IntelliJ IDEA创建一个spark的项目
在开始之前,需要说明的是 要跑通基本的wordcount程序,是不需要在windows上安装 hadoop 和spark的,因为idea在跑程序的时候,会按照 pom.xml配置文件,从指定的 repository源,按照properties指定的版本,下载dependency中指定的依赖包 。
如果需要在本地通过 spark-shell,或者 运行开发完的包,那么就需要完整的hadoop 和spark环境,就需要把这两个都安装好。
我是新入门,之前idea建立spark项目是同事指导着创建的,但是过了一段时间,具体步骤都不记得了,所以试着自己重新建立一个新的spark项目,算是熟悉一下IDEA这个工具吧。
参考文档:写的很详细
Windows平台搭建Spark开发环境(Intellij idea 2020.1社区版+Maven 3.6.3+Scala 2.11.8)_windows下安装scala+hadoop+spark运行环境,集成到idea中-CSDN博客
1. 需要安装的软件及版本
jdk1.8-1.8.0_25
Scala:Scala code runner version 2.11.12
Intellij idea 2019.2.3(community edition)
Maven:apache-maven-3.6.3
2.配置环境变量 及 验证
配置环境变量过程中 前面的是 变量名(如 JAVA_HOME),后面是变量的值(C:\Program Files\Java)。
1. java
新增系统环境变量:JAVA_HOME C:\Program Files\Java
PATH 中增加:C:\Program Files\Java\jdk1.8.0_91\bin 和 C:\Program Files\Java\jre1.8.0_91\bin
CLASSPATH 中要增加:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar;
验证是否安装成功(文字是粘的别人的,代码是我本机运行的):
C:\Users\brayden.liu>java -version
java version "1.4.2_03"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.4.2_03-b02)
Java HotSpot(TM) Client VM (build 1.4.2_03-b02, mixed mode)2.Scala
新增系统环境变量:SCALA_HOME C:\Program Files (x86)\scala
PATH 中增加:%SCALA_HOME%\bin
验证
C:\Users\brayden.liu>scala -version
Picked up JAVA_TOOL_OPTIONS: -Djava.vendor="Sun Microsystems Inc."
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL3.Maven
原文是:
Maven下载后,解压到了D:\spark_study ,删除了 apache-maven-3.6.3-bin目录,路径为D:\spark_study\apache-maven-3.6.3
我记得我安装时候,就是直接解压缩放到D:\dev_home\apache-maven-3.6.3,好像也能用
注意一下操作
新增系统环境变量:MAVEN_HOME D:\spark_study\apache-maven-3.6.3
新增系统环境变量:MAVEN_OPTS -Xms128m -Xmx512m
CLASSPATH 中要增加:%MAVEN_HOME%\bin
设置 本地maven 仓库 的路径为:D:\spark_study\localWarehouse,这个路径就是用来存放下载各种依赖包的。如果采用idea默认的Maven,那么仓库地址一般是 C:\Users\用户名\.m2 ,建议自己设置路径而非采用默认的路径。
重点
打开 D:\dev_home\apache-maven-3.6.3\conf\settings.xml,在文件中添加:
<localRepository>D:\spark_study\localWarehouse</localRepository>
后面加载maven的时候,可以联动带出本地仓库
接下来设置 国内maven仓库 如阿里仓库,后面就会从这个镜像地址下载依赖包,速度会更快。
在 <mirrors>标签中添加:
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
验证(靠,后面有异常,但是好像不影响使用)
C:\Users\brayden.liu>mvn -V
Picked up JAVA_TOOL_OPTIONS: -Djava.vendor="Sun Microsystems Inc."
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: D:\dev_home\apache-maven-3.6.3\bin\..
Java version: 1.8.0_251, vendor: Sun Microsystems Inc., runtime: C:\Program Files\Java\jdk1.8.0_251\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.161 s
[INFO] Finished at: 2023-12-08T15:10:31+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] No goals have been specified for this build. You must specify a valid lifecycle phase or a goal in the format <plugin-prefix>:<goal> or <plugin-group-id>:<plugin-artifact-id>[:<plugin-version>]:<goal>. Available lifecycle phases are: validate, initialize, generate-sources, process-sources, generate-resources, process-resources, compile, process-classes, generate-test-sources, process-test-sources, generate-test-resources, process-test-resources, test-compile, process-test-classes, test, prepare-package, package, pre-integration-test, integration-test, post-integration-test, verify, install, deploy, pre-clean, clean, post-clean, pre-site, site, post-site, site-deploy. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/NoGoalSpecifiedException
3.配置intellij idea
1.安装软件
特别需要注意的是 这里只是安装社区版,没有安装专业版,因为社区版也够用了。
另外,如果用专业版,特别是来回安装了多次,会出现 安装完后,双击打开没有反应的问题,需要把 C:\Users\用户名\.IntelliJIdea版本号 这个目录底下的文件全部删除。
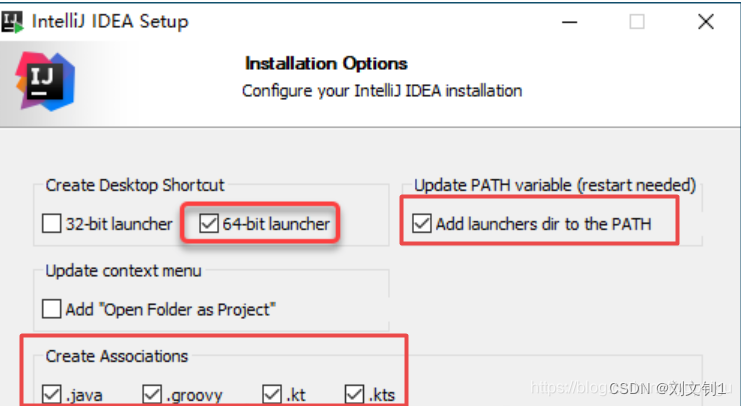
注意勾选红色框部分,然后一步一步安装就行。
图片是我粘的和我本机大差不差吧
2、安装scala插件
通过菜单 File -》Settings 进入如下页面,然后输入 scala 找到要安装的插件,点击 安装。按照提示,需要重启 IDE。
如果你已经下载了,好像可以本地安装,我是早就安装好了的,所以不太记得了。

