PyTorch: 基于【VGG16】处理MNIST数据集的图像分类任务【准确率98.9%+】
目录
- 引言
- 在Conda虚拟环境下安装pytorch
- 步骤一:利用代码自动下载mnist数据集
- 步骤二:搭建基于VGG16的图像分类模型
- 步骤三:训练模型
- 步骤四:测试模型
- 运行结果
- 后续模型的优化和改进建议
- 完整代码
- 结束语
引言
在本博客中,小编将向大家介绍如何使用VGG16处理MNIST数据集的图像分类任务。MNIST数据集是一个常用的手写数字分类数据集,包含60,000个训练样本和10,000个测试样本。我们将使用Python编程语言和PyTorch深度学习框架来实现这个任务。
在Conda虚拟环境下安装pytorch
# CUDA 11.6
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
# CUDA 11.3
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# CUDA 10.2
pip install torch==1.12.1+cu102 torchvision==0.13.1+cu102 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu102
# CPU only
pip install torch==1.12.1+cpu torchvision==0.13.1+cpu torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cpu
步骤一:利用代码自动下载mnist数据集
import torchvision.datasets as datasets
import torchvision.transforms as transforms # 定义数据预处理操作
transform = transforms.Compose([transforms.Resize(224), # 将图像大小调整为(224, 224)transforms.ToTensor(), # 将图像转换为PyTorch张量transforms.Normalize((0.5,), (0.5,)) # 对图像进行归一化
])# 下载并加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
步骤二:搭建基于VGG16的图像分类模型
class VGGClassifier(nn.Module):def __init__(self, num_classes):super(VGGClassifier, self).__init__()self.features = models.vgg16(pretrained=True).features # 使用预训练的VGG16模型作为特征提取器# 重构VGG16网络的第一层卷积层,适配mnist数据的灰度图像格式self.features[0] = nn.Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096), # 添加一个全连接层,输入特征维度为512x7x7,输出维度为4096nn.ReLU(True),nn.Dropout(), # 随机将一些神经元“关闭”,这样可以有效地防止过拟合。nn.Linear(4096, 4096), # 添加一个全连接层,输入和输出维度都为4096nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes), # 添加一个全连接层,输入维度为4096,输出维度为类别数(10))self._initialize_weights() # 初始化权重参数def forward(self, x):x = self.features(x) # 通过特征提取器提取特征x = x.view(x.size(0), -1) # 将特征张量展平为一维向量x = self.classifier(x) # 通过分类器进行分类预测return xdef _initialize_weights(self): # 定义初始化权重的方法,使用Xavier初始化方法for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
步骤三:训练模型
import torch.optim as optim
from torch.utils.data import DataLoader # 定义超参数和训练参数
batch_size = 64 # 批处理大小
num_epochs = 5 # 训练轮数
learning_rate = 0.01 # 学习率
num_classes = 10 # 类别数(MNIST数据集有10个类别)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 判断是否使用GPU进行训练,如果有GPU则使用GPU进行训练,否则使用CPU。# 定义训练集和测试集的数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) # 初始化模型和优化器
model = VGGClassifier(num_classes=num_classes).to(device) # 将模型移动到指定设备(GPU或CPU)
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # 使用随机梯度下降优化器(SGD) # 训练模型
for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): images = images.to(device) # 将图像数据移动到指定设备 labels = labels.to(device) # 将标签数据移动到指定设备 # 前向传播 outputs = model(images) loss = criterion(outputs, labels) # 反向传播和优化 optimizer.zero_grad() # 清空梯度缓存 loss.backward() # 计算梯度 optimizer.step() # 更新权重参数 if (i+1) % 100 == 0: # 每100个batch打印一次训练信息 print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item())) # 保存模型参数
torch.save(model.state_dict(), './model.pth')
步骤四:测试模型
# 加载训练好的模型参数
model.load_state_dict(torch.load('./model.pth'))
model.eval() # 将模型设置为评估模式,关闭dropout等操作# 定义评估指标变量
correct = 0 # 记录预测正确的样本数量
total = 0 # 记录总样本数量# 测试模型性能
with torch.no_grad(): # 关闭梯度计算,节省内存空间for images, labels in test_loader:images = images.to(device) # 将图像数据移动到指定设备labels = labels.to(device) # 将标签数据移动到指定设备outputs = model(images) # 模型前向传播,得到预测结果_, predicted = torch.max(outputs.data, 1) # 取预测结果的最大值对应的类别作为预测类别total += labels.size(0) # 更新总样本数量correct += (predicted == labels).sum().item() # 统计预测正确的样本数量# 计算模型准确率并打印出来
accuracy = 100 * correct / total # 计算准确率,将正确预测的样本数量除以总样本数量并乘以100得到百分比形式的准确率。
print('Accuracy of the model on the test images: {} %'.format(accuracy)) # 打印出模型的准确率。运行结果

