大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类
大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类
过拟合,欠拟合
针对模型的拟合,这里引入两个概念:过拟合,欠拟合。
过拟合:在机器学习任务中,我们通常将数据集分为两部分:训练集和测试集。训练集用于训练模型,而测试集则用于评估模型在未见过数据上的性能。过拟合就是指模型在训练集上表现较好,但在测试集上表现较差的现象。
当模型过度拟合训练集时,它会学习到训练数据中的噪声和异常模式,导致对新数据的泛化能力下降。过拟合的典型特征是模型对训练集中每个样本都产生了很高的拟合度,即模型过于复杂地学习了训练集的细节和噪声。
欠拟合:在训练集上的效果就很差。
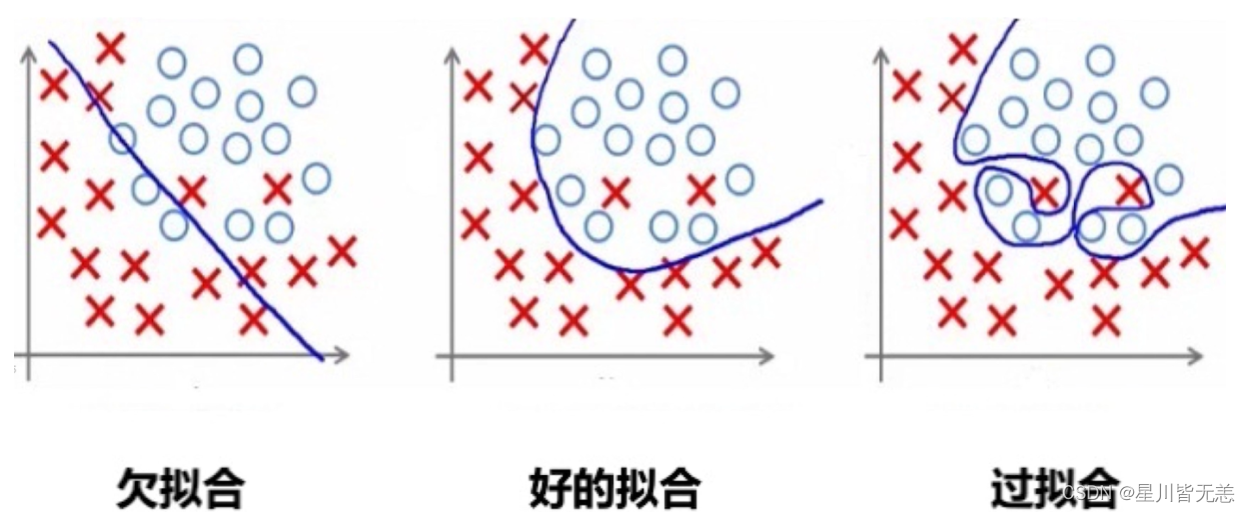
对于二分类数据,我们可以用下面三个图更直观的理解过拟合与欠拟合
一、欠拟合
首先来说欠拟合,欠拟合主要是由于学习不足造成的,那么我们可以通过以下方法解决此问题
1、增加特征
增加新的特征,或者衍生特征(对特征进行变换,特征组合)
2、使用较复杂的模型,或者减少正则项
其次讨论过拟合,为什么我们的模型会过拟合呢?这里,我总结了一下,将其原因分成两大类:
二、过拟合
1、样本问题
1)样本量太少:
样本量太少可能会使得我们选取的样本不具有代表性,从而将这些样本独有的性质当作一般性质来建模,就会导致模型在测试集上效果很差;
模型复杂度过高:当模型的复杂度过高时,它有足够的灵活性来捕捉训练集中的每个数据点,但也容易记住数据中的噪声和特定样本的细节,导致在新数据上的性能下降。
数据不足:如果训练集样本数量较少,模型难以捕捉到数据的整体分布,容易受到极端值的影响,从而导致过拟合问题。
特征选择不当:选择的特征过多或过少都可能导致过拟合。特征选择的关键是要选择那些与预测目标相关的特征,过多或过少都可能引入噪声或忽略重要信息。
2)训练集、测试集分布不一致:
对于数据集的划分没有考虑业务场景,有可能造成我们的训练、测试样本的分布不同,就会出现在训练集上效果好,在测试集上效果差的现象;
3)样本噪声干扰大:
如果数据的声音较大,就会导致模型拟合这些噪声,增加了模型复杂度;
2、模型问题
1)参数太多,模型过于复杂,对于树模型来说,比如:决策树深度较大等。
3、解决方法
1)增加样本量:
样本量越大,过拟合的概率就越小(不过有的由于业务受限,样本量增加难以实现);
2)减少特征:
减少冗余特征;
3)加入正则项:
损失函数中加入正则项,惩罚模型的参数,降低模型的复杂度(树模型可以控制深度等);
4)集成学习:
详细一点:
练多个模型,将模型的平均结果作为输出,这样可以弱化每个模型的异常数据影响。
增加训练数据:通过增加更多的训练数据,可以帮助模型更好地学习数据的整体分布,减少对特定样本的依赖,从而缓解过拟合现象。
减少模型复杂度:选择适当的模型复杂度可以有效避免过拟合问题。可以通过减少模型的隐藏层、降低多项式的阶数等方式来降低模型复杂度,以提高泛化能力。
正则化:正则化是一种常用的缓解过拟合的方法。通过在损失函数中引入惩罚项,限制模型参数的大小,可以防止模型过度拟合训练数据,减少对噪声和异常样本的敏感性。
特征选择:选择与预测目标高度相关的特征,去除冗余或无关的特征,有助于减少过拟合的风险,并提高模型的泛化能力。
交叉验证:使用交叉验证可以更好地评估模型的性能,并帮助选择适当的模型和参数配置,以避免过拟合问题。
机器学习算法分类
监督学习
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督式学习的常见应用场景
分类问题:目标值离散
回归问题:目标值连续
无监督学习
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
半监督学习
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
强化学习
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
强化学习是一个动态过程,上一步数据的输出是下一步数据的输入。
强化学习基本结构如图所示,和人类大脑学习的过程非常地类似,agent(人)在某种场景(state)下,做出某种行为(action),得到某种反馈(reward),这就是强化学习的四要素:状态(state)、动作(action)、策略(policy)、奖励(reward)。通过与环境的不断交互,agent可以优化自己做决策(policy)的正确性,以获取整个交互过程的最大收益。