如果 显示找不到插件,可以通过 点击 Auto-detect proxy settings 来设置代理(注意 这里并不需要输入具体的url),点击保存。
3、配置java、scala、maven
重点,这里是重点
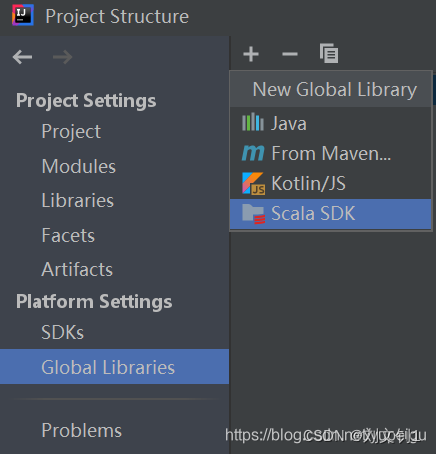
通过菜单 File -》Project Structure 进入页面进行设置:
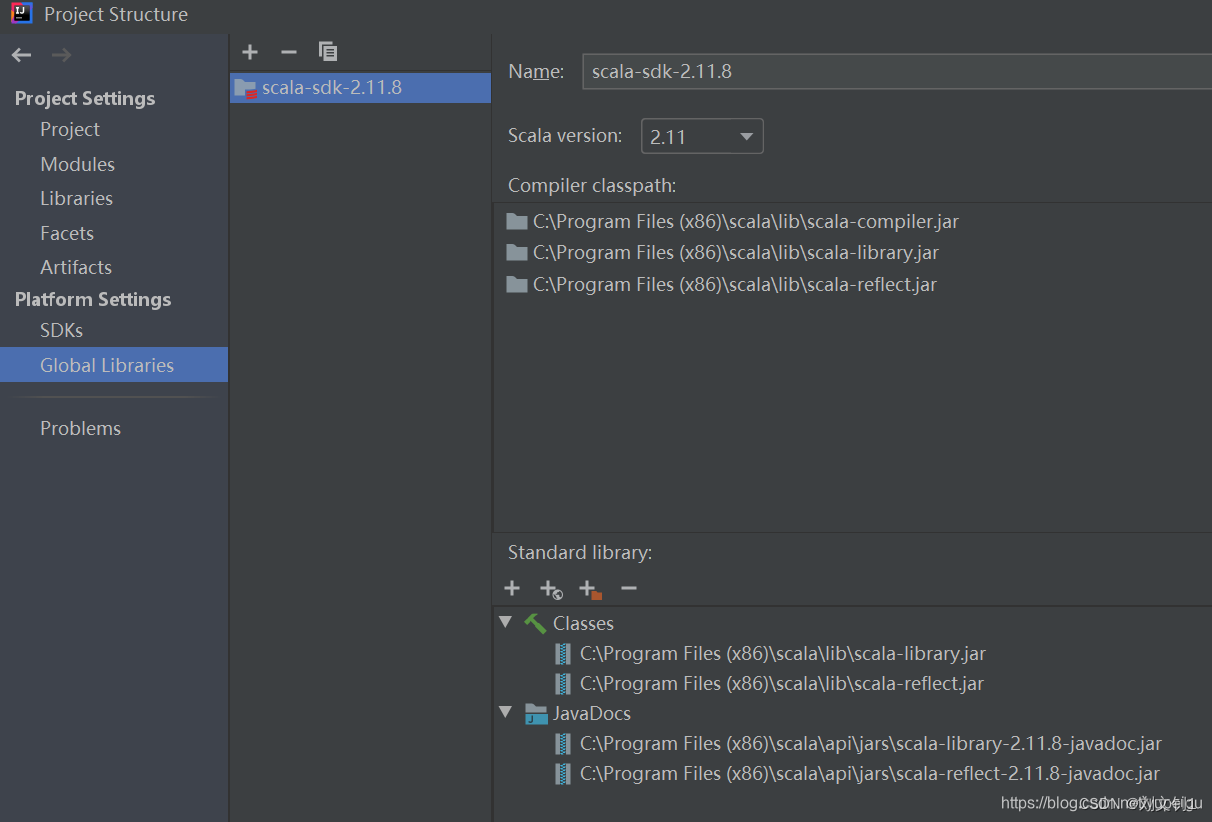
Global Libraries 点击 + 号,选择 Scala SDK
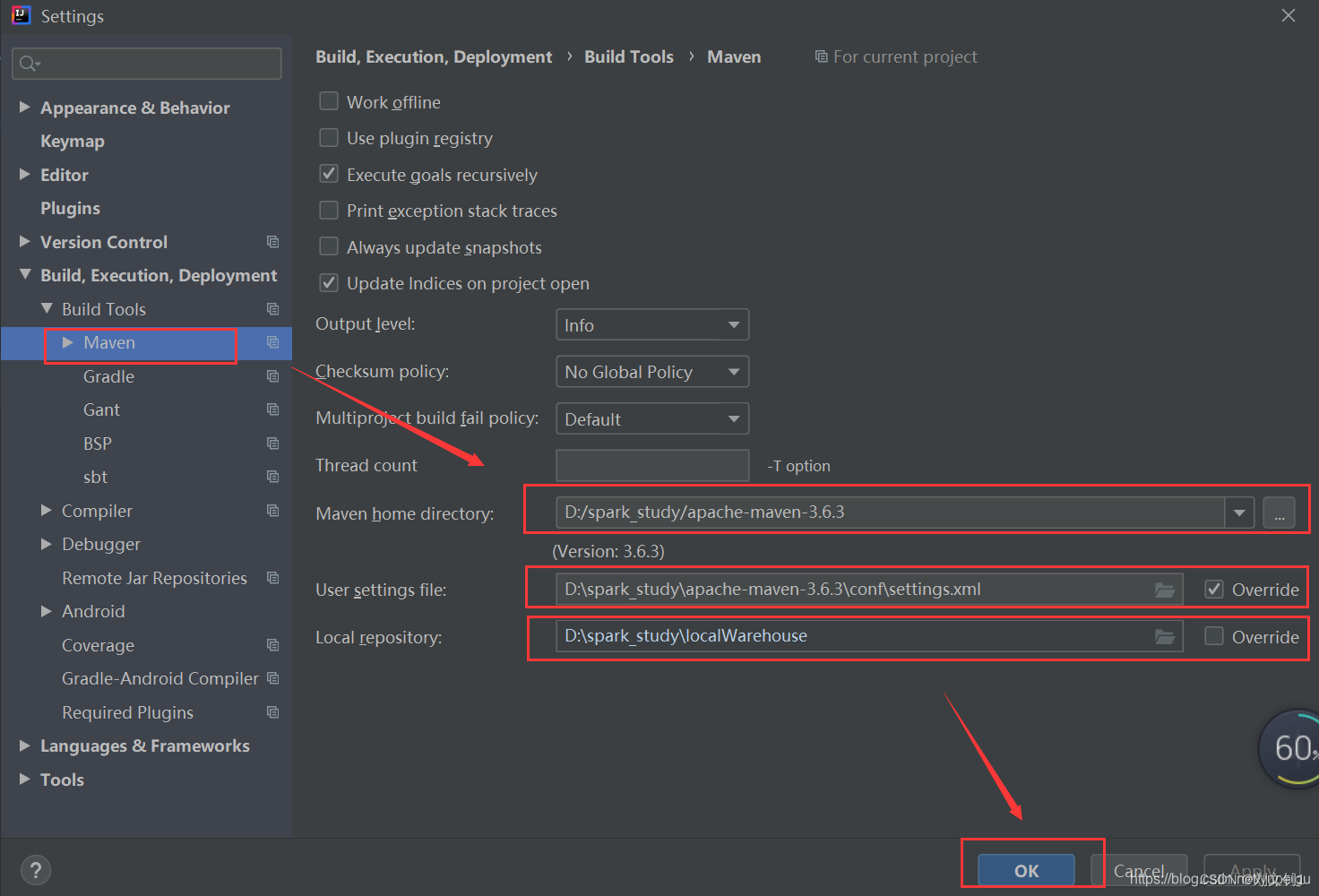
通过菜单 File-》Settings -》 Build,Exection,Deployment -》 Build Tools -》 Maven进入页面,要修改 Maven home directory,User settings file,Local repository,最后点击 OK 保存。
这里采用 手动安装的Maven 3.6.3版本,而非idea自带的Maven,同时指定相应的 settings.xml文件、Maven仓库的路径。
图片是我粘的别人的文档,我的也差不多,另外别忘了左边的勾选框
在IEDA中设置apache
file->settings->Build,Execution,Deployment->build Tools->maven
maven home directory:本机的maven的位置
我的是在D:/dev_home/apache-maven-3.6.3
User settings file:maven的设置文件位置,是在maven home directory路进下
我的是在D:\dev_home\apache-maven-3.6.3\conf\settings.xml
记得后边的Override勾选框勾上
Loca repository:本地jar仓库位置
我的是在E:\repository--这个由于前面在maven中设置了,所以这里自动带出来了,很好。
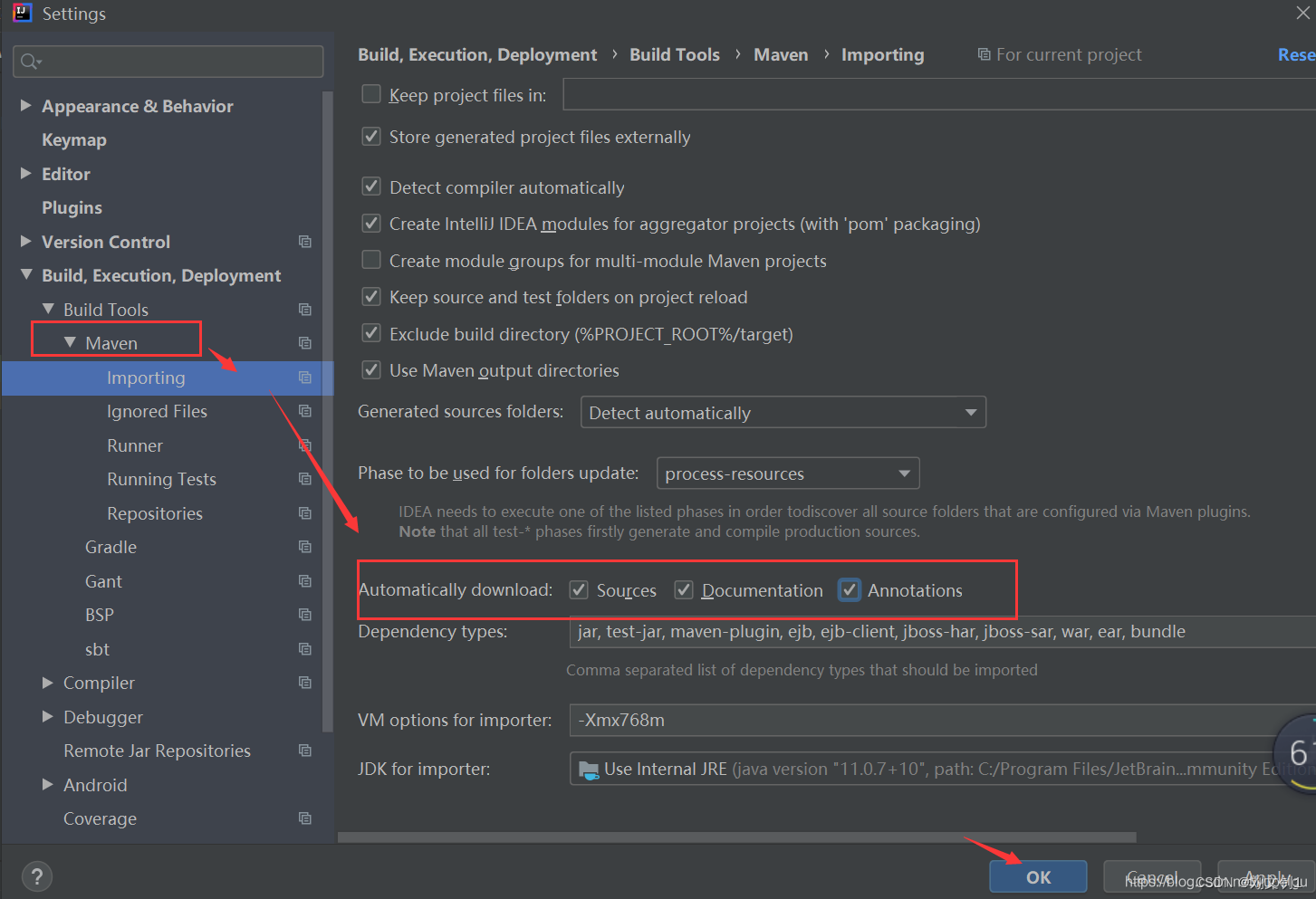
然后 继续点击 Maven 左侧的向右的三角形,展开子菜单,点击 Importing ,再勾选 红色框的3个 复选框,点击 OK 保存。
这里不知道具体是干啥的,我的软件只有前两项,感觉勾不勾差不多
4.intellij idea中新建项目
File -》New -》Project,注意 不要勾选 “Create from archetype”(这里是重点,用了后运行程序会报一些莫名其妙的错误),因为 scala-archetype-simple:1.2 版本太低,会有很多问题,也就是上面下载的 插件并没有排上用场,这也是试了很多次才发现的。。。
图片依然是粘的别人的,我都和这个有些不同,但是大差不差
 修改pom.xml文件,在 </project> 前面增加 依赖项:
修改pom.xml文件,在 </project> 前面增加 依赖项:
这个pom是我本机的,不太明白都是干啥的,所以查了文档,加了一些备注,后面再逐步明细吧
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><!--groupId(组织的ID):表示当前模块所属于的项目artifactId:模块的ID,如果是项目级的那就是项目名version:当前的版本--><groupId>testNewProject1</groupId><artifactId>testNewProject1</artifactId><packaging>pom</packaging><version>1.0-SNAPSHOT</version><!--modules这里需要在file->project structure里面建立一个新的modules并且在他下面建立一个pom这里指定后,本pom的参数可以被scala继承--><modules><module>scala</module></modules><!