Mysql大数据量删除
Mysql大数据量删除
在一些操作中,可能需要清理一下积压的数据,如果数据量小的话自然没有问题,但是如果是个大数据量的问题,那么就该考虑一个合适的办法了。
在清理大数据量的时候需要考虑是清理部分数据还是清理所有数据,这两种场景有着不同的策略。
注意:本次测试与方法均针对mysql5.7,存储引擎为InnoDB
清理表中的所有数据
清空表数据,建议直接使用truncate,效率上truncate远高于delete,truncate不走事务,不会锁表,也不会产生大量日志写入日志文件,我们访问log执行日志可以发现每次delete都有记录。truncate table table_name 会立刻释放磁盘空间,并重置auto_increment的值,delete 删除不释放磁盘空间,insert会覆盖之前的数据上,因为我们创建表的时候有一个创建版本号。
delete删除数据的原理:(delete属于DML语句)
表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放!!!
这种删除表的优点是:支持回滚,后悔了可以恢复数据,可以删除单条数据
缺点:删除效率比较低
效率比较高,表被一次截断,物理删除
优点:快速,不走事务,不会锁表,也不会产生大量日志写入日志文件
缺点:不支持回滚,只能删除表中所有数据,不能删单条数据
如果说公司项目里面有一张大表,数据非常多,几亿条记录:
删除的时候,使用delete,也许执行一个小时才能删除完,效率极其低;
可以选择使用truncate删除表中的数据。只需要不到1s的时间就能删除结束,效率较高。
但是使用truncate之前,必须仔细询问客户是否真的需要删除,并警告删除之后不可恢复!!!
删除表操作:
drop table 表名;// 删除表,不是删除表中的数据
清理表中部分数据
情景一:如果删除的数据占据表的绝大部分
这是mysql官方文档中提到的一种情形,这里直接复制过来
https://dev.mysql.com/doc/refman/8.0/en/delete.html
如果要从大型表中删除许多行,则可能会超出表的锁定表大小InnoDB。为了避免这个问题,或者只是为了最大限度地减少表保持锁定的时间,以下策略(根本不使用 DELETE)可能会有所帮助:
选择不需要删除的行到一个与原表结构相同的空表中:
INSERT INTO t_copy SELECT * FROM t WHERE … ;
用于RENAME TABLE以原子方式将原始表移开并将副本重命名为原始名称:
RENAME TABLE t TO t_old, t_copy TO t;
删除原始表:
DROP TABLE t_old;
总体来说就是:建立一个相同的表,把不删除得数据复制的新表,然后将表重命名倒换,最后删掉旧表
情形二:数据是主键索引
删除大表的多行数据时,会超出innod block table size的限制,最小化的减少锁表的时间的方案是:
1、选择不需要删除的数据,并把它们存在一张相同结构的空表里
2、重命名原始表,并给新表命名为原始表的原始表名
3、删掉原始表
每次删除固定的数据量
批量删除(每次限定一定数量),然后循环删除直到全部数据删除完毕;同时key_buffer_size 由默认的8M提高到512M
DELETE FROM test_table WHERE value=12;
如果要用order by 必须要和 limit 联用,否则被优化掉。然后分多次执行就可以把这些记录成功删除。
注意:
执行大批量删除的时候注意要使用上limit。因为如果不用limit,删除大量数据很有可能造成死锁。
如果delete的where语句不在索引上,可以先找主键,然后根据主键删除数据库。
平时update和delete的时候最好也加上limit 1 来防止误操作。
暂时删除索引
在My SQL数据库使用中,有的表存储数据量比较大,达到每天三百万条记录左右,此表中建立了三个索引,这些索引都是必须的,其他程序要使用。由于要求此表中的数据只保留当天的数据,所以每当在凌晨的某一时刻当其他程序处理完其中的数据后要删除该表中昨天以及以前的数据,使用delete删除表中的上百万条记录时,MySQL删除速度非常缓慢,每一万条记录需要大概4分钟左右,这样删除所有无用数据要达到八个小时以上,这是难以接受的。
查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的,于是删除掉其中的两个索引后测试,发现此时删除速度相当快,一百万条记录在一分钟多一些,可是这两个索引其他模块在每天一次的数据整理中还要使用,于是想到了一个折中的办法:
在删除数据之前删除这两个索引,此时需要三分钟多一些,然后删除其中无用数据,此过程需要不到两分钟,删除完成后重新创建索引,因为此时数据库中的数据相对较少,约三四十万条记录(此表中的数据每小时会增加约十万条),创建索引也非常快,约十分钟左右。这样整个删除过程只需要约15分钟。对比之前的八个小时,大大节省了时间。
强制指定索引
分表
如果数据量过大,可以考虑分表,这个分表策越需要根据实际情况来决定,比如每月建立一个表,这个表只存储当月的数据,下个月之后直接将此表truncate。
表分区,直接删除过期日期所在的分区
官方文档 https://dev.mysql.com/doc/refman/5.7/en/alter-table-partition-operations.html
MySQL表分区有几种方式,包括RANGE、KEY、LIST、HASH,详情请参见官方文档。应用场景:日期在变化,所以不适合用RANGE设置固定的分区名称,HASH分区更符合此处场景
分区表定义,SQL语句如下:
ALTER TABLE table_name PARTITION BY HASH(TO_DAYS(cnt_date)) PARTITIONS 7;
TO_DAYS将日期(必须为日期类型,否则会报错:Constant, random or timezone-dependent expressions in (sub)partitioning function are not allowed)转换为天数(年月日总共的天数),然后HASH;建立7个分区。实际上,就是 days MOD 7 。
异步删除
前置数据
在这之前首先要建立一个存储过程可表来做测试
建立一个表:
CREATE TABLE test_table (starttime DATETIME,endtime DATETIME,resourceid INT,value INT,PRIMARY KEY (resourceid),INDEX idx_starttime_endtime_resourceid (starttime, endtime, resourceid)
);
定义了主键 resourceid,通过 PRIMARY KEY 关键字指定。
然后,我们使用 INDEX 关键字创建了一个名为 idx_starttime_endtime_resourceid 的联合索引,该索引包含了 starttime、endtime 和 resourceid 列。注意,INDEX 关键字在MySQL中用于创建普通索引。
DELIMITER //CREATE PROCEDURE insert_data(IN num_records_to_generate INT)
BEGINDECLARE i INT DEFAULT 1;DECLARE start_time DATETIME DEFAULT '2023-06-29 00:00:00';WHILE i <= num_records_to_generate DOINSERT INTO test_table (starttime, endtime, value)VALUES (start_time, DATE_ADD(start_time, INTERVAL 1 SECOND), 12);SET start_time = DATE_ADD(start_time, INTERVAL 1 SECOND);SET i = i + 1;END WHILE;
END //DELIMITER ;在这个存储过程中,是以endtime作为变量来测试的。
调用方式为
call inser_data(插入数目)
mysql> call insert_data(1000);
Query OK, 1 row affected (4.18 sec)
mysql> select count(*) from test_table;
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.00 s
引用文献
https://blog.csdn.net/jike11231/article/details/126551510
https://www.cnblogs.com/NaughtyCat/p/one-fast-way-to-delete-huge-data-in-mysql.html
相关文章:

Mysql大数据量删除
Mysql大数据量删除 在一些操作中,可能需要清理一下积压的数据,如果数据量小的话自然没有问题,但是如果是个大数据量的问题,那么就该考虑一个合适的办法了。 在清理大数据量的时候需要考虑是清理部分数据还是清理所有数据…...

【python中类的介绍】
python中类的介绍 在Python中,定义类需要使用关键字 class类名通常使用大写字母开头,举例: class MyClass:pass解释:定义了一个MyClass的空类。 1、python中类定义 “”" 类中可以定义属性和方法。 1、属性是类的数据成…...
PO模式在selenium自动化测试框架有什么好处
PO模式是在UI自动化测试过程当中使用非常频繁的一种设计模式,使用这种模式后,可以有效的提升代码的复用能力,并且让自动化测试代码维护起来更加方便。 PO模式的全称叫page object model(POM),有时候叫做 p…...

智能优化算法应用:基于斑马算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于斑马算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于斑马算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.斑马算法4.实验参数设定5.算法结果6.参考文献7.MATLAB…...
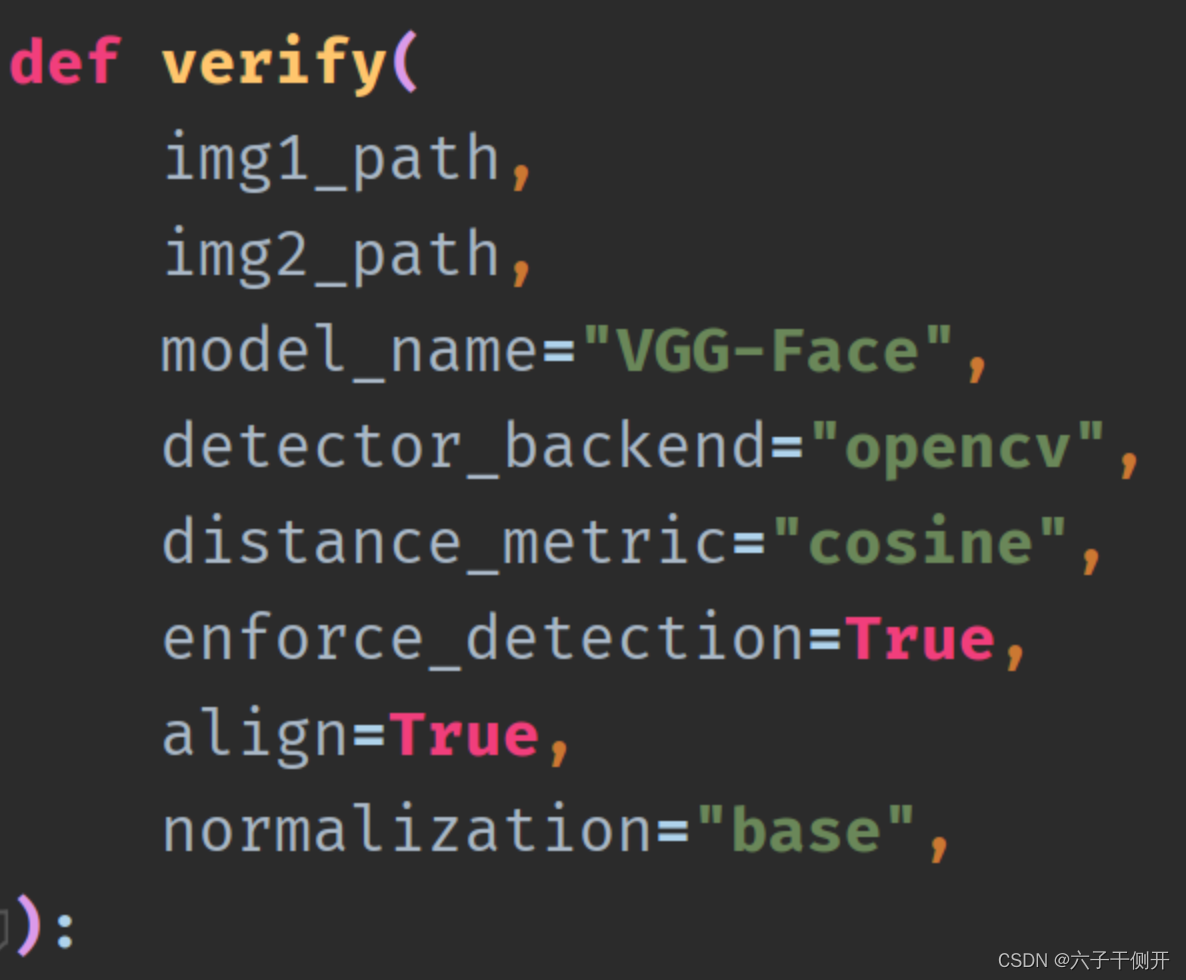
deepface:实现人脸的识别和分析
deepface介绍 deepface能够实现的功能 人脸检测:deepface 可以在图像中检测出人脸的位置,为后续的人脸识别任务提供基础。 人脸对齐:为了提高识别准确性,deepface 会将检测到的人脸进行对齐操作,消除姿态、光照和表…...
层的作用)
Pytorch当中nn.Identity()层的作用
在深度学习中,nn.Identity() 是 PyTorch 中的一个层(layer)。它实际上是一个恒等映射,不对输入进行任何变换或操作,只是简单地将输入返回作为输出。 通常在神经网络中,各种层(比如全连接层、卷…...

linux课程第二课------命令的简单的介绍2
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

【PTA刷题】 求子串(代码+详解)
【PTA刷题】 求子串(代码详解) 题目 请编写函数,求子串。 函数原型 char* StrMid(char *dst, const char *src, int idx, int len);说明:函数取源串 src 下标 idx 处开始的 len 个字符,保存到目的串 dst 中,函数值为 dst。若 len…...

