Flink+Kafka消费
引入jar
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.8.0</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.8.0</version>
</dependency>
<!-- flink整合kafka_2.11 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.10.0</version>
</dependency>二、处理逻辑
//2、定义环境 => Env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(9);
env.enableCheckpointing(1000);FlinkKafkaConsumer<String> consumer = this.getConsumer();//调用下面的方法获取数据源
consumer.setStartFromLatest();//消费最新数据//2、绑定数据源=> resource
DataStream<String> stream = env.addSource(consumer);//3、批量读取的方法=>
stream.timeWindowAll(Time.milliseconds(500)) //timeWindowAll:时间滚动窗口,滑动窗口会有数据元素重叠可能,而滚动窗口不存在元素重叠.apply(new ReadKafkaFlinkWindowFunction())//使用自己定义的apply来收集.addSink(new KafkaBatchSink());//批量的sink方法
env.execute();
2、定义消费者,并且将消费者consumer转成FlinkKafkaConsumer
public FlinkKafkaConsumer<String> getConsumer(){//定义消费者信息Properties properties = new Properties();properties.put("bootstrap.servers", "192.168.131.147:9092");properties.put("group.id", "flink-consumer-kafka-group");properties.put("auto.offset.reset", "latest");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("demo", new SimpleStringSchema(), properties);return consumer;
}
3、收集数据ReadKafkaFlinkWindowFunction的实现类
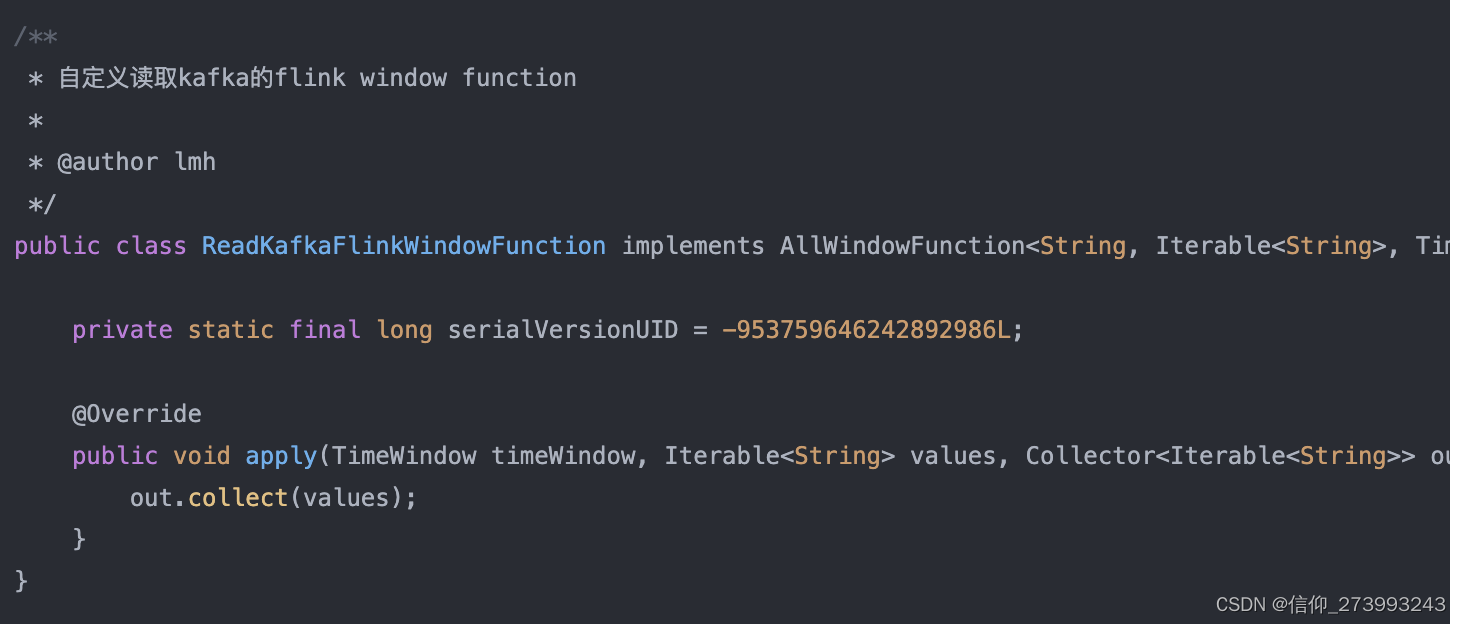
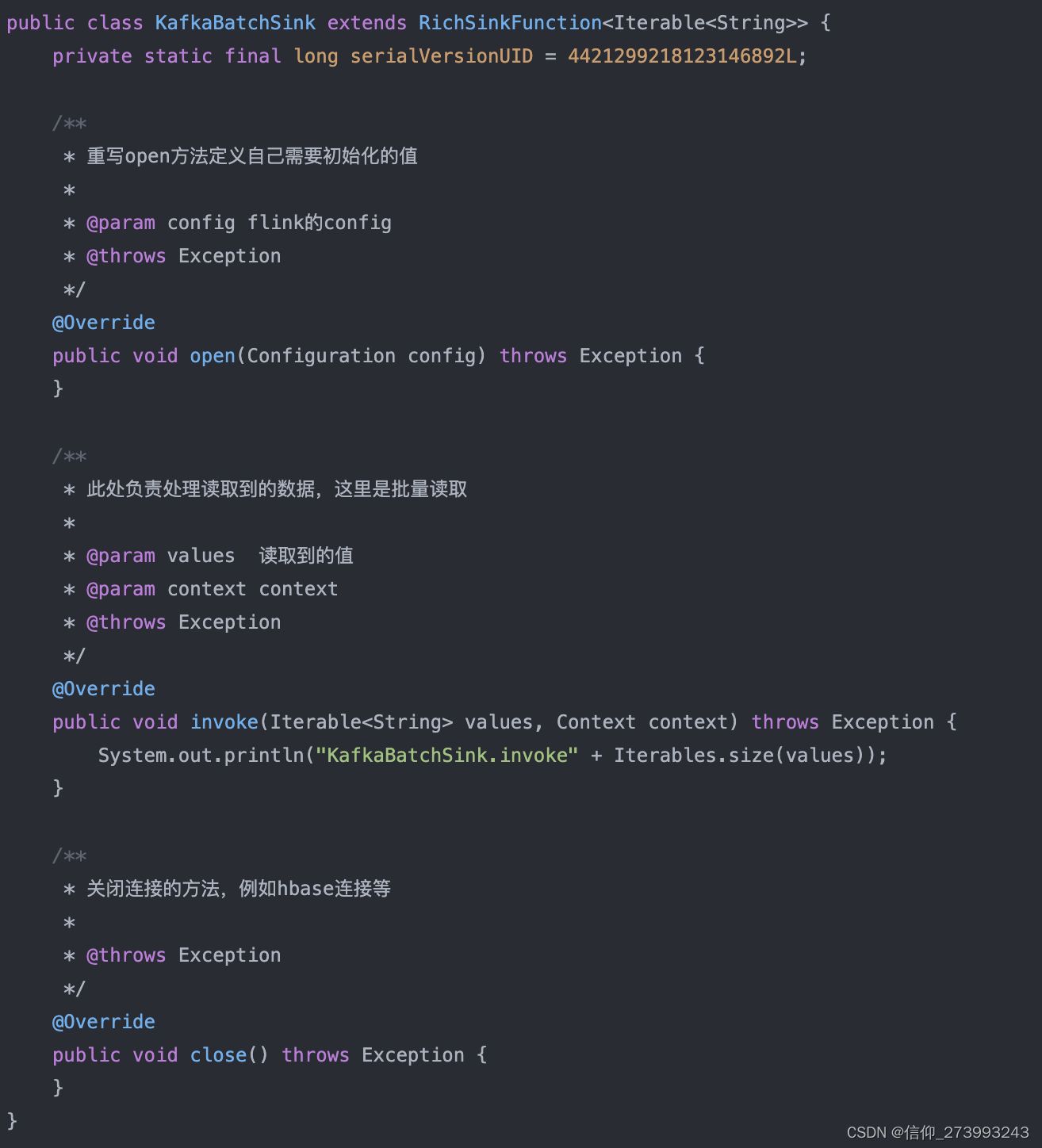
总结
分布式处理引擎Flink使用至少一个【job】调度和至少一个【task】实现分布式处理
有界:就是指flink【消费指定范围内】的数据。例如我定义某个作业间隔时间为0.5秒,则flink已0.5秒为界,进行数据处理。有界数据用在离线数据的处理场景较多
无界:就是指flink始终【监听数据源】里的数据,获取到就处理。无界数据往往用在【实时数据】处理下的场景较多。
我这里结合我们项目的场景来给各位说一下该选那种处理。我们的场景为:
1:尽量支持最多的数据落地
2:数据必须要准确。所以我们最终了有界处理,将flink的界限设置为0.5秒,0.5秒内收集的所有数据整体使用一个算
子消费。保证数据的准确和消费高效性。
1、一定要有抛出异常的机制
我们都知道抛出异常会终止消费,但是为什么要抛出异常呢?这注意是因为如果用户不抛出异常的话,flink会认为当前的数据时正常消费的,这就造成了我们的kafka数据误消费
2、关于并行度parallelism
并行度的配置都是setParallelism,对于env和stream来说,stream的优先级比env高
3、关于checkpoint
我们如果定义程序运行在SPring Boot时,一定要配置检查点这个是flink实现容错的核心配置!
4、关于并行度
我们在设置并行度的时候,将里边的数字设置为多少,最终就会有多少个线程来执行任务。
所以大家一定要清楚对于数据准确性高的数据来说,宁愿牺牲多线程带来的效率提升也要只设置一个线程来执行消费。