后续模型的优化和改进建议
- 数据增强:通过旋转、缩放、平移等方式来增加训练数据,从而让模型拥有更好的泛化能力。
- 调整模型参数:可以尝试调整模型的参数,比如学习率、批次大小、迭代次数等,来提高模型的性能。
- 更换网络结构:可以尝试使用更深的网络结构,如ResNet、DenseNet等,来提高模型的性能。
- 调整优化器:本次代码采用SGD优化器,但仍可以尝试使用不同的优化器,如Adam、RMSprop等,来找到最适合我们模型的优化器。
- 添加正则化操作:为了防止过拟合,可以添加一些正则化项,如L1正则化、L2正则化等。
- 代码目前只有等训练完全结束后才能进入测试阶段,后续可以在每个epoch结束,甚至是指定的迭代次数完成后便进入测试阶段。因为训练完全结束的模型很可能已经过拟合,在测试集上不能表现较强的泛化能力。
完整代码
import torch
import torch.nn as nnimport torch.optim as optim
from torch.utils.data import DataLoaderimport torchvision.models as models
import torchvision.datasets as datasets
import torchvision.transforms as transformsimport warnings
warnings.filterwarnings("ignore")# 定义数据预处理操作
transform = transforms.Compose([transforms.Resize(224), # 将图像大小调整为(224, 224)transforms.ToTensor(), # 将图像转换为PyTorch张量transforms.Normalize((0.5,), (0.5,)) # 对图像进行归一化
])# 下载并加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)class VGGClassifier(nn.Module):def __init__(self, num_classes):super(VGGClassifier, self).__init__()self.features = models.vgg16(pretrained=True).features # 使用预训练的VGG16模型作为特征提取器# 重构网络的第一层卷积层,适配mnist数据的灰度图像格式self.features[0] = nn.Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096), # 添加一个全连接层,输入特征维度为512x7x7,输出维度为4096nn.ReLU(True),nn.Dropout(), # 随机将一些神经元“关闭”,有效地防止过拟合。nn.Linear(4096, 4096), # 添加一个全连接层,输入和输出维度都为4096nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes), # 添加一个全连接层,输入维度为4096,输出维度为类别数(10))self._initialize_weights() # 初始化权重参数def forward(self, x):x = self.features(x) # 通过特征提取器提取特征x = x.view(x.size(0), -1) # 将特征张量展平为一维向量x = self.classifier(x) # 通过分类器进行分类预测return xdef _initialize_weights(self): # 定义初始化权重的方法,使用Xavier初始化方法for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)# 定义超参数和训练参数
batch_size = 64 # 批处理大小
num_epochs = 5 # 训练轮数(epoch)
learning_rate = 0.01 # 学习率(learning rate)
num_classes = 10 # 类别数(MNIST数据集有10个类别)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断是否使用GPU进行训练,如果有GPU则使用第一个GPU(cuda:0)进行训练,否则使用CPU进行训练。# 定义数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)# 初始化模型和优化器
