kafka学习笔记--安装部署、简单操作
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。
如有侵权、联系速删
视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
文章目录
- 1 安装部署
- 1.1 集群规划
- 1.2 集群部署
- 2 命令行操作
- 2.1 主题
- 2.2 生产者
- 2.3 消费者
- 2.4 消费者组
1 安装部署
1.1 集群规划
这里采用的是三节点的kafka集群,名称为hadoop102、hadoop103、hadoop104

1.2 集群部署
官方下载地址:http://kafka.apache.org/downloads.html
- 解压安装包
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/ - 修改解压后的文件名称
mv kafka_2.12-3.0.0/ kafka - 进入到/opt/module/kafka 目录,修改配置文件
按需修改以下内容:cd config/vim server.properties#broker 的全局唯一编号,不能重复,只能是数字(一般修改这个)。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔。(一般修改这个) log.dirs=/opt/module/kafka/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)(一般修改这个) zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka - 另外两个节点也装安装包
- 分别在 hadoop103 和 hadoop104 上修改配置文件/opt/module/kafka/config/server.properties中的 broker.id=1、broker.id=2
注:broker.id 不得重复,整个集群中唯一。 - 配置环境变量
- 在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
增加如下内容:sudo vim /etc/profile.d/my_env.sh#KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin - 刷新一下环境变量。
source /etc/profile - 其他节点一样的操作。
在另外两个节点 source刷新source /etc/profile
- 在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
- 启动集群
先启动 Zookeeper 集群,然后启动 Kafka。zk.sh start kafka-server-start.sh -daemon config/server.properties - 关闭集群
注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止,Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。bin/kafka-server-stop.sh
2 命令行操作
2.1 主题
1 查看操作主题命令参数
bin/kafka-topics.sh + 参数
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
| –create | 创建主题。 |
| –delete | 删除主题。 |
| –alter | 修改主题。 |
| –list | 查看所有主题。 |
| –describe | 查看主题详细描述。 |
| –partitions <Integer: # of partitions> | 设置分区数。 |
| –replication-factor<Integer: replication factor> | 设置分区副本。 |
| –config <String: name=value> | 更新系统默认的配置。 |
操作时要先连接,所以后面的命令行都有--bootstrap-server hadoop102:9092
2 查看当前服务器中的所有 topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
3 创建一个topic,这里我起名为first
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first
选项说明:
--topic定义topic名
--replication-factor定义副本数
--partitions 定义分区数
4 查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
5 修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
6 再次查看 first 主题修改后的详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
7 删除 topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first
2.2 生产者
1 查看生产者
bin/kafka-console-producer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
2 发送消息
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
hello world
atguigu atguigu
2.3 消费者
1 查看消费者
bin/kafka-console-consumer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
| –from-beginning | 从头开始消费。 |
| –group <String: consumer group id> | 指定消费者组名称。 |
2 消费消息
- 消费指定主题的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first - 把主题中所有的数据都读取出来(包括历史数据)。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
2.4 消费者组
1 查看消费者组
bin/kafka-consumer-groups.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –describe | 列出消费者组详情信息。 |
| –list | 列出所有消费者。 |
| –group <String: consumer group id> | 指定消费者组名称。 |
如果我们要查询testGroup消费者组的详细信息,执行如下命令
bin/kafka-consumer-groups.sh --bootstrap-server hadoop102:9092 --describe --group testGroup