--properties全局属性,一般情况下同于定义全局的jar包的版本作用:比如在properties中定义版本<ljy.version>4.3.12</ljy.version>那么在对于的依赖下添加${ljy.version}在properties中改了 后面对应的依赖版本也跟着改了(方便)在依赖的version中alt+ctrl+v(快速提取)--><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><encoding>UTF-8</encoding><java.version>1.8</java.version><scala.version>2.11.12</scala.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><cdh.version>3.3.0-cdh6.3.1</cdh.version><hadoop.version>3.3.0</hadoop.version><hbase.version>2.1.0</hbase.version><hive-jdbc.version>2.1.1</hive-jdbc.version><spark2.version>2.4.0</spark2.version><spark.version>2.4.0</spark.version><maven.version>3.3</maven.version><parquet.version>1.0.0-cdh6.3.1</parquet.version><hbase-spark.version>2.1.0-cdh6.3.1</hbase-spark.version><kafka.version>0.11.0.1</kafka.version><hive.version>2.1.1</hive.version><kudu-client.version>1.10.0-cdh6.3.1</kudu-client.version><config.version>1.2.1</config.version><zkclient.version>0.10</zkclient.version><guava.version>18.0</guava.version><redis.version>2.8.2</redis.version><mysql.version>5.1.34</mysql.version><ojdbc.version>11.1.0.7.0</ojdbc.version><junit.version>3.8.1</junit.version><fast.version>1.2.62</fast.version><jcommander.version>1.71</jcommander.version></properties><build><pluginManagement><!--plugins配置插件,是一种工具--><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.1</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>2.3.1</version></plugin></plugins></pluginManagement></build><!--repositories用来配置当前工程使用的远程仓库依赖查找的顺序:本地仓库——>当前工程pom.xml中配置的远程仓库——>setting.xml中配置的远程仓库spring为例:url 是spring官方地址--><repositories><repository><id>apache.snapshots</id><name>Apache Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url></repository><repository><id>cdh.repo</id><name>Cloudera Repositories</name><url>https://repository.cloudera.com/artifactory/cloudera-repos</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>scala-tools.org</id><name>Scala-tools Maven2 