6.3 C++11 原子操作与原子类型
一、原子类型
1.多线程下的问题
在C++中,一个全局数据在多个线程中被同时使用时,如果不加任何处理,则会出现数据同步的问题。
#include <iostream>
#include <thread>
#include <chrono>
long val = 0;void test()
{for (int i = 0; i < 10000000; i++) {val++;}
}int main()
{auto time1 = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count();std::thread thread1(test);std::thread thread2(test);thread1.join();thread2.join();auto time2 = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count();time2 - time1;std::cout << "val:" << val<<" " << ((time2 - time1)/1000.0)<<"s"<<std::endl;
}上述例子中test函数对全局变量val进行累加,并在thread1和thread2两个线程中分别处理test函数。得到的结果如下:
val:11260278 0.105sval的值并不是期望的20000000,这是因为val++操作不是原子操作导致的。
对于val++,实际上会被拆为三步:
- 从内存读取val值到寄存器
- 寄存器自增
- 将寄存器值回写到val的内存
而多线程同时操作时,实际步骤可能为:
- thread1读取val值为0
- thread2读取val值为0
- thread1增加val值为1
- thread2增加val值为1(注意与thread1增加的不是一个原始值)
- thread1写入val,值为1
- thread2覆盖写入val,值为1
这样就会导致两个线程的操作重复,最终结果小于20000000。
2.原子操作
所谓原子操作,指的是多线程中"最小且不可并行化"的操作,如val++语句的三步在一个线程中执行完之前,不会运行其他的进程。
在C++11之前,原子操作都是通过“互斥”(即在临界区间内,一个线程正在访问,则其他线程会等待)处理的,如互斥锁。下面则是通过添加互斥锁处理这个问题:
#include <mutex>long val = 0;std::mutex locker;
void test()
{for (int i = 0; i < 10000000; i++) {locker.lock();val++;locker.unlock();}
}
输出结果如下:
val:20000000 5.648s可以看到val值正确,但是性能消耗非常大。
3.原子类型
C++11将原子操作抽象,引入原子类型atomic,并提供相应的操作接口(原子操作)。通过atomic实现线程间数据同步:
#include <atomic>std::atomic_long val = 0;
void test()
{for (int i = 0; i < 10000000; i++) {val++;}
}输出为:
val:20000000 2.29s可见val值正确,且耗时比互斥锁小了很多。(因为mutex使用涉及:多次atomic原子指令操作+用户态和内核态切换、线程切换调度开销、全局锁hash queue维护等开销,所以时间更长。但是atomic只能对变量,而锁可以针对范围内的所有内容)
3.1 内置原子类型
类似于前面的atomic_long,C++11为所有内置类型都提供了对应的原子类型:

3.2 自定义类型原子类型
因为atomic为类模板,所以可以通过:
std::atomic<T> t;创建自定义类型的原子类型,当然也可以使用此方式创建内置类型的原子类型。
atomic为作为类模板,提供了统一的操作接口:

其中is_lock_free用于判断是否有锁,load用于读取,store用于存,exchange用于交换数据。
由于原子类型属于资源类型,所以为了避免拷贝时引起的问题,atomic类模板删除了相关的拷贝构造和赋值函数。
此外,atomic到原始类型的转换也是允许的(隐式的),但非原子操作。
atomic_flag
atomic_flag是无锁的,仅支持test_and_set和clear两个接口。其中test_and_set表示:
- 如果atomic_flag原始为false,则设置其为true,并返回false
- 如果原始为true,则不处理,并返回true
而clear则表示将atomic_flag置为false。
所以可以使用atomic_flag实现一个自旋锁:
#include <thread>
#include <atomic>
#include <iostream>
#include <unistd.h>
using namespace std;
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void f(int n) {while (lock.test_and_set(std::memory_order_acquire)) // 尝试获得锁cout << "Waiting from thread " << n << endl; // 自旋cout << "Thread " << n << " starts working" << endl;
}
void g(int n) {cout << "Thread " << n << " is going to start." << endl;lock.clear();cout << "Thread " << n << " starts working" << endl;
}
int main() {lock.test_and_set(); //设为truethread t1(f, 1);thread t2(g, 2);t1.join();usleep(100);t2.join();
}
// 编译选项:g++ -std=c++11 6-3-3.cpp -lpthread
上述代码声明了一个全局的atomic_flag变量lock。最开始,将lock初始化为值ATOMIC_FLAG_INIT,即false的状态。
而在线程t1中(执行函数f的代码),我们不停地通过lock的成员test_and_set来设置lock为true。这里的test_and_set()是一种原子操作,用于在一个内存空间原子地写入新值并且返回旧值。因此test_and_set会返回之前的lock的值。
所以当线程t1执行join之后,由于在main函数中调用过test_and_set,因此f中的test_and_set将一直返回true,并不断打印信息,即自旋等待。
而当线程t2加入运行的时候,由于其调用了lock的成员clear,将lock的值设为false,因此此时线程t1的自旋将终止,从而开始运行后面的代码。这样一来,我们实际上就通过自旋锁达到了让t1线程等待t2线程的效果。
当然,还可以将lock封装为锁操作,比如:
void Lock(atomic_flag *lock) { while (lock.test_and_set ()); }
void Unlock(atomic_flag *lock) { lock.clear(); }二、内存模型、顺序一致性和memory_order
原子类型为线程间数据同步提供了一定的保障,但是这是建立在顺序一致性的内存模型基础上。
1.问题
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a {0};
atomic<int> b {0};
int ValueSet(int) {int t = 1;a = t;b = 2;
}
int Observer(int) {cout << "(" << a << ", " << b << ")" << endl; // 可能有多种输出
}
int main() {thread t1(ValueSet, 0);thread t2(Observer, 0);t1.join();t2.join();cout << "Got (" << a << ", " << b << ")" << endl; // Got (1, 2)
}
// 编译选项:g++ -std=c++11 6-3-4.cpp -lpthread对于上面的代码,比较合理的打印值有:(0,0),(1,0),(1,2),然而在非顺序一致性时可能会打印(0,2)这样的结果。
这是因为对于非顺序一致性场景下,编译器在认定a、b的赋值语句的执行先后顺序对输出结果有任何的影响的话,则可以依情况将指令重排序(reorder)以提高性能。因此就有可能会将b的赋值语句提前到a的赋值语句之前,从而得到(0,2)这样的结果。
当然,默认情况下,在C++11中的原子类型的变量在线程中总是保持着顺序执行的特性(非原子类型则没有必要,因为不需要在线程间进行同步)。我们称这样的特性为“顺序一致”的,即代码在线程中运行的顺序与程序员看到的代码顺序一致,a的赋值语句永远发生于b的赋值语句之前。
2.内存模型
通常情况下,内存模型是一个硬件的概念,表示机器指令以什么样的顺序被执行。
对于"t = 1; a = t; b = 2;"可以用如下的伪汇编表示:
1: Loadi reg3, 1; # 将立即数1放入寄存器reg3
2:Move reg4, reg3; # 将reg3的数据放入reg4
3: Store reg4, a; # 将寄存器reg4中的数据存入内存地址a4: Loadi reg5, 2; # 将立即数2放入寄存器reg5
5: Store reg5, b; # 将寄存器reg5中的数据存入内存地址b通常情况下,应该按照1,2,3,4,5顺序执行,这样的内存模型称为强顺序的。这时a的赋值始终先于b的赋值执行。
但是我们可以看到,指令1,2,3与指令4,5毫无关联,因此一些处理器可能就会重排指令顺序,比如1,4,2,5,3的顺序执行。这种场景,我们称为弱顺序的,b的赋值也就会先于a的赋值。
而在多线程中,强顺序意味着,多个线程看到的指令执行顺序是一致的且反馈到处理器层面,内存数据变换顺序与指令顺序一致,而弱顺序则无法保证这一点。
而原子操作要求都是顺序的,这在强顺序内存模型下是不需要额外处理的,而对于弱顺序内存模型下,则需要添加内存栅栏这样的指令来确保顺序一致性,这对性能往往有较大的损耗。
3.内存顺序memory_order
以上描述的都是硬件上的一些内存模型,而C++11引入的内存模型和顺序一致性则是针对编译器而言:
- 编译器保证原子操作的指令间顺序不变,即保证产生的读写原子类型的变量的机器指令与代码编写者看到的是一致的。
- 处理器对原子操作的汇编指令的执行顺序不变。这对于x86这样的强顺序的体系结构而言,并没有任何的问题;而对于PowerPC这样的弱顺序的体系结构而言,则要求编译器在每次原子操作后加入内存栅栏。
C++11的原子操作默认都是顺序一致性的,这对强顺序体系而言没有影响,但是对于弱顺序体系而言,添加内存栅栏来确保顺序一致性,会大大增加性能消耗。为了解决这一问题,C++11引入了内存顺序memory_order的概念,即对所有的原子操作提供一个参数入口,传入不同的momery_order以弱化对顺序一致性的要求。
具体使用如下:
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a {0};
atomic<int> b {0};
int ValueSet(int) {int t = 1;a.store(t, memory_order_relaxed);b.store(2, memory_order_relaxed);
}
int Observer(int) {cout << "(" << a << ", " << b << ")" << endl; // 可能有多种输出
}
int main() {thread t1(ValueSet, 0);thread t2(Observer, 0);t1.join();t2.join();cout << "Got (" << a << ", " << b << ")" << endl; // Got (1, 2)return 0;
}
// 编译选项:g++ -std=c++11 6-3-6.cpp -lpthread
a和b的赋值操作传入参数memory_order_relaxed,表示对执行顺序不做任何要求,从而放开顺序一致性。
memory_order的枚举值有:

通常情况下,我们可以把atomic成员函数可使用的memory_order值分为以下3组:
❑ 原子存储操作(store)可以使用memorey_order_relaxed、memory_order_release、memory_order_seq_cst。
❑ 原子读取操作(load)可以使用memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_seq_cst。
❑ RMW操作(read-modify-write),即一些需要同时读写的操作,比如之前提过的atomic_flag类型的test_and_set()操作。又比如atomic类模板的atomic_compare_exchange()操作等都是需要同时读写的。RMW操作可以使用memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst。
排除顺序一致和松散两种方式,我们能不能保证程序“既快又对”地运行呢?实际上,我们所需要的只是a.store先于b.store发生,b.load先于a.load发生的顺序。这要这两个“先于发生”关系得到了遵守,对于整个程序而言来说,就不会发生线程间的错误。所以我们可以修改代码如下:
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int) {int t = 1;a.store(t, memory_order_relaxed);b.store(2, memory_order_release); // 本原子操作前所有的写原子操作必须完成
}
int Thread2(int) {while(b.load(memory_order_acquire) != 2); // 本原子操作必须完成才能执行之后所有的读原子操作cout << a.load(memory_order_relaxed) << endl; // 1
}
int main() {thread t1(Thread1, 0);thread t2(Thread2, 0);t1.join();t2.join();return 0;
}
// 编译选项:g++ -std=c++11 6-3-8.cpp -lpthread
b.store采用了memory_order_release内存顺序,这保证了本原子操作前所有的写原子操作必须完成,也即a.store操作必须发生于b.store之前。b.load采用了memory_order_acquire作为内存顺序,这保证了本原子操作必须完成才能执行之后所有的读原子操作。即b.load必须发生在a.load操作之前。这样一来,通过确立“先于发生”关系的,我们就完全保证了代码运行的正确性,即当b的值为2的时候,a的值也确定地为1。
相关文章:
6.3 C++11 原子操作与原子类型
一、原子类型 1.多线程下的问题 在C中,一个全局数据在多个线程中被同时使用时,如果不加任何处理,则会出现数据同步的问题。 #include <iostream> #include <thread> #include <chrono> long val 0;void test() {for (i…...

智能优化算法应用:基于狮群算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于狮群算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于狮群算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.狮群算法4.实验参数设定5.算法结果6.参考文献7.MA…...

BERT、GPT学习问题个人记录
目录 1. 为什么过去几年大家都在做BERT, 做GPT的人少。 2. 但最近做GPT的多了以及为什么GPT架构的scaling(扩展性)比BERT好。 3.BERT是否可以用来做生成,如果可以的话为什么大家都用GPT不用BERT. 4. BERT里的NSP后面被认为是没用的&#x…...
HeartBeat监控Mysql状态
目录 一、概述 二、 安装部署 三、配置 四、启动服务 五、查看数据 一、概述 使用heartbeat可以实现在kibana界面对 Mysql 服务存活状态进行观察,如有必要,也可在服务宕机后立即向相关人员发送邮件通知 二、 安装部署 参照章节:监控组件…...