可能大家没有注意,如果你不设置flink的并行度为1时。它是以的是系统的线程数来作为并行度!这样顺序是会乱的。
5、saveBatch很好
但是我建议你先封装一下或者改为批量的保存。可能大家都知道或者说都用过mybatis plus的saveBatch,它能将一个列表的inseert封装为一条sql(insert into a values(a1),(a2),(a3)),但是我们一条sql的长度过长的话会存在性能问题。建议在批量处理的时候每隔1000条记录saveBatch一次
为什么flink消费kafka比官方的listener都要快
1、并行度和分区处理: Flink 具有高度的并行度支持
可以为每个 Kafka 分区创建独立的消费者实例,以便并行地处理多个分区。这使得 Flink能够更有效地利用资源,并提高整体的消费速度。相比之下,一些官方 Kafka Consumer 实现可能没有明确的并行度配置或并行处理策略。
2、事件时间处理
Flink 强调【事件时间】处理,支持按照事件的实际发生时间进行【有序处理】。这对于一些需要处理时间相关业务逻辑的应用来说很重要。Flink 可以轻松处理乱序事件,并确保事件按照正确的顺序进行处理。官方 Kafka Consumer 也提供了类似的功能,但 Flink在这方面的设计更加深入和专注。
状态管理
Flink 提供了强大的状态管理机制,对于需要在处理过程中保持状态的任务,这一点非常重要。在消费 Kafka消息时,可能需要追踪某些状态,例如记录已处理的偏移量。Flink 的状态管理可以更好地支持这种场景,而官方 Kafka Consumer可能没有提供类似的状态管理机制。
异步处理模型:
Flink 使用异步处理模型,这使得在处理一条消息时,可以同时进行其他处理而无需等待。这有助于提高整体的处理效率。
相关文章:
Flink+Kafka消费
引入jar <dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.8.0</version> </dependency> <dependency><groupId>org.apache.flink</groupId><artifactI…...

