hive的分区表和分桶表详解
分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
静态分区表基本语法
创建分区表
create table dept_partition
(deptno int, --部门编号dname string, --部门名称loc string --部门位置
)partitioned by (day string)row format delimited fields terminated by '\t';
写数据:
创建文件写入以下数据并上传到HDFS上面:
10 行政部 1700
20 财务部 1800
load加载数据:
load data inpath 'hdfs://flinkv1:8020/input/dept_20220401.log'into table dept_partitionpartition(day='20220401');
insert加载数据
将day='20220401’分区的数据插入到day='20220402’分区,可执行如下装载语句
insert overwrite table dept_partition partition (day = '20220402')
select deptno, dname, loc
from dept_partition
where day = '20220401';
读数据
查询分区表数据时,可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段。
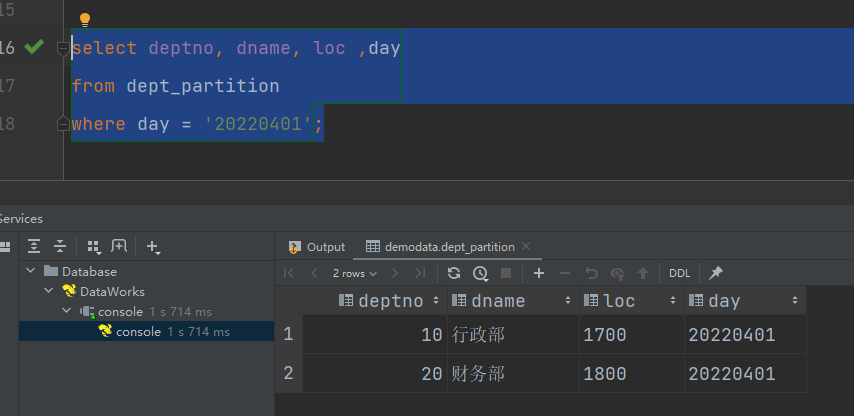
select deptno, dname, loc ,day
from dept_partition
where day = '20220401';
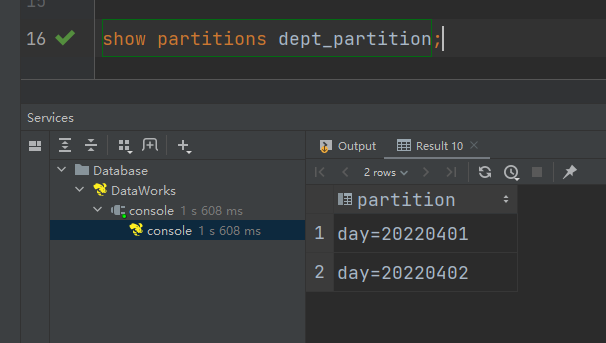
查看所有分区信息
show partitions dept_partition;
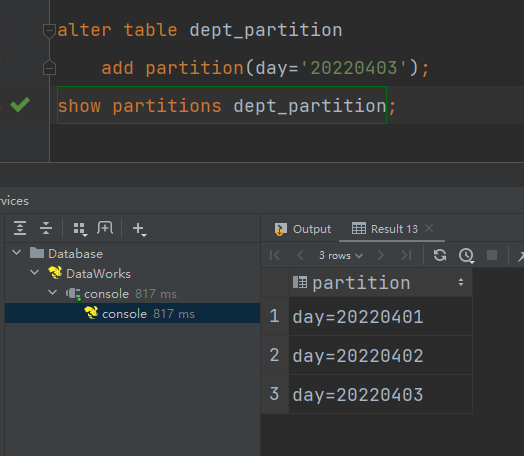
增加分区
(1)创建单个分区
alter table dept_partition
add partition(day='20220403');
(2)同时创建多个分区(分区之间不能有逗号)
alter table dept_partition
add partition(day='20220404') partition(day='20220405');
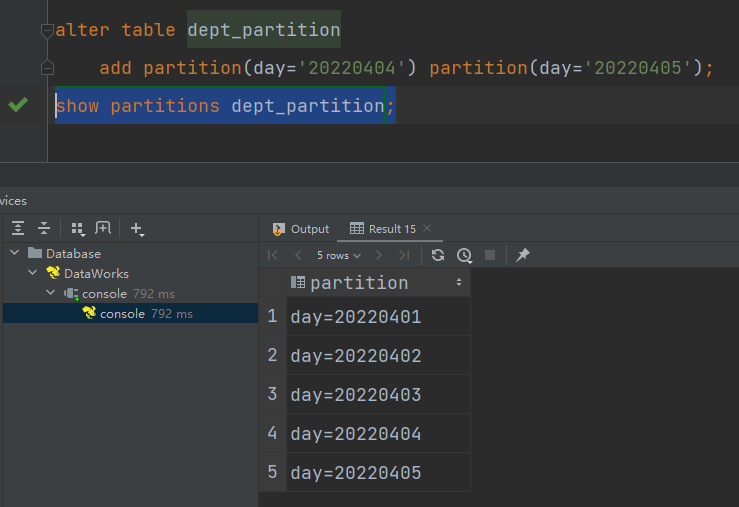
删除分区
(1)删除单个分区
alter table dept_partition
drop partition (day='20220403');
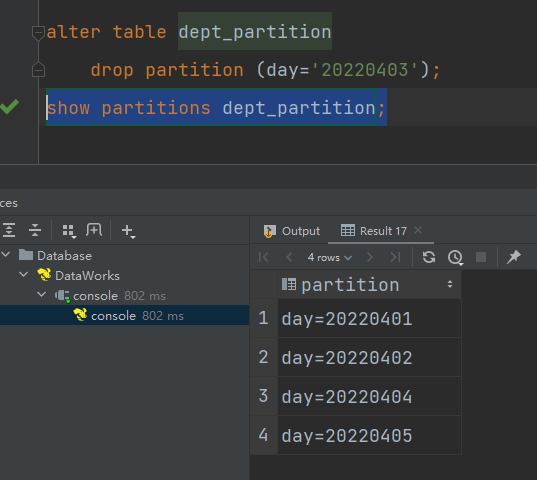
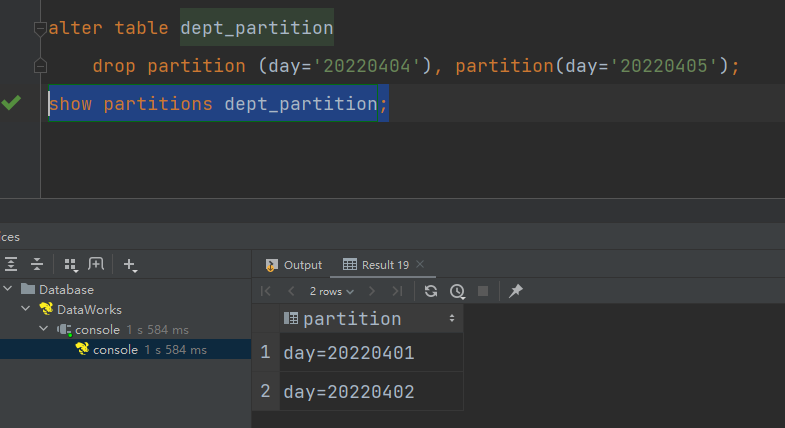
(2)同时删除多个分区(分区之间必须有逗号)
alter table dept_partition
