五:爬虫-数据解析之xpath解析
五:数据解析之xpath解析
1.xpath介绍:
-
xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素路径来完成对元素的查找,HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式 -
XPath(XML Path Language)是一种XML的查询语言,它能在XML树状图中寻找节点。XPath用于在XML文档中通过元素和属性进行导航 -
xml是一种标记语法的文本格式,xpath可以方便的定位xml中的元素和其中的属性值。lxml是Python中的一个第三方模块,它包含了将html文本转成xml对象,和对对象执行xpath的功能
lxml的安装:
#在终端输入
pip install lxml
xpath的弊端:
当我们在批量获取数据的时候,如果存在的特别数据比较多,这个时候只用xpath的话,会无法满足用户的需求,所以针对于不同的网页,我们要灵活的去运用我们的数据解析方式
(1)HTML树状结构图:

HTML 的结构就是树形结构,HTML 是根节点,所有的其它元素节点都是从根节点发出的,其它的元素都是这棵树上的节点,每个节点还可能有属性和文本值,而路径就是指某个节点到另一个节点的路线
(2)节点之间的关系:
- 父节点:
HTML是 body 和head节点的父节点 - 子节点:
head和body是HTML的子节点 - 兄弟节点:拥有相同的父节点,
head和body就是兄弟节点,title和div不是兄弟,因为他们不是同一个父节点 - 祖先节点:
body是form的祖先节点,爷爷辈及以上 - 后代节点:
form是HTML的后代节点,孙子辈及以下
2.Xpath中的绝对路径与相对路径 :
Xpath中的绝对路径是从HTML根节点开始算的;而相对路径(使用的更多)则是从任意节点开始的。通过开发者工具,我们可以拷贝到Xpath的绝对路径和相对路径代码:

注意: 绝对路径是以 Elements 为基准去寻找的,我们爬虫获取的是右键的网页源代码;右键的网页源代码 != Elements,Elements 是前端页面最终渲染的结果,它与网页源代码是有属性上的差异的;但右键的网页源代码与Elements是非常相似的,但是在某些元素或者元素属性上会存在不同。这就会导致我们直接右键复制的xpath获取不到真正的数据;所以说只能手写,不能复制(把数据解析全部学会之后,可以复制,因为到那个时候就有能力对复制到的内容进行微调了)
(1)绝对路径(了解即可):
在Xpath中最直观的定位策略就是绝对路径,绝对路径是从根节点/html开始往下一层层的表示,直到出来需要的节点为止
(2)相对路径(常用):
在Xpath中相对路径方法以 “//” 开头,相对路径可以从任意的节点开始,一般会选取一个可以唯一定位到的元素开始写,这样可以增加查找的准确性
相对路径的定位语法:
(1)基本定位语法:
| 表达式 | 说明 | 举例 |
|---|---|---|
/ | 从根节点开始选取 | /html/div/span |
// | 从任意节点开始选取 | //input |
. | 选取当前节点 | |
.. | 选取当前节点的父节点 | //input/.. 选取input的父节点 |
@ | 选取属性或者根据属性选取 | //input[@data]选取具备data属性的input元素 //@data 选取所有data属性 |
* | 通配符,表示任意节点或任意属性 |
(2)元素属性定位:

(3)层级属性结合定位:
遇到某些元素无法精确定位的时候,可以查找其父级及其祖先节点,找到有确定的祖先节点后通过层级依次向下定位
示例:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<form action="search" id="form" method="post"><span class="bg"><span class="soutu">搜索</span></span><span class="soutu"><input type="text" name="key" id="su"></span><div></div>
</form>
</body>
</html>
图片解析:

(4)使用谓语定位:
谓语是Xpath中用于描述元素位置,主要有数字下标、最后一个子元素last()、元素下标函数position()
注意: Xpath中的下标从 1 开始
图片解析:
1、使用下标的方式,从form找到input:
//form[@id="form"]/span[2]/input2、查找最后一个子元素,选取form下的最后一个span:
//form[@id="form"]/span[last()]3、查找倒数第几个子元素,选取 form下的倒数第二个span:
//form[@id="form"]/span[last()-1]4、使用 position() 函数,选取 from 下第二个span:
//form[@id="form"]/span[position()=2]5、使用 position() 函数,选取下标大于 2 的span:
//form[@id="form"]/span[position()>2]
(5)使用逻辑运算符定位:
用于嵌套的标签,如果元素的某个属性无法精确定位到这个元素,还可以用逻辑运算符and连接多个属性进行定位
以百度首页为例:
使用and:
//*[@name='wd' and @class='s_ipt']
#查找 name 属性为 wd 并且 class 属性为 s_ipt 的任意元素使用or:
//*[@name='wd' or @class='s_ipt']
#查找 name 属性为 wd 或者 class 属性为 s_ipt 的任意元素,取其中之一满足即可
以上述示例代码为例:
使用|同时查找多个路径,取或:
//form[@id="form"]//span | //form[@id="form"]//input
(6)使用文本定位:
我们在爬取网站使用Xpath提取数据的时候,最常使用的就是Xpath的text()方法,该方法可以提取当前元素的信息,但是某些元素下包含很多嵌套元素,这时候就用到了string()方法
爬取别逗了网站示例代码:
import requests
from lxml import etreeurl = 'https://www.biedoul.com/article/180839'headers= {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}response = requests.get(url,headers=headers)
response.encoding = 'utf-8' # 在requests.get的时候,会默认指定一个编码,但默认指定的编码不一定会是utf-8,是随机的# 将获取的网页源代码html文件转换成xml对象,方便后续执行xpath语法
html = etree.HTML(response.text)
data = html.xpath('//div[@class="cc2"]//text()') # //text()指的是取标签中的文本值,不是属性值
# print(data)
#
# data = [i.replace('\r\n','') for i in data]
# print('\n'.join(data))data1 = html.xpath('//div[@class="cc2"]')[0].xpath('string(.)')
print(data1)
注意: xpath对象获取的数据返回的是一个列表
(7)使用部分匹配函数:
| 函数 | 说明 | 示例 |
|---|---|---|
contains | 选取属性或者文本包含某些字符 | //div[contains(@id, 'data')]选取id属性包含data的div元素 |
starts-with | 选取属性或者文本以某些字符开头 | //div[starts-with(@id, 'data')]选取id属性以data开头的div元素 |
ends-with | 选取属性或者文本以某些字符结尾 | //div[ends-with(@id, 'require')]选取id属性以require结尾的div元素 |
3.lxml的使用与xpath实战:
(1)lxml的基本使用:
# 导入模块
from lxml import etree
# html源代码
web_data = """<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>"""
# 将html转成xml对象
element = etree.HTML(web_data)
# print(element)
# 获取li标签下面的a标签的href
links = element.xpath('//ul/li/a/@href')
print(links) # 列表
# 获取li标签下面的a标签的文本数据
result = element.xpath('//ul/li/a/text()')
print(result)