初识Dockerfile
Dockerfile:创建镜像,创建自定义的镜像 包括配置文件,挂载点,对外暴露的端口,设置环境变量 Docker的创建镜像方式: 1.基于已经镜像进行创建 根据官方号已提供的镜像源,创建镜像,然…...
)
Python入门第2篇(pip、字符串、方法、json、io操作)
目录 pip包管理器 字符串 方法 json 文件操作 pip包管理器 包管理器类似.NET下的nuget,主要用于管理引用依赖项。 安装Python的时候,已经默认安装了pip包管理器,因此无需单独安装 cmd,输入:pip --version 显示…...
IntelliJ IDEA 智能(AI)编码工具插件
文章目录 通义灵码-阿里CodeGeeX-清华大学智谱AIBitoAmazon CodeWhisperer-亚马逊GitHub Copilot - 买不起CodeiumAIXcoder 仅仅自动生成单元测试功能 TestMe插件(免费)仅仅是模板填充,不智能。 Squaretest插件(收费)…...

Java编程中通用的正则表达式(二)
正则表达式,又称正则式、规则表达式、正规表达式、正则模式或简称正则,是一种用来匹配字符串的工具。它是一种字符串模式的表示方法,可以用来检索、替换和验证文本。正则表达式是一个字符串,它描述了一些字符的组合,这…...
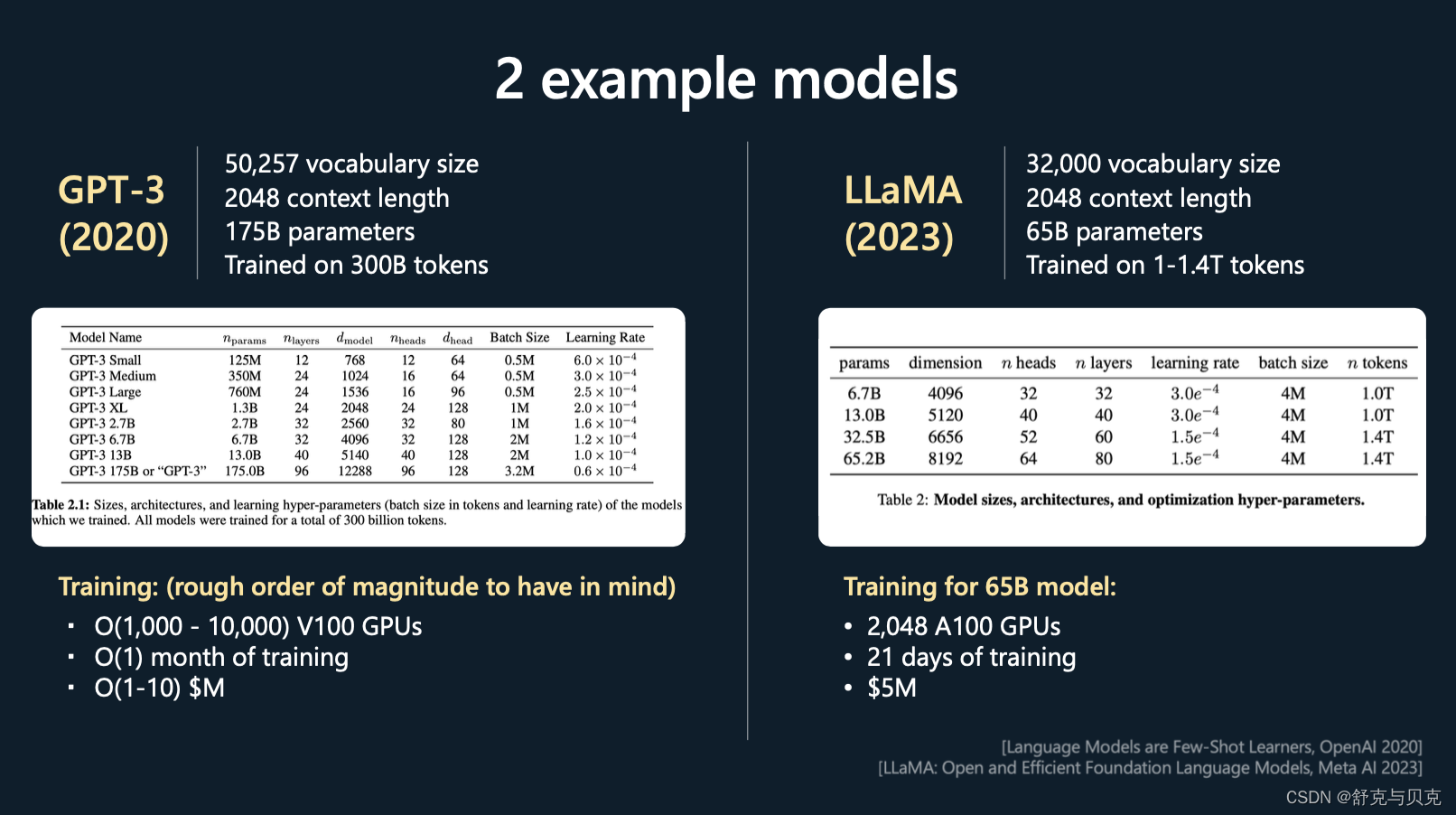
[GPT]Andrej Karpathy微软Build大会GPT演讲(上)--GPT如何训练
前言 OpenAI的创始人之一,大神Andrej Karpthy刚在微软Build 2023开发者大会上做了专题演讲:State of GPT(GPT的现状)。 他详细介绍了如何从GPT基础模型一直训练出ChatGPT这样的助手模型(assistant model)。作者不曾在其他公开视频里看过类似的内容,这或许是OpenAI官方…...
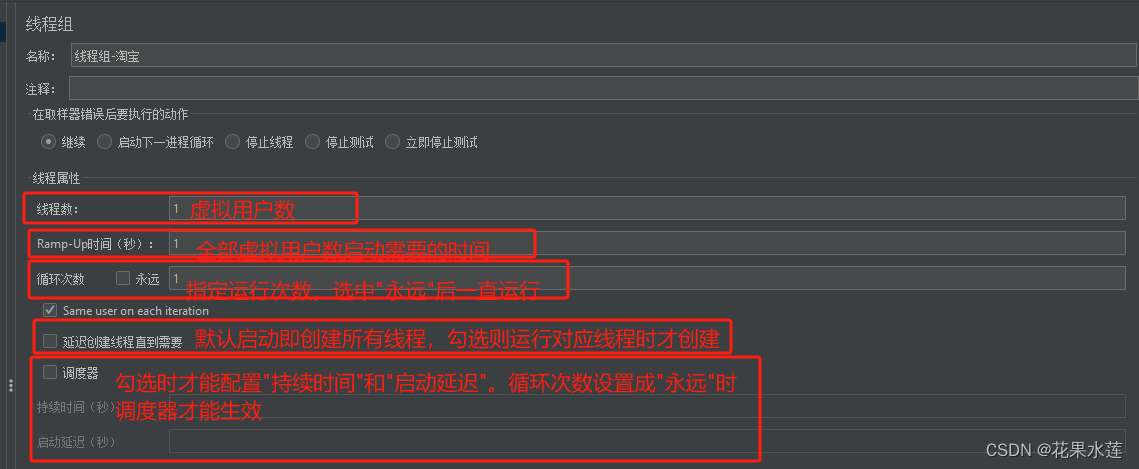
接口测试-Jmeter使用
一、线程组 1.1 作用 线程组就是控制Jmeter用于执行测试的一组用户 1.2 位置 右键点击‘测试计划’-->添加-->线程(用户)-->线程组 1.3 特点 模拟多人操作线程组可以添加多个,多个线程组可以并行或者串行取样器(请求)和逻辑控制器必须依赖线程组才能…...