drop partition (day='20220404'), partition(day='20220405');
修复分区
Hive将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。若用户手动创建/删除分区路径,Hive都是感知不到的,这样就会导致Hive的元数据和HDFS的分区路径不一致。再比如,若分区表为外部表,用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,同样会导致Hive的元数据和HDFS的分区路径不一致。
若出现元数据和HDFS路径不一致的情况,可通过如下几种手段进行修复。
(1)add partition
若手动创建HDFS的分区路径,Hive无法识别,可通过add partition命令增加分区元数据信息,从而使元数据和分区路径保持一致。
(2)drop partition
若手动删除HDFS的分区路径,Hive无法识别,可通过drop partition命令删除分区元数据信息,从而使元数据和分区路径保持一致。
(3)msck
若分区元数据和HDFS的分区路径不一致,还可使用msck命令进行修复,以下是该命令的用法说明。
msck repair table table_name [add/drop/sync partitions];
说明::该命令会增加HDFS路径存在但元数据缺失的分区信息。
msck repair table table_name add partitions
该命令会删除HDFS路径已经删除但元数据仍然存在的分区信息。
msck repair table table_name drop partitions
该命令会同步HDFS路径和元数据分区信息,相当于同时执行上述的两个命令。
msck repair table table_name sync partitions
等价于msck repair table table_name add partitions命令。
msck repair table table_name
二级分区表
思考:如果一天内的日志数据量也很大,如何再将数据拆分?答案是二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时进行分区。
二级分区表建表语句
create table dept_partition2(deptno int, -- 部门编号dname string, -- 部门名称loc string -- 部门位置
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
数据装载语句
load data inpath 'hdfs://flinkv1:8020/input/dept_20220401.log'into table dept_partition2partition(day='20220401', hour='12');
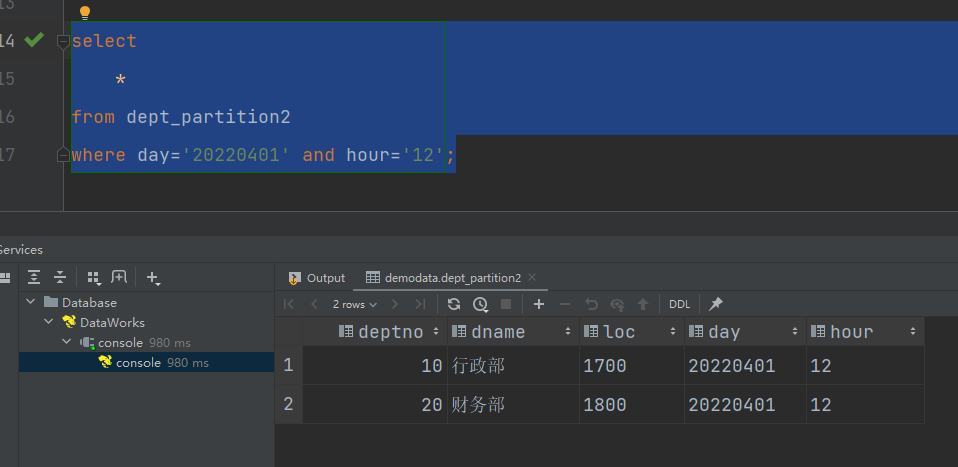
查询分区数据
select *
from dept_partition2
where day='20220401' and hour='12';
动态分区