Seconds_Behind_Master越来越大,主从同步延迟
问题现象 发现从库mysql_slave的参数Seconds_Behind_Master越来越大。已排除主从服务器时间不一致;那么主要就判断两点:是io thread慢还是 sql thread慢?先观察show slave status\G 。 判断3个参数(参数后面的值是默认空闲时候的…...

除法求值[中等]
一、题目 给你一个变量对数组equations和一个实数值数组values作为已知条件,其中equations[i] [Ai, Bi]和values[i]共同表示等式Ai / Bi values[i]。每个Ai或Bi是一个表示单个变量的字符串。另有一些以数组queries表示的问题,其中queries[j] [Cj, Dj…...

新时代商业市场:AR技术的挑战与机遇并存
随着科技的不断发展,增强现实(AR)技术逐渐成为当今社会的一个重要组成部分。AR技术能够将虚拟世界与现实世界相结合,为人们提供更加丰富、多样化的体验。在新时代的社会商业市场中,AR技术也正逐渐被应用于各种商业活动…...

RHEL8中ansible的使用
编写ansible.cfg和清单文件ansible的基本用法 本章实验三台RHEL8系统(rhel801,rhel802,rhel803),其中rhel801是ansible主机 这里要确保ansible主机能够解析所有被管理的机器,这里通过配置/etc/hosts来实现…...

【1.6计算机组成与体系结构】存储系统
目录 1.层次化存储结构2.Cache2.1 Cache的介绍2.2 局部性原理2.3 Cache应用 1.层次化存储结构 由 ⬆ CPU:寄存器。 快 ⬆ Cache:按内容存取(相联存储器)。 到 ⬆内存(主存):DRAM。 慢 ⬆ 外存(辅存&#…...
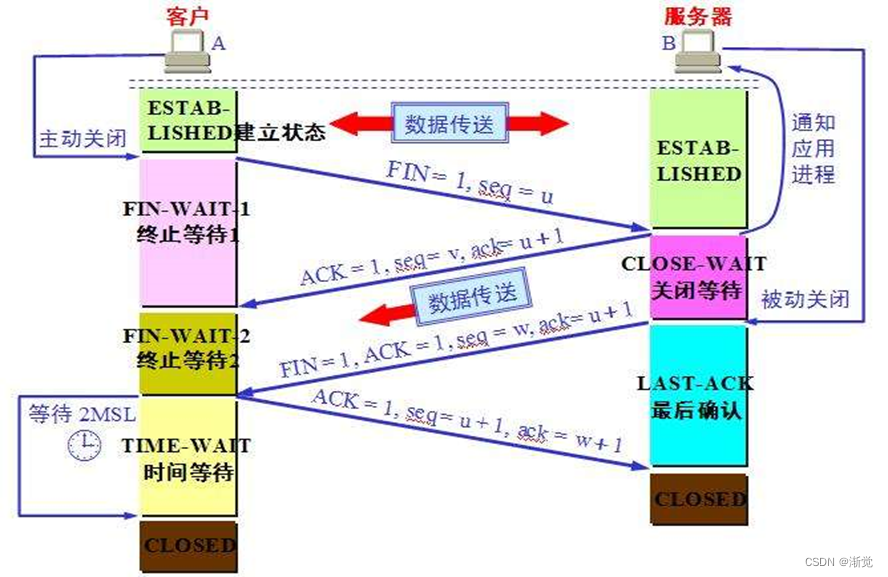
TCP/UDP 协议
目录 一.TCP协议 1.介绍 2.报文格式 编辑 确认号 控制位 窗口大小 3.TCP特性 二.TCP协议的三次握手 1.tcp 三次握手的过程 三.四次挥手 2.有限状态机 四.tcp协议和udp协议的区别 五.udp协议 UDP特性 六.telnet协议 一.TCP协议 1.介绍 TCP(Transm…...

