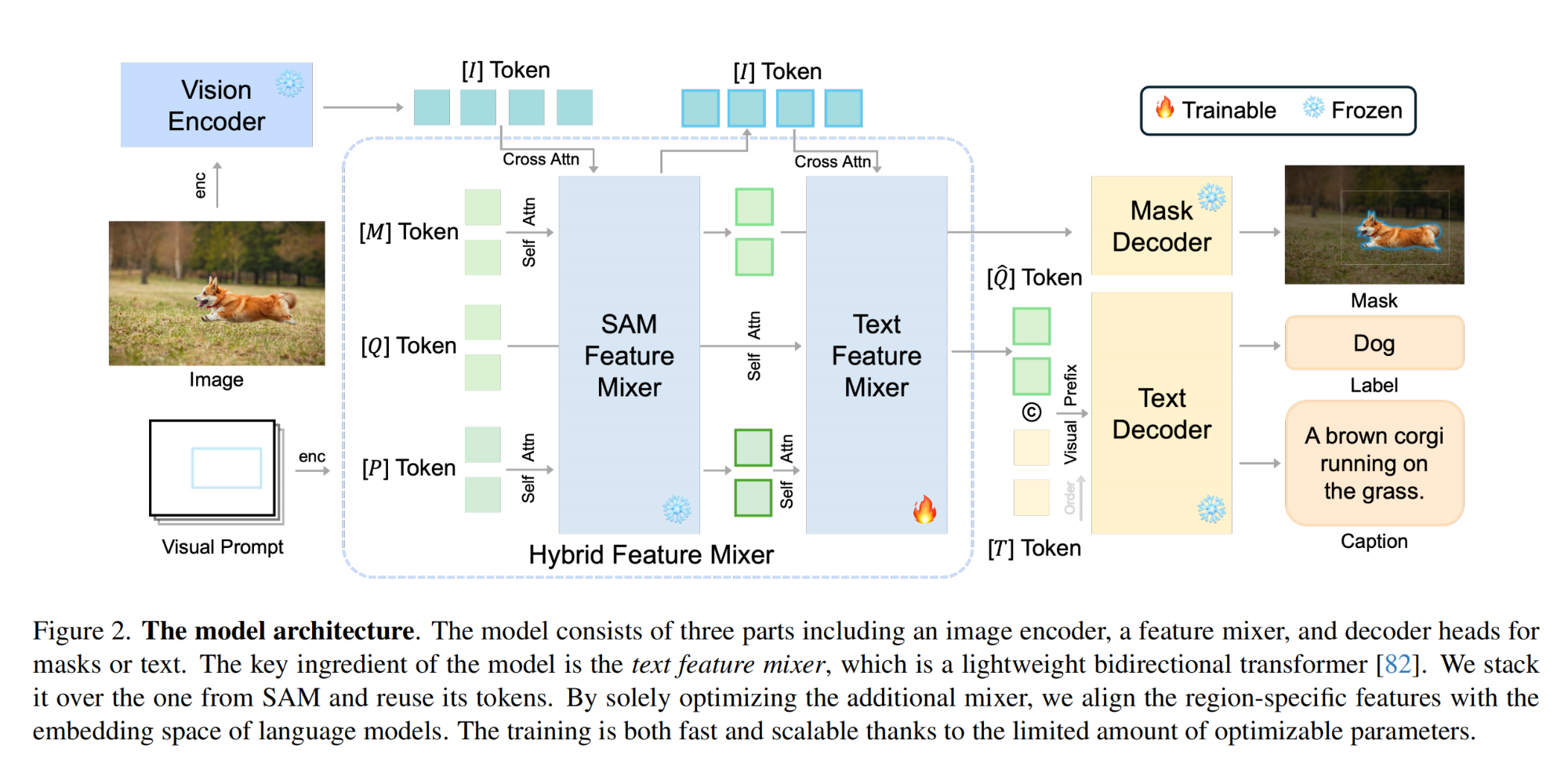
17.【多模态】Segment and Caption Anything
-
论文地址:https://arxiv.org//pdf/2312.00869
-
工程主页:Segment and Caption Anything
-
开源代码:https://github.com/xk-huang/segment-caption-anything
18.【多模态】VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models
-
论文地址:https://arxiv.org//pdf/2312.00845
-
工程主页:VMC
-
开源代码:https://github.com/HyeonHo99/Video-Motion-Customization

19.【多模态】A Challenging Multimodal Video Summary: Simultaneously Extracting and Generating Keyframe-Caption Pairs from Video
-
论文地址:https://arxiv.org//pdf/2312.01575
-
开源代码:https://github.com/keitokudo/Multi-VidSum

20.【数字人】GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
-
论文地址:https://arxiv.org//pdf/2312.02134
-
工程主页:Projectpage of GaussianAvatar
-
开源代码(即将开源):https://github.com/huliangxiao/GaussianAvatar

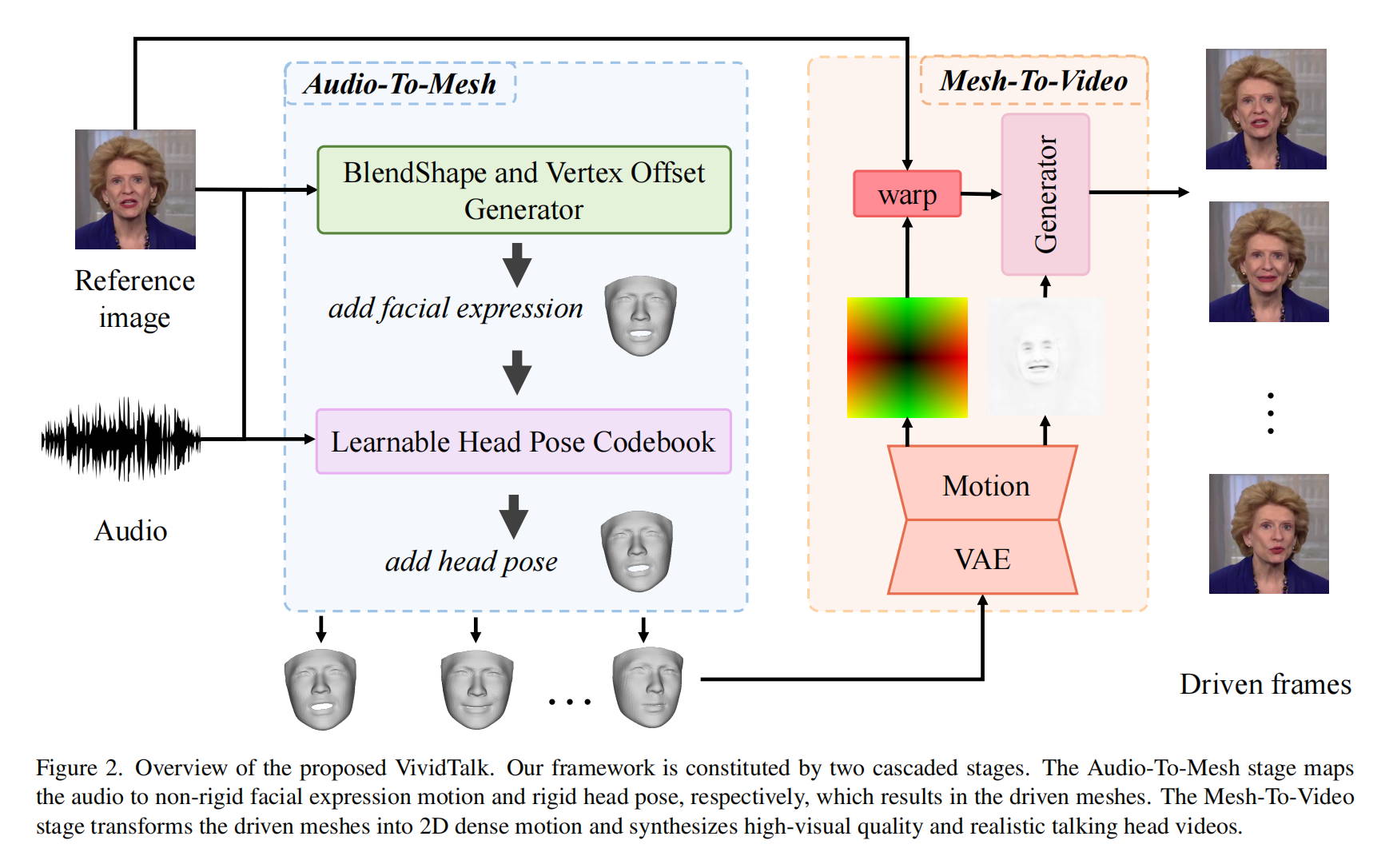
21.【数字人】VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
-
论文地址:https://arxiv.org//pdf/2312.01841
-
工程主页:VividTalk: One-Shot Audio-Driven Talking Head Generation Based 3D Hybrid Prior
-
开源代码(即将开源):https://github.com/HumanAIGC/VividTalk
22.【数字人】3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
-
论文地址:https://arxiv.org//pdf/2312.00870
-
工程主页:3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
-
开源代码(即将开源):https://github.com/bala1144/3DiFACE

