基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
目录
- 前言
- 引言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 1)数据介绍
- 2)数据测试
- 3)数据处理
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰写一篇关于方言分类的博客,以满足读者对这一主题的进一步了解和探索的需求。上篇博客可参考:
《基于Python+WaveNet+CTC+Tensorflow智能语音识别与方言分类—深度学习算法应用(含全部工程源码)》
引言
本项目以科大讯飞提供的数据集为基础,通过特征筛选和提取的过程,选用WaveNet模型进行训练。旨在通过语音的梅尔频率倒谱系数(MFCC)特征,建立方言和相应类别之间的映射关系,解决方言分类问题。
首先,项目从科大讯飞提供的数据集中进行了特征筛选和提取。包括对语音信号的分析,提取出最能代表语音特征的MFCC,为模型训练提供有力支持。
其次,选择了WaveNet模型进行训练。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。
在训练过程中,利用语音的MFCC特征,建立了方言和相应类别之间的映射关系。这样,模型能够识别和分类输入语音的方言,并将其划分到相应的类别中。
最终,通过这个项目,实现了方言分类问题的解决方案。这对于语音识别、语音助手等领域具有实际应用的潜力,也有助于保护和传承各地区的语言文化。
总体设计
本部分包括系统整体结构图和系统流程图。
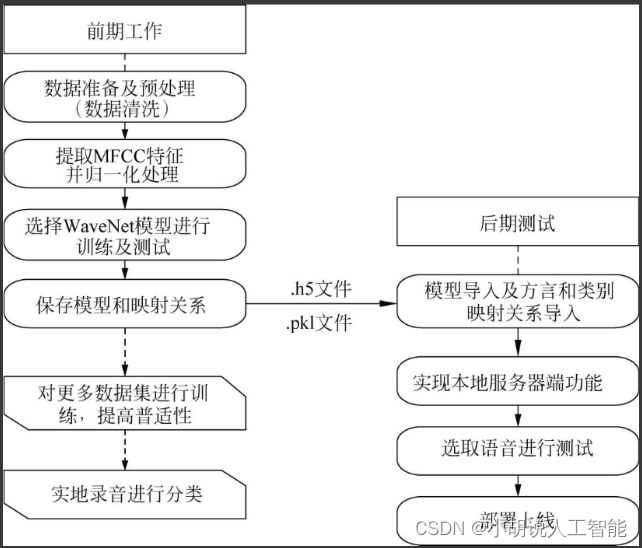
系统整体结构图
系统整体结构如图所示。
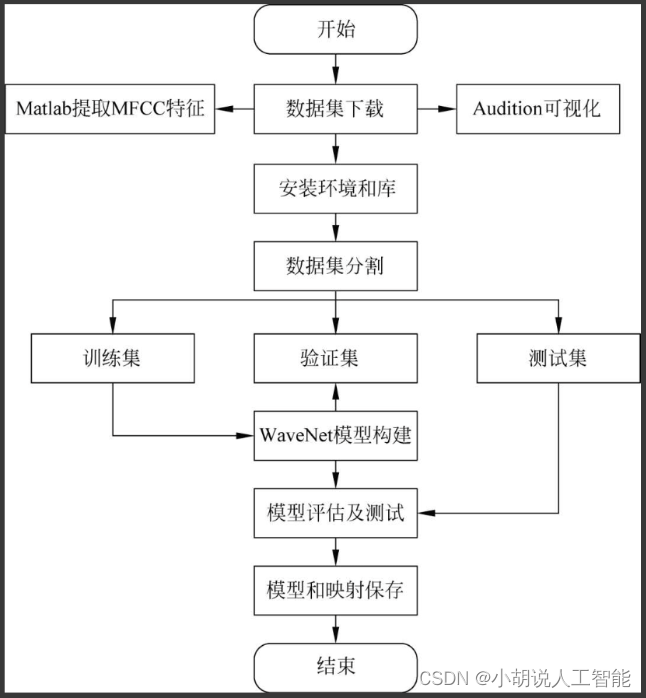
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据介绍、数据测试和数据处理。
1)数据介绍
数据集网址为:challenge.xfyun.cn,向用户免费提供了3种方言(长沙话、南昌话、上海话),每种方言包括30人,每人200条数据,共计18000条训练数据,以及10人、每人50条,共计1500条验证数据。数据以pcm格式提供,可以理解为.wav文件去掉多余信息之后仅保留语音数据的格式。
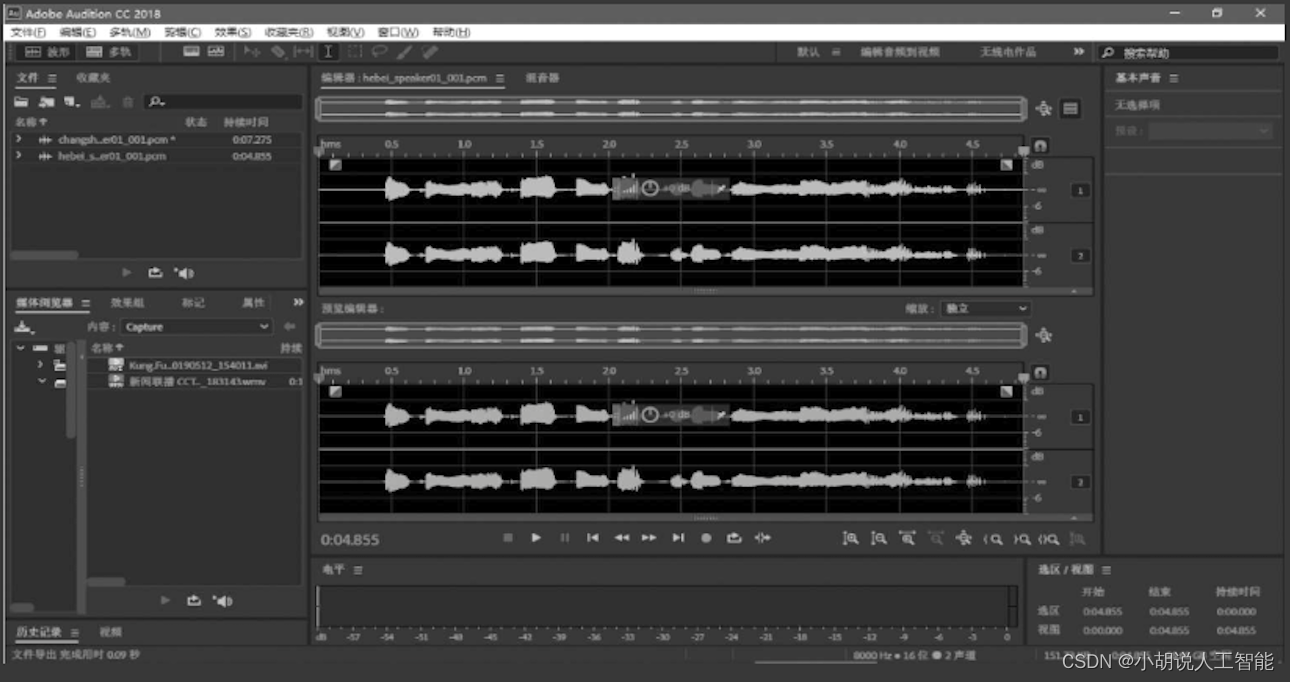
2)数据测试
使用Audition进行语音测试,导出mp3格式进行检测,如图所示。
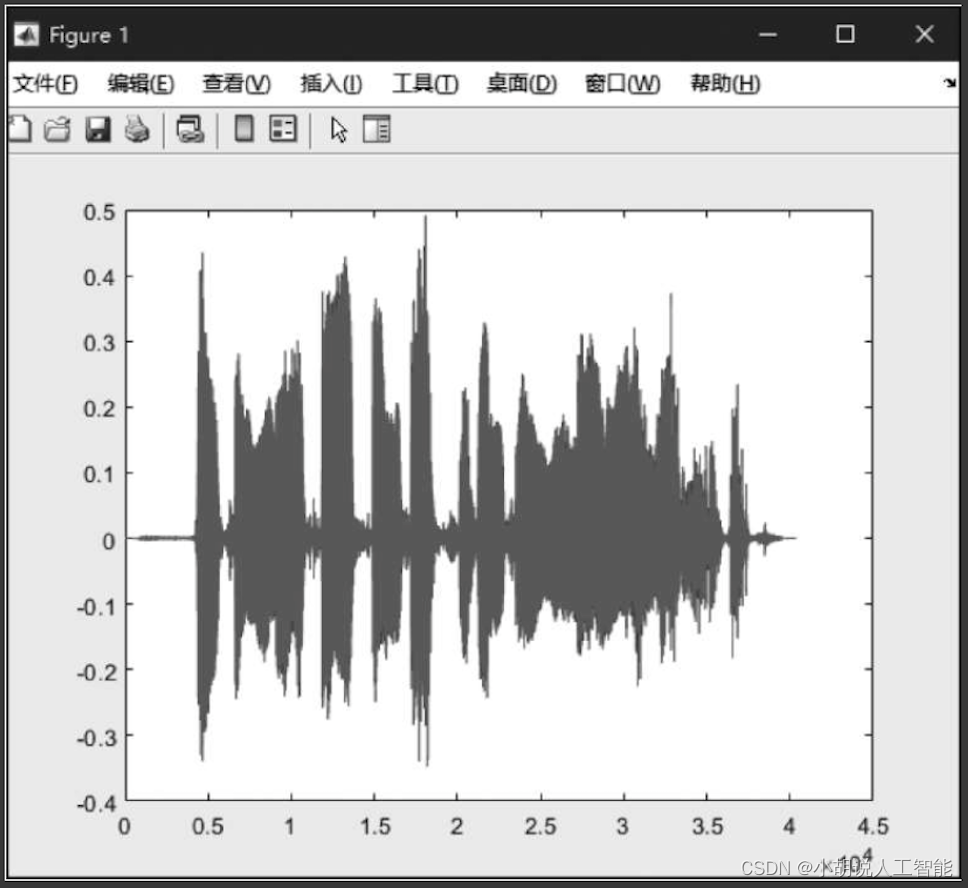
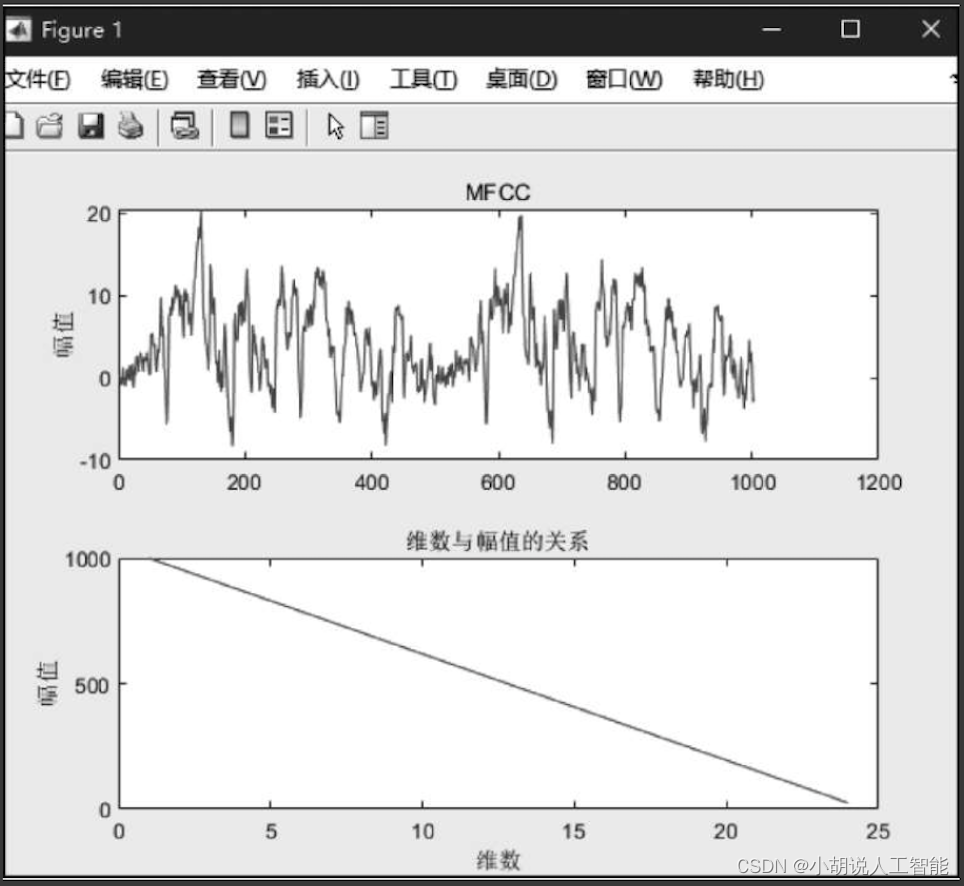
使用MATLAB得到该语音片段的波形和MFCC特征,相关代码如下:
[x, fs]=audioread('test.mp3');
bank=melbankm(24,256,fs,0,0.4,'m');
%Mel滤波器的阶数为24
%fft变换的长度为256,采样频率为8000Hz
%归一化mel滤波器组系数
bank=full(bank);
bank=bank/max(bank(:));
for k=1:12 %归一化mel滤波器组系数
n=0:23;
dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24));
end
w=1+6*sin(pi*[1:12]./12);%归一化倒谱提升窗口
w=w/max(w);%预加重滤波器
xx=double(x);
xx=filter([1-0.9375],1,xx);%语音信号分帧
xx=enframe(xx,256,80);%对*256点分为一帧
%计算每帧的MFCC参数
for i=1:size(xx,1)
y=xx(i,:);
s=y'.*hamming(256);