Repository</name><url>http://scala-tools.org/repo-releases</url></repository></repositories><pluginRepositories><pluginRepository><id>scala-tools.org</id><name>Scala-tools Maven2 Repository</name><url>http://scala-tools.org/repo-releases</url></pluginRepository><pluginRepository><id>cloudera-repos</id><name>Cloudera Repos</name><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></pluginRepository></pluginRepositories><!--dependencies模块的依赖信息scope:作用域,具体指含义如下compile:该依赖可以在整个项目中使用,参与打包部署,默认值,如:commons-fileuploadtest:该依赖只能在测试代码中使用,并且不参与打包部署的,如:junitprovided:该依赖编写源代码时需要,不参与打包部署,如:servlet-api、jsp-apiruntime:该依赖编写代码时不需要,运行时需要,参与打包部署,如:mysql-connectorsystem:表示使用本地系统路径下的jar包,需要和一个systemPath一起使用,如:ojdbc.jar--><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><!--<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.0.25</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>2.5.6</version></dependency>--><!--<dependency><groupId>org.apache.kudu</groupId><artifactId>kudu-client</artifactId><version>1.10.0-cdh6.3.1</version></dependency>--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark2.version}</version><!-- <scope>runtime</scope> --></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark2.version}</version><!-- <version>2.2.0</version> --></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fast.version}</version></dependency><!-- hive impala --><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>1.2.1</version><exclusions><exclusion><groupId>org.eclipse.jetty.aggregate</groupId><artifactId>jetty-all</artifactId></exclusion><exclusion><groupId>org.apache.hive</groupId><artifactId>hive-shims</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.mongodb.spark</groupId><artifactId>mongo-spark-connector_2.11</artifactId><version>2.3.0</version></dependency><dependency><groupId>org.mongodb</groupId><artifactId>mongo-java-driver</artifactId><version>3.8.0</version></dependency><dependency><groupId>org.mongodb</groupId><artifactId>casbah_2.10</artifactId><version>3.1.1</version><type>pom</type></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.4.0</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.1.