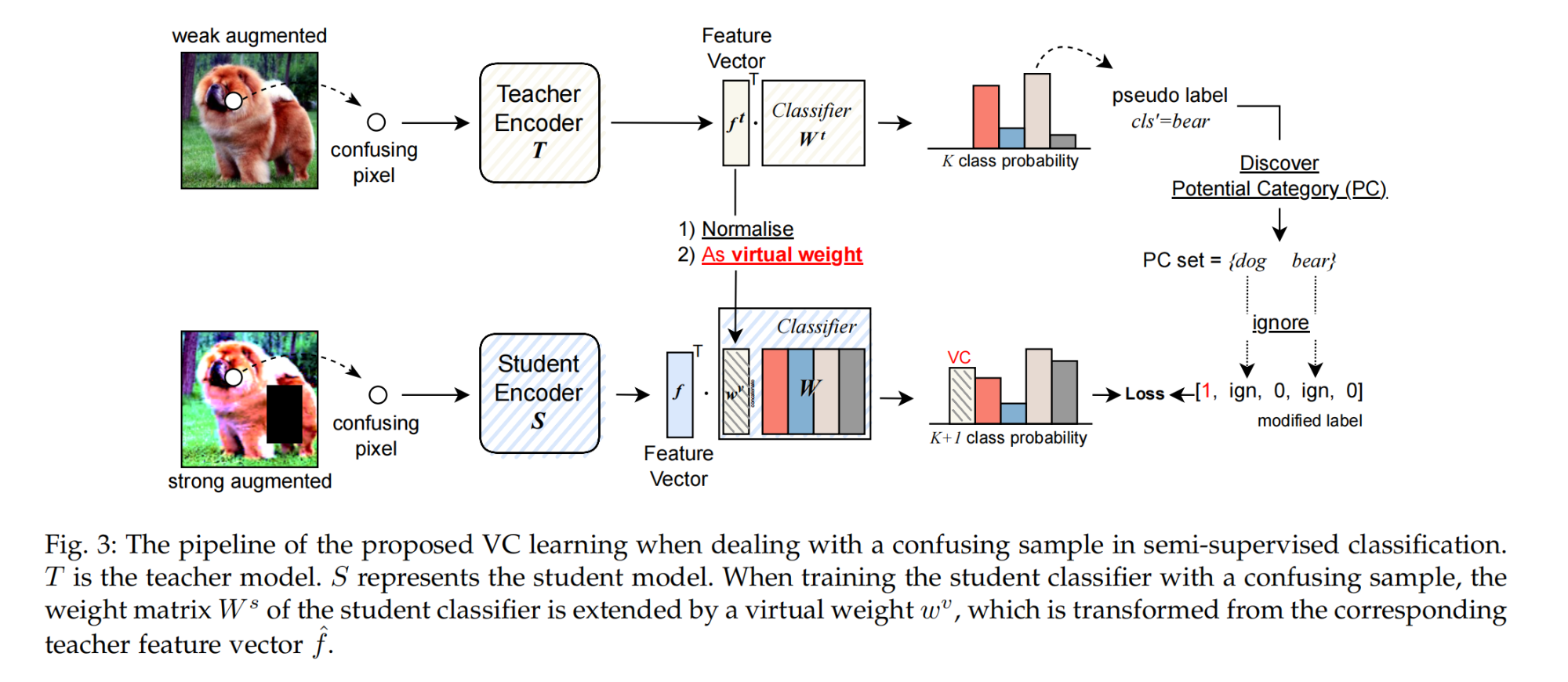
23.【半监督学习】Virtual Category Learning: A Semi-Supervised Learning Method for Dense Prediction with Extremely Limited Labels
-
论文地址:https://arxiv.org//pdf/2312.01169
-
开源代码:https://github.com/GeoffreyChen777/VC
24.【深度估计】Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
-
论文地址:https://arxiv.org//pdf/2312.02145
-
工程主页:Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
-
开源代码:https://github.com/prs-eth/marigold

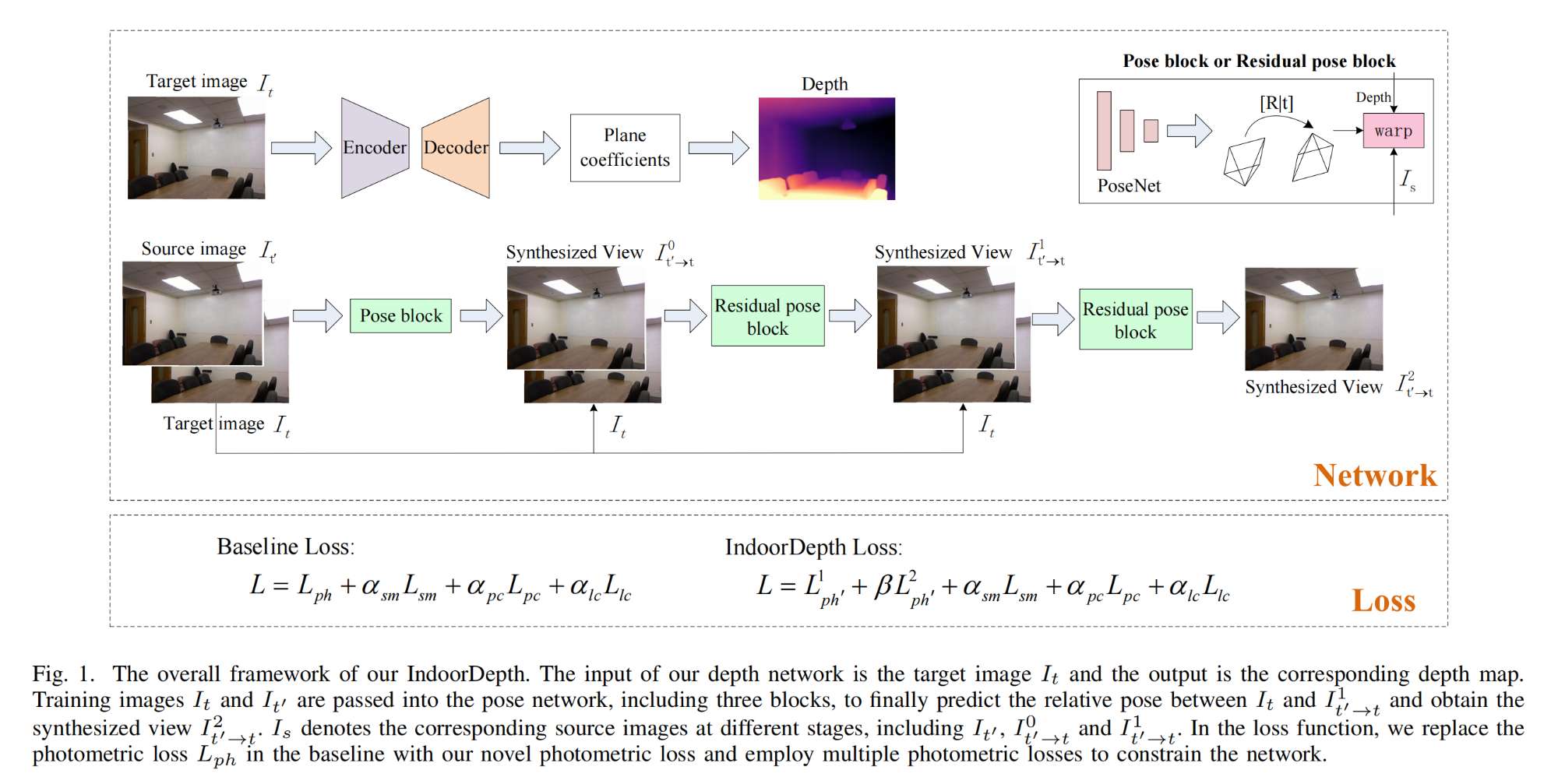
25.【深度估计】Deeper into Self-Supervised Monocular Indoor Depth Estimation
-
论文地址:https://arxiv.org//pdf/2312.01283
-
开源代码:https://github.com/fcntes/IndoorDepth
26.【场景补全】PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
-
论文地址:https://arxiv.org//pdf/2312.02158
-
工程主页:PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
-
开源代码(即将开源):https://github.com/astra-vision/PaSCo
27.【风格迁移】Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
-
论文地址:https://arxiv.org//pdf/2312.01671
-
工程主页:Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
-
代码即将开源
28.【Diffusion】Readout Guidance: Learning Control from Diffusion Features
-
论文地址:https://arxiv.org//pdf/2312.02150
-
工程主页:Readout Guidance: Learning Control from Diffusion Features
-
代码即将开源

29.【Diffusion】ResEnsemble-DDPM: Residual Denoising Diffusion Probabilistic Models for Ensemble Learning
-
论文地址:https://arxiv.org//pdf/2312.01682
-
开源代码(即将开源):https://github.com/nkicsl/ResEnsemble-DDPM
30.【Diffusion】DeepCache: Accelerating Diffusion Models for Free
-
论文地址:https://arxiv.org//pdf/2312.00858
-
开源代码:https://github.com/horseee/DeepCache

31.【网络剪枝】Visual Prompting Upgrades Neural Network Sparsification: A Data-Model Perspective
-
论文地址:https://arxiv.org//pdf/2312.01397
-
开源代码:https://github.com/UNITES-Lab/VPNs
32.【网络剪枝】Physics Inspired Criterion for Pruning-Quantization Joint Learning
-
论文地址:https://arxiv.org//pdf/2312.00851
-
开源代码:https://github.com/fanxxxxyi/PIC-PQ