软件开发经常出现的bug原因有哪些
软件开发中出现bug的原因是多方面的,这些原因可能涉及到开发流程、人为因素、设计问题以及其他一系列因素。以下是一些常见的导致bug的原因: 1. 错误的需求分析: 不正确、不完整或者模糊的需求分析可能导致开发人员误解客户的需求࿰…...
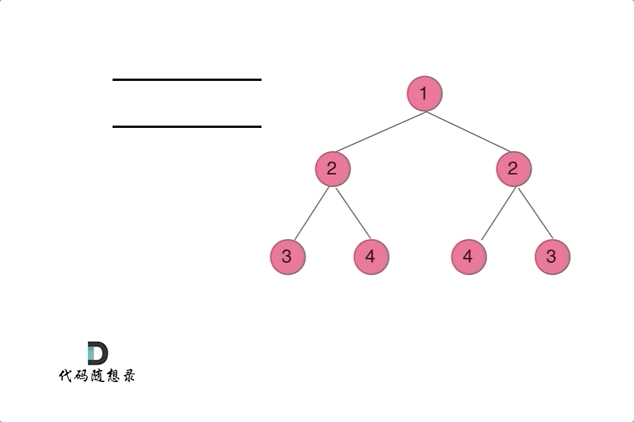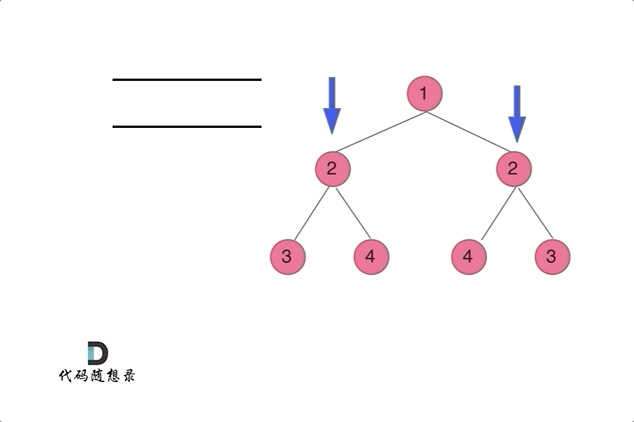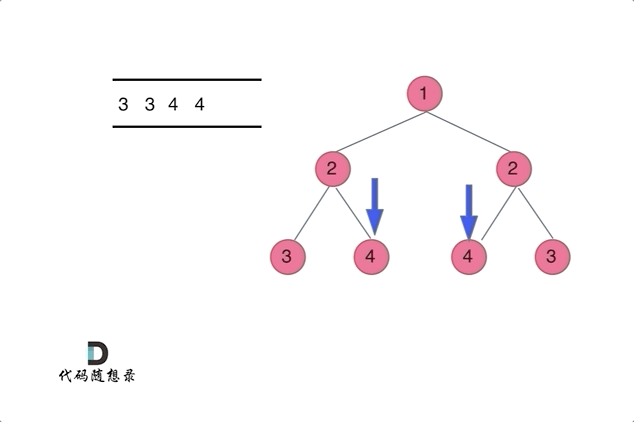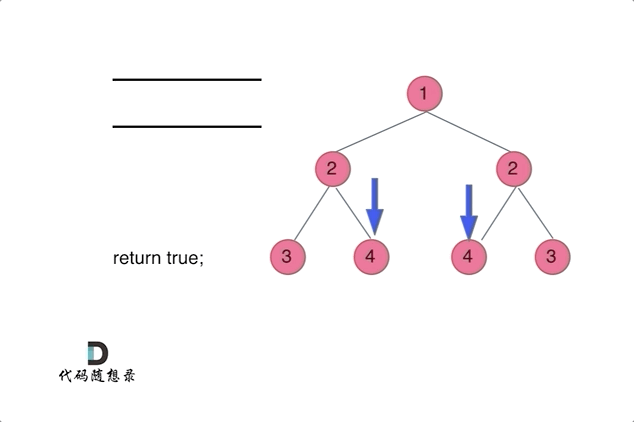
代码随想录27期|Python|Day15|二叉树|层序遍历|对称二叉树|翻转二叉树
本文图片来源:代码随想录 层序遍历(图论中的广度优先遍历) 这一部分有10道题,全部可以套用相同的层序遍历方法,但是需要在每一层进行处理或者修改。 102. 二叉树的层序遍历 - 力扣(LeetCode) 层…...
鸿蒙开发组件之Web
一、加载一个url myWebController: WebviewController new webview.WebviewControllerbuild() {Column() {Web({src: https://www.baidu.com,controller: this.myWebController})}.width(100%).height(100%)} 二、注意点 2.1 不能用Previewer预览 Web这个组件不能使用预览…...