t=abs(fft(s));%fft快速傅立叶变换
t=t.^2;
c1=dctcoef*log(bank*t(1:129));
c2=c1.*w';
m(i,:)=c2';
end
%求取差分系数
dtm=zeros(size(m));
for i=3:size(m,1)-2
dtm(i,:)=-2*m(i-2,:)-m(i-1,:)+m(i+1,:)+2*m(i+2,:);
end
dtm=dtm/3;
%合并mfcc参数和一阶差分mfcc参数
ccc=[m dtm];
%去除首尾两帧,因为这两帧的一阶差分参数为0
ccc=ccc(3:size(m,1)-2,:);
subplot(2,1,1)
ccc_1=ccc(:,1);
plot(ccc_1);title('MFCC');ylabel('幅值');
[h,w]=size(ccc);
A=size(ccc);
subplot(212) ;
plot([1,w],A);
xlabel('维数');
ylabel('幅值');
title('维数与幅值的关系')
运行代码,成功得到一段语音的波形片段和MFCC特征,如图1和图2所示。
3)数据处理
本部分包括数据处理过程中的相关代码。
(1)加载库。在实验过程中,通过查找发现Matplotlib包内没有中文字体,加载库之后添加参数设定或者更改Matplotlib默认字体可以解决。相关代码如下:
#-*- coding:utf-8 -*-
import numpy as np
import os
from matplotlib import pyplot as plt
#在实验过程中使用pyplot参数设置,使得图像可打印中文,且中文内容格式应该为u“内容”
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
plt.rcParams['axes.unicode_minus']=False
from mpl_toolkits.axes_grid1 import make_axes_locatable
%matplotlib inline
from sklearn.utils import shuffle #导入各种模块
import glob
import pickle
from tqdm import tqdm
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Input, Activation, Conv1D, Add, Multiply, BatchNormalization, GlobalMaxPooling1D, Dropout
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from python_speech_features import mfcc
import librosa
from IPython.display import Audio
import wave
(2)加载pcm文件,共18000条训练数据,1500条验证数据,相关代码如下:
train_files = glob.glob('data/*/train/*/*.pcm')
dev_files = glob.glob('data/*/dev/*/*/*.pcm')
#glob.glob()用于查找符合特定规则的文件路径名,并返回所有匹配的文件路径列表
#其中“*”为匹配符,匹配多个字符
print(len(train_files), len(dev_files), train_files[0])
#读取代码成功,打印结果
(3)整理每条语音数据对应的分类标签,相关代码如下:
labels = {'train': [], 'dev': []}
#使用dict与list类型嵌套存储分类标签
#tqdm打印进度条,用于观察读取情况