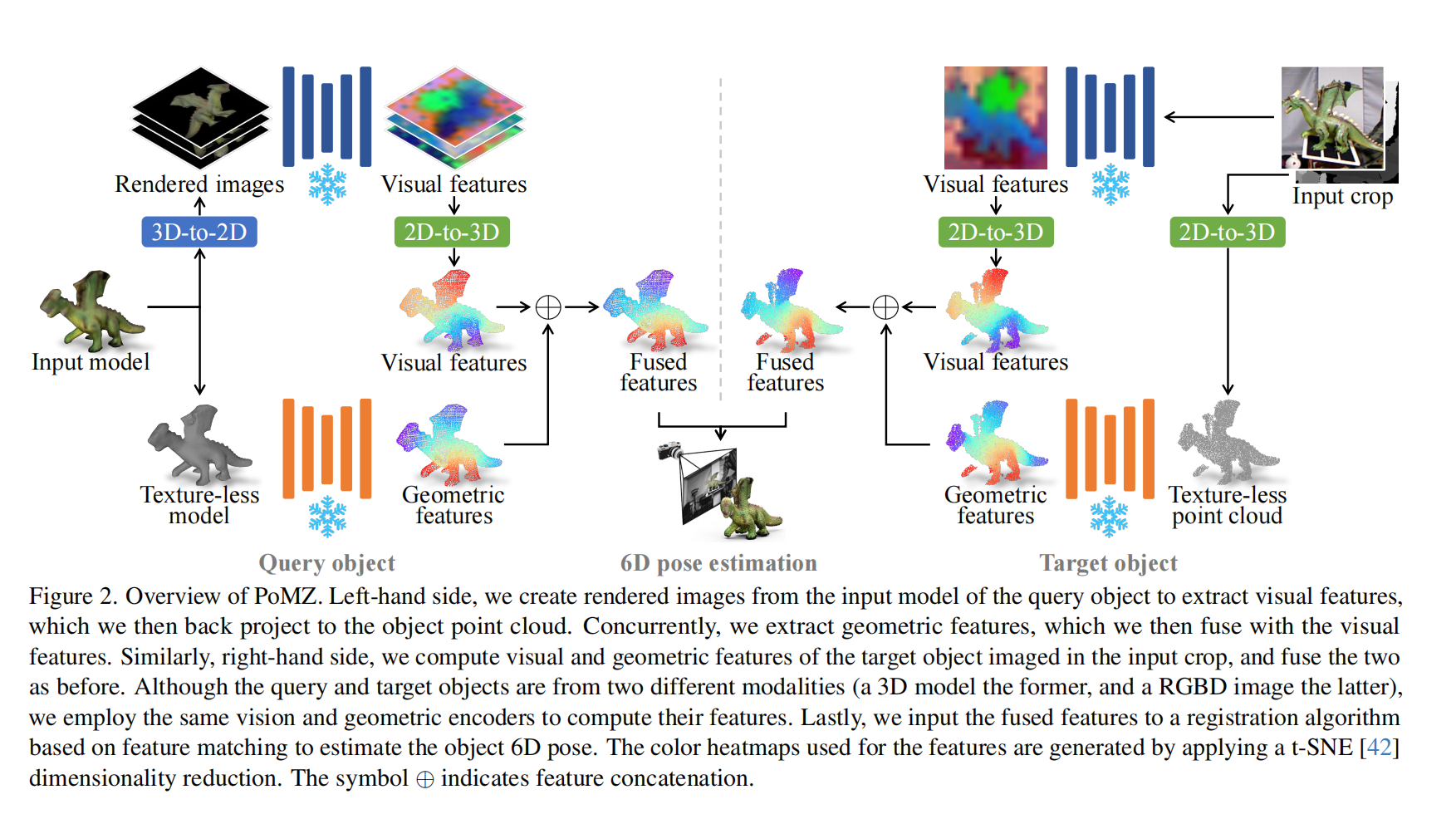
33.【姿态估计】Object 6D pose estimation meets zero-shot learning
-
论文地址:https://arxiv.org//pdf/2312.00947
-
工程主页:PoMZ: Object 6D Pose Estimation Meets Zero-Shot Learning
-
代码即将开源
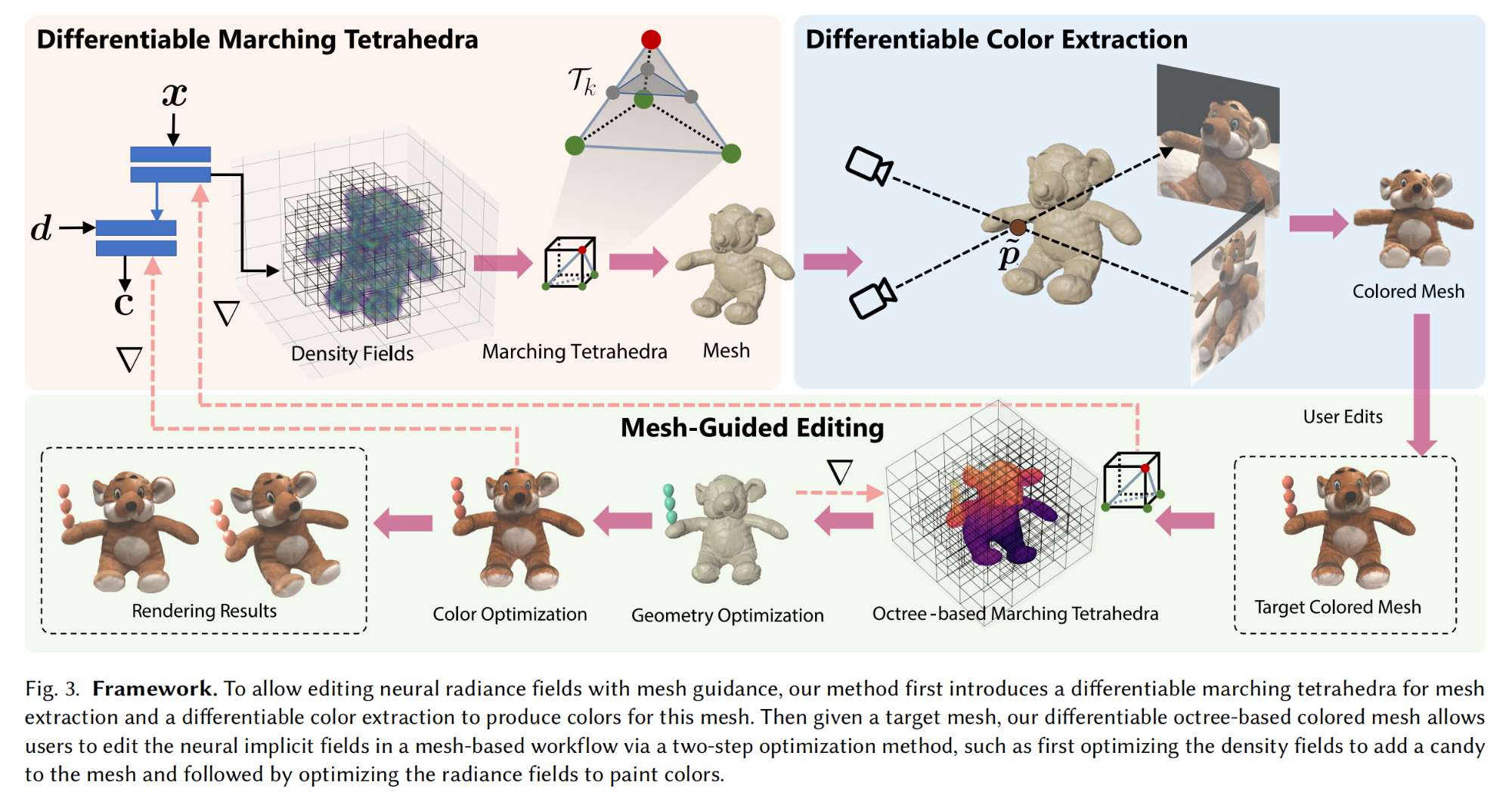
34.【NeRF】Mesh-Guided Neural Implicit Field Editing
-
论文地址:https://arxiv.org//pdf/2312.02157
-
工程主页:Mesh-Guided Neural Implicit Field Editing
-
开源代码(即将开源):https://github.com/cassiePython/MNeuEdit/tree/master
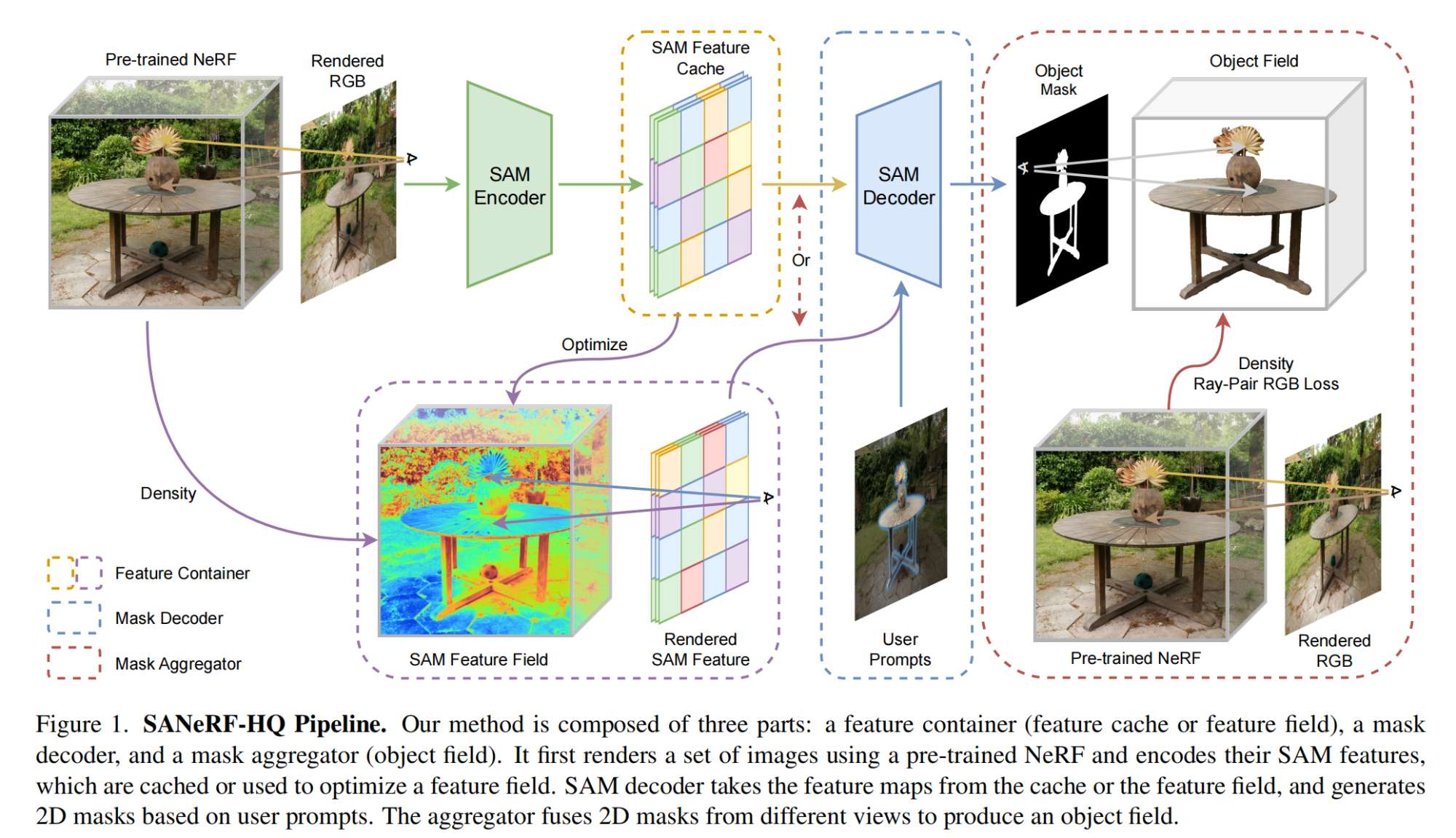
35.【NeRF】SANeRF-HQ: Segment Anything for NeRF in High Quality
-
论文地址:https://arxiv.org//pdf/2312.01531
-
工程主页:SANeRF-HQ
-
开源代码(即将开源):https://github.com/lyclyc52/SANeRF-HQ
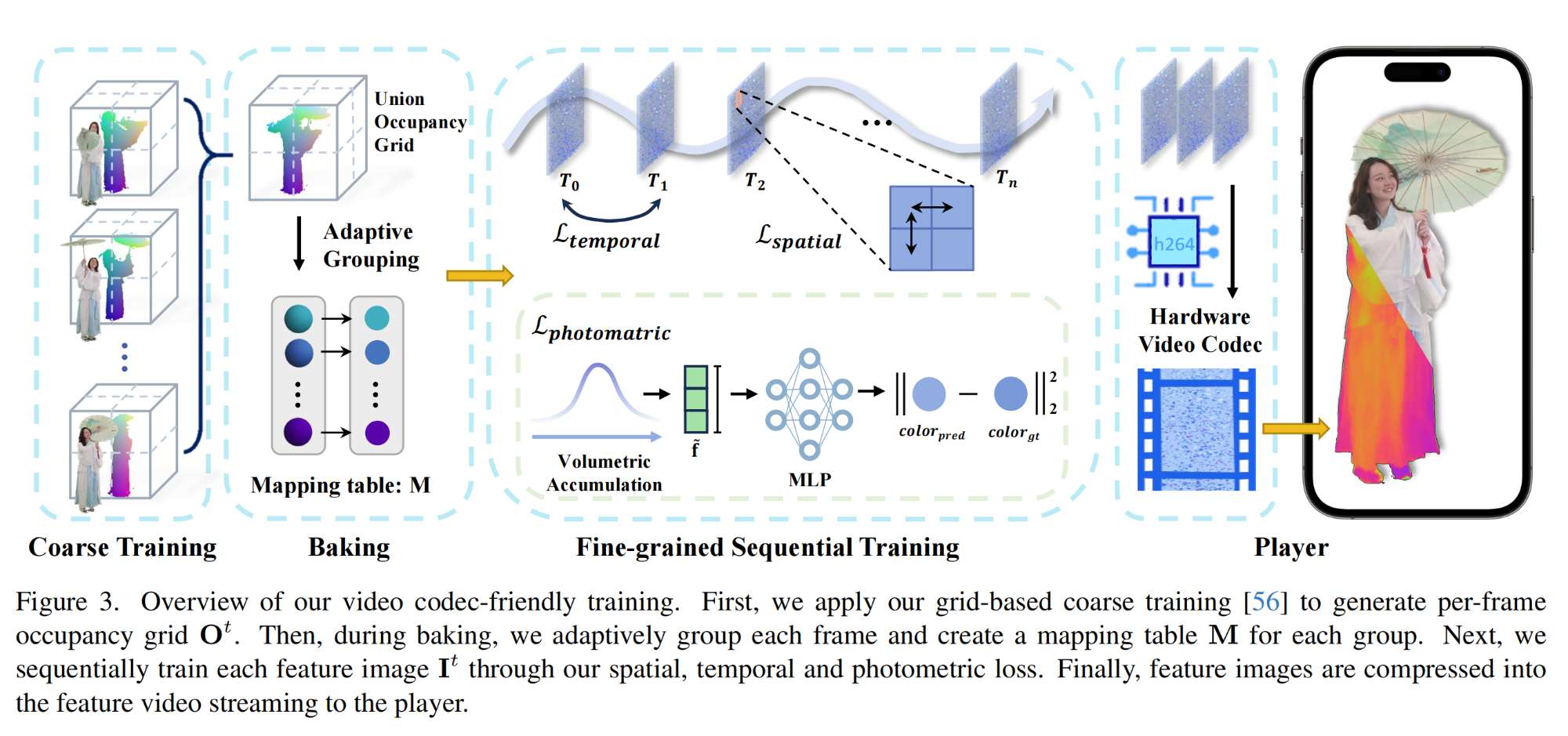
