Pytorch-Transformer轴承故障一维信号分类(三)
目录
前言
1 数据集制作与加载
1.1 导入数据
第一步,导入十分类数据
第二步,读取MAT文件驱动端数据
第三步,制作数据集
第四步,制作训练集和标签
1.2 数据加载,训练数据、测试数据分组,数据分batch
2 Transformer分类模型和超参数选取
2.1 定义Transformer分类模型,采用Transformer架构中的编码器:
2.2 定义模型参数
2.3 模型结构
3 Transformer模型训练与评估
3.1 模型训练
3.2 模型评估

往期精彩内容:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理
Python轴承故障诊断 (一)短时傅里叶变换STFT
Python轴承故障诊断 (二)连续小波变换CWT
Python轴承故障诊断 (三)经验模态分解EMD
Python轴承故障诊断 (四)基于EMD-CNN的故障分类
Python轴承故障诊断 (五)基于EMD-LSTM的故障分类
Pytorch-LSTM轴承故障一维信号分类(一)
Pytorch-CNN轴承故障一维信号分类(二)
前言
本文基于凯斯西储大学(CWRU)轴承数据,先经过数据预处理进行数据集的制作和加载,最后通过Pytorch实现Transformer模型对故障数据的分类,并介绍Transformer模型的超参数。凯斯西储大学轴承数据的详细介绍可以参考下文:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理
1 数据集制作与加载
1.1 导入数据
参考之前的文章,进行故障10分类的预处理,凯斯西储大学轴承数据10分类数据集:

第一步,导入十分类数据
import numpy as np
import pandas as pd
from scipy.io import loadmatfile_names = ['0_0.mat','7_1.mat','7_2.mat','7_3.mat','14_1.mat','14_2.mat','14_3.mat','21_1.mat','21_2.mat','21_3.mat']for file in file_names:# 读取MAT文件data = loadmat(f'matfiles\\{file}')print(list(data.keys()))
第二步,读取MAT文件驱动端数据
# 采用驱动端数据
data_columns = ['X097_DE_time', 'X105_DE_time', 'X118_DE_time', 'X130_DE_time', 'X169_DE_time','X185_DE_time','X197_DE_time','X209_DE_time','X222_DE_time','X234_DE_time']
columns_name = ['de_normal','de_7_inner','de_7_ball','de_7_outer','de_14_inner','de_14_ball','de_14_outer','de_21_inner','de_21_ball','de_21_outer']
data_12k_10c = pd.DataFrame()
for index in range(10):# 读取MAT文件data = loadmat(f'matfiles\\{file_names[index]}')dataList = data[data_columns[index]].reshape(-1)data_12k_10c[columns_name[index]] = dataList[:119808] # 121048 min: 121265
print(data_12k_10c.shape)
data_12k_10c