model = VGGClassifier(num_classes=num_classes).to(device) # 将模型移动到指定设备(GPU或CPU)
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # 使用随机梯度下降优化器(SGD)# 训练模型
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):images = images.to(device) # 将图像数据移动到指定设备labels = labels.to(device) # 将标签数据移动到指定设备# 前向传播outputs = model(images)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad() # 清空梯度缓存loss.backward() # 计算梯度optimizer.step() # 更新权重参数if (i + 1) % 100 == 0: # 每100个batch打印一次训练信息print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, i + 1, len(train_loader),loss.item()))# 训练结束,保存模型参数
torch.save(model.state_dict(), './model.pth')# 加载训练好的模型参数
model.load_state_dict(torch.load('./model.pth'))
model.eval() # 将模型设置为评估模式,关闭dropout等操作# 定义评估指标变量
correct = 0 # 记录预测正确的样本数量
total = 0 # 记录总样本数量# 测试模型性能
with torch.no_grad(): # 关闭梯度计算,节省内存空间for images, labels in test_loader:images = images.to(device) # 将图像数据移动到指定设备labels = labels.to(device) # 将标签数据移动到指定设备outputs = model(images) # 模型前向传播,得到预测结果_, predicted = torch.max(outputs.data, 1) # 取预测结果的最大值对应的类别作为预测类别total += labels.size(0) # 更新总样本数量correct += (predicted == labels).sum().item() # 统计预测正确的样本数量# 计算模型准确率并打印出来
accuracy = 100 * correct / total # 计算准确率,将正确预测的样本数量除以总样本数量并乘以100得到百分比形式的准确率。
print('Accuracy of the model on the test images: {} %'.format(accuracy)) # 打印出模型的准确率。
结束语
如果本博文对你有所帮助/启发,可以点个赞/收藏支持一下,如果能够持续关注,小编感激不尽~
如果有相关需求/问题需要小编帮助,欢迎私信~
小编会坚持创作,持续优化博文质量,给读者带来更好de阅读体验~
相关文章:
PyTorch: 基于【VGG16】处理MNIST数据集的图像分类任务【准确率98.9%+】
目录 引言在Conda虚拟环境下安装pytorch步骤一:利用代码自动下载mnist数据集步骤二:搭建基于VGG16的图像分类模型步骤三:训练模型步骤四:测试模型运行结果后续模型的优化和改进建议完整代码结束语 引言 在本博客中,小…...
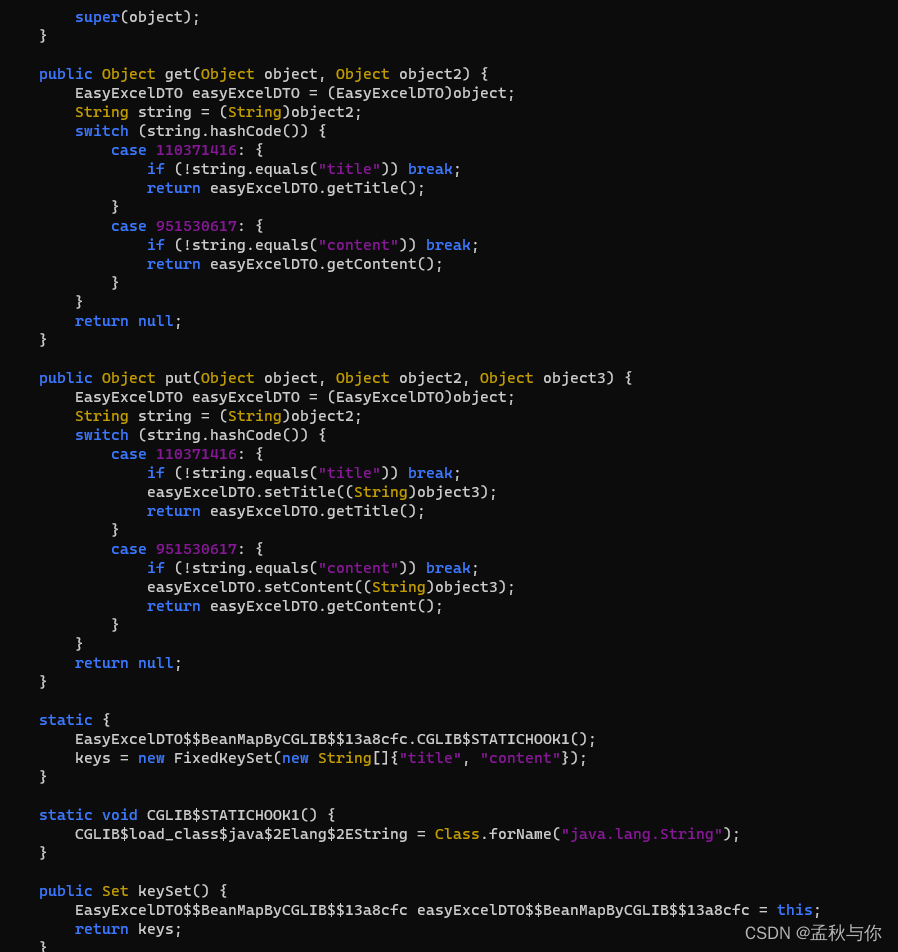
【lombok】从easyExcel read不到值到cglib @Accessors(chain = true)隐藏的大坑
背景: 在一次使用easyExcel.read 读取excel时,发现实体类字段没有值,在反复测试后,发现去掉Accessors(chain true)就正常了,为了验证原因,进行了一次代码跟踪 由于调用链路特别长,只列举出部分代码&#x…...