(2)xpath实战 – 豆瓣top250示例代码:
import requests
from lxml import etree
'''
目标:熟悉xpath解析数的方式
需求:爬取电影的名称 评分 引言 详情页的url 翻页爬取1-10页 保存到列表中如何实现?
设计技术与需要的库 requests lxml(etree)实现步骤
1 页面分析(一般讲数据解析模块 都是静态页面)1.1 通过观察看网页源代码中是否有我们想要的数据 如果有就分析这个url如果没有再通过ajax寻找接口 通过分析数据在网页源代码中1.2 确定目标urlhttps://movie.douban.com/top250?start=0&filter= 第一页通过页面分析发现所有我们想要的数据都在一个div[class="info"]里面具体实现步骤
1 获取整个网页的源码 html
2 将获取的数据源码转成一个element对象(xml)
3 通过element对象实现xpath语法 对数据进行爬取(标题 评分 引言 详情页的url)
4 保存数据 先保存到字典中-->列表中'''# 定义一个函数用来获取网页源代码
def getsource(pagelink):# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}# 获取源码response = requests.get(pagelink, headers=headers)response.encoding = 'utf-8'html = response.textreturn html# 定义一个函数用于解析我们的网页源代码并获取我们想要的数据
def geteveryitem(html):element = etree.HTML(html)# 拿到[class="info"]的所有divmovieitemlist = element.xpath('//li//div[@class="info"]')# print(movieitemlist,len(movieitemlist))# 定义一个列表itemlist = []for item in movieitemlist:# 定义一个字典itemdict = {}# 标题title = item.xpath('./div[@class="hd"]/a/span[@class="title"]/text()')title = "".join(title).replace("\xa0", "")# print(title)# 副标题othertitle = item.xpath('./div[@class="hd"]/a/span[@class="other"]/text()')[0].replace("\xa0", "")# print(othertitle)# 评分grade = item.xpath('./div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]# print(grade)# 详情页的urllink = item.xpath('div[@class="hd"]/a/@href')[0]# print(link)# 引言quote = item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()')# print(quote)# list index out of range# 处理方式1 非空处理if quote:quote = quote[0]else:quote = ""# 将数据存放到字典中itemdict['title'] = ''.join(title + othertitle)itemdict['grade'] = gradeitemdict['link'] = linkitemdict['quote'] = quote# print(itemdict)itemlist.append(itemdict)# print(itemlist)return itemlistif __name__ == '__main__':url = 'https://movie.douban.com/top250?start=0&filter='html = getsource(url)itemlist = geteveryitem(html)print(itemlist)
dict['quote'] = quote# print(itemdict)itemlist.append(itemdict)# print(itemlist)return itemlistif __name__ == '__main__':url = 'https://movie.douban.com/top250?start=0&filter='html = getsource(url)itemlist = geteveryitem(html)print(itemlist)
相关文章:

五:爬虫-数据解析之xpath解析
五:数据解析之xpath解析 1.xpath介绍: xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素路径来完成对元素的查找,HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式 XPa…...

什么是Laravel?它有哪些特性?
Laravel 是一款流行的 PHP Web 框架,设计用于构建现代、优雅且功能强大的 Web 应用程序。它提供了一套丰富的工具和库,以简化常见的开发任务,同时保持灵活性和可扩展性。以下是 Laravel 框架的一些主要特性: 优雅的语法࿱…...
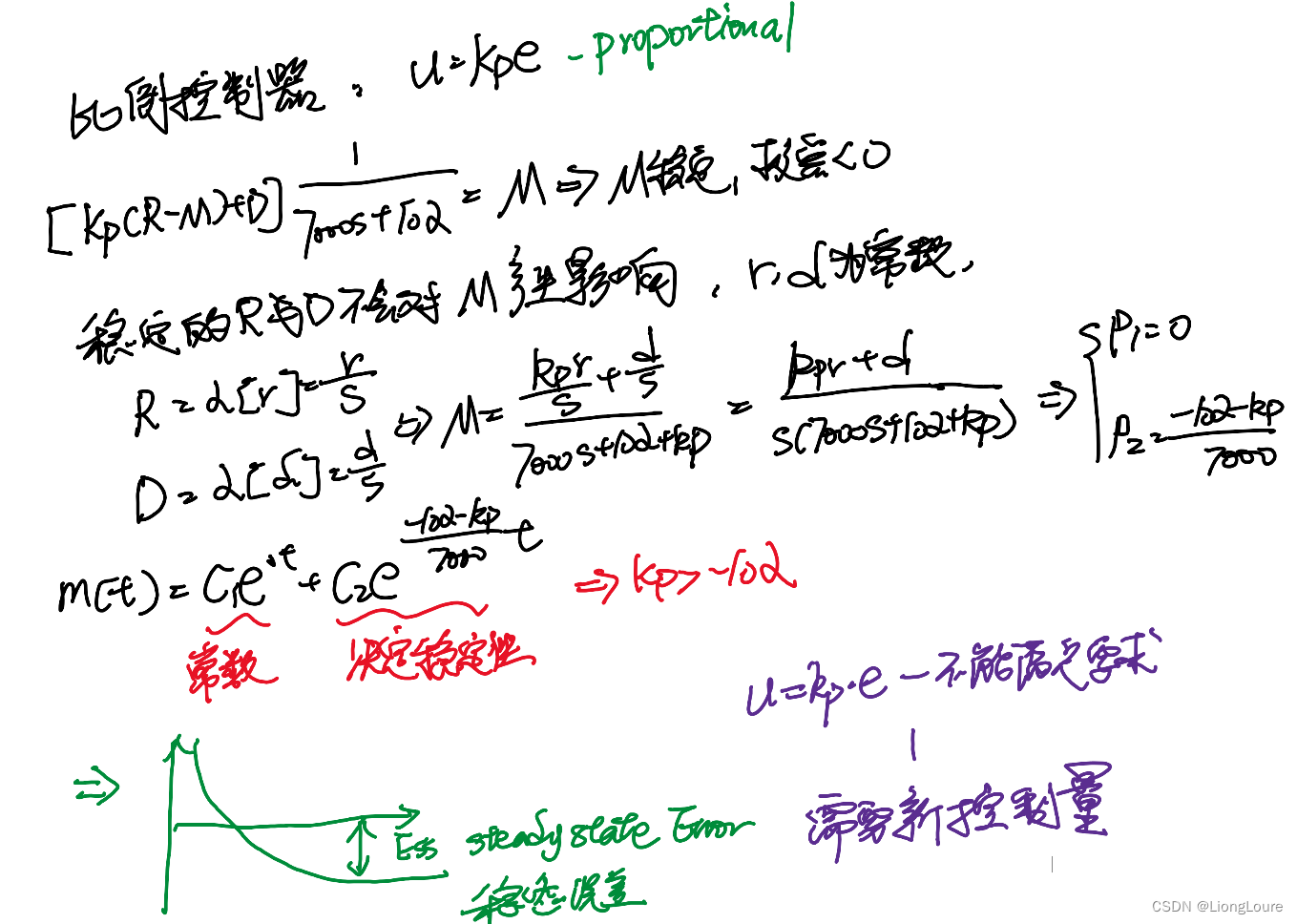
[足式机器人]Part2 Dr. CAN学习笔记-自动控制原理Ch1-3燃烧卡路里-系统分析实例