第三步,制作数据集

train_set、val_set、test_set 均为按照7:2:1划分训练集、验证集、测试集,最后保存数据
第四步,制作训练集和标签
# 制作数据集和标签
import torch# 这些转换是为了将数据和标签从Pandas数据结构转换为PyTorch可以处理的张量,
# 以便在神经网络中进行训练和预测。def make_data_labels(dataframe):'''参数 dataframe: 数据框返回 x_data: 数据集 torch.tensory_label: 对应标签值 torch.tensor'''# 信号值x_data = dataframe.iloc[:,0:-1]# 标签值y_label = dataframe.iloc[:,-1]x_data = torch.tensor(x_data.values).float()y_label = torch.tensor(y_label.values.astype('int64')) # 指定了这些张量的数据类型为64位整数,通常用于分类任务的类别标签return x_data, y_label# 加载数据
train_set = load('train_set')
val_set = load('val_set')
test_set = load('test_set')# 制作标签
train_xdata, train_ylabel = make_data_labels(train_set)
val_xdata, val_ylabel = make_data_labels(val_set)
test_xdata, test_ylabel = make_data_labels(test_set)
# 保存数据
dump(train_xdata, 'trainX_1024_10c')
dump(val_xdata, 'valX_1024_10c')
dump(test_xdata, 'testX_1024_10c')
dump(train_ylabel, 'trainY_1024_10c')
dump(val_ylabel, 'valY_1024_10c')
dump(test_ylabel, 'testY_1024_10c')1.2 数据加载,训练数据、测试数据分组,数据分batch
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 有GPU先用GPU训练# 加载数据集