1-SaaS通识
云计算 讲SaaS必须先讲云计算。云计算通过互联网提供计算服务,包括服务器、存储、数据库、网络、应用等,采用按需付费的定价模式。 云计算的4种部署模式 公有云:由云服务商拥有和管理,就好比水电,居民共享ÿ…...

Spring Boot实现接口幂等
Spring Boot实现接口幂等 1、pom依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http:…...
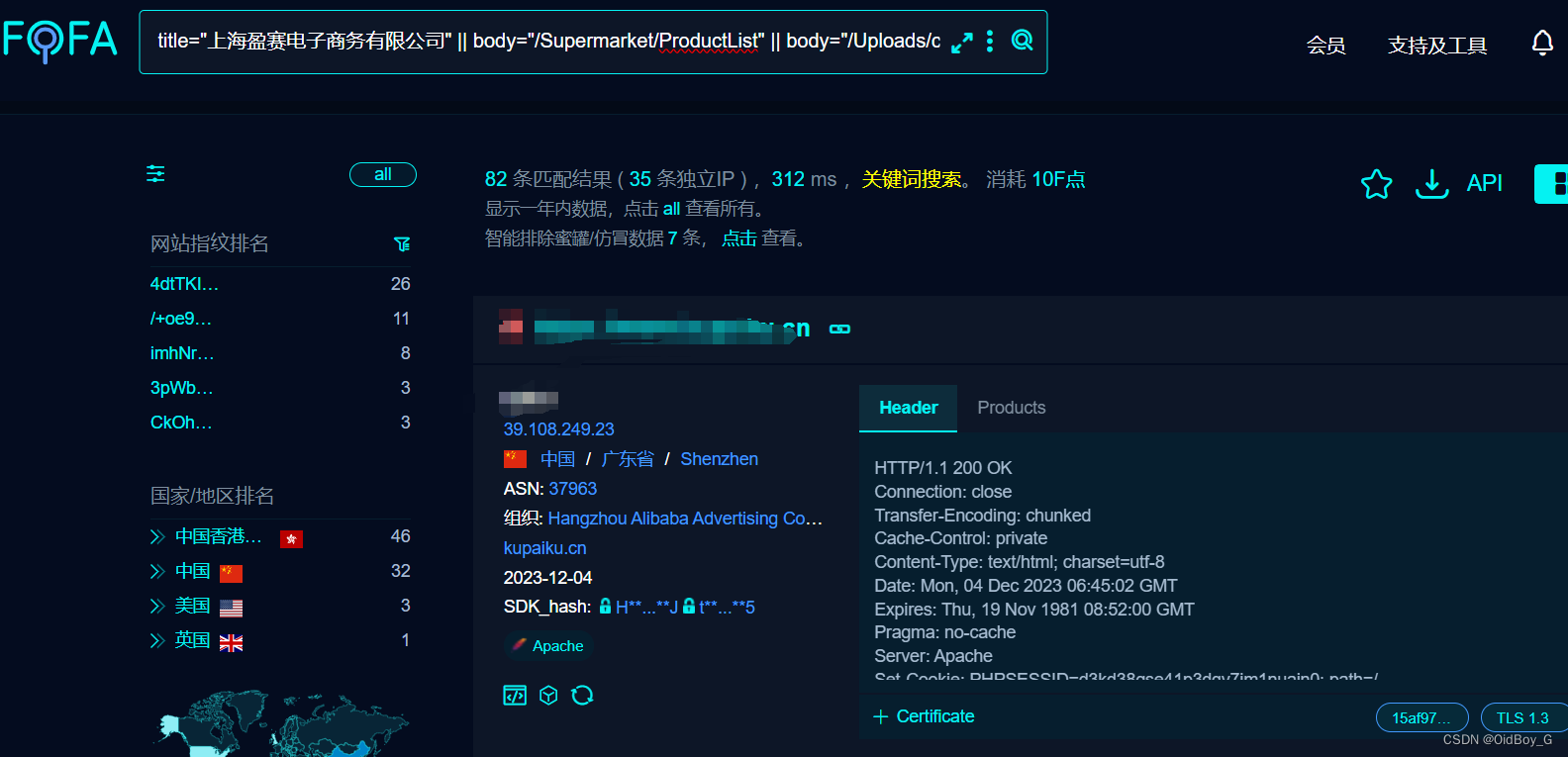
ShopsN commentUpload 文件上传漏洞复现
0x01 产品简介 ShopsN 是一款符合企业级商用标准全功能的真正允许免费商业用途的开源网店全网系统。 0x02 漏洞概述 ShopsN commentUpload 接口处存在任意文件上传漏洞,攻击者可以利用文件上传漏洞执行恶意代码、写入后门、读取敏感文件,从而可能导致服务器受到攻击并被控…...