成绩分析。
成绩分析 题目描述 小蓝给学生们组织了一场考试,卷面总分为 100分,每个学生的得分都是一个0到100的整数。 请计算这次考试的最高分、最低分和平均分 输入描述 输入的第一行包含一个整数n(1n104),表示考试人数。 接下来n行,每行包含…...
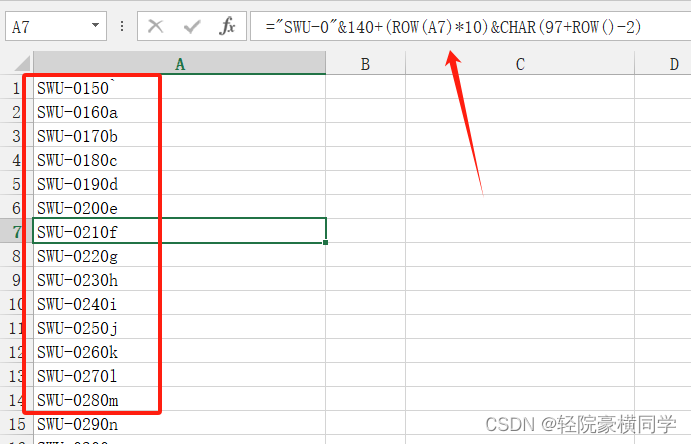
Excel实现字母+数字拖拉自动递增,步长可更改
目录 1、带有字母的数字序列自增加(步长可变) 2、仅字母自增加 3、字母数字同时自增 1、带有字母的数字序列自增加(步长可变) 使用Excel通常可以直接通过拖拉的方式,实现自增数字…...

Java之Stream流
一、什么是Stream流 Stream是一种处理集合(Collection)数据的方式。Stream可以让我们以一种更简洁的方式对集合进行过滤、映射、排序等操作。 二、Stream流的使用步骤 先得到一条Stream流,并把数据放上去利用Stream流中的API进行各种操作 中间…...

vue中element-ui日期选择组件el-date-picker 清空所选时间,会将model绑定的值设置为null 问题 及 限制起止日期范围
一、问题 在Vue中使用Element UI的日期选择组件 <el-date-picker>,当你清空所选时间时,组件会将绑定的 v-model 值设置为 null。这是日期选择器的预设行为,它将清空所选日期后将其视为 null。但有时后端不允许日期传空。 因此ÿ…...
使用模方时,三维模型在su中显示不了怎么办?
答:可以借助截图功能截取模型影像在su中绘制白模。 模方是一款针对实景三维模型的冗余碎片、水面残缺、道路不平、标牌破损、纹理拉伸模糊等共性问题研发的实景三维模型修复编辑软件。模方4.1新增自动单体化建模功能,支持一键自动提取房屋结构ÿ…...
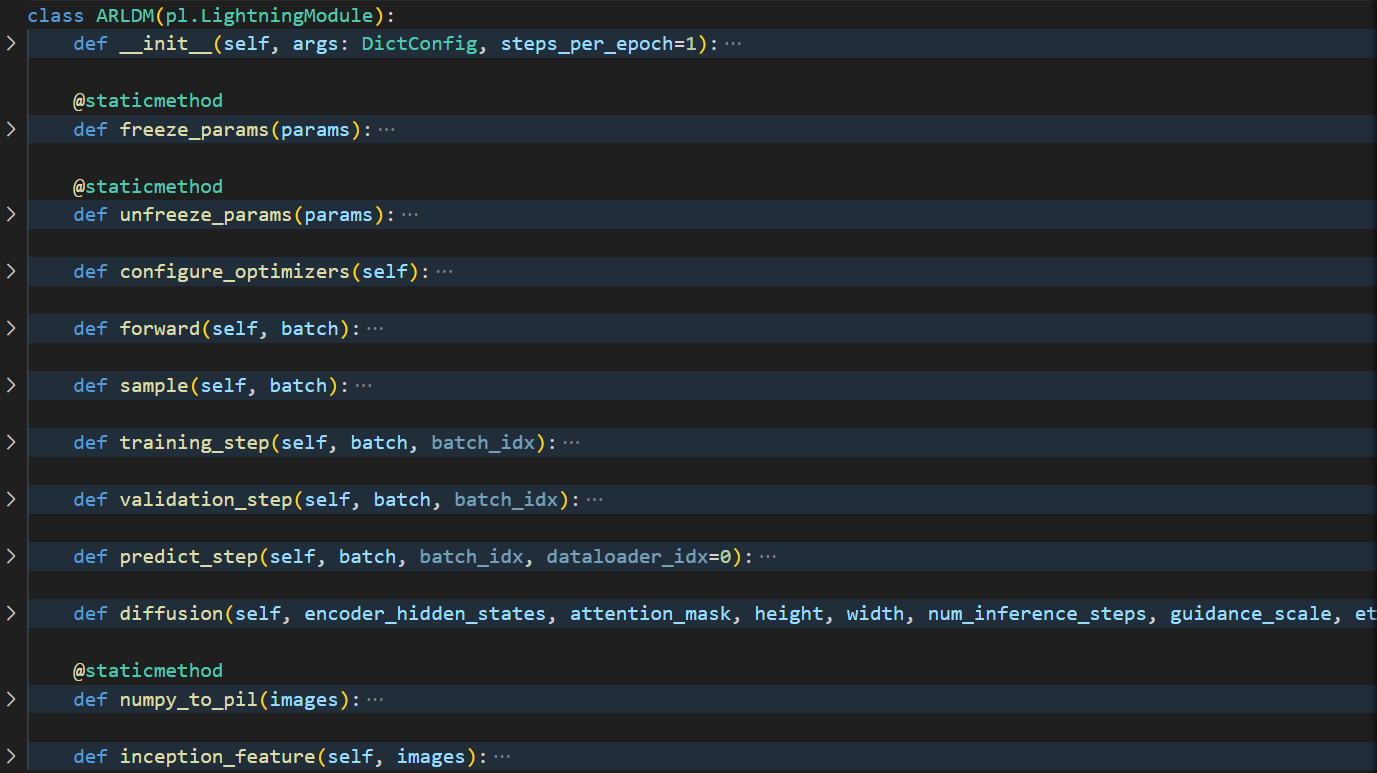
AR-LDM原理及代码分析
AR-LDM原理AR-LDM代码分析pytorch_lightning(pl)的hook流程main.py 具体分析TrainSampleLightningDatasetARLDM blip mm encoder AR-LDM原理 左边是模仿了自回归地从1, 2, ..., j-1来构造 j 时刻的 frame 的过程。 在普通Stable Diffusion的基础上,使用了1, 2, .…...