意义:
提高预测性能: 了解过拟合和欠拟合的问题有助于选择适当的模型和调整参数,提高机器学习模型在大数据上的预测性能。
优化算法选择: 理解不同类型的机器学习算法有助于在大数据场景中选择合适的算法,以更好地满足任务需求。
加强模型解释力: 通过深入理解模型的过拟合和欠拟合问题,可以更好地解释模型在大数据中的预测结果,增强对模型的信任度。
因此,深入了解过拟合、欠拟合以及机器学习算法分类对于在大数据背景下构建高效、准确的机器学习和深度学习模型至关重要。
相关文章:
大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类
大数据机器学习与深度学习——过拟合、欠拟合及机器学习算法分类 过拟合,欠拟合 针对模型的拟合,这里引入两个概念:过拟合,欠拟合。 过拟合:在机器学习任务中,我们通常将数据集分为两部分:训…...

Lenovo联想拯救者Legion Y9000X 2021款(82BD)原装出厂Windows10系统
链接:https://pan.baidu.com/s/1GRTR7CAAQJdnh4tHbhQaDQ?pwdl42u 提取码:l42u 联想原厂WIN10系统自带所有驱动、出厂主题壁纸、系统属性专属LOGO标志、Office办公软件、联想电脑管家等预装程序 所需要工具:16G或以上的U盘 文件格式&am…...