36.【NeRF】VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
-
论文地址:https://arxiv.org//pdf/2312.01407
-
工程主页:VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
-
开源代码(即将开源):https://github.com/aoliao12138/VideoRF
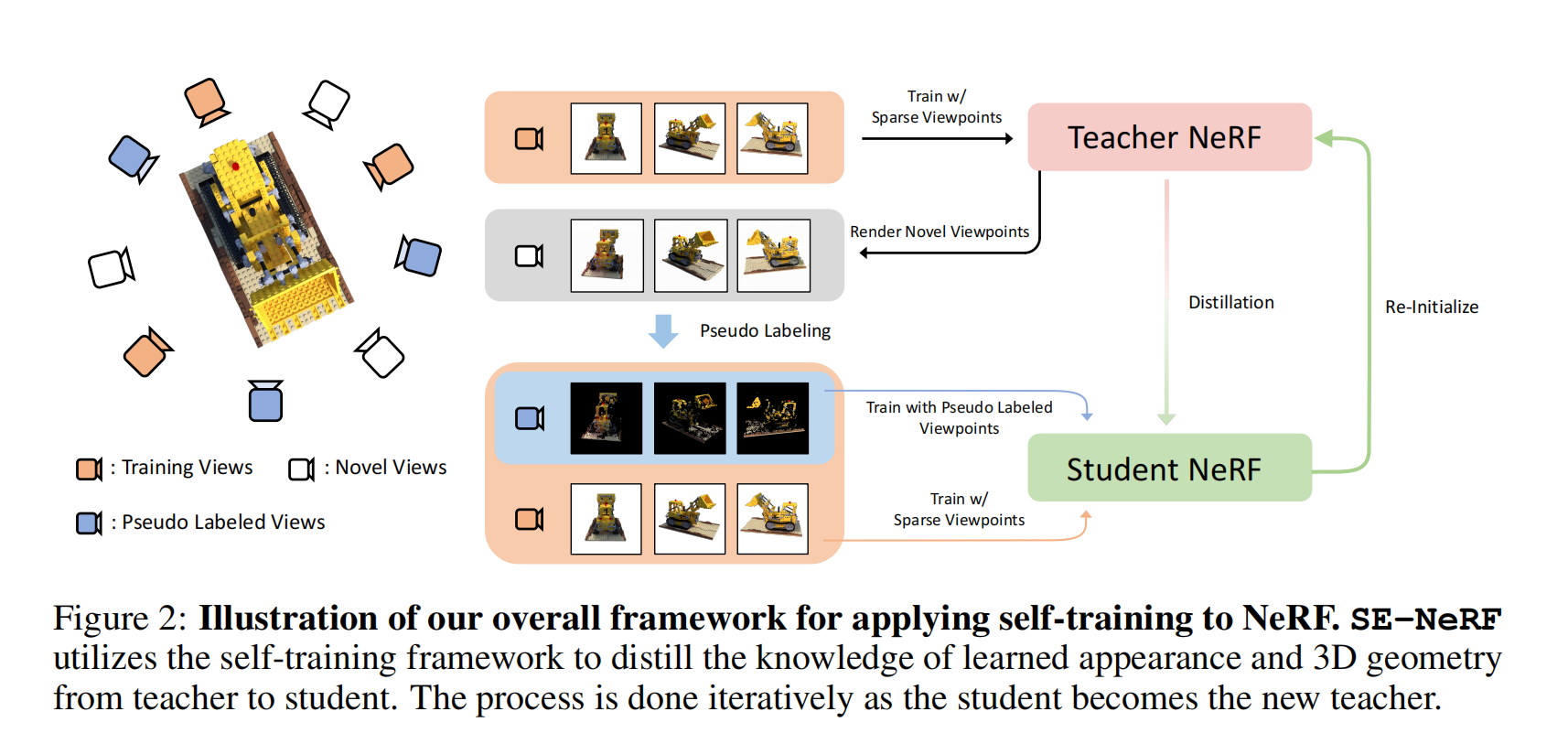
37.【NeRF】Self-Evolving Neural Radiance Fields
-
论文地址:https://arxiv.org//pdf/2312.01003
-
工程主页:SE-NeRF
-
开源代码(即将开源):https://github.com/KU-CVLAB/SE-NeRF
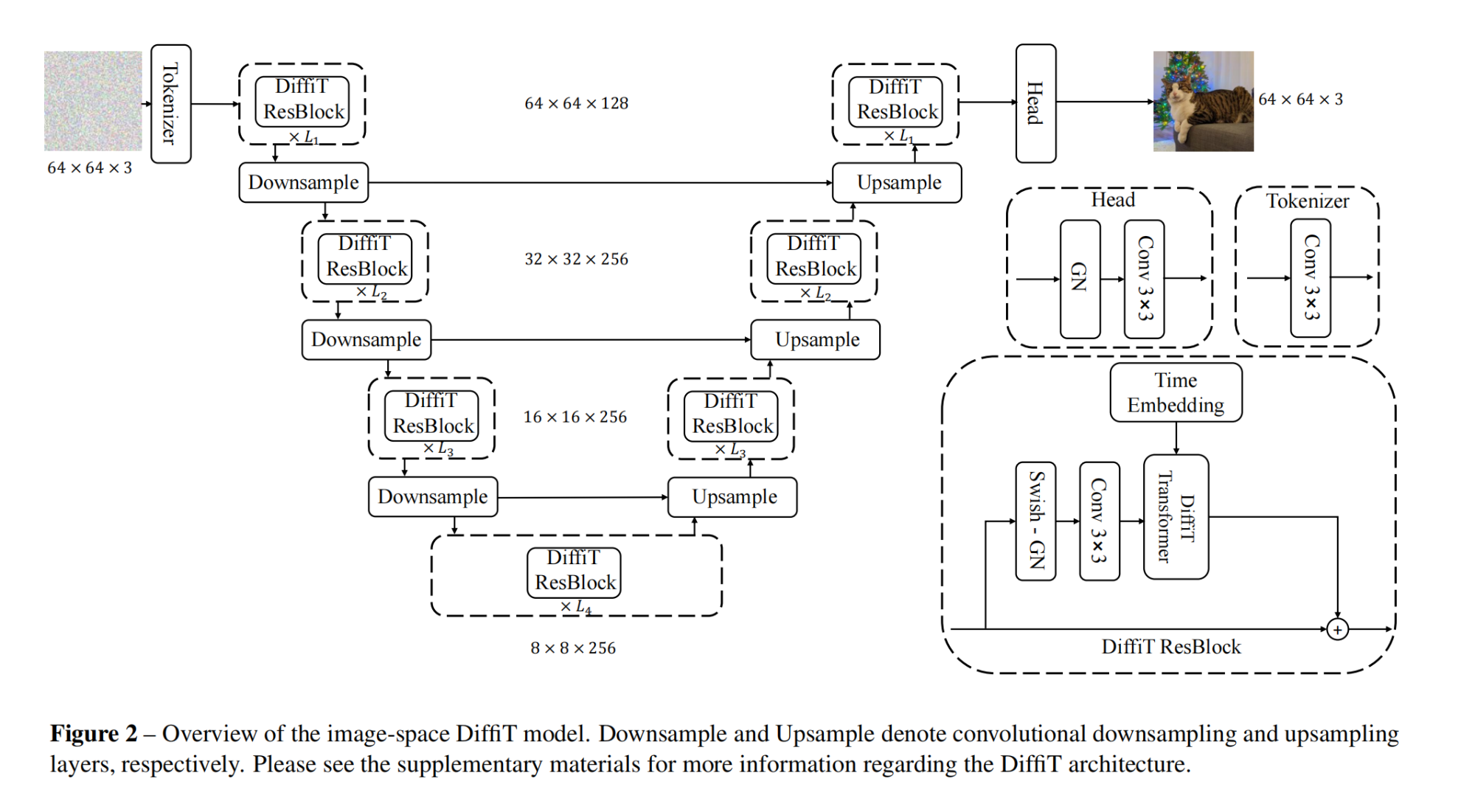
38.【图像合成】DiffiT: Diffusion Vision Transformers for Image Generation
-
论文地址:https://arxiv.org//pdf/2312.02139
-
开源代码:https://github.com/NVlabs/DiffiT
39.【图像合成】Style Aligned Image Generation via Shared Attention
-
论文地址:https://arxiv.org//pdf/2312.02133
-
工程主页:StyleAlign
-
开源代码:https://github.com/google/style-aligned/