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.46</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency><dependency><groupId>com.crealytics</groupId><artifactId>spark-excel_2.11</artifactId><version>0.12.2</version></dependency></dependencies></project>
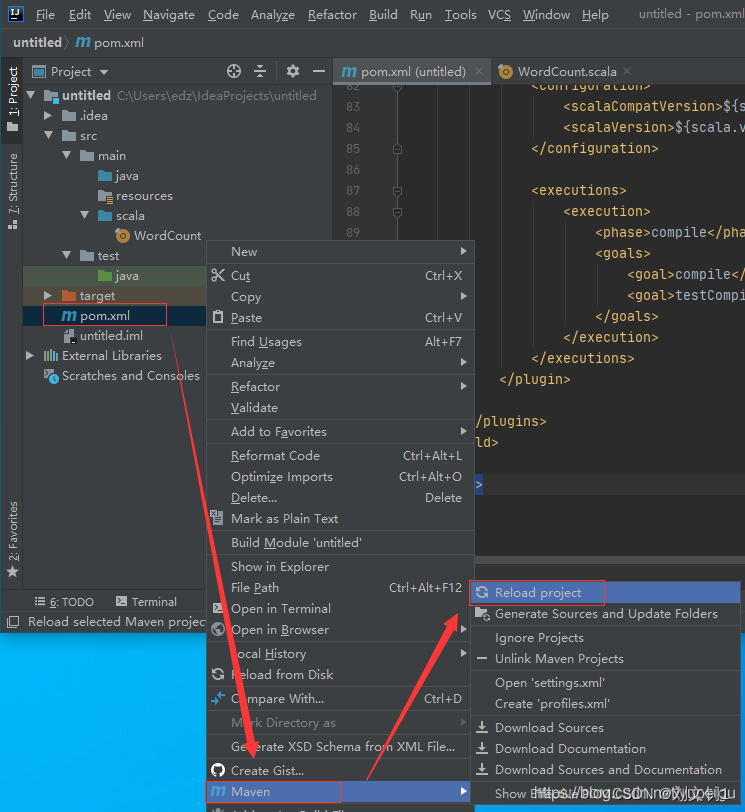
然后 右键项目中的 pom.xml 文件 -》Maven -》reload project 下载依赖包:
5.编写WordCount代码
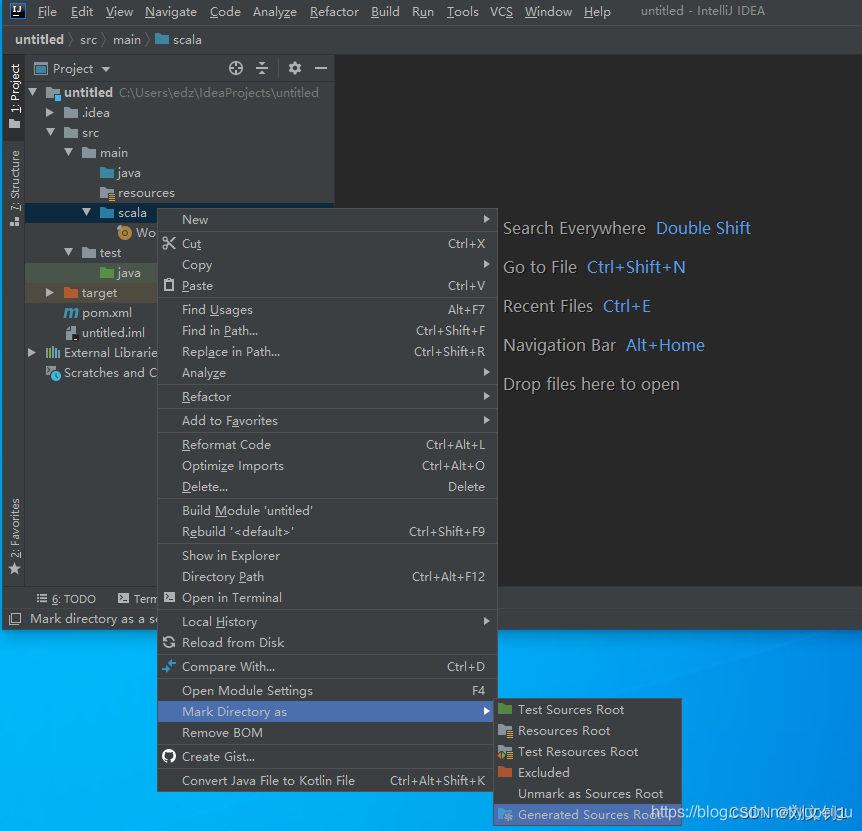
右键 Main 目录 -》 New -》 Directory ,目录名称为: scala
右键 scala 目录 -》Make Directory as -》Generate Sources Root
右键 scala 目录-》New -》scala class -》 object ,名称为:WordCoun
这里有个诡异的事情,我右键后,找不到scala的创建,然后使用file创建了个文件,文件名后缀.scala,执行后删除该文件,再右键新建的时候,可以创建scala的object了,很神奇!!!
6.出现的异常
1. 报错Exception in thread "main" java.lang.ClassNotFoundException: oracle.jdbc.driver.OracleDriver
写了一个scala来测试项目是否正常,主体逻辑是连接oracle,查询一个表,展示到工作台
但是报错:
Exception in thread "main" java.lang.ClassNotFoundException: oracle.jdbc.driver.OracleDriver
很奇怪,之前项目里面是可以正常使用的,但是新的不行,对比了以下,发现新项目的External Libraies中没有Oracle
试了手动在Project structure中导入,刷新Libraries等,依然报错。
并且发现本地仓库中有这个Oracle驱动类的。
最后,想到是不是pom中没加,手动加上,idea自动导入到了Libraries,程序可以正常运行了。
所以可见,External Libraries中的类是根据pom来导入的。
<dependency><groupId>com.oracle</groupId><artifactId>ojdbc6</artifactId><version>11.1.0.7.0</version></dependency>说一下猜测:
com.oracle:是该类的路径
ojdbc6:类名,但是时间上也是路径下的文件夹
11.1.0.7.0:版本,感觉也是类名下的文件夹
因为,这个驱动jar就是放在这个路径下的
E:\repository\com\oracle\ojdbc6\11.1.0.7.0
而 E:\repository 这个路径是我在file->setting->Build,Execution,Deployment->Build Tool->Maven的Local repository中设置的
相关文章:
IntelliJ IDEA创建一个spark的项目
在开始之前,需要说明的是 要跑通基本的wordcount程序,是不需要在windows上安装 hadoop 和spark的,因为idea在跑程序的时候,会按照 pom.xml配置文件,从指定的 repository源,按照properties指定的版本&#x…...