def dataloader(batch_size, workers=2):# 训练集train_xdata = load('trainX_1024_10c')train_ylabel = load('trainY_1024_10c')# 验证集val_xdata = load('valX_1024_10c')val_ylabel = load('valY_1024_10c')# 测试集test_xdata = load('testX_1024_10c')test_ylabel = load('testY_1024_10c')# 加载数据train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_xdata, train_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)val_loader = Data.DataLoader(dataset=Data.TensorDataset(val_xdata, val_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_xdata, test_ylabel),batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)return train_loader, val_loader, test_loaderbatch_size = 32
# 加载数据
train_loader, val_loader, test_loader = dataloader(batch_size)2 Transformer分类模型和超参数选取
2.1 定义Transformer分类模型,采用Transformer架构中的编码器:
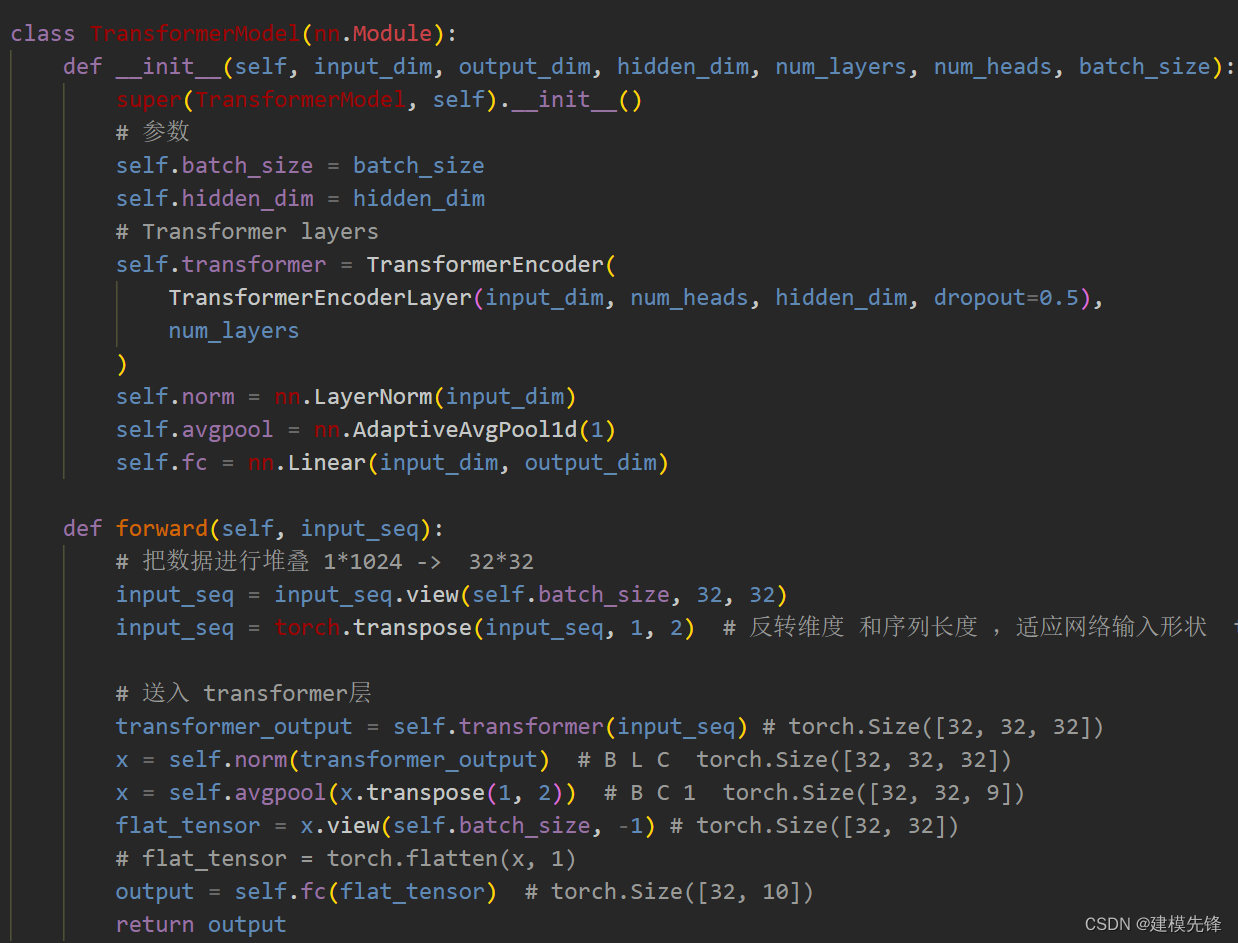
注意:输入数据进行了堆叠 ,把一个1*1024 的序列 进行划分堆叠成形状为 32 * 32, 就使输入序列的长度降下来了
2.2 定义模型参数
# 模型参数
input_dim = 32 # 输入维度
hidden_dim = 512 # 注意力维度
output_dim = 10 # 输出维度
num_layers = 4 # 编码器层数
num_heads = 8 # 多头注意力头数
batch_size = 32
# 模型
model = TransformerModel(input_dim, output_dim, hidden_dim, num_layers, num_heads, batch_size)
model = model.to(device)
loss_function = nn.CrossEntropyLoss(reduction='sum') # loss
learn_rate = 0.0003
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate) # 优化器2.3 模型结构
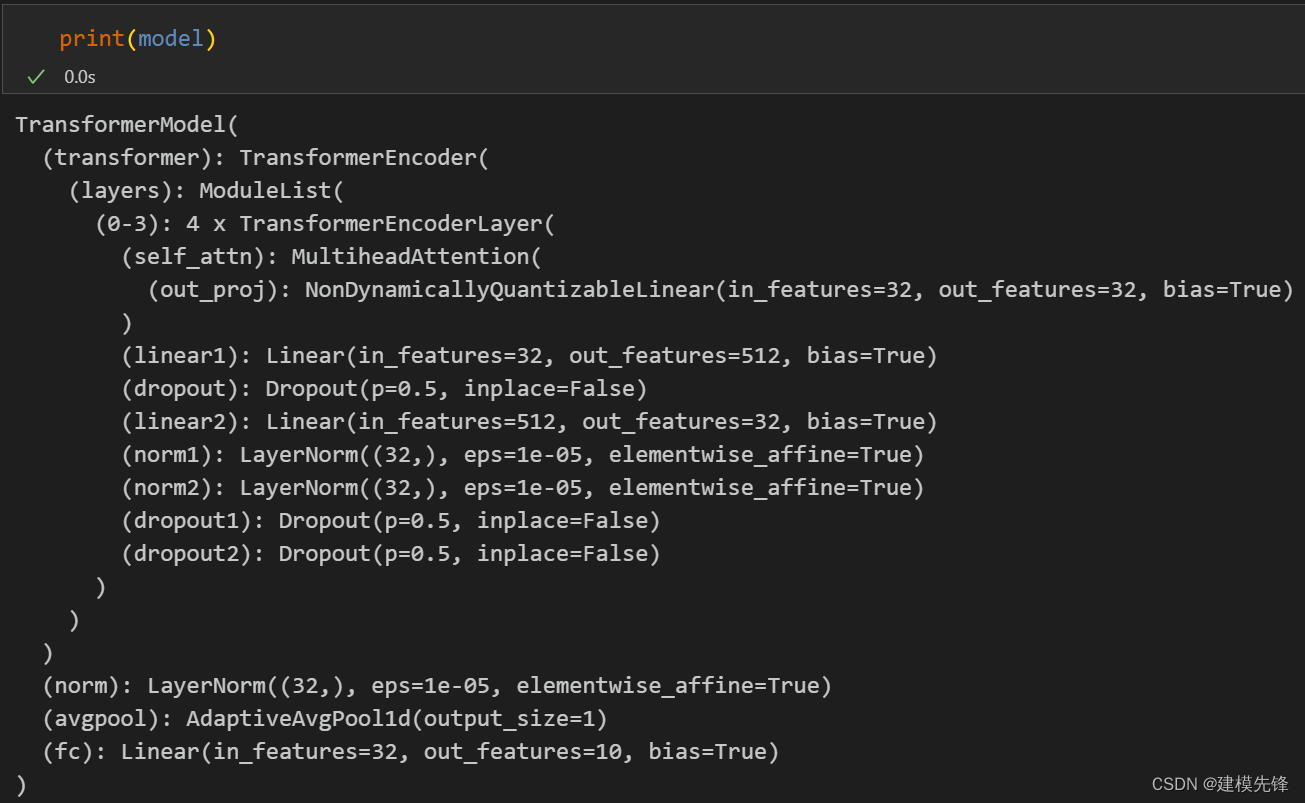
3 Transformer模型训练与评估
3.1 模型训练

