Logstash输入Kafka输出Es配置
Logstash介绍
Logstash是一个开源的数据收集引擎,具有实时管道功能。它可以从各种数据源中动态地统一和标准化数据,并将其发送到你选择的目的地。Logstash的早期目标主要是用于收集日志,但现在的功能已经远远超出这个范围。任何事件类型都可以通过Logstash进行分析,通过输入、过滤器和输出插件进行转换。
Logstash的工作原理是使用管道方式进行日志的搜集处理和输出。这个管道包括三个阶段:输入、处理和输出。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
Logstash的输入支持各种选择,可以同时从众多常用来源捕捉事件,如日志、指标、Web应用、数据存储以及各种AWS服务等。在数据从源传输到存储库的过程中,Logstash的过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash的输出也可以根据需要选择不同的存储方式,除了Elasticsearch作为首选输出方向外,还有其他的输出选择。
Logstash是一个强大的开源工具,可以用于实时处理和转换来自各种数据源的数据,为数据分析和商业决策提供支持。
Kafka介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。它是一种高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka是一个可行的解决方案。
Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Es介绍
ES指的是Elasticsearch,它是一个基于RESTful web接口并且构建在Apache Lucene之上的开源分布式搜索引擎。它还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索。它能够横向扩展至数以百计的服务器存储以及处理PB级的数据,可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机。
Logstash输入输出配置
Logstash的输入输出配置主要是针对其输入和输出插件进行设置。以下是一些常见的输入和输出插件的配置示例:
输入配置:
- file:从文件读取日志信息,例如:
input {file {path => "/var/log/error.log"type => "error"start_position => "beginning"}
}
- stdin:从标准输入读取日志信息,例如:
input {stdin {}
}
- syslog:从系统日志读取日志信息,例如:
input {syslog {type => "syslog"}
}
输出配置:
- stdout:将日志信息输出到标准输出,例如:
output {stdout {}
}
- elasticsearch:将日志信息输出到Elasticsearch集群,例如:
output {elasticsearch {hosts => "localhost:9200"index => "myindex"}
}
以上是一些常见的输入输出插件配置示例,Logstash还支持其他多种输入输出插件,可以根据具体需求进行选择和配置。
Logstash输入Kafka输出Es配置
Logstash的输入配置可以通过Kafka插件从Kafka中读取数据,输出配置可以通过Elasticsearch插件将数据写入Elasticsearch集群。以下是一个示例配置:
input {kafka {bootstrap_servers => "your_kafka_server:9092"client_id => "your_client_id"group_id => "your_group_id"auto_offset_reset => "latest"consumer_threads => 1decorate_events => truetopics => ["your_topic"]}
}output {if [@metadata][kafka][topic] == "your_topic" {elasticsearch {hosts => "your_elasticsearch_server:9200"index => "your_index"timeout => 300}}
}
在这个配置中,Logstash通过Kafka插件从指定的Kafka服务器和主题中读取数据,然后通过Elasticsearch插件将数据写入指定的Elasticsearch索引。你可以根据实际情况修改配置中的参数,例如Kafka服务器的地址、客户端ID、组ID、主题等。
- 上面的配置参数的含义如下所示:
- bootstrap_servers: 这是Kafka服务器的地址和端口。你需要提供Kafka集群中至少一个服务器的地址。
- client_id: 这是客户端的唯一标识符,用于标识连接到Kafka集群的客户端。
- group_id: 这是消费者组的ID。如果你有多个Logstash实例读取同一个Kafka主题,并且你想将它们作为一个消费者组来处理,那么你需要使用这个参数。
- auto_offset_reset: 这个参数决定了当Logstash无法找到其之前读取的偏移量时应该怎么做。设置为"latest"意味着从最新的记录开始读取。
- consumer_threads: 这是用于消费Kafka消息的线程数。增加线程数可以加快数据读取速度,但也会增加CPU和内存的使用。