十大排序(含java代码)
一、冒泡排序 冒泡排序就是把小的元素往前调或者把大的元素往后调,比较是相邻的两个元素比较,交换也发生在这两个元素之间。(类似于气泡上浮过程) 动图演示 代码实现 int a[]{2,5,3,7,4,8};for (int i 0; i < a.length; i) {f…...

js基础:简介、变量与数据类型、流程循环控制语句、数组及其api
JS基础:简介、变量与数据类型、流程循环控制语句、数组及其api 一、简介 1、js概述 tip:JavaScript是什么? 有什么作用? JavaScript(简称JS)是一种轻量级的、解释性的编程语言,主要用于在网页…...
kubeadm搭建单master多node的k8s集群--小白文,图文教程
参考文献 K8S基础知识与集群搭建 kubeadm搭建单master多node的k8s集群—主要参考这个博客,但是有坑,故贴出我自己的过程,坑会少很多 注意: 集群配置是:一台master:zabbixagent-k8smaster,两台…...

CSS层叠样式表一
1,CSS简介 1.1 CSS-网页的美容师 CSS的主要使用场景就是美化网页,布局页面的 CSS也是一种标记语言 CSS主要用于设置HTML页面中的文本内容(字体,大小,对齐方式等)、图片的外形(宽高、边框样式…...