其中列出的参数含义为:
| 参数 | 描述 |
|---|---|
| GROUP | 消费者组名 |
| TOPIC | 主题名称 |
| PARTITION | 该主题消息的分区ID列表 |
| CURRENT-OFFSET | 最后被消费的消息的偏移量 |
| LOG-END-OFFSET | 该主题最后一条消息的偏移量 |
| LAG | 消息积压量 |
| CONSUMER-ID | 该组消费者ID |
| HOST | 该组消费者主机IP/brokerID |
| CLIENT-ID | 该组消费者客户端ID |
相关文章:
kafka学习笔记--安装部署、简单操作
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。 如有侵权、联系速删 视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优…...
UE4 材质实现Glitch效果
材质实现Glitch效果 UE4 材质实现Glitch效果预览1预览2 UE4 材质实现Glitch效果 预览1 添加材质函数: MF_RandomNoise 添加材质: 预览2 添加材质函数MF_CustomPanner: 添加材质函数:MF_Glitch 材质添加: 下面用…...
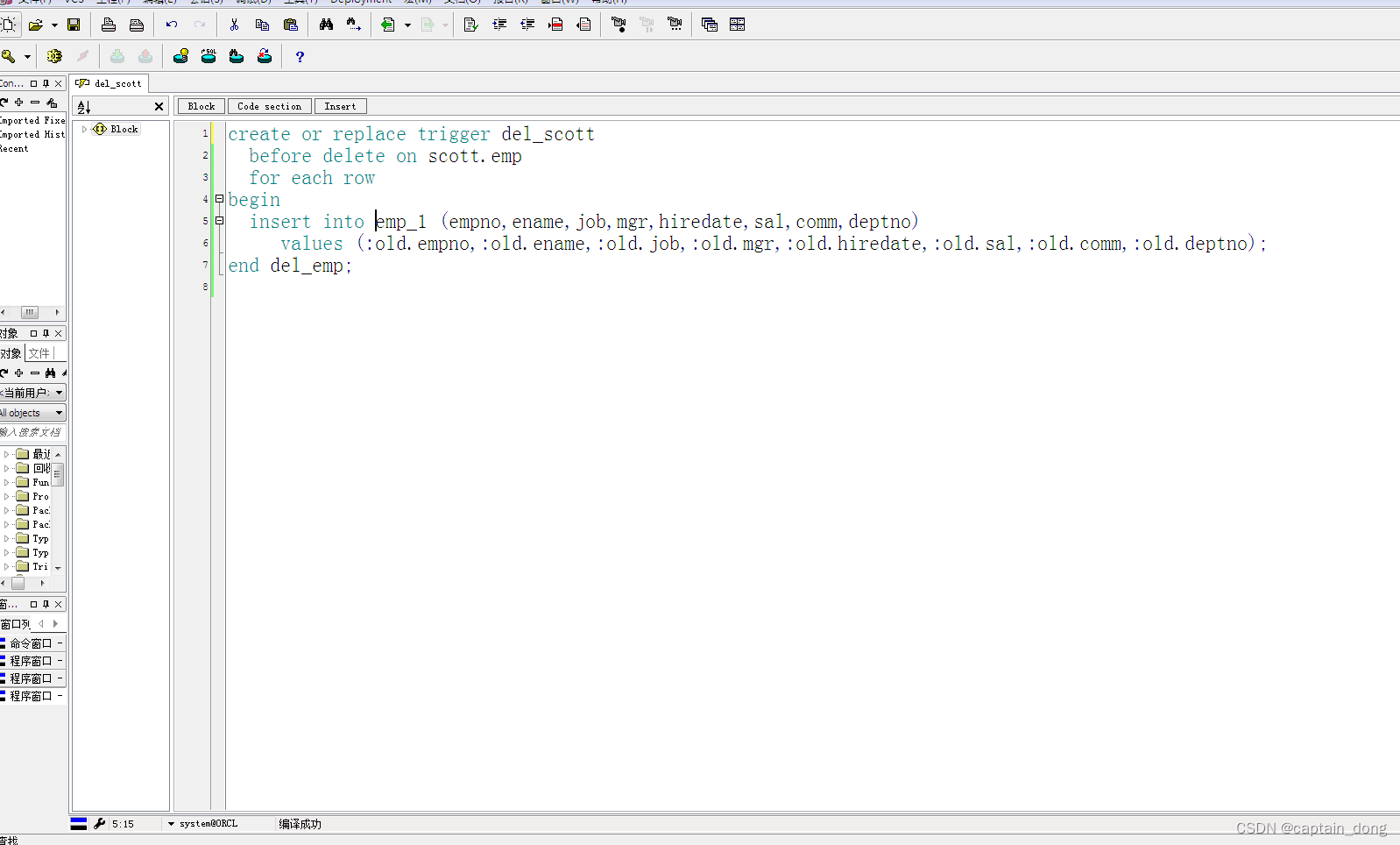
oracle实验2023-12-8--触发器
第十四周实验 【例】功能要求:增加一新表XS_1,表结构和表XS相同,用来存放从XS表中删除的记录。 分析: 1、创建表 xs_1 SQL> create table xs_1 as select * from xs; Table created SQL> truncate table xs_1; Table truncated题目&a…...