【数据库】数据库多种锁模式,共享锁、排它锁,更新锁,增量锁,死锁消除与性能优化
多种锁模式的封锁系统 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会…...
串口通信(1)-硬件知识
本文讲解串口通信的硬件知识。让读者快速了解硬件知识,为下一步编写代码做基础。 目录 一、概述 二、串口通信分类 2.1信息的传送方向进行分类 2.2同步通信和异步通信 三、串口协议 3.1 RS232 3.1.1 电气特性 3.1.2 连接器的机械特性 3.1.3 连接类型 3.1…...

越南语翻译,人工翻译哪个值得信赖?
近年来,随着中越两国的交流日益频繁,为了促进双方的交流与理解,市场上对越南语翻译的需求也日益增加。那么,如何做好越南语翻译,人工翻译哪家公司值得信赖呢? 据了解,中文翻译越南语是一项颇具挑…...
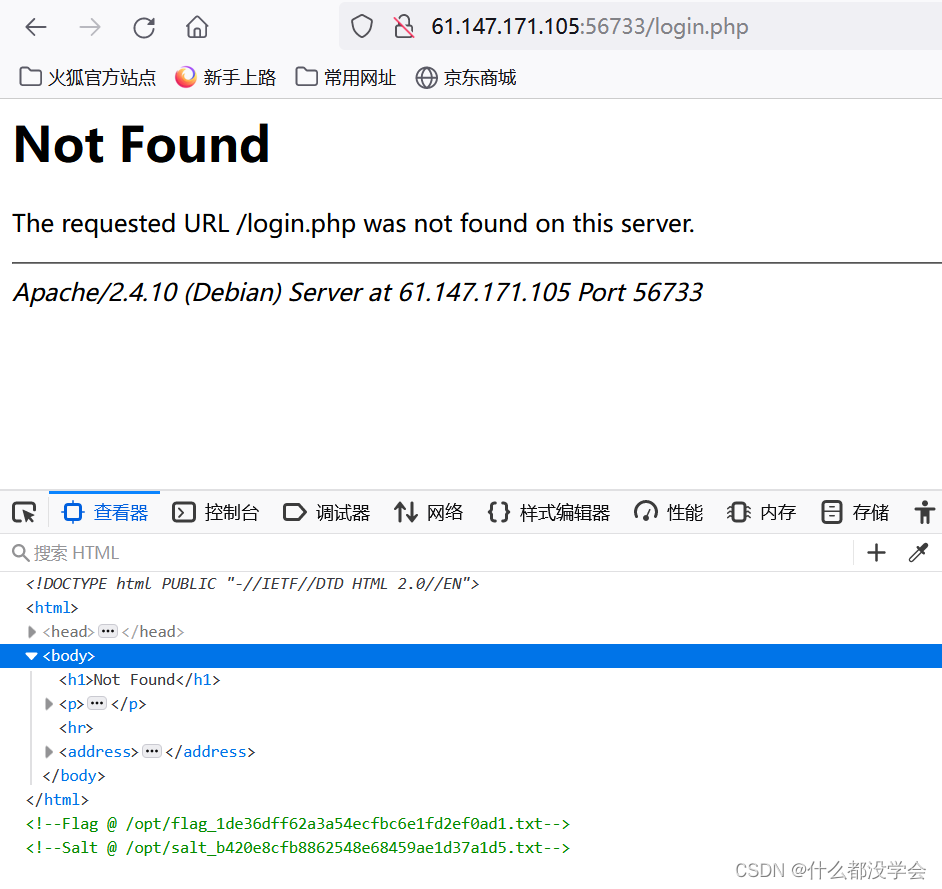
攻防世界题目练习——Web引导模式(五)(持续更新)
题目目录 1. FlatScience2. bug3. Confusion1 1. FlatScience 参考博客: 攻防世界web进阶区FlatScience详解 题目点进去如图,点击链接只能看到一些论文pdf 用dirsearch和御剑扫描出一些隐藏文件: robots.txt: admin.php: login.php: f…...