for i in tqdm(range(len(train_files))):path = train_files[i]label = path.split('/')[1]#使用split将path以“/”分隔的字符串进行切片,并选取第1个分片labels['train'].append(label)
for i in tqdm(range(len(dev_files))):path = dev_files[i]label = path.split('/')[1]labels['dev'].append(label)
print(len(labels['train']), len(labels['dev']))
#读取代码成功,打印结果
(4)定义处理语音、pcm转wav、可视化语音的三个函数,由于语音片段长短不一,所以去除少于1s的短片段,对于长片段则切分为不超过3s的片段。相关代码如下:
mfcc_dim = 13
sr = 16000
min_length = 1 * sr
slice_length = 3 * sr
#语音处理函数
def load_and_trim(path, sr=16000):audio = np.memmap(path, dtype='h', mode='r')#使用numpy内的memmap函数读写大文件,返回对象可使用ndarray算法操作audio = audio[2000:-2000]audio = audio.astype(np.float32)#astype实现dataframe类型转换energy = librosa.feature.rmse(audio)#librosa为音频处理包,使用feature.rmse求均方根误差frames = np.nonzero(energy >= np.max(energy) / 5)#nonzero()函数将布尔数组转为整数数组,用于进行下标运算#nonzero()返回参数数组中值不为0的元素下标,返回类型是元组#元组的每个元素均为一个整数数组,值为非零元素下标在对应帧的值indices = librosa.core.frames_to_samples(frames)[1]#将样本索引采样转换为帧audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]slices = []for i in range(0, audio.shape[0], slice_length):s = audio[i: i + slice_length]if s.shape[0] >= min_length:slices.append(s)#长度>3s进行切片,<1s过滤return audio, slices
#文件格式处理,pcm转为wav函数
def pcm2wav(pcm_path, wav_path, channels=1, bits=16, sample_rate=sr):data = open(pcm_path, 'rb').read()fw = wave.open(wav_path, 'wb')#设置转化为.wav格式时相同的参数(通道数、采样率等)fw.setnchannels(channels) #通道fw.setsampwidth(bits // 8)fw.setframerate(sample_rate) #采样率fw.writeframes(data) #写入fw.close()
#语音可视化
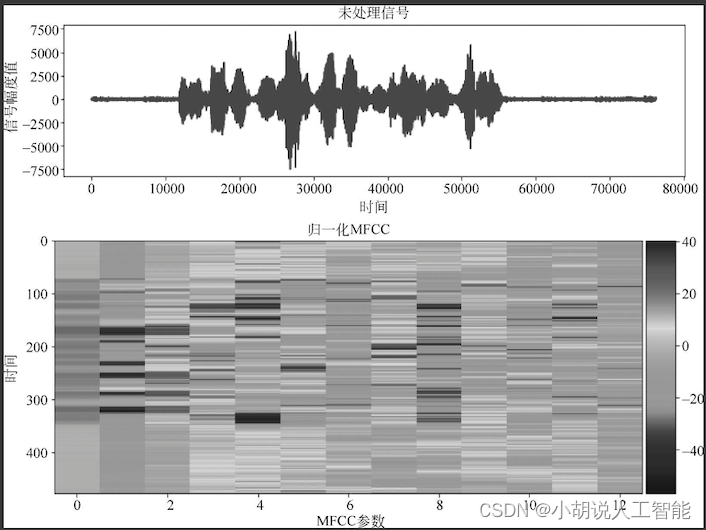