【Python百宝箱】贝叶斯统计的魅力:从PyMC3到ArviZ,探索数据背后的不确定性
标题:预测未来趋势的利器:深入贝叶斯统计和概率编程的世界 前言 贝叶斯统计和概率编程是一种强大的分析方法,可以帮助我们处理不确定性、建立灵活的模型以及进行参数估计和推断。本文将介绍几个常用的Python库,包括PyMC3、ArviZ…...

Knowledge Graph知识图谱—8. Web Ontology Language (OWL)
8. Web Ontology Language (OWL) 在RDFs不可能实现: Property cardinalities, Functional properties, Class disjointness, we cannot produce contradictions, circumvent the Non Unique Naming Assumption, circumvent the Open World Assumption 8.1 OWL Tr…...

排序算法——冒泡排序
排序算法是计算机科学中最基本的概念之一。在众多排序算法中,冒泡排序因其实现简单而被广泛学习。尽管它不是最高效的排序方法,但对于理解基本的排序概念非常有用。本文将深入探讨冒泡排序的原理、实现、优缺点以及应用场景。 1. 冒泡排序原理 冒泡排序…...
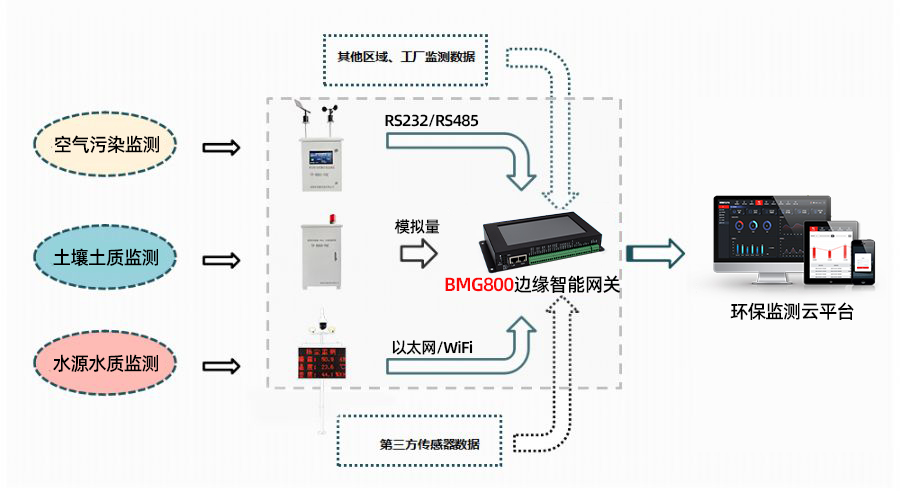
边缘智能网关如何应对环境污染难题
随着我国工业化、城镇化的深入推进,包括大气污染在内的环境污染防治压力继续加大。为应对环境污染防治难题,佰马综合边缘计算、物联网、智能感知等技术,基于边缘智能网关打造环境污染实时监测、预警及智能干预方案,可应用于大气保…...

uniapp定时器的应用
1、初始化定时器 data(){return{timer: null, //定时器} } 2、定时器的使用 定时器分两种,setInterval和setTimeout。 二者的区别: setInterval函数会无限执行下去,除非调用clearInterval函数来停止它。setTimeout函数只执行一次&#x…...