【Qt5】ui文件最后会变成头文件
2023年12月14日,周四下午 我也是今天下午偶然间发现这个的 在使用Qt的uic(User Interface Compiler)工具编译ui文件时,会生成对应的头文件。 在Qt中,ui文件是用于描述用户界面的XML文件,而头文件是用于在…...
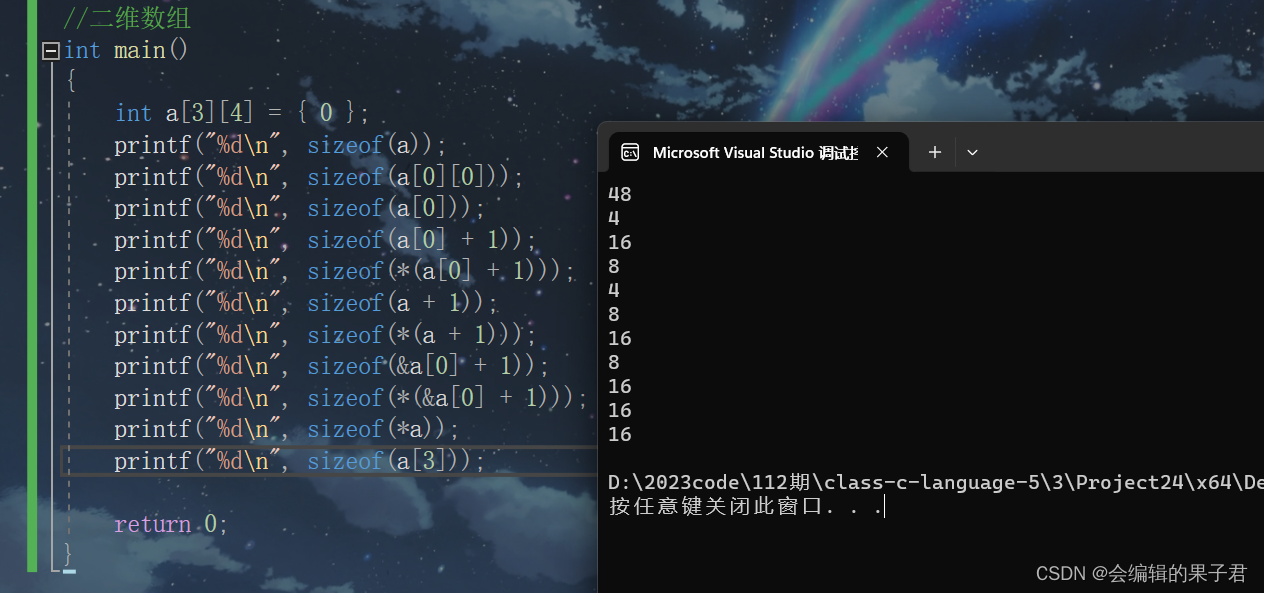
数组笔试题解析(下)
数组面试题解析 字符数组 (一) 我们上一篇文章学习了一维数组的面试题解析内容和字符数组的部分内容,我们这篇文章讲解一下字符数组和指针剩余面试题的解析内容,那现在,我们开始吧。 我们继续看一组字符数组的面试…...
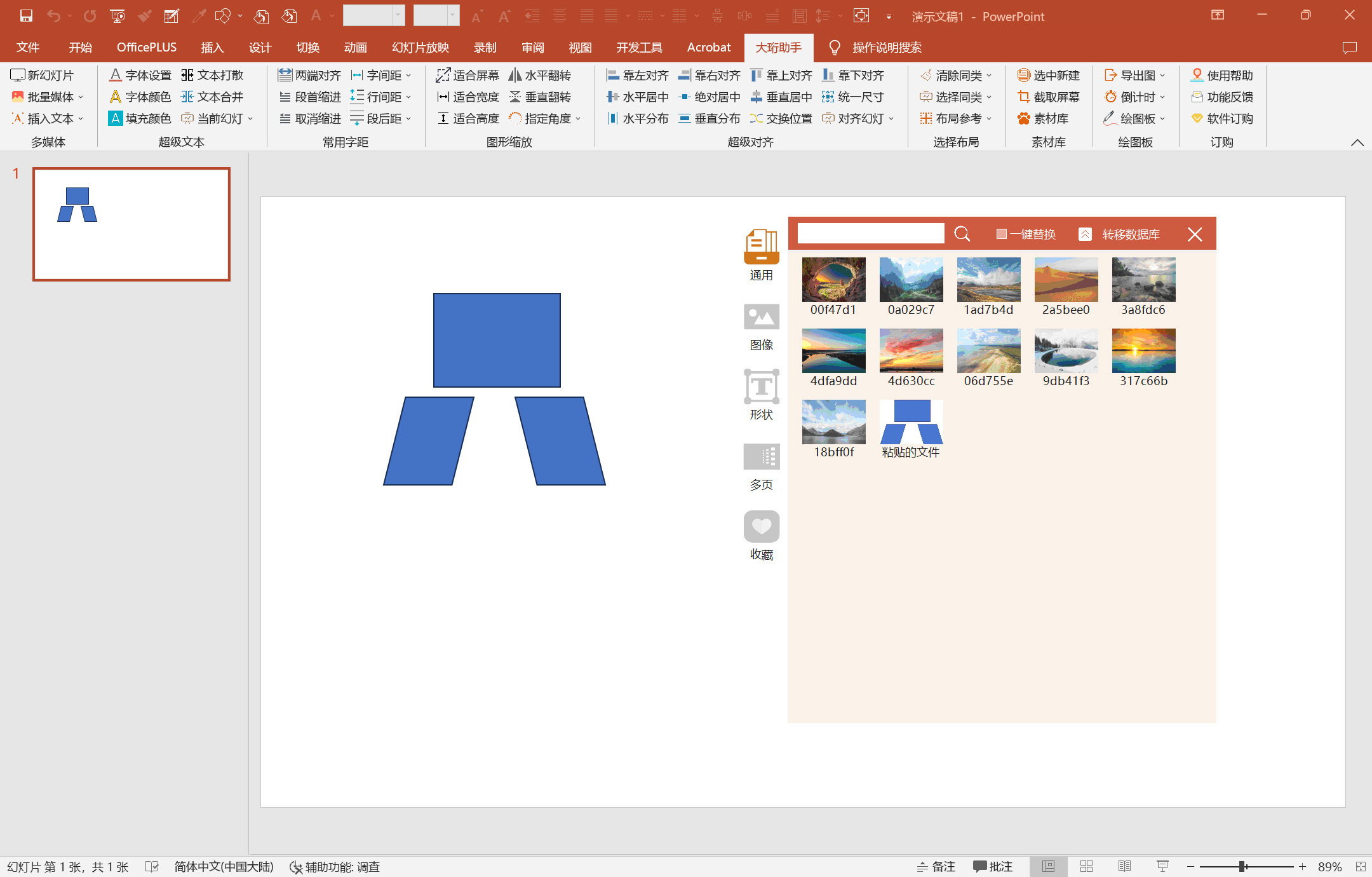
PPT插件-好用的插件-图形缩放-大珩助手
图形缩放 包括适合屏幕、适合宽度、适合高度、水平翻转、垂直翻转、指定角度,可同时对多个形状进行操作 适合屏幕 一键设置图像、文本、形状的长宽尺寸与当前幻灯片一致 适合宽度 一键设置图像、文本、形状的宽度尺寸与当前幻灯片一致 适合高度 一键设置图像…...

五:爬虫-数据解析之xpath解析
五:数据解析之xpath解析 1.xpath介绍: xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素路径来完成对元素的查找,HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式 XPa…...