def visualize(index, source='train'):#可视化语音,默认可视化训练集内的语音,也可以选择参数“dev”可视化测试集if source == 'train':path = train_files[index]else:path = dev_files[index]print(path)audio, slices = load_and_trim(path)#读取语音信号print('Duration: %.2f s' % (audio.shape[0] / sr))#使用matplotlob库内的pyplot进行绘图plt.figure(figsize=(12, 3))plt.plot(np.arange(len(audio)), audio)plt.title(u'未处理信号')plt.xlabel(u'时间')plt.ylabel(u'信号幅度值')plt.show()#展示未处理的音频信号feature = mfcc(audio, sr, numcep=mfcc_dim)#提取MFCC特征print('Shape of MFCC:',feature.shape)#进行画图fig = plt.figure(figsize=(12, 5))#figsize指定figure的宽和高,单位为英寸ax = fig.add_subplot(111)#subplot()为图像分区,参数111表示只有一张图im = ax.imshow(feature,cmap=plt.cm.jet, aspect='auto')#imshow热图绘制,通过色差、亮度展示数据的差异plt.title(u'归一化MFCC')plt.ylabel('时间')plt.xlabel('MFCC参数')plt.colorbar(im,cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
#给图配渐变色时,在图旁边把色标(colorbar)标注出来#其中cax参数表示将要绘制颜色条的轴ax.set_xticks(np.arange(0,13,2),minor=False);#设置横坐标刻度plt.show()wav_path = 'example.wav'pcm2wav(path,wav_path)return wav_path
Audio(visualize(2)) #调用函数选取其中一条语音信号进行可视化
读取代码成功可以得到一句长沙话对应的波形和MFCC特征,如图所示。
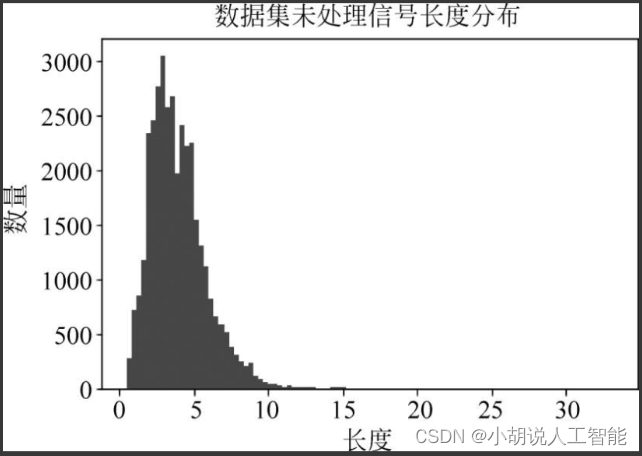
(5)整理数据,查看语音片段的长度分布,最后得到18890个训练片段,1632个验证片段。相关代码如下:
X_train = [] #参数设置
X_dev = []
Y_train = []
Y_dev = []
lengths = []
for i in tqdm(range(len(train_files))):path = train_files[i]audio, slices = load_and_trim(path) #取语音信号lengths.append(audio.shape[0] / sr) #除以sr(=16000)换算成时间长度for s in slices: #按照片段进行训练X_train.append(mfcc(s, sr, numcep=mfcc_dim))Y_train.append(labels['train'][i])
for i in tqdm(range(len(dev_files))): #输出参数path = dev_files[i]audio, slices = load_and_trim(path)lengths.append(audio.shape[0] / sr)for s in slices:X_dev.append(mfcc(s, sr, numcep=mfcc_dim))Y_dev.append(labels['dev'][i])
print(len(X_train), len(X_dev))
plt.hist(lengths, bins=100)#matplotlib中的hist()函数,用于可视化生成直方图
plt.show()
读取代码成功,如图所示。
(6)将MFCC特征进行归一化处理,相关代码如下:
#矩阵堆叠,沿竖直方向矩阵堆叠
samples = np.vstack(X_train)