- decorate_events: 如果设置为true,Logstash会为每个事件添加额外的元数据,例如Kafka主题和分区信息。
- topics: 这是Logstash要读取的Kafka主题列表。
- if [@metadata][kafka][topic] == “your_topic”: 这是一个条件语句,用于确定是否将事件发送到Elasticsearch。只有当事件的主题与指定的"your_topic"匹配时,事件才会被发送到Elasticsearch。
- hosts: 这是Elasticsearch集群的地址和端口。
- index: 这是Logstash将数据写入Elasticsearch的索引名称。
- timeout: 这是Logstash与Elasticsearch集群通信的超时时间(以秒为单位)。
这些参数可以根据你的具体需求进行调整,以满足你的数据收集和处理需求。
java发送消息到Kafka示例
Apache Kafka是一种分布式流处理平台,你可以使用它来处理各种数据。以下是使用Java向Kafka发送消息的示例代码:
首先,你需要添加Apache Kafka的依赖到你的项目中。如果你正在使用Maven,那么你可以在pom.xml文件中添加如下依赖:
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.0</version></dependency>
</dependencies>
以下是使用Java发送消息的示例代码:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class ProducerDemo {public static void main(String[] args) {// 1. 配置生产者客户端参数Properties props = new Properties();// Kafka集群地址props.put("bootstrap.servers", "your_kafka_server:9092");// 消息ack模式: all表示消息被leader和follower都写入后才返回ack, -1表示只被leader写入就返回ackprops.put("acks", "all");// 重试次数props.put("retries", 0);// 批量发送大小props.put("batch.size", 16384);// 发送延时,用于控制producer发送请求的延迟时间,可以提高吞吐量props.put("linger.ms", 1);// 缓冲区大小props.put("buffer.memory", 33554432);// key序列化类props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");// value序列化类props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 2. 创建生产者对象,传入配置参数Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 100; i++) {// 3. 创建消息对象,指定topic、消息key和消息体valueProducerRecord<String, String> record = new ProducerRecord<>("your_topic", "key" + i, "value" + i);// 4. 发送消息到Kafka集群,并获取返回结果RecordMetadata metadata = producer.send(record).get();// 打印结果,发送是否成功,以及发送到的分区和offset等信息System.out.printf("offset = %d, partition = %d%n", metadata.offset(), metadata.partition());}// 5. 关闭生产者对象,释放资源producer.close();}
}
在这个示例中,我们创建了一个名为ProducerDemo的类,这个类使用Kafka的生产者API发送消息到名为"my-topic"的主题。请注意你需要替换"bootstrap.servers"属性的值为你的Kafka集群的实际地址。如果你的集群在本地运行,并且使用的是默认的端口,那么你可以使用"localhost:9092"。
Logstash常用输入插件
Logstash的常用输入插件包括以下几种:
- file:该插件可以从文件中读取事件。它使用了FileWatch库来监听文件变化,并跟踪被监听的日志文件的当前读取位置,从而确保不会漏过任何数据。
- stdin:该插件是标准的输入插件,能够从命令行中读取事件。
- TCP:从TCP连接中读取数据。
- UDP:从UDP套接字中读取数据。
- Redis:从Redis中读取数据。
- JDBC:从关系型数据库中读取数据。
- HTTP:从HTTP服务器中读取数据。
Logstash常用输出插件
Logstash常用的输出插件包括以下几种:
- Elasticsearch:将日志数据输出到Elasticsearch,用于后续的搜索和分析。
- Kafka:将日志数据发送到Kafka集群,供其他消费者使用。
- File:将日志数据输出到文件中,便于后续查看和审计。
- Gelf:将日志数据输出到Gelf兼容的服务器,用于远程监控和报警。
- Fluentd:将日志数据输出到Fluentd,用于统一日志收集和转发。
拓展
Logstash使用指南
Kafka使用指南
Elasticsearch使用指南