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-自动控制原理Ch1-3燃烧卡路里-系统分析实例 1. 数学模型2. 比例控制 Proprotional Control 1. 数学模型 2. 比例控制 Proprotional Control...
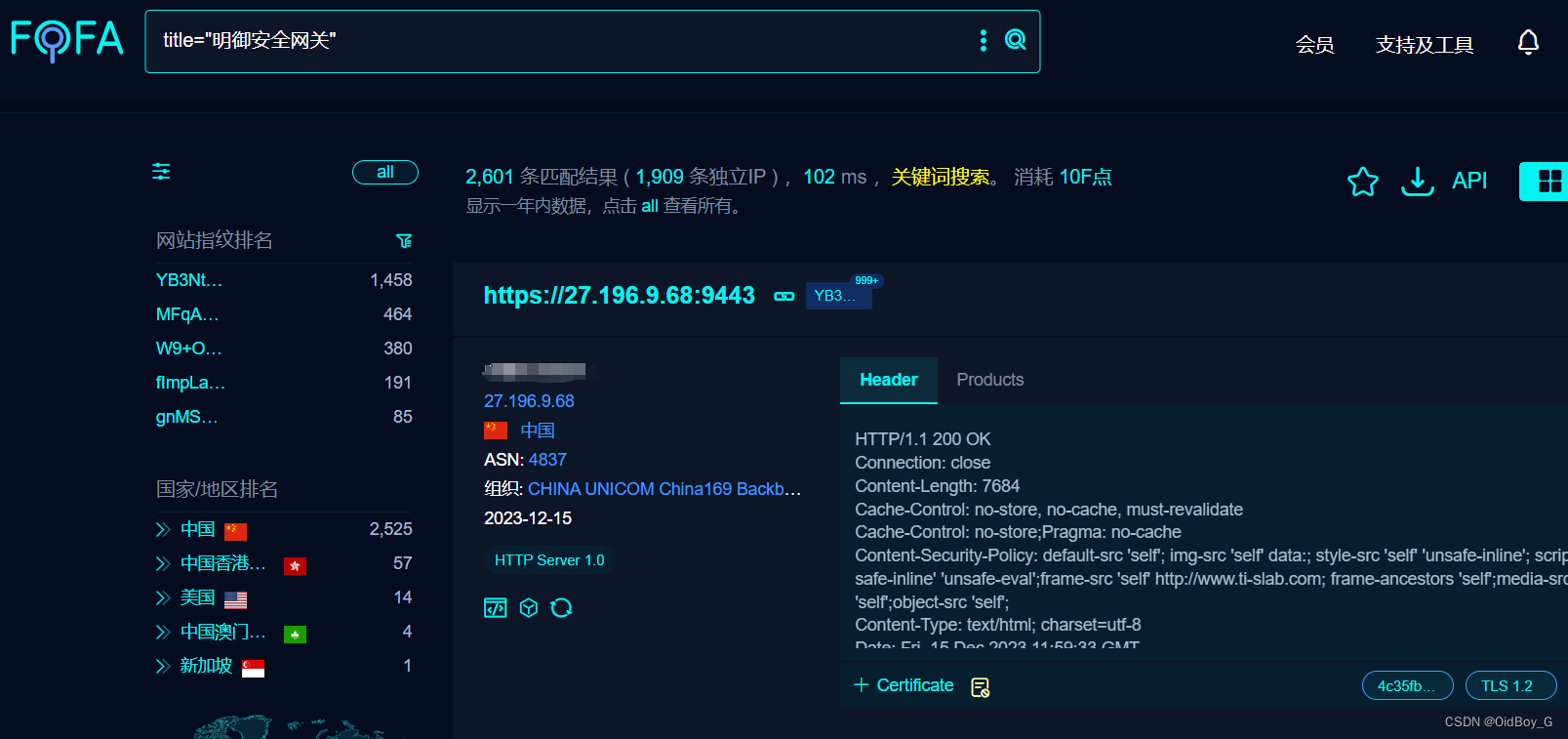
安恒明御安全网关 aaa_local_web_preview文件上传漏洞复现
0x01 产品简介 明御安全网关秉持安全可视、简单有效的理念,以资产为视角,构建全流程防御的下一代安全防护体系,并融合传统防火墙、入侵检测、入侵防御系统、防病毒网关、上网行为管控、VPN网关、威胁情报等安全模块于一体的智慧化安全网关。 0x02 漏洞概述 明御安全网关在…...
基于ssm企业人事管理系统的设计与实现论文
摘 要 进入信息时代以来,很多数据都需要配套软件协助处理,这样可以解决传统方式带来的管理困扰。比如耗时长,成本高,维护数据困难,数据易丢失等缺点。本次使用数据库工具MySQL和编程技术SSM开发的企业人事管理系统&am…...