pytorch中的transpose用法
注意:维数从0开始,0维 1维2维…,负数代表从右往左数,-1代表第一维,以此类推 import torch import numpy as np# 创建一个二维数组 arr torch.tensor([[[1, 2],[3, 4]],[[5, 6],[7, 8]]]) print("原始数组:"…...
SpringBoot面试题及答案(最新50道大厂版,持续更新)
在准备Spring Boot相关的面试题时,我发现网络上的资源往往缺乏深度和全面性。为了帮助广大Java程序员更好地准备面试,我花费了大量时间进行研究和整理,形成了这套Spring Boot面试题大全。 这套题库不仅包含了一系列经典的Spring Boot面试题及…...
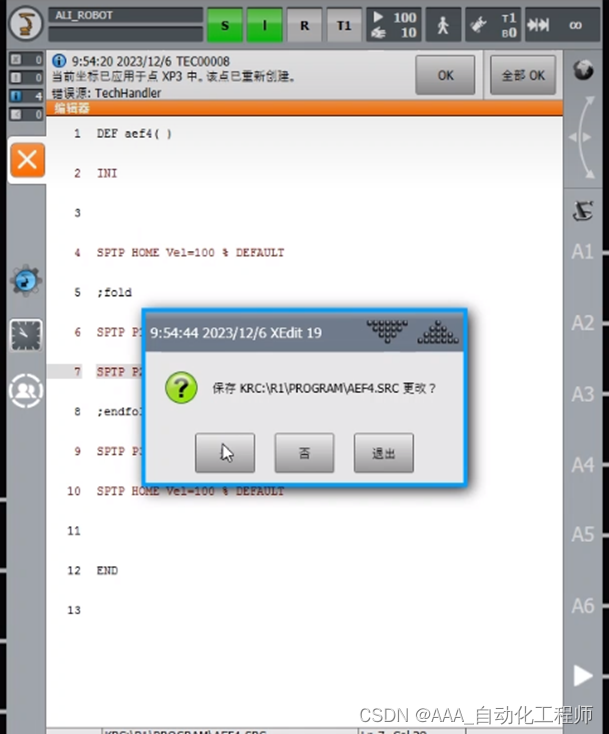
KUKA机器人如何隐藏程序或程序段?
KUKA机器人如何隐藏程序或程序段? 如下图所示,新建一个示例程序进行说明, 如下图所示,如果红框中的动作指令不想让别人看到,想隐藏起来,如何做到? 如下图所示,在想要隐藏的程序或程序段的前后,分别添加 ;fold 和 endfold指令(这里要注意是英文状态下的输入法), 如…...
--概述)
C++ STL(1)--概述
1. 简述 STL即标准模板库 Standard Template Library,包含了许多在计算机科学领域里所常用的基本数据结构和算法。STL具有高可重用性、高性能、高可移植性(跨平台)的优点。 两个特点: 1.1 数据结构和算法分离。 1.2 它不是面向对象的,是基于模…...
unity 2d 入门 飞翔小鸟 死亡闪烁特效(十三)
一、c#脚本 using System.Collections; using System.Collections.Generic; using UnityEngine;public class Bling : MonoBehaviour {public Texture img;public float speed;public static bool changeWhite false;private float alpha0f;// Start is called before the fi…...

Cannot find cache named ‘‘ for Builder Redis
当引入 Redissson 时,springCache 缓存机制失效 原因:springCache 默认使用本地缓存 Redisson 使用redis 缓存 最后都转成redis了。。。 总感觉哪不对 两者居然不共存...
IntelliJ IDEA的下载安装配置步骤详解
引言 IntelliJ IDEA 是一款功能强大的集成开发环境,它具有许多优势,适用于各种开发过程。本文将介绍 IDEA 的主要优势,并提供详细的安装配置步骤。 介绍 IntelliJ IDEA(以下简称 IDEA)之所以被广泛使用,…...

光线追踪算法实现
我们已经涵盖了所有要说的内容! 我们现在准备编写第一个光线追踪器。 你现在应该能够猜测光线追踪算法是如何工作的。 首先,请花点时间注意一下,光在自然界中的传播只是从光源发出的无数光线,它们四处反弹,直到到达我…...

学习深度强化学习---第3部分----RL蒙特卡罗相关算法
文章目录 3.1节 蒙特卡罗法简介3.2节 蒙特卡罗策略评估3.3节 蒙特卡罗强化学习3.4节 异策略蒙特卡罗法 本部分视频所在地址:深度强化学习的理论与实践 3.1节 蒙特卡罗法简介 在其他学科中的蒙特卡罗法是一种抽样的方法。 如果状态转移概率是已知的,则是…...

linux虚拟机使用81-persistent-net.rule后接口名依然改变的问题处理
测试环境:vmware workstation17 、oracle linux 7.8 1. 复位原有ifname 1)nmcli c s 查看管理的网卡 [rootrac2 ~]# nmcli c s NAME UUID TYPE DEVICE enp0s3 5b01a9de-9552-45da-a84a-1ae6c9506354…...

ARMV8 - A64 - 跳转和返回指令
说明 C语言等高级语言,根据是否需要返回到触发跳转代码的下一条代码,跳转有两种语句: 不需要返回,例如:if,goto,switch,while等语句。需要返回,例如:函数调…...