【等保】安徽省等保测评机构名单看这里!
随着互联网技术的飞速发展,网络安全已成为国家安全、社会稳定的重要保障,因此我们严格贯彻落实等保政策。等保测评机构在等保制度执行过程中发挥着重要的作用。现在我们就来看看安徽省等保测评机构有哪些? 【等保】安徽省等保测评机构名单看…...
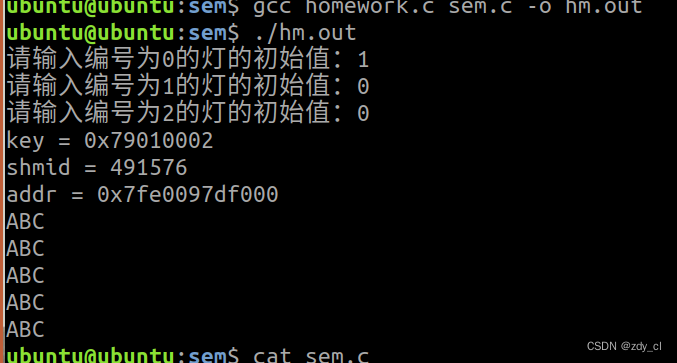
学习IO的第八天
作业:使用信号灯循环输出ABC sem.c #include <head.h>union semun {int val; /* Value for SETVAL */struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */unsigned short *array; /* Array for GETALL, SETALL */struct seminf…...

嵌入式JPEG解码库JPEGDecoder深度解析
1. JPEGDecoder 库深度技术解析:面向嵌入式显示系统的轻量级 JPEG 解码实践1.1 库定位与工程价值JPEGDecoder 是一个专为资源受限嵌入式平台设计的轻量级 JPEG 解码库,其核心目标并非替代 PC 级全功能解码器,而是在 MCU 级别实现“够用、可控…...

PostgreSQL 二进制安装全流程详解
1. 为什么选择二进制安装PostgreSQL 第一次接触PostgreSQL时,我也纠结过到底该用哪种安装方式。源码编译、包管理器、二进制安装各有优劣,但实测下来,二进制安装是最适合新手的方案。它既不像源码编译那样需要处理复杂的依赖关系,…...

2026大模型训练全景,从底座到上线,决定AI体验的完整链路
在人工智能飞速发展的2026年,大众对大模型的认知早已不再停留在“参数越大越强”的简单层面。我们日常使用AI助手时感受到的流畅对话、精准指令响应、高效工具调用,甚至稳定可靠的输出风格,背后都不是单一的预训练环节在支撑,而是…...
)
保姆级教程:手把手教你用Aruba Instant On APP搞定家庭Wi-Fi(从开箱到上网)
保姆级教程:手把手教你用Aruba Instant On APP搞定家庭Wi-Fi(从开箱到上网) 刚拿到Aruba Instant AP时,我盯着那个白色小盒子发了十分钟呆——作为一个连路由器都没碰过的纯小白,这玩意儿真的能让我家Wi-Fi快起来&…...

Windows系统优化与驱动管理完全指南:释放磁盘空间并解决驱动冲突
Windows系统优化与驱动管理完全指南:释放磁盘空间并解决驱动冲突 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否遇到过系统磁盘空间莫名减少?设备管理器中…...

Genshin Impact 模型导入工具完全指南
Genshin Impact 模型导入工具完全指南 【免费下载链接】GI-Model-Importer Tools and instructions for importing custom models into a certain anime game 项目地址: https://gitcode.com/gh_mirrors/gi/GI-Model-Importer 一、模型导入工具核心功能解析 Genshin Im…...

3步构建企业级AI应用:无代码开发新范式
3步构建企业级AI应用:无代码开发新范式 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-Workflow …...

【带AI】基于SpringBoot+Vue图书管理系统设计与实现+文档+指导搭建视频
特色实现QQ邮箱注册/找回密码,WebSocket实时推送,协同过滤算法图书推荐,接入DeepSeek大模型技术栈 1.后端:Spring Boot2、MyBatis、Java Mail(QQ SMTP)、WebSocket、DevTools、Spring Security Crypto&…...

CBAM:轻量级注意力机制在CNN中的高效集成与应用
1. CBAM:让CNN学会"看重点"的黑科技 第一次听说CBAM这个名词时,我还以为是什么新型环保政策(笑)。后来才发现,这其实是计算机视觉领域的一个"小而美"的发明——Convolutional Block Attention Mod…...

BilibiliDown:高效下载B站视频的3步实战指南
BilibiliDown:高效下载B站视频的3步实战指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibil…...