如何正确理解和使用 Golang 中 nil ?
目录 指针中的 nil 切片中的 nil map 中的 nil 通道中的 nil 函数中的 nil 接口中的 nil 避免 nil 相关问题的最佳实践 小结 在 Golang 中,nil 是一个预定义的标识符,在不同的上下文环境中有不同的含义,但通常表示“无”、“空”或“…...
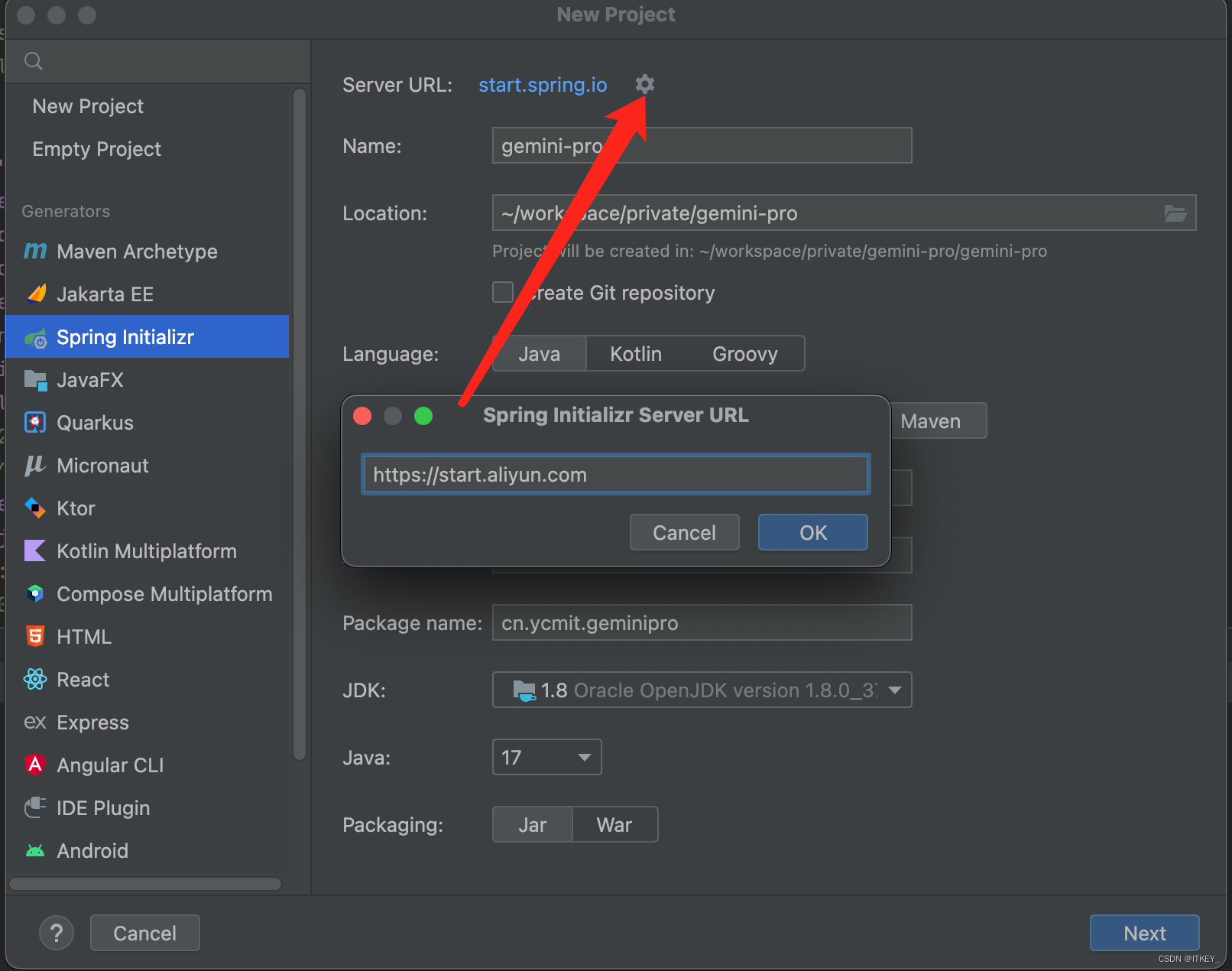
IDEA新建jdk8 spring boot项目
今天新建spring boot项目发现JDK版本最低可选17。 但是目前用的最多的还是JDK8啊。 解决办法 Server URL中设置: https://start.aliyun.com/设置完成后,又可以愉快的用jdk8创建项目了。 参考 https://blog.csdn.net/imbzz/article/details/13469117…...

Qt/C++音视频开发59-使用mdk-sdk组件/原qtav作者力作/性能凶残/超级跨平台
一、前言 最近一个月一直在研究mdk-sdk音视频组件,这个组件是原qtav作者的最新力作,提供了各种各样的示例demo,不仅限于支持C,其他各种比如java/flutter/web/android等全部支持,性能上也是杠杠的,目前大概…...