Docker中安装Oracle10g和oracle增删改查
Docker中安装Oracle 10g 一、Docker中安装Oracle 10安装步骤二、连接数据库登录三 oracle数据库的增删改查及联表查询的相关操作oracle数据库,创建students数据表,创建100万条数据增删改查 一、Docker中安装Oracle 10安装步骤 Docker中安装Oracle 10g 1.下载镜像 docker pull …...
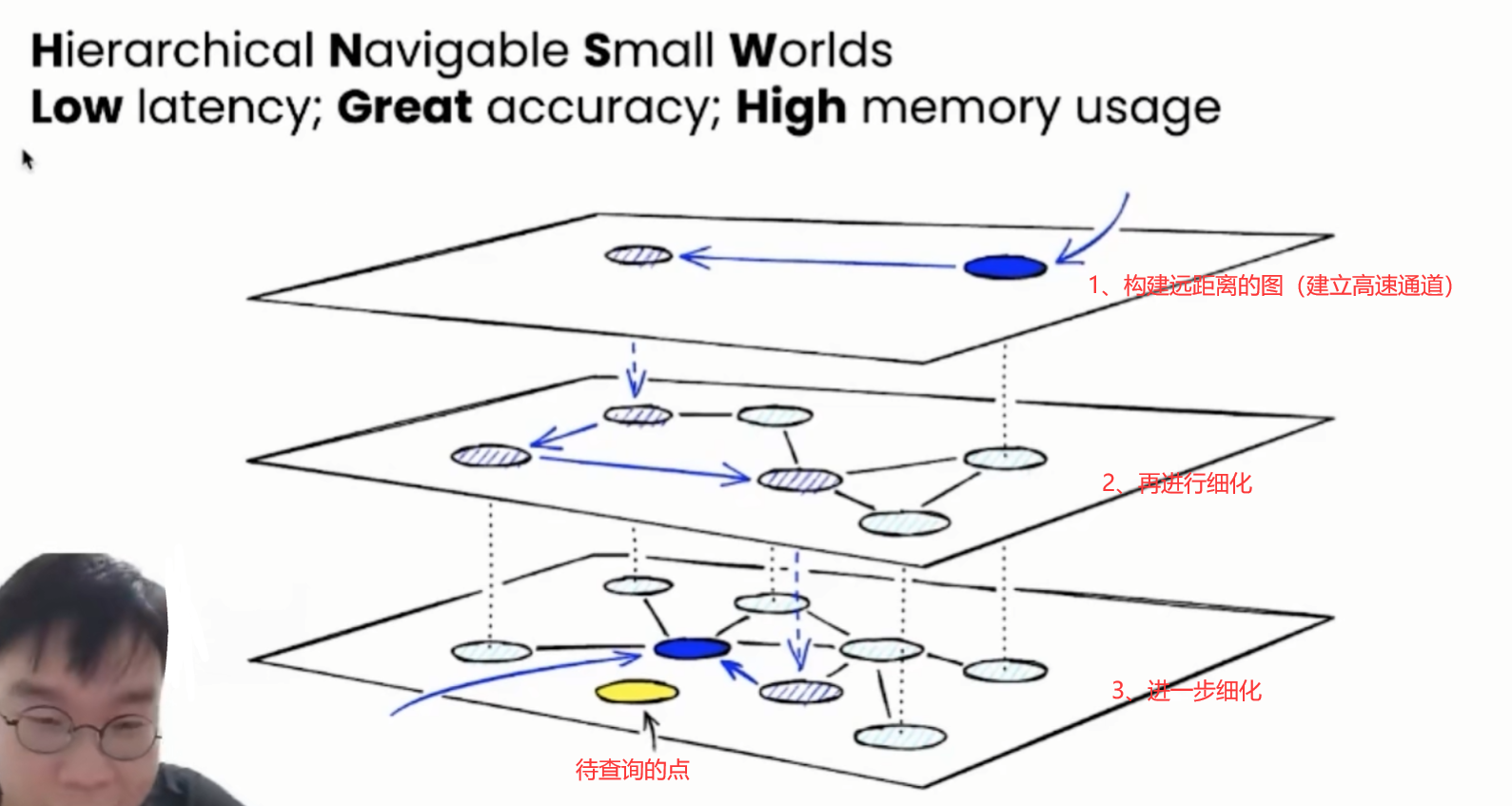
推荐算法:HNSW【推荐出与用户搜索的类似的/用户感兴趣的商品】
HNSW算法概述 HNSW(Hierarchical Navigable Small Word)算法算是目前推荐领域里面常用的ANN(Approximate Nearest Neighbor)算法了。其目的就是在极大量的候选集当中如何快速地找到一个query最近邻的k个元素。 要找到一个query的…...