什么是Laravel?它有哪些特性?
Laravel 是一款流行的 PHP Web 框架,设计用于构建现代、优雅且功能强大的 Web 应用程序。它提供了一套丰富的工具和库,以简化常见的开发任务,同时保持灵活性和可扩展性。以下是 Laravel 框架的一些主要特性: 优雅的语法࿱…...
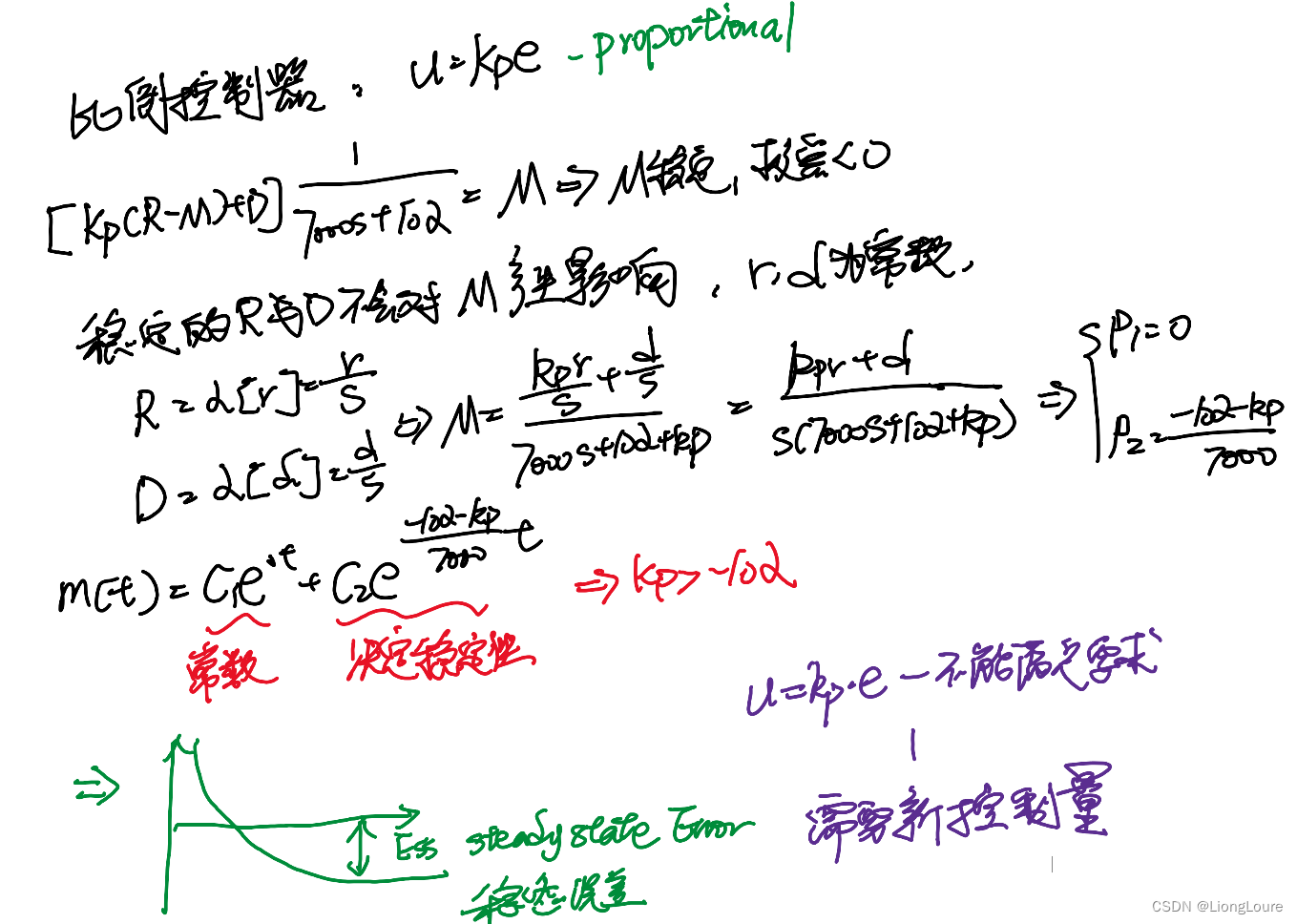
[足式机器人]Part2 Dr. CAN学习笔记-自动控制原理Ch1-3燃烧卡路里-系统分析实例
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-自动控制原理Ch1-3燃烧卡路里-系统分析实例 1. 数学模型2. 比例控制 Proprotional Control 1. 数学模型 2. 比例控制 Proprotional Control...