智安网络|企业网络安全工具对比:云桌面与堡垒机,哪个更适合您的需求
随着云计算技术的快速发展,越来越多的企业开始采用云计算解决方案来提高效率和灵活性。在云计算环境下,云桌面和堡垒机被广泛应用于企业网络安全和办公环境中。尽管它们都有助于提升企业的安全和效率,但云桌面和堡垒机在功能和应用方面存在着…...
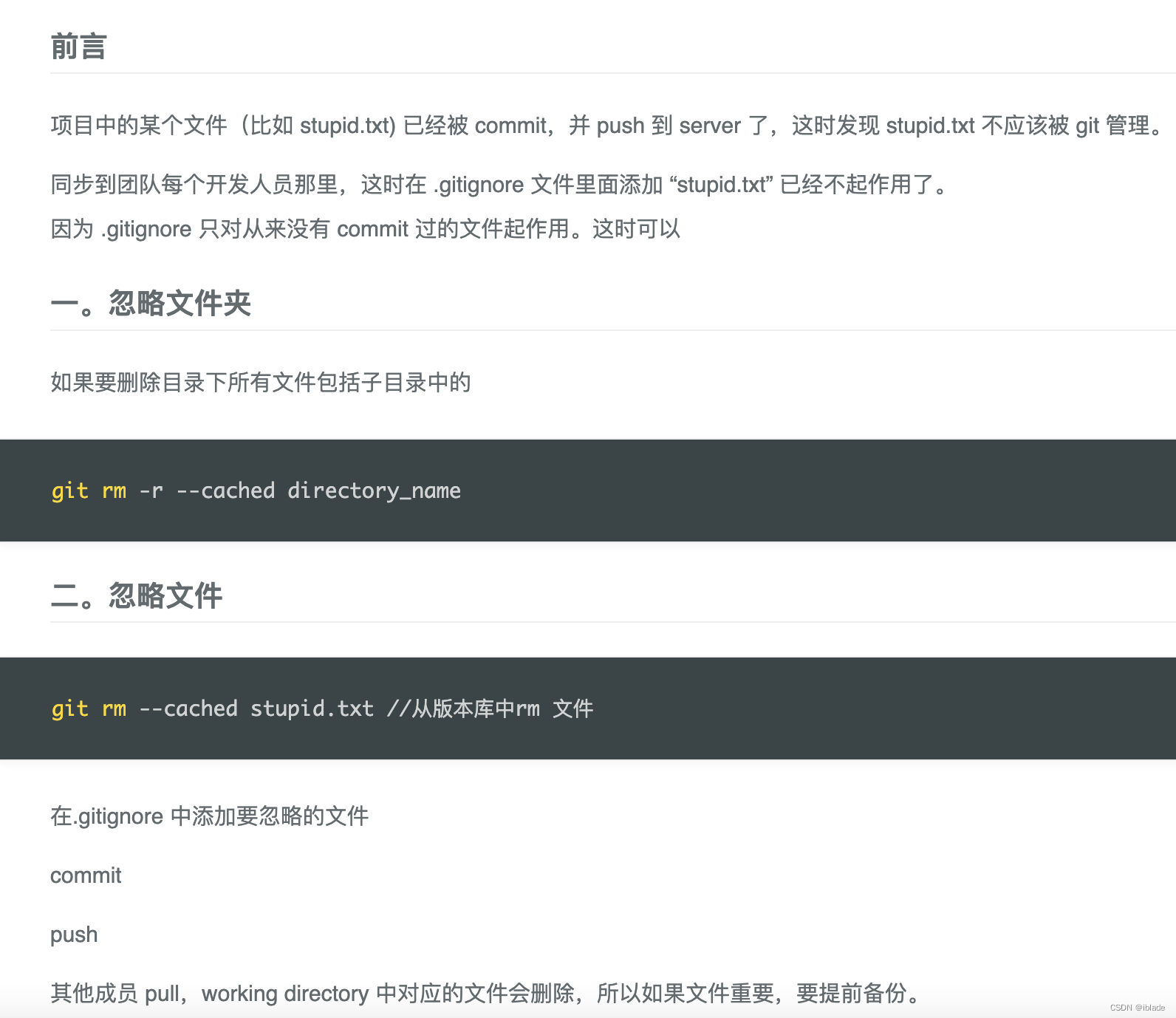
Git忽略已经提交的文件
原理类似于 Android修改submodule的lib包名...