MySQL常见死锁的发生场景以及如何解决
死锁的产生是因为满足了四个条件: 互斥占有且等待不可强占用循环等待 这个网站收集了很多死锁场景 接下来介绍几种常见的死锁发生场景。其中,id 为主键,no(学号)为二级唯一索引,name(姓名&am…...
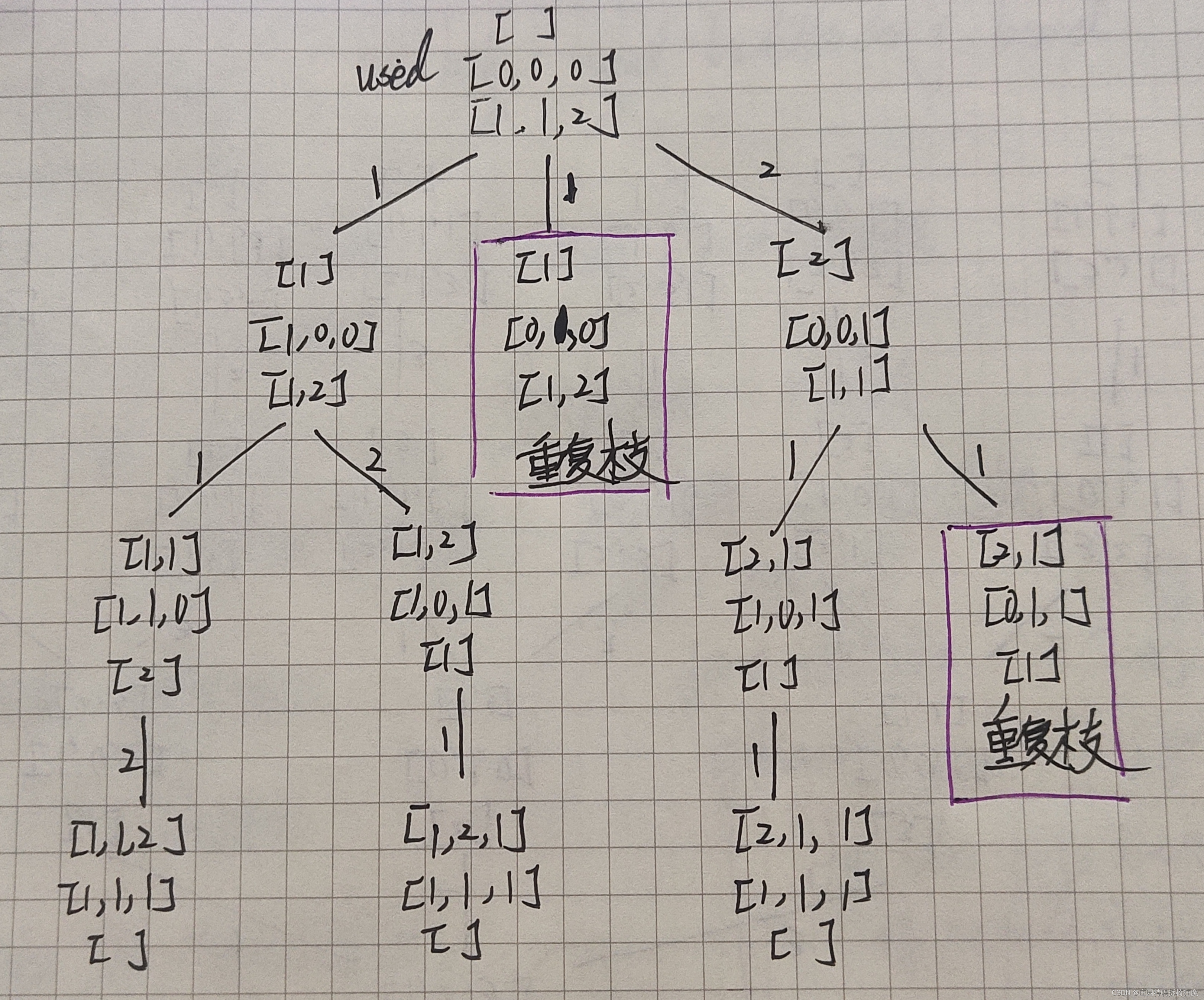
Leetcode 47 全排列 II
题意理解: 首先理解全排列是什么?全排列:使用集合中所有元素按照不同元素进行排列,将所有的排列结果的集合称为全排列。 这里的全排列难度升级了,问题在于集合中的元素是可以重复的。 问题:相同的元素会导致…...
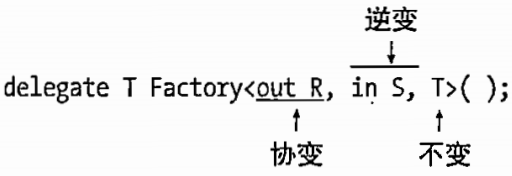
C# 图解教程 第5版 —— 第18章 泛型
文章目录 18.1 什么是泛型18.2 C# 中的泛型18.3 泛型类18.3.1 声明泛型类18.3.2 创建构造类型18.3.3 创建变量和实例18.3.4 使用泛型的示例18.3.5 比较泛型和非泛型栈 18.4 类型参数的约束18.4.1 Where 子句18.4.2 约束类型和次序 18.5 泛型方法18.5.1 声明泛型方法18.5.2 调用…...