动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。使用动态分区,可只用一个insert语句将数据写入多个分区。
动态分区相关参数
(1)动态分区功能总开关(默认true,开启)
set hive.exec.dynamic.partition=true
(2)严格模式和非严格模式
动态分区的模式,默认strict(严格模式),要求必须指定至少一个分区为静态分区,nonstrict(非严格模式)允许所有的分区字段都使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict
(3)一条insert语句可同时创建的最大的分区个数,默认为1000。
set hive.exec.max.dynamic.partitions=1000
(4)单个Mapper或者Reducer可同时创建的最大的分区个数,默认为100。
set hive.exec.max.dynamic.partitions.pernode=100
(5)一条insert语句可以创建的最大的文件个数,默认100000。
hive.exec.max.created.files=100000
(6)当查询结果为空时且进行动态分区时,是否抛出异常,默认false。
hive.error.on.empty.partition=false
案例实操
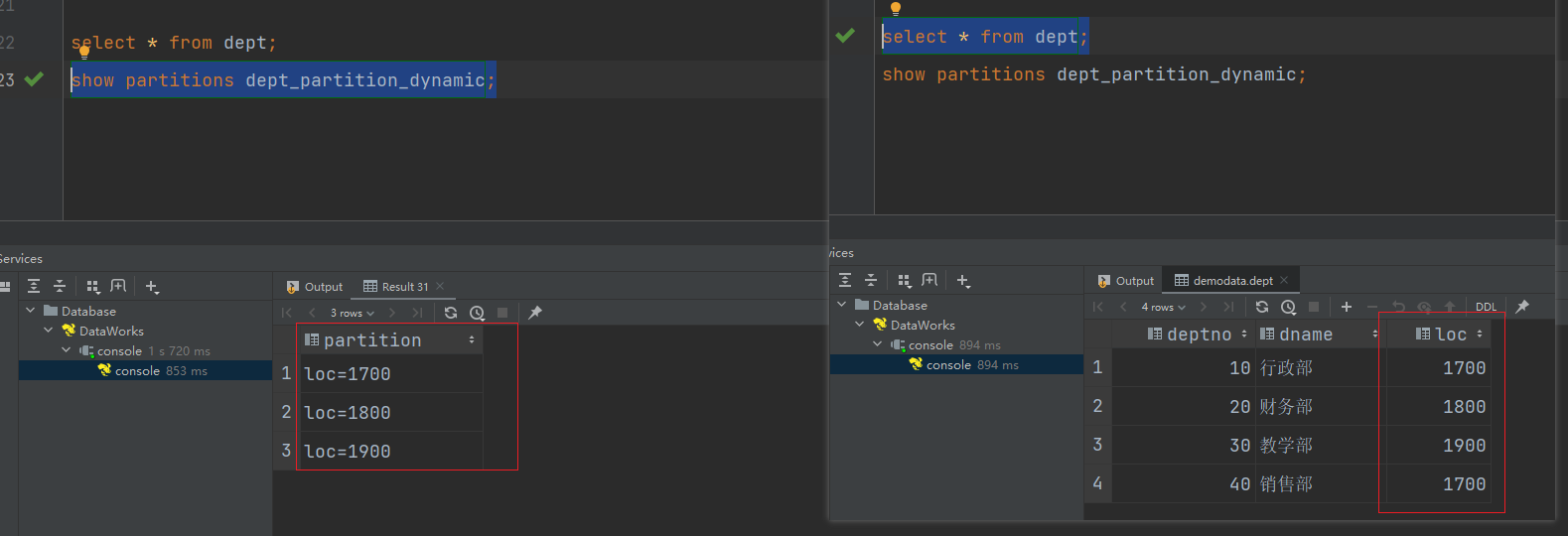
需求:将dept表中的数据按照地区(loc字段),插入到目标表dept_partition_dynamic的相应分区中。
(1)创建目标分区表
create table dept_partition_dynamic(id int, name string
)
partitioned by (loc int)
row format delimited fields terminated by '\t';
(2)设置动态分区
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table dept_partition_dynamic
partition(loc)
select deptno, dname, loc
from dept;
(3)查看目标分区表的分区情况
show partitions dept_partition_dynamic;
分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分,分区针对的是数据的存储路径,分桶针对的是数据文件。
分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)。
分桶表基本语法
(1)建表语句
create table stu_buck(id int, name string
)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
(2)数据装载
创建student.txt文件,并输入如下内容,上传HDFS
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