你知道为什么要加 final 关键字了吗?
嗨,大家好,欢迎来到程序猿漠然公众号,我是漠然。 在Java编程中,我们经常会遇到需要使用final关键字的情况。那么,为什么要使用final关键字呢?它到底有什么作用?本文将从以下几个方面来详细…...
找不到mfc100u.dll,程序无法继续执行?三步即可搞定
在使用电脑过程中,我们经常会遇到一些错误提示,其中之一就是“找不到mfc100u.dll”。mfc100u.dll是Microsoft Foundation Class(MFC)库中的一个版本特定的DLL文件。MFC是微软公司为简化Windows应用程序开发而提供的一套C类库。它包…...
postman接口测试之Postman配置环境变量和全局变量
前言 我们在测试的过程中,遇到最多的问题也可以是环境的问题了吧,今天开发用了这个测试环境,明天又换了另一个测试环境,这样对于我们测试非常的麻烦,特别最接口的时候需要来回的输入环境地址比较麻烦,今天…...

OpenSSL 编程示例
参考:深入探索 OpenSSL:概念、原理、开发步骤、使用方法、使用场景及代码示例 地址:https://oneisall.blog.csdn.net/article/details/131489812?spm1001.2014.3001.5502 目录 1. OpenSSL 概念2. OpenSSL 原理3. OpenSSL 开发步骤4. OpenSSL…...
-k8s核心对象CronJob)
K8S学习指南(17)-k8s核心对象CronJob
文章目录 前言什么是CronJob?示例演示步骤1:创建CronJob步骤2:定义任务模板步骤3:部署CronJob步骤4:监视CronJob的执行 总结 前言 Kubernetes(简称K8s)是一种用于自动部署、扩展和管理容器化应…...
任务调度的介绍)
单片机Freertos入门(二)任务调度的介绍
简介: FreeRTOS支持的任务调度方法有抢占式、协作式、时间片轮转,下面分别来讲解。 1.抢占式调度 抢占式调度,是最高优先级的任务一旦就绪,总能得到CPU的执行权。 高优先级运行时候,低优先级不运行,等待…...
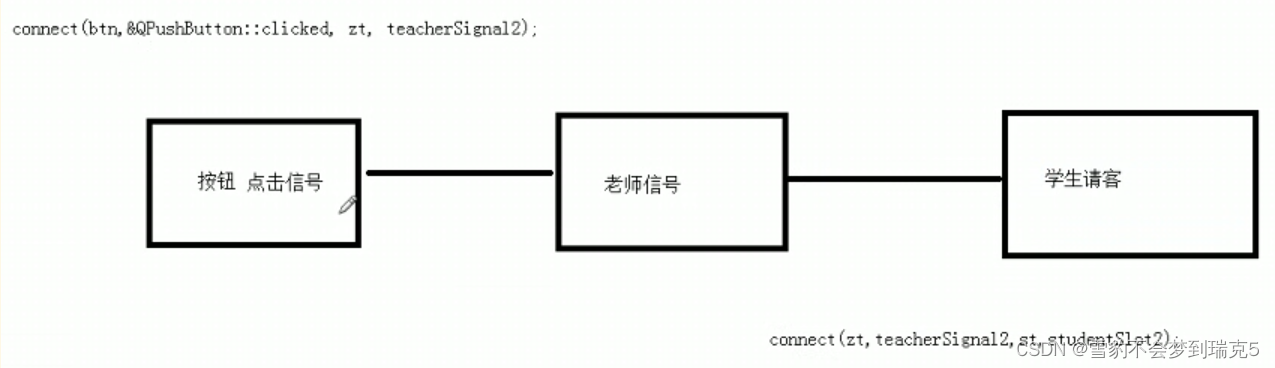
QT----自定义信号和槽
第二天 2.1自定义信号和槽 新建一个Qtclass 自定义信号:返回值是void ,只需要声明,不需要实现,可以有参数,可以重载 自定义槽:返回值void ,需要声明,也需要实现,可以有…...
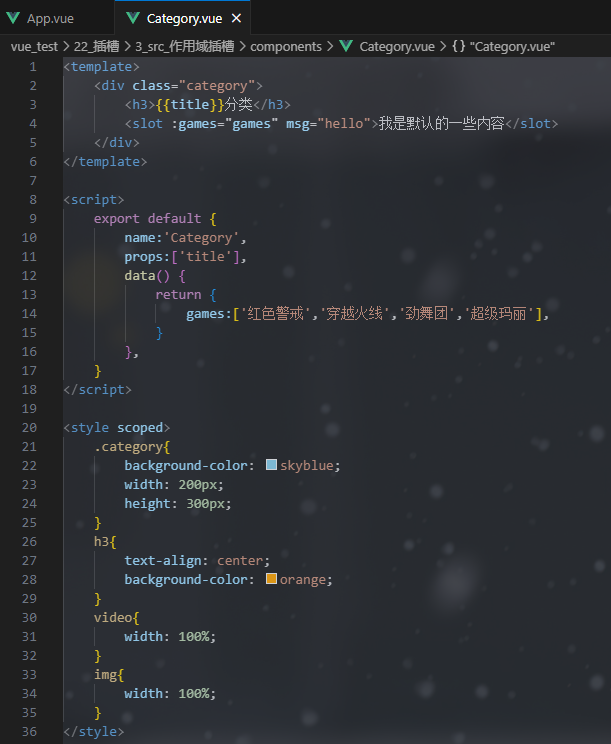
【Vue第4章】Vue中的ajax_Vue2
目录 4.1 解决开发环境Ajax跨域问题 4.1.1 解决跨域的三种方法 4.1.2 使用代理服务器 4.1.3 笔记与代码 4.1.3.1 笔记 4.1.3.2 19_src_配置代理服务器 4.2 github用户搜索案例 4.2.1 效果 4.2.2 接口地址 4.2.3 笔记与代码 4.2.3.1 20_src_github搜索案例 4.3 vue项…...