attack vector
攻击介质,是指可以攻击信息系统,破坏其安全性的特定路径、方法或是情景。 vector 此处并不是向量的意思。...

好看的早上问候语早安图片,今天最新唯美温馨祝福语
1、天气冷了,情谊不凉,树叶黄了,思念不忘,问候像一杯热茶,让人暖心!祝愿我们与健康平安同行!朋友们,大家早上好! 2、多一个人牵挂是一种幸福;多一个人相知是一…...

人体关键点检测2:Pytorch实现人体关键点检测(人体姿势估计)含训练代码
人体关键点检测2:Pytorch实现人体关键点检测(人体姿势估计)含训练代码 目录 人体关键点检测2:Pytorch实现人体关键点检测(人体姿势估计)含训练代码 1. 前言 2.人体关键点检测方法 (1)Top-Down(自上而下)方法 (2)Bottom-Up(自下而上)方法࿱…...

聚类分析 | Matlab实现基于谱聚类(Spectral Cluster)的数据聚类可视化
聚类分析 | Matlab实现基于谱聚类(Spectral Cluster)的数据聚类可视化 目录 聚类分析 | Matlab实现基于谱聚类(Spectral Cluster)的数据聚类可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现基于谱聚类(Spectral Cluster)的聚类算法可视化(完…...

【回眸】Tessy 单元测试软件使用指南(三)怎么打桩和指针测试
目录 前言 Tessy 如何进行打桩操作 普通桩 高级桩 手写桩 Tessy单元测试之指针相关测试注意事项 有类型的指针(非函数指针): 有类型的函数指针: void 类型的指针: 结语 前言 进行单元测试之后,但凡…...

关系型数据库-SQLite介绍
优点: 1>sqlite占用的内存和cpu资源较少 2>源代码开源,完全免费 3>检索速度上十几兆、几十兆的数据库sqlite很快,但是上G的时候最慢 4>管理简单,几乎无需管理。灵巧、快速和可靠性高 5>功能简…...
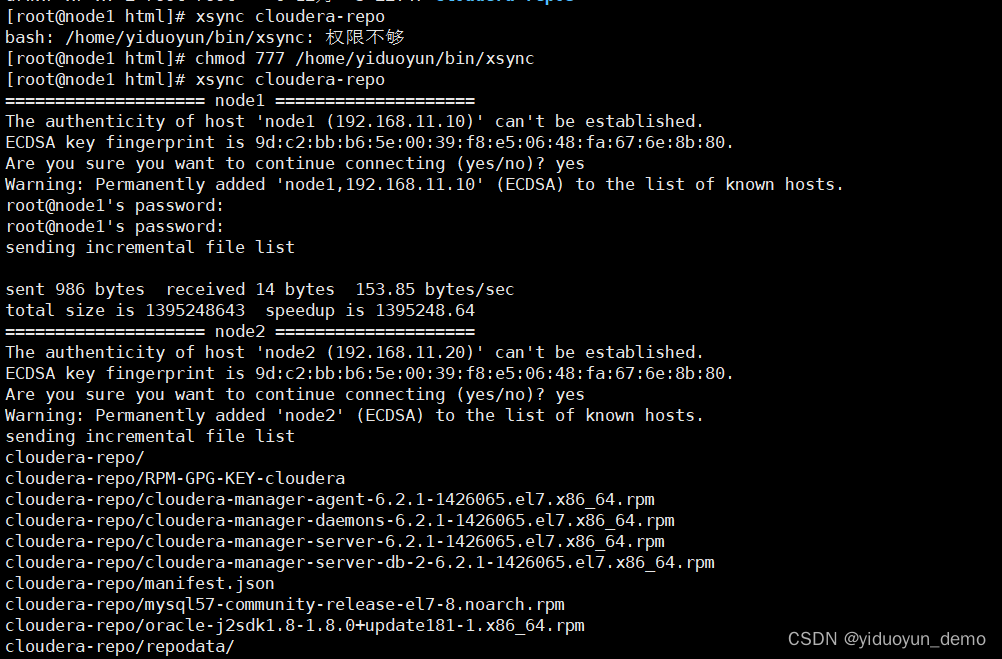
使用shell脚本将一台虚拟机上面数据分发到其他虚拟机上面xsync
目录 1,功能2,注意点3,shell脚本介绍4,bash内容 1,功能 使用shell脚本将一台虚拟机上面数据分发到其他虚拟机上面。 2,注意点 需要修改的地方:hadoop250 hadoop251 hadoop252 hadoop253 hado…...
绘制三维图形 固定管线)
OpenGL学习(二)绘制三维图形 固定管线
一.简单步骤 考虑顶点数据上色旋转 二.完整代码 myopenglwidget.h // An highlighted block #ifndef MYOPENGLWIDGET_H #define MYOPENGLWIDGET_H #include <QOpenGLWidget> #include <QOpenGLFunctions> #include <QOpenGLShaderProgram> #include <Q…...