相关文章:
Logstash输入Kafka输出Es配置
Logstash介绍 Logstash是一个开源的数据收集引擎,具有实时管道功能。它可以从各种数据源中动态地统一和标准化数据,并将其发送到你选择的目的地。Logstash的早期目标主要是用于收集日志,但现在的功能已经远远超出这个范围。任何事件类型都可…...

Bash脚本处理ogg、flac格式到mp3格式的批量转换
现在下载的许多音乐文件是flac和ogg格式的,QQ音乐上下载的就是这样的,这些文件尺寸比较大,在某些场合使用不便,比如在车机上播放还是mp3格式合适,音质这些在车机上播放足够了,要求不高。比如本人就喜欢下载…...

Android 依据Build相关信息判断机型
Android 依据Build相关信息判断机型 本文主要通过Build的相关信息获取机型,目前机型判断的较少,后续继续维护更新 public static String parseBuild() {StringBuilder sb new StringBuilder();String deriveFingerprint Build.FINGERPRINT;String manufacturer Build.MANU…...
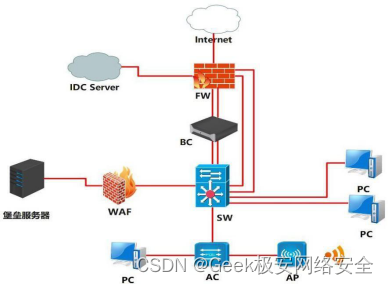
2024年甘肃省职业院校技能大赛信息安全管理与评估赛项一阶段样题一
2024年甘肃省职业院校技能大赛高职学生组电子与信息大类信息安全管理与评估赛项样题一 竞赛需要完成三个阶段的任务,分别完成三个模块,总分共计 1000分。三个模块内容和分值分别是: 1.第一阶段:模块一 网络平台搭建与设备安全防…...
ARM:作业3
按键中断代码编写 代码: key_it.h #ifndef __KEY_IT_H__ #define __KEY_IT_H__#include "stm32mp1xx_gpio.h" #include "stm32mp1xx_exti.h" #include "stm32mp1xx_rcc.h" #include "stm32mp1xx_gic.h"void key1_it_config(); voi…...
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含python、JS工程源码)+数据集+模型(二)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境Jupyter Notebook环境Pycharm 环境微信开发者工具OneNET云平台 相关其它博客工程源代码下载其它资料下载 前言 本项目基于Keras框架,引入CNN进行模型训练,采用Dropout梯度…...

*上位机的定义
上位机是指在分布式控制系统中,负责监控和控制下位机(也称为远程终端设备)的计算机或者计算机网络。它通常是一个高性能的计算设备,运行着特定的监控软件,用于实时监测、控制和管理下位机设备。 上位机负责与各个下位…...
架构LAMP
目录 1.什么是LAMP 2.LAMP组成及作用 3.搭建Apache httpd服务 4.编译安装mysqld 服务 5.编译安装PHP 解析环境 6.安装论坛 1.什么是LAMP LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务…...