#计算每一列的平均值(axis=0)
mfcc_mean = np.mean(samples, axis=0)
#计算每一列的标准差(axis=0)
mfcc_std = np.std(samples, axis=0)
print(mfcc_mean)
print(mfcc_std)
#归一化处理
X_train = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_train]
X_dev = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_dev]
maxlen = np.max([x.shape[0] for x in X_train + X_dev])
X_train = pad_sequences(X_train, maxlen, 'float32', padding='post', value=0.0)
#pad_sequences对序列进行预处理
#maxlen参数为序列的最大长度,返回类型dtype为float32,“post”表示需要补0时在末尾补
X_dev = pad_sequences(X_dev, maxlen, 'float32', padding='post', value=0.0)
print(X_train.shape, X_dev.shape)
(7)对分类标签进行处理,相关代码如下:
from sklearn.preprocessing import LabelEncoder
from keras.utils import to_categorical
#将标签标准化
le = LabelEncoder()
#为非监督学习
Y_train = le.fit_transform(Y_train) #fit_transform()
Y_dev = le.transform(Y_dev)
print(le.classes_)
class2id = {c: i for i, c in enumerate(le.classes_)}
#enumerate将可遍历数据对象组合为索引序列
id2class = {i: c for i, c in enumerate(le.classes_)}
num_class = len(le.classes_)
Y_train = to_categorical(Y_train, num_class)
#keras内的to_categorical将类别向量转换为二进制矩阵类型表示
Y_dev = to_categorical(Y_dev, num_class)
print(Y_train.shape, Y_dev.shape)
#代码运行,获得分类标签的处理图
(8)定义产生批数据的迭代器,相关代码如下:
batch_size = 16
def batch_generator(x, y, batch_size=batch_size): #批次处理offset = 0while True:offset += batch_sizeif offset == batch_size or offset >= len(x):#将序列的所有元素随机排序
x, y = shuffle(x, y) offset = batch_sizeX_batch = x[offset - batch_size: offset] Y_batch = y[offset - batch_size: offset]#yield返回生成器
yield (X_batch, Y_batch)
相关其它博客
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理1)数据介绍2)数据测试3)数据处理 相关其它博客工程源代码下载其它资料下载 前言 博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者…...