微信小程序游戏:移动游戏市场的新兴力量
随着移动互联网的迅猛发展,微信小程序游戏已经成为现代数字娱乐领域的一股不可忽视的力量。这些游戏通过融入微信这一广泛使用的社交平台,为用户带来了全新的游戏体验。本文探讨了微信小程序游戏的特点、发展现状和未来趋势。 微信小程序游戏最大的特点之…...

Netflix Mac(奈飞客户端)激活版软件介绍
Netflix Mac(奈飞客户端)是一款流行的视频播放软件,专为Mac用户设计。它提供了大量的高质量电影、电视剧、纪录片和动画片资源,让用户可以随时随地观看自己喜欢的内容。 首先,Netflix Mac(奈飞客户端)以其简洁直观的用户界面而闻名。用户可以…...
Docker日志管理)
【Docker】进阶之路:(十)Docker日志管理
【Docker】进阶之路:(十)Docker日志管理 查看引擎日志查看容器日志清理容器日志日志驱动程序日志驱动程序概述local日志驱动json-file 日志驱动syslog 日志驱动日志驱动的选择 Docker 容器日志分为两类:引擎日志和容器日志。Docke…...

Lcss算法介绍与应用演示
Lcss算法介绍 LCSS(最长公共子序列,Longest Common Subsequence)算法是一种用于比较两个序列相似度的方法。它寻找两个序列中的最长子序列,这个子序列不需要在原始序列中连续,但必须保持原有序列中元素的相对顺序。LC…...

【SpringBoot】从入门到精通的快速开发指南
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《SpringBoot》。🎯🎯 &…...

每日一练【长度最小的子数组】
一、题目描述 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 二、题目解析 经…...

HTML 块级元素与行内元素有哪些以及注意、总结
行内元素和块级元素是HTML中的两种元素类型,它们在页面中的显示方式和行为有所不同。 块级元素(Block-level Elements): 常见的块级元素有div、p、h1-h6、ul、ol、li、table、form等。 块级元素会独占一行,即使没有…...

MiroFish 深度技术研究报告
1. 项目概述与核心定位 1.1 项目愿景与设计理念 1.1.1 群体智能镜像:映射现实世界的数字孪生 MiroFish 的核心愿景是构建 “映射现实的群体智能镜像”——一种能够精确复刻复杂社会系统动态的数字孪生系统。该项目由盛大集团战略支持与孵化,其技术路径区别于传统预测方法:…...

仪器设备显示屏选型:从交期与服务看适配价值
作为仪器设备厂商的客户品质人员,在显示屏选型与品质把关工作中,交期稳定性与全流程服务能力,是影响设备研发进度、量产交付与长期运维的核心要素,仪器设备行业研发迭代快、量产周期紧、售后要求高,显示屏供应商能否稳…...

从手动15秒到自动0.8秒:米哈游游戏扫码登录的智能革命
从手动15秒到自动0.8秒:米哈游游戏扫码登录的智能革命 【免费下载链接】MHY_Scanner MHY扫码登录器,支持从直播流抢码。 项目地址: https://gitcode.com/gh_mirrors/mh/MHY_Scanner 在直播抢码、多账号切换的激烈竞争中,你是否还在为手…...

告别资源获取繁琐,实现高效资源管理与效率提升
告别资源获取繁琐,实现高效资源管理与效率提升 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader res-downloader是一…...

如何通过CMLM-仲景中医AI大模型解决传统中医诊疗现代化难题
如何通过CMLM-仲景中医AI大模型解决传统中医诊疗现代化难题 【免费下载链接】CMLM-ZhongJing 首个中医大语言模型——“仲景”。受古代中医学巨匠张仲景深邃智慧启迪,专为传统中医领域打造的预训练大语言模型。 The first-ever Traditional Chinese Medicine large …...

【JavaSE-网络部分06】TCP 纯高性能优化机制:延迟应答・捎带应答【传输层】
上一期咱们把TCP稳如泰山的三大核心机制——滑动窗口、流量控制、拥塞控制彻底盘明白了📚。 这三者强强联手,既守住了可靠传输的底线,又大幅提升传输效率,让数据既稳又快地跑在网络里。 但TCP对性能的“抠搜”可不止于此…...

华为云CCE内网部署Nacos集群实战:不用Helm,纯页面操作搞定镜像上传与配置
华为云CCE内网部署Nacos集群实战:纯控制台操作指南 在企业级容器化部署场景中,内网环境下的服务部署往往面临特殊挑战。当安全合规要求严格限制外网访问时,传统依赖公网镜像仓库和Helm工具的部署方案便不再适用。本文将详细介绍如何在华为云…...
)
保姆级教程:用Vue 3 + Cesium 1.107 加载倾斜摄影模型(从OSGB到3DTiles全流程)
从OSGB到Web三维:Vue 3与Cesium 1.107的倾斜摄影实战指南 当我们需要在网页中展示真实世界的三维场景时,倾斜摄影技术提供了绝佳的解决方案。这种通过航拍获取多角度影像并重建三维模型的技术,已经成为数字孪生、智慧城市等领域的标配。但将专…...
Pixel Script Temple多场景落地:政务宣传短视频、乡村振兴纪录片脚本生成
Pixel Script Temple多场景落地:政务宣传短视频、乡村振兴纪录片脚本生成 1. 专业剧本创作工具介绍 Pixel Script Temple(像素剧本圣殿)是一款基于Qwen2.5-14B-Instruct大模型深度优化的专业剧本创作工具。它将先进的AI推理能力与独特的8-B…...

Ollama+GPT-OSS-20B黄金组合:无需网络,随时可用的智能助手
OllamaGPT-OSS-20B黄金组合:无需网络,随时可用的智能助手 1. 为什么需要本地化AI助手 在当今AI技术快速发展的时代,云端AI服务虽然方便,但也存在诸多限制:网络依赖、隐私担忧、API费用高昂、响应延迟等问题。对于需要…...