vue实现浏览器不同分辨率下的不同样式,css的媒体查询与js判断当前浏览器宽度
前言: 实现实现浏览器不同分辨率下的不同样式的方法很多,这里整理两种,1个是css的媒体查询来实现,另一个是js判断当前浏览器的宽度,然后动态给他添加不同的class名,或者动态用style修改样式,添加…...
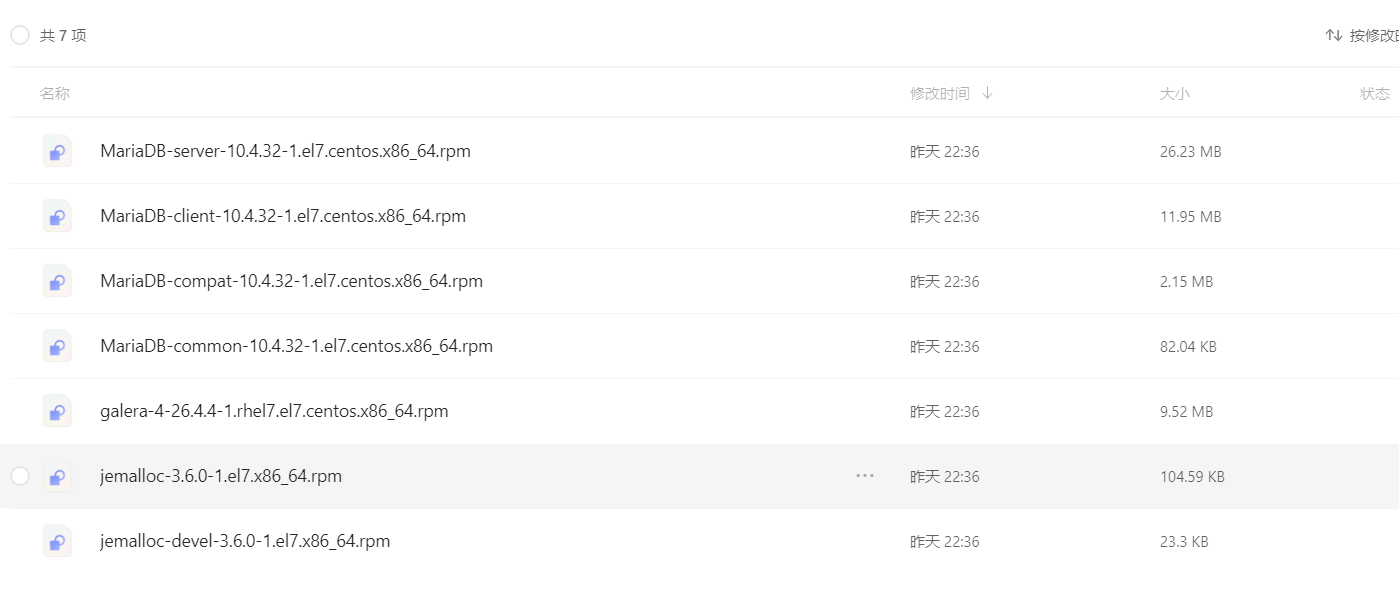
CentOS7 安装包 MariaDB 10.4.x
CentOS7 安装包 MariaDB 10.4.x 统一 MariaDB安装包 https://www.alipan.com/s/fvLg3gN7LPX 提取码: nh81 打开「阿里云盘」...

js中箭头函数简单介绍
1.箭头函数是 ES6 中新增的一种函数定义方式, 简单举例为 var nameA function(a){return a} 可以用箭头函数简化为 var nameA a >a; 返回的是你输入的值 比如 nameA(5) 返回的就是5 nameA(2) 返回的就是2 以上两个表达的含义是一样的。nameA为名字 2.…...

分布式ID服务实践
背景 分布式场景下需要一个全局 ID 来标识唯一性,比如在单数据库时通过表唯一主键即可实现唯一 ID,分库分表时就需要全局唯一 ID。 业务对唯一 ID 的要求如下: 全局唯一性 不能出现重复的 ID 号,既然是唯一标识,这…...