训练结果

100个epoch,准确率将近90%,Transformer模型分类效果良好,参数过拟合了,适当调整模型参数,降低模型复杂度,还可以进一步提高分类准确率。
注意调整参数:
-
可以适当增加 Transforme编码器层数 和隐藏层的维度,微调学习率;
-
调整多头注意力的头数,增加更多的 epoch (注意防止过拟合)
-
可以改变一维信号堆叠的形状(设置合适的长度和维度)
3.2 模型评估
# 模型 测试集 验证
import torch.nn.functional as F# 加载模型
model =torch.load('best_model_transformer.pt')
# model = torch.load('best_model_cnn2d.pt', map_location=torch.device('cpu'))# 将模型设置为评估模式
model.eval()
# 使用测试集数据进行推断
with torch.no_grad():correct_test = 0test_loss = 0for test_data, test_label in test_loader:test_data, test_label = test_data.to(device), test_label.to(device)test_output = model(test_data)probabilities = F.softmax(test_output, dim=1)predicted_labels = torch.argmax(probabilities, dim=1)correct_test += (predicted_labels == test_label).sum().item()loss = loss_function(test_output, test_label)test_loss += loss.item()test_accuracy = correct_test / len(test_loader.dataset)
test_loss = test_loss / len(test_loader.dataset)
print(f'Test Accuracy: {test_accuracy:4.4f} Test Loss: {test_loss:10.8f}')Test Accuracy: 0.9570 Test Loss: 0.12100271
相关文章:
Pytorch-Transformer轴承故障一维信号分类(三)
目录 前言 1 数据集制作与加载 1.1 导入数据 第一步,导入十分类数据 第二步,读取MAT文件驱动端数据 第三步,制作数据集 第四步,制作训练集和标签 1.2 数据加载,训练数据、测试数据分组,数据分batch…...
pycharm多线程报错的问题(未解决)
暂未解决! 看了一下可能是这里的问题: 根据建议,在walks之前加了 freeze_support() 但是没有效果。 关键是,在jupyter上运行是没有问题的! 未解决。...

【常用字符大全】含emoji表情
常用符号大全 ❤❥웃유♋☮✌☏☢☠✔☑♚▲♪✈✞↑↓◆◇⊙■□△▽─│♥❣♂♀☿Ⓐ✍✉☣☤✘☒♛▼♫⌘☪≈←→◈◎☉★☆⊿※¡━┃♡ღツ☼☁❅♒✎©™Σ✪✯☭➳卐√↖↗●◐Θ◤◥︻〖〗┄┆℃℉✿ϟ☃☂✄¢€£∞✫★✡↙↘○◑⊕◣◢︼【】┅┇…...

android 蓝牙开关设置
frameworks/base/packages/SettingsProvider/res/values/defaults.xml <bool name"def_bluetooth_on">false</bool>将 def_bluetooth_on 的值设为false(系统默认开启值) adb动态设置 关闭:adb shell settings put gl…...

C++ extern “C“ 用法
extern “C” 由于c中需要支持函数重载,所以c和c中对同一个函数经过编译后生成的函数名是不相同的 extern “C” 的主要作用就是为了实现c代码能够调用其他 c 语言代码。 1(不常用) //告诉编译器 show() 函数按c语言的方式进行编译和链接 extern "C" voi…...

HTML面试题---专题四
文章目录 一、前言二、如何在 HTML 中嵌入音频文件?三、解释 <script> 标签中 defer 属性的用途。四、如何在 HTML 中创建粘性/固定导航栏?五、HTML 中的 span 元素的用途是什么?六、如何使 HTML 元素可拖动?七、解释 <i…...
stm32项目(11)——基于stm32的俄罗斯方块游戏机
1.功能设计 使用stm32f103zet6平台,以及一块LCD屏幕,实现了一个俄罗斯方块游戏机。可以用按键调整方块的位置、还可以控制方块下降的速度! 2.视频演示 俄罗斯方块 3.俄罗斯方块发展史 俄罗斯方块是一种经典的拼图游戏,由苏联俄罗…...