1011 student11
1012 student12
1013 student13
1014 student14
1015 student15
1016 student16
(2)导入数据到分桶表中
说明:Hive新版本load数据可以直接跑MapReduce,老版的Hive需要将数据传到一张表里,再通过查询的方式导入到分桶表里面。
load data inpath 'hdfs://flinkv1:8020/input/student.txt'into table stu_buck;
(3)查看创建的分桶表中是否分成4个桶
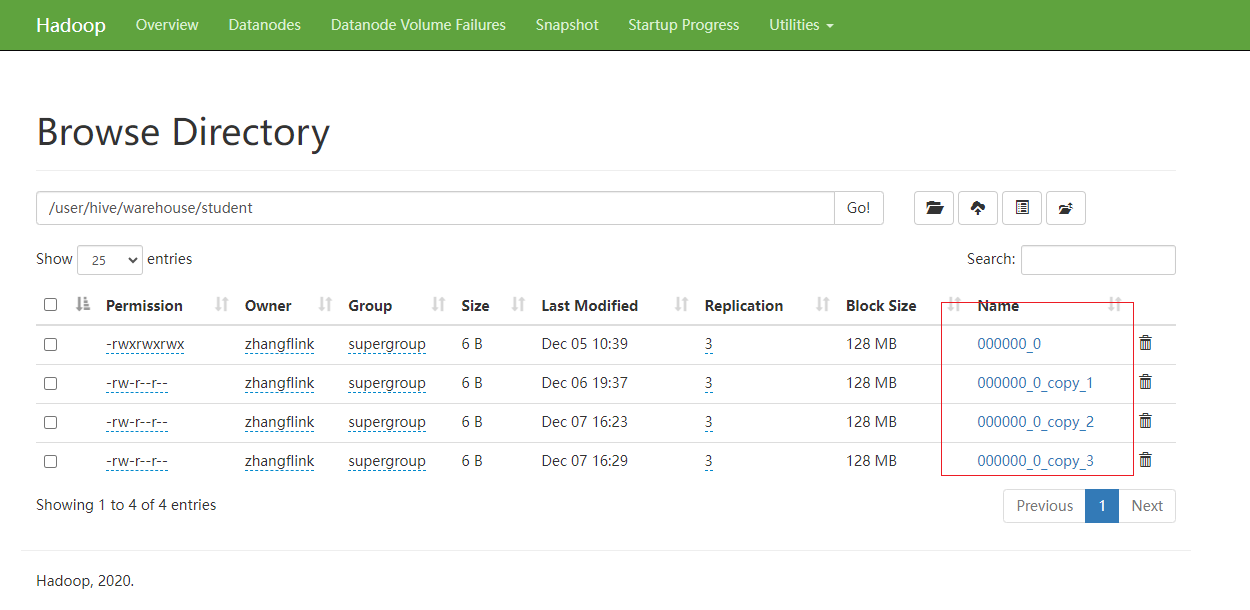
(4)观察每个分桶中的数据
分桶排序表
(1)建表语句
create table stu_buck_sort(id int, name string
)
clustered by(id) sorted by(id)
into 4 buckets
row format delimited fields terminated by '\t';
(2)数据装载
load data inpath 'hdfs://flinkv1:8020/input/student.txt'into table stu_buck_sort;
相关文章:
hive的分区表和分桶表详解
分区表 Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。 静态分区表基本语法 创建分区表 create table dept_p…...
verilog语法进阶-分布式ram
概述: FPGA的LUT查找表是用RAM设计的,所以LUT可以当成ram来使用,也并不是所有的LUT都可以当成ram来使用,sliceM的ram可以当成分布式ram来使用,而sliceL的ram只能当成rom来使用,也就是只能读,不能写&#x…...

HarmonyOS使用HTTP访问网络
HTTP数据请求 1 概述 日常生活中我们使用应用程序看新闻、发送消息等,都需要连接到互联网,从服务端获取数据。例如,新闻应用可以从新闻服务器中获取最新的热点新闻,从而给用户打造更加丰富、更加实用的体验。 那么要实现这样一种…...
GZ015 机器人系统集成应用技术样题1-学生赛
2023年全国职业院校技能大赛 高职组“机器人系统集成应用技术”赛项 竞赛任务书(学生赛) 样题1 选手须知: 本任务书共 25页,如出现任务书缺页、字迹不清等问题,请及时向裁判示意,并进行任务书的更换。参赛队…...
计算机毕业设计 基于SpringBoot的日常办公用品直售推荐系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
uniapp:使用fixed定位,iOS平台的安全区域问题解决
manifest.json > 添加节点 "safearea": { //iOS平台的安全区域"background": "#1C1E22","backgroundDark": "#1C1E22", // HX 3.1.19支持"bottom": {"offset": "auto"} },已解决ÿ…...