QX320F28335,自研内核指令集,主频150MHz,自研工具链,纯国产DSP,硬件兼容TMS320F28335
32位单核CPU 主频150MHz flash 1M SRAM 500KB 单精度浮点运算FPU 3个4M精度12位的ADC 12个ePWM 6个HRPWM(150ps)...
《使用ThinkPHP6开发项目》 - 登录接口一
《使用ThinkPHP6开发项目》 - 安装ThinkPHP框架-CSDN博客 《使用ThinkPHP6开发项目》 - 设置项目环境变量-CSDN博客 《使用ThinkPHP6开发项目》 - 项目使用多应用开发-CSDN博客 《使用ThinkPHP6开发项目》 - 创建应用-CSDN博客 《使用ThinkPHP6开发项目》 - 创建控制器-CSD…...

zabbix精简模板
一、监控项目介绍 linux自带得监控项目比较多,也不计较杂,很多监控项目用不到。所以这里要做一个比较精简得监控模版 二、监控模板克隆 1.搜索原模板 2.克隆模板 全克隆模板,这样就和原来原模板没有联系了,操作也不会影响原模…...
)
GO设计模式——14、代理模式(结构型)
目录 代理模式(Proxy Pattern) 代理模式的核心角色: 优缺点 使用场景 注意事项 代码实现 代理模式(Proxy Pattern) 代理模式(Proxy Pattern)通过引入代理对象来控制对真实对象的访问。 代…...

外贸SOHO建站怎么做?海洋建站方法策略?
外贸SOHO建站多少钱?外贸自助建站系统有哪些? 随着全球化的加速发展,外贸SOHO已经成为越来越多创业者的选择。然而,要想在竞争激烈的外贸市场中脱颖而出,一个专业的外贸网站是必不可少的。接下来海洋建站将探讨外贸SO…...
商城免费搭建之java鸿鹄云商 java电子商务商城 Spring Cloud+Spring Boot+mybatis+MQ+VR全景+b2b2c
鸿鹄云商 SAAS云产品概述 1. 涉及平台 平台管理、商家端(PC端、手机端)、买家平台(H5/公众号、小程序、APP端(IOS/Android)、微服务平台(业务服务) 2. 核心架构 Spring Cloud、Spring Boot、My…...

【淘宝网消费类电子产品销售数据可视化】
淘宝网消费类电子产品销售数据可视化 引言数据爬取与处理数据可视化系统功能1. 总数据量分析2. 店铺总数据3. 店铺销售额排名4. 不同电子商品销售价格5. 单个商品价格排名6. 不同省份平均销量7. 不同地区的平均销售额8. 省份数量9. 每个省份有用的平均个数 创新点结语 引言 随…...

基于WPF开发桌面AI助手:架构设计与实现详解
1. 项目概述:一个开源的WPF桌面AI助手 最近在GitHub上看到一个挺有意思的项目,叫“MayDay-wpf/AIBotPublic”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现这其实是一个用WPF(Windows Present…...

Chrome扩展开发实战:打造浏览器侧边栏ChatGPT助手
1. 项目概述:一个让ChatGPT常驻浏览器侧边栏的利器如果你和我一样,每天的工作和学习都离不开浏览器,并且频繁地与ChatGPT对话来获取灵感、润色文案或者调试代码,那么你肯定对在无数个标签页之间来回切换感到厌烦。每次都要打开一个…...

Performance-Fish:深度解析《环世界》400%性能优化核心技术
Performance-Fish:深度解析《环世界》400%性能优化核心技术 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish 是专为《环世界》(RimWorld&#…...

从零构建现代化Web控制面板:安全架构与实时监控实践
1. 项目概述:一个为开发者设计的现代化控制面板最近在GitHub上看到一个挺有意思的项目,叫clawpanel,作者是kweephyo-pmt。光看名字,你可能会联想到“爪子”和“面板”,感觉像是个带点攻击性或工具属性的管理界面。实际…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

基于RAG的电影智能体构建:从向量检索到Agentic设计
1. 项目概述:一个能聊电影的智能体最近在GitHub上看到一个挺有意思的项目,叫tomasonjo/llm-movieagent。光看名字,你大概能猜到,这是一个和电影、和大型语言模型(LLM)相关的智能体。简单来说,它…...

终极指南:如何用WarcraftHelper让魔兽争霸3在现代电脑上完美运行 [特殊字符]
终极指南:如何用WarcraftHelper让魔兽争霸3在现代电脑上完美运行 🎮 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

ARM处理器仿真技术:Cortex-R52与Neoverse实战解析
1. ARM处理器仿真技术概述在现代芯片设计和软件开发流程中,处理器仿真模型已成为不可或缺的关键工具。作为Arm生态系统的重要组成部分,Iris仿真组件提供了对Cortex-R52和Neoverse系列处理器的精确模拟能力。这些模型不仅能够模拟指令执行流程,…...