【计算机网络基础2】IP地址和子网掩码
1、IP地址 网络地址 IP地址由网络号(包括子网号)和主机号组成,网络地址的主机号为全0,网络地址代表着整个网络。 广播地址 广播地址通常称为直接广播地址,是为了区分受限广播地址。 广播地址与网络地址的主机号正…...

ES6-import后是否有{}的区别
在ES6中,import语句用于导入其他模块中的变量、函数、类等。在使用import语句时,可以选择是否使用花括号{}来包裹导入的内容,这会影响导入的内容的使用方式。 1.使用花括号{}: 当使用花括号{}时,表示只导入指定的变量…...

rv1126-rv1109-以太网功能-eth-(原理篇)
这里只是浅浅分析一下 1.主控里面会内置mac 2.mac有组接口接到phy(网络芯片:8201) 3.phy(网络芯片:8201)接到网口 //这里就到达硬件的接口了,大致就是这个原理; 4.然后涉及到软件部分 就是mdio总线;这个总线是注册phy用的; 如果注册失败会导致网口无法使用 [ 1.002751] m…...
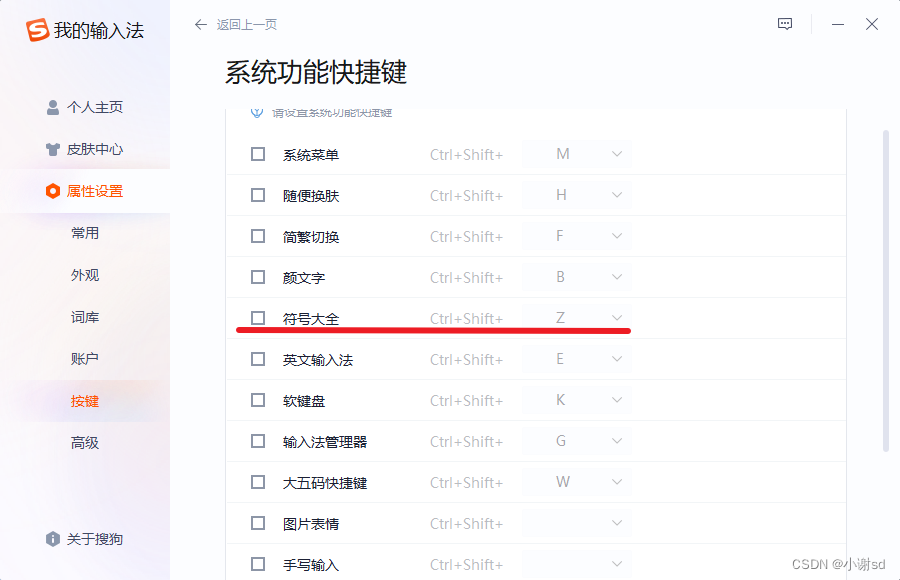
【IDEA】反向撤销操作快捷键 ctrl+shift+z 和搜狗热键冲突的解决办法
当我们执行某些操作时与搜狗热键冲突,直接取消搜狗的快捷键即可!!!以下以 ctrlshiftz 为例。 在输入悬浮框右键找到更多设置 按键里面找到系统功能快捷键设置 取消掉冲突的热键即可...
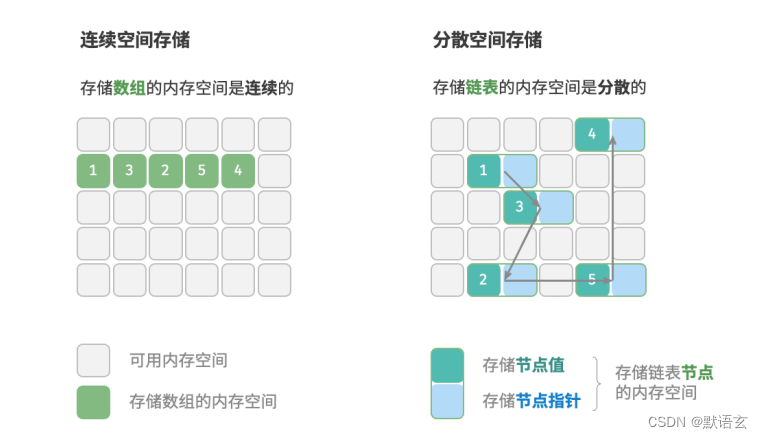
数据结构之----逻辑结构、物理结构
数据结构之----逻辑结构、物理结构 目前我们常见的数据结构分别有: 数组、链表、栈、队列、哈希表、树、堆、图 而它们可以从 逻辑结构和物理结构两个维度进行分类。 什么是逻辑结构? 逻辑结构是指数据元素之间的逻辑关系,而逻辑结构又分为…...

pip 通过git安装库
举例:安装peft库 git clone https://github.com/huggingface/peft.git cd peft python -m pip install . 解释: 使用git clone克隆PEFT库的代码。进入克隆的目录。使用python -m pip install .来安装PEFT库。 补充:使用pip安装到指定编译器…...