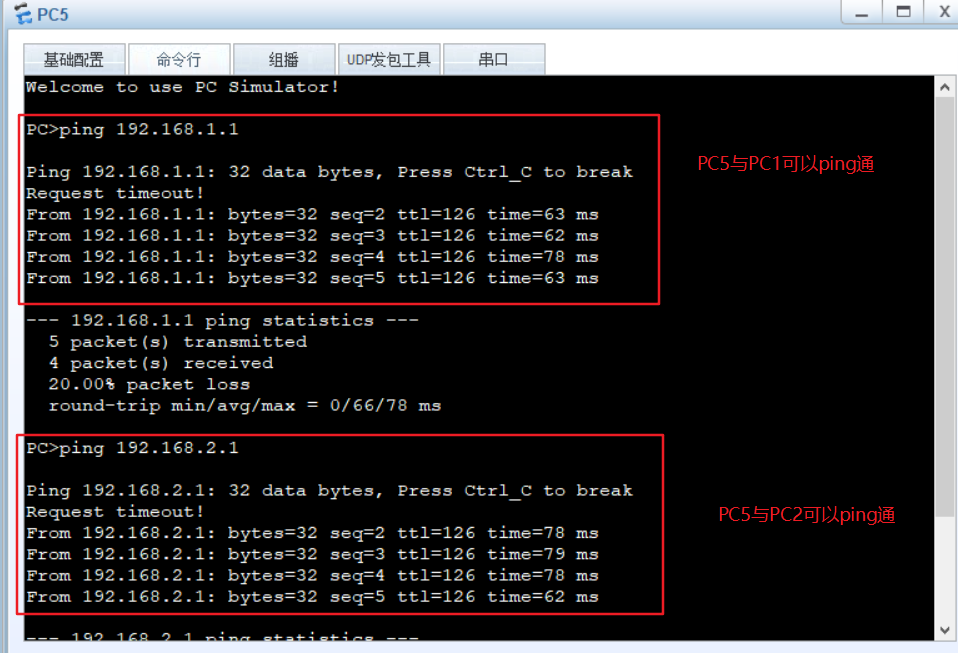
三层交换机原理与配置
文章目录 三层交换机原理与配置一、三层交换技术概述二、传统的 MLS三、基于CEF 的MLS1、转发信息库(FIB)2、邻接关系表3、工作原理: 四、三层交换机的配置1、三层交换机配置命令2、三层交换机配置步骤 三层交换机原理与配置 一、三层交换技…...
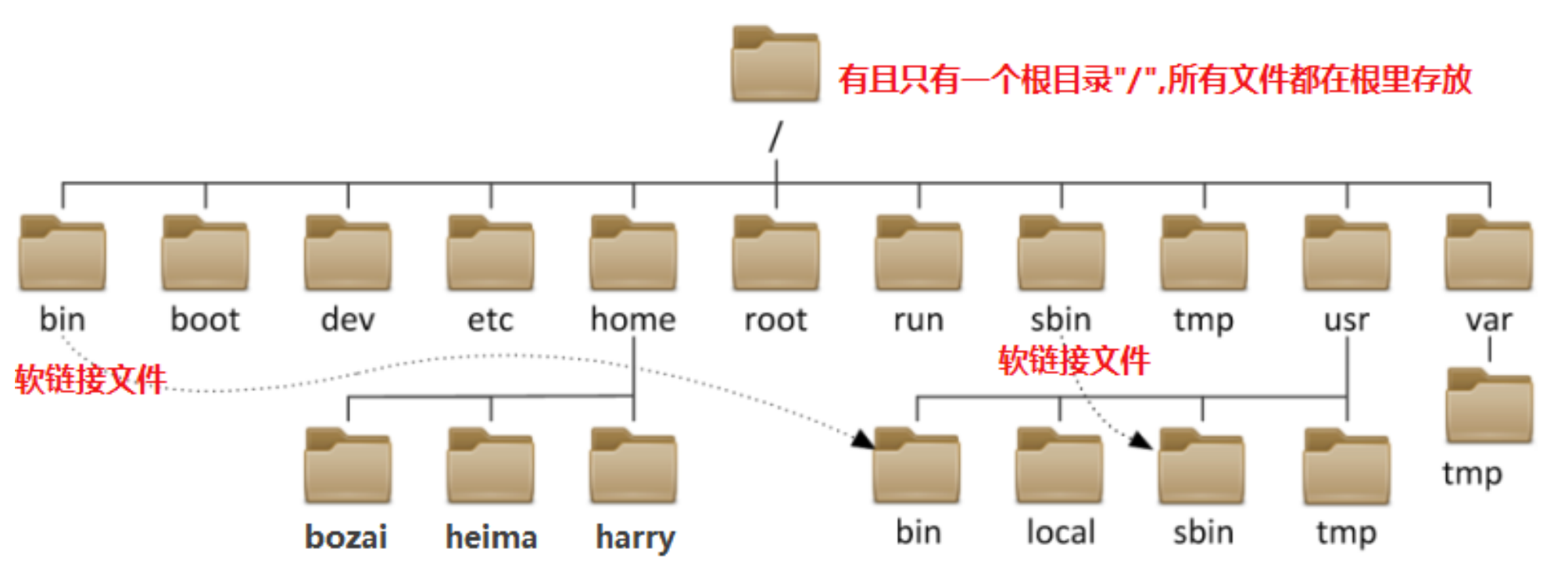
Linux-----5、文件系统
# 文件系统 # 终端的基本操作 ㈠ 打开多个终端 ㈡ 快速清屏 新建标签:command T 新建窗口:command N 关闭标签:command Q 关闭窗口:command W 放大:command 缩小:command - 清屏ÿ…...
电脑自动关机怎么设置?
电脑自动关机怎么设置?如果你是一名上班族,工作忙起来很多事情都会忘记做,有时候忙到很晚后紧急下班,就会忘记给电脑关机,电脑如果经常不关机,那么电脑就会超负荷的运转,大家都知道电脑的寿命是…...