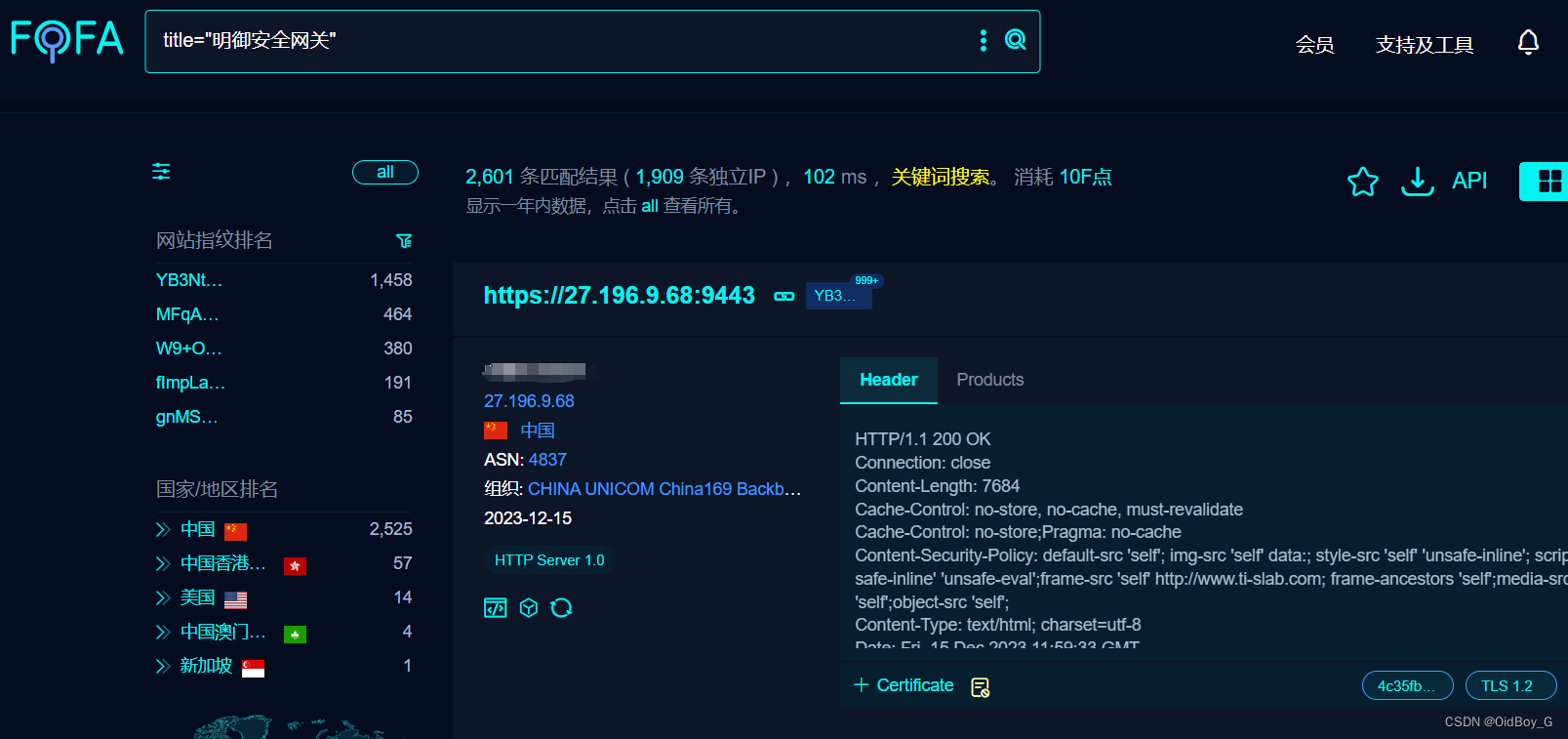
安恒明御安全网关 aaa_local_web_preview文件上传漏洞复现
0x01 产品简介 明御安全网关秉持安全可视、简单有效的理念,以资产为视角,构建全流程防御的下一代安全防护体系,并融合传统防火墙、入侵检测、入侵防御系统、防病毒网关、上网行为管控、VPN网关、威胁情报等安全模块于一体的智慧化安全网关。 0x02 漏洞概述 明御安全网关在…...
基于ssm企业人事管理系统的设计与实现论文
摘 要 进入信息时代以来,很多数据都需要配套软件协助处理,这样可以解决传统方式带来的管理困扰。比如耗时长,成本高,维护数据困难,数据易丢失等缺点。本次使用数据库工具MySQL和编程技术SSM开发的企业人事管理系统&am…...