C语言——从终端输入 3 个数 a、b、c,按从大到小的顺序输出。
方式一 #include <stdio.h> int main() {int a, b, c, temp;printf("请输入三个数:\n");scanf("%d %d %d", &a, &b, &c);if (a < b) {temp a;a b;b temp;}if (a < c) {temp a;a c;c temp;}if (b < c) {temp…...
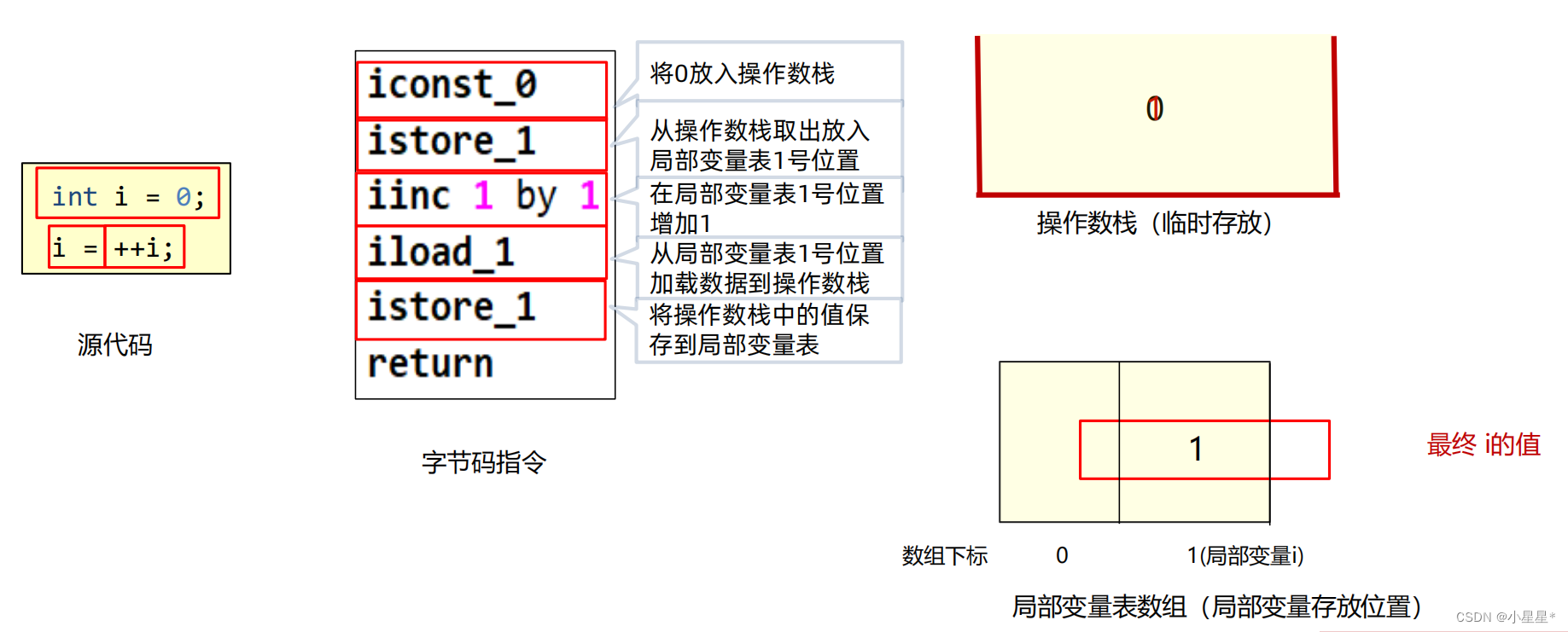
【JVM从入门到实战】(二)字节码文件的组成
一、Java虚拟机的组成 二、字节码文件的组成 字节码文件的组成 – 应用场景 字节码文件的组成部分-Magic魔数 什么是魔数? Java字节码文件中的魔数 文件是无法通过文件扩展名来确定文件类型的,文件扩展名可以随意修改,不影响文件的内容。…...