secrets --- 生成管理密码的安全随机数
3.6 新版功能. 源代码: Lib/secrets.py secrets 模块用于生成高度加密的随机数,适于管理密码、账户验证、安全凭据及机密数据。 最好用 secrets 替代 random 模块的默认伪随机数生成器,该生成器适用于建模和模拟,不宜用于安全与加密。 参见…...
宇视科技视频监控 main-cgi 文件信息泄露漏洞
宇视科技视频监控 main-cgi 文件信息泄露漏洞 一、产品简介二、漏概述三、复现环境四、漏洞检测手工抓包自动化检测 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失&#…...

【数学建模】《实战数学建模:例题与讲解》第十一讲-因子分析、聚类与主成分(含Matlab代码)
【数学建模】《实战数学建模:例题与讲解》第十一讲-因子分析、聚类与主成分(含Matlab代码) 基本概念聚类分析Q型聚类分析R型聚类分析 主成分分析因子分析 习题10.11. 题目要求2.解题过程3.程序4.结果 习题10.21. 题目要求2.解题过程3.程序4.结…...

Python查找列表中不重复的数字
Python每日一练 文章目录 Python每日一练问题:函数输入函数输出 代码实现示例输入:示例输出: 总结 问题: 编写一个程序来查找列表中不重复的数字。 定义函数find_unique(),它接受一个列表作为参数。 在函数内部&…...
用docker创建jmeter容器,如何实现性能测试?
用 docker 创建 jmeter 容器, 实现性能测试 我们都知道,jmeter可以做接口测试,也可以用于性能测试,现在企业中性能测试也大多使用jmeter。docker是最近这些年流行起来的容器部署工具,可以创建一个容器,然后把项目放到…...
pytest-fixtured自动化测试详解
fixture的作用 1.同unittest的setup和teardown,作为测试前后的初始化设置。 fixture的使用 1.作为前置条件使用 2.fixture的的作用范围 1.作为前置条件使用 pytest.fixture() def a():return 3def test_b(a):assert a3 2.fixture的作用范围 首先实例化更高范围的fixture…...
计算机网络:应用层(一)
我最近开了几个专栏,诚信互三! > |||《算法专栏》::刷题教程来自网站《代码随想录》。||| > |||《C专栏》::记录我学习C的经历,看完你一定会有收获。||| > |||《Linux专栏》࿱…...