40.【人脸重建】DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
-
论文地址:https://arxiv.org//pdf/2312.01068
-
工程主页:DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
-
开源代码(即将开源):https://github.com/tangjiapeng/DPHMs

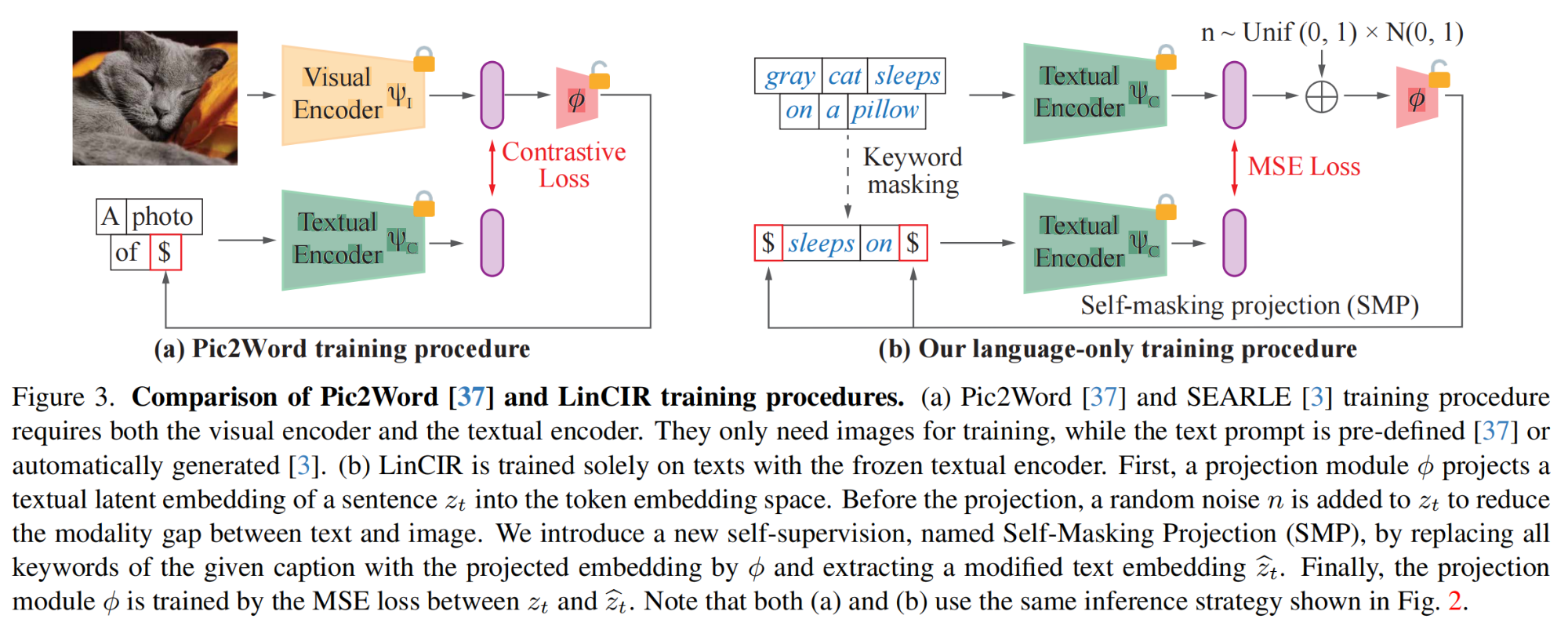
41.【图像检索】Language-only Efficient Training of Zero-shot Composed Image Retrieval
-
论文地址:https://arxiv.org//pdf/2312.01998
-
开源代码:https://github.com/navervision/lincir
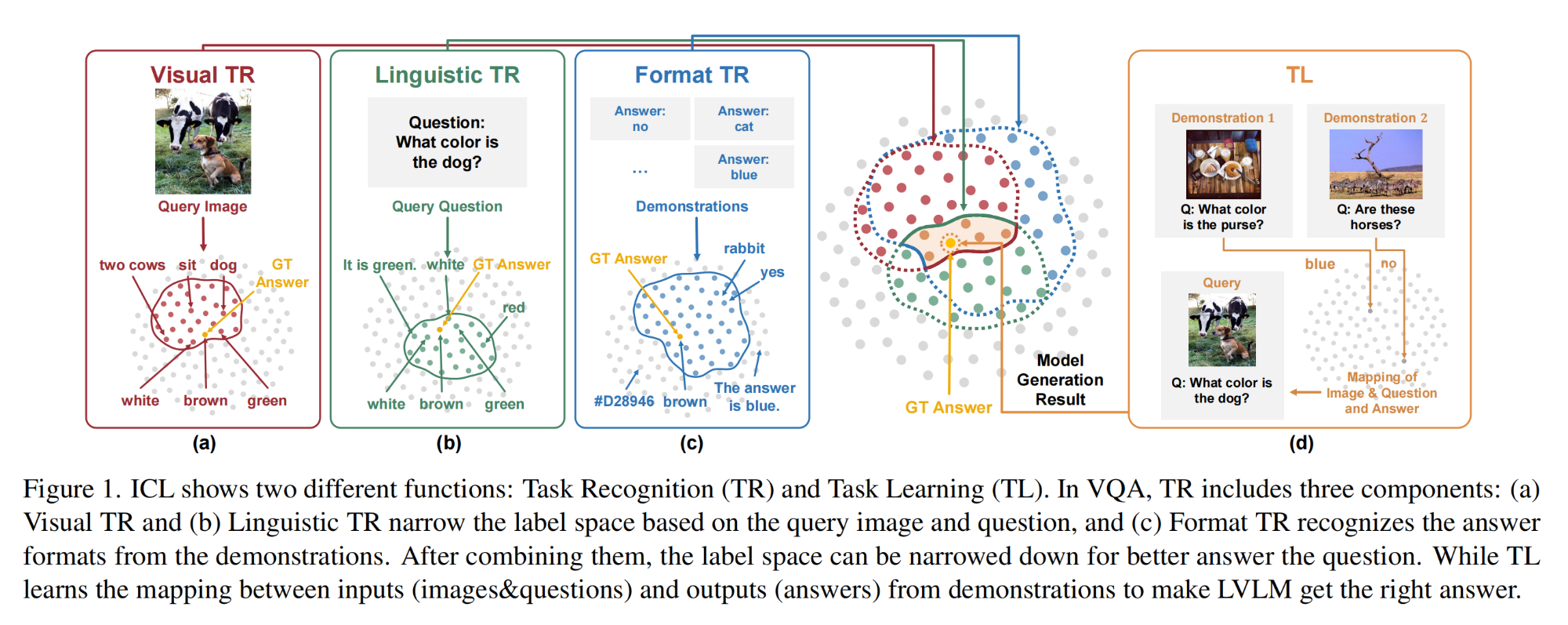
42.【Visual Question Answering】How to Configure Good In-Context Sequence for Visual Question Answering
-
论文地址:https://arxiv.org//pdf/2312.01571
-
开源代码:https://github.com/GaryJiajia/OFv2_ICL_VQA
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.12.5
CV计算机视觉每日开源代码Paper with code速览-2023.12.4
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
相关文章:
CV计算机视觉每日开源代码Paper with code速览-2023.12.6
点击计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【基础网络架构:Transformer】Rejuvenating image-GPT as Strong Visual Representation Learners 论文地址:https://a…...
)
面试经典150题(1-2)
leetcode 150道题 计划花两个月时候刷完,今天完成了两道(1-2)150: (88. 合并两个有序数组)题目描述: 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 n…...
MySQL使用教程
数据构成了我们日益数字化的社会基础。想象一下,从移动应用和银行系统到搜索引擎,再到如 ChatGPT 这样的先进人工智能聊天机器人,这些工具若没有数据支撑,将寸步难行。你有没有好奇过这些海量数据都存放在哪里呢?答案正…...