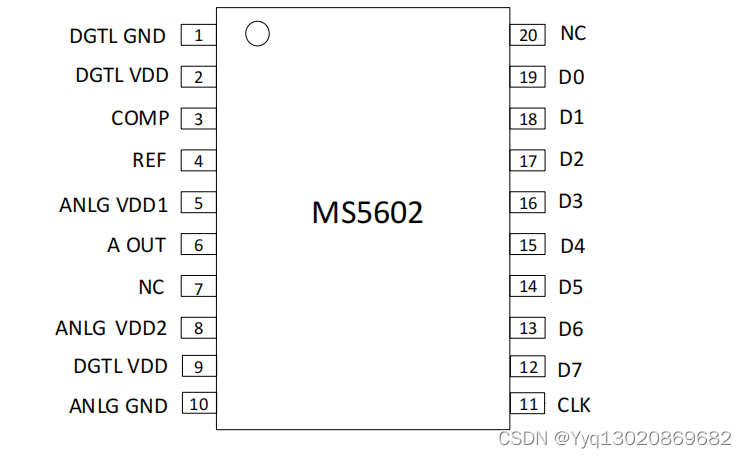
MS5602视频 8 位数模转换器,可替代TLC5602
MS5602 是低功率、超高速视频数模转换器。 MS5602 以 DC 至 20MHz 的采样速率,将数字信号转换成模拟信号。由于高速工作 的特性, MS5602 适合于数字电视、电脑视频处理及雷达信号处 理等数字视频应用。 MS5602 工作在 -40C 至 85C 的温度范围内 …...
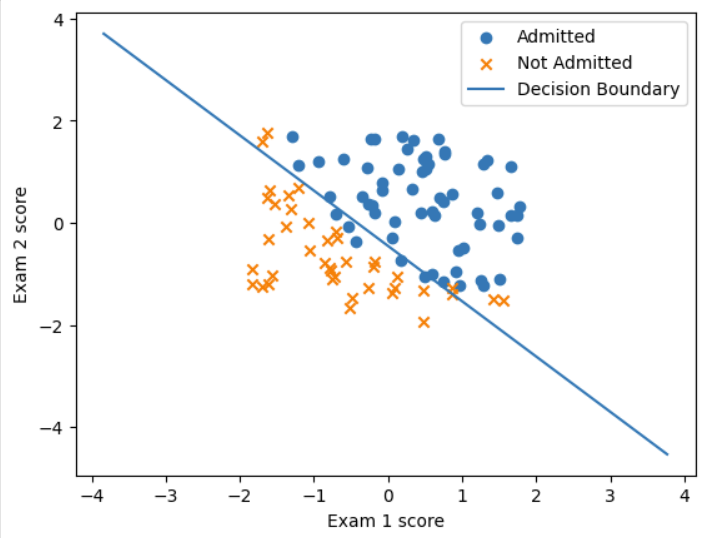
Logistic Regression——逻辑回归
1. 为什么需要逻辑回归 在前面学习的线性回归中,我们的预测值都是任意的连续值,例如预测房价。除此之外,还有一个常见的问题就是分类问题,而逻辑回归是一个解决分类问题的模型,其预测值是离散的。 分类问题又包括…...
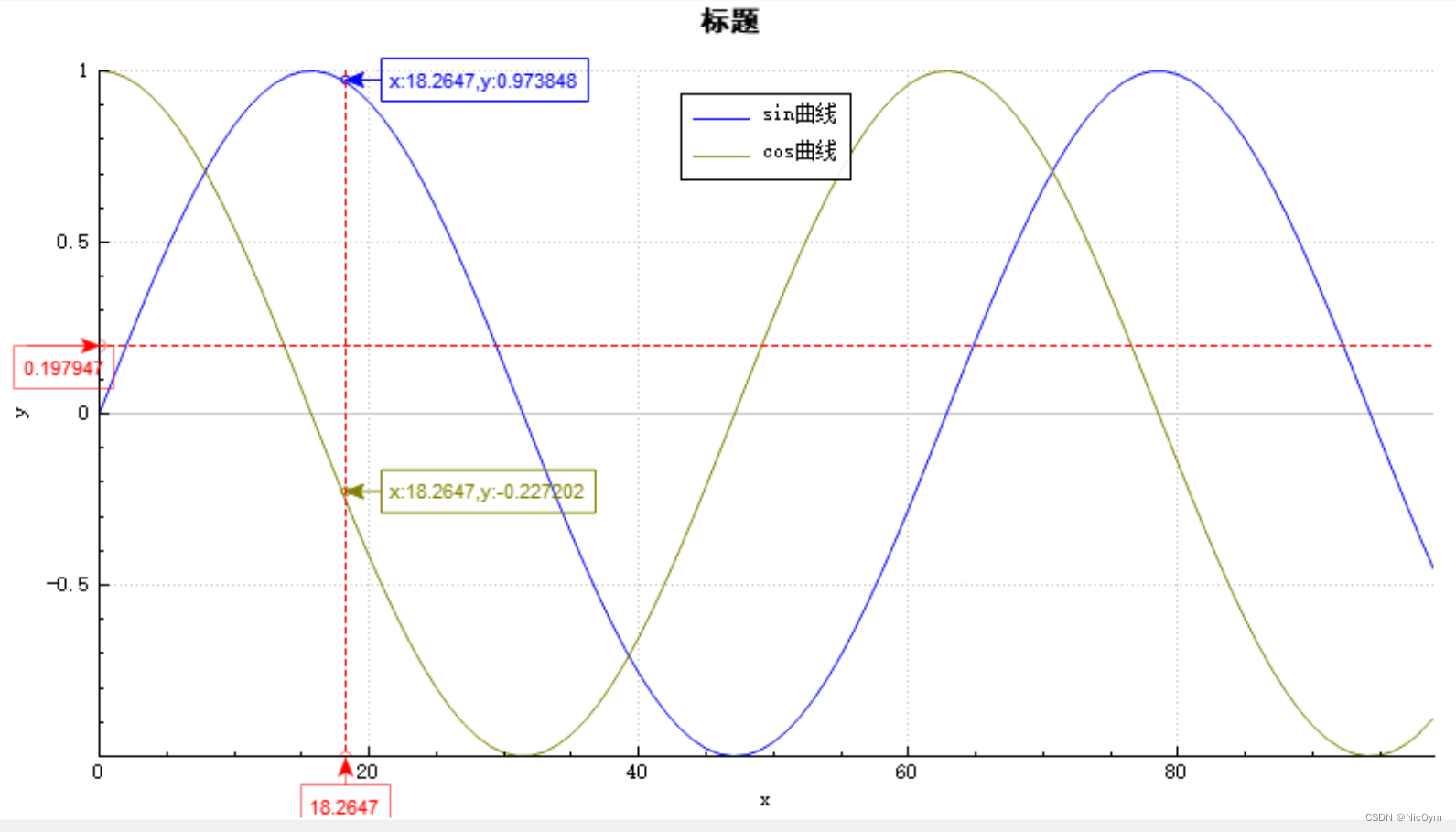
跟随鼠标动态显示线上点的值(基于Qt的开源绘图控件QCustomPlot进行二次开发)
本文为转载 原文链接: 采用Qt快速绘制多条曲线(折线),跟随鼠标动态显示线上点的值(基于Qt的开源绘图控件QCustomPlot进行二次开发) 内容如下 QCustomPlot是一个开源的基于Qt的第三方绘图库,能…...
Todesk、向日葵等访问“无显示器”主机黑屏问题解决
我的环境是 ubuntu 22.04 安装 要安装 video dummy,请在终端中运行以下命令: sudo apt install xserver-xorg-video-dummy配置 video dummy 的配置文件请自行搜索 使用任何文本编辑器打开此文件。 我的是 /etc/X11/xorg.conf 默认配置文件包含以下内…...

maven打包插件maven-jar-plugin与spring-boot-maven-plugin