力扣labuladong——一刷day72
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣109. 有序链表转换二叉搜索树二、力扣1382. 将二叉搜索树变平衡 前言 二叉树的递归分为「遍历」和「分解问题」两种思维模式,这道题需要用到…...

Leetcode—509.斐波那契数【简单】
2023每日刷题(五十七) Leetcode—509.斐波那契数 实现代码 int fib(int n){if(n 0) {return 0;}if(n 1) {return 1;}return fib(n-1) fib(n-2); }运行结果 之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点…...

山峰个数 - 华为OD统一考试
OD统一考试 分值: 100分 题解: Java / Python / C++ 题目描述 给定一个数组,数组中的每个元素代表该位置的海拔高度。0表示平地,>=1时表示属于某个山峰,山峰的定义为当某个位置的左右海拔均小于自己的海拔时,该位置为山峰。数组起始位置计算时可只满足一边的条件。 …...

38、池化的特征不变性
池化操作有一个比较独特的特性,叫作特征不变性。 很多文章中是这么描述池化的特征不变性的:池化操作的特征不变性,可以提高模型对图片平移、缩放和旋转等变换的鲁棒性。 之前看到这句话的时候,似懂非懂。后来查了一些资料&#…...

051:vue项目webpack打包后查看各个文件大小
第051个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...
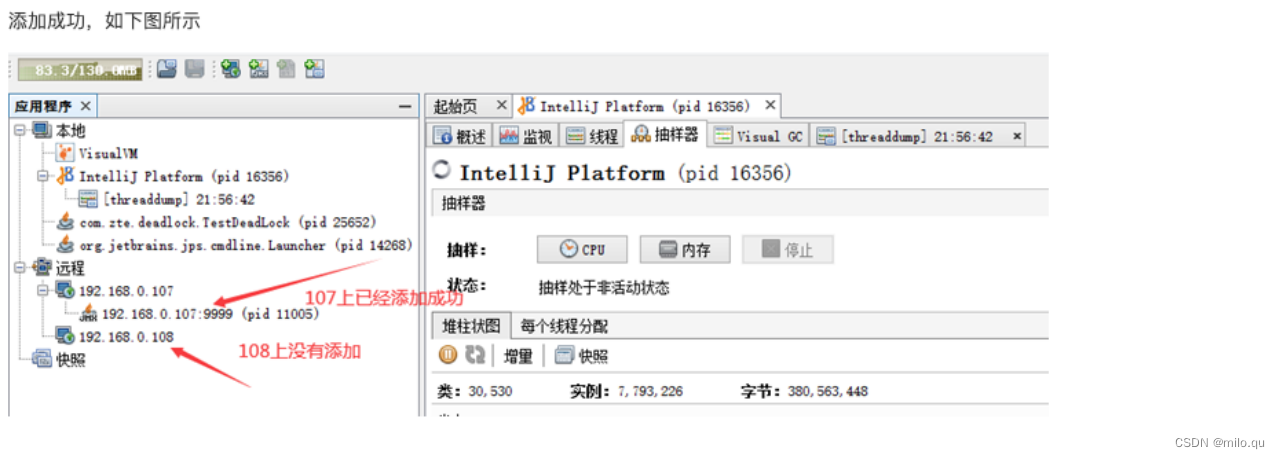
JVM调优:参数(学习笔记)
一、jvm的运行参数 标准参数 -help、-version、-D参数 jvm的标准参数,一般都是很稳定的,在未来的JVM版本中不会改变,可以使用java -help 检索出所有的标准参数。 通过以下命令查看: 命令:java -help 可以看到我们经常…...
MVC Gantt Wrapper:RadiantQ jQuery
The RadiantQ jQuery Gantt Package includes fully functional native MVC Wrappers that let you declaratively and seamlessly configure the Gantt component within your aspx or cshtm pages just like any other MVC extensions. 如果您还没有准备好转向完全基于客户端…...