YOLOv8改进 | 2023主干篇 | 利用RT-DETR特征提取网络PPHGNetV2改进YOLOv8(超级轻量化精度更高)
一、本文介绍 本文给大家带来利用RT-DETR模型主干HGNet去替换YOLOv8的主干,RT-DETR是今年由百度推出的第一款实时的ViT模型,其在实时检测的领域上号称是打败了YOLO系列,其利用两个主干一个是HGNet一个是ResNet,其中HGNet就是我们…...
笔记——<stdarg.h>、<stdlib.h>和<time.h>标准库)
C现代方法(第26章)笔记——<stdarg.h>、<stdlib.h>和<time.h>标准库
文章目录 第26章 <stdarg.h>、<stdlib.h>和<time.h>标准库26.1 <stdarg.h>: 可变参数26.1.1 调用带有可变参数列表的函数26.1.2 v...printf函数26.1.3 v...scanf函数(C99) 26.2 <stdlib.h>: 通用的实用工具26.2.1 数值转换函数26.2.1.1 测试数值…...
CCKS2023-面向金融领域的主体事件检测-亚军方案分享
赛题分析 大赛地址 https://tianchi.aliyun.com/competition/entrance/532098/introduction?spma2c22.12281925.0.0.52b97137bpVnmh 任务描述 主体事件检测是语言文本分析和金融领域智能应用的重要任务之一,如在金融风控领域往往会对公司主体进行风险事件的检测…...
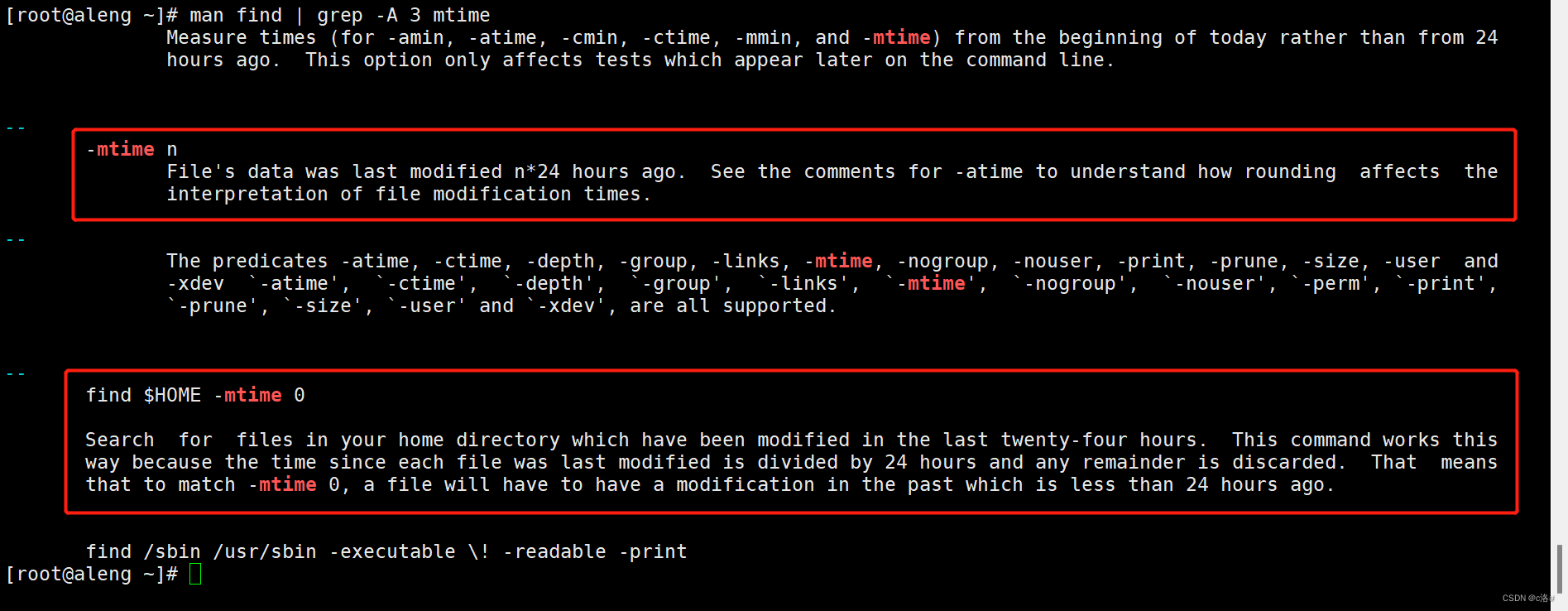
Linux下通过find找文件---通过修改时间查找(-mtime)
通过man手册查找和-mtime选项相关的内容 man find | grep -A 3 mtime # 这里简单介绍了 -mtime ,还有一个简单的示例-mtime n Files data was last modified n*24 hours ago. See the comments for -atime to understand how rounding affects the interpretati…...