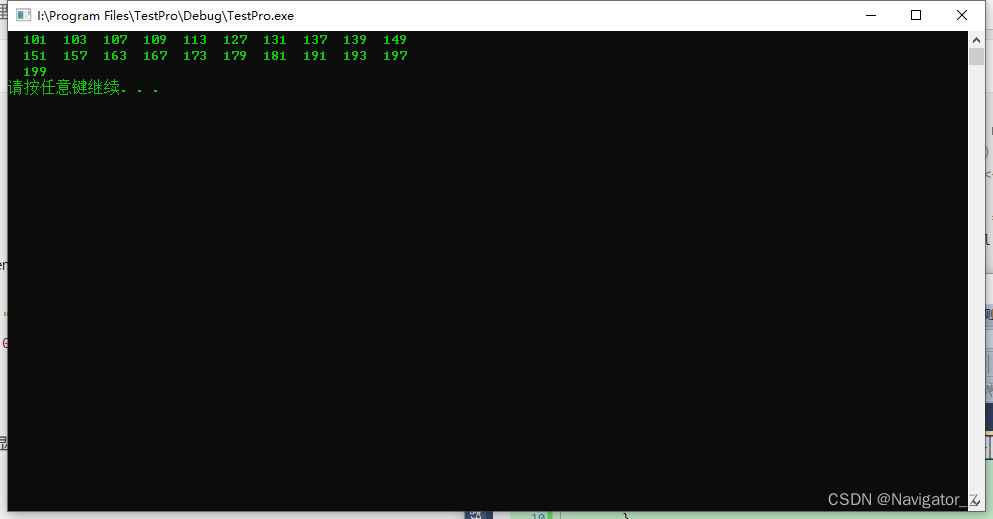
C++ //例3.14 找出100~200间的全部素数。
C程序设计 (第三版) 谭浩强 例3.14 例3.14 找出100~200间的全部素数。 IDE工具:VS2010 Note: 使用不同的IDE工具可能有部分差异。 代码块 方法:使用函数的模块化设计 #include <iostream> #include <iomanip> #i…...
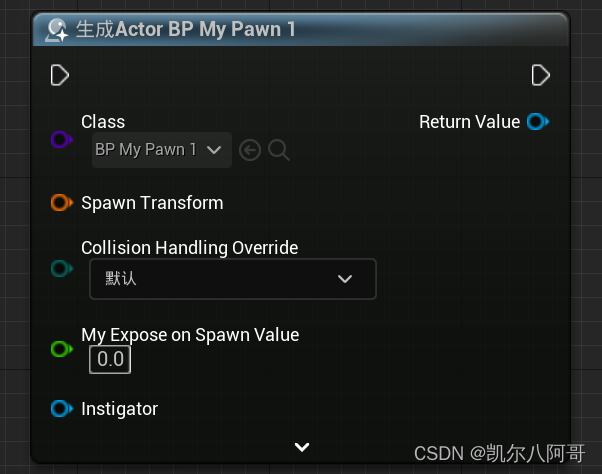
虚幻学习笔记11—C++结构体、枚举与蓝图的通信
一、前言 结构体的定义和枚举类似,枚举的定义有两种方式。区别是结构体必须以“F”开头命名,而枚举不用。 额外再讲了一下蓝图生成时暴露变量的方法。 二、实现 2.1、结构体 1、定义结构体 代码如下,注意这个定义的代码一定要在“UCLASS()”…...