保障事务隔离级别的关键措施
目录 引言 1. 锁机制的应用 2. 多版本并发控制(MVCC)的实现 3. 事务日志的记录与恢复 4. 数据库引擎的实现策略 结论 引言 事务隔离级别是数据库管理系统(DBMS)中的一个关键概念,用于控制并发事务之间的可见性。…...

Docker导入导出镜像、导入导出容器的命令详解以及使用的场景
一、Docker 提供用于管理镜像和容器命令 1.1 docker save 与 docker load 这是一对操作,用于处理 Docker 镜像。这个操作会将所有的镜像层以及元数据打包到一个 tar 文件中。然后,你可以使用 docker load 命令将这个 tar 文件导入到任何 Docker 环境中…...
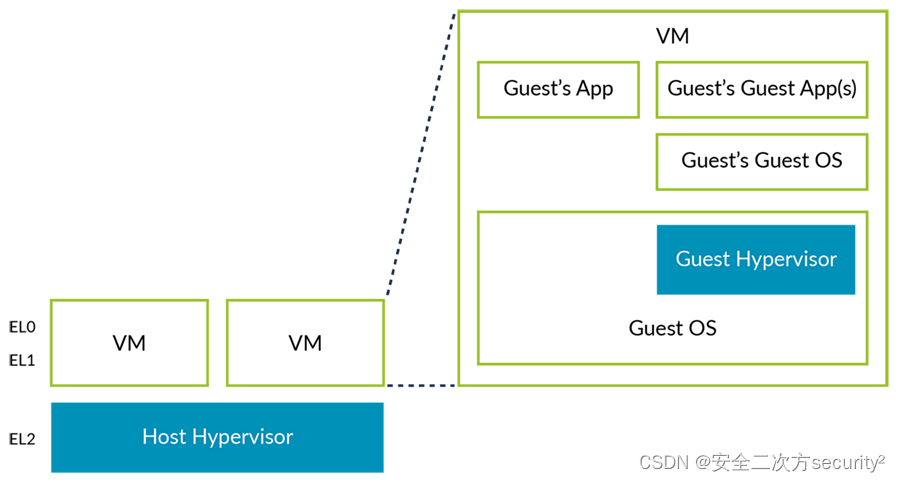
虚拟化嵌套
在理论上,可以在虚拟机(VM)内运行一个hypervisor,这个概念被称为嵌套虚拟化: 我们将第一个hypervisor称为Host Hypervisor,将VM内的hypervisor称为Guest Hypervisor。 在Armv8.3-A发布之前,可以通过在EL0中运行Guest Hypervisor来在VM中运行Guest Hypervisor。然而,这…...