图文教程:stable-diffusion的基本使用教程 txt2img(多图)
之前我介绍了SD的安装过程,那么这篇将介绍怎么使用SD 使用模型 SD安装好之后,我们只有一个默认的模型。这个模型很难满足我们的绘图需求,那么有2种方法。 1是自己训练一个模型(有门槛)2是去网站上找一个别人练好的模…...
VisualSVN Server的安装全过程
目录 背景: 安装过程: 步骤1: 步骤2: 步骤3: 步骤4: 步骤5: 安装出现的bug: 问题: 解决办法: 总结: 背景: VisualSVN Server 是一款免费的 SVN (Subversion) 服务器软件,…...

Python 进阶(十六):二进制和ASCII码的转换(binascii 模块)
大家好,我是水滴~~ 本文详细介绍了Python中的binascii模块及其使用方法。通过binascii模块,我们可以方便地进行二进制和ASCII字符串之间的转换操作。文章中包含大量的示例代码,希望能够帮助新手同学快速入门。 《Python入门核心技术》专栏总…...
CSS Grid布局入门:从零开始创建一个网格系统
CSS Grid布局入门:从零开始创建一个网格系统 引言 在响应式设计日益重要的今天,CSS Grid布局系统是前端开发中的一次革新。它使得创建复杂、灵活的布局变得简单而直观。本教程将通过分步骤的方式,让你从零开始掌握CSS Grid,并在…...

无王无帝定乾坤,来自田间第一人:大道同源归本心
无王无帝定乾坤,来自田间第一人。 世间千般法理,万般修行,流派纷杂,说辞各异; 世人终日寻道问路,遍历山河苦思真谛, 却往往舍近求远,向外求索不休, 反倒遗忘最本真的根源…...

MaterialSkin终极指南:10分钟让WinForms应用焕然一新
MaterialSkin终极指南:10分钟让WinForms应用焕然一新 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 你是否厌倦了传统WinForms应…...

猫头鹰的秘密网络
原文:towardsdatascience.com/the-secret-network-of-owls-d55e7b2c4910 你知道 8 月 4 日是国际猫头鹰意识日吗?我也不知道,直到无聊地浏览可爱的猫头鹰表情包,这让我来到了这个网站。然后,正如我们最近在我们的花园里…...

用VSCode+ESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程
用VSCodeESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程 在机器人开发中,精确控制多个舵机是实现复杂动作的基础。想象一下,一个六足机器人需要协调18个关节的运动,或者一个机械臂要完成精准抓取动作——这些场景都…...

Beyond Compare 5密钥生成终极指南:从激活失败到完全使用
Beyond Compare 5密钥生成终极指南:从激活失败到完全使用 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否也遇到过Beyond Compare 5弹出"评估模式错误"的困扰&#…...

Figma界面3分钟变中文:设计师必备的完整汉化终极指南
Figma界面3分钟变中文:设计师必备的完整汉化终极指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?作为一名中文设计师&#x…...

SD-PPP终极秘籍:在Photoshop中直接召唤AI助手的实战宝典
SD-PPP终极秘籍:在Photoshop中直接召唤AI助手的实战宝典 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否曾为了给设计作品添加AI特效,不得不在Photoshop和AI工具间来回切换、导出导入…...

DLSS Swapper:免费开源的游戏性能优化终极解决方案
DLSS Swapper:免费开源的游戏性能优化终极解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的免费开源工具,它能够智能管理、下载和替换游戏中的DL…...
)
CTF新手必看:用Python脚本搞定RSA常见攻击(附实战代码)
CTF密码学实战:Python脚本破解RSA五大攻击场景 在CTF竞赛中,RSA加密系统是最常见的密码学挑战之一。本文将带你深入实战,通过Python代码复现五种经典RSA攻击场景,从基础分解到高级数学技巧,每个案例都配有可直接运行的…...
)
别再手动填Excel了!用EasyExcel 3.3.2 + SpringBoot实现模板化导出(附金额大写工具类)
告别手工填表:SpringBootEasyExcel智能报表生成实战 财务小张每周五下午都要面对同样的噩梦:从ERP系统导出销售数据,然后对照模板手动填写上百行Excel报表。金额大写转换要逐个核对,格式错位要反复调整,加班到深夜已成…...