微服务学习:Ribbon实现客户端负载均衡,将请求分发到多个服务提供者
Ribbon是Netflix开源的一个基于HTTP和TCP客户端负载均衡器。它主要用于在微服务架构中实现客户端负载均衡,将请求分发到多个服务提供者上,从而实现高可用性和扩展性。 Ribbon的主要特点包括: 客户端负载均衡:Ribbon是一个客户端负…...
孩子还是有一颗网安梦——Bandit通关教程:Level0
🕵️♂️ 专栏《解密游戏-Bandit》 🌐 游戏官网: Bandit游戏 🎮 游戏简介: Bandit游戏专为网络安全初学者设计,通过一系列级别挑战玩家,从Level0开始,逐步学习基础命令行和安全概念…...

读excel文件,借助openpyxl工具
读excel文件,借助openpyxl工具 import osimport requestsos.environ["http_proxy"] "http://127.0.0.1:7890" os.environ["https_proxy"] "http://127.0.0.1:7890"base_url "https://testnet.starscan.io/explore…...

ubuntu16.04升级openssl
Ubuntu16.04 默认带的openssl版本为1.0.2 查看:openssl version 1.下载openssl wget https://www.openssl.org/source/openssl-1.1.1.tar.gz 编译安装 tar xvf openssl-1.1.1.tar.gz cd openssl-1.1.1 ./config make sudo make install sudo ldconfig 删除旧版本 su…...

【力扣100】56.合并区间
添加链接描述 class Solution:def merge(self, intervals: List[List[int]]) -> List[List[int]]:# 队列,每次加进来两个元素:1.不包含:第一个元素出去,并放入result;2.包含:合并nlen(intervals)result…...

重磅!2023中国高校计算机大赛-人工智能创意赛结果出炉
目录 中国计算机大赛-人工智能创意赛现场C4-AI大赛颁奖及留影800个AI应用?这届大学生真能“搞事情”AI原生时代,百度要再培养500万大模型人才 中国计算机大赛-人工智能创意赛现场 12月8日,杭州,一位“白发老人”突然摔倒在地&…...
[Linux] 用LNMP网站框架搭建论坛
一、nginx在其中工作原理 原理: php-fpm.conf是控制php-fpm守护进程 它是php.ini是一个php解析器 工作过程: 1.当客户端通过域名请求访问时,Nginx会找到对应的虚拟主机 2. Nginx将确定请求。 对于静态请求,Nginx会自行处理…...
记录 | 使用samba将ubuntu文件夹映射到windows实现共享文件夹
一、ubuntu配置 1. 安装 samba samba 是在 Linux 和 UNIX 系统上实现 SMB 协议的一个免费软件,由服务器及客户端程序构成。SMB(Server Messages Block,信息服务块)是一种在局域网上共享文件和打印机的一种通信协议。 sudo apt-…...
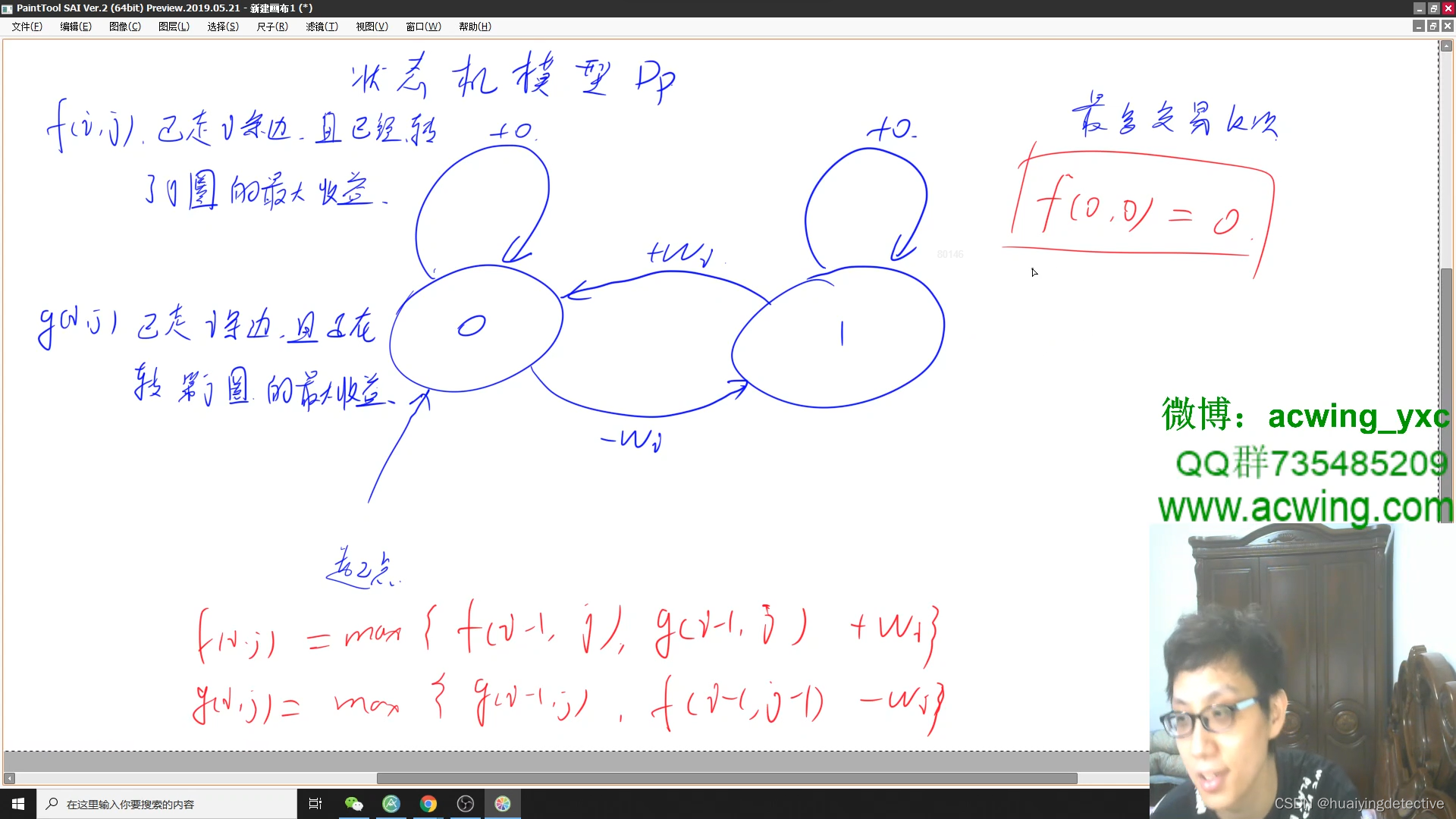
leetcode 股票DP系列 总结篇
121. 买卖股票的最佳时机 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。 只能进行一次交易 很简单,只需边遍历边记录最小值即可。 class Solution { public:int maxProfit(vector<int>& prices) {int res …...

深入理解Java虚拟机---对象的创建和内存异常溢出
深入理解Java虚拟机---对象的创建和内存异常溢出 对象的创建对象内存布局对象的访问定位内存溢出Java堆溢出虚拟机栈和本地方法栈溢出方法区和运行时常量池溢出本地直接内存溢出 对象的创建 Step1:虚拟机遇到一条new指令时,首先将去检查这个指令的参数是…...
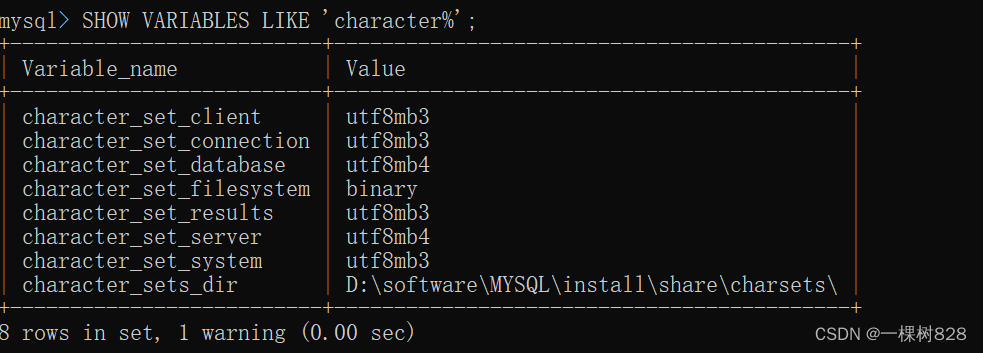
windows MYSQL解决中文乱码问题
1.首先确保你已经把mysql配置了环境变量 2.打开window终端 3.输入mysql -u root -p 4.输入密码,就是安装的时候设置的root超级管理员权限密码 5.输入: SHOW VARIABLES LIKE ‘character%’; 出现上图,说明就会出现中文乱码问题。 6.该怎么办…...