maven几种打包插件介绍 文章目录 🔊1.spring-boot-maven-plugin打包后效果 📕2.maven-jar-plugin打包后效果🖊️最后总结 🔊1.spring-boot-maven-plugin <plugins><plugin><groupId>org.springframework.boot&…...

uniapp微信小程序下载base64图片流或https图片
常规https的图片下载是这样的 const urlPath https://test/logo.png uni.downloadFile({url: urlPath,success(res){// 这时会产生一个临时路径,在应用本次启动期间可以正常使用。if (res.statusCode 200) {// 需要将图片保存到相册uni.saveImageToPhotosAlbum({…...
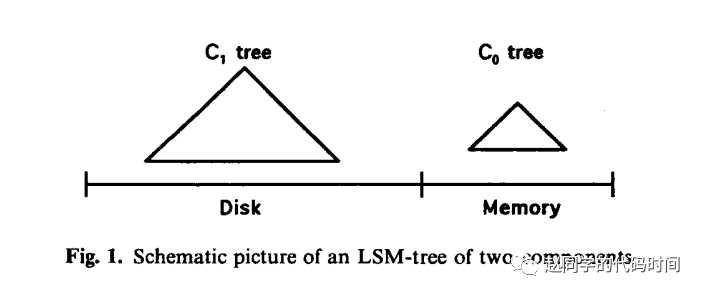
数据结构 | Log-Structured Merge Tree (LSM Tree)
今天介绍LSM Tree这个数据结构,严格意义上来说,他并不像他的名字一样是一棵树型的数据结构,而更多是一种设计思想。 LSM Tree最先在1996年被提出,后来被广泛运用于现代NoSQL(非关系型数据库)系统中…...
)
QEMU源码全解析 —— virtio(9)
接前一篇文章: 上两回讲解了virtio balloon相关类所涉及的realize函数以及大致流程,如下表所示: realize函数parent_dc_realize函数DeviceClassvirtio_pci_dc_realizePCIDeviceClassvirtio_pci_realizeVirtioPCIClassvirtio_balloon_pci_rea…...