OPC UA常见故障信息代码
错误信息解释0x00000000操作成功。0x40000000值不确定,但原因不明。0x80000000值为坏,但原因不明。Bad_UnexpectedError 0x80010000发生非预期错误。Bad_InternalError 0x80020000编程或配置错误时发生内部错误。Bad_OutOfMemory 0x80030000完成操作所需…...

第20关 快速掌握K8S下的有状态服务StatefulSet
------> 课程视频同步分享在今日头条和B站 大家好,我是博哥爱运维,K8s是如何来管理有状态服务的呢?跟着博哥来会会它们吧! 前面我们讲到了Deployment、DaemonSet都只适合用来跑无状态的服务pod,那么这里的Statefu…...
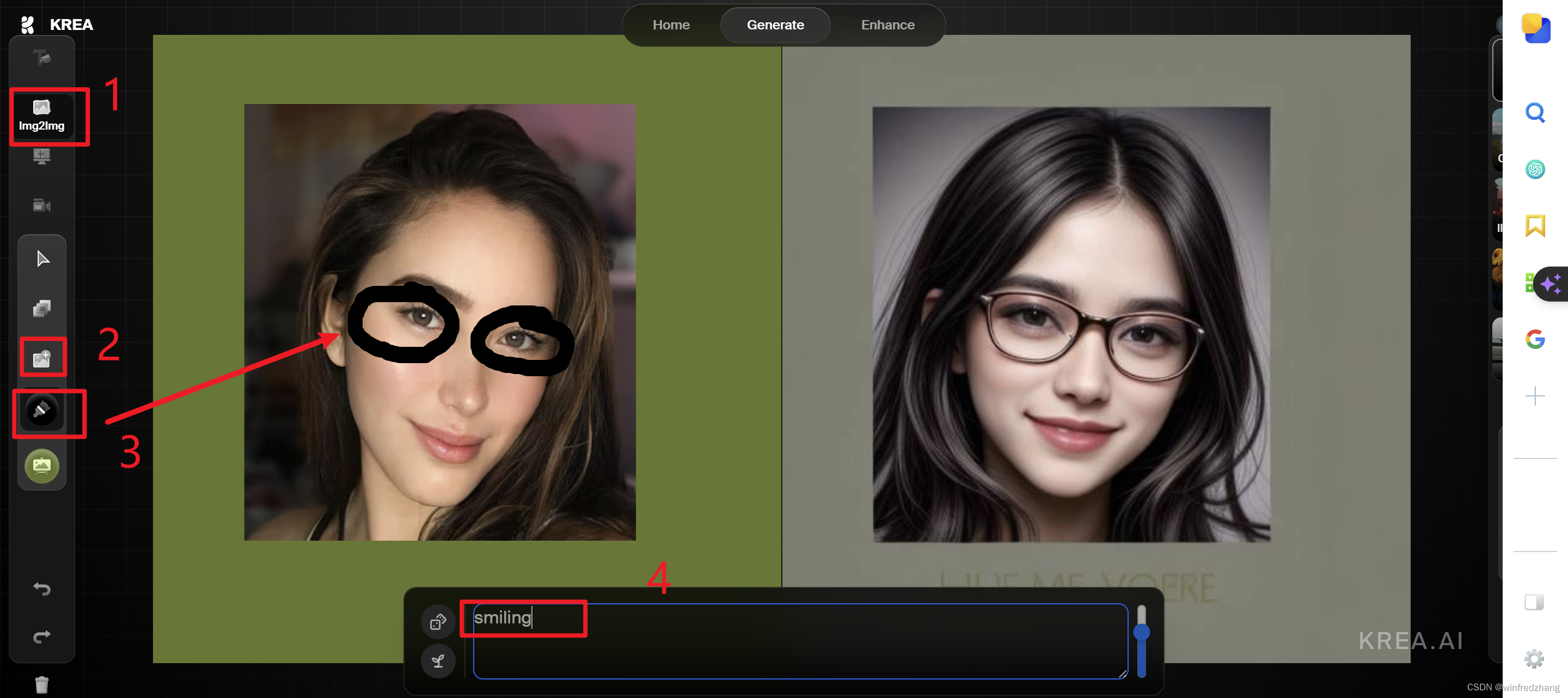
如何使用https://www.krea.ai/来实现文生图,图生图,
网址:https://www.krea.ai/apps/image/realtime Krea.ai 是一个强大的人工智能艺术生成器,可用于创建各种创意内容。它可以用来生成文本描述的图像、将图像转换为其他图像,甚至写博客文章。 文本描述生成图像 要使用 Krea.ai 生成文本描述…...