【android开发-19】android中内容提供者contentProvider用法讲解
1,内容URI 在Android系统中,Content URI是一种用于唯一标识和访问应用程序中的数据的方法。它由Android系统提供,通过Content Provider来实现数据的共享和访问。 Content URI使用特定的格式来标识数据,通常以"content://&qu…...
)
浅谈排序——快速排序(最常用的排序)
快速排序(Quick Sort)是一种常见的排序算法,由英国计算机科学家东尼霍尔(Tony Hoare)在1960年发明。这是一种分治算法,基本思想是通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所…...

Springboot项目实现简单的文件服务器,实现文件上传+图片及文件回显
文章目录 写在前面一、配置1、application.properties2、webMvc配置3、查看效果 二、文件上传 写在前面 平常工作中的项目,上传的文件一般都会传到对象存储云服务中。当接手一个小项目,如何自己动手搭建一个文件服务器,实现图片、文件的回显…...

5V低压步进电机驱动芯片GC6150,应用于摄像机,机器人 医疗器械等产品中。具有低噪声、低振动的特点
GC6150是双通道5V低压步进电机驱动器,具有低噪声、低振动的特点,特别适用于相机变焦对焦系统、万向架、摇头机等精度、低噪声STM控制系统,该芯片为每个通道集成了一个256微步的驱动器。通过SPI & T2C接口,客户可以方使地调整驱…...
3D Web轻量引擎HOOPS Communicator如何实现对大模型的渲染支持?
除了读取轻松外,HOOPS Communicator对超大模型的支持效果也非常好,它可以支持30GB的包含70万个零件和3.5亿个三角面的Catia装配模型! 那么它是如何来实现对大模型的支持呢? 我们将从以下几个方面与大家分享:最低帧率…...
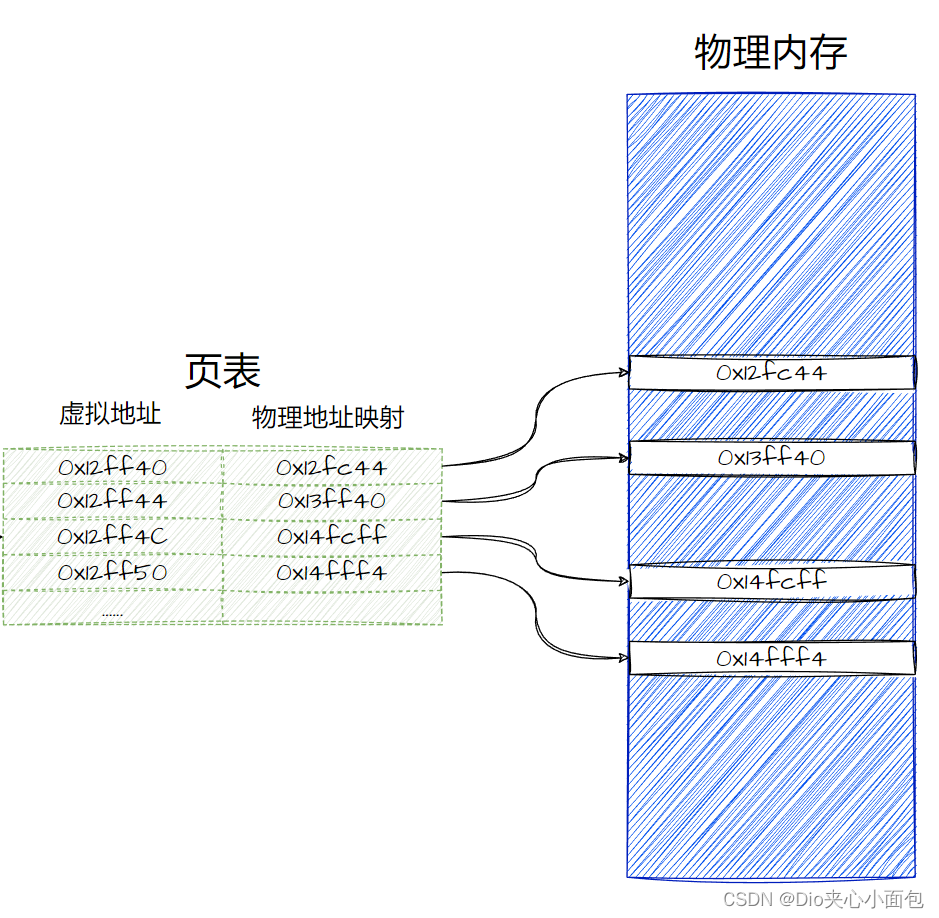
『 Linux 』进程地址空间概念
文章目录 🫙 前言🫙 进程地址空间是什么🫙 写时拷贝🫙 可执行程序中的虚拟地址🫙 物理地址分布方式 🫙 前言 在c/C中存在一种内存的概念; 一般来说一个内存的空间分布包括栈区,堆区,代码段等等; 且内存是…...