MVVM和MVC以及MVP的原理以及它们的区别
MVVM、MVC 和 MVP 都是前端架构模式,它们各自有不同的原理和特点。 MVC(Model-View-Controller) 原理:MVC 将应用程序分为三个部分:模型(Model)、视图(View)和控制器&a…...
WeChatMsg: 导出微信聊天记录 | 开源日报 No.108
Mozilla-Ocho/llamafile Stars: 3.5k License: NOASSERTION llamafile 是一个开源项目,旨在通过将 lama.cpp 与 Cosmopolitan Libc 结合成一个框架,将 LLM (Large Language Models) 的复杂性折叠到单个文件可执行程序中,并使其能够在大多数…...
)
Python学习之复习MySQL-Day3(DQL)
目录 文章声明⭐⭐⭐让我们开始今天的学习吧!DQL简介基本查询查询多个/全部字段设置别名去除重复记录 条件查询条件查询介绍实例演示 聚合函数什么是聚合函数?常见的聚合函数实例演示 分组查询分组查询语法where 和 having 的区别实例演示 排序查询语法实…...

AI超级个体:ChatGPT与AIGC实战指南
目录 前言 一、ChatGPT在日常工作中的应用场景 1. 客户服务与支持 2. 内部沟通与协作 3. 创新与问题解决 二、巧用ChatGPT提升工作效率 1. 自动化工作流程 2. 信息整合与共享 3. 提高决策效率 三、巧用ChatGPT创造价值 1. 优化产品和服务 2. 提高员工满意度和留任率…...
|(使用OkHttpClient实现websocket以及详细介绍))
SpringBoot集成websocket(5)|(使用OkHttpClient实现websocket以及详细介绍)
SpringBoot集成websocket(5)|(使用OkHttpClient实现websocket以及详细介绍) 文章目录 SpringBoot集成websocket(5)|(使用OkHttpClient实现websocket以及详细介绍)[TOC] 前言一、初始…...
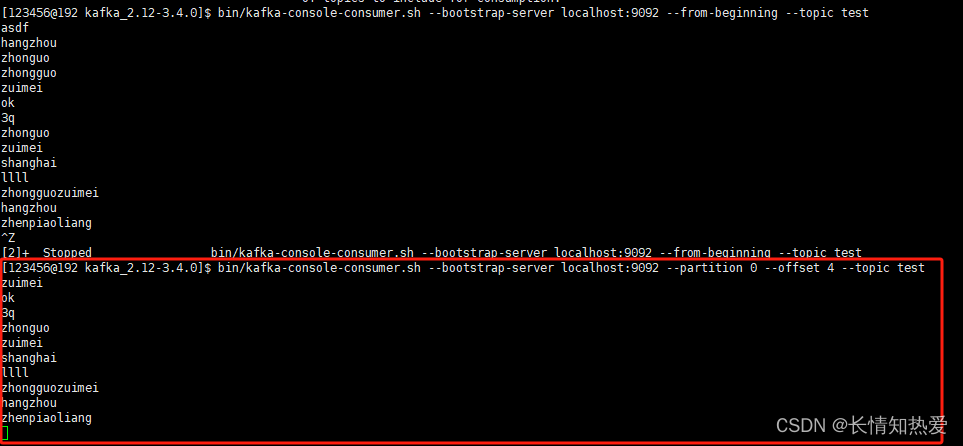
Kafka-Kafka基本原理与集群快速搭建(实践)
Kafka单机搭建 下载Kafka Apache Download Mirrors 解压 tar -zxvf kafka_2.12-3.4.0.tgz -C /usr/local/src/software/kafkakafka内部bin目录下有个内置的zookeeper(用于单机) 启动zookeeper(在后台启动) nohup bin/zookeeper-server-start.sh conf…...
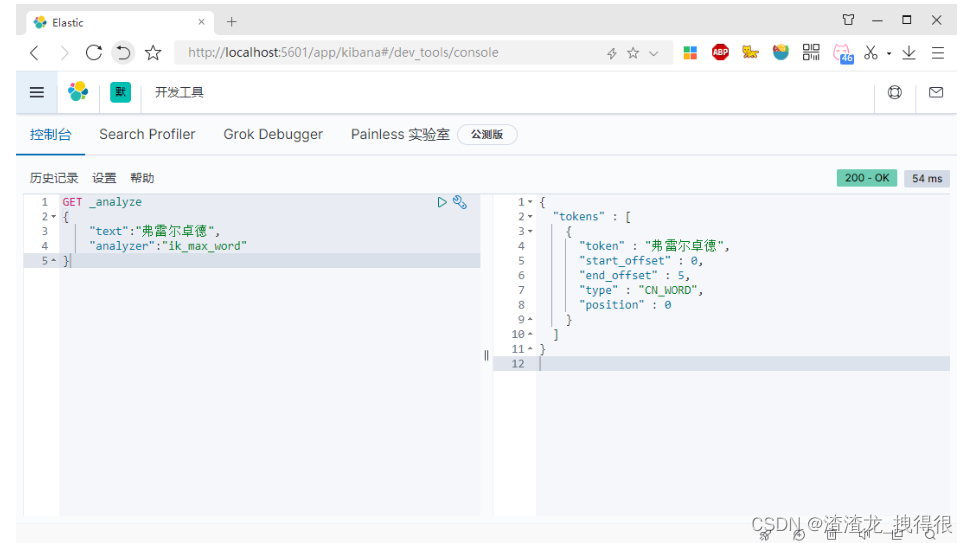
Elasticsearch 进阶(索引、类型、字段、分片、副本、集群等详细说明)-06
笔记来源:Elasticsearch Elasticsearch进阶 进阶-核心概念 索引Index 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字…...
hive的分区表和分桶表详解
分区表 Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。 静态分区表基本语法 创建分区表 create table dept_p…...