点滴生活记录2
我从小跟着我爷爷奶奶,小学六年级转到县城上小学,就没跟我奶奶他们住一起了。十一回家,把奶奶接到我这住,细想,自六年级之后,就很少跟奶奶住一起了。 奶奶(间歇性)耳聋,为…...

【带头学C++】----- 九、类和对象 ---- 9.12 C++之友元函数(9.12.1---12.4)
❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️创做不易,麻烦点个关注❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️ ❤️❤️❤️❤️❤️❤️❤️❤️❤️文末有惊喜!献舞一支!❤️❤️❤️❤️❤️❤️❤️❤️❤️❤️ 目录 9.12…...

3分钟上手VSCode Mermaid Preview:在IDE中实现可视化图表实时预览
3分钟上手VSCode Mermaid Preview:在IDE中实现可视化图表实时预览 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为编写Mermaid图表时需要在代码编辑器与预览…...

CMB2前端集成教程:将元框和表单带到网站前台
CMB2前端集成教程:将元框和表单带到网站前台 【免费下载链接】CMB2 CMB2 is a developers toolkit for building metaboxes, custom fields, and forms for WordPress that will blow your mind. 项目地址: https://gitcode.com/gh_mirrors/cm/CMB2 想要在Wo…...

通过精准电源管理延长Apple Silicon Mac电池寿命的解决方案
通过精准电源管理延长Apple Silicon Mac电池寿命的解决方案 【免费下载链接】Battery-Toolkit Control the platform power state of your Apple Silicon Mac. 项目地址: https://gitcode.com/gh_mirrors/ba/Battery-Toolkit 你是否注意到,新买的MacBook Pro…...

洪城寻缘角
洪城寻缘角 南昌人的免费寻缘平台 不必再奔波相亲角,不必被收费套路困扰 洪城寻缘角,全功能永久免费 无需注册即可登记,一键发布个人资料 支持多条件精准筛选,快速匹配同频有缘人 覆盖南昌全城单身,真实、高效、安心…...

ASLR:现代操作系统中的内存安全守护者
1. ASLR:现代操作系统的内存安全基石 想象一下你家的门锁每天都会自动更换位置——这就是ASLR(地址空间布局随机化)对计算机程序做的事。作为现代操作系统最基本的安全机制之一,ASLR通过打乱程序在内存中的"居住地址"&…...

电子电路实战:PWM转DAC的滤波参数优化策略
1. PWM转DAC的基础原理 PWM(脉冲宽度调制)转DAC(数模转换)是嵌入式系统中常见的低成本解决方案。简单来说,就是通过调节数字信号的占空比来模拟不同的电压值。比如一个3.3V的PWM信号,50%占空比就相当于1.65…...

智能制造企业数字化转型智慧工厂建设方案:涵盖研发、供应、生产、销售、服务五大核心环节的智慧工厂建设路径
该方案围绕研发、供应、生产、销售、服务全价值链,融合AI、大数据、5G等技术,通过智能优化、智慧供应链、智能质检、数字孪生及精准营销等模块,构建全链路智慧工厂,实现降本增效与制造企业全面数字化转型。 该方案以“研发—供应…...

Graphormer多场景教程:学术论文配图生成、课程教学演示、项目原型开发
Graphormer多场景教程:学术论文配图生成、课程教学演示、项目原型开发 1. 认识Graphormer模型 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。这个模型在OGB、…...

如何快速搭建抖音批量下载工具:面向初学者的完整指南
如何快速搭建抖音批量下载工具:面向初学者的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...
)
三自由度机械手-工业机器人(说明书+CAD图纸)
三自由度机械手作为工业机器人领域的典型代表,其核心作用在于通过三个独立运动轴的协同控制,实现末端执行器在三维空间内的精准定位与灵活操作。这种结构通过旋转、俯仰与伸缩三个方向的复合运动,能够覆盖工作空间内的任意目标点,…...