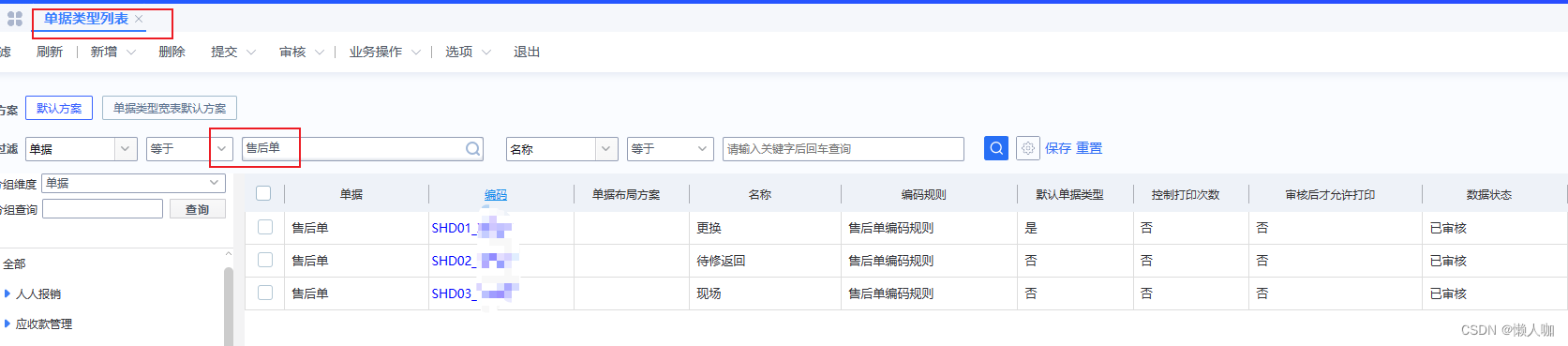
金蝶云星空协同开发环境应用内执行单据类型脚本
文章目录 金蝶云星空协同开发环境应用内执行单据类型脚本业务界面查询单据类型表数据导出数据执行数据库脚本单据类型xml检验是否执行成功检查数据库检查业务数据 金蝶云星空协同开发环境应用内执行单据类型脚本 业务界面 查询单据类型表数据 先使用类型中文在单据类型多语言…...

矩阵理论及其应用邱启荣习题3.5题解
(1) P ( − 1 0 1 − 1 − 1 2 1 1 − 1 ) \begin{pmatrix} -1 & 0&1 \\ -1 & -1&2\\1&1&-1 \end{pmatrix} −1−110−1112−1 A ( 1 0 1 1 1 0 − 1 2 1 ) \begin{pmatrix} 1 & 0&1 \\ 1 & 1&0\\-1&2&1 \end{pmat…...
-------连载(49))
Java面试题(每天10题)-------连载(49)
目录 Tomcat篇 1、Tomcat的缺省端口是多少?怎么修改? 2、Tomcat有哪几种Connector运行模式(优化)? 3、Tomcat有几种部署方式? 4、Tomcat容器时如何创建servlet类实例?用到了什么原理&…...

电子围栏系统设计:基于基站定位的防疫隔离技术方案解析
1. 项目概述:电子围栏系统的核心逻辑与设计初衷在2020年初那场席卷全球的公共卫生事件中,如何有效管理居家隔离人员,防止疫情在社区内扩散,成了各国政府面临的共同难题。当时,我作为技术顾问,深度参与了一些…...

Java统一AI SDK实战:集成OpenAI、Claude、Gemini多模型API
1. 项目概述与核心价值 最近在折腾一个需要集成多个大模型API的Java项目,从OpenAI到Claude再到Google Gemini,每个厂商的SDK调用方式、请求体结构、错误处理都不太一样,光是写适配代码就够喝一壶的。更别提还要处理流式响应、文件上传、Func…...

别再只会用ActivePart了!CATIA二次开发中,如何用C#递归遍历任意复杂结构树?
CATIA二次开发进阶:用C#递归算法征服任意复杂装配树 在CATIA二次开发领域,ActivePart就像新手司机的自动挡——简单易用却限制重重。当面对包含数百个零件的飞机发动机装配体,或是横跨多个产品的汽车底盘系统时,仅能操作当前激活零…...


3步搞定微信聊天记录导出:Mac用户必备的数据备份指南
3步搞定微信聊天记录导出:Mac用户必备的数据备份指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录因为手机丢失或系统升级而…...
)
ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板) Discord 的异步消息流、上下文截断机制与用户高频…...
)
Discord服务器日活破5万后ChatGPT机器人崩了?百万级消息队列+状态分片架构设计(附GitHub星标1.2k的开源模板)
更多请点击: https://intelliparadigm.com 第一章:Discord服务器日活破5万后ChatGPT机器人崩了? 当 Discord 社区日活跃用户突破 5 万时,一个基于 OpenAI API 的 ChatGPT 机器人在高峰时段突然出现 98% 的请求超时与 429…...

Cursor Pro破解工具完整指南:如何绕过限制实现永久免费使用
Cursor Pro破解工具完整指南:如何绕过限制实现永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

浏览器扩展开发实战:KeepChatGPT会话保持原理与实现
1. 项目概述:一个浏览器扩展的诞生与使命 最近在和一些做AI应用开发的朋友交流时,大家普遍反映了一个痛点:在使用一些大型语言模型(LLM)的在线服务时,对话经常会被意外中断。这种中断可能源于网络波动、服…...

pip cache purge 清理下载缓存文件
如上图所示的这个目录是 Python 的包管理工具 pip 用来存储下载过的安装包(wheel 或源码包)的缓存。它的主要作用是在你下次安装同一个包时,可以直接从本地读取,而无需再次从网络下载,从而加快安装速度。 但是…...