你知道为什么要加 final 关键字了吗?
嗨,大家好,欢迎来到程序猿漠然公众号,我是漠然。 在Java编程中,我们经常会遇到需要使用final关键字的情况。那么,为什么要使用final关键字呢?它到底有什么作用?本文将从以下几个方面来详细…...
找不到mfc100u.dll,程序无法继续执行?三步即可搞定
在使用电脑过程中,我们经常会遇到一些错误提示,其中之一就是“找不到mfc100u.dll”。mfc100u.dll是Microsoft Foundation Class(MFC)库中的一个版本特定的DLL文件。MFC是微软公司为简化Windows应用程序开发而提供的一套C类库。它包…...
postman接口测试之Postman配置环境变量和全局变量
前言 我们在测试的过程中,遇到最多的问题也可以是环境的问题了吧,今天开发用了这个测试环境,明天又换了另一个测试环境,这样对于我们测试非常的麻烦,特别最接口的时候需要来回的输入环境地址比较麻烦,今天…...

OpenSSL 编程示例
参考:深入探索 OpenSSL:概念、原理、开发步骤、使用方法、使用场景及代码示例 地址:https://oneisall.blog.csdn.net/article/details/131489812?spm1001.2014.3001.5502 目录 1. OpenSSL 概念2. OpenSSL 原理3. OpenSSL 开发步骤4. OpenSSL…...
-k8s核心对象CronJob)
K8S学习指南(17)-k8s核心对象CronJob
文章目录 前言什么是CronJob?示例演示步骤1:创建CronJob步骤2:定义任务模板步骤3:部署CronJob步骤4:监视CronJob的执行 总结 前言 Kubernetes(简称K8s)是一种用于自动部署、扩展和管理容器化应…...
任务调度的介绍)
单片机Freertos入门(二)任务调度的介绍
简介: FreeRTOS支持的任务调度方法有抢占式、协作式、时间片轮转,下面分别来讲解。 1.抢占式调度 抢占式调度,是最高优先级的任务一旦就绪,总能得到CPU的执行权。 高优先级运行时候,低优先级不运行,等待…...
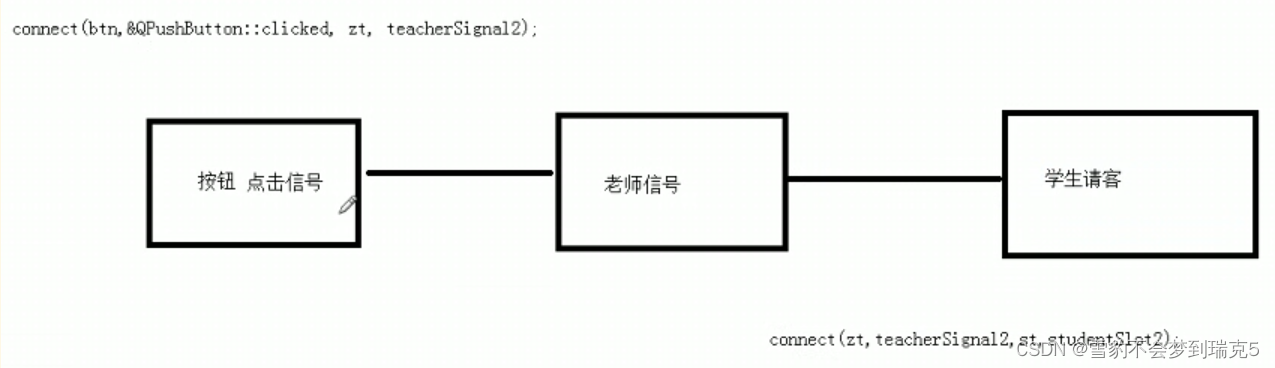
QT----自定义信号和槽
第二天 2.1自定义信号和槽 新建一个Qtclass 自定义信号:返回值是void ,只需要声明,不需要实现,可以有参数,可以重载 自定义槽:返回值void ,需要声明,也需要实现,可以有…...
)
从DC到DCG:手把手教你搭建物理感知综合流程(含DEF文件处理避坑指南)
从DC到DCG:物理感知综合全流程实战指南 在28nm以下工艺节点,传统逻辑综合工具已难以应对复杂的物理效应。我们团队在最近一次5nm芯片项目中,由于初期忽视物理感知综合的约束设置,导致时序收敛多耗费三周时间。本文将分享从Design …...
)
告别混乱的SVN日志!保姆级教程:用TortoiseSVN图形界面导出清晰可读的变更记录(含过滤与导出选项详解)
高效管理SVN变更记录:TortoiseSVN图形界面全攻略 在团队协作开发中,版本控制系统扮演着至关重要的角色。SVN(Subversion)作为集中式版本控制的代表,其提交日志记录了项目的完整演进历程。然而,面对杂乱无章…...

机器人抓取仿真与数据分析:从PyBullet集成到抓取性能评估
1. 项目概述与核心价值最近在机器人控制与仿真领域,一个名为PyroMind-Dynamics/openclaw-tracer的项目引起了我的注意。乍一看这个标题,它像是一个典型的GitHub仓库名,由组织名“PyroMind-Dynamics”和项目名“openclaw-tracer”组成。作为一…...

3步掌握VADER情感分析:颠覆传统NLP方法的实战指南
3步掌握VADER情感分析:颠覆传统NLP方法的实战指南 【免费下载链接】vaderSentiment VADER Sentiment Analysis. VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to s…...

3大核心功能揭秘:如何用SMUDebugTool深度掌控AMD Ryzen处理器性能
3大核心功能揭秘:如何用SMUDebugTool深度掌控AMD Ryzen处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

从零上手Ranorex:录制、验证与参数化测试实战解析
1. Ranorex自动化测试入门指南 第一次接触Ranorex时,我和大多数测试工程师一样,被它强大的功能所震撼。作为一款专业的自动化测试工具,Ranorex能够显著提升测试效率,特别适合需要频繁回归测试的项目场景。记得我第一次用它完成计算…...

AI工作流引擎设计:从Prompt工程到可编程组件的系统化实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫jmagly/aiwg。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它其实是一个关于“AI写作指南”或“AI工作流生成器”的雏形。这类项目在当前AI应用爆发…...

AssetRipper完整指南:从游戏资源提取到Unity项目重建的终极工具
AssetRipper完整指南:从游戏资源提取到Unity项目重建的终极工具 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipp…...

告别手动刷新!为你的Qt串口调试助手添加‘设备热插拔’自动感知功能
告别手动刷新!为你的Qt串口调试助手添加‘设备热插拔’自动感知功能 在嵌入式开发和硬件调试过程中,串口工具是不可或缺的得力助手。然而,大多数基础串口调试软件都存在一个令人困扰的痛点——当设备突然断开或新设备接入时,用户不…...
CircuitPython硬件交互实战:从数字I/O到NeoPixel灯带控制
1. 项目概述如果你刚开始接触嵌入式硬件开发,面对一堆引脚、传感器和电机,可能会觉得有点无从下手。我刚开始玩Arduino和树莓派Pico的时候,也是这种感觉,总觉得底层寄存器、数据手册太复杂。直到后来用上了CircuitPythonÿ…...