mybatis的快速入门以及spring boot整合mybatis(二)
需要用到的SQL脚本: CREATE TABLE dept (id int unsigned PRIMARY KEY AUTO_INCREMENT COMMENT ID, 主键,name varchar(10) NOT NULL UNIQUE COMMENT 部门名称,create_time datetime DEFAULT NULL COMMENT 创建时间,update_time datetime DEFAULT NULL COMMENT 修改…...

lua基本语法使用
Lua 是一个小巧的脚本语言。Lua由标准C编写而成,几乎在所有操作系统和平台上都可以编译,运行。Lua并没有提供强大的库,这是由它的定位决定的。所以Lua不适合作为开发独立应用程序的语言。 1.基本语法 注解 -- 单行 -- [[ ]] -- 多行 …...

Git远程操作
目录 1.远程操作 1.1理解分布式版本控制系统 1.2远程仓库. 1.2.1新建远程仓库 1.2.2克隆远程仓库 1.2.3向远程仓库推送 1.2.4拉取远程仓库 1.3配置Git 1.3.1忽略特殊文件 1.3.2给命令配置别名 2.标签管理 2.1理解标签 2.2创建标签 2.3操作标签 1.远程操作 1.1理…...

链表基础知识(一、单链表)
一、链表表示和实现 顺序表的问题及思考 问题: 1. 中间/头部的插入删除,时间复杂度为O(N) 2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。 3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当…...

mysql的ON DELETE CASCADE 和ON DELETE RESTRICT区别
ON DELETE CASCADE 和 ON DELETE RESTRICT 是 MySQL 中两种不同的外键约束级联操作。它们之间的主要区别在于当主表中的记录被删除时,子表中相关记录的处理方式。 ON DELETE CASCADE: 当在主表中删除一条记录时,所有与之相关的子表中…...
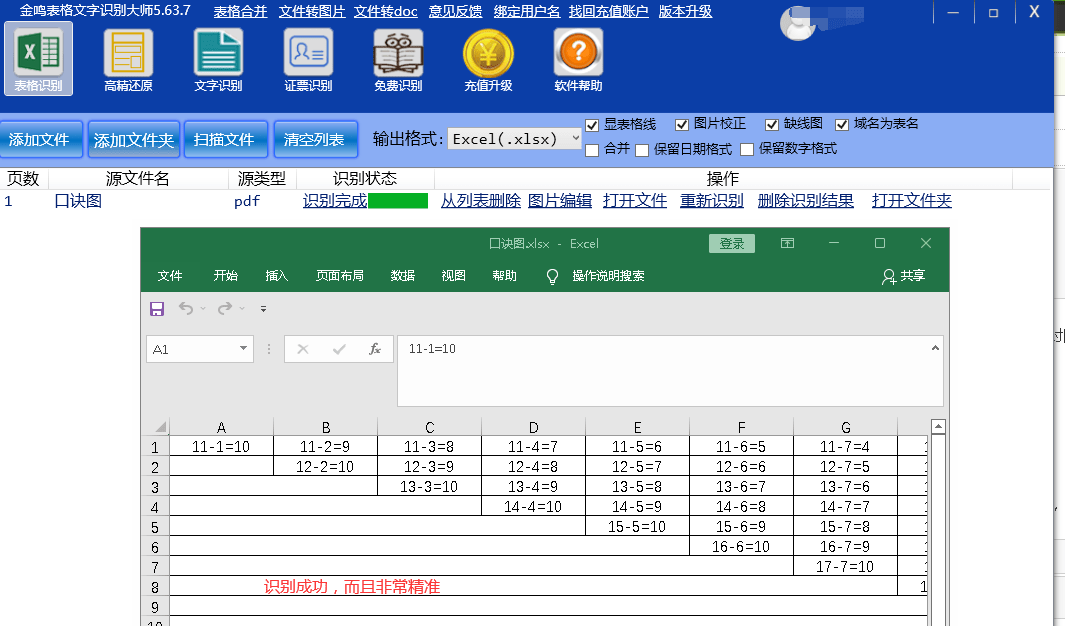
如何快速将图片转为excel?
一、打开金鸣表格文字识别软件。 二、点击添加文件按钮,在打开的窗口中选择目标图片,然后点击“打开”,将图片添加进待识别的列表中。 三、点击提交识别或识别全部。 四、识别完成后点击“打开文件”即可打开识别好的结果文件(EXC…...
)
元编程(Metaprogramming)
本章将介绍第8️⃣种编程范式---元编程,以及它的优缺点、案例分析和小项目的代码示例。 优点 元编程的优点: 灵活性和可重用性:元编程允许在运行时生成代码,使得程序更加灵活和可重用。可以根据需要动态生成代码片段࿰…...

IEEE Transactions on Industrial Electronics工业电子TIE论文投稿须知
一、背景 IEEE TIE作为控制领域的TOP期刊,接收机器人、控制、自动驾驶、仪器和传感等方面的论文,当然范围不止这些,感兴趣的可以自行登录TIE官网查看。所投稿论文必须经过实验验证,偏工程应用类,当然也必须有方法上的…...
Linux--操作系统
1. 常见的操作系统 Windowsmac OSLinuxiOSAndroid 2. 操作系统的定义 操作系统直接运行在计算机上的系统软件, 它是控制硬件和支持软件运行的计算机程序。 3. 操作系统的作用 向下控制硬件向上支持软件的运行,具有承上启下的作用。 4.总结 操作系统…...