【2024最新版】ElevenLabs有声书生产流水线:1个API Key+3个Python脚本+2个FFmpeg指令=日更10小时高质量音频
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs有声书生产流水线全景概览 ElevenLabs 的有声书生产流水线是一套融合文本预处理、语音合成、音频后处理与元数据封装的端到端自动化系统,专为高质量、多语种、情感一致的有声内容…...

企业级应用awesome-stock-resources:商业项目合规使用终极指南
企业级应用awesome-stock-resources:商业项目合规使用终极指南 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awe…...

如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南
如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南 【免费下载链接】ChatGLM3 ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGLM3 ChatGLM3作为开源双语对话语言…...

使用Nodejs和Taotoken构建一个多轮对话代理服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken构建一个多轮对话代理服务 为全栈或后端开发者设计一个场景,利用Node.js环境下的openai包&#…...

低代码平台表单设计器 unione form editor 组件介绍--文件上传
低代码平台表单设计器 unione form editor 组件介绍--文件上传 在企业级低代码表单开发中,文件上传组件是实现“附件提交、资料归档、证据留存”的核心组件,广泛应用于合同上传、简历提交、凭证上传、图片上传等场景。不同于其他输入类组件,文…...

基于插件化架构的OBS实时音乐信息集成系统技术解析
基于插件化架构的OBS实时音乐信息集成系统技术解析 【免费下载链接】tuna Song information plugin for obs-studio 项目地址: https://gitcode.com/gh_mirrors/tuna1/tuna Tuna是一款面向OBS Studio的高性能插件化实时音乐信息集成系统,采用模块化架构设计&…...

RPG Maker Decrypter终极指南:轻松解密游戏资源文件
RPG Maker Decrypter终极指南:轻松解密游戏资源文件 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/RPG…...

ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 [特殊字符]
ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 🚀 【免费下载链接】ServerPackCreator Create a server pack from a Minecraft Forge, NeoForge, Fabric, LegacyFabric or Quilt modpack! 项目地址: https://gitcode.com/gh_mirrors/s…...

从ST-Ericsson案例剖析半导体合资企业的战略困境与生存法则
1. 从一篇旧文看半导体合资企业的生存逻辑最近在整理行业历史资料时,翻到了一篇2011年发布于EE Times的文章,标题是《ST-Ericsson还能撑多久?》。这篇文章像一枚时间胶囊,精准地记录了一家曾经备受瞩目的无线芯片合资公司在特定时…...

TrollInstallerX终极指南:深入解析iOS 14.0-16.6.1越狱工具部署技术
TrollInstallerX终极指南:深入解析iOS 14.0-16.6.1越狱工具部署技术 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14.0到16…...