EasyRecovery2024免费永久版手机数据恢复软件
EasyRecovery2024是一款操作安全、用户可自主操作的数据恢复方案,它支持从各种各样的存储介质恢复删除或者丢失的文件,其支持的媒体介质包括:硬盘驱动器、光驱、闪存、硬盘、光盘、U盘/移动硬盘、数码相机、手机以及其它多媒体移动设备。能恢…...
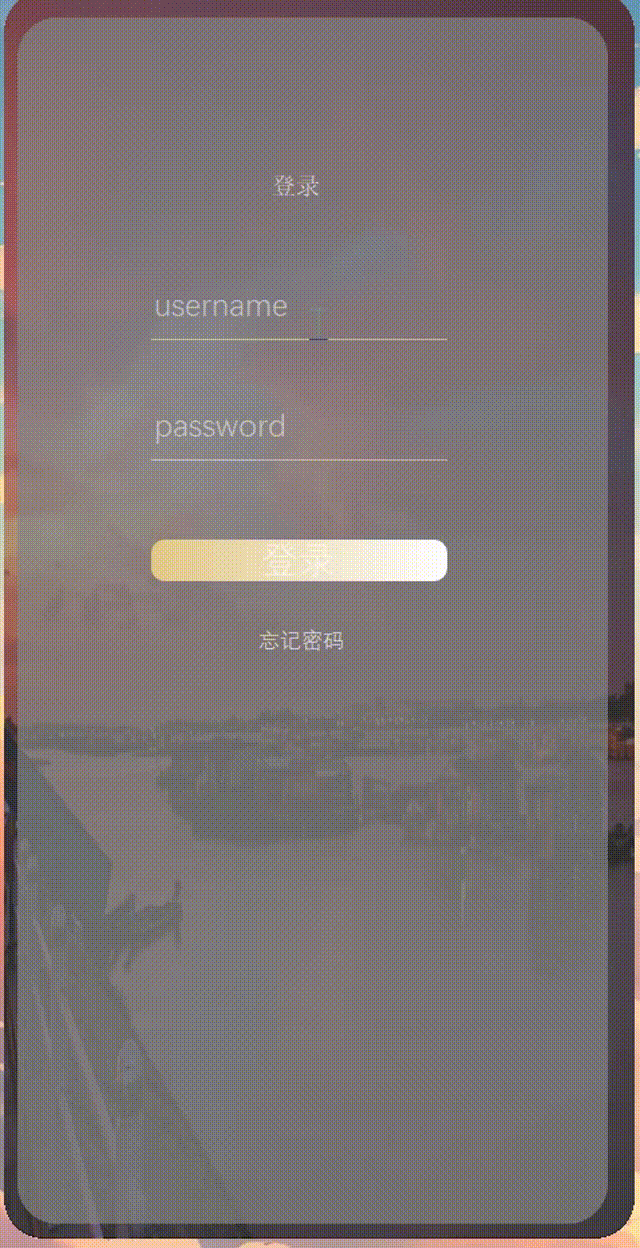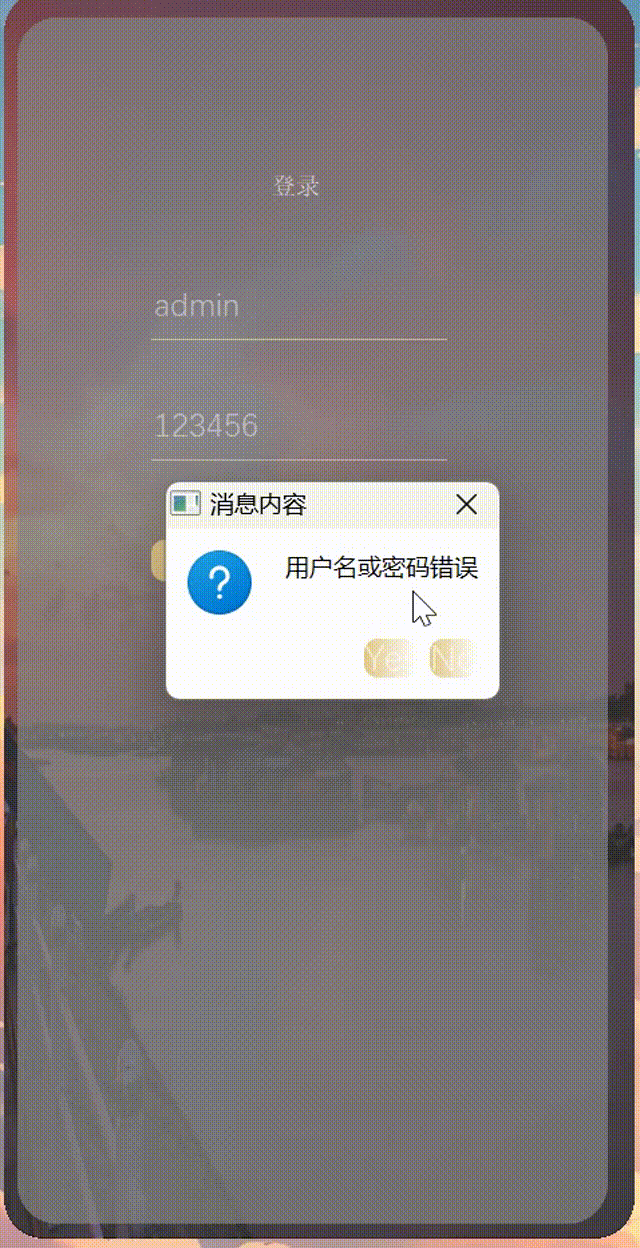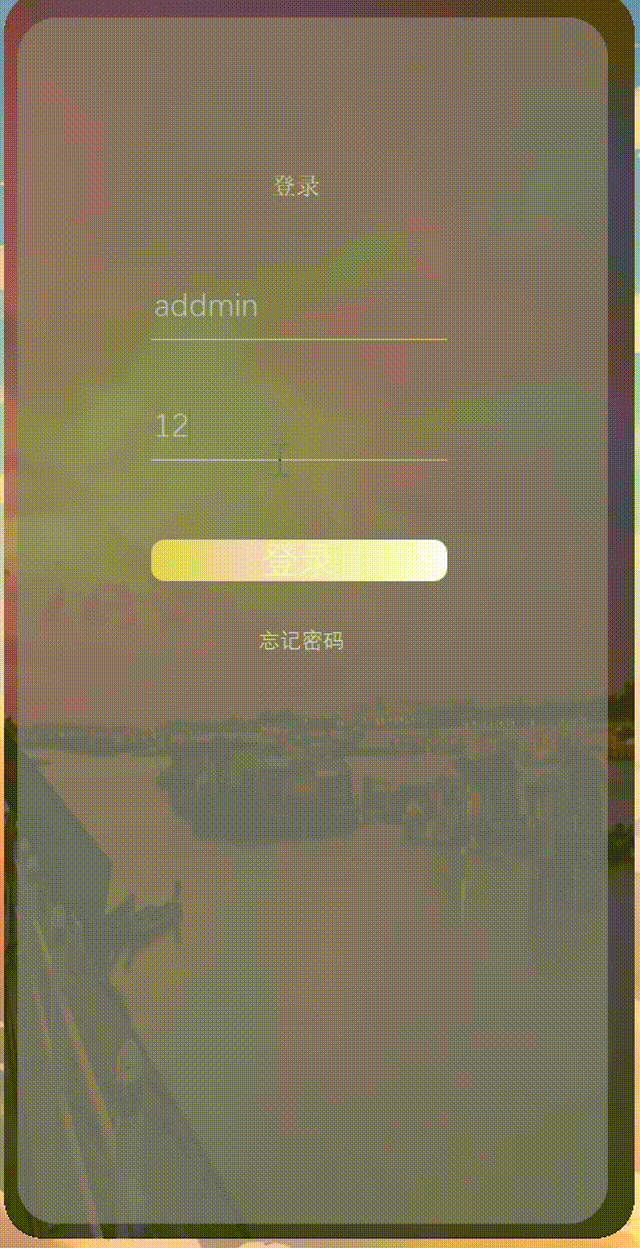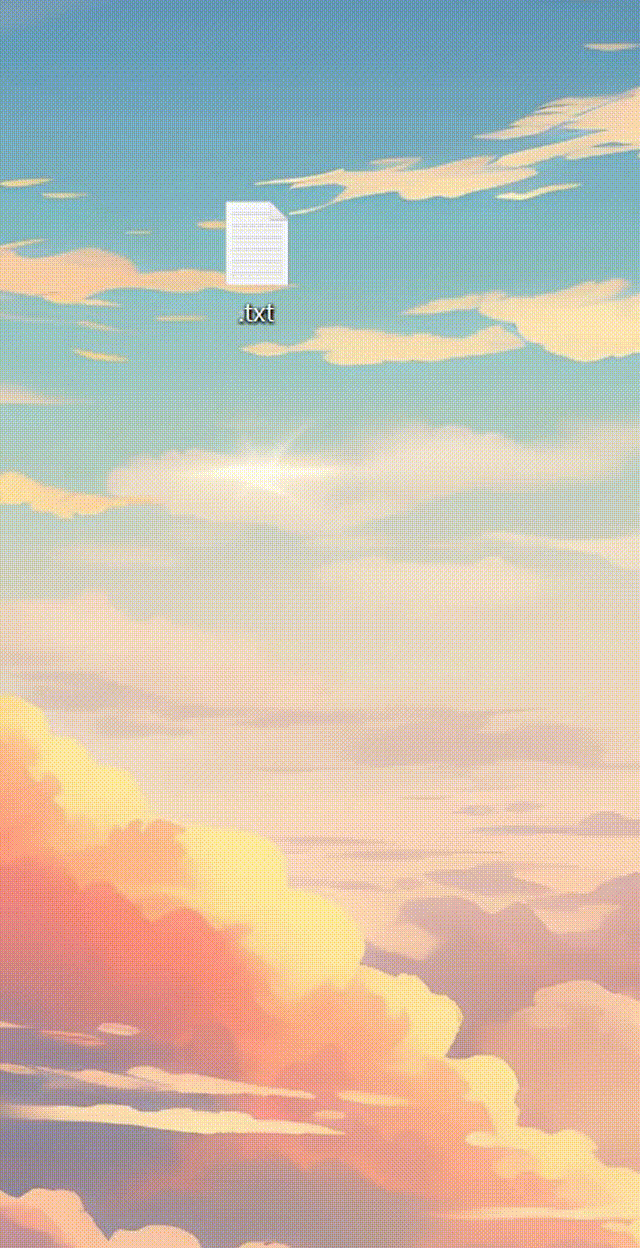
2023/12/11 作业
1.思维导图 2.作业 成果: 第一个头文件 #ifndef TEST3GET_H #define TEST3GET_H #include <QWidget> #include<QMessageBox> QT_BEGIN_NAMESPACE namespace Ui { class test3get; } QT_END_NAMESPACE class test3get : public QWidget { Q_OBJE…...
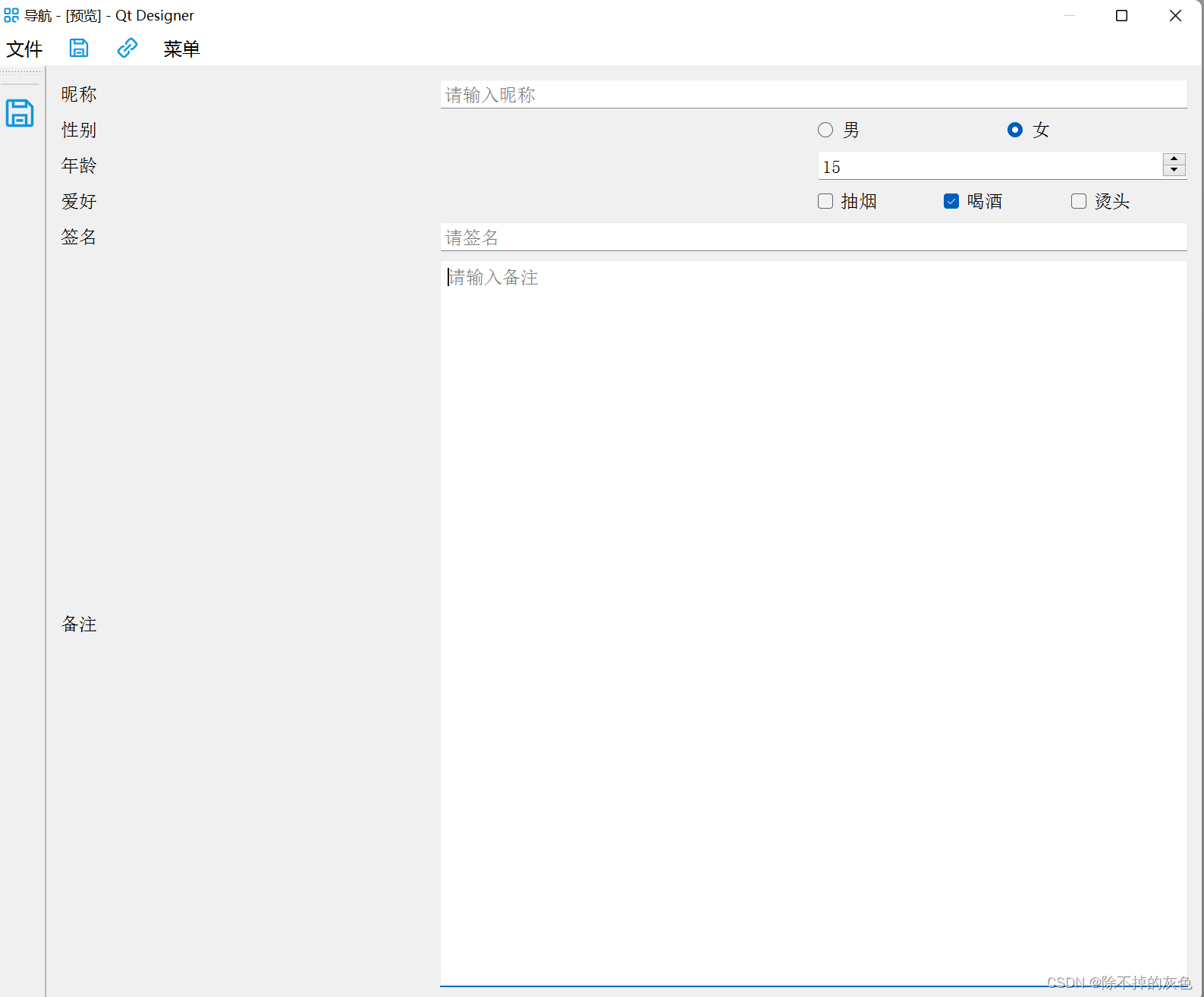
【11】Qt Designer
目录 VSCode添加外部工具 QtDesigner PyUIC PyRCC 加载UI文件模板代码 QMainWindow QWidget 常用知识点 1. 修改标题图标 2. 图片资源管理 3. 图片按钮 4. 加载对话框 5. 动态加载Widget 6. 修改主题 其他注意事项 事件被多次触发 PyQt5提供了一个可视化图形工…...
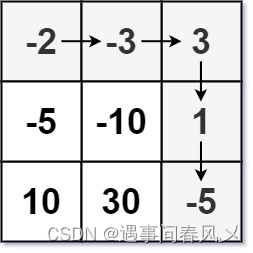
【算法优选】 动态规划之路径问题——贰
文章目录 🎋前言🌲[下降最小路径和](https://leetcode.cn/problems/minimum-path-sum/)🚩题目描述🚩算法思路:🚩代码实现 🎍[最小路径和](https://leetcode.cn/problems/minimum-path-sum/)&…...