PySpark大数据处理详细教程
欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们…...
ts非基础类型(对象))
三(五)ts非基础类型(对象)
在ts里面定义对象的方式也有很多。 普通定义 let obj1:{} {} // obj1.name fufu 报错,只能定义为空对象且不能修改 // 但是可以在赋初始值的时候直接添加属性,这是ts在类型推断时,它会宽容地匹配对象的结构。 let obj2:{} {name: fufu}…...
)
计算机毕业设计 | SpringBoot+vue文理医院预约挂号系(附源码+论文)
1,绪论 1.1 研究背景与意义 信息化管理模式是将行业中的工作流程由人工服务,逐渐转换为使用计算机技术的信息化管理服务。这种管理模式发展迅速,使用起来非常简单容易,用户甚至不用掌握相关的专业知识,根据教程指导即…...
3.11 浮点代码(3.11.1 浮点传送和转换操作))
(学习笔记)3.11 浮点代码(3.11.1 浮点传送和转换操作)
文章目录线索栏笔记栏总结栏线索栏 x86-64浮点体系结构经历了哪几个关键发展阶段?当前的AVX2架构提供了哪些寄存器(YMM/XMM)?它们的位宽和用途是什么?(图1,2)用于在内存和XMM寄存器之间、以及X…...

锁相双极性PWM电机驱动原理与STM32实现
1. 项目概述Motor_LockedAntiphase是一个面向嵌入式电机控制的轻量级驱动库,专为实现锁相双极性PWM(Locked Antiphase PWM)控制模式而设计。该模式广泛应用于直流有刷电机(DC Brushed Motor)的双向调速与精确力矩控制场…...

嵌入式开发中全局变量的优化实践与替代方案
1. 嵌入式开发中的全局变量困境作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多因为滥用全局变量而陷入维护噩梦的项目。记得刚入行时接手过一个智能家居控制器的代码库,打开项目一看,光是extern声明的全局变量就有200多个,…...

NTPAsyncClient:嵌入式异步时间同步轻量库解析
1. NTPAsyncClient 库深度解析:面向嵌入式实时系统的异步时间同步方案1.1 设计定位与工程价值NTPAsyncClient 是一个专为资源受限嵌入式平台设计的轻量级网络时间协议(NTP)客户端库,其核心目标并非替代标准 NTP daemon 的全功能实…...

嵌入式系统可靠性设计:内存保护与硬件检测实践
1. 嵌入式系统可靠性设计概述在工业控制、医疗设备和汽车电子等关键领域,嵌入式系统的可靠性直接关系到人身安全和财产安全。作为一名有十年嵌入式开发经验的工程师,我见过太多因可靠性设计不足导致的现场故障。这些故障往往不是由复杂算法错误引起&…...

SecGPT-14B知识库增强:让OpenClaw安全决策更精准
SecGPT-14B知识库增强:让OpenClaw安全决策更精准 1. 为什么需要知识库增强的OpenClaw 去年我在尝试用OpenClaw自动化处理安全日志时,发现一个尴尬的问题:当模型遇到CVE漏洞编号时,经常给出模棱两可的判断。比如看到"CVE-20…...

设计键盘键帽个性替换件,精准适配,输出,客制化键盘低成本平替。
如何低成本获得独一无二的键帽。项目方案:基于Python的键盘键帽激光雕刻参数化生成系统一、 实际应用场景描述想象一下,你是一个 VIM 党,或者是一个重度使用 Figma 的设计师。你对键盘有着极致的追求:你想把 "ESC" 键换…...

AtCoder Beginner Contest 433
AtCoder Beginner Contest 433 ABCD https://www.bilibili.com/video/BV1srUTBEEfa/ AtCoder Beginner Contest 433 https://www.bilibili.com/video/BV14xUWBYELd/ https://blog.csdn.net/2503_93669452/article/details/155140717 【实况】AtCoder Beginner Contest 433&…...

Linux内核中的内存屏障技术详解
Linux内核中的内存屏障技术详解 引言 内存屏障(Memory Barrier)是Linux内核中用于确保内存操作顺序的重要机制。在多处理器系统中,由于CPU缓存、指令重排序等因素,内存操作的实际执行顺序可能与代码中的顺序不同,这可能…...