HarmonyOS—实现UserDataAbility
UserDataAbility接收其他应用发送的请求,提供外部程序访问的入口,从而实现应用间的数据访问。Data提供了文件存储和数据库存储两组接口供用户使用。 文件存储 开发者需要在Data中重写FileDescriptoropenFile(Uriuri,Stringmode)方法来操作文件…...
Java实现插入排序及其动图演示
插入排序是一种简单直观的排序算法。它的基本思想是将一个待排序的元素插入到已经排序好的序列中的适当位置,从而得到一个新的、元素个数加一的有序序列。 具体的插入排序算法过程如下: 从第一个元素开始,认为第一个元素已经是有序序列。取…...
设计模式——原型模式(创建型)
引言 原型模式是一种创建型设计模式, 使你能够复制已有对象, 而又无需使代码依赖它们所属的类。 问题 如果你有一个对象, 并希望生成与其完全相同的一个复制品, 你该如何实现呢? 首先, 你必须新建一个属于…...

SAP查询字段定义的字符数
用户常会问到“***的文本描述可以输入多少个字符”。 操作步骤: 输入事物代码:SE11就能看到字段配置的字符数量。如何获得表名称:(OBB8举例) 操作步骤: 输入事物代码:OBB8...

新手避坑指南:STM32用Makefile编译时,遇到‘junk at end of line’错误怎么办?
STM32 Makefile编译实战:彻底解决junk at end of line汇编错误 第一次用Makefile编译STM32项目时,看到满屏的junk at end of line错误提示,确实容易让人头皮发麻。这就像你兴冲冲地下载了一个开源项目准备大展身手,结果刚执行make…...

委外加工成本智能核算与利润分析方案:基于LLM+超自动化的端到端实践
在2026年的工业数字化语境下,委外加工不再仅仅是生产能力的延伸,而是企业利润控制的核心环节。随着全球供应链的碎片化,委外成本的精细化核算已成为财务数字化转型的“深水区”。传统模式下,数据孤岛、BOM(物料清单&am…...

ARM ETM集成测试与验证方法详解
1. ARM ETM集成测试概述嵌入式跟踪宏单元(ETM)作为ARM处理器调试子系统的核心组件,其功能验证是芯片开发流程中的关键环节。ETM7/ETM9分别对应ARM7和ARM9系列处理器,通过实时捕获指令流水线活动、数据访问和处理器状态变化,为开发者提供非侵入…...

39. UE5 GAS RPG:利用Motion Warping实现技能释放时的智能角色转向
1. Motion Warping插件基础与启用 Motion Warping是UE5官方提供的一个实验性插件,专门用于解决角色动画过程中的动态转向问题。这个插件的工作原理是在动画播放过程中插入一个"变形窗口",允许开发者指定某个时间段内角色的朝向或位置变化。我刚…...

Keil C51评估版SRC指令限制解析与解决方案
1. 问题现象与背景解析最近在调试一个基于8051架构的嵌入式项目时,遇到了一个令人困惑的编译错误。当我在Keil C51开发环境中使用SRC指令时,编译器突然报出致命错误(Fatal Error),但检查代码语法看起来完全正确。这个SRC指令是用来控制编译器…...

AI Agent Harness Engineering 后端架构选型:微服务 vs 单体架构的取舍
AI Agent Harness Engineering 后端架构选型深度指南:微服务 vs 单体架构的取舍、落地与最佳实践 摘要/引言 你有没有过这样的经历:团队好不容易赶完了AI Agent的POC验证,正准备规模化落地,却卡在了后端架构选型上? 有人说“微服务是未来”,上来就拆了8个服务,结果3个后…...

5分钟搞定!NewGAN-Manager终极配置指南:让Football Manager游戏体验焕然一新
5分钟搞定!NewGAN-Manager终极配置指南:让Football Manager游戏体验焕然一新 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager …...

【MySQL百日打怪升级第8天】SELECT执行流程
【第8天】每天一个MySQL知识点,百日打怪升级 SQL基础:SELECT执行流程 大家好,我是一名拥有10年以上经验的DBA老兵。 做这个系列,源于一个朴素的愿望:把踩过的坑、总结的经验系统化输出,希望能帮到刚入行或…...

化工行业节能改造数据监测系统方案
针对工厂存在能源利用不足、设备利用率偏低、人工抄表粗放等痛点,某化工企业通过落实多项节能数字化改造措施,实现变废为宝、节能增效等多种能源效益。主要举措包括:通过回收高温蒸汽驱动闲置汽轮机实现发电、通过回收富余蒸汽为生产提供热源…...