【XILINX】记录ISE/Vivado使用过程中遇到的一些warning及解决方案
前言 XILINX/AMD是大家常用的FPGA,但是在使用其开发工具ISE/Vivado时免不了会遇到很多warning,(大家是不是发现程序越大warning越多?),并且还有很多warning根据消除不了,看着特心烦? 我这里汇总一些我遇到的…...

基本面分析建模——用Excel构建财务筛选系统
价值投资就像相亲——你得设定条件,才能筛选出合适的对象。ROE是"赚钱能力",净利润增长率是"成长潜力",资产负债率是"家底厚不厚"。财报就像企业的"体检报告",而Excel就是你的"红娘系统"。记住,股东的钱生钱能力,才是…...

LaTeX中文排版难题:如何快速解决字体缺失问题?
LaTeX中文排版难题:如何快速解决字体缺失问题? 【免费下载链接】latex-chinese-fonts Simplified Chinese fonts for the LaTeX typesetting. 项目地址: https://gitcode.com/gh_mirrors/la/latex-chinese-fonts 你是否曾经在深夜赶论文时&#x…...

深度架构解析:深圳地铁大数据客流分析系统的技术演进与架构哲学
深度架构解析:深圳地铁大数据客流分析系统的技术演进与架构哲学 【免费下载链接】SZT-bigdata 深圳地铁大数据客流分析系统🚇🚄🌟 项目地址: https://gitcode.com/gh_mirrors/sz/SZT-bigdata 在智慧城市建设的浪潮中&#…...

知识竞赛代表队分组方法详解
🎲 知识竞赛代表队分组方法详解公平 均衡 策略 让每一支队伍都在合适的起点🎯 引言知识竞赛中,代表队的合理分组是赛事公平与精彩的基础。无论是学校比赛、企业活动还是大型公开赛,组织者都需要根据队伍数量和赛制选择合适的分…...

华硕笔记本终极优化神器:GHelper完整使用教程
华硕笔记本终极优化神器:GHelper完整使用教程 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook…...

智能定时任务管理:用自然语言替代Crontab,TickGPTick项目实践
1. 项目概述:一个能“听懂”你需求的定时任务管理器最近在折腾一个自动化脚本项目时,我又一次陷入了“定时任务”的泥潭。相信很多开发者都有同感:写个脚本容易,但想让它定时、可靠、有状态地跑起来,总得和 crontab、s…...

探索高效仓库管理革命:揭秘GreaterWMS开源系统的全面指南
探索高效仓库管理革命:揭秘GreaterWMS开源系统的全面指南 【免费下载链接】GreaterWMS This Inventory management system is the currently Ford Asia Pacific after-sales logistics warehousing supply chain process . After I leave Ford , I start this proje…...

Ollama客户端开发指南:构建本地大模型交互工具的核心原理与实践
1. 项目概述:一个与Ollama对话的客户端工具如果你正在本地运行像Llama 3、Mistral或者Qwen这类开源大语言模型,那么Ollama这个名字对你来说一定不陌生。它让部署和管理这些模型变得像在命令行里敲几个单词一样简单。但Ollama本身主要是一个服务端工具&am…...

如何在不同终端里面使用claude code并使用不同模型
在使用 Claude Code 开发项目时,我们可能会遇到这样的需求:一个终端使用速度更快、成本更低的模型处理日常代码修改,另一个终端使用推理能力更强的模型处理复杂问题。比如:一个终端用 deepseek-v4-pro[1m],另一个终端用…...

Glass Browser:如何在Windows上免费实现终极多任务处理体验
Glass Browser:如何在Windows上免费实现终极多任务处理体验 【免费下载链接】glass-browser A floating, always-on-top, transparent browser for Windows. 项目地址: https://gitcode.com/gh_mirrors/gl/glass-browser 你是否经常需要在多个窗口间来回切换…...