从视频中截取指定帧图片
前言: 我们在很多时候需要对视频文件进行分析,或者对视频产生缩略图。因此视频截取技术必不可少。 从本地文件中读取视频帧 导包 <dependency><groupId>org.jcodec</groupId><artifactId>jcodec</artifactId><versio…...
全套教程2023年12月最新)
2023最新vue安装(npm,yarn,国内镜像,vue安装,vue导包)全套教程2023年12月最新
第一步(安装npm) 官网地址:https://nodejs.org/en/download windows安装yarn 详细教程_windows yarn-CSDN博客 第二步(yarn下载) windows 下需要下载msi文件 ,下载地址:https://yarnpkg.com/latest.msi npm install -g…...

实测分享:电脑端专业金价查看软件 AnyGold,办公盯盘两不误
作为经常关注黄金行情的开发者与上班族,日常总被浏览器反复刷新、网页卡顿、广告弹窗、数据分散等问题困扰。最近试用了 AnyGold 这款电脑端金价查看工具,连续使用两周,整体体验稳定、轻量、实用。下面以纯实测角度,客观讲讲它的功…...

5分钟部署大麦抢票助手:告别手动刷票的智能解决方案
5分钟部署大麦抢票助手:告别手动刷票的智能解决方案 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 在热门演唱会门票秒光的时代,手动刷新抢票已经成为历史。DamaiHelper大…...

RCS 核心系统架构:AGV 调度“大脑”的底层逻辑
在现代智能物流与制造系统中,RCS(Robot Control System)作为 AGV 集群的核心调度中枢,扮演着"智慧大脑"的关键角色。不同于单台 AGV 的自主导航,RCS 需要解决多车协同、任务分配、路径规划与冲突避免等复杂问…...

会议纪要秒变问答库!WeKnora即时知识系统实战教程
会议纪要秒变问答库!WeKnora即时知识系统实战教程 1. 为什么你需要一个"不跑题"的会议助手? 想象这些常见的工作场景: 项目复盘会上,有人问"三个月前那次迭代的排期是怎样的?",所有…...
)
告别命令行!用wxPython+wxFormBuilder给Python脚本做个Windows桌面GUI界面(附完整代码)
告别命令行!用wxPythonwxFormBuilder给Python脚本做个Windows桌面GUI界面(附完整代码) 每次写完一个实用的Python脚本,比如数据爬虫、自动化工具或者数据处理程序,总会遇到一个尴尬的问题——怎么让不懂命令行的同事或…...

vite-plugin-federation实战:构建React+Vue混合应用完整教程
vite-plugin-federation实战:构建ReactVue混合应用完整教程 【免费下载链接】vite-plugin-federation Module Federation for vite & rollup 项目地址: https://gitcode.com/gh_mirrors/vi/vite-plugin-federation 想要在Vite项目中实现模块联邦…...
)
终极指南:如何使用Ohm构建JavaScript解释器(10个完整步骤)
终极指南:如何使用Ohm构建JavaScript解释器(10个完整步骤) 【免费下载链接】ohm A library and language for building parsers, interpreters, compilers, etc. 项目地址: https://gitcode.com/gh_mirrors/oh/ohm Ohm是一个强大的解析…...
Laravel Stats Tracker设备检测技术解析:精准识别移动端与桌面端
Laravel Stats Tracker设备检测技术解析:精准识别移动端与桌面端 【免费下载链接】tracker Laravel Stats Tracker 项目地址: https://gitcode.com/gh_mirrors/tr/tracker Laravel Stats Tracker是一款强大的Laravel统计跟踪工具,它提供了精准的设…...
lite-avatar形象库效果展示:教师数字人在直播授课场景中的眼神交互与手势模拟
lite-avatar形象库效果展示:教师数字人在直播授课场景中的眼神交互与手势模拟 1. 引言:当数字人老师走进直播间 想象一下,你正在准备一场面向数千名学生的在线直播课。除了精心准备的课件和讲稿,你还需要一个能清晰传达知识、与…...

PCIe AVIP架构
验证工程师可以用C语言接口快速实现仿真加速。C实现的仿真文件testbench可以直接访问AVIP,与总线功能模块BFM交换数据。PCIe AVIP的C接口就是一组C类;C程序或工具可以调用这些类的方法。C类可以实现如下功能:与BFM建立通信;向BFM发…...