从锡疫到无铅焊料失效:材料环境可靠性设计实战解析
1. 从拿破仑的纽扣说起:材料失效背后的工程警示在电子工程领域,我们每天都在与材料打交道。从PCB上的焊点,到芯片内部的金属互连,再到外壳的塑料,材料的可靠性直接决定了产品的成败。几年前,当整个行业因Ro…...

Hotkey Detective终极指南:3分钟快速定位Windows热键冲突的完整教程
Hotkey Detective终极指南:3分钟快速定位Windows热键冲突的完整教程 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

安全测试人员必备:手把手教你用WePE+Ghost镜像在VMware里快速部署Win7靶机环境
安全测试人员必备:手把手教你用WePEGhost镜像在VMware里快速部署Win7靶机环境 在网络安全学习和渗透测试领域,拥有一个随时可用的标准化测试环境至关重要。对于刚入门的安全研究员、白帽子或需要进行漏洞复现的技术人员来说,Windows 7系统仍然…...
优化技术与实践)
半导体制造中的光学邻近校正(OPC)优化技术与实践
1. 光学邻近校正(OPC)在半导体制造中的关键作用在32nm以下节点的半导体制造中,光学邻近效应已成为制约光刻精度的首要瓶颈。当特征尺寸远小于曝光波长时(例如193nm光刻下的22nm节点),光线衍射会导致图案边缘…...
)
JY901陀螺仪数据解析实战:从原始字节到工程可用的姿态角(附完整代码)
JY901陀螺仪数据解析实战:从原始字节到工程可用的姿态角(附完整代码) 在嵌入式开发中,姿态感知是实现自动平衡、导航定位等功能的基石。JY901作为一款高性价比的9轴运动传感器,其输出的原始数据需要经过精确解析才能转…...

AI代码库分析:用大模型自动生成项目教程与架构图
1. 项目概述:用AI将陌生代码库变成你的专属教程 你有没有过这样的经历?接手一个新项目,或者想学习一个热门的开源库,打开GitHub仓库,面对成百上千个文件、错综复杂的目录结构,瞬间感觉无从下手。README.md可…...

保姆级教程:手把手教你用MuJoCo和Spinning Up让UR5机械臂学会‘指哪打哪’
从零实现UR5机械臂强化学习控制:MuJoCo与Spinning Up实战指南 看着实验室里崭新的UR5机械臂,你是否想过让它像人类手臂一样灵活地指向任意位置?传统控制方法需要复杂的运动学计算,而强化学习能让机械臂通过"试错"自主掌…...
)
【限时解禁】Google I/O 2024未发布的Gemini Android Enterprise Integration白皮书核心章节(仅剩37份授权访问码)
更多请点击: https://intelliparadigm.com 第一章:Gemini Android深度整合的战略定位与演进脉络 Google 将 Gemini 模型深度嵌入 Android 生态,并非单纯叠加 AI 功能,而是重构操作系统级智能代理的交互范式。其战略内核在于将大模…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...

年薪50W+!AI产品经理爆火,0经验也能入行?3类人才需求+4大陪跑方案助你拿下高薪offer!
今年,无论是一些头部厂商,中小厂商,从海外到国内,大中小公司都在积极拥抱讨论AI和拥抱AI。AI 相关的人才缺口已达 500 万,其中AI产品经理需求旺盛,薪资中位数再创新高,36k